Транспонирование таблицы sql: Как транспонировать в sql — Q&A Хекслет
Содержание
SQL: Транспонирование таблиц(?) — Меркантильный гуру — LiveJournal
?
| |||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||
| LiveJournal.com | |||||||||||||||||||||||||||||||||
 ..];
..]; The output of a pivot
operation typically includes more columns and fewer rows than the starting data set.
The output of a pivot
operation typically includes more columns and fewer rows than the starting data set.Как транспонировать в sql
Обратите внимание, что значения в FieldName не ограничиваются именем пользователя, паролем и адресом электронной почты. Они могут быть чем угодно, так как они определены пользователем.
Они могут быть чем угодно, так как они определены пользователем.
Есть ли способ сделать это в SQL?
1 ответ
MySQL не поддерживает синтаксис ANSI PIVOT /UNPIVOT, так что вам остается использовать:
Как видите, операторы CASE должны быть определены для каждого значения. Чтобы сделать это динамичным, вам нужно использовать Синтаксис подготовленного оператора MySQL (динамический SQL) .
Я пробовал транпозу, но не нашел хорошего образца для получения этой таблицы в Teradata:
Спасибо за помощь.
1 ответ
я искал в течение нескольких часов без реального решения. Я хочу настроить постоянную задачу (каждую ночь). У меня есть таблица в базе данных Teradata на сервере 1. Каждую ночь мне нужно копировать всю таблицу из этого экземпляра teradata на мой сервер разработки (сервер 2), который имеет MySQL.
У меня есть таблица SQL, которая сохраняет значения, как показано на рисунке ниже Теперь мне нужно транспонировать эту таблицу, как показано ниже. Мне нужно сделать это без использования хранимой процедуры. Я пытаюсь привязать 2-ю таблицу к столбцу 4 datagridview checkbox.
Мне нужно сделать это без использования хранимой процедуры. Я пытаюсь привязать 2-ю таблицу к столбцу 4 datagridview checkbox.
случай использования, когда
Похожие вопросы:
Я использую Teradata. Я бы хотел переименовать таблицу со скриптом sql и не использовать bteq, если выполняются определенные условия. В частности: если TABLE_A существует => переименуйте таблицу.
Как транспонировать строки и столбцы из запроса SQL, как показано ниже. Использование SQL Server 2012 для написания запроса, который будет работать даже при добавлении данных в таблицу базы данных
Я хотел бы создать таблицу из набора данных, сгенерированного функцией teradata help table, чтобы добавить дополнительную информацию о таблице и иметь возможность фильтровать строки по условиям.
я искал в течение нескольких часов без реального решения. Я хочу настроить постоянную задачу (каждую ночь). У меня есть таблица в базе данных Teradata на сервере 1. Каждую ночь мне нужно копировать.
У меня есть таблица SQL, которая сохраняет значения, как показано на рисунке ниже Теперь мне нужно транспонировать эту таблицу, как показано ниже. Мне нужно сделать это без использования хранимой.
Мне нужно сделать это без использования хранимой.
Я хочу транспонировать эту таблицу, которая имеет только 1 строку с идентификатором клиента и столбцами ответа как response1, response2 и так далее. Я пробовал с pivot, но не смог правильно.
Как создать временную таблицу в teradata SQL Assistant? У меня есть запрос, который работает очень медленно, и я хочу оптимизировать его, создав временную таблицу. Я хочу иметь возможность.
кто-нибудь может мне помочь с этим, пожалуйста? Я хочу вставить данные в таблицу в Teradata SQL Assistant, но вставить только то, что не существует в таблице. У меня есть идеальный способ сделать.
Я хотел бы спросить вас, как переместить стол из SAS в TeradataSQL помощника. То, что я сделал в SAS, — это определить имя libname, а затем создать таблицу, которую я хочу переместить в Teradata.
У меня есть некоторые проблемы при создании таблицы в SQL/teradata,, так как простой следующий код успешно создает таблицу, но не вставляет в нее данные : CREATE VOLATILE MULTISET TABLE tablename.
как я могу просто переключать столбцы со строками в SQL? Есть ли простая команда для транспонирования?
ie повернуть этот результат:
PIVOT кажется слишком сложным для этого сценария.
8 ответов:
существует несколько способов преобразования этих данных. В своем первоначальном посте вы заявили, что PIVOT кажется слишком сложным для этого сценария, но он может быть очень легко наносится как с помощью UNPIVOT и PIVOT функции в SQL Server.
однако, если у вас нет доступа к этим функциям, это может быть реплицировано с помощью UNION ALL до UNPIVOT а затем агрегатная функция с CASE заявление PIVOT :
создать Таблица:
соединение все, агрегат и версия случая:
посмотреть SQL Скрипка с демо
The UNION ALL выполняет UNPIVOT данных путем преобразования столбцов Paul, John, Tim, Eric в отдельных строках. Затем вы применяете агрегатную функцию sum() С case утверждение, чтобы получить новые столбцы для каждого color .
преобразование и сводных статических Версия:
и UNPIVOT и PIVOT функции в SQL server делают это преобразование намного проще. Если вы знаете все значения, которые вы хотите преобразовать, вы можете жестко закодировать их в статической версии, чтобы получить результат:
посмотреть SQL Скрипка с демо
внутренний запрос с UNPIVOT выполняет ту же функцию, что и UNION ALL . Он берет список столбцов и превращает его в строки, PIVOT затем выполняет окончательное преобразование в столбцы.
