Sql loop join: Nested Loops Join / Хабр
Содержание
Nested Loops Join / Хабр
По материалам статьи Craig Freedman: Nested Loops Join
SQL Server поддерживает три физические оператора соединений: соединение вложенных циклов, соединение слиянием и хэш-соединение. В этой статье я опишу соединение вложенных циклов — Nested Loops Join (или NL-соединение, для краткости).
Основной алгоритм
В упрощённом виде, Nested Loops Join (далее будем называть его соединением вложенных циклов) сравнивает каждую строку одной таблицы (называемой внешней таблицей) с каждой строке другой таблицы (называемой внутренней таблицей), ища те строки, которые удовлетворяют предикату соединения. Обратите внимание, что термины «внутренняя» и «внешняя» многозначны; их понимание зависит от контекста. «Внутренняя таблица» и «внешняя таблица» относится к потребляемым соединением строкам. «Внутреннее соединение» и «внешнее соединение» относятся к логическим операциям.
Этот алгоритм в псевдокоде можно представить таким образом:
for each row R1 in the outer table for each row R2 in the inner table if R1 joins with R2 return (R1, R2)
Эти вложенные циклы представляют тот самый алгоритм, который дал название соединению вложенных циклов.
Все строки должны подвергнуться сравнению, и, таким образом, стоимость этого алгоритма пропорциональна размеру внешней таблицы, умноженному на размер внутренней таблицы. Поскольку при увеличении размеров соединяемых таблиц стоимость растет очень сильно, на практике её уменьшают путём сокращения выборки из внутренней таблицы, строки которой обрабатываются для каждой строки внешней таблицы.
Для последующих примеров давайте использовать ту же самую схему, которая была в моей предшествующей статье:
create table Customers (Cust_Id int, Cust_Name varchar(10)) insert Customers values (1, 'Craig') insert Customers values (2, 'John Doe') insert Customers values (3, 'Jane Doe') create table Sales (Cust_Id int, Item varchar(10)) insert Sales values (2, 'Camera') insert Sales values (3, 'Computer') insert Sales values (3, 'Monitor') insert Sales values (4, 'Printer')
Рассмотрим такой запрос:
select * from Sales S inner join Customers C on S.Cust_Id = C.Cust_Id option(loop join)
 Cust_Id
option(loop join)
Cust_Id
option(loop join)Я использовал подсказку оптимизатору «loop join» для того, чтобы явно задать соединение вложенных циклов. В результате, будет получен показанный ниже план исполнения запроса, который был получен при выполнении с установкой «set statistics profile on»:
В этом плане исполнения внешней является таблица Customers, в то время как внутренней таблицей является Sales. Таким образом, всё начинается с просмотра таблицы Customers, откуда выбираются клиенты (по одному) и, для каждого из них просматривается таблица Sales. Поскольку у нас в таблице 3 клиента, просмотр таблицы Sales выполняется 3 раза. Каждый просмотр таблицы Sales возвращает 4 строки. Мы сравниваем каждую продажу с текущим клиентом и оцениваем, одинаковый ли у пары строк Cust_Id. Если это так, возвращаем эту пару строк. У нас имеется 3 клиента и 4 продажи, так что это сравнение исполняется всего 3*4 = 12 раз. Только три из этих сравнений соответствию заданным требованиям.
Теперь посмотрим, что случается, если создать индекс для таблицы Sales:
create clustered index CI on Sales(Cust_Id)
Теперь мы получаем такой план:
На этот раз, вместо просмотра таблицы Sales выполняется поиск по индексу. Поиск по индексу все еще делается три раза, по разу для каждого клиента, но каждый поиск по индексу возвращает только те строки, которые ссылаются на C.Cust_Id и квалифированы предикатом соединения. Таким образом, поиск возвращает только 3 строки по сравнению с 12 строками, возвращаемыми при просмотре таблицы.
Поиск по индексу все еще делается три раза, по разу для каждого клиента, но каждый поиск по индексу возвращает только те строки, которые ссылаются на C.Cust_Id и квалифированы предикатом соединения. Таким образом, поиск возвращает только 3 строки по сравнению с 12 строками, возвращаемыми при просмотре таблицы.
