Sql rank dense: RANK() DENSE_RANK() | SQL | SQL-tutorial.ru
Содержание
DENSE_RANK (Transact-SQL) — SQL Server
-
Статья -
-
Применимо к: SQL Server Azure SQL DatabaseУправляемый экземпляр SQL AzureAzure Synapse Analytics AnalyticsPlatform System (PDW)Конечная точка SQL в хранилище Microsoft Fabricв Microsoft Fabric
Эта функция возвращает ранг каждой строки в секции результирующего набора без промежутков в значениях ранжирования. Ранг определенной строки равен количеству различных значений рангов, предшествующих строке, увеличенному на единицу.
Соглашения о синтаксисе Transact-SQL
Синтаксис
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
Примечание
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
в статье Документация по предыдущим версиям.
Аргументы
<partition_by_clause>
Делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым затем применяется функция DENSE_RANK. Синтаксис PARTITION BY см. в статье Предложение OVER (Transact-SQL).
<order_by_clause>
Определяет порядок, в котором функция DENSE_RANK применяется к строкам в секции.
Типы возвращаемых данных
bigint
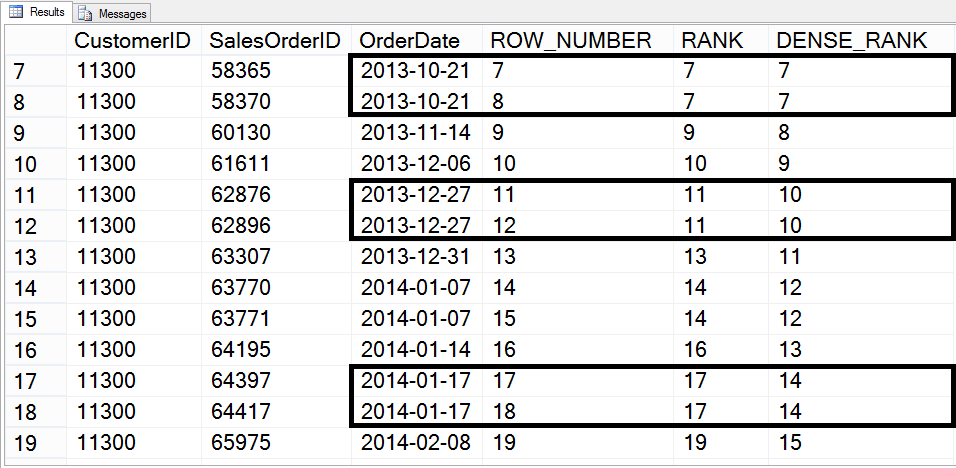
Если две строки или несколько в одной секции имеют одинаковые значения ранга, каждой такой строке присваивается один и тот же ранг. Например, если двум лучшим менеджерам по продажам соответствует одинаковое значение SalesYTD, им обоим присваивается значение ранга 1. Менеджеру по продажам со следующим по величине значением SalesYTD присваивается значение ранга 2. Это значение превышает количество отдельных строк, предшествующих данной строке, на единицу. Таким образом, между номерами, возвращаемыми функцией DENSE_RANK, нет промежутков, и они всегда имеют последовательные значения ранга.
Порядок сортировки, используемый для всего запроса, определяет порядок строк в результирующем наборе. Из этого следует, что строка с рангом 1 не всегда является первой строкой в секции.
Функция DENSE_RANK не детерминирована. Дополнительные сведения см. в статье Детерминированные и недетерминированные функции.
Примеры
A. Ранжирование строк внутри секции
В приведенном ниже примере продукты ранжируются по количеству в указанных местоположениях в описи. Функция DENSE_RANK секционирует результирующий набор по LocationID и логически сортирует его по Quantity. Обратите внимание, что количество продуктов 494 и 495 совпадает. Так как они имеют одинаковое значение количества, им обоим присваивается значение ранга 1.
USE AdventureWorks2012;
GO
SELECT i.ProductID, p.Name, i.LocationID, i.Quantity
,DENSE_RANK() OVER
(PARTITION BY i.LocationID ORDER BY i.Quantity DESC) AS Rank
FROM Production. ProductInventory AS i
INNER JOIN Production.Product AS p
ON i.ProductID = p.ProductID
WHERE i.LocationID BETWEEN 3 AND 4
ORDER BY i.LocationID;
GO
ProductInventory AS i
INNER JOIN Production.Product AS p
ON i.ProductID = p.ProductID
WHERE i.LocationID BETWEEN 3 AND 4
ORDER BY i.LocationID;
GO
 ProductInventory AS i
INNER JOIN Production.Product AS p
ON i.ProductID = p.ProductID
WHERE i.LocationID BETWEEN 3 AND 4
ORDER BY i.LocationID;
GO
ProductInventory AS i
INNER JOIN Production.Product AS p
ON i.ProductID = p.ProductID
WHERE i.LocationID BETWEEN 3 AND 4
ORDER BY i.LocationID;
GO
Результирующий набор:
ProductID Name LocationID Quantity Rank ----------- ---------------------------------- ---------- -------- ----- 494 Paint - Silver 3 49 1 495 Paint - Blue 3 49 1 493 Paint - Red 3 41 2 496 Paint - Yellow 3 30 3 492 Paint - Black 3 17 4 495 Paint - Blue 4 35 1 496 Paint - Yellow 4 25 2 493 Paint - Red 4 24 3 492 Paint - Black 4 14 4 494 Paint - Silver 4 12 5 (10 row(s) affected)
Б.
 Ранжирование всех строк в результирующем наборе
Ранжирование всех строк в результирующем наборе
В приведенном ниже примере возвращается список первых десяти сотрудников, ранжированных по окладу. Так как в инструкции SELECT предложение PARTITION BY не указывалось, функция DENSE_RANK применялась ко всем строкам результирующего набора.