Динамическая Версия Pivot:
если у вас есть неизвестное количество столбцов ( Paul, John, Tim, Eric в вашем примере), а затем неизвестное количество цветов для преобразования вы можете использовать динамический sql для создания списка в UNPIVOT а то PIVOT :
посмотреть SQL Скрипка с демо
динамическая версия запрашивает оба yourtable а то sys.columns таблица для создания список элементов UNPIVOT и PIVOT . Это затем добавляется в строку запроса для выполнения.
Плюсом динамической версии является то, что у вас есть изменяющийся список colors и/или names это создаст список во время выполнения.
все три запроса приведут к одному и тому же результату:

 Плюсом динамической версии является то, что у вас есть изменяющийся список colors и/или names это создаст список во время выполнения.
Плюсом динамической версии является то, что у вас есть изменяющийся список colors и/или names это создаст список во время выполнения.обычно это требует, чтобы вы заранее знали все метки столбцов и строк. Как вы можете видеть в приведенном ниже запросе, все метки перечислены в их полностью в операциях UNPIVOT и (re)PIVOT.
Настройка схемы MS SQL Server 2012:
запрос 1:
результаты:
Дополнительная Информация:
- дана таблица имя, вы можете определить все имена столбцов из sys.колонки или для XML обмана с помощью local-name ().
- вы также можете создать список различных цветов (или значений для одного столбца), используя для XML.
- вышеизложенное может быть объединено в динамический пакет sql для обработки любой таблицы.
вертикальное расширение
похоже на PIVOT, курсор имеет динамическую возможность добавлять больше строк по мере расширения набора данных, чтобы включить больше номеров политик.
горизонтальное расширение
в отличие от PIVOT, курсор выделяется в этой области, поскольку он может расширяться, чтобы включить новый добавленный документ, не изменяя сценарий.
расстройства
основное ограничение транспонирования строк в столбцы с помощью Курсор является недостатком, который связан с использованием курсоров в целом – они приходят при значительных затратах на производительность. Это происходит потому, что курсор создает отдельный запрос для каждой следующей операции выборки.

вертикальное расширение
подобно PIVOT и Курсору, недавно добавленные политики могут быть получены в XML-версии сценария без изменения исходного сценария.
горизонтальное расширение
В отличие от оси, недавно добавленные документы могут отображаться без изменения сценария.
расстройства
с точки зрения ввода – вывода статистика XML – версии скрипта почти аналогична сводной-единственное отличие заключается в том, что XML имеет второе сканирование таблицы dtTranspose, но на этот раз из логического кэша чтения данных.

на основе этого решение С bluefeet вот хранимая процедура, которая использует динамический sql для создания транспонированной таблицы. Он требует, чтобы все поля были числовыми, за исключением транспонированного столбца (столбец, который будет заголовком в результирующей таблице):
вы можете проверить его с помощью таблицы, поставляемой с этой командой:
я делаю UnPivot сначала и сохранение результатов в CTE и с помощью CTE на Pivot операции.
демо
добавление к потрясающему ответу @Paco Zarate выше, если вы хотите транспонировать таблицу, которая имеет несколько типов столбцов, затем добавьте это в конец строки 39, поэтому она только транспонирует int столбцы:
вот полный запрос, который был изменен:
найти другие system_type_id ‘ s, запустите это:
мне нравится делиться кодом, который я использую для транспонирования разделенного текста на основе ответа + bluefeet.
Я смешиваю это решение с информацией о том, как упорядочить строки без порядка по (SQLAuthority.com) и функция разделения на MSDN (social.msdn.microsoft.com)
когда вы выполняете prodecure
вы получаете следующее результат
 В этом приближении я реализован как процедура в MS SQL 2005
В этом приближении я реализован как процедура в MS SQL 2005таким образом, преобразуйте все данные из полей(столбцов) в таблице в запись (строку).
Номеров телефонов может быть разное т.к. сегодня звонки были только на 2 телефона, а завтра на 4, к примеру.
Какими командами это можно сделать? Была идея взять отдельно 2 и 3 колонку и повернуть их, но как потом обратно вернуть первую колонку я не придумал.
Нужно транспонировать таблицу
Добрый день! есть две таблицы: 1) Таблица скидок — id скидки — название.
Транспонировать одну таблицу и связать вывод со второй
Всем привет! Есть две таблицы: CREATE TABLE Options ( id_opt smallint NOT NULL PRIMARY KEY.
Транспонировать строки teradata
Добрый день, коллеги. Прошу помощи. Необходимо транспонировать строки с цикличной обработкой.
Транспонировать несколько столбцов таблицы
Всем доброго времени суток! Нужна помощь знатоков SQL. С SQL только недавно начал знакомиться и.
сервер sql — транспонирование MS SQL как транспонирование Excel (динамический SQL)
Мне нужен динамический код SQL, аналогичный операции транспонирования excel.
Я пробовал транспонировать таблицу с помощью Dynamic SQL.
Я пробовал Pivot/XML, Dynamic SQL. Разобрать. Я потерпел неудачу.
Я пробовал CAST (сопоставление столбцов database_default AS NVARCHAR (MAX)) преобразования.
Что я делаю не так? Как я могу написать код?
