Sql join синтаксис: Оператор SQL INNER JOIN: синтаксис, примеры
Содержание
Синтаксис SQL — CodeChick
В этой статье вы познакомитесь с синтаксисом SQL, который регулируется Американским национальным институтом стандартов (ANSI) и Международной организацией по стандартизации (ISO).
Инструкции в SQL
Инструкции в SQL очень просты и понятны, как обычный английский язык. Но у них есть специфический синтаксис.
SQL-инструкция состоит из последовательности ключевых слов, идентификаторов и т.д., завершаемых точкой с запятой (;). Вот пример правильной инструкции в SQL:
SELECT emp_name, hire_date, salary FROM employees WHERE salary > 5000;
Для лучшей читабельности лучше переписать ту же инструкцию следующим образом:
SELECT emp_name, hire_date, salary FROM employees WHERE salary > 5000;
Точка с запятой в конце оператора SQL завершает инструкцию или отправляет инструкцию на сервер базы данных.
В некоторых системах управления базами данных, правда, такого требования нет, но использование точки с запятой считается хорошей практикой. Мы подробно рассмотрим каждую часть этих операторов в следующих статьях.
Примечание. Внутри SQL-инструкции может быть сколько угодно переносов строк, при условии, что любой перенос строки не обрывает ключевые слова, значения, выражения и т.д.
Чувствительность к регистру в SQL
Рассмотрим другую инструкцию в SQL, который извлекает записи из таблицы employees:
SELECT emp_name, hire_date, salary FROM employees;
Эту же инструкцию можно записать так — используя ключевые слова в нижнем регистре:
select emp_name, hire_date, salary from employees;
Ключевые слова в SQL не чувствительны к регистру, то есть SELECT — это то же самое, что select. Но имена баз данных и таблиц могут быть чувствительны к регистру в зависимости от операционной системы. Обычны Unix или Linux чувствительны к регистру, а Windows — нет.
Но имена баз данных и таблиц могут быть чувствительны к регистру в зависимости от операционной системы. Обычны Unix или Linux чувствительны к регистру, а Windows — нет.
Совет. Лучше записать ключевые слова в верхнем регистре, чтобы отличать их от другого текста внутри SQL-инструкции — так проще читать.
Комментарии в SQL
Комментарий — это просто текст, который игнорируется механизмом базы данных.
SQL поддерживает как однострочные, так и многострочные комментарии. Чтобы написать однострочный комментарий, используйте перед комментарием два дефиса (--). Например:
-- Выбирает всех сотрудников SELECT * FROM employees;