USE AdventureWorks2012;
GO
SELECT TOP(10) BusinessEntityID, Rate,
DENSE_RANK() OVER (ORDER BY Rate DESC) AS RankBySalary
FROM HumanResources.EmployeePayHistory;
Результирующий набор:
BusinessEntityID Rate RankBySalary ---------------- --------------------- -------------------- 1 125.50 1 25 84.1346 2 273 72.1154 3 2 63.4615 4 234 60.0962 5 263 50.4808 6 7 50.4808 6 234 48.5577 7 285 48.
 101 8
274 48.101 8
101 8
274 48.101 8
В. Использование четырех ранжирующих функций в одном запросе
В этом примере демонстрируются четыре функции ранжирования:
- DENSE_RANK()
- NTILE()
- RANK()
- ROW_NUMBER()
Они используются в одном запросе. См. конкретные примеры по каждой ранжирующей функции.
USE AdventureWorks2012;
GO
SELECT p.FirstName, p.LastName
,ROW_NUMBER() OVER (ORDER BY a.PostalCode) AS "Row Number"
,RANK() OVER (ORDER BY a.PostalCode) AS Rank
,DENSE_RANK() OVER (ORDER BY a.PostalCode) AS "Dense Rank"
,NTILE(4) OVER (ORDER BY a.PostalCode) AS Quartile
,s.SalesYTD
,a.PostalCode
FROM Sales.SalesPerson AS s
INNER JOIN Person.Person AS p
ON s.BusinessEntityID = p.BusinessEntityID
INNER JOIN Person.Address AS a
ON a.AddressID = p.BusinessEntityID
WHERE TerritoryID IS NOT NULL AND SalesYTD <> 0;
Результирующий набор:
| FirstName | LastName | Row Number | Rank | Dense Rank | Quartile | SalesYTD | PostalCode |
|---|---|---|---|---|---|---|---|
| Michael | Blythe | 1 | 1 | 1 | 1 | 4557045,0459 | 98027 |
| Linda | Mitchell | 2 | 1 | 1 | 1 | 5200475,2313 | 98027 |
| Jillian | Carson | 3 | 1 | 1 | 1 | 3857163,6332 | 98027 |
| Garrett | Vargas | 4 | 1 | 1 | 1 | 1764938,9859 | 98027 |
| Tsvi | Reiter | 5 | 1 | 1 | 2 | 2811012,7151 | 98027 |
| Shu | Ito | 6 | 6 | 2 | 2 | 3018725,4858 | 98055 |
| Josй | Saraiva | 7 | 6 | 2 | 2 | 3189356,2465 | 98055 |
| David | Campbell | 8 | 6 | 2 | 3 | 3587378,4257 | 98055 |
| Tete | Mensa-Annan | 9 | 6 | 2 | 3 | 1931620,1835 | 98055 |
| Lynn | Tsoflias | 10 | 6 | 2 | 3 | 1758385,926 | 98055 |
| Rachel | Valdez | 11 | 6 | 2 | 4 | 2241204,0424 | 98055 |
| Jae | Pak | 12 | 6 | 2 | 4 | 5015682,3752 | 98055 |
| Ranjit | Varkey Chudukatil | 13 | 6 | 2 | 4 | 3827950,238 | 98055 |
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
Г.
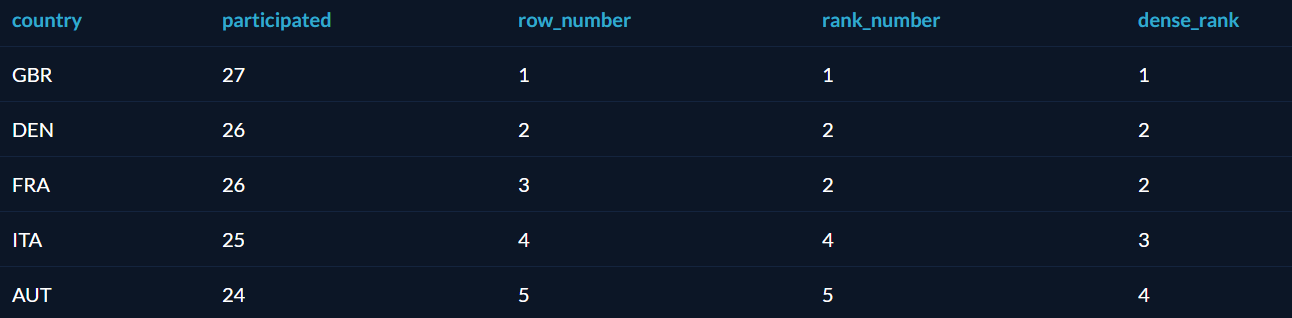 Ранжирование строк внутри секции
Ранжирование строк внутри секции
В приведенном ниже примере торговые представители на каждой территории продаж ранжируются в соответствии с общим объемом продаж. Функция DENSE_RANK секционирует набор строк по SalesTerritoryGroup и логически сортирует результирующий набор по SalesAmountQuota.
-- Uses AdventureWorks
SELECT LastName, SUM(SalesAmountQuota) AS TotalSales, SalesTerritoryGroup,
DENSE_RANK() OVER (PARTITION BY SalesTerritoryGroup ORDER BY SUM(SalesAmountQuota) DESC ) AS RankResult
FROM dbo.DimEmployee AS e
INNER JOIN dbo.FactSalesQuota AS sq ON e.EmployeeKey = sq.EmployeeKey
INNER JOIN dbo.DimSalesTerritory AS st ON e.SalesTerritoryKey = st.SalesTerritoryKey
WHERE SalesPersonFlag = 1 AND SalesTerritoryGroup != N'NA'
GROUP BY LastName, SalesTerritoryGroup;
Результирующий набор:
LastName TotalSales SalesTerritoryGroup RankResult ---------------- ------------- ------------------- -------- Pak 10514000.