Обратите внимание, что поиск по индексу зависит от C.CustId, который получается из внешней таблицы соединения, путём просмотра таблицы Customers. Каждый раз, когда выполняется поиск по индексу (как Вы помните, он выполняется три раза — по одному для каждого клиента), C.CustId будет иметь разные значения. Обратите внимание, что C.CustId, по сути, является «коррелированным параметром». Если соединение вложенных циклов использует коррелированные параметры, они будут показаны в плане исполнения, как внешние ссылки «OUTER REFERENCES». Соединения вложенных циклов часто встречаются там, где имеется поиск по индексу, который зависит от коррелированного параметра, и эта зависимость носит характер соединения индекса «index join». Это распространённый сценарий.
Это распространённый сценарий.
Какие типы предикатов соединения поддерживает соединение вложенных циклов?
Соединение вложенных циклов поддерживает все предикаты соединения, включая предикаты эквивалентности (равенство) и предикаты неравенства.
Какие логические операторы соединения поддерживает соединение вложенных циклов?
Соединение вложенных циклов поддерживает следующие логические операторы соединения:
Внутреннее соединение
Левое внешнее соединение
Перекрестное соединение
CROSS APPLY и OUTER APPLY
Левое полусоединение и левое анти-полусоединение
Соединение вложенных циклов не поддерживает следующие логические операторы соединения:
Почему соединение вложенных циклов поддерживает только левые соединения?
Алгоритм соединения вложенных циклов легко поддаётся расширению, позволяющему поддерживать левое внешнее и полусоединение. В качестве примера, ниже показан псевдокод для левого внешнего соединения. Можно написать подобный псевдокод для левого полусоединения и левого анти-полусоединения.
Можно написать подобный псевдокод для левого полусоединения и левого анти-полусоединения.
for each row R1 in the outer table begin for each row R2 in the inner table if R1 joins with R2 return (R1, R2) if R1 did not join return (R1, NULL) end
Этот алгоритм отслеживает соединение каждой строки внешней таблицы, и, если после просмотра всех строк внутренней таблицы не удалось найти для соединения строку во внутренней таблице, создаёт дополнительные строки с NULL значениями.
Теперь давайте посмотрим, какие возможности существуют для поддержки правого внешнего соединения. В этом случае, нужно возвратить пары (R1, R2) для удовлетворяющих условию соединения строк, и пары (NULL, R2) для строк внутренней таблицы, которые не удовлетворяют условие соединения. Проблема состоит в том, что просмотр внутренней таблицы выполняется несколько раз, по одному разу для каждой строки внешнего соединения. В результате этих нескольких сканирований, могут быть получены те же самые строки внутренней таблицы. При этом неизвестно, как определить, что конкретная строка внутренней таблицы не удовлетворяет или не будет удовлетворять условию соединения? Кроме того, если мы используем соединение индекса, некоторые строками внутренней таблицы могут вообще оказаться пропущенными, хотя они должны быть возвращены для внешнего соединения.
При этом неизвестно, как определить, что конкретная строка внутренней таблицы не удовлетворяет или не будет удовлетворять условию соединения? Кроме того, если мы используем соединение индекса, некоторые строками внутренней таблицы могут вообще оказаться пропущенными, хотя они должны быть возвращены для внешнего соединения.
