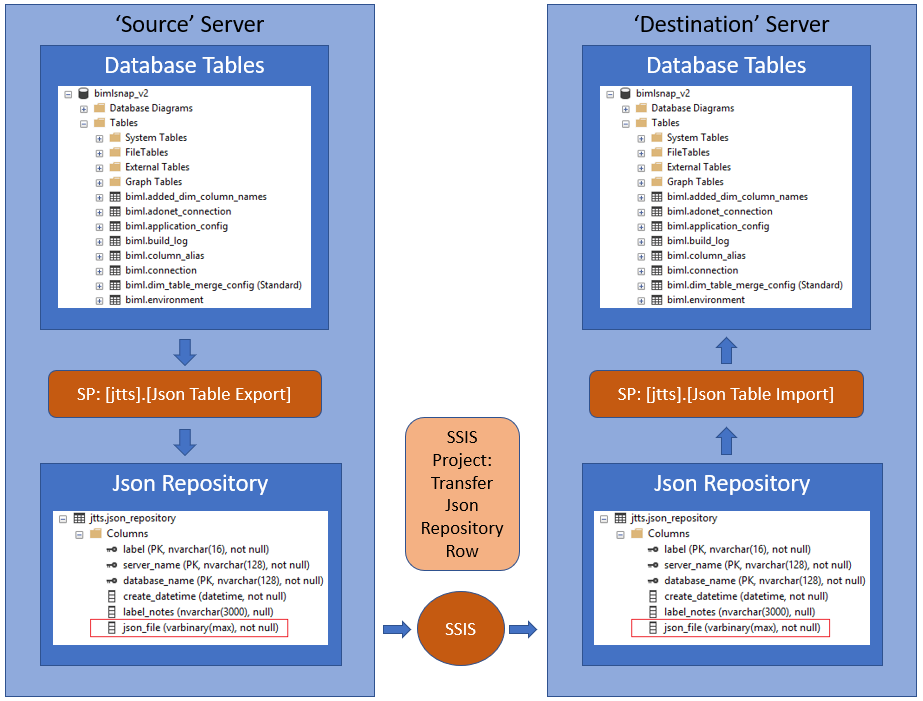
Sql json: Работа с данными JSON в SQL Server — SQL Server
Содержание
Работаем с JSON в SQL Server 2016 / Хабр
JSON сейчас один из самых используемых форматов данных в разработке. Большинство современных сервисов возвращают информацию в виде JSON. JSON также предпочитаемый формат для хранения структурированный информации в файлах, например. Так как очень много данных используется в JSON-формате, то поддержка JSON в SQL Server особенно становится актуальной, чтобы иметь возможность обмениваться данными с другими сервисами.
JSON стал одной из самых востребованных фич, добавленных в SQL Server 2016. Далее в статье мы рассмотрим основные механизмы работы с JSON.
Краткий обзор
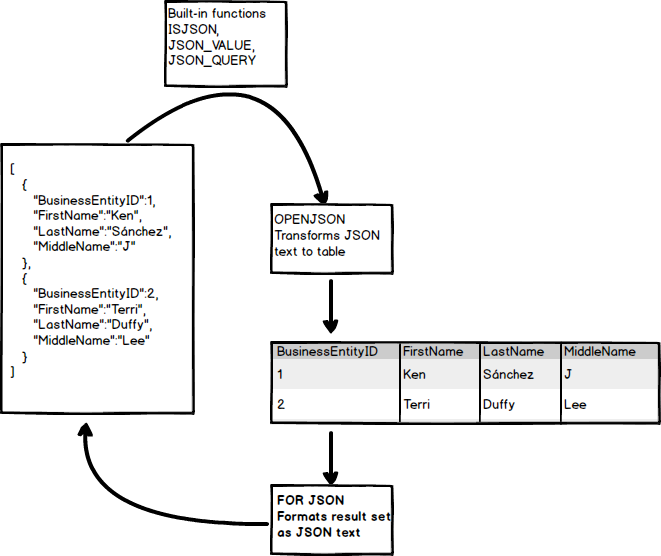
Функции для работы с JSON в SQL Server позволяют анализировать и запрашивать данные JSON, преобразовывать JSON в реляционный вид и экспортировать результат SQL-запроса как JSON.
Если у вас есть JSON, вы можете достать оттуда данные или проверить их на валидность, используя встроенные функции JSON_VALUE, JSON_QUERY и ISJSON. Для изменения данных может быть использована функция JSON_MODIFY. Для более продвинутого использования функция OPENJSON позволяет преобразовывать массив JSON объектов в набор строк. Затем над этим набором можно выполнить любой SQL-запрос. Наконец, существует конструкция FOR JSON, которая преобразует результат запроса в JSON.
Для изменения данных может быть использована функция JSON_MODIFY. Для более продвинутого использования функция OPENJSON позволяет преобразовывать массив JSON объектов в набор строк. Затем над этим набором можно выполнить любой SQL-запрос. Наконец, существует конструкция FOR JSON, которая преобразует результат запроса в JSON.
Посмотрим на несколько простых примеров. В следующем коде мы определим текстовую переменную, в которой будет JSON:
DECLARE @json NVARCHAR(4000)
SET @json =
N'{
"info":{
"type":1,
"address":{
"town":"Bristol",
"county":"Avon",
"country":"England"
},
"tags":["Sport", "Water polo"]
},
"type":"Basic"
}'
Теперь мы можем получить отдельные значения или объекты из JSON с помощью JSON_VALUE и JSON_QUERY:
SELECT JSON_VALUE(@json, '$.type') as type, JSON_VALUE(@json, '$.info.address.town') as town, JSON_QUERY(@json, '$.info.tags') as tags
Этот запрос вернет «Basic», «Bristol» и [«Sport», «Water polo»]. Функция JSON_VALUE возвращает скалярное значение из JSON (то есть строку, число, булевское значение), которое расположено по «пути», указанному вторым параметром. JSON_QUERY возвращает объект или массив (в нашем примере это массив тегов) по «пути». Встроенные функции JSON используют похожий на JavaScript синтаксис для обращения к значениям и объектам в качестве второго параметра.
Функция JSON_VALUE возвращает скалярное значение из JSON (то есть строку, число, булевское значение), которое расположено по «пути», указанному вторым параметром. JSON_QUERY возвращает объект или массив (в нашем примере это массив тегов) по «пути». Встроенные функции JSON используют похожий на JavaScript синтаксис для обращения к значениям и объектам в качестве второго параметра.
Функция OPENJSON позволяет обратиться к массиву внутри JSON и возвратить элементы этого массива:
SELECT value FROM OPENJSON(@json, '$.info.tags')
В этом примере возвращаются строковые значения из массива тегов. Кроме того, OPENJSON может возвращать любой сложный объект.
Наконец, конструкция FOR JSON может отформатировать любой результат выполнения SQL-запроса в JSON:
SELECT object_id, name FROM sys.tables FOR JSON PATH
Рассмотрим эти функции подробнее.