Моя конечная цель — создать составную таблицу, полученную в результате следующего запроса. Как видите, в этой таблице образцы столбцов пусты. Я хочу выполнить запрос «цикла while», чтобы заполнить эти значения.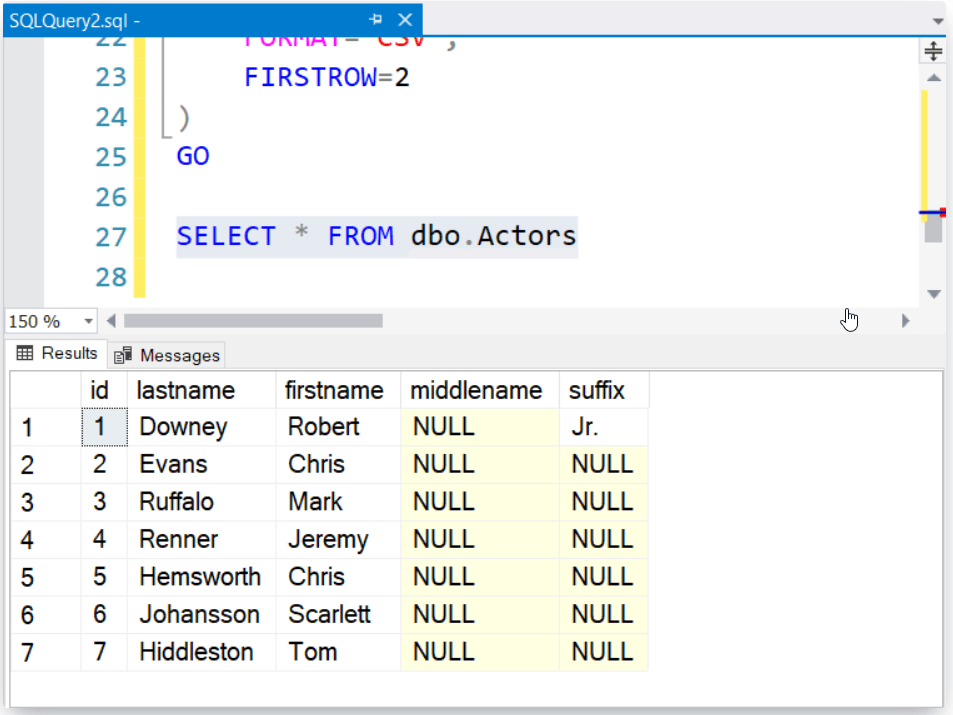 Перед созданием цикла мне нужен код, аналогичный операции транспонирования Excel. С помощью этой операции я могу скопировать результаты в составную таблицу.
Перед созданием цикла мне нужен код, аналогичный операции транспонирования Excel. С помощью этой операции я могу скопировать результаты в составную таблицу.
ВЫБЕРИТЕ A.TABLE_CATALOG, A. TABLE_SCHEMA, B.COLUMN_CNT, B.DUM_TABLE_POSITION, A.ORDINAL_POSITION AS DEF_COLUMN_POSITION, A.TABLE_NAME, A.COLUMN_NAME, SAMPLE_1=NULL,SAMPLE_2=NULL,SAMPLE_3=NULL,SAMPLE_4=NULL,SAMPLE_5=NULL, SAMPLE_6=NULL,SAMPLE_7=NULL,SAMPLE_8=NULL,SAMPLE_9=NULL,SAMPLE_10=NULL ИЗ INFORMATION_SCHEMA.COLUMNS A, (ВЫБЕРИТЕ TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME,COUNT(*) AS COLUMN_CNT, ROW_NUMBER() OVER (ORDER BY TABLE_NAME) AS DUM_TABLE_POSITION ИЗ INFORMATION_SCHEMA.COLUMNS СГРУППИРОВАТЬ ПО TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME СЧЕТЧИК(*)>0 ) B ГДЕ A.TABLE_CATALOG=B.TABLE_CATALOG И A.TABLE_SCHEMA=B.TABLE_SCHEMA И A.TABLE_NAME=B.TABLE_NAME И A.TABLE_CATALOG='DWH_PROD' И A.TABLE_SCHEMA='dbo' И A.TABLE_NAME IN (N'DWH_PROD.dbo.MY_TABLE_1', N'DWH_PROD.dbo.MY_TABLE_2')
введите здесь описание изображения
. ……………………….
……………………….
Демонстрационные данные
CREATE TABLE #temporary_table
(CUS_ID INT,
ТИТУЛ НВАРЧАР (50),
ПРОМОУТЕР НВАРЧАР (50),
CUS_STATUS NVARCHAR (50))
;
ВСТАВИТЬ В #temporary_table
ЦЕННОСТИ
(11,'A',НУЛЬ,'ПАССИВ'),
(22, 'B', NULL, 'АКТИВНО'),
(33,'D',NULL,'ACTIVE'),
(44, 'В', НУЛЬ, 'АКТИВНО'),
(55, 'B', NULL, 'АКТИВНО'),
(66,'C',NULL,'ACTIVE'),
(77,'D',NULL,'ACTIVE'),
(88,'D',NULL,'ACTIVE'),
(101,'D',NULL,'ACTIVE'),
(123,'D',NULL,'ACTIVE'),
(200,'D',NULL,'ACTIVE'),
(300, 'А', НУЛЬ, 'ПАССИВ')
;
SELECT TOP 10 CONCAT('SAMPLE_', ROW_NUMBER() OVER( ORDER BY (SELECT 1)) ) AS AAA,*
ОТ #temporary_table
Я могу получить результаты отдельно с помощью одного кода ниже. Но этот результат не соответствует моей просьбе.
