Оконные функции могут отображаться только в предложениях SELECT или ORDER BY. Sql оконные функции
sql - Оконные функции могут отображаться только в предложениях SELECT или ORDER BY
Оконечные функции определены в спецификации ANSI для логического выполнения после обработки GROUP BY, HAVING, WHERE.
Чтобы быть более конкретными, они разрешены на этапах 5.1 и 6 в блок-схеме обработки логических запросов здесь.
Я полагаю, что они могли бы определить его другим способом и разрешили GROUP BY, WHERE, HAVING использовать функции окна, а окно было логическим результатом, установленным в начале этой фазы, но предположим, что они были и мы были разрешено создавать запросы, такие как
SELECT a, b, NTILE(2) OVER (PARTITION BY a ORDER BY b) AS NtileForSelect FROM YourTable WHERE NTILE(2) OVER (PARTITION BY a ORDER BY b) > 1 GROUP BY a, b, NTILE(2) OVER (PARTITION BY a ORDER BY b) HAVING NTILE(2) OVER (PARTITION BY a ORDER BY b) = 1С четырьмя различными логическими окнами в игре удачи, выясняя, каков будет результат этого! Кроме того, что, если в HAVING вы действительно хотели отфильтровать выражение из уровня GROUP BY выше, а не с окном строк, являющимся результатом после GROUP BY?
Версия CTE более подробная, но более ясная и удобная в использовании.
WITH T1 AS ( SELECT a, b, NTILE(2) OVER (PARTITION BY a ORDER BY b) AS NtileForWhere FROM YourTable ), T2 AS ( SELECT a, b, NTILE(2) OVER (PARTITION BY a ORDER BY b) AS NtileForGroupBy FROM T1 WHERE NtileForWhere > 1 ), T3 AS ( SELECT a, b, NtileForGroupBy, NTILE(2) OVER (PARTITION BY a ORDER BY b) AS NtileForHaving FROM T2 GROUP BY a,b, NtileForGroupBy ) SELECT a, b, NTILE(2) OVER (PARTITION BY a ORDER BY b) AS NtileForSelect FROM T3 WHERE NtileForHaving = 1Поскольку все они определены в инструкции SELECT и сглажены, это легко достижимо для устранения неоднозначности результатов с разных уровней, например. просто переключив WHERE NtileForHaving = 1 в NtileForGroupBy = 1
qaru.site
Как использовать оконные функции в sql для получения отдельных значений? MS SQL Server
Чтобы получить результат, который вы хотите, я бы предложил несколько иной подход к этому. Поскольку вы хотите повернуть на два столбца данных « Contacts и « Phone , я бы сначала отключил эти столбцы в несколько строк, а затем применил PIVOT – я думаю, что это проще, чем при попытке применить PIVOT дважды.
Я вижу несколько вещей, которые я исправил бы в вашем текущем запросе. Основная часть вашего запроса, соединяющая все таблицы, может изменить несколько вещей. Во-первых, я бы создал только один столбец Row :
row_number() over(partition by relation.company_id order by contact.first_name, contact.last_name) rowЭтот столбец будет разбит на company_Id в таблице contact_company_relation . Этот номер новой строки будет использоваться для столбцов « Contact и «Номер Phone .