К счастью, поскольку правое внешнее соединение легко переписать как левое внешнее соединение, а правое полусоединение переписывается левым полусоединение, остаётся возможность использовать соединение вложенных циклов для правого внешнего и полусоединения. Однако, хотя такие преобразования и допустимы, они могут повлиять на производительность. Например, соединение «Customer left outer join Sales» применённое на указанной выше схеме с кластеризованным индексом по Sales, может использовать поиск по индексу Sales по аналогии с тем, как это делается в примере по внутренним соединениям. С другой стороны, соединение «Customer right outer join Sales» можно преобразовать в «Sales left outer join Customer», но теперь понадобится индекс по Customer.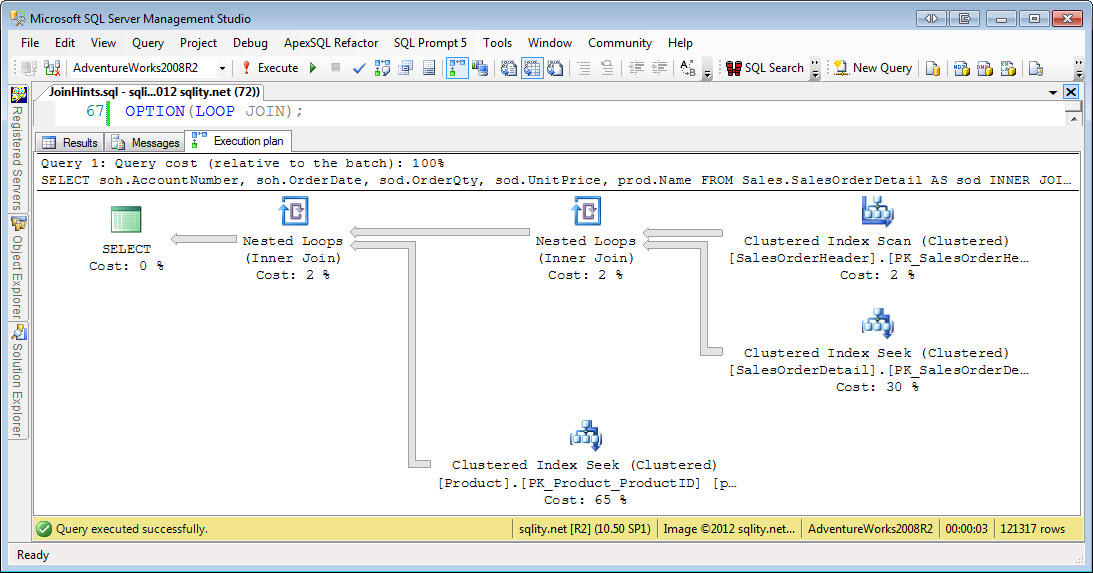
Почему не поддерживаются полные внешние соединения?
Соединение вложенных циклов не поддерживает полное внешнее соединение. Однако, всегда можно преобразовать «T1 full outer join T2» в «T1 left outer join T2 UNION T2 left anti-semi-join T1». В основе подобного преобразования лежит преобразование полного внешнего соединения в левое внешнее соединение, которое включает все подлежащие соединению пары строк из T1 и T2, и все строки T1, который не подлежат соединению, после чего, с помощью анти-полусоединения, добавляются строки T2, которые также не подлежат соединению. Вот так это может выглядеть:
select * from Customers C full outer join Sales S on C.Cust_Id = S.Cust_Id
Конкатенация тут представляет собой объединение красных строк (2-4) — левое внешнее соединение, и зеленых строк (5-9) — полусоединение, что позволяет реализовать полное внешнее соединение. Compute Scalar — это просто вычисление константы NULL для столбцов Customer, которое необходимо потому, что само по себе полусоединение не может генерировать выходные значения для внутренней таблицы (в этом случае имеется ввиду таблица Customer). Получается, что полусоединение только проверяет существование; т.е. то, что нет фактического соответствия никакой строке. TOP применяется в целях дополнительной (не обязательной) оптимизации, это позволяет прекратить просмотр таблицы при создании более чем одной строки. Ещё раз подчеркну, полусоединение только выполняет проверку на существование, поэтому единственное соответствие — это всё, что нам тут нужно. Говоря: «не обязательной», я имел ввиду то, что полусоединение остановилось бы после первого соответствия даже без TOP.
Получается, что полусоединение только проверяет существование; т.е. то, что нет фактического соответствия никакой строке. TOP применяется в целях дополнительной (не обязательной) оптимизации, это позволяет прекратить просмотр таблицы при создании более чем одной строки. Ещё раз подчеркну, полусоединение только выполняет проверку на существование, поэтому единственное соответствие — это всё, что нам тут нужно. Говоря: «не обязательной», я имел ввиду то, что полусоединение остановилось бы после первого соответствия даже без TOP.