DECLARE @sql nvarchar(max) = N''; ВЫБЕРИТЕ @sql += N' SELECT TOP (10) [таблица] = N''' + REPLACE (имя, '''','') + ''', * ОТ ' + QUOTENAME(SCHEMA_NAME([schema_id])) + '.' + QUOTENAME(имя) + ';' ИЗ sys.tables AS t ГДЕ имя В (N'DWH_PROD.
 dbo.MY_TABLE_1', N'DWH_PROD.dbo.MY_TABLE_2')
EXEC sys.sp_executesql @sql;
dbo.MY_TABLE_1', N'DWH_PROD.dbo.MY_TABLE_2')
EXEC sys.sp_executesql @sql;
РЕДАКТИРОВАТЬ::::::::::::::::::::::::::::
Большое спасибо @John Cappelletti Я почти закончил запрос. Код работает на сервере 2014. Все остальные сценарии я не тестировал. Если для первых 10 строк столбца есть только значения NULL, второе имя таблицы будет отображаться как NULL.
-- УДАЛИТЬ СТОЛ #HamdullahUstadKacincidir2 -- DROP TABLE #HamdullahUstadKacincidir СОЗДАТЬ СТОЛ #HamdullahUstadKacincidir2 (ИМЯ_СТОЛОНЦА NVARCHAR (МАКС.), SAMPLE_1 NVARCHAR (МАКС.), SAMPLE_2 NVARCHAR (МАКС.), SAMPLE_3 NVARCHAR (МАКС.), SAMPLE_4 NVARCHAR (МАКС.), SAMPLE_5 NVARCHAR (МАКС.), SAMPLE_6 NVARCHAR (МАКС.), SAMPLE_7 NVARCHAR (МАКС.), SAMPLE_8 NVARCHAR (МАКС.), SAMPLE_9 NVARCHAR (МАКС.), SAMPLE_10 NVARCHAR (МАКС)) CREATE TABLE #HamdullahUstadKacincidir (ИМЯ ТАБЛИЦЫ NVARCHAR (МАКС.), COLUMN_NAME NVARCHAR (МАКС.), SAMPLE_1 NVARCHAR (МАКС.), SAMPLE_2 NVARCHAR (МАКС.), SAMPLE_3 NVARCHAR (МАКС.), SAMPLE_4 NVARCHAR (МАКС.
 ),
SAMPLE_5 NVARCHAR (МАКС.),
SAMPLE_6 NVARCHAR (МАКС.),
SAMPLE_7 NVARCHAR (МАКС.),
SAMPLE_8 NVARCHAR (МАКС.),
SAMPLE_9НВАРЧАР (МАКС),
SAMPLE_10 NVARCHAR (МАКС))
ОБЪЯВИТЬ @SourceTableName КАК NVARCHAR (МАКС.)
ОБЪЯВИТЬ @SourceTableSql КАК NVARCHAR (МАКСИМАЛЬНО)
ОБЪЯВИТЬ @SourceTableSql22 КАК NVARCHAR (МАКС)
ОБЪЯВИТЬ @SourceTableSql333 КАК NVARCHAR (МАКС.)
ОБЪЯВИТЬ @TableI INT
ОБЪЯВИТЬ @TableIN NVARCHAR(MAX)
ОБЪЯВИТЬ @SampleSize INT
ОБЪЯВИТЬ @TableCount INT
УСТАНОВИТЬ @ТаблицаI=1
УСТАНОВИТЕ @SampleSize= 10
УСТАНОВИТЬ @TableCount= (ВЫБРАТЬ COUNT(*) AS MAX_TABLE_CNT
ОТ
(ВЫБЕРИТЕ TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME,COUNT(*) AS COLUMN_CNT
ИЗ INFORMATION_SCHEMA.COLUMNS
WHERE CONCAT(TABLE_CATALOG,'.', TABLE_SCHEMA,'.', TABLE_NAME) NOT IN --Имеет хотя бы один столбец Geography Data_Type
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,'.', C.TABLE_SCHEMA,'.', C.TABLE_NAME) AS TABLE_HAS_GEOGRAPHY_DATA_TYPE
ИЗ INFORMATION_SCHEMA.COLUMNS C
ГДЕ DATA_TYPE='География')
AND CONCAT(TABLE_CATALOG,'.', TABLE_SCHEMA,'.
),
SAMPLE_5 NVARCHAR (МАКС.),
SAMPLE_6 NVARCHAR (МАКС.),
SAMPLE_7 NVARCHAR (МАКС.),
SAMPLE_8 NVARCHAR (МАКС.),
SAMPLE_9НВАРЧАР (МАКС),
SAMPLE_10 NVARCHAR (МАКС))
ОБЪЯВИТЬ @SourceTableName КАК NVARCHAR (МАКС.)
ОБЪЯВИТЬ @SourceTableSql КАК NVARCHAR (МАКСИМАЛЬНО)
ОБЪЯВИТЬ @SourceTableSql22 КАК NVARCHAR (МАКС)
ОБЪЯВИТЬ @SourceTableSql333 КАК NVARCHAR (МАКС.)