 0000 Europe 1
Varkey Chudukatil 5557000.0000 Europe 2
Valdez 2287000.0000 Europe 3
Carson 12198000.0000 North America 1
Mitchell 11786000.0000 North America 2
Blythe 11162000.0000 North America 3
Reiter 8541000.0000 North America 4
Ito 7804000.0000 North America 5
Saraiva 7098000.0000 North America 6
Vargas 4365000.0000 North America 7
Campbell 4025000.0000 North America 8
Ansman-Wolfe 3551000.0000 North America 9
Mensa-Annan 2753000.0000 North America 10
Tsoflias 1687000.0000 Pacific 1
0000 Europe 1
Varkey Chudukatil 5557000.0000 Europe 2
Valdez 2287000.0000 Europe 3
Carson 12198000.0000 North America 1
Mitchell 11786000.0000 North America 2
Blythe 11162000.0000 North America 3
Reiter 8541000.0000 North America 4
Ito 7804000.0000 North America 5
Saraiva 7098000.0000 North America 6
Vargas 4365000.0000 North America 7
Campbell 4025000.0000 North America 8
Ansman-Wolfe 3551000.0000 North America 9
Mensa-Annan 2753000.0000 North America 10
Tsoflias 1687000.0000 Pacific 1
См. также:
RANK (Transact-SQL)
ROW_NUMBER (Transact-SQL)
NTILE (Transact-SQL)
Ранжирующие функции (Transact-SQL)
Функции
3 функции нумерации и ранжирования строк в Apache Hive: ликбез
Автор Анна Вичуговав категории Hive, Статьи
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank().
Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank().
Генерация порядкового номера строки в Apache Hive
Иногда при обработке данных с помощью Apache Hive нужно сгенерировать порядковый номер строки. Например, чтобы создать суррогатные ключи или упорядочить последовательность. Предположим, есть набор данных с ответами на вопросы, которые требуется упорядочить средствами Apache Hive. Для этого сперва создадим внешнюю таблицу:
CREATE EXTERNAL TABLE data_source_raw ( QUESTION STRING ) LOCATION '/user/hive/warehouse/datasource.db/survey_results/';
Задачу установки порядкового номера строки в Hive можно решить с помощью аналитической функции row_number(), которая возвращает восходящую последовательность целых чисел, начиная с 1. Эта функция начинает последовательность заново для каждой группы, созданной предложением PARTITIONED BY. Выходная последовательность включает разные значения для повторяющихся входных значений. Таким образом, результирующая последовательность никогда не содержит дубликатов или пробелов, независимо от повторяющихся входных значений.
Эта функция начинает последовательность заново для каждой группы, созданной предложением PARTITIONED BY. Выходная последовательность включает разные значения для повторяющихся входных значений. Таким образом, результирующая последовательность никогда не содержит дубликатов или пробелов, независимо от повторяющихся входных значений.
На практике функция row_number() чаще всего используется для первых N и нижних N запросов, когда известно, что входные значения уникальны или требуется ровно N строк независимо от повторяющихся значений. Поскольку результирующее значение отличается для каждой строки в результирующем наборе без использования в запросе выражения PARTITION BY, row_number() можно использовать для синтеза уникальных числовых значений идентификаторов, например, для результирующих наборов, содержащих уникальные значения или кортежи. Результаты, возвращаемые этой функцией аналогичны применению RANK и DENSE_RANK в SQL-запросах, но процессы обработки повторяющихся комбинации значений немного отличаются. Чем именно row_number() отличается от rank() с dense_rank(), рассмотрим далее.
Чем именно row_number() отличается от rank() с dense_rank(), рассмотрим далее.
Hadoop SQL администратор Hive
ROW_NUMBER vs RANK и DENSE_RANK
Итак, аналитическая функция row_number() в Hive используется для присвоения уникальных значений каждой строке или строкам в группе на основе значений столбца, используемых в предложении OVER.
Функция rank() используется для получения ранга строк в столбце или в группе. Строки с одинаковыми значениями получают одинаковый ранг, а следующее значение ранга пропускается.
Функция dense_rank() также возвращает ранг значения в группе. Строки с одинаковыми значениями критериев ранжирования получают одинаковый ранг в последовательном порядке, т. е. никакие ранговые значения не пропускаются.
Таким образом, row_number() просто возвращает номер строки каждой записи, начиная с 1. В отличие от rank() и dense_rank(), эта функция не будет учитывать никакой связи между строками, даже если в ней присутствуют одинаковые значения. Поэтому row_number() можно использовать для удаления повторяющихся записей в Hive.
В отличие от rank() и dense_rank(), эта функция не будет учитывать никакой связи между строками, даже если в ней присутствуют одинаковые значения. Поэтому row_number() можно использовать для удаления повторяющихся записей в Hive.
Функцию rank() можно использовать для ранжирования строк на основе значения столбца. Но при наличии связи между N предыдущими записями для значения в столбце ORDER BY, функции rank() пропускают следующие N-1 позиции перед увеличением счетчика. Dense_rank() также аналогична функции rank(), но она не пропускает ни одного ранга, даже если между строками есть связь.
Практический пример использования функции row_number()
Итак, после создания таблицы и вставки данных при выполнении HiveQL-запроса с применением функции row_number()имеем следующий результат:
select row_number() over( order by question) id, question from data_source_raw;
Чтобы использовать функцию row_number() и добавить столбец с порядковым номером, следует сообщить столбцу о разделении на более высокий порядок. В нашем примере можно использовать столбец вопроса и создать порядковый номер на его основе. Выполнив запрос, получим упорядоченные вопросы и созданный идентификатор столбца последовательности.