Хранение данных JSON в SQL Server
В SQL Server JSON хранится как текст.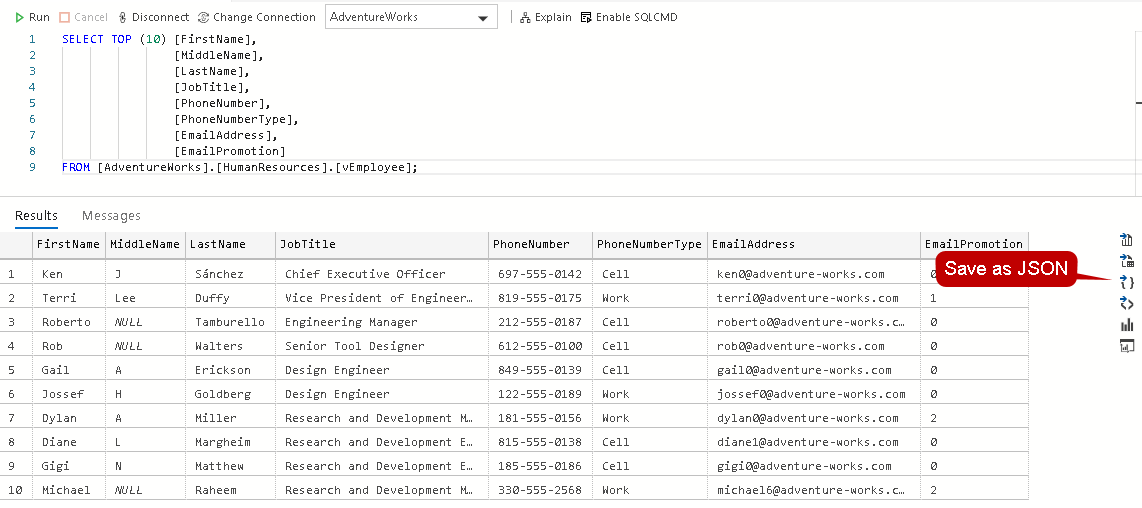 Вы можете использовать тип NVARCHAR для этого. В следующем примере мы будем хранить JSON в поле InfoJson:
Вы можете использовать тип NVARCHAR для этого. В следующем примере мы будем хранить JSON в поле InfoJson:
CREATE TABLE Person ( Id int IDENTITY PRIMARY KEY NONCLUSTERED, FirstName nvarchar(100) NOT NULL, LastName nvarchar(100) NOT NULL, InfoJson nvarchar(max) ) WITH (MEMORY_OPTIMIZED=ON)
В SQL Server 2016 вы можете комбинировать обычные столбцы (FirstName и LastName в примере) и столбцы с JSON (InfoJSON в примере) в одной таблице. Также вы можете комбинировать столбцы JSON со столбцами с пространственными данными (spatial columns) и XML. В отличие от только реляционных или только документоориентированных хранилищ, вы можете выбирать принципы хранения для достижения большей гибкости в разработке.
Хотя JSON хранится в текстовых столбцах, это не просто обычный текст. В SQL Server есть механизм для оптимизации хранения текстовых столбцов с использованием различных механизмов сжатия, таких как сжатие UNICODE, которые позволяют экономить до 50% размера.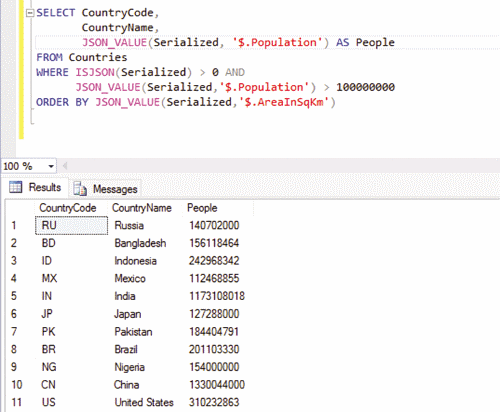 Также вы можете хранить JSON в таблицах с columnstore индексами или сжимать их явно с использованием встроенный функции COMPRESS, которая использует алгоритм GZip.
Также вы можете хранить JSON в таблицах с columnstore индексами или сжимать их явно с использованием встроенный функции COMPRESS, которая использует алгоритм GZip.
JSON полностью совместим с любым компонентом SQL Server, который работает с типом NVARCHAR. В примере выше, JSON хранится в OLTP (Hekaton) таблице в памяти, которая предлагает суперпроизводительность. Вы можете хранить JSON в обычных таблицах, использовать columnstore индексы или FILESTREAM. Вы также можете загружать его из Hadoop используя таблицы Polybase, считывать из файловой системы, работать с ним в Azure SQL, использовать репликацию и т.д. Если вы скомбинируете таблицы, в которых хранится JSON с другими фичами SQL Server, такими как безопасность временных таблиц или безопасность на уровне строк, вы можете обнаружить мощные возможности, которые недоступны в существующих документоориентированных СУБД.
Если вы хотите обеспечить валидность хранимого JSON, вы можете добавить проверку на валидность с помощью ограничения и функции ISJSON:
ALTER TABLE Person ADD CONSTRAINT [Content should be formatted as JSON] CHECK ( ISJSON( InfoJSON )> 0 )
Во время выполнения ваши запросы не будут работать, если JSON отформатирован неправильно.
Т.к. JSON представлен в виде текста, нет необходимости менять что-то в ваших приложениях. Вы можете работать с JSON как с обычными строками. JSON может быть загружен с помощью ORM как строка и отправлен в клиентское JavaScript-приложение. Любые утилиты извлечения данных также будут работать.
Встроенные функции для обработки JSON
SQL Server 2016 предлагает несколько функций для обработки JSON:
- ISJSON( jsonText ) проверяет валидность JSON на соответствие спецификации. С помощью этой функции вы можете накладывать ограничения на столбцы, содержащие JSON
- JSON_VALUE( jsonText, path ) разбирает jsonText и выделяет отдельные значения по определенному «пути» (см. примеры ниже)
- JSON_QUERY( jsonText, path ) разбирает jsonText и выделяет объекты или массивы по определенному «пути» (см. примеры ниже)
- JSON_MODIFY( jsonText, path, newValue) изменяет значение какого-либо свойства по определенному «пути (см, примеры ниже)
Эти функции используют „пути“ в JSON для обращения к значениям или объектам. Примеры:
Примеры:
'$' // ссылается на весь объект JSON в исходном тексте '$.property1' // ссылается на property1 в объекте JSON '$[4]' // ссылается на 5-й элемент в массиве (индексы начинаются с 0) '$.property1.property2.array1[5].property3.array2[15].property4' // ссылается на вложенное свойство '$.info."first name"' // ссылается на свойство "first name" в объекте. Если название свойства содержит спецсимволы (пробелы, знак доллар и т.д.), то его нужно заключить в двойные кавычки
При использовании функции JSON_MODIFY в параметре path могут быть использованы дополнительные модификаторы. В общем случае синтаксис „пути“ выглядит как:
[append] [ lax | strict ] $.json_path
При указании модификатора append новое значение будет добавлено к массиву, на который ссылается json_path. Модификатор lax устанавливает режим работы, при котором неважно, существует свойство или нет. Если его нет, то будет добавлено. При использовании strict, если свойства нет, будет сгенерирована ошибка.
При использовании strict, если свойства нет, будет сгенерирована ошибка.
Знак доллара ($) ссылается на весь объект JSON (аналогично корневому узлу „/“ в XPath). Вы можете добавлять любое свойство после „$“ для обращения к элементам объекта. Рассмотрим простой пример:
SELECT Id, FirstName, LastName,
JSON_VALUE(InfoJSON, '$.info."social security number"') as SSN,
JSON_QUERY(InfoJSON, '$.skills') as Skills
FROM Person AS t
WHERE ISJSON( InfoJSON ) > 0
AND JSON_VALUE(InfoJSON, '$.Type') = 'Student'
Этот запрос возвращает имя и фамилию из обычных столбцов, социальный номер и массив навыков из JSON столбца. Результаты фильтруются по условию, при котором столбец InfoJSON должен содержать валидный JSON и значение Type в JSON столбце равно „Student“. Как вы уже поняли, вы можете использовать значения из JSON в любой части запроса (сортировка, группировка и т.п.).
Преобразование JSON в реляционный вид – OPENJSON
Функция OPENJSON возвращает таблицу, которая определяет массив объектов, проиводит итерацию по массиву и выводит каждый элемент массива в строке.
Пример
Данные на входе (JSON):
{
"Orders":
[
{
"Order": {
"Number": "S043659",
"Date": "2011-05-31T00:00:00"
},
"Account": "Microsoft",
"Item": {
"Price": 59.99,
"Quantity": 1
}
},
{
"Order": {
"Number": "S043661",
"Date": "2011-06-01T00:00:00"
},
"Account": "Nokia",
"Item": {
"Price": 24.99,
"Quantity": 3
}
}
]
}
SQL-запрос:
SELECT *
FROM OPENJSON(@json, N'$.Orders')
WITH (
Number VARCHAR(200) N'$.Order.Number',
Date DATETIME N'$.Order.Date',
Customer VARCHAR(200) N'$.Account',
Quantity INT N'$.Item.Quantity'
)
Результат
| Number | Date | Customer | Quantity ---------------------------------------------------------- | S043659 | 2011-05-31 00:00:00.000 | Microsoft | 1 | S043661 | 2011-06-01 00:00:00.000 | Nokia | 3
 000 | Microsoft | 1
| S043661 | 2011-06-01 00:00:00.000 | Nokia | 3
000 | Microsoft | 1
| S043661 | 2011-06-01 00:00:00.000 | Nokia | 3
В примере выше мы определили, где будем искать массив JSON, который обрабатываем (т.е. по пути $.Orders), какие столбцы возвращаем и где в объектах JSON находятся значения, которые мы возвращаем как ячейки.