А чтобы написать многострочные комментарии, используйте перед комментарием слеш и звездочку (/*). В конце комментария — звездочка и слеш (*/). Например:
/* Выбирает всех сотрудников, у которых зарплата больше 5000 */ SELECT * FROM employees WHERE salary > 5000;
sql — Как правильно организовать синтаксис LEFT JOIN при объединении нескольких таблиц
Создайте представление (VIEW), которое будет объединять в себе все значения атрибутов по всем
поставкам.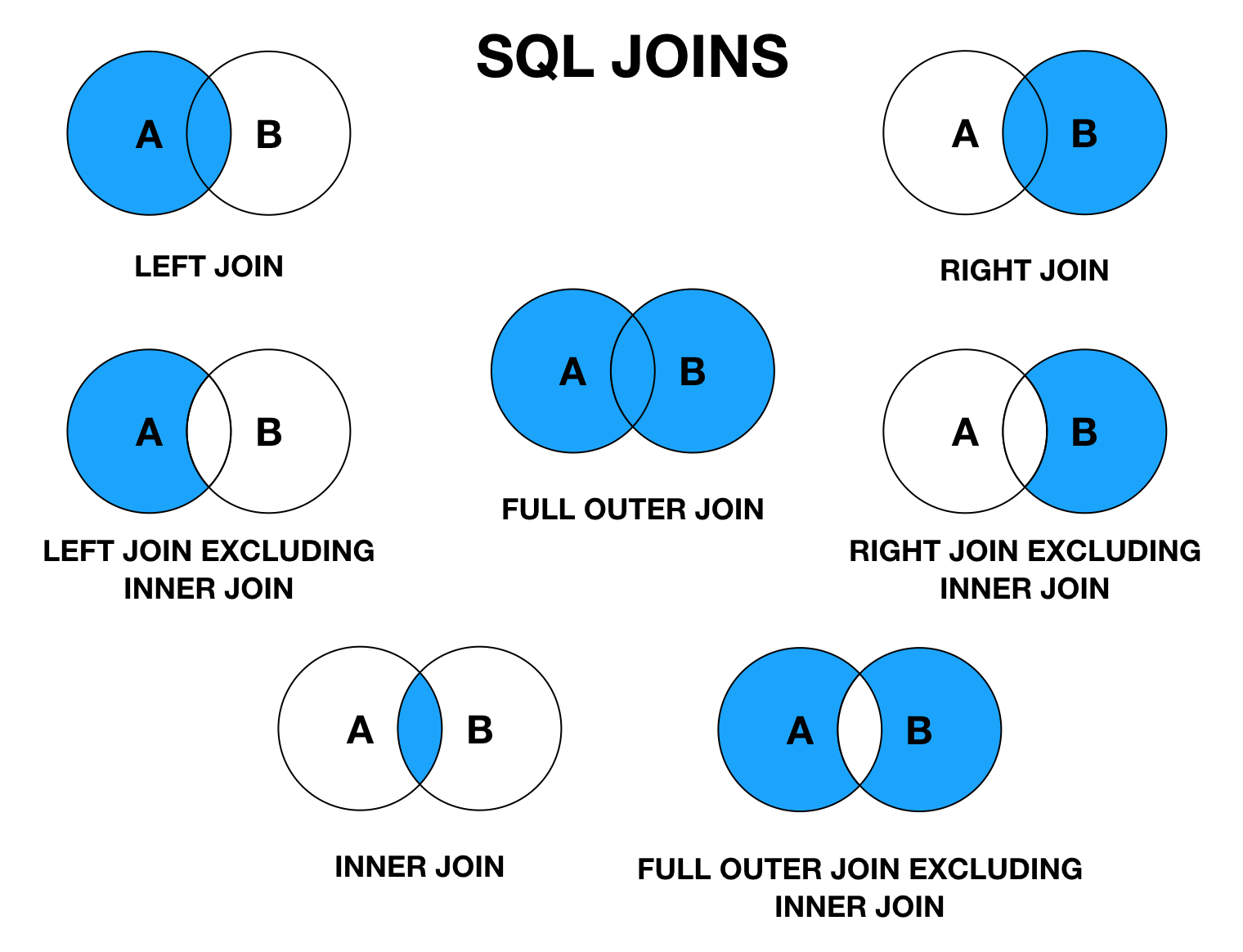 Это представление должно включать в себя в денормализованной форме все данные по
Это представление должно включать в себя в денормализованной форме все данные по
поставке из БД. Одна строка – одна поставка. Идентификаторы записей из таблиц, при помощи которых
связываем таблицы соединениями (JOIN) в представление включать НЕ НАДО. Только фактические
значения.
Таблица 1city — справочник городов
city_id Уникальный идентификатор города, первичный
ключ
city_name Название города
state Штат, к которому относится город
population Население города
area Площадь города
Таблица 2 driver — справочник водителей
driver_id Уникальный идентификатор водителя, первичный ключ
first_name Имя водителя
last_name Фамилия водителя
address Адрес водителя
zip_code Почтовый индекс водителя
phone Телефон водителя
city_id Идентификатор города водителя, внешний ключ к
таблице city
Таблица 3 customer — справочник клиентов
cust_id Уникальный идентификатор клиента, первичный ключ
cust_name Название клиента
annual_revenue Ежегодная выручка
cust_type Тип пользователя
address Адрес
zip Почтовый индекс
phone Телефон
city_id Идентификатор города, внешний ключ к таблице city
Таблица 4 truck — информация о грузовиках, на которых совершаются перевозки
truck_id Уникальный идентификатор грузовика, первичный ключ
make Производитель грузовика
model_year Дата выпуска грузовика
Таблица 5 shipment — доставки
ship_id integer Уникальный идентификатор доставки, первичный ключ
cust_id integer Идентификатор клиента, которому отправлена доставка, внешний ключ к таблице customer
weight numeric Вес посылки
truck_id integer Идентификатор грузовика,на котором отправлена доставка, внешний ключ к таблице truck
driver_id integer Идентификатор водителя, который осуществлял доставку, внешний ключ к таблице driver
city_id integer Идентификатор города в который совершена доставка, внешний ключ к таблице city
ship_date date Дата доставки
ниже пример моей организации кода. только начинаю изучать и не понимаю до конца, как правильно расположить всё. Что располагать в ON?