В нашем примере можно использовать столбец вопроса и создать порядковый номер на его основе. Выполнив запрос, получим упорядоченные вопросы и созданный идентификатор столбца последовательности.
А если нужно создать столбец последовательности на основе порядка вопросов в файле, то при использовании функции row_number() можно упорядочивать данные по NULL:
select row_number() over( order by null) id, question from data_source_raw;
Чтобы упорядочить данные, как в исходном файле, с помощью Apache Hive, можно использовать предыдущий запрос в качестве подзапроса и упорядочить столбец идентификатора по убыванию:
select row_number() over( order by s.id desc) id, s.question from (select row_number() over( order by null) id, * from data_source_raw) s;
Интеграция Hadoop и NoSQL
Освойте все тонкости работы с Apache Hive для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
Смотреть расписание
Записаться на курс
Источники
- https://jozimarback. medium.com/generating-sequence-number-in-apache-hive-279b73c315df
- https://studywithswati.wordpress.com/2020/06/12/rank-dense_rank-row_number-in-hive/
- http://www.bigdatainterview.com/rank-vs-dense_rank-vs-row_number-in-hive-or-differences-between-rank-dense_rank-and-row_number-or-ranking-window-functions-in-hive/
 medium.com/generating-sequence-number-in-apache-hive-279b73c315df
medium.com/generating-sequence-number-in-apache-hive-279b73c315dfФункции
RANK, DENSE_RANK и ROW_NUMBER в SQL Server
Введение
В этой статье вы узнаете о функциях RANK, DENSE_RANK и ROW_NUMBER в SQL Server.
Функции RANK, DENSE_RANK и ROW_NUMBER в SQL Server
- Функции RANK, DENSE_RANK и ROW_NUMBER используются для получения возрастающего целочисленного значения на основе упорядочения строк путем наложения предложения ORDER BY в операторе SELECT.
- Когда мы используем функции RANK, DENSE_RANK или ROW_NUMBER, условие ORDER BY является обязательным, а предложение PARTITION BY является необязательным.
- Когда мы используем предложение PARTITION BY, выбранные данные будут разбиты на разделы, а целочисленное значение сбрасывается до 1 при изменении раздела.

Давайте посмотрим на пример.
Для этого примера я создал таблицу «Сотрудники», в которую добавил три столбца: EMPID, Имя и Зарплата соответственно. Чтобы создать таблицу и столбец, скрипт приведен ниже.
Создание таблицы
- CREATE TABLE [dbo].[Сотрудник](
- [EMPID] [nvarchar](30) NOT NULL,
- [Имя] [nvarchar](150) NULL,
- [Зарплата] [деньги] NULL
- )
Вставьте некоторые данные в эту таблицу, скрипт следующим образом
- ВСТАВИТЬ [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) ЗНАЧЕНИЯ (‘EMP101’, ‘Вишал’, 15000)
- ВСТАВЬТЕ [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) ЗНАЧЕНИЯ (‘EMP102’, ‘Сэм’, 20000)
- INSERT [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) VALUES (‘EMP105’, ‘Ravi’, 10000)
- ВСТАВИТЬ [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) ЗНАЧЕНИЯ (‘EMP106’, ‘Махеш’, 18000)
Таблица создана и данные вставлены. Теперь давайте посмотрим, как ведут себя эти функции about RANK, DENSE_RANK и ROW_NUMBER.
Теперь давайте посмотрим, как ведут себя эти функции about RANK, DENSE_RANK и ROW_NUMBER.
Для этого мы можем написать оператор Select, как показано ниже.
- выберите EMPID, Имя,Зарплата,
- RANK() больше (упорядочить по описанию зарплаты) как _Rank,
- DENSE_RANK() более (порядок по зарплате Desc) как DenseRank ,
- ROW_NUMBER() больше (порядок по зарплате) как RowNumber от сотрудника
В приведенном ниже выводе вы видите, что функции RANK, DENSE_RANK и ROW_NUMBER дают одинаковые выходные данные и возвращают целочисленные значения на основе самой высокой заработной платы.
Я предполагаю, что вы знаете, что делают функции RANK, DENSE_RANK и ROW_NUMBER.
Функции RANK, DENSE_RANK и ROW_NUMBER
Теперь давайте посмотрим, в чем разница между этими функциями. Для этого нам нужно вставить в эту таблицу некую дублирующую зарплату.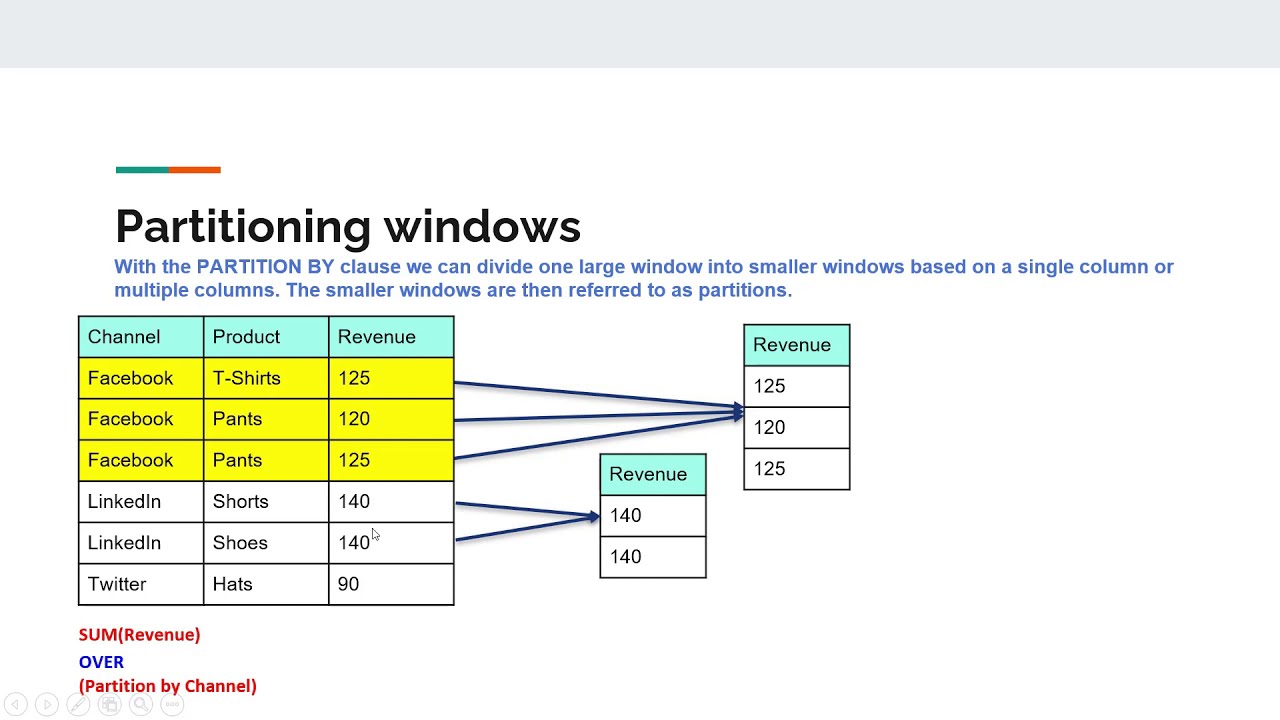 Сценарий ниже вставит еще несколько данных с той же зарплатой.