OPENJSON может быть использован в любом запросе при работе с данными. Как в примере, мы можем преобразовать массив JSON из переменной orders в набор строк и затем вставить их в обычную таблицу:
INSERT INTO Orders(Number, Date, Customer, Quantity)
SELECT Number, Date, Customer, Quantity
OPENJSON (@orders)
WITH (
Number varchar(200),
Date datetime,
Customer varchar(200),
Quantity int
) AS OrdersArray
4 столбца возвращаемого OPENJSON набора данных определены с помощью конструкции WITH. OPENJSON попытается найти свойства Number, Date, Customer и Quantity в каждом объекте JSON и преобразовать значения в столбцы в результирующем наборе данных. По умолчанию, если свойство не найдено, будет возвращен NULL. Предполагаем, что в переменной orders содержится следующий JSON:
По умолчанию, если свойство не найдено, будет возвращен NULL. Предполагаем, что в переменной orders содержится следующий JSON:
'[
{"Number":1, "Date": "8/10/2012", "Customer": "Adventure works", "Quantity": 1200},
{"Number":4, "Date": "5/11/2012", "Customer": "Adventure works", "Quantity": 100},
{"Number":6, "Date": "1/3/2012", "Customer": "Adventure works", "Quantity": 250},
{"Number":8, "Date": "12/7/2012", "Customer": "Adventure works", "Quantity": 2200}
]'
Как видите, преобразование из JSON в реляционную форму очень простое. Все, что нужно, это определить имена столбцов и типы, а OPENJSON найдет свойства в JSON, которые соответствуют столбцам. В этом примере используется простой одноуровневый JSON, но OPENJSON может работать и со сложными вложенными объектами.
Также OPENJSON может быть использован, когда нужно скомбинировать реляционные данные и JSON в одном и том же запросе. Предположим, что массив JSON из предыдущего примера хранится в столбце OrdersJson. Следующий запрос вернет обычные и JSON поля:
Следующий запрос вернет обычные и JSON поля:
SELECT Id, FirstName, LastName, Number, Date, Customer, Quantity
FROM Person
CROSS APPLY OPENJSON (OrdersJson)
WITH (
Number varchar(200),
Date datetime,
Customer varchar(200),
Quantity int ) AS OrdersArray
OPENJSON обработает массив в каждой ячейке и вернет одну строку для каждого объекта JSON в массиве. Синтаксис CROSS APPLY OPENJSON используется для объединения строк таблицы с данными JSON.
Индексирование данных JSON
Хотя значения в JSON хранятся как текст, вы можете индексировать их как обычные значения в столбцах. Можно использовать некластеризованные или полнотекстовые индексы.
Если нужно создать индекс на каком-либо свойстве JSON, которое часто используется в запросах, вы можете создать вычисляемый столбец, который ссылается на нужное свойство, затем создать обычный индекс по этому полю. В следующем примере мы оптимизируем запросы, которые фильтруют строки, используя свойство $.Company из столбца InfoJSON:
В следующем примере мы оптимизируем запросы, которые фильтруют строки, используя свойство $.Company из столбца InfoJSON:
ALTER TABLE Person
ADD vCompany AS JSON_VALUE(InfoJSON, '$.Company')
CREATE INDEX idx_Person_1
ON Person(vCompany)
SQL Server предоставляет гибридную модель, в которой вы можете комбинировать обычные столбцы и значения из JSON в одном индексе.
Т.к. JSON это просто текст, можно использовать полнотекстовый индекс. Полнотекстовые индексы могут быть созданы на массиве значений. Вы создаете полнотекстовый индекс на столбце, который содержит массив JSON, или можете создать вычисляемый столбец, который ссылается на массив и добавить полнотекстовый индекс на этот столбец:
ALTER TABLE Person
ADD vEmailAddresses AS JSON_QUERY(InfoJSON, '$.Contact.Emails')
CREATE FULLTEXT INDEX ON Person(vEmailAddresses)
KEY INDEX PK_Person_ID ON jsonFullTextCatalog;
Полнотекстовый индекс полезен, если вам нужно оптимизировать запросы, которые ищут какое-либо значение в массиве JSON:
SELECT PersonID, FirstName,LastName,vEmailAddresses FROM Person WHERE CONTAINS(vEmailAddresses, 'john@mail.
 microsoft.com')
microsoft.com')
Этот запрос вернет строки из Person, где массив электронных адресов содержит „[email protected]“. Полнотекстовый индекс не имеет специальных правил парсинга JSON. Он делит массив, используя разделители (двойные кавычки, запятые, квадратные скобки) и индексирует значения в массиве. Полнотекстовый индекс применим к массивам чисел или строк. Если у вас более сложные объекты в JSON, полнотекстовый индекс неприменим, так как он не сможет отличить ключи от значений.
В общем, одни и те же принципы создания индексов могут применяться к обычным столбцам или столбцам JSON.
Экспорт данных в JSON – FOR JSON
В SQL Server есть возможность преобразования реляционных данных в JSON с помощью конструкции FOR JSON. Если вам знакома конструкция FOR XML, то вы уже практически знаете и FOR JSON.
Пример
Исходные данные
| Number | Date | Customer | Price | Quantity | -------------------------------------------------------------------- | S043659 | 2011-05-31 00:00:00.
 000 | Microsoft | 59.99 | 1 |
| S043661 | 2011-06-01 00:00:00.000 | Nokia | 24.99 | 3 |
000 | Microsoft | 59.99 | 1 |
| S043661 | 2011-06-01 00:00:00.000 | Nokia | 24.99 | 3 |
SQL-запрос
SELECT Number AS [Order.Number], Date AS [Order.Date],
Customer AS [Account],
Price AS 'Item.UnitPrice', Quantity AS 'Item.Qty'
FROM SalesOrder
FOR JSON PATH, ROOT('Orders')
Результирующий JSON
{
"Orders": [
{
"Order": {
"Number": "S043659",
"Date": "2011-05-31T00:00:00"
},
"Account": "Microsoft",
"Item": {
"UnitPrice": 59.99,
"Qty": 1
}
},
{
"Order": {
"Number": "S043661",
"Date": "2011-06-01T00:00:00"
},
"Account": "Nokia",
"Item": {
"UnitPrice": 24.99,
"Qty": 3
}
}
]
}
Когда вы добавляете FOR JSON в конец SELECT запроса, SQL Server форматирует результат в виде JSON.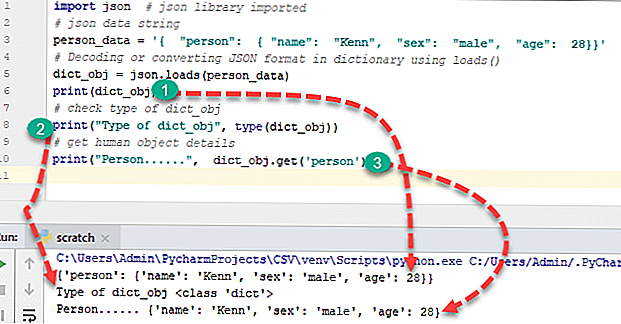 Каждая строка будет представлена как один объект JSON, значения из ячеек будут значениями JSON, а названия столбцов будут использованы как ключи. Есть 2 типа конструкций FOR JSON:
Каждая строка будет представлена как один объект JSON, значения из ячеек будут значениями JSON, а названия столбцов будут использованы как ключи. Есть 2 типа конструкций FOR JSON:
- FOR JSON PATH позволяет определить структуру JSON на выходе, используя названия столбцов. Если вы используете разделенные точкой имена как синонимы столбцов, свойства JSON будут следовать соглашениям по именованию. Это похоже на FOR XML PATH где вы можете указать путь, разделенный слешами.