Во-вторых, ваше текущее соединение для возврата номера Phone кажется неправильным. Ваш текущий код использует основной идентификатор company но вы хотите присоединиться к каждому контакту. Измените свой код:
left join contact_phones phone on company.id = phone.contact_idчтобы:
left join contact_phones phone on contact.id = phone.contact_idЭто сделает ваш подзапрос:
См. SQL Fiddle with Demo . Теперь данные будут выглядеть так:
| CONTACT_NAME | DISPLAY_PHONE | COMPANY_NAME | ROW | |--------------|---------------|--------------|-----| | Ben Gurion | 2222222 | Analist | 1 | | Ofer Jerus | 3333333 | Analist | 2 | | Ori Reshef | 1111111 | Analist | 3 |Когда у вас есть данные с номером строки, вы можете отключить display_phone и company_name в нескольких строках вместо столбцов. Вы не указали, какую версию SQL Server используете, но для этого вы можете использовать UNPIVOT или CROSS APPLY. Когда вы отключите данные, вы будете использовать значение Row для объединения каждой пары contact и phone – это гарантирует, что каждый контакт по-прежнему связан с правильным номером телефона. Код будет похож на:
См. SQL Fiddle with Demo . Теперь данные будут в формате, который имеет несколько строк для каждого имени компании, контакта и телефона:
| COMPANY_NAME | COL | VALUE | |--------------|-----------|------------| | Analist | Contact_1 | Ben Gurion | | Analist | Phone_1 | 2222222 | | Analist | Contact_2 | Ofer Jerus | | Analist | Phone_2 | 3333333 | | Analist | Contact_3 | Ori Reshef | | Analist | Phone_3 | 1111111 |Последним шагом было бы добавить функцию PIVOT, создающую окончательный код:
;with cte as ( select contact.first_name + ' ' + contact.last_name as contact_name, phone.display_phone, company.company_name, row_number() over(partition by relation.company_id order by contact.first_name, contact.last_name) row from contacts company left join contact_company_relation relation on company.id = relation.company_id left join contacts contact on relation.contact_id = contact.id and contact.is_company = 0 left join contact_phones phone on contact.id = phone.contact_id -- change to join on contact where company.is_company = 1 ) select company_name, contact_1, contact_2, contact_3, contact_4, contact_5, phone_1, phone_2, phone_3, phone_4, phone_5 from ( select company_name, col = col+'_'+cast(row as varchar(50)), value from cte cross apply ( select 'Contact', Contact_name union all select 'Phone', display_phone ) c (col, value) ) src pivot ( max(value) for col in (contact_1, contact_2, contact_3, contact_4, contact_5, phone_1, phone_2, phone_3, phone_4, phone_5) ) p;Оконные функции SQL Server 2012 на практике
Однажды пришлось решать некоторые аналитические задачи бизнеса. Как оказалось, новые оконные функции SQL Server 2012 оказались очень кстати.
Задача 1. Дан скрипт создания таблицы, содержащей данные о платежах клиента:
CREATE TABLE dbo.pays ( -- Идентификатор клиента client_id int not null, -- Дата и время платежа [date] datetime not null, -- Сумма платежа pay_sum decimal(19,2) not null ) Напишите запрос, который выбирал бы все данные из таблицы с добавлением 2 полей:- сумма платежа нарастающим итогом
- количество записей выше текущей для записей с тем же идентификатором клиента
Решение
SELECT [client_id], [date], [pay_sum], SUM([pay_sum]) OVER ( PARTITION BY [client_id] ORDER BY [date] ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS grow_sum, COUNT([client_id]) OVER ( PARTITION BY [client_id] ORDER BY [date] ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING ) AS prec_count FROM [dbo].[pays] ORDER BY [date], [client_id]- начало периода
- код ЦБ
- первая цена
- последняя цена
- максимальное значение
- минимальное значение
Решение (ключевая часть кода)
DECLARE @date_start smalldatetime = '20010101', @date_stop smalldatetime = '20010101' -- Ближайший период перед временным промежутком SELECT @date_start = DATEADD(ss, FLOOR(DATEDIFF(ss, @date_start, @date_begin) / @period_length) * @period_length, @date_start) SELECT @date_stop = DATEADD(ss, @period_length, @date_start) -- Выборка за один временной промежуток SELECT @date_start, [contract], ROW_NUMBER() OVER ( PARTITION BY [contract] ORDER BY [date] ), FIRST_VALUE([price]) OVER ( PARTITION BY [contract] ORDER BY [date] ), LAST_VALUE([price]) OVER ( PARTITION BY [contract] ORDER BY [date] RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ), MIN([price]) OVER (PARTITION BY [contract]), MAX([price]) OVER (PARTITION BY [contract]) FROM [dbo].[pays] WHERE [date] >= @date_start and [date]Задача 3. Дана таблица:
- client_id
- first_date
- last_date
Решение
DECLARE @type_id int = 1, @first_date date = '20130115', @last_date date = '20130415'; WITH cte_dates AS ( SELECT client_id, first_date, LEAD (first_date) OVER ( PARTITION BY client_id ORDER BY first_date ) AS new_first_date, LAG (last_date) OVER ( PARTITION BY client_id ORDER BY last_date ) AS old_last_date, last_date FROM dbo.docs WHERE [type_id] = @type_id AND first_date = @first_date) ) SELECT client_id, IIF(first_date @last_date, @last_date, last_date) AS last_date FROM cte_dates WHERE ( ABS(DATEDIFF(DAY, first_date, old_last_date)) > 1 AND ABS(DATEDIFF(DAY, last_date, new_first_date)) > 1 ) OR (old_last_date IS NULL AND new_first_date IS NULL)Оконные функции в SQL
Примечание: Запросы в данной статье работают в PostgreSQL и могут не работать в вашей СУБД, сверяйтесь с документацией!