Обратите внимание, что в последнем примере, оптимизатор выбирает просмотр внутреннего кластеризованного индекса даже при том, что вполне можно было использовать поиск. Это обусловлено стоимостью решения. Таблица настолько маленькая (помещается на одной странице), что нет никакой разницы между просмотром и поиском.
NL-соединение — это хорошо или плохо?
Это некорректный вопрос. Не бывает «лучшего» алгоритма соединений, и никакой алгоритм соединения не может считаться хорошим или плохим. Каждый алгоритм соединения хорошо работает в определённых условиях и может плохо работать в других условиях. Поскольку эффективность соединения вложенных циклов зависит от размера внешних данных, умножаемых на размер внутренних данных, это соединение лучше всего использовать для относительно маленьких наборов входных данных. Внутренний набор данных не обязательно должен быть маленьким, но, если он большой, может помочь создание индекса по ключу соединения с хорошей селективностью.
Каждый алгоритм соединения хорошо работает в определённых условиях и может плохо работать в других условиях. Поскольку эффективность соединения вложенных циклов зависит от размера внешних данных, умножаемых на размер внутренних данных, это соединение лучше всего использовать для относительно маленьких наборов входных данных. Внутренний набор данных не обязательно должен быть маленьким, но, если он большой, может помочь создание индекса по ключу соединения с хорошей селективностью.
В некоторых случаях, соединение вложенных циклов может оказаться единственным алгоритмом соединения, который SQL Server сможет использовать. SQL Server должен использовать соединение вложенных циклов в случае перекрестных соединений, а так же при некоторых сложных CROSS APPLY и OUTER APPLY. Кроме того, с одним исключением (для полного внешнего соединения), соединение вложенных циклов является единственным доступным алгоритмом соединения, который SQL Server может использовать без предикатов соединения по эквивалентности.
Что дальше …
В следующей статье, я продолжу рассмотрение физических операторов соединения, описав то, как работает соединение слиянием.
sql server 2008 — Чем объединение вложенных циклов отличается от внутреннего соединения?
спросил
Изменено
1 год, 7 месяцев назад
Просмотрено
5к раз
Чем соединение вложенного цикла отличается от внутреннего соединения с точки зрения рабочего\псевдокода и того, что предлагает использовать соединение вложенного цикла вместо внутреннего соединения.
- SQL-сервер-2008
2
Это не «вместо» — логическое ВНУТРЕННЕЕ СОЕДИНЕНИЕ может быть обработано несколькими физическими способами — вложенными циклами, сопоставлением хэшей или слиянием. Существует также четвертый тип, адаптивное соединение, но это своего рода мошенничество… на самом деле это просто отсрочка выбора между вложенными циклами и совпадением хэшей.
Существует также четвертый тип, адаптивное соединение, но это своего рода мошенничество… на самом деле это просто отсрочка выбора между вложенными циклами и совпадением хэшей.
Соединение с вложенными циклами обычно выбирается, когда одна сторона соединения относительно мала. Подумайте о присоединении к 9Таблица 0021 Customers к таблице Orders — в идеале клиент должен разместить большое количество заказов, поэтому способ соединения вложенного цикла (концептуально), если дисбаланс достаточно высок, заключается в том, что он начинается с первого клиент, собирает их заказы, затем переходит к следующему покупателю, собирает их заказы и т. д. В действительности оптимизатор примет решение во время составления плана о том, какая физическая операция наиболее целесообразна, и он делает это на основе множества факторов, такие как кардинальность двух таблиц, статистика, аппаратные ресурсы и т.д. и т.п.
(Кратко скажу, что объединение слиянием работает как застежка-молния, а хэш-соединение работает как набор сегментов. Но вы можете прочитать об этом в другом месте для получения более подробной информации.)
Но вы можете прочитать об этом в другом месте для получения более подробной информации.)