- FOR JSON AUTO автоматически создает вложенные массивы на базе иерархии таблиц в запросе. Похоже на FOR XML AUTO.
Заключение
JSON функции в SQL Server позволяют запрашивать и анализировать данные в виде JSON, а также преобразовывать их в реляционный вид и наоборот. Это позволяет интегрировать SQL Server во внешние системы, которые отдают или принимают JSON без дополнительных преобразований.
SQL Server также предлагает гибридную модель хранения, когда вы комбинируете реляционные данные и данные JSON в одной таблице. Такая модель позволяет получить компромисс между высокой скоростью доступа к данным и гибкими возможностями разработки приложений.
Такая модель позволяет получить компромисс между высокой скоростью доступа к данным и гибкими возможностями разработки приложений.
Кроме того, вы можете индексировать значения в JSON как обычные столбцы, а также преобразовывать реляционные данные в JSON с помощью FOR JSON и обратно, используя OPENJSON.
Преобразуйте SQL в JSON онлайн бесплатно
редактор
Зритель
Преобразование
Слияние
Разблокировать
Защищать
Сплиттер
Сравнение
Аннотация
Парсер
Метаданные
Водяной знак
Поиск
Заменять
Повернуть
Обеспечить регресс
Диаграмма
Ипотека
Сборка
Перевод
Компресс
Прозрачный
ИМТ
ВебКонвертер
Питаться от
aspose. com
com
&
aspose.cloud
*Загружая свои файлы или используя наш сервис, вы соглашаетесь с нашими
Условия использования
&
политика конфиденциальности
Сохранить как
JSONPDFDOCXXLSXXLSXLSMXLSBXLTXXLTXLTMODSOTSCSVTSVHTMLMHTBMPJPGJPEGPNGGIFWEBPSVGTIFFEMFXPSXML
Ваши файлы успешно обработаны
СКАЧАТЬ СЕЙЧАС
Сохранить в облачное хранилище:
Отправить по электронной почте
On Premise API
Нажмите Ctrl+D, чтобы сохранить его в закладках, чтобы не искать его снова
Поделиться через фейсбук
Поделиться в Твиттере
Посмотреть другие приложения
Попробуйте наш облачный API
См. исходный код
исходный код
Оставить отзыв
Добавить это приложение в закладки
Нажмите Ctrl + D, чтобы добавить эту страницу в избранное, или Esc, чтобы отменить действие.
Вы хотите сообщить об этой ошибке на форум, чтобы мы могли изучить ее и решить проблему? Вы получите уведомление по электронной почте, когда ошибка будет исправлена.
Email:
Сделайте этот форум закрытым, чтобы он был доступен только вам и нашим разработчикам.
Вы успешно сообщили об ошибке. Вы получите уведомление по электронной почте, когда ошибка будет исправлена.
Нажмите эту ссылку, чтобы посетить форумы.
Вы уверены, что хотите удалить файлы?
Обработка…
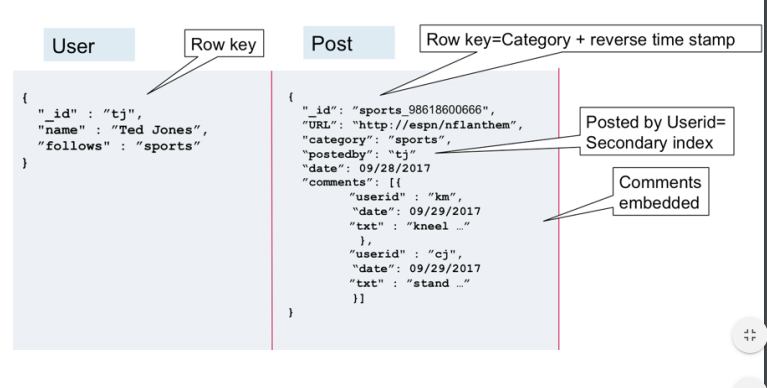
Работа с JSON в SQL Server
Введение
JSON (нотация объектов JavaScript) — это облегченный формат обмена данными. Он не зависит от языка, прост для понимания и дает самоописание. Он используется как альтернатива XML. JSON — это модный формат обмена данными в настоящее время. Большинство современных сервисов возвращают данные в виде текста JSON. SQL Server JSON — это одна из потребностей разработчиков данных для возврата JSON в SQL Server. В этой статье давайте узнаем, как реализовать объекты JSON в SQL Server.
Встроенная поддержка JSON на сервере SQL отличается от собственного типа JSON. JSON будет представлен как тип NVARCHAR по следующим причинам.
- Совместимость между функциями
Тип данных NVARCHAR поддерживает все компоненты сервера SQL, такие как Hekaton, временные таблицы, таблицы хранилища столбцов и т. д. Он работает почти со всеми функциями SQL Server. Если мы думаем, что JSON работает с функцией X SQL Server, простой ответ заключается в том, что если NVARCHAR работает с функцией X, JSON также будет работать. - Миграция
До SQL Server разработчики сохраняли JSON в базе данных как текст. Им нужно было изменить схему базы данных и перенести данные в новую функцию, если был введен тип JSON. - Поддержка на стороне клиента
В настоящее время на стороне клиента нет стандартизированного типа объекта JSON, например объекта XmlDom. JSON рассматривается как объект в JavaScript.
 д. Он работает почти со всеми функциями SQL Server. Если мы думаем, что JSON работает с функцией X SQL Server, простой ответ заключается в том, что если NVARCHAR работает с функцией X, JSON также будет работать.
д. Он работает почти со всеми функциями SQL Server. Если мы думаем, что JSON работает с функцией X SQL Server, простой ответ заключается в том, что если NVARCHAR работает с функцией X, JSON также будет работать.Следующие встроенные функции представлены в SQL Server для поддержки JSON.
- ISJSON
- JSON_VALUE
- JSON_QUERY
- JSON_MODIFY
- ОПЕНЬСОН
- ДЛЯ JSON
ISJSON (строка json)
Эта функция очень полезна для проверки входной строки в формате JSON перед ее сохранением в базе данных.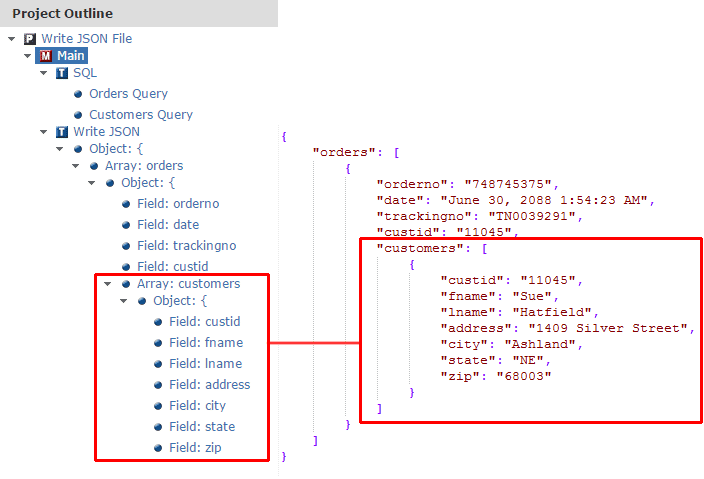 Он проверяет, находится ли предоставленный текстовый ввод NVARCHAR в правильном формате в соответствии со спецификацией JSON. Эта функция возвращает значение INT; если строка правильно отформатирована как JSON, она возвращает 1. В противном случае она возвращает 0.
Он проверяет, находится ли предоставленный текстовый ввод NVARCHAR в правильном формате в соответствии со спецификацией JSON. Эта функция возвращает значение INT; если строка правильно отформатирована как JSON, она возвращает 1. В противном случае она возвращает 0.
Пример
Для демонстрации примера я взял следующую строку JSON.