Недавно я открыл для себя существование оконных функций в SQL. Расскажу о них на примере ситуации, когда они мне помогли: перенумерация записей в базе.
В то время я вносил мультитенантность в наше приложение — оно должно было работать в рамках разных станций. Соответственно, все сущности должны существовать в рамках станции и никогда не влиять на такие же сущности на других станциях. Добавить внешних ключей в таблицы — плёвое дело. Но что делать с существующими данными?
Итак, ситуация: у нас в приложении есть «путевые листы», они пронумерованы по порядку, в качестве номера используется просто ID. Но теперь оказывается, что должна быть своя нумерация в рамках каждой станции, а на станциях у документов есть ещё и серии, и внутри каждой серии тоже должна быть своя нумерация.
Сперва привяжем путевые листы напрямую к станциям. Смотрим схему данных: путевые листы привязаны к машинам, машины — к станциям, добавляем в миграции колонку station_id и пишем простой запрос, который добавит ID станции в таблицу waybills:
UPDATE waybills SET station_id = vehicles.station_id FROM vehicles WHERE vehicles.id = waybills.vehicle_idТеперь надо заново перенумеровать все путевые листы в рамках станции и серии. Тут-то нам и помогут оконные функции:
UPDATE waybills SET number = w.number FROM ( SELECT id, row_number() OVER ( PARTITION BY station_id, series ORDER BY created_at ) AS number FROM waybills ) w WHERE waybills.id = w.id;Итак, что же здесь происходит?
Во внешнем запросе мы используем уже виденный ранее синтаксис UPDATE … FROM, специфичный для PostgreSQL, мы заполняем колонку number значением, которое нам вычисляет подзапрос для записи с таким же id, как и в подзапросе.
В подзапросе же мы выбираем id каждой строки в нашей таблице waybills и с помощью оконной функции row_number() вычисляем порядковый номер этой строки в заданном разбиении.
Обратите внимание на синтаксис вызова оконных функций: функция OVER (разбиение). Разбиение задаётся ключевым словом PARTITION BY со списком колонок, по уникальным значениям которых строки и разбиваются на отдельные группы. Отличие от GROUP BY как раз и состоит в том, что строки в группах не схлопываются в одну, а обрабатываются по отдельности. Ключевое слово ORDER BY позволяет упорядочить строки внутри каждой группы.
Таким образом мы разбили строки на группы для каждой станции и серии документа и строки в каждой группе отсортировали по старшинству — от старых к новым. (функция row_number() вернёт 1 для самой старой строки в группе).
Пробуем подзапрос на тестовых данных:
=# SELECT id, station_id, series, created_at, row_number() OVER (PARTITION BY station_id, series ORDER BY created_at) AS number FROM waybills; id | station_id | series | created_at | number ----+--------------------------------------+--------+----------------------------+-------- 5 | 258d39b6-7b09-49ad-94f6-33b0dcb2fa32 | | 2015-04-07 10:53:44.736078 | 1 1 | 69c5b783-034c-47ea-84fd-c4abd0a323d6 | 123 | 2015-03-16 09:55:16.689384 | 1 6 | 69c5b783-034c-47ea-84fd-c4abd0a323d6 | 123 | 2015-04-28 13:47:16.397076 | 2 7 | 69c5b783-034c-47ea-84fd-c4abd0a323d6 | 123 | 2015-04-28 13:47:40.23337 | 3 2 | 69c5b783-034c-47ea-84fd-c4abd0a323d6 | 23 | 2015-03-18 12:06:25.688768 | 1 4 | 69c5b783-034c-47ea-84fd-c4abd0a323d6 | 4606 | 2015-03-24 08:10:38.143429 | 1 3 | 69c5b783-034c-47ea-84fd-c4abd0a323d6 | 656565 | 2015-03-18 15:30:10.709491 | 1 (7 rows)Отлично!
