Sql partition by over: Оконные функции SQL простым языком с примерами / Хабр
Знакомство с функцией разделения по окнам
Поиск
Оконные функции T-SQL выполняют вычисления над набором строк (известным как «окно») и возвращают одно значение для каждой строки из базового запроса. Оконная (или оконная, или оконная) функция использует значения из строк в окне для вычисления возвращаемых значений.
Окно определяется с помощью предложения OVER() . Предложение OVER() T-SQL имеет следующие функции:
- Оно определяет разделы окна с помощью предложения PARTITION BY .
- Упорядочивает строки внутри разделов с помощью предложения ORDER BY .
Предложение OVER() может принимать три различных аргумента:
- PARTITION BY — PARTITION BY сбрасывает свой счетчик каждый раз, когда данный столбец изменяет значения.

- ORDER BY – ORDER BY упорядочивает строки (только в окне), которые оценивает функция.
- ROWS BETWEEN – ROWS BETWEEN позволяет дополнительно ограничить количество строк в окне.

Основное внимание в этой статье уделяется функции PARTITION BY, но я могу коснуться и некоторых других предложений.
Небольшой сценарий
Предположим, вы являетесь страстным поклонником автомобильного спорта и отслеживаете разных водителей, разные автомобили, скорости, которые они достигают, и скорости, которые разные машины достигают в определенные даты. Запрос, подобный приведенному ниже, даст вам подробные результаты.
SELECT
SpeedTestID,
SpeedTestDate,
CarID,
CarSpeed,
ROW_NUMBER() OVER (PARTITION BY SpeedTestDate, CarID ORDER BY SpeedTestID) AS SpeedTestsDoneToday, – перечисляет номер строки, упорядоченный по SpeedTestID
SUM(CarSpeed) OVER () AS CarSpeedTotal, – общая сумма Carspeed для всего набора результатов строка на SpeedTestdate,
SUM(CarSpeed) OVER (PARTITION BY SpeedTestDate, CarID) AS SpeedTotalPerCar, – Total CarSpeed для строки SpeedTestDate AND Car TestDate) AS SpeedAvg, – Средняя скорость автомобиля для строки в SpeedTestdate,
AVG(CarSpeed) OVER (PARTITION BY SpeedTestDate, CarID) AS SpeedAvgPerCar, –Average CarSpeed для строки SpeedTestDate AND Car код вниз.
Первые несколько строк должны быть очевидны; вы уже должны знать (особенно если вы читаете эту статью), как выбирать данные и указывать поля, необходимые в запросе на выборку.
ROW_NUMBER() отобразит текущий номер строки, вычисляемой оператором окна. В этом случае дата теста скорости, ID автомобиля и он будет упорядочен по полю SpeedTestID.
В следующих нескольких строках используются агрегатные функции для определения общей скорости автомобиля в тестах скорости, общей скорости в определенном ряду, общей скорости автомобиля на определенную дату, общей скорости автомобиля для конкретного автомобиля на определенную дату. , а также их средние значения.
Давайте продвинем пример еще на несколько шагов!
Добавьте в запрос следующее:
SUM(CarSpeed) OVER (ПО СТРОКАМ SpeedTestDate МЕЖДУ НЕОГРАНИЧЕННЫМИ ПРЕДЫДУЩЕЙ И ТЕКУЩЕЙ СТРОКАМИ) AS SpeedRunningTotal, — добавьте все значения CarSpeed в строках до текущей строки включительно
SUM( CarSpeed) OVER (ЗАКАЗАТЬ ПО SpeedTestDate СТРОКАМИ МЕЖДУ 3 ПРЕДЫДУЩЕЙ И ТЕКУЩЕЙ СТРОКАМИ) AS SpeedSumLast4 – добавить все значения CarSpeed в строках между текущей строкой и 3 строками перед ней
Используя ROWS BETWEEN, вы сужаете область действия, подлежащую оценке оконной функцией. Функция будет просто начинаться и заканчиваться там, где указано ROWS BETWEEN.
Функция будет просто начинаться и заканчиваться там, где указано ROWS BETWEEN.
Давай сойдем с ума. Добавьте следующие несколько строк в скрипт:
FIRST_VALUE(CarSpeed) OVER (ORDER BY SpeedTestDate) AS FirstSpeed, функция –FIRST_VALUE вернет первое значение CarSpeed в результирующем наборе PRECEDING AND UNBOUNDED FOLLOWING) AS LastSpeed, функция –LAST_VALUE вернет последнюю CarSpeed в наборе результатов
Здесь вы использовали First_Value и Last_Value, названия которых вполне уместны. Получить первое значение и получить последнее значение.