ОБЪЯВИТЬ @TableI INT
ОБЪЯВИТЬ @TableIN NVARCHAR(MAX)
ОБЪЯВИТЬ @SampleSize INT
ОБЪЯВИТЬ @TableCount INT
УСТАНОВИТЬ @ТаблицаI=1
УСТАНОВИТЕ @SampleSize= 10
УСТАНОВИТЬ @TableCount= (ВЫБРАТЬ COUNT(*) AS MAX_TABLE_CNT
ОТ
(ВЫБЕРИТЕ TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME,COUNT(*) AS COLUMN_CNT
ИЗ INFORMATION_SCHEMA.COLUMNS
WHERE CONCAT(TABLE_CATALOG,'.', TABLE_SCHEMA,'.', TABLE_NAME) NOT IN --Имеет хотя бы один столбец Geography Data_Type
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,'.', C.TABLE_SCHEMA,'.', C.TABLE_NAME) AS TABLE_HAS_GEOGRAPHY_DATA_TYPE
ИЗ INFORMATION_SCHEMA.COLUMNS C
ГДЕ DATA_TYPE='География')
AND CONCAT(TABLE_CATALOG,'.', TABLE_SCHEMA,'. ', TABLE_NAME) NOT IN --Eliminate Empty Tables
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,'.', C.TABLE_SCHEMA,'.', C.TABLE_NAME) AS EMPTY_TABLE
ИЗ sys.tables t
присоединиться к sys.schemas s (t.schema_id = s.schema_id)
присоединиться к sys.partitions p (t.object_id = p.object_id)
присоединиться к INFORMATION_SCHEMA.COLUMNS c (s.name=c.TABLE_SCHEMA и t.name=c.TABLE_NAME)
ГДЕ p.index_id в (0,1)
СГРУППИРОВАТЬ ПО C.TABLE_CATALOG, C.TABLE_SCHEMA, C.TABLE_NAME
СУММА (p.rows) = 0)
AND CONCAT(TABLE_CATALOG,'.', TABLE_SCHEMA,'.', TABLE_NAME) NOT IN --Black List Tables
('DWH_PROD.dbo._tmp_retro')
СГРУППИРОВАТЬ ПО ТАБЛИЦЕ_КАТАЛОГУ, ТАБЛИЦЕ_СХЕМА, ТАБЛИЦА_ИМЯ) T )
ПОКА @TableI<=@TableCount
НАЧИНАТЬ
УСТАНОВИТЬ @TableIN=CAST(@TableI КАК NVARCHAR(MAX))
УСТАНОВИТЬ @SourceTableSql=
'SELECT @SourceTableTemp=CONCAT(TABLE_CATALOG,''.'',TABLE_SCHEMA,''.'',TABLE_NAME)
ОТ
(ВЫБЕРИТЕ TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME,COUNT(*) AS COLUMN_CNT,
ROW_NUMBER() OVER (ORDER BY TABLE_NAME) AS DUM_TABLE_POSITION
ИЗ INFORMATION_SCHEMA.
', TABLE_NAME) NOT IN --Eliminate Empty Tables
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,'.', C.TABLE_SCHEMA,'.', C.TABLE_NAME) AS EMPTY_TABLE
ИЗ sys.tables t
присоединиться к sys.schemas s (t.schema_id = s.schema_id)
присоединиться к sys.partitions p (t.object_id = p.object_id)
присоединиться к INFORMATION_SCHEMA.COLUMNS c (s.name=c.TABLE_SCHEMA и t.name=c.TABLE_NAME)
ГДЕ p.index_id в (0,1)
СГРУППИРОВАТЬ ПО C.TABLE_CATALOG, C.TABLE_SCHEMA, C.TABLE_NAME
СУММА (p.rows) = 0)
AND CONCAT(TABLE_CATALOG,'.', TABLE_SCHEMA,'.', TABLE_NAME) NOT IN --Black List Tables
('DWH_PROD.dbo._tmp_retro')
СГРУППИРОВАТЬ ПО ТАБЛИЦЕ_КАТАЛОГУ, ТАБЛИЦЕ_СХЕМА, ТАБЛИЦА_ИМЯ) T )
ПОКА @TableI<=@TableCount
НАЧИНАТЬ
УСТАНОВИТЬ @TableIN=CAST(@TableI КАК NVARCHAR(MAX))
УСТАНОВИТЬ @SourceTableSql=
'SELECT @SourceTableTemp=CONCAT(TABLE_CATALOG,''.'',TABLE_SCHEMA,''.'',TABLE_NAME)
ОТ
(ВЫБЕРИТЕ TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME,COUNT(*) AS COLUMN_CNT,
ROW_NUMBER() OVER (ORDER BY TABLE_NAME) AS DUM_TABLE_POSITION
ИЗ INFORMATION_SCHEMA. COLUMNS
WHERE CONCAT(TABLE_CATALOG,''.'', TABLE_SCHEMA,''.'', TABLE_NAME) NOT IN --Имеет хотя бы один столбец Geography Data_Type
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,''.'', C.TABLE_SCHEMA,''.'', C.TABLE_NAME) AS TABLE_HAS_GEOGRAPHY_DATA_TYPE
ИЗ INFORMATION_SCHEMA.COLUMNS C
ГДЕ DATA_TYPE=''География'')
AND CONCAT(TABLE_CATALOG,''.'', TABLE_SCHEMA,''.'', TABLE_NAME) NOT IN --Eliminate Empty Tables
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,''.'', C.TABLE_SCHEMA,''.'', C.TABLE_NAME) AS EMPTY_TABLE
ИЗ sys.tables t
присоединиться к sys.schemas s (t.schema_id = s.schema_id)
присоединиться к sys.partitions p (t.object_id = p.object_id)
присоединиться к INFORMATION_SCHEMA.COLUMNS c (s.name=c.TABLE_SCHEMA и t.name=c.TABLE_NAME)
ГДЕ p.index_id в (0,1)
СГРУППИРОВАТЬ ПО C.TABLE_CATALOG, C.TABLE_SCHEMA, C.TABLE_NAME
СУММА (p.rows) = 0)
AND CONCAT(TABLE_CATALOG,''.'', TABLE_SCHEMA,''.'', TABLE_NAME) NOT IN --Black List Tables
(''DWH_PROD.dbo._tmp_retro'')
СГРУППИРОВАТЬ ПО TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME) K
ГДЕ DUM_TABLE_POSITION=@TableIN'
EXECUTE sp_executesql @SourceTableSql, N'@TableIN NVARCHAR(MAX),@SourceTableTemp NVARCHAR(MAX) OUTPUT',
@TableIN=@TableIN, @SourceTableTemp = @SourceTableName ВЫВОД
УДАЛИТЬ #HamdullahUstadKacincidir2
SET @SourceTableSql22 = 'ВСТАВИТЬ В #HamdullahUstadKacincidir2
ВЫБИРАТЬ *
ИЗ ( ВЫБРАТЬ A.