только начинаю изучать и не понимаю до конца, как правильно расположить всё. Что располагать в ON?
На просторах интернета синтаксис только для двух таблиц нашла. или нужно еще подзапрос реализовывать?
create view aggregate5 AS select city_name, state,population, area, weight, ship_date, first_name, last_name, sql_driver.address as address_drive, zip_code, sql_driver.phone as phone_drive, make, model_year, cust_name, annual_revenue, cust_type, sql_customer.address as address_cust, zip, sql_customer.phone as phone_cust
from sql_shipment, sql_customer, sql_city, sql_driver, sql_truck
LEFT JOIN sql_shipment ON sql_shipment.ship_id=sql_customer.cust_id
LEFT JOIN sql_customer on sql_customer.city_id=sql_city.city_id
LEFT JOIN sql_city on sql_city.city_id=sql_customer.city_id
LEFT JOIN sql_driver on sql_driver.driver_id= sql_shipment.driver_id
LEFT JOIN sql_truck on sql_truck.truck_id=sql_shipment.truck_id
where sql_shipment.cust_id=sql_customer.cust_id and sql_customer. city_id=sql_city.city_id and sql_shipment.driver_id=sql_driver.driver_id
city_id=sql_city.city_id and sql_shipment.driver_id=sql_driver.driver_id
 city_id=sql_city.city_id and sql_shipment.driver_id=sql_driver.driver_id
city_id=sql_city.city_id and sql_shipment.driver_id=sql_driver.driver_id
Несколько замечаний по синтаксису соединений в SQL
В этом руководстве мы познакомим вас с некоторыми особенностями синтаксиса соединений в SQL. Не только внутренние соединения, но и соединения любого типа.
Чтобы полностью понять код, который мы написали, вы можете просмотреть предыдущее руководство по этой теме и наш курс SQL. Кроме того, вы можете увидеть, как загрузить базу данных, которую мы будем использовать, в связанном руководстве.
Возможные изменения в синтаксисе соединений в SQL
Во-первых, мы знаем, что в выводе мы можем выбрать разные столбцы из таблиц, на которые мы ссылаемся.
В нашем примере мы выбрали номера отделов и сотрудников из таблицы-дубликата « dept_manager_dup », а название отдела — из таблицы « Departments_dup ».
Мы могли бы также добавить даты начала и окончания контрактов менеджеров. Проверим на м.от_даты и м.до_даты.
Проверим на м.от_даты и м.до_даты.
Таким образом, мы можем добавить любую комбинацию столбцов в наш вывод. Единственным условием является то, что каждый столбец должен быть частью одной из соединяемых таблиц.
Другой способ написания кода
Второе замечание, которым я хотел бы поделиться с вами, заключается в том, что некоторые люди предпочитают сначала вводить код в блоке FROM . Это потому, что они хотят заранее указать все псевдонимы, которые им понадобятся в остальной части запроса.
Изменение заказа
Например, они сначала напечатают следующее:
Затем они будут указывать интересующие выборки, вставляя имена полей с помощью назначенных псевдонимов. Итак, в итоге код будет выглядеть так:
ВЫБЕРИТЕ
m.dept_no, m.emp_no, m.from_date, m.to_date, d.dept_name
ОТ
dept_manager_dup м
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Departments_dup d ON m. dept_no = d.dept_no;  dept_no = d.dept_no;
dept_no = d.dept_no; Это может быть полезно, если вы присоединяетесь к более чем 2 таблицам, но, на мой взгляд, можно привыкнуть помнить несколько букв и следовать нисходящему потоку запроса.
В любом случае порядок следования остается на усмотрение кодировщика. Важно то, что запрос, который вы написали, правильный.
Исключение ключевого слова INNER
Что касается синтаксиса внутренних соединений в SQL, то слово INNER не обязателен. Его можно было бы опустить. В этом запросе, вводите ли вы INNER JOIN или просто JOIN , разницы нет.