- Понимание соединений вложенных циклов
- Общие сведения о объединениях слияния
- Понимание хеш-соединений
В следующий раз, пожалуйста, поищите эти концепции и обратитесь за помощью по программированию, когда у вас возникнут реальные проблемы с их реализацией или пониманием того, почему в конкретном случае был выбран конкретный метод соединения. Это не библиотека. 🙂
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Общие сведения о физических соединениях SQL Server
Автор: Arshad Ali |
Обновлено: 2020-07-29 |
Комментарии (8) | Связанный: Подробнее > JOIN Tables
Проблема
В подсказке Присоединение к SQL Server
Например, Джереми Кадлек говорил о различных операторах логического соединения, но как
SQL Server реализует их физически? Чем отличается физическое соединение
операторы? Чем они отличаются друг от друга и в каком сценарии предпочтительнее
над другими? В этом совете мы рассмотрим эти и другие вопросы.
Решение
Мы используем логические операторы, когда пишем запросы для определения реляционного запроса в
концептуальный уровень (что нужно сделать). SQL реализует эти логические операторы
с тремя различными физическими операторами для реализации операции, определенной
логические операторы (как это нужно делать). Хотя существуют десятки физических
операторы, в этом совете я расскажу о конкретных операторах физического соединения. Хотя мы
Хотя мы
имеют разные типы логических соединений на концептуальном уровне/уровне запросов, но SQL Server
реализует их все с помощью трех разных операторов физического соединения, как описано ниже.
Мы покроем:
- Объединение вложенных циклов
- Объединить Присоединиться
- Хэш-соединение
Посмотрим
выполнение планов, чтобы увидеть эти операторы, и я объясню, почему каждый из них происходит.
Для этих примеров я использую
База данных AdventureWorks.
Объяснение соединения вложенных циклов SQL Server
Прежде чем углубляться в детали, позвольте мне сначала рассказать вам, что такое объединение вложенных циклов.
если вы новичок в мире программирования.
Соединение вложенных циклов — это логическая структура, в которой находится один цикл (итерация).
внутри другого, то есть для каждой итерации внешнего цикла все
выполняются/обрабатываются итерации внутреннего цикла.
Объединение вложенных циклов работает таким же образом. Одна из соединяемых таблиц обозначена
Одна из соединяемых таблиц обозначена
как внешний стол и еще один как внутренний стол. Для каждого ряда внешнего
таблица, все строки из внутренней таблицы сопоставляются одна за другой, если строка соответствует
он включается в набор результатов, в противном случае он игнорируется. Затем следующий ряд из
берется внешняя таблица, повторяется тот же процесс и так далее.
Оптимизатор SQL Server может выбрать соединение с вложенными циклами, когда одно из соединений
таблица маленькая (рассматривается как внешняя таблица), а другая большая (рассматривается
как внутренняя таблица, которая индексируется по столбцу, который находится в соединении) и, следовательно,
он требует минимального ввода-вывода и наименьшего количества сравнений.
Оптимизатор рассматривает три варианта объединения вложенных циклов:
- наивные вложенные циклы соединяются с , и в этом случае поиск сканирует
вся таблица или индекс - вложенные циклы индекса соединяются с , когда поиск может использовать
существующий индекс для выполнения поиска - Вложенные циклы временного индекса присоединяются к , если оптимизатор создает
временный индекс как часть плана запроса и уничтожает его после выполнения запроса
завершает
Соединение индекса с вложенными циклами работает лучше, чем соединение слиянием или хеш-соединение, если
участвует небольшой набор строк. Принимая во внимание, что если задействован большой набор строк,
Принимая во внимание, что если задействован большой набор строк,
Объединение вложенных циклов может быть не оптимальным выбором. Вложенные циклы поддерживают почти все
типы соединения, кроме правого и полного внешнего соединения, правого полусоединения и правого антиполусоединения.
присоединяется.