COLUMNS
WHERE CONCAT(TABLE_CATALOG,''.'', TABLE_SCHEMA,''.'', TABLE_NAME) NOT IN --Имеет хотя бы один столбец Geography Data_Type
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,''.'', C.TABLE_SCHEMA,''.'', C.TABLE_NAME) AS TABLE_HAS_GEOGRAPHY_DATA_TYPE
ИЗ INFORMATION_SCHEMA.COLUMNS C
ГДЕ DATA_TYPE=''География'')
AND CONCAT(TABLE_CATALOG,''.'', TABLE_SCHEMA,''.'', TABLE_NAME) NOT IN --Eliminate Empty Tables
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,''.'', C.TABLE_SCHEMA,''.'', C.TABLE_NAME) AS EMPTY_TABLE
ИЗ sys.tables t
присоединиться к sys.schemas s (t.schema_id = s.schema_id)
присоединиться к sys.partitions p (t.object_id = p.object_id)
присоединиться к INFORMATION_SCHEMA.COLUMNS c (s.name=c.TABLE_SCHEMA и t.name=c.TABLE_NAME)
ГДЕ p.index_id в (0,1)
СГРУППИРОВАТЬ ПО C.TABLE_CATALOG, C.TABLE_SCHEMA, C.TABLE_NAME
СУММА (p.rows) = 0)
AND CONCAT(TABLE_CATALOG,''.'', TABLE_SCHEMA,''.'', TABLE_NAME) NOT IN --Black List Tables
(''DWH_PROD.dbo._tmp_retro'')
СГРУППИРОВАТЬ ПО TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME) K
ГДЕ DUM_TABLE_POSITION=@TableIN'
EXECUTE sp_executesql @SourceTableSql, N'@TableIN NVARCHAR(MAX),@SourceTableTemp NVARCHAR(MAX) OUTPUT',
@TableIN=@TableIN, @SourceTableTemp = @SourceTableName ВЫВОД
УДАЛИТЬ #HamdullahUstadKacincidir2
SET @SourceTableSql22 = 'ВСТАВИТЬ В #HamdullahUstadKacincidir2
ВЫБИРАТЬ *
ИЗ ( ВЫБРАТЬ A. AAA,C.*
FROM ( SELECT TOP '+CONCAT('',@SampleSize)+' AAA = CONCAT(''SAMPLE_'', ROW_NUMBER() OVER( ORDER BY (SELECT 1)) ),*
FROM '+@SourceTableName+' SRC ) A
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ ( ЗНАЧЕНИЯ ((Выберите A.* FOR XML RAW, Type)) B(XMLData)
CROSS APPLY ( SELECT COLUMN_NAME = xAttr.value(''local-name(.)'', ''VARCHAR(MAX)''),VALUE = xAttr.value(''.'',''VARCHAR(MAX)' ')
ИЗ XMLData.nodes(''//@*'') xNode(xAttr)
ГДЕ xAttr.value(''local-name(.)'', ''varchar(100)'') не в (''AAA'')) C ) SRC
PIVOT (MAX(VALUE) FOR [AAA] IN (' + STUFF((SELECT TOP (@SampleSize) ','+CONCAT('SAMPLE_', ROW_NUMBER() OVER( ORDER BY (SELECT 1))
FROM master..spt_values FOR XML Path('')),1,1,'') + ')) ) P'
ВЫПОЛНИТЬ(@SourceTableSql22)
ВСТАВЬТЕ В #HamdullahUstadKacincidir
ВЫБЕРИТЕ TABLE_NAME=@SourceTableName,* FROM #HamdullahUstadKacincidir2
УСТАНОВИТЬ @TableI=@TableI+1
КОНЕЦ
ВЫБЕРИТЕ E.*,K.*,H.*
ОТ
(ВЫБЕРИТЕ CONCAT(TABLE_CATALOG,'.',TABLE_SCHEMA,'.',TABLE_NAME) AS TABLE_NAME,COLUMN_NAME,DATA_TYPE,
ROW_NUMBER() OVER (PARTITION BY TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME ORDER BY ORDINAL_POSITION ) AS COLUMN_POSITION
ИЗ INFORMATION_SCHEMA.