SQL всегда поймет, что вы говорите о внутреннем соединении. Это то, что обычно делают практикующие. Вот почему мы будем использовать JOIN вместо INNER JOIN .
Указание совпадающих столбцов
Еще одна проблема, с которой может столкнуться начинающий программист SQL, заключается в том, имеет ли значение порядок, в котором вы указываете совпадающие столбцы.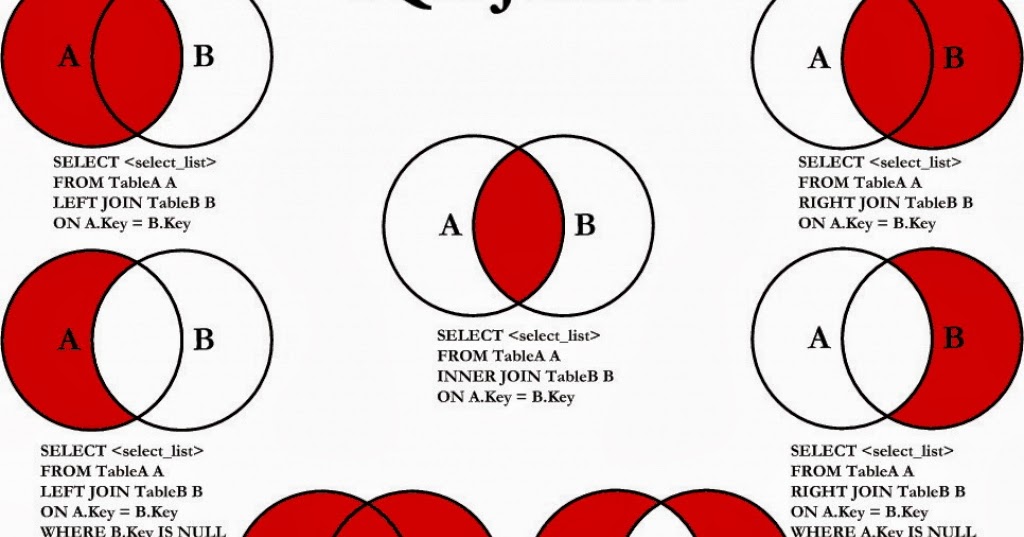
То есть есть ли разница между вводом « m.dept_no = d.dept_no » и « d.dept_no = m.dept_no »?
Как видно на картинке выше, разницы нет. Это зависит от вас. Сначала я использовал таблицу M , а затем таблицу D , чтобы избежать путаницы с порядком, в котором мы определили две таблицы для соединения. Так что с технической точки зрения разницы никакой.
ЗАКАЗ ПО Пункт
Давайте сосредоточимся на предложении ORDER BY . Мы отсортировали полученный результат по номеру отдела из таблицы « dept_manager_dup ». Технически этот запрос будет работать, если мы удалим указание таблицы.
Также будет работать, если мы изменим его на таблицу « Departments_dup ».
Дело в том, что не очевидно, почему мы используем « m.dept_no », а не что-то другое. Но вы оцените эту маленькую деталь, когда будете работать с гораздо большими наборами данных, процедурами, индексами и другими инструментами. Если вы не используете это обозначение при указании столбца « dept_manager_dup », SQL выдаст ошибку!
Если вы не используете это обозначение при указании столбца « dept_manager_dup », SQL выдаст ошибку!
Различные стили кода
Подводя итог, можно сказать, что существуют различные способы кодирования, и все они возможны благодаря синтаксису соединений в SQL. Вы можете решить, писать ли оператор SELECT сначала или после написания FROM . Вы можете отдохнуть, не написав ни одного лишнего слова, например INNER при создании JOIN . Кроме того, вы можете указать соответствующие столбцы в любом порядке. Что вы напишете после 9Пункт 0009 ORDER BY также является вашим решением.
Я надеюсь, что после прочтения этих заметок вы почувствуете, что присоединились к сообществу SQL.
Перейдя к следующему руководству, вы отправитесь в путешествие, чтобы узнать, что такое дубликаты записей и как с ними бороться.
***
Стремитесь отточить свои навыки SQL? Узнайте, как применить теорию на практике с помощью наших практических руководств !