Миграция в полном виде будет выглядеть так:
class AddMultistationSupportForWaybills < ActiveRecord::Migration def change change_table :waybills do |t| t.integer :number t.references :station, type: :uuid end add_foreign_key :waybills, :stations reversible do |to| to.up do execute <<-PostgreSQL.strip_heredoc.tr("\n", ' ') UPDATE waybills SET station_id = vehicles.station_id FROM vehicles WHERE vehicles.id = waybills.vehicle_id PostgreSQL execute <<-PostgreSQL.strip_heredoc.tr("\n", ' ') UPDATE waybills SET number = w.number FROM ( SELECT row_number() OVER (PARTITION BY station_id, series ORDER BY created_at) AS number, id FROM waybills ) w WHERE waybills.id = w.id; PostgreSQL end end end endЗаключение
SQL обладает огромными возможностями на все случаи жизни. Но запомнить их все — пожалуй, непосильная задача. Надеюсь, что данная статья поможет людям изучить этот инструмент чуть лучше.
Материалы для изучения
Please enable JavaScript to view the comments powered by Disqus.envek.name
Biblioтека интересных материалов
Туризм – общее понятие, охватывающие несколько отраслей туристической деятельности. При подготовке специалистов в данной сфере изучению подлежит несколько профильных учебных дисциплин, в частности, связанные с изучением стран, картографии, социально-экономической географией. По итогу изучения готовится работа, представляющая собой изучение конкретной темы.… Продолжить чтение →
Написание курсовых работ – задача, с которой сталкивается каждый студент. Не каждый способен четко и ясно изложить мысли, обработать материал, выделив из него главное. В таком случае на помощь приходит Zalik.by – ресурс, на котором можно заказать работу у профессионалов.… Продолжить чтение →
Мы предлагаем только оригинальные работы, сделанные творческими людьми и квалифицированными авторами. Все их работы уникальны (это означает, что авторы никогда не загружают готовые работы из Интернета). Теперь проблема сходства работ и плохих оценок решена! Использование надежных источников информации обеспечивает индивидуальные… Продолжить чтение →
Узнать стоимость написания твоей работы Тема Предмет Выберите предмет…Авиационная и ракетно-космическая техникаАвтоматизация технологических процессовАвтоматика и управлениеАрхитектура и строительствоБазы данныхВысшая математикаГеометрияГидравликаДетали машинИздательское делоИнформатикаИнформационная безопасностьИнформационные технологииМатериаловедениеМашиностроениеМеталлургияМетрологияМеханикаМорская техникаНаноинженерияНачертательная геометрияПолиграфияПриборостроение и оптотехникаПрограммированиеПроцессы и аппаратыРабота на компьютереРадиофизикаСопротивление материаловТелевидениеТеоретическая механикаТеория вероятностейТеория машин и механизмовТеплоэнергетика и теплотехникаТехнологические… Продолжить чтение →
Список литературы Конституция Российской Федерации (принята всенародным голосованием 12.12.1993) (с учетом поправок, внесенных Законами РФ о поправках к Конституции РФ от 30.12.2008 N 6-ФКЗ, от 30.12.2008 N 7-ФКЗ, от 05.02.2014 N 2-ФКЗ, от 21.07.2014 N 11-ФКЗ) // Собрании законодательства РФ,… Продолжить чтение →
Заключение Государственные заимствования Российской Федерации — это займы и кредиты, привлекаемые от физических и юридических лиц, иностранных государств, международных финансовых организаций, по которым возникают долговые обязательства РФ как заемщика или гаранта погашения займов (кредитов) другими заемщиками. Государственный заем, как его… Продолжить чтение →