Сценарий ниже вставит еще несколько данных с той же зарплатой.
- ВСТАВЬТЕ [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) ЗНАЧЕНИЯ (‘EMP108’, ‘Рахул’, 20000)
- ВСТАВЬТЕ [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) ЗНАЧЕНИЯ (‘EMP109’, ‘menaka’, 15000)
- ВСТАВЬТЕ [dbo].[Сотрудник] ([EMPID], [Имя], [Зарплата]) ЗНАЧЕНИЯ (‘EMP111’, ‘akshay’, 20000)
Теперь вы можете увидеть таблицу, в которой есть несколько повторяющихся записей о зарплате.
Теперь мы можем увидеть разницу между функциями RANK, DENSE_RANK и ROW_NUMBER, выполнив тот же оператор SELECT, который мы выполняли ранее.
Здесь, на рисунке выше, вы можете видеть, что функция ROW_NUMBER не имеет никаких изменений. Он продолжает увеличивать целое число на единицу и не заботится о повторяющихся значениях.
В функции RANK, DENSE_RANK ищет повторяющиеся значения. Целочисленное значение увеличивается на единицу, но если в таблице присутствует одно и то же значение (Зарплата), то одно и то же целочисленное значение присваивается всем строкам с одинаковым значением (Зарплата), отмеченным небесно-голубым цветом.
В функции RANK следующая строка после повторяющихся значений (зарплата), отмеченная красным цветом, не будет давать целочисленное значение в качестве следующего ранга, а вместо этого пропускает эти ранги и дает следующий увеличенный ранг. В приведенном выше случае первые три значения имеют одинаковую заработную плату, поэтому им присваивается одинаковый ранг, но в следующей строке он дает 4, он пропускает два и три, поскольку первые три строки имеют одинаковые ранги.
В функции DENSE_RANK ни один ранг не будет пропущен. Это означает, что следующая строка после повторяющихся строк значения (зарплаты) будет иметь следующий ранг в последовательности.
Некоторое использование этих функций в режиме реального времени
- Используя функцию ROW_NUMBER, мы можем удалить повторяющиеся данные из таблицы. Для этого нам нужно вставить несколько повторяющихся записей в эту таблицу.
Чтобы удалить все повторяющиеся строки, нам нужно сохранить одну строку, а остальные строки нужно удалить. Для этого мы используем функцию ROW_NUMBER, так как это будет легко.
Для этого мы используем функцию ROW_NUMBER, так как это будет легко.
- с empCTE как
- (
- выберите *, ROW_NUMBER() over(раздел по EMPID порядку по EMPID) как rowno от Employee
- )
- удалить из empCTE, где rowno>1
В этом коде я написал оператор Select, чтобы получить ранг, и я сделал это как CTE. После этого я удаляю записи из CTE, где номер строки больше единицы, чтобы осталась одна запись.
Как видно на рисунке выше, повторяющиеся строки удаляются.
- Используя функцию RANK или DENSE_RANK, мы можем очень легко найти N-ю самую высокую зарплату, однако какую функцию использовать, зависит от того, что нам нужно.
Для этого обновим зарплату Рави так же, как у Сэма. Сценарий выглядит следующим образом:
- update Employee set Salary=20000, где EMPID=’EMP105′
Теперь у нас есть две записи о зарплате первой высоты. Давайте напишем оператор Select, чтобы найти вторую по величине зарплату, используя функцию RANK или DENSE_RANK, как показано ниже.
Давайте напишем оператор Select, чтобы найти вторую по величине зарплату, используя функцию RANK или DENSE_RANK, как показано ниже.
Как вы можете видеть выше, функция DENSE_RANK дает точный результат, а функция RANK не возвращает ни одной строки. Таким образом, мы можем использовать функцию DENSE_RANK, даже если зарплата одинаковая.
Rank и функция Dense_Rank в SQL Server
Вернуться к: Учебное пособие по SQL Server для начинающих и профессионалов
В этой статье я собираюсь обсудить Rank и функцию Dense_Rank в SQL Server с примерами. Пожалуйста, прочитайте нашу предыдущую статью, где мы обсуждали Функция Row_Number в SQL Server с примерами. В рамках этой статьи мы собираемся подробно обсудить следующие указатели.
- Понимание функций RANK и DENSE_RANK.