Следующее руководство: повторяющиеся записи в SQL
Обнаружение запахов кода с помощью подсказки SQL: синтаксис соединения в старом стиле (ST001)
- SQL-запрос
- Анализ кода SQL
Использование старого синтаксиса объединения не дает никаких преимуществ.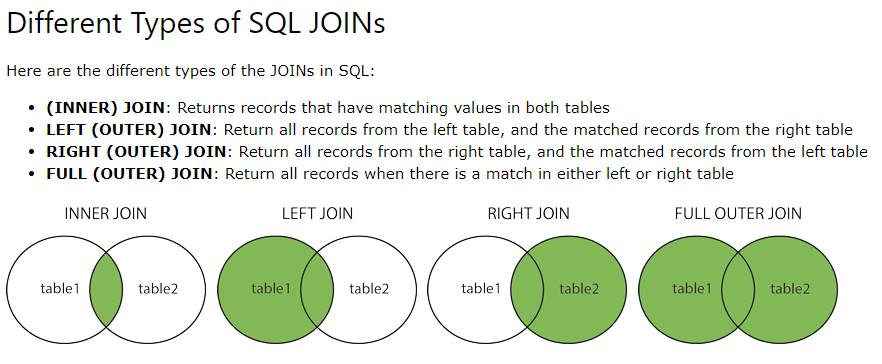 Если подсказка SQL определяет его использование в устаревшем коде, то переписывание операторов для использования стандартного синтаксиса соединения ANSI упростит и улучшит код.
Если подсказка SQL определяет его использование в устаревшем коде, то переписывание операторов для использования стандартного синтаксиса соединения ANSI упростит и улучшит код.
Гостевой пост
Это гостевой пост от Фила Фактора. Фил Фактор (настоящее имя не разглашается, чтобы защитить виновных), также известный как Database Mole, имеет 30-летний опыт работы с приложениями, интенсивно использующими базы данных.
Несмотря на то, что однажды разъяренный Билл Гейтс накричал на него на выставке в начале 1980-х, он оставался решительно анонимным на протяжении всей своей карьеры.
Он является постоянным участником Simple Talk и SQLServerCentral .
SQL Prompt реализует правило статического анализа кода, ST001, которое будет автоматически проверять код во время разработки и тестирования на наличие нестандартного синтаксиса JOIN, отличного от ANSI.
«Старый стиль» Microsoft/Sybase JOIN для SQL, который использует синтаксис =* и *=, устарел и больше не используется. Запросы, использующие этот синтаксис, завершатся ошибкой, если уровень ядра базы данных равен 10 (SQL Server 2008) или более поздней версии (уровень совместимости 100). ANSI-89список цитирования таблицы (FROM tableA, tableB) по-прежнему является стандартом ISO только для ВНУТРЕННИХ СОЕДИНЕНИЙ. Ни один из этих стилей не стоит использовать. Всегда лучше указать требуемый тип соединения: ВНУТРЕННЕЕ, ЛЕВОЕ ВНЕШНЕЕ, ПРАВОЕ ВНЕШНЕЕ, ПОЛНОЕ ВНЕШНЕЕ и ПЕРЕКРЕСТНОЕ, которое является стандартным с момента публикации ANSI SQL-92. Хотя вы можете выбрать любой поддерживаемый стиль JOIN, не влияя на план запроса, используемый SQL Server, использование стандартного синтаксиса ANSI сделает ваш код более понятным, более согласованным и переносимым в другие системы реляционных баз данных.
Запросы, использующие этот синтаксис, завершатся ошибкой, если уровень ядра базы данных равен 10 (SQL Server 2008) или более поздней версии (уровень совместимости 100). ANSI-89список цитирования таблицы (FROM tableA, tableB) по-прежнему является стандартом ISO только для ВНУТРЕННИХ СОЕДИНЕНИЙ. Ни один из этих стилей не стоит использовать. Всегда лучше указать требуемый тип соединения: ВНУТРЕННЕЕ, ЛЕВОЕ ВНЕШНЕЕ, ПРАВОЕ ВНЕШНЕЕ, ПОЛНОЕ ВНЕШНЕЕ и ПЕРЕКРЕСТНОЕ, которое является стандартным с момента публикации ANSI SQL-92. Хотя вы можете выбрать любой поддерживаемый стиль JOIN, не влияя на план запроса, используемый SQL Server, использование стандартного синтаксиса ANSI сделает ваш код более понятным, более согласованным и переносимым в другие системы реляционных баз данных.