муниципальным ценным бумагам реестр владельцев именных ценных бумаг не ведется (ст. 4 Закона N 136-ФЗ). В соответствии со ст. 5 Закона N 136-ФЗ государственные и муниципальные ценные бумаги размещаются выпусками. Выпуск государственных и муниципальных ценных бумаг — это совокупность всех… Продолжить чтение →
но и иных ценных бумаг, относящихся к эмиссионным ценным бумагам в соответствии с ст. 2 Закона «О рынке ценных бумаг»[1]. В соответствии со ст. 2 Закона «О рынке ценных бумаг» и ст. 816 ГК РФ под облигацией понимается эмиссионная ценная… Продолжить чтение →
2 Правовое регулирование выпуска государственных внутренних долговых ценных бумаг Порядок выпуска, обращения и погашения государственных ценных бумаг РФ регулируется Федеральным законом от 29 июля 1998 г. N 136-ФЗ «Об особенностях эмиссии и обращения государственных и муниципальных ценных… Продолжить чтение →
объем иных (за исключением указанных) долговых обязательств Российской Федерации, оплата которых в валюте Российской Федерации предусмотрена федеральными законами до введения в действие БК РФ. Государственные займы являются добровольными. Принцип добровольности размещения государственных займов имеет конституционную основу — согласно ч. 4… Продолжить чтение →
biblo-ok.ru
MS SQL 2014 оконные функции
Вопрос: MSSQL 2014 и row level security
Коллеги, требуется реализовать RLS на MS SQL 2014.Пытаюсь делать через такую функцию
CREATE FUNCTION [dbo].[fn_Security](@ID_COMPANY AS int) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 as fn_Security_result WHERE (IS_MEMBER('группа1') = 1 AND @ID_COMPANY = 5) OR (IS_MEMBER('группа2') = 1 AND @ID_COMPANY = -1) ( все это вынесено в функцию, чтобы инкапсулировать логику предоставления доступа, а потом легко и просто перейти на 2016)В запросе (1), который нужно ускорить
select t1.* from таблица as t1 -- есть некластерный индекс по ID_COMPANY cross apply [dbo].[fn_Security](t1.ID_COMPANY) as t2 данные фильтруются уже после выборки:|--Filter(WHERE:(is_member(N'группа1')=(1) AND .[dbo].[таблица].[ID_COMPANY] as [t1].[ID_COMPANY]=(5) OR is_member(N'группа2')=(1) AND [dbo].[таблица].[ID_COMPANY] as [t1].[ID_COMPANY]=(-1)))|--Table Scan(OBJECT:([dbo].[таблица] AS [t1]))
а если сделать вот так (2)
select * from таблица as t1 -- есть некластерный индекс по ID_COMPANY where (IS_MEMBER('группа1') = 1 AND ID_COMPANY = 5) OR (IS_MEMBER('группа2') = 1 AND ID_COMPANY = -1) |--Table Scan(OBJECT:([таблица] AS [t1]), WHERE:(is_member(N'группа1')=(1) AND [dbo].[таблица].[ID_COMPANY] as [t1].[ID_COMPANY]=(5) OR is_member(N'группа2')=(1) AND [dbo].[таблица].[ID_COMPANY] as [t1].[ID_COMPANY]=(-1)))то в table scan-блоке сразу имеется предикат с фильтром, и этот запрос работает в 20 раз быстрее, чем предыдущий.
Ситуация с проблемным запросом с cross apply волшебным образом исправляется, если убрать одно OR-условие из функции. Но убирать его нельзя, т.к. оно нужно, чтобы для разных групп дать разный доступ.
Как ускорить запрос с cross apply?
forundex.ru
- Как найти тачпад в диспетчере устройств

- Какой может быть пароль

- Очистка места на диске с windows 10
- Средства администрирования удаленного сервера для windows 7
- На компьютере не открывается браузер
- Как включить компоненты windows 7
- Как пользоваться бесплатно касперским
- Интернет через вай фай
- Музыка в одноклассниках
- Одноклассники стали маленькие как вернуть обратно

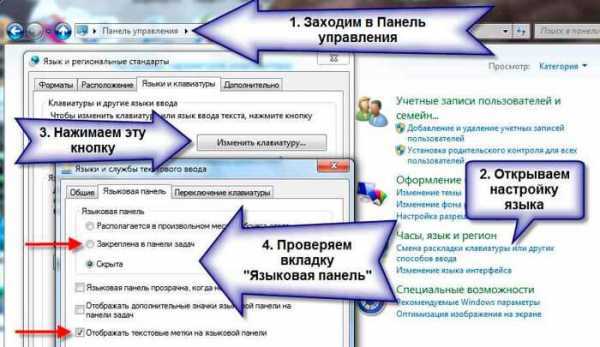
- Как вывести значок языка на панель задач