AAA,C.*
FROM ( SELECT TOP '+CONCAT('',@SampleSize)+' AAA = CONCAT(''SAMPLE_'', ROW_NUMBER() OVER( ORDER BY (SELECT 1)) ),*
FROM '+@SourceTableName+' SRC ) A
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ ( ЗНАЧЕНИЯ ((Выберите A.* FOR XML RAW, Type)) B(XMLData)
CROSS APPLY ( SELECT COLUMN_NAME = xAttr.value(''local-name(.)'', ''VARCHAR(MAX)''),VALUE = xAttr.value(''.'',''VARCHAR(MAX)' ')
ИЗ XMLData.nodes(''//@*'') xNode(xAttr)
ГДЕ xAttr.value(''local-name(.)'', ''varchar(100)'') не в (''AAA'')) C ) SRC
PIVOT (MAX(VALUE) FOR [AAA] IN (' + STUFF((SELECT TOP (@SampleSize) ','+CONCAT('SAMPLE_', ROW_NUMBER() OVER( ORDER BY (SELECT 1))
FROM master..spt_values FOR XML Path('')),1,1,'') + ')) ) P'
ВЫПОЛНИТЬ(@SourceTableSql22)
ВСТАВЬТЕ В #HamdullahUstadKacincidir
ВЫБЕРИТЕ TABLE_NAME=@SourceTableName,* FROM #HamdullahUstadKacincidir2
УСТАНОВИТЬ @TableI=@TableI+1
КОНЕЦ
ВЫБЕРИТЕ E.*,K.*,H.*
ОТ
(ВЫБЕРИТЕ CONCAT(TABLE_CATALOG,'.',TABLE_SCHEMA,'.',TABLE_NAME) AS TABLE_NAME,COLUMN_NAME,DATA_TYPE,
ROW_NUMBER() OVER (PARTITION BY TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME ORDER BY ORDINAL_POSITION ) AS COLUMN_POSITION
ИЗ INFORMATION_SCHEMA.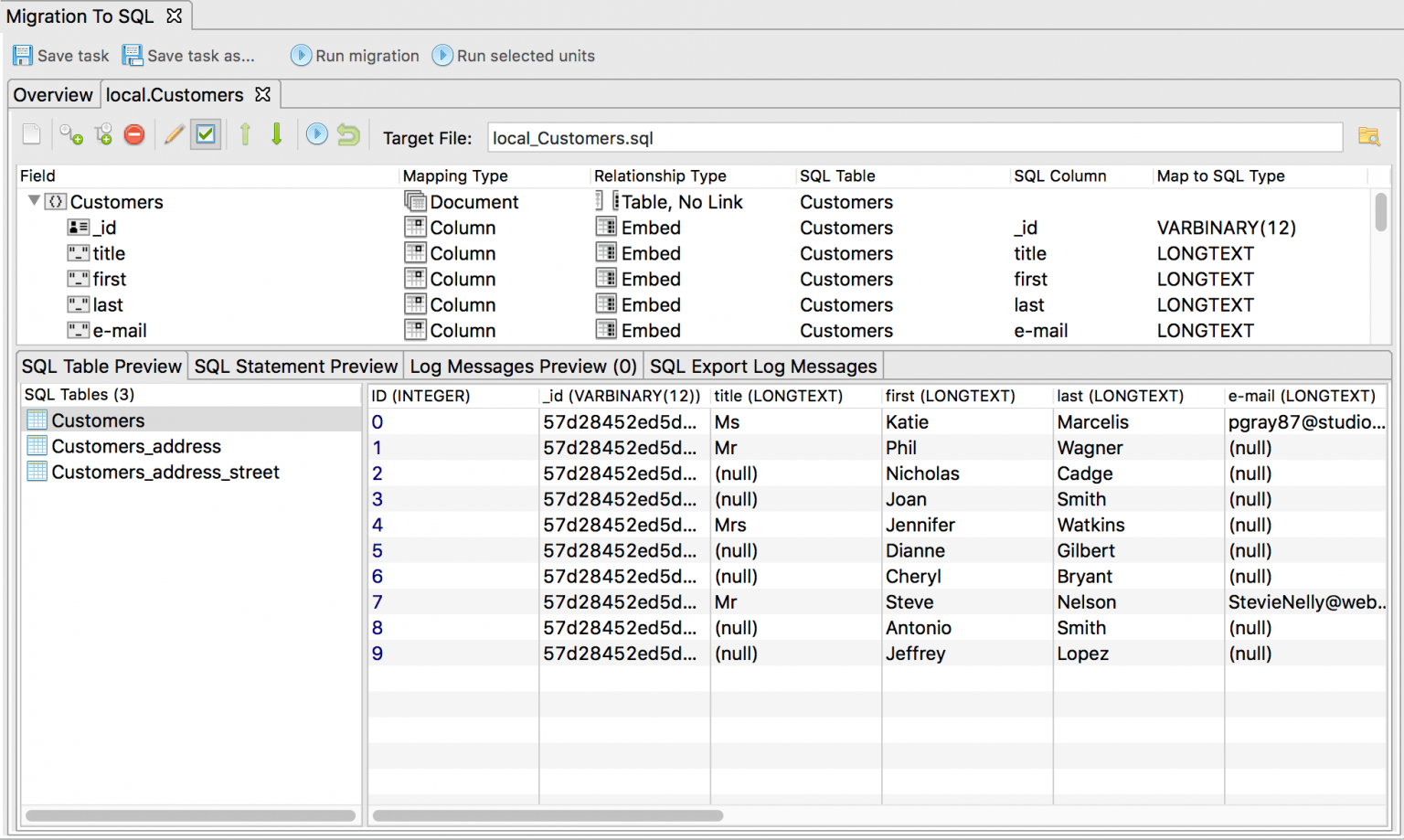 COLUMNS
) К
ЛЕВОЕ СОЕДИНЕНИЕ
#HamdullahUstadKacincidir H
ON K.TABLE_NAME COLLATE DATABASE_DEFAULT=H.TABLE_NAME COLLATE DATABASE_DEFAULT
AND K.COLUMN_NAME COLLATE DATABASE_DEFAULT=H.COLUMN_NAME COLLATE DATABASE_DEFAULT
ЛЕВОЕ СОЕДИНЕНИЕ
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,'.', C.TABLE_SCHEMA,'.', C.TABLE_NAME) AS EMPTY_TABLE
ИЗ sys.tables t
присоединиться к sys.schemas s (t.schema_id = s.schema_id)
присоединиться к sys.partitions p (t.object_id = p.object_id)
присоединиться к INFORMATION_SCHEMA.COLUMNS c (s.name=c.TABLE_SCHEMA и t.name=c.TABLE_NAME)
ГДЕ p.index_id в (0,1)
СГРУППИРОВАТЬ ПО C.TABLE_CATALOG, C.TABLE_SCHEMA, C.TABLE_NAME
СУММА (p.rows) = 0) E
ON K.TABLE_NAME=EMPTY_TABLE
ЗАКАЗ ПО K.TABLE_NAME,K.COLUMN_POSITION
COLUMNS
) К
ЛЕВОЕ СОЕДИНЕНИЕ
#HamdullahUstadKacincidir H
ON K.TABLE_NAME COLLATE DATABASE_DEFAULT=H.TABLE_NAME COLLATE DATABASE_DEFAULT
AND K.COLUMN_NAME COLLATE DATABASE_DEFAULT=H.COLUMN_NAME COLLATE DATABASE_DEFAULT
ЛЕВОЕ СОЕДИНЕНИЕ
(ВЫБЕРИТЕ CONCAT(C.TABLE_CATALOG,'.', C.TABLE_SCHEMA,'.', C.TABLE_NAME) AS EMPTY_TABLE
ИЗ sys.tables t
присоединиться к sys.schemas s (t.schema_id = s.schema_id)
присоединиться к sys.partitions p (t.object_id = p.object_id)
присоединиться к INFORMATION_SCHEMA.COLUMNS c (s.name=c.TABLE_SCHEMA и t.name=c.TABLE_NAME)
ГДЕ p.index_id в (0,1)