- В чем разница между функциями RANK и DENSE_RANK?
- Примеры в реальном времени с использованием функций RANK и DENSE_RANK в SQL Server.

Функция RANK и DENSE_RANK в SQL Server:
Обе функции RANK и DENSE_RANK были введены в SQL Server 2005. Опять же, обе эти функции используются для возврата последовательных чисел, начиная с 1, в зависимости от порядка строк, заданного предложение ORDER BY. Давайте сначала подробно разберем эти функции на некоторых примерах, а затем попробуем понять разницу между ними.
Примечание: Если у вас есть две записи с одинаковыми данными, обеим строкам будет присвоен одинаковый ранг.
Функция RANK в SQL Server:
Ниже приведен синтаксис для использования функции RANK в SQL Server. Как видите, как и в случае с функцией Row_Number, здесь предложение Partition By является необязательным, а предложение Order By — обязательным.
Предложение PARTITION BY в основном используется для разделения набора результатов на несколько групп. Поскольку это необязательно, и если вы не указали предложение PARTITION BY, функция RANK будет рассматривать весь результирующий набор как один раздел или группу. Предложение ORDER BY является обязательным, и это предложение используется для определения последовательности, в которой каждая строка будет назначать свой RANK, т.е. номер. Если на данный момент это неясно, не волнуйтесь, мы постараемся понять это на нескольких примерах.
Предложение ORDER BY является обязательным, и это предложение используется для определения последовательности, в которой каждая строка будет назначать свой RANK, т.е. номер. Если на данный момент это неясно, не волнуйтесь, мы постараемся понять это на нескольких примерах.
Примеры для понимания функций Rank и Dense_Rank в SQL Server:
Мы собираемся использовать следующую таблицу Employees, чтобы понять функции RANK и DENSE_RANK.
Используйте следующий сценарий SQL, чтобы создать и заполнить таблицу «Сотрудники» необходимыми тестовыми данными.
Создать таблицу сотрудников
(
Идентификатор INT ПЕРВИЧНЫЙ КЛЮЧ,
Имя VARCHAR(50),
Кафедра ВАРЧАР(10),
Зарплата ИНТ,
)
Идти
Вставьте значения сотрудников (1, «Джеймс», «ИТ», 80000)
Вставьте в значения сотрудников (2, «Тейлор», «ИТ», 80000)
Вставьте в значения сотрудников (3, «Памела», «HR», 50000)
Вставьте в значения сотрудников (4, «Сара», «HR», 40000)
Вставить в значения сотрудников (5, «Дэвид», «ИТ», 35000)
Вставьте в значения сотрудников (6, «Смит», «HR», 65000)
Вставьте в значения сотрудников (7, «Бен», «HR», 65000)
Вставить в значения сотрудников (8, «Стоукс», «ИТ», 45000)
Вставьте в значения сотрудников (9, 'Тейлор', 'Оно', 70000)
Вставить в значения сотрудников (10, «Джон», «ИТ», 68000)
Идти
Функция RANK без PARTITION
Давайте рассмотрим пример функции RANK в SQL Server без использования предложения PARTITION BY. Если мы не указали предложение PARTITION BY, то функция RANK будет рассматривать весь набор результатов как один раздел и давать последовательную нумерацию, начиная с 1, за исключением случаев, когда есть ничья.
Если мы не указали предложение PARTITION BY, то функция RANK будет рассматривать весь набор результатов как один раздел и давать последовательную нумерацию, начиная с 1, за исключением случаев, когда есть ничья.
Ниже приведен пример функции RANK без использования предложения PARTITION BY. Здесь мы используем пункт «Заказать по пункту» в столбце «Зарплата». Таким образом, он даст ранг на основе столбца «Зарплата».
ВЫБЕРИТЕ Имя, Отдел, Зарплата,
RANK() OVER (ORDER BY Salary DESC) AS [Rank]
FROM Сотрудники
Выполнив приведенный выше запрос, вы получите следующий вывод. Как вы можете видеть в приведенном ниже выводе, раздела не будет, и, следовательно, всем строкам присваиваются последовательные последовательности, начиная с 1, за исключением случаев, когда есть ничья, т. Е. Когда зарплата составляет 8000 и 65000, это дает одинаковый ранг ряды.
Функция ранжирования в SQL Server пропускает ранжирование(я) при равенстве. Как вы можете видеть в приведенном выше выводе, ранги 2 и 6 пропускаются, поскольку есть 2 строки в ранге 1, а также 2 строки в ранге 5. Третья строка получает ранг 3, а строка 7 th получает ранг 7.
Как вы можете видеть в приведенном выше выводе, ранги 2 и 6 пропускаются, поскольку есть 2 строки в ранге 1, а также 2 строки в ранге 5. Третья строка получает ранг 3, а строка 7 th получает ранг 7.
Функция RANK с предложением PARTITION BY в SQL Server:
Давайте посмотрим на пример функции RANK, использующей предложение PARTITION BY в SQL Server. Когда вы указываете предложение PARTITION BY, результирующий набор секционируется на основе столбца, который вы указываете в предложении Partition BY. Пожалуйста, взгляните на следующее изображение, чтобы понять это лучше. Как видите, мы указали отдел в предложении Partition By и зарплату в предложении Order By.
Как и в таблице «Сотрудники», у нас есть два отдела (IT и HR). Таким образом, пункт Partition By разделит все записи на два раздела или две группы. Один раздел предназначен для сотрудников ИТ-отдела, а другой — для сотрудников отдела кадров. Затем в каждом разделе данные сортируются по столбцу «Зарплата». Затем функция RANK присваивает целочисленный порядковый номер, начиная с 1, каждой записи в каждом разделе, за исключением случаев, когда имеется равенство. В случае ничьей он дает тот же ранг, а затем пропускает рейтинг.