Внешние соединения в старом стиле устарели
Когда SQL Server отделился от Sybase, он унаследовал свой старый нестандартный синтаксис Transact-SQL для соединений, который включал синтаксис = и = для левого и правого внешние соединения соответственно.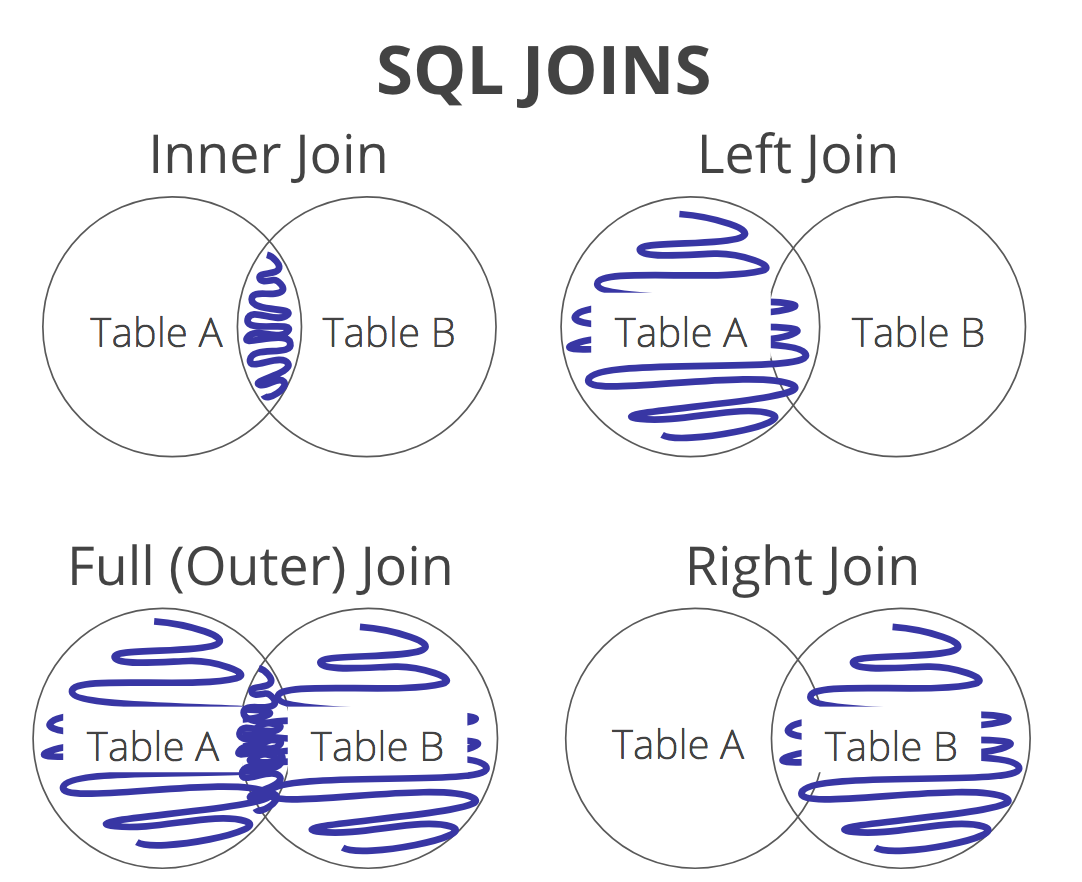
Левый оператор внешнего соединения, *= , выбрал из первой таблицы («внешнего члена» внешнего соединения) все строки, соответствующие ограничениям инструкции. Вторая таблица («внутренний элемент») генерирует значения только в том случае, если для этой строки есть совпадение по условию соединения; в противном случае он предоставлял нулевые значения. И наоборот, для правого оператора внешнего соединения =* вторая таблица стала «внешним элементом», из которого были выбраны все строки, соответствующие критериям.