- В сценарии № 1 я присоединяюсь к таблице SalesOrderHeader с помощью SalesOrderDetail
таблицу и указать критерии для фильтрации результата клиента с
ID клиента = 670. - Этот отфильтрованный критерий возвращает 12 записей из таблицы SalesOrderHeader.
и, следовательно, будучи меньшей, эта таблица считается
внешняя таблица (верхняя в графическом плане выполнения запроса)
оптимизатором. - Для каждого ряда из этих 12 рядов внешних таблица, строки
из внутренней таблицы SalesOrderDetail сопоставляются (или внутренние
таблица сканируется 12 раз каждый раз для каждой строки с использованием поиска по индексу или корреляции
параметр из внешней таблицы) и 312 совпадающих строк возвращаются, как вы можете
см. на втором изображении. - Во втором запросе ниже я использую SET STATISTICS PROFILE ON для отображения
профильная информация о выполнении запроса вместе с набором результатов запроса.
 на втором изображении.
на втором изображении.Сценарий №1 — соединение вложенных циклов, пример
ВЫБЕРИТЕ H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal ОТ Sales.SalesOrderHeader H ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID ГДЕ H.CustomerID = 670
ВКЛЮЧИТЬ ПРОФИЛЬ СТАТИСТИКИ ВЫБЕРИТЕ H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal ОТ Sales.SalesOrderHeader H ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID ГДЕ H.CustomerID = 670 ВЫКЛЮЧИТЬ ПРОФИЛЬ СТАТИСТИКИ
Если количество задействованных записей велико, SQL Server может выбрать распараллеливание
вложенный цикл путем случайного распределения строк внешней таблицы среди доступных
Вложенные потоки циклов динамически. Это не относится к внутренней таблице
ряды однако. Дополнительные сведения о параллельном сканировании
Дополнительные сведения о параллельном сканировании
кликните сюда.
Объяснение объединения слиянием SQL Server
Первое, что вам нужно знать о соединении слиянием, это то, что оно требует
оба входа должны быть отсортированы по ключам соединения/столбцам слияния (или обе входные таблицы сгруппированы
индексирует столбец, соединяющий таблицы), а также требуется по крайней мере одно соединение по эквивалентности.
(равно) выражение/предикат.
Поскольку строки предварительно отсортированы, объединение слиянием немедленно начинает сопоставление
процесс. Он считывает строку с одного входа и сравнивает ее со строкой другого входа.
Если строки совпадают, эта совпадающая строка рассматривается в наборе результатов (тогда она читается
следующая строка из входной таблицы, выполняет такое же сравнение/сопоставление и т. д.) или
иначе меньшая из двух строк игнорируется, и процесс продолжается до тех пор, пока
все строки обработаны..
Соединение слиянием работает лучше при объединении больших входных таблиц (предварительно проиндексированных/отсортированных)
поскольку стоимость представляет собой сумму строк в обеих входных таблицах, а не во вложенных
Циклы, где это произведение строк обеих входных таблиц. Иногда оптимизатор
Иногда оптимизатор
решает использовать соединение слиянием, когда входные таблицы не отсортированы, и поэтому
использует явный физический оператор сортировки, но это может быть медленнее, чем использование индекса
(предварительно отсортированная входная таблица).
- В сценарии № 2 я использую запрос, аналогичный приведенному выше, но на этот раз у меня есть
добавлено предложение WHERE, чтобы получить всех клиентов больше 100. - В этом случае оптимизатор решает использовать соединение слиянием, так как оба входа
большие с точки зрения строк, и они также предварительно проиндексированы/отсортированы. - Вы также можете заметить, что оба входа сканируются только один раз, в отличие от
12 сканирований, которые мы видели во вложенных циклах, соединяются выше.
Сценарий № 2 — Пример объединения слиянием
ВЫБЕРИТЕ H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal ОТ Sales.SalesOrderHeader H ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesOrderDetail D ON H.