Еще дурацче… Добавьте следующий код:
LAG(CarSpeed, 1, 0) OVER (ORDER BY SpeedTestID) AS PrevSpeed, функция –LAG вернет CarSpeed из 1 строки позади него
LEAD(CarSpeed, 3 ) OVER (ORDER BY SpeedTestID) AS NextSpeed, функция –LEAD будет получать CarSpeed на 3 строки вперед
Lag получает скорость на одну строку раньше и опережает 3 строки после текущего набора результатов.
Причина, по которой я вставил их, заключается в том, чтобы вы могли увидеть истинную мощь оконных функций, так как это лишь верхушка айсберга
Заключение
Оконные функции могут спасти жизнь, упрощая сложные вычисления SQL . Вместо написания массивных операторов SQL, пытающихся понять определенную логику, оконная функция объединяет эту логику и обеспечивает обратную связь построчно или по окну.
Вместо написания массивных операторов SQL, пытающихся понять определенную логику, оконная функция объединяет эту логику и обеспечивает обратную связь построчно или по окну.
Предложение
OVER в SQL Server с примерами
Вернуться к: Учебник по SQL Server для начинающих и профессионалов
В этой статье я собираюсь обсудить пункт OVER в SQL Server с примерами. Пожалуйста, прочтите нашу предыдущую статью, в которой мы обсуждали встроенную строковую функцию в SQL Server. В конце этой статьи вы поймете силу и использование предложения OVER в SQL Server с примерами.
Предложение OVER в SQL Server:
Предложение OVER в SQL Server используется с PARTITION BY для разбиения данных на разделы. Ниже приведен синтаксис предложения OVER.
Указанная функция будет работать для каждого раздела. См. следующий пример. Допустим, у нас есть три отдела (HR, IT, Payroll).
COUNT (Department) OVER (PARTITION BY Departition)
В приведенном выше примере данные будут разделены по отделам, т. е. будет три раздела (IT, HR и Payroll), а затем функция COUNT(). будет применяться к каждому разделу. Здесь вы можете использовать широкий спектр встроенных функций, таких как COUNT(), SUM(), MAX(), ROW_NUMBER(), RANK(), DENSE_RANK(), AVG(), MIN() и т. д.
е. будет три раздела (IT, HR и Payroll), а затем функция COUNT(). будет применяться к каждому разделу. Здесь вы можете использовать широкий спектр встроенных функций, таких как COUNT(), SUM(), MAX(), ROW_NUMBER(), RANK(), DENSE_RANK(), AVG(), MIN() и т. д.
Пример: предложение OVER в SQL Server
Давайте рассмотрим пример, чтобы понять использование предложения SQL Server Over. Мы собираемся использовать следующую таблицу сотрудников.
Используйте следующий сценарий SQL для создания и заполнения таблицы «Сотрудники» необходимыми данными.
СОЗДАТЬ ТАБЛИЦУ Сотрудники
(
ID ИНТ,
Имя VARCHAR(50),
Кафедра ВАРЧАР(50),
Заработная плата
)
Идти
ВСТАВИТЬ В Значения сотрудников (1, «Джеймс», «ИТ», 15000)
ВСТАВИТЬ В Ценности сотрудников (2, «Смит», «ИТ», 35000)
ВСТАВИТЬ В Ценности сотрудников (3, «Расол», «HR», 15000)
ВСТАВИТЬ В Значения сотрудников (4, «Ракеш», «Заработная плата», 35000)
ВСТАВИТЬ В Ценности сотрудников (5, «Pam», «IT», 42000)
ВСТАВИТЬ В Значения сотрудников (6, «Стоукс», «HR», 15000)
ВСТАВИТЬ В Ценности сотрудников (7, «Тейлор», «HR», 67000)
ВСТАВИТЬ В Значения сотрудников (8, «Прити», «Заработная плата», 67000)
ВСТАВИТЬ В Ценности сотрудников (9, "Приянка", "Зарплатная ведомость", 55000)
ВСТАВИТЬ В Значения сотрудников (10, «Анураг», «Заработная плата», 15000)
ВСТАВИТЬ В Ценности сотрудников (11, «Маршал», «HR», 55000)
ВСТАВИТЬ В Ценности сотрудников (12, «Дэвид», «ИТ», 96000)
Пример:
Нам нужно создать отчет для отображения общего количества сотрудников по отделам. Наряду с этим нам также необходимо отобразить общую заработную плату, среднюю заработную плату, минимальную заработную плату и максимальную заработную плату по отделам. Это означает, что нам нужно создать отчет, как показано ниже.
Наряду с этим нам также необходимо отобразить общую заработную плату, среднюю заработную плату, минимальную заработную плату и максимальную заработную плату по отделам. Это означает, что нам нужно создать отчет, как показано ниже.
Мы можем легко получить вышеуказанные данные, просто используя предложение GROUP BY в SQL Server. Следующий SQL-запрос даст вам желаемый результат.