DECLARE @JSONData AS NVARCHAR(4000)
SET @JSONData = N'{
«Информация о сотруднике»: {
"Имя":"Джигнеш",
"Фамилия":"Триведи",
«Код»: «CCEEDD»,
"Адреса": [
{ "Адрес":"Тест 0", "Город":"Гандинагар", "Штат":"Гуджарат"},
{ "Адрес":"Тест 1", "Город":"Гандинагар", "Штат":"Гуджарат"}
]
}
}' SELECT ISJSON(@JSONData)
Вывод
JSON_VALUE (строка json, путь)
Возвращает скалярное значение из строки JSON. Он анализирует строку JSON и извлекает скалярное значение из строки JSON по определенному пути. Существует определенный формат для предоставления пути. Например,
- ‘$’ — ссылка на весь объект JSON
- ‘$.Property1’ — ссылка на свойство 1 в объекте JSON
- ‘$[2]’ — ссылка на 2-й элемент в массиве JSON
- ‘$.Property1.property2[4].property3’ — ссылка на вложенное свойство в объекте JSON
.
Пример
Я использовал точную строку JSON в качестве предыдущего примера для демонстрации примера.
SELECT JSON_VALUE(@JSONData,'$.EmployeeInfo.FirstName')
SELECT JSON_VALUE(@JSONData,'$.EmployeeInfo.Addresses[0].Address')
5 9000 Возвращает значение null, если указанный путь не найден в объекте JSON. Если мы хотим выдать ошибку, если указанный путь не найден в объекте JSON, мы можем использовать ключевое слово strict перед путем.
SELECT JSON_VALUE(@JSONData,'strict $.EmployeeInfo.Addresses[0].Address1')
JSON_QUERY(строка json, путь)
Извлекает массив данных или объектов из строки JSON. В следующем примере я извлек данные «Адреса» из объекта JSON и первый элемент данных «Адреса» из объекта JSON.
SELECT JSON_QUERY(@JSONData,'$.EmployeeInfo.Addresses') SELECT JSON_QUERY(@JSONData,'$.EmployeeInfo.Addresses[1]')
Если строка JSON содержит повторяющееся свойство, т. е. два ключа с одинаковым именем и на одном уровне, функции JSON_VALUE и JSON_QUERY возвращают первое значение, соответствующее пути.
DECLARE @JSONData AS NVARCHAR(4000)
SET @JSONData = N'{
«Информация о сотруднике»: {
"Имя":"Джигнеш",
"Фамилия":"Триведи",
"Имя":"Теджас",
"Код":"CCEEDD
}
}'
SELECT JSON_VALUE(@JSONData,'$.EmployeeInfo.FirstName') JSON_MODIFY (строка json, путь, новое значение)
Эта функция возвращает обновленную строку JSON в типе NVARCHAR. Он принимает три параметра; первый параметр — это строка JSON, второй параметр — это путь, по которому необходимо изменить значение, а третий параметр — это значение, которое необходимо обновить. Используя эту функцию, мы можем вставлять, обновлять, удалять или добавлять значение в строку JSON.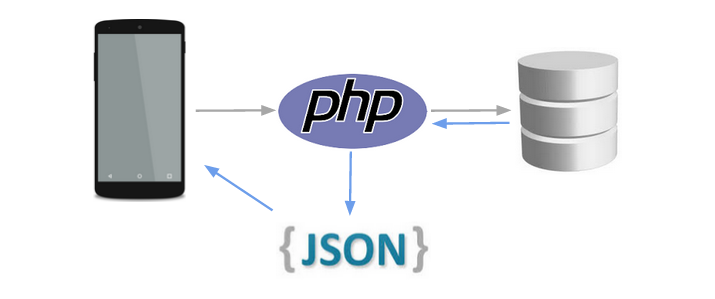
Обновление существующего значения
Чтобы обновить значение существующего JSON, нам нужно указать точный путь с новым значением. Например, мы можем обновить значение поля FirstName строки JSON, используя следующий запрос.
SET @JSONData = JSON_MODIFY(@JSONData,'$.EmployeeInfo.FirstName', 'Rakesh')
В следующем примере я обновил поле Address первого элемента EmployeeInfo.Addresses.
SET @JSONData = JSON_MODIFY(@JSONData,'$.EmployeeInfo.Addresses[0].Address', 'Test Address')
Вставка значения
Эта функция вставляет значение в строку JSON, если атрибут по указанному пути не существует. Если указанный путь уже существует, он обновит существующее значение новым. Новый атрибут всегда добавляется в конец существующей строки.
В следующем примере я добавил MiddleName в качестве нового атрибута в корень EmployeeInfo.
SET @JSONData = JSON_MODIFY(@JSONData,'$.EmployeeInfo.
 MiddleName ', 'G')
MiddleName ', 'G') Добавление значения
Используя существующее ключевое слово append, мы можем добавить элемент в массив в JSON. В следующем примере я добавил новый объект Address в элемент EmployeeInfo.Addresses.
SET @JSONData = JSON_MODIFY(@JSONData,'append $.EmployeeInfo.Addresses', JSON_QUERY('{"Address":"Test 2", "City":"Bhavnagar", "State":"Gujarat"}' ,'$')) Множественные обновления
Используя функцию JSON_MODIFY, мы можем обновить только одно свойство; если мы хотим обновить несколько свойств, нам нужно использовать несколько вызовов JSON_MODIFY.
В следующем примере я изменил два элемента: «Имя» и «Фамилия».
SET @JSONData = JSON_MODIFY(JSON_MODIFY(@JSONData,'$.EmployeeInfo.FirstName', 'Ramesh'),'$.EmployeeInfo.LastName','Oza')
Удаление существующего значения
Чтобы удалить существующее значение, нам нужно указать полный путь к элементу и установить новое значение равным NULL.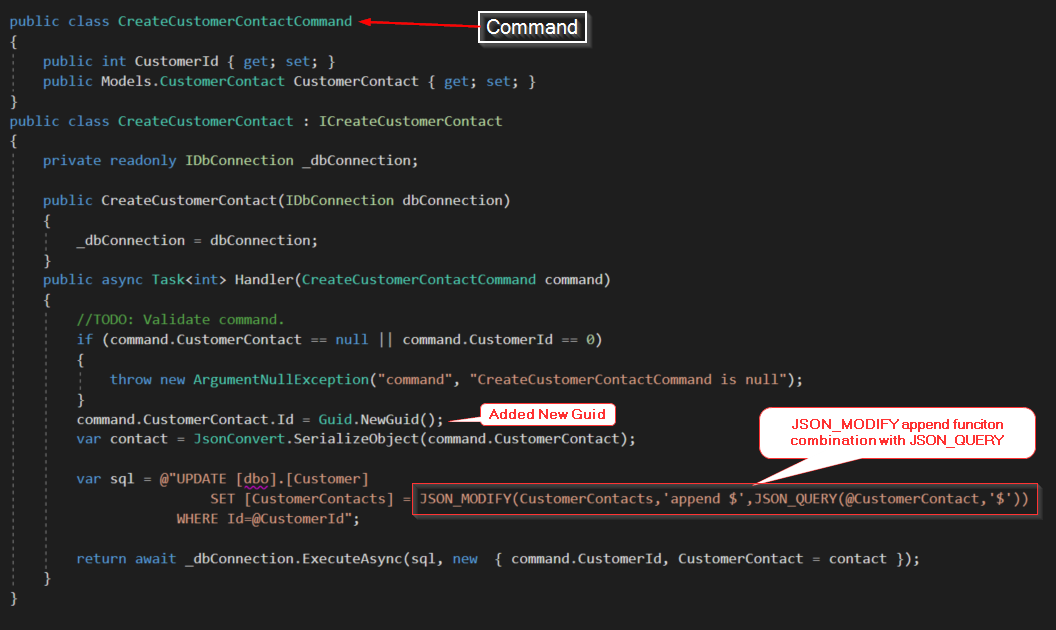
В следующем примере я удалил элемент «FirstName».