 SalesOrderID = D.SalesOrderID
ГДЕ H.CustomerID> 100
SalesOrderID = D.SalesOrderID
ГДЕ H.CustomerID> 100 ВКЛЮЧИТЬ ПРОФИЛЬ СТАТИСТИКИ ВЫБЕРИТЕ H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal ОТ Sales.SalesOrderHeader H ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID ГДЕ H.CustomerID> 100 ВЫКЛЮЧИТЬ ПРОФИЛЬ СТАТИСТИКИ
Соединение слиянием часто является более эффективным и быстрым оператором соединения, если отсортированное
данные могут быть получены из существующего индекса B-дерева, и он выполняет почти все соединения
операций, если задействован хотя бы один предикат соединения равенства. Это
также поддерживает несколько предикатов соединения на равенство, если входные таблицы
отсортированы по всем задействованным ключам соединения и расположены в том же порядке.
Наличие оператора Compute Scalar указывает на вычисление выражения
для получения вычисленного скалярного значения. В приведенном выше запросе я выбираю LineTotal
который является производным столбцом, поэтому он использовался в плане выполнения.
Объяснение хеш-соединения SQL Server
Хэш-соединение обычно используется, когда входные таблицы достаточно велики и не имеют подходящего размера.
на них есть индексы. Хэш-соединение выполняется в два этапа; этап сборки и
Фаза зонда и, следовательно, хэш-соединение имеет два входа, т. е. вход для сборки и зонд.
вход. Меньший из входов считается входом сборки (чтобы минимизировать
потребность в памяти для хранения хеш-таблицы, которая будет обсуждаться позже) и, очевидно, другая
один вход датчика.
На этапе сборки сканируются ключи соединения всех строк таблицы сборки.
Хэши генерируются и помещаются в хеш-таблицу в памяти. В отличие от соединения слиянием,
он блокируется (строки не возвращаются) до этого момента.
Во время фазы проверки сканируются ключи соединения каждой строки таблицы проверки.
Снова генерируются хэши (с использованием той же хэш-функции, что и выше) и сравниваются
против соответствующей хеш-таблицы для совпадения.
Хеш-функция требует значительного количества циклов ЦП для создания хэшей
и ресурсы памяти для хранения хеш-таблицы. Если есть нехватка памяти, некоторые
Если есть нехватка памяти, некоторые
разделов хеш-таблицы заменяются на tempdb и всякий раз, когда есть
при необходимости (проверить или обновить содержимое) он возвращается в кеш.
Для достижения высокой производительности оптимизатор запросов может распараллелить хеш-соединение с
масштабируется лучше, чем любое другое соединение, подробнее
кликните сюда.
Существует три основных типа хеш-соединений:
- Хэш-соединение в памяти , в этом случае доступно достаточно памяти
для хранения хеш-таблицы - Grace Hash Join , в этом случае хеш-таблица не подходит
в памяти и некоторые разделы пролиты на tempdb - Рекурсивное хэш-соединение , в этом случае хеш-таблица будет слишком большой.
оптимизатор должен использовать много уровней соединений слиянием.
Для получения более подробной информации об этих различных типах
нажмите здесь.
- В сценарии №3 я создаю две новые большие таблицы (из существующих таблиц AdventureWorks).
таблицы) без индексов. - Вы можете видеть, что оптимизатор решил использовать хеш-соединение в этом случае.
- Опять же, в отличие от объединения вложенных циклов, оно не сканирует несколько внутренних таблиц.
раз.

Сценарий № 3 — пример хэш-соединения
--Создать таблицы без индексов из существующих таблиц базы данных AdventureWorks SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail ИДТИ ВЫБЕРИТЕ H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal ОТ Sales.SalesOrderHeader1 H ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID ГДЕ H.CustomerID = 670 ИДТИ
ВКЛЮЧИТЬ ПРОФИЛЬ СТАТИСТИКИ ВЫБЕРИТЕ H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal ОТ Sales.SalesOrderHeader1 H ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID ГДЕ H.CustomerID = 670 ВЫКЛЮЧИТЬ ПРОФИЛЬ СТАТИСТИКИ
--Удалить таблицы, созданные для демонстрации
УДАЛИТЬ ТАБЛИЦУ Sales.