Отдел выбора, COUNT(*) КАК NoOfEmployees, СУММ(Зарплата) AS TotalSalary, AVG(Зарплата) AS AvgSalary, МИН(Зарплата) КАК Мин.Зарплата, МАКС(Зарплата) КАК Макс.Зарплата ОТ сотрудников СГРУППИРОВАТЬ ПО отделам
Пример:
Теперь бизнес-требования меняются, теперь нам также нужно показать неагрегированные значения (Имя и Зарплата) в отчете вместе с агрегированными значениями, как показано на рисунке ниже.
Вы можете использовать следующий SQL-запрос, добавив столбец Salary, Name в предложение select. Но это не будет работой.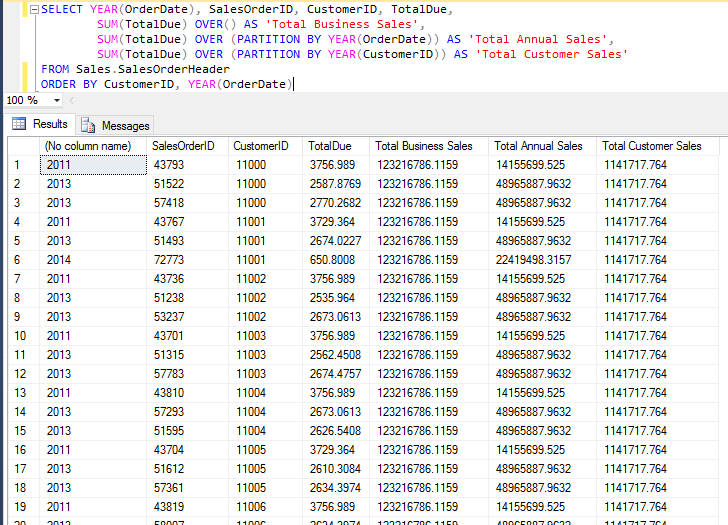
ВЫБЕРИТЕ Имя, Заработная плата, Отдел, COUNT(*) КАК NoOfEmployees, СУММ(Зарплата) AS TotalSalary, AVG(Зарплата) AS AvgSalary, МИН(Зарплата) КАК Мин.Зарплата, МАКС(Зарплата) КАК Макс.Зарплата ОТ сотрудников СГРУППИРОВАТЬ ПО отделам
При выполнении вышеуказанного запроса вы получите следующую ошибку. Это связано с тем, что невозможно включить неагрегированный столбец в список выбора при использовании предложения group by в SQL Server.
Как добиться желаемого результата?
Мы можем получить желаемый результат двумя способами.
Решение 1:
Один из способов получить желаемый результат – включить все агрегаты в подзапрос, а затем СОЕДИНИТЬ этот подзапрос с основным запросом. Следующий пример делает то же самое.
ВЫБЕРИТЕ Имя, Зарплата, Сотрудники.Отдел, Отделы.ОтделИтоги, Подразделения.Общая зарплата, Подразделения.
 Средняя зарплата,
Подразделения.Мин.Зарплата,
Отделы.MaxSalary
ОТ сотрудников
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
( ВЫБЕРИТЕ отдел, COUNT(*) AS DepartmentTotals,
СУММ(Зарплата) AS TotalSalary,
AVG(Зарплата) AS AvgSalary,
МИН(Зарплата) КАК Мин.Зарплата,
МАКС(Зарплата) КАК Макс.Зарплата
ОТ сотрудников
СГРУППИРОВАТЬ ПО отделам) AS Отделы
ON Отделы.Отдел = Сотрудники.Отдел
Средняя зарплата,
Подразделения.Мин.Зарплата,
Отделы.MaxSalary
ОТ сотрудников
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
( ВЫБЕРИТЕ отдел, COUNT(*) AS DepartmentTotals,
СУММ(Зарплата) AS TotalSalary,
AVG(Зарплата) AS AvgSalary,
МИН(Зарплата) КАК Мин.Зарплата,
МАКС(Зарплата) КАК Макс.Зарплата
ОТ сотрудников
СГРУППИРОВАТЬ ПО отделам) AS Отделы
ON Отделы.Отдел = Сотрудники.Отдел
Выполнив приведенный выше запрос, вы получите желаемый результат. Но посмотрите на количество написанных нами операторов T-SQL.
Решение 2:
Второй наиболее предпочтительный способ получения желаемого результата — использование предложения OVER в сочетании с предложением PARTITION BY , как показано в приведенном ниже коде.
ВЫБЕРИТЕ Имя,
Зарплата,
Отделение,
COUNT(Department) OVER(PARTITION BY Department) AS DepartmentTotals,
СУММА(Зарплата) НА(РАЗБИВКА ПО ОТДЕЛАМ) AS TotalSalary,
AVG(Зарплата) НАД(РАЗДЕЛЕНИЕ ПО ОТДЕЛАМ) AS AvgSalary,
МИН(Зарплата) ПРЕВЫШЕНИЕ(РАЗБИВКА ПО ОТДЕЛАМ) КАК Мин.