SET @JSONData = JSON_MODIFY(@JSONData,'$.EmployeeInfo.FirstName', NULL)
Переименование ключа
Переименование ключа напрямую не поддерживается, но мы можем добавить значение с новым ключом и удалить значение старый ключ. В следующем примере я переименовал ключ с «FirstName» на «ForeName».
SET @JSONData = JSON_MODIFY(JSON_MODIFY(@JSONData,'$.EmployeeInfo.ForeName', JSON_VALUE(@JSONData,'$.EmployeeInfo.FirstName')),'$.EmployeeInfo.FirstName', NULL)
FOR JSON
Функция FOR JSON очень полезна при экспорте данных таблицы SQL в формате JSON. Это очень похоже на функцию FOR XML. Здесь имена столбцов или псевдонимы являются ключевыми именами для объектов JSON. Есть два варианта JSON.
- АВТО — Будет создан вложенный подмассив JSON на основе иерархии таблиц, используемой в запросе.
- PATH — Это позволяет нам определить необходимую структуру JSON, используя имя столбца или псевдонимы. Если мы поместим имена, разделенные точками (.), в псевдонимах столбцов, свойства JSON будут следовать тому же соглашению об именах.
FOR JSON AUTO подходит для большинства сценариев, но FOR JSON PATH очень полезен в определенных сценариях, где мы должны контролировать, как данные JSON генерируются или вкладываются. FOR JSON PATH дает нам полный контроль над указанием выходного формата для данных JSON.
Синтаксис
ВЫБРАТЬ COL1, COL2 ИЗ СТОЛ ДЛЯ JSON АВТО| PATH
Пример
Чтобы продемонстрировать пример, я создал таблицы EmployeeInfo и Addresses. Я также вставил некоторые данные. Соотношение между таблицами следующее.
ГО CREATE TABLE [dbo].[Адреса]( [Id] [int] IDENTITY(1,1) NOT NULL, [EmployeeId] [int] NULL, [Адрес] [varchar](250) NULL, [Город] [varchar](50) NULL, [Состояние] [varchar](50) NULL, ОГРАНИЧЕНИЕ [PK_Addresses] ПЕРВИЧНЫЙ КЛЮЧ КЛАСТЕРИРОВАН ( [Идентификатор] ASC )С (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) НА [ПЕРВИЧНОМ] ИДТИ CREATE TABLE [dbo].
Пример – ДЛЯ JSON AUTO
SELECT * FROM [dbo].[EmployeeInfo] e INNER JOIN [dbo].[Addresses] Addresses ON e.Id = Addresses.EmployeeId ГДЕ e.Id = 1 ДЛЯ JSON AUTO
Вывод – JSON
[
{
"Идентификатор": 1,
"Код": "ABCD",
"Имя": "Джигнеш",
"Фамилия": "Триведи",
"Адреса": [
{
"Идентификатор": 1,
"EmployeeId": 1,
"Адрес": "Тест 0",
"Город": "Гандинагар",
"Штат": "Гуджарат"
},
{
"Идентификатор": 2,
"EmployeeId": 1,
"Адрес": "Тест 1",
"Город": "Бхавнагар",
"Штат": "Гуджарат"
}
]
}
] Пример: FOR JSON PATH
SELECT Id, Code, FirstName, LastName, (ВЫБЕРИТЕ Идентификатор, Адрес, Город, Штат ОТ [dbo].
Вывод
{
"Информация о сотруднике": [
{
"Идентификатор": 1,
"Код": "ABCD",
"Имя": "Джигнеш",
"Фамилия": "Триведи",
"Адреса": [
{
"Идентификатор": 1,
"Адрес": "Тест 0",
"Город": "Гандинагар",
"Штат": "Гуджарат"
},
{
"Идентификатор": 2,
"Адрес": "Тест 1",
"Город": "Бхавнагар",
"Штат": "Гуджарат"
}
]
}
]
} OPENJSON
Функция табличного значения создаст реляционную таблицу с ее содержимым из строки JSON. Он будет перебирать элементы и массивы объектов JSON и генерировать строку для каждого элемента. Мы можем сгенерировать таблицу без предопределенной схемы или с четко определенной схемой.
OPENJSON Без предопределенной схемы
Эта функция возвращает значение в виде пар ключ-значение, включая их тип. В следующем примере данные JSON показаны в виде пары ключ-значение с типом.
DECLARE @JSONData AS NVARCHAR(4000)
SET @JSONData = N'{
"Имя":"Джигнеш",
"Фамилия":"Триведи",
«Код»: «CCEEDD»,
"Адреса":[
{ "Адрес":"Тест 0", "Город":"Гандинагар", "Штат":"Гуджарат"},
{ "Адрес":"Тест 1", "Город":"Гандинагар", "Штат":"Гуджарат"}
]
}'
SELECT * FROM OPENJSON(@JSONData) OPENJSON с предварительно определенной схемой
Функция OPENJSON также может генерировать результирующий набор с предварительно определенной схемой. Если мы генерируем результаты с предопределенной схемой, она создает таблицу на основе предоставленной схемы, а не пары ключ-значение.
DECLARE @JSONData AS NVARCHAR(4000)
SET @JSONData = N'{
"Имя":"Джигнеш",
"Фамилия":"Триведи",
«Код»: «CCEEDD»
}'
ВЫБЕРИТЕ * ИЗ OPENJSON(@JSONData)
С (Имя VARCHAR(50),
Фамилия VARCHAR(50),
Код VARCHAR(50)) Мы также можем получить доступ к дочерним объектам JSON, используя функцию OPENJSON. Это можно сделать путем ПЕРЕКРЕСТНОГО ПРИМЕНЕНИЯ дочернего элемента JSON с родительским элементом.
В следующем примере объекты EmployeeInfo и Addresses извлекаются и применяются для перекрестного соединения. Нам нужно использовать параметр «AS JSON» в определении столбца, чтобы указать, какое из них ссылается на свойство, содержащее дочерний узел JSON. В столбце, указанном с помощью параметра «AS JSON», тип должен быть NVARCHAR (MAX). Без этого параметра эта функция возвращает значение NULL вместо дочернего объекта JSON и возвращает ошибку времени выполнения в «строгом» режиме.
DECLARE @JSONData AS NVARCHAR(4000)
SET @JSONData = N'{
"Имя":"Джигнеш",
"Фамилия":"Триведи",
«Код»: «CCEEDD»,
"Адреса":[
{ "Адрес":"Тест 0", "Город":"Бхавнагар", "Штат":"Гуджарат"},
{ "Адрес":"Тест 1", "Город":"Гандинагар", "Штат":"Гуджарат"}
]
}'
ВЫБИРАТЬ
Имя, Фамилия, Адрес, Город, Штат
ОТ OPENJSON(@JSONData)
С (Имя VARCHAR(50),
Фамилия VARCHAR(50),
Код VARCHAR(50),
Адреса NVARCHAR(max) как json
) как B
перекрестное применение openjson (B.Addresses)
с
(
Адрес VARCHAR(50),
Город ВАРЧАР(50),
Состояние VARCHAR(50)
) Резюме
Все современные веб-приложения поддерживают JSON, и это один из широко известных форматов обмена данными. Теперь SQL Server также поддерживает формат JSON. Для JSON SQL Server нет определенного типа данных, такого как XML. Нам нужно использовать NVARCHAR, когда мы взаимодействуем с JSON.
В SQL Server доступны многие встроенные функции, например ISJSON, JSON_VALUE, JSON_QUERY, JSON_MODIFY, OPENJSON и FOR JSON. Используя эти функции, мы можем поиграть с объектом JSON.
Почему (и как) вам следует управлять JSON с помощью SQL
Все мы знаем, что многие современные приложения используют REST API для взаимодействия с другими службами, особенно в облаке. Мы все знаем, что эти API обычно отправляют и получают данные, используя недавнее новшество: документы JavaScript Object Notation (JSON). И мы знаем, что существует множество способов хранения, управления и совместного использования этих документов в ваших приложениях.
Крис Саксон
Крис является сторонником разработки Oracle Database, и его работа заключается в том, чтобы помочь вам извлечь из этого максимум пользы и получить удовольствие от работы с SQL. Вы можете найти его в Твиттере, @ChrisRSaxon, и в его блоге All Things SQL.