Затем функция RANK присваивает целочисленный порядковый номер, начиная с 1, каждой записи в каждом разделе, за исключением случаев, когда имеется равенство. В случае ничьей он дает тот же ранг, а затем пропускает рейтинг.
Теперь выполните следующий код, и вы получите вывод, как мы обсуждали на предыдущем изображении.
ВЫБЕРИТЕ Имя, Отдел, Оклад,
РАНГ() НАД (
РАЗДЕЛ ПО ОТДЕЛУ
ЗАКАЗ ПО Окладу DESC) КАК [Звание]
ОТ Сотрудников
Итак, вкратце, Функция RANK Возвращает увеличивающееся уникальное число для каждой строки, начиная с 1, и для каждого раздела. При наличии дубликатов всем повторяющимся строкам присваивается один и тот же ранг, но следующая строка после повторяющихся строк будет иметь ранг, который был бы присвоен, если бы дубликатов не было. Таким образом, функция RANK пропускает ранжирование, если есть дубликаты.![]()
Функция DENSE_RANK в SQL Server:
Ниже приведен синтаксис для использования функции DENSE_RANK. Как видите, как и в случае с функцией RANK, здесь также предложение Partition By является необязательным, а предложение Order By — обязательным.
Предложение PARTITION BY является необязательным и используется для разделения набора результатов на несколько групп. Если вы не указали предложение PARTITION BY, функция DENSE_RANK будет рассматривать весь результирующий набор как один раздел. Предложение ORDER BY является обязательным и используется для определения последовательности, в которой каждой строке будет присвоен их DENSE_RANK, т. е. номер. Давайте разберемся, как использовать функцию DENSE_RANK в SQL Server, на нескольких примерах.
Функция DENSE_RANK без предложения PARTITION BY в SQL Server:
Давайте рассмотрим пример функции DENSE_RANK без использования предложения PARTITION BY. Как мы уже обсуждали, если мы не указали предложение PARTITION BY, то функция DENSE_RANK будет рассматривать весь набор результатов как один раздел и давать последовательную нумерацию, начиная с 1, за исключением случаев, когда есть ничья.
Ниже приведен пример функции DENSE_RANK без использования предложения PARTITION BY. Как и в случае с функцией RANK, здесь мы также применяем пункт Order By в столбце Salary. Таким образом, он даст ранг на основе столбца «Зарплата».
ВЫБЕРИТЕ Имя, Отдел, Зарплату,
DENSE_RANK() НАД (ЗАКАЗ ПО ЗАРПЛАТЕ DESC) КАК [Ранг]
ОТ Сотрудников
Когда вы выполните приведенный выше SQL-запрос, он даст вам следующий вывод . Как вы можете видеть в выводе, разделения не будет, и, следовательно, всем строкам присваиваются последовательные последовательности, начиная с 1, за исключением случаев, когда есть ничья, т. Е. Когда зарплата составляет 8000 и 65000, это дает одинаковый ранг обеим строкам. .
В отличие от функции ранжирования, функция DENSE_RANK не будет пропускать ранжирование(я) при равенстве результатов. Как видно из приведенного выше вывода, у нас есть две строки с рангом 1, а ранг следующей строки равен 3, и это единственная разница между функциями RANK и DENSE_RANK в SQL Server.
Функция DENSE_RANK с предложением PARTITION BY в SQL Server:
Давайте рассмотрим пример функции DENSE_RANK в SQL Server с использованием предложения PARTITION BY. Как и функция RANK, она также разделит результирующий набор на основе столбца, указанного в предложении PARTITION BY. Чтобы лучше понять это, пожалуйста, взгляните на следующую диаграмму. Как видите, мы указали столбец «Отдел» в предложении «Разделить по» и столбец «Зарплата» в предложении «Заказ по».
Поскольку у нас есть два отдела, т. е. ИТ и отдел кадров, пункт «Разделение по» разделит все данные на два раздела. Один раздел будет содержать сотрудников ИТ-отдела, а другой раздел будет содержать сотрудников отдела кадров. Затем в каждом разделе записи сортируются по столбцу «Зарплата». Затем функция DENSE_RANK применяется к каждой записи в каждом разделе и предоставляет порядковые номера, начинающиеся с 1, за исключением случаев совпадения. В случае ничьей он дает тот же ранг, не пропуская рейтинг.![]()
Теперь выполните приведенный ниже SQL-скрипт, и вы должны получить вывод, как мы обсуждали на предыдущем изображении.
Select Name, Department, зарплата,
Dense_rank () Over (
Раздел от отделения
Порядок по заработной плате Desc). 2 В чем разница между Функции Rank и Dense_Rank в SQL Server?
Как мы уже обсуждали, одно и единственное отличие заключается в том, что функция Rank пропускает ранжирование (я), если есть ничья, тогда как Dense_Rank не пропускает ранжирование.
Примеры функций RANK и DENSE_RANK в реальном времени в SQL Server:
Если вы посещаете любое собеседование, то почти на всех собеседованиях задают один известный вопрос, т.е. найдите n-ю самую высокую зарплату. Обе функции RANK и DENSE_RANK можно использовать для нахождения n-й самой высокой зарплаты. Однако, когда использовать какую функцию, это в основном зависит от того, что вы хотите делать, когда есть ничья. Давайте разберемся в этом на примере.
Давайте разберемся в этом на примере.
Предположим, что есть 2 сотрудника с ПЕРВОЙ самой высокой зарплатой, тогда может быть 2 бизнес-кейса следующим образом:
- Если ваше бизнес-требование состоит в том, чтобы не давать никаких результатов для ВТОРОЙ самой высокой зарплаты, тогда вы должны использовать функцию РАНГ .
- Если ваше бизнес-требование состоит в том, чтобы вернуть следующую зарплату после связанных строк как ВТОРУЮ по величине зарплату, вам нужно использовать функцию DENSE_RANK.
