Sql server 2018 как установить: Руководство по установке SQL Server — SQL Server
Содержание
SQL Server 2017. Установка и начальная настройка.
В этой статье мы покажем наглядно как установить Microsoft SQL Server 2017 и как произвести первоначальную настройку. На примере будем рассматривать Microsoft SQL Server 2017 Standard, но Вы можете так же аналогично настроить другие редакции SQL Server.
1) Первое, что нужно сделать — это скачать сам дистрибутив. Скачать его можете с нашего сервера.
— Скачать Microsoft SQL Server 2017 Standard
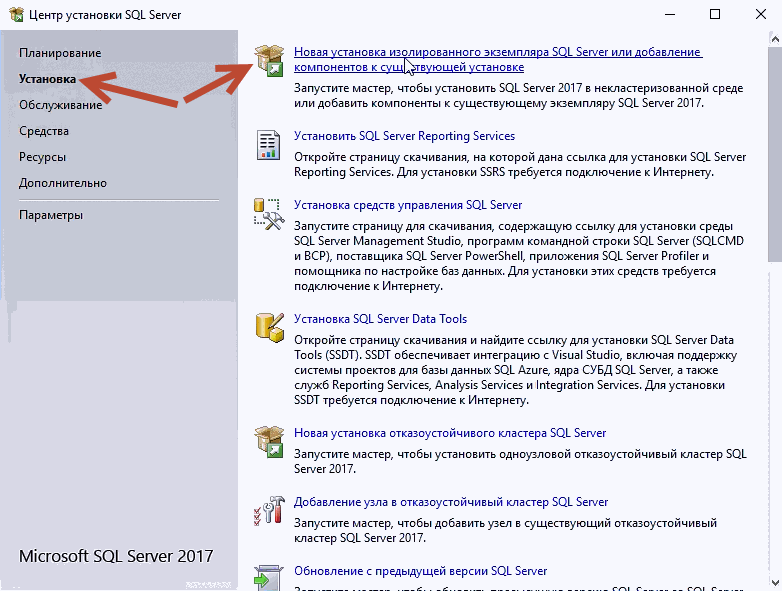
2) Открываете дистрибутив и запускаете установку. В меню слева нажимаете «Installation» => New SQL Server stand-alone installation
3) В новом открывшемся окне Вас запросят выбрать бесплатную версию установки, к примеру «Ознакомительныя», т.е Evaluation, либо если у Вас есть ключ активации, для SQL Server 2017 Standard, или любой другой полнофункциональный ключ, то вводите его.
При установке SQL Server 2017 сам предложит Вам пробный ключ, он аналогичен Evaluation — PHDV4-3VJWD-N7JVP-FGPKY-XBV89, для теста мы будем использовать его. (Внимание: Пробная версия такого ключа работает только 180 дней, далее без действующего ключа активации приложение закрывает свой функционал. Приобрести полную версию ключа активации Microsoft SQL Server 2017 Standard можете в нашем каталоге на следующей странице Доставка ключа на Вашу электронную почту.) После ввода ключа жмем «Next».
(Внимание: Пробная версия такого ключа работает только 180 дней, далее без действующего ключа активации приложение закрывает свой функционал. Приобрести полную версию ключа активации Microsoft SQL Server 2017 Standard можете в нашем каталоге на следующей странице Доставка ключа на Вашу электронную почту.) После ввода ключа жмем «Next».
4) Соглашаемся с лицензионным соглашением.
5) Соглашаемся на загрузку обновлений при наличии доступа в интернет. (либо можете отказаться, тут опционально)
6) В следующем окне нам предлагают выбрать компоненты MS SQL Server, которые Вы хотите установить. Выбираете нужные компоненты под Ваши задачи и идем далее.
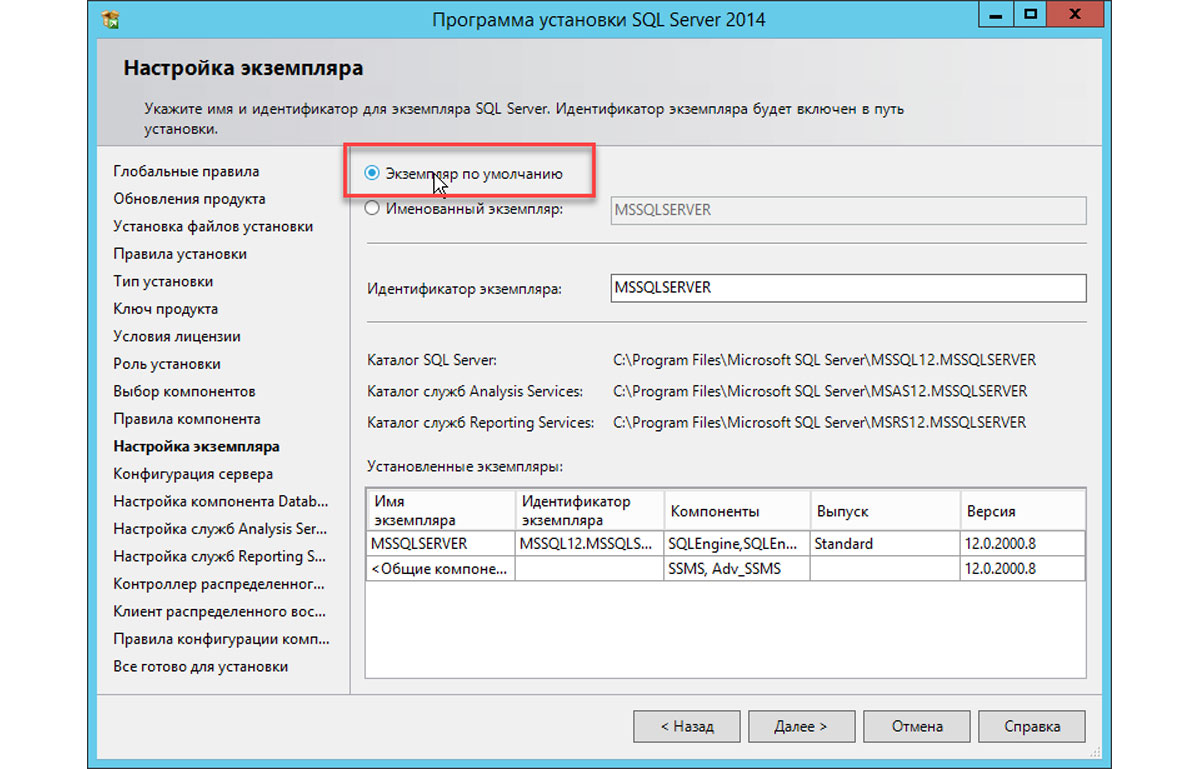
7) Теперь нужно установить экземпляр. Если у на Вашем сервере, или виртуальной машине еще не установлен никакой SQL Server, то можете выбрать «Default instance», если уже SQL Server был установлен ранее и вы поверх его ставите еще один экземпляр, то Вам нужно выбрать «Named instance» и дать ему имя.
8) В следующем окне нам предлагают выбрать сервисные аккаунты, это те учетные записи из под которых будут стартовать службы SQL Server Agent, SQL Server Database, SQL Server Browser. По умолчанию используются персонализированные учетные записи.
Но вы можете выбрать учетную запись Вашего домена, если Ваша сеть работает на домене (сервер включен в домен).
Не забываем выбрать то, как будут стартовать службы, автоматически, в ручную, либо вообще будут отключены, если они не нужны под Ваши задачи.
.
Хотим отметить, что выбранные учетные записи желательно не должны являться «администраторами» SQL Server.