Чего многие люди не знают, так это того, что лучший способ управления JSON — это, казалось бы, древний инструмент: язык SQL. Давайте посмотрим, почему это так, и пять примеров того, как это сделать.
Реляционные базы данных и язык SQL, управляющий данными внутри них, были разработаны более 40 лет назад для решения проблем качества данных с помощью современных технологий хранения. Базы данных, такие как MySQL, Oracle Database, IBM DB2, Microsoft SQL Server и другие, стали чрезвычайно успешными отчасти потому, что они сэкономили разработчикам и администраторам баз данных столько времени, сколько ручные методы работы с дубликатами, частичными или отсутствующими записями. Эти базы данных также обеспечивали надежные гарантии транзакций, что облегчало разработчикам получение правильных результатов в многопользовательских средах.
За последние четыре десятилетия реляционная модель и язык SQL снова и снова доказывали, что являются идеальными инструментами для работы с большими объемами данных. Очень большие объемы данных. Огромный. Массивный. Вот где на помощь приходит JSON.
Документы JSON могут быть большими и содержать значения, разбросанные по таблицам в вашей реляционной базе данных. Это может затруднить создание и использование этих API, поскольку вам может потребоваться объединить данные из нескольких таблиц для формирования ответа.
Однако при использовании сервисного API возникает противоположная проблема, а именно разбиение большого (он же массивного) документа JSON на соответствующие таблицы. Использование специально написанного кода для сопоставления этих элементов на уровне приложений утомительно. Такой пользовательский код, если только он не создан сверхтщательно кем-то, кто знает, как работают базы данных, также может привести к множеству обращений к службе базы данных, замедляя работу приложения и потенциально потребляя избыточную пропускную способность. Это ужасно для мобильного приложения.
Использование специально написанного кода для сопоставления этих элементов на уровне приложений утомительно. Такой пользовательский код, если только он не создан сверхтщательно кем-то, кто знает, как работают базы данных, также может привести к множеству обращений к службе базы данных, замедляя работу приложения и потенциально потребляя избыточную пропускную способность. Это ужасно для мобильного приложения.
Более быстрый и простой способ обработки JSON, поступающего от сервисных API, — это использование SQL.
Вы можете использовать всего несколько строк SQL, чтобы лучше управлять документами JSON в своем приложении. Вот пять быстрых примеров:
- Создание JSON с помощью SQL.
- Преобразование JSON в реляционные строки и столбцы.
- Обновление документов JSON.
- Эффективный поиск JSON.
- См. структуру документов JSON.
Создание JSON с помощью SQL
Вам поручили создать API. Он должен возвращать сведения об отделе и массив сотрудников, работающих в нем. Например:
Он должен возвращать сведения об отделе и массив сотрудников, работающих в нем. Например:
{
«отдел»: «Бухгалтерия»,
«сотрудники»: [
{
«name»: «Хиггинс, Шелли»,
«НаемДате»: «2002-06-07T00:00:00»
},
{
«name»: «Гитц, Уильям»,
«НаемДате»: «2002-06-07T00:00:00»
}
]
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | { «Департамент»: «бухгалтерский учет», «Сотрудники»: [ { «Имя»: «Хиггинс, Шелли», «Наем»: «2002-06-07T00: 00:00″ }, { «name»: «Гитц, Уильям», «hireDate»: «2002-06-07T00:00:00» } ] } |
Вероятно, данные отдела и данные о сотрудниках находятся в отдельных таблицах. Чтобы создать документ JSON в приложении, вы можете сначала запросить таблицу отделов, а затем получить ее сотрудников, перебирая их для создания массива JSON.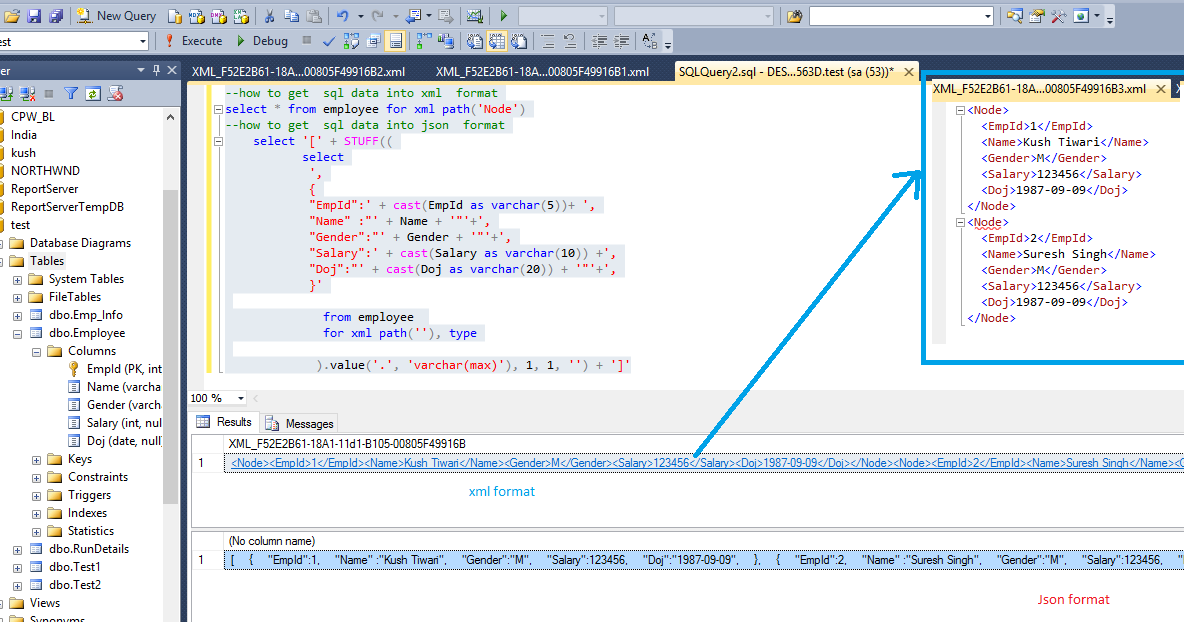
Это может привести к большому количеству обращений к базе данных, а сеть обычно является самой медленной частью стека. Таким образом, каждый дополнительный вызов тратит время, которое лучше потратить на обработку данных или на предоставление конечному пользователю быстрой работы.
С помощью SQL вы можете создать весь документ одним запросом:
выберите json_object (
значение ‘department’ d.department_name,
значение «сотрудники» json_arrayagg (
json_объект (
‘имя’ значение last_name || ‘, ‘ || имя,
Значение «hireDate»
)
)
)
от отдела кадров d
присоединиться к hr.employees e
на d.department_id = e.department_id
сгруппировать по d.department_name;
1 2 3 4 5 6 7 8 10 110005 12 13 | Выберите json_object ( ‘Department’ value D. ‘value json_arrayagg ( json_object ( ‘ Имя ‘value last_name || ) ) ) От Hr.Departments D Присоединяйтесь к HR.Employee E на D.Department_id = E.Department_id Группа от D.Department_Name; |
 Department_Name,
Department_Name,Этот код SQL создает весь документ JSON за одно обращение к базе данных. Даже если данные разбросаны по 10 таблицам, просто добавьте их в соединение, и вы сможете получить все за одну выборку.
Возврат данных в формате JSON избавляет вас от необходимости сопоставлять столбцы с полями JSON в приложении. Это уменьшает количество кода, который вам нужно написать. Он также отделяет код приложения от схемы базы данных, что упрощает изменение структуры таблиц в будущем. Все, что вам нужно сделать, это обновить код SQL.
В качестве последнего преимущества структура функций JSON точно соответствует схеме документа JSON, что упрощает проверку того, возвращает ли запрос нужный формат.
Создание JSON — это только полдела. При использовании API вам также необходимо принимать ответы JSON и сохранять их в реляционных таблицах.
Преобразование JSON в реляционные строки и столбцы
Если вы программируете, это сложно. Но SQL упрощает эту задачу. С помощью JSON_table вы можете разделять массивы JSON, возвращая строку для каждого элемента внутри них.