Получить 2 и наивысшую зарплату с помощью функции RANK:
Поскольку в нашей таблице «Сотрудники» у нас есть 2 сотрудника с ПЕРВОЙ самой высокой зарплатой (80000), функция Rank() не вернет никаких данных для ВТОРОЙ самой высокой зарплаты. Пожалуйста, выполните приведенный ниже SQL-скрипт и посмотрите результат.
-- Получить вторую высокую зарплату
С сотрудником CTE AS
(
SELECT Salary, RANK() OVER (ORDER BY Salary DESC) AS Rank_Salry
ОТ сотрудников
)
ВЫБЕРИТЕ ТОП-1 Зарплату ИЗ EmployeeCTE, ГДЕ Rank_Salry = 2
Получить 2 и Самая высокая зарплата с использованием функции DENSE_RANK:
Поскольку у нас есть 2 сотрудника с ПЕРВОЙ самой высокой зарплатой, т.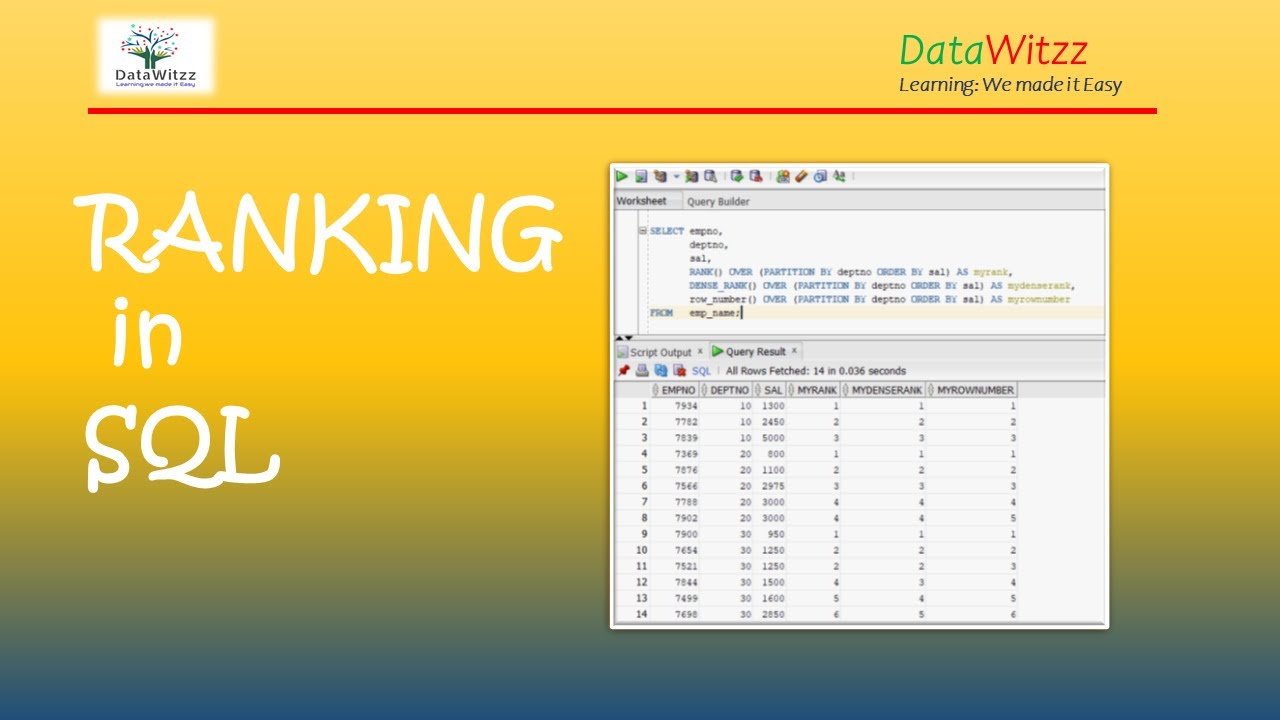 е. 80000, функция Dense_Rank() вернет следующую зарплату после связанных строк как ВТОРУЮ самую высокую зарплату, т.е. 70000. Пожалуйста, выполните следующий скрипт SQL и увидеть вывод.
е. 80000, функция Dense_Rank() вернет следующую зарплату после связанных строк как ВТОРУЮ самую высокую зарплату, т.е. 70000. Пожалуйста, выполните следующий скрипт SQL и увидеть вывод.
-- Получить вторую высокую зарплату
С сотрудником CTE AS
(
SELECT Salary, DENSE_RANK() OVER (ORDER BY Salary DESC) AS DenseRank_Salry
ОТ сотрудников
)
ВЫБЕРИТЕ ТОП-1 Зарплату ИЗ EmployeeCTE, ГДЕ DenseRank_Salry = 2
Пример поиска отдела с самой высокой зарплатой:
Вы также можете использовать функции RANK и DENSE_RANK в SQL Server, чтобы найти отдел с самой высокой зарплатой на n-м месте. Например, если кто-то попросит вас найти третью по величине зарплату в ИТ-отделе, вы можете использовать функцию DENSE_RANK, как показано ниже.
С Сотрудником CTE AS
(
ВЫБЕРИТЕ Заработная плата, отдел,
DENSE_RANK() OVER (РАЗДЕЛЕНИЕ ПО ОТДЕЛАМ ПО ЗАКАЗУ ПО ЗАРПЛАТЕ DESC)
AS Salary_Rank
ОТ сотрудников
)
ВЫБЕРИТЕ ТОП-1 Зарплату ИЗ EmployeeCTE, ГДЕ Salary_Rank = 3
И отдел = «ИТ»
Короче говоря, функция DENSE_RANK возвращает увеличивающееся уникальное число для каждой строки, начиная с 1, и для каждого раздела.