Для этого синтаксиса существовали ограничения, даже когда они поддерживались. Вы не могли включить внешнее соединение Transact-SQL в предложение HAVING , и вы не могли сделать дополнительное INNER JOIN в том же выражении, что и внешнее соединение в старом стиле. Кроме того, синтаксис внешнего соединения ( *= или =* ) не всегда дает правильные результаты, иногда используется перекрестное соединение, когда указано внешнее соединение.
В любом случае этот синтаксис устарел в SQL Server 2005 и более поздних версиях и перестал работать в SQL Server 2008. Цель листинга 1, который запрашивает базу данных pubs, состоит в том, чтобы вернуть все заголовки, у которых нет соответствующего автора.
—все заголовки без автора ВЫБЕРИТЕ ti.title + Coalesce( ‘ (‘ + ti.type + ‘) -‘ + ti.pub_id,’ (Неизвестная категория)’) КАК публикация FROM dbo.titles AS ti, dbo.titleавтор AS Ta где ti.title_id *= Ta.title_id AND Ta.title_id IS NULL; |
Листинг 1
Однако в SQL Server 2008 или позже, если вы не установите уровень совместимости до 90. Этот параметр был возможен только до SQL Server 2012:
MSG 102, уровень 15, состояние 1 , Строка 6
Неверный синтаксис рядом с '*='.
Если у вас все еще есть запросы, использующие этот синтаксис, вам придется переписать их для использования стандартного синтаксиса ANSI, показанного в листинге 2, перед обновлением до SQL Server 2012, поскольку уровень совместимости 90 больше не поддерживается.
1 2 3 4 5 6 7 | —все заголовки без автора ВЫБЕРИТЕ ti.title + Coalesce( ‘ (‘ + ti.type + ‘) -‘ + ti.pub_id,’ (Неизвестная категория)’) КАК публикация FROM dbo.titles AS ti LEFT OUTER JOIN dbo.titleauthor AS Ta ON ti.title_id = Ta.title_id ГДЕ Ta.title_id IS NULL ПОРЯДОК ПО ti.title |
Листинг 2
Это дает следующий результат:
Внутренние соединения старого стиля, но не предлагают никаких преимуществ
Эта таблица Синтаксис цитирования для внутренних соединений является частью стандарта ANSI и, следовательно, все еще поддерживается. В листинге 3 он используется и возвращает всех авторов, живущих в том же городе, что и их издатель.
– (старый синтаксис) авторы, живущие в том же городе, что и их издатели
1 2 3 4 5 6 7 8 9 9 0003 | —(Старый синтаксис)авторы, проживающие в том же городе, что и их издатели 03 ОТ dbo. ГДЕ authors.au_id = titleauthor.au_id И titleauthor.title_id = titles.title_id И titles.pub_id = publishers.pub_id И publishers.city = author.city 9000 3 |
 authors, dbo.titleauthor, dbo.titles, dbo.publishers
authors, dbo.titleauthor, dbo.titles, dbo.publishersЛистинг 3
В листинге 4 показан тот же код, использующий стандарт ANSI-92, где типы соединений указаны явно.
1 2 3 4 5 6 7 8 9 10 11 12 | —(новый синтаксис) авторы, проживающие в том же городе, что и их издатели 0002 ОТ dbo .authors ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.titleauthor ON authors.au_id = titleauthor.au_id ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.titles ON titleauthor.title_id = titles.title_id ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.publishers ON titles.pub_id = publishers. ГДЕ издательства.город = авторы.город |
 pub_id
pub_idЛистинг 4
Оба дают одинаковый результат с идентичными планами выполнения.
Однако общепризнано, что старый синтаксис внутреннего соединения «список цитирования» гораздо сложнее читать и понимать, и поэтому он более подвержен ошибкам, чем новый синтаксис.
В любом случае, нет причин сожалеть об отказе от этого синтаксиса старого стиля, хотя он все еще поддерживается. Как, например, определить процент авторов, живущих в разных городах, от их издателей, используя синтаксис объединения в старом стиле? Это будет сложный запрос с использованием скобок и подзапросов. С новым синтаксисом его просто написать, легко понять его логику.
1 2 3 4 5 6 7 8 9 10 11 90 002 12 13 | —доля авторов, проживающих в том же городе, что и их издатели , (Сумма(СЛУЧАЙ, КОГДА publishers. |