Например, передав приведенный выше документ в качестве переменной связывания для этого запроса, SQL может создать строку для каждого сотрудника:
выберите j.*
из json_table (
:json_document,
столбцы ‘$’ (
путь к отделу ‘$.department’,
вложенный путь ‘$.employees[*]’
столбцы (
путь имени ‘$.name’,
путь найма_даты ‘$.hireDate’
)
)
) ж;
НАЗВАНИЕ ОТДЕЛА HIRE_DATE
Бухгалтерский учет Гитц, Уильям 2002-06-07T00:00:00
Бухгалтерия Хиггинс, Шелли 07.06.2002 T00:00:00
1 2 3 4 5 6 7 8 10 110005 12 13 140005 15 | Выберите J. из JSON_TABL0005 имя путь ‘$.name’, Hire_date путь ‘$.hireDate’ ) ) ) j; ОТДЕЛ ИМЯ HIRE_DATE Бухгалтерия Gietz, William 2002-06-07T00:00:00 Бухгалтерия Higgins, Shelley 2002-06-07 T00:00:00 |
 *
*Вы можете вставлять выходные данные запроса прямо в свои таблицы, избегая необходимости в коде сопоставления базы данных и ограничивая круговые обращения.
В этот момент вы можете подумать: не проще ли было бы вставить документ как есть в одну таблицу базы данных? Это, безусловно, упростило бы добавление новых документов и получение их по первичному ключу.
Но это приносит разные проблемы. Возможно, вам по-прежнему потребуется изменить существующие документы. Поиск сохраненных документов JSON может быть медленным. И как именно вы знаете, какова структура этих документов?
К счастью, у Oracle Database есть много возможностей, которые помогут вам работать с документами JSON, хранящимися в базе данных.
Обновление документов JSON
Вероятно, вам потребуется изменить документ JSON после его загрузки в базу данных, например, когда клиент обновляет информацию в мобильном приложении или если вы добавили новую функцию в API.
Редактирование документов JSON может быть затруднено, особенно если вам нужно внести много изменений в один документ. Таким образом, хотя просто изменить одно значение в документе JSON, например, адрес клиента, изменение объектов в массиве становится сложной задачей.
С помощью JSON_transform вы можете добавлять, удалять или обновлять многие атрибуты с помощью одного оператора SQL. Вот SQL для удаления первой записи в массиве сотрудников, добавления нового объекта в конец этого массива и обновления названия отдела:
json_transform (
:json_document,
удалить ‘$.employees[0]’,
добавить ‘$.employees’ = (
json_объект (
‘имя’ значение ‘Саксон, Крис’,
Значение ‘hireDate’ ‘2020-01-01T00:00:00’
)
),
заменить ‘$. department’ = ‘Финансы и бухгалтерский учет’
department’ = ‘Финансы и бухгалтерский учет’
)
1 2 3 4 5 6 7 8 10 11 | JSON_TRANSFORM ( : JSON_DOCUMENT, Удалите ‘$ .mployees [0]’, Приложение ‘$ .mopecties’ = ( JSON_OBJECT ( ‘Имя’ Значение ‘Saxon, Chris’, ‘ HireDate’ value ‘2020-01-01T00:00:00’ ) ), заменить ‘$.department’ = ‘Финансы и бухгалтерский учет’ ) |
Свободная форма документов JSON означает, что атрибуты могут неожиданно присутствовать, отсутствовать или иметь значение null. Чтобы помочь вам избежать нежелательных изменений или побочных эффектов, JSON_transform содержит пункты, охватывающие каждый из этих случаев. Каждое предложение дает вам возможность игнорировать аномалию или создать исключение. Эти параметры позволяют точно контролировать изменения.
С помощью SQL и JSON легко объединить массивы сотрудников из двух отделов в один массив. Вам может быть интересно: как найти эти документы JSON?
Эффективный поиск в JSON
Простой доступ к точечной нотации SQL позволяет выполнять поиск в JSON без особых усилий. Все, что вам нужно сделать, это передать путь к атрибуту и значение, которое вы ищете.
Например, будут найдены все документы с атрибутом отдела, имеющим значение Финансы :
выберите * из компаний c
где c.department_data.department = ‘Финансы’;
выберите * из компаний c где c.department_data.department = ‘Финансы’; |
Конечно, в таблице могут быть миллионы строк, а реальные документы JSON могут быть большими (или огромными, или массивными). Сканирование всех этих строк может занять много времени. Отсюда возникает важный вопрос: как сделать эти запросы быстрыми?
Ключевым моментом является создание индексов для поддержки запроса. В Oracle Database есть несколько способов создания индексов. Вот три:
В Oracle Database есть несколько способов создания индексов. Вот три:
- Поисковый индекс JSON. Это индексирует весь документ.
- Функциональные индексы. Они нацелены на один атрибут в документе.
- Многозначные индексы. Они нацелены на множество элементов в массиве.
Индексы поиска лучше всего подходят, когда у вас есть инструменты отчетности или другие специальные запросы для доступа к данным. Они также включают руководство по данным JSON. Используя это, вы можете получить схему JSON, хранящуюся в таблицах базы данных.
Многозначные и функциональные индексы нацелены на определенные атрибуты, что делает их меньшими по размеру и более эффективными, чем поисковые индексы. Когда вы пишете поисковые запросы JSON в своем приложении, рекомендуется создать индекс, соответствующий предложению запроса where.
См. структуру документов JSON
Свободная форма JSON является одновременно его самой большой силой и самой большой слабостью. Как только вы начнете хранить документы JSON в своей базе данных, легко потерять представление об их структуре. Единственный способ узнать структуру документа — запросить его атрибуты.
Как только вы начнете хранить документы JSON в своей базе данных, легко потерять представление об их структуре. Единственный способ узнать структуру документа — запросить его атрибуты.
Руководство по данным JSON — это функция, которая решает эту проблему за вас. Передав документы JSON в функцию JSON_dataguide , вы можете получить их схему. Если вы создаете поисковый индекс, эта информация становится доступной в словаре данных базы данных, который включает путь и тип данных для каждого атрибута, хранящегося в индексированном документе JSON.
Например, этот запрос возвращает структуру документа JSON, хранящегося в Departments.department_json :
выберите json_dataguide (
d.department_json,
dbms_json.format_hierarchical
)
из отделов д;
{
«тип»: «объект»,
«о: длина»: 256,
«характеристики» : {
«сотрудники» : {
«тип»: «массив»,
«о: длина»: 128,
«o:preferred_column_name»: «сотрудники»,
«предметы» : {
«характеристики» : {
«имя» : {
«тип»: «строка»,
«о: длина»: 16,
«o:preferred_column_name»: «имя»
},
«Дата приема на работу» : {
«тип»: «строка»,
«о: длина» : 32,
«o:preferred_column_name»: «Дата найма»
}
}
}
},
«отделение» : {
«тип»: «строка»,
«о: длина»: 16,
«o:preferred_column_name»: «отдел»
}
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 31 28 29 4000 30 28 29 4 30 31 0005 32 33 34 35 36 | select json_dataguide ( d. dbms_json.format_hierarchical ) из отделов d; { «Тип»: «Объект», «O: длина»: 256, «Свойства»: { «Сотрудники»: { «Тип»: «Ассист», «o:length» : 128, «o: Preferred_column_name»: «Сотрудники», «Элементы»: { «Свойства»: { «Имя»: { «Тип»: «Строка», «O: Длина» : 16, «O: Preferred_column_name»: «Имя» }, «Наемник»: { «Тип»: «Строка», «O: длина»: 32, «O: Preferred_column_name» : «Дата найма» } } } }, «Отдел»: { «Тип»: «Строка», «O: Длина»: 16, «O: Preferred_column_Name»: «Департамент» » } } } |
 department_json,
department_json,Заключение
Работа с большими документами JSON может быть сложной задачей для любого приложения. Независимо от того, как хранятся данные, скорее всего, вам нужно сопоставить JSON с реляционным или наоборот.