СГРУППИРОВАТЬ ПО C.TABLE_CATALOG, C.TABLE_SCHEMA, C.TABLE_NAME
СУММА (p.rows) = 0) E
ON K.TABLE_NAME=EMPTY_TABLE
ЗАКАЗ ПО K.TABLE_NAME,K.COLUMN_POSITION
sql server — транспонирование столбцов таблицы SQL в строки с подсчетом в каждой категории
Задавать вопрос
спросил
Изменено
2 года, 2 месяца назад
Просмотрено
428 раз
У меня есть таблица с 12 000 строк данных. Таблица состоит из 7 столбцов данных (PIDA, NIDA, SIDA, IIPA, RPRP, IORS, DDSN), каждый столбец с 4 типами записей («Поддерживается», «Не поддерживается», «Не каталогизированный» или «Нулевой»)
Таблица состоит из 7 столбцов данных (PIDA, NIDA, SIDA, IIPA, RPRP, IORS, DDSN), каждый столбец с 4 типами записей («Поддерживается», «Не поддерживается», «Не каталогизированный» или «Нулевой»)
+--------------+-----------+--------------+----- ------+ | ПИДА | НИДА | СИДА | IIPA | +--------------+-----------+--------------+------- ----+ | Нуль | Поддерживается | Нуль | Нуль | | Некаталогизированный | Поддерживается | Нуль | Нуль | | Поддерживается | Поддерживается | Некаталогизированный | Поддерживается | | Поддерживается | Нуль | Некаталогизированный | Нуль | +--------------+-----------+--------------+------- ----+
Я хотел бы создать вывод, в котором каждая запись подсчитывается для каждого столбца. Как транспонировать столбец в строку.
+---------------+------+------+------+------+ | Категории | ПИДА | НИДА | СИДА | IIPA | +---------------+------+------+------+------+ | Поддерживается | 10 | 20 | 50 | 1 | | Не поддерживается | 30 | 50 | 22 | 5 | | Некаталогизированный | 5 | 10 | 22 | 22 | | НУЛЕВОЙ | 10 | 11 | 22 | 22 | +---------------+------+------+------+------+
Не повезло со встроенными операторами select или case. У меня есть ощущение, что нужно немного и того, и другого, чтобы сначала подсчитать, а затем перечислить каждую строку в выводе
У меня есть ощущение, что нужно немного и того, и другого, чтобы сначала подсчитать, а затем перечислить каждую строку в выводе
Всем спасибо,
- sql
- sql-server
- select
- count
- transpose
1
Один из вариантов: UNPIVOT ваши данные, а затем PIVOT результаты
Пример
Выберите *
От (
Выберите Б.*
Из вашей таблицы А
Перекрестное применение (значения (PIDA,'PIDA',1)
,(НИДА,'НИДА',1)
,(СИДА,'СИДА',1)
,(IIPA,'IIPA',1)
) B(Категории,Элемент,Значение)
) источник
Pivot (sum(Value) for Item in ([PIDA],[NIDA],[SIDA],[IIPA])) pvt
Результаты (с небольшим размером выборки)
Категории PIDA NIDA SIDA IIPA ПУСТО 1 1 2 3 Поддерживается 2 3 NULL 1 Некаталогизированный 1 NULL 2 NULL
3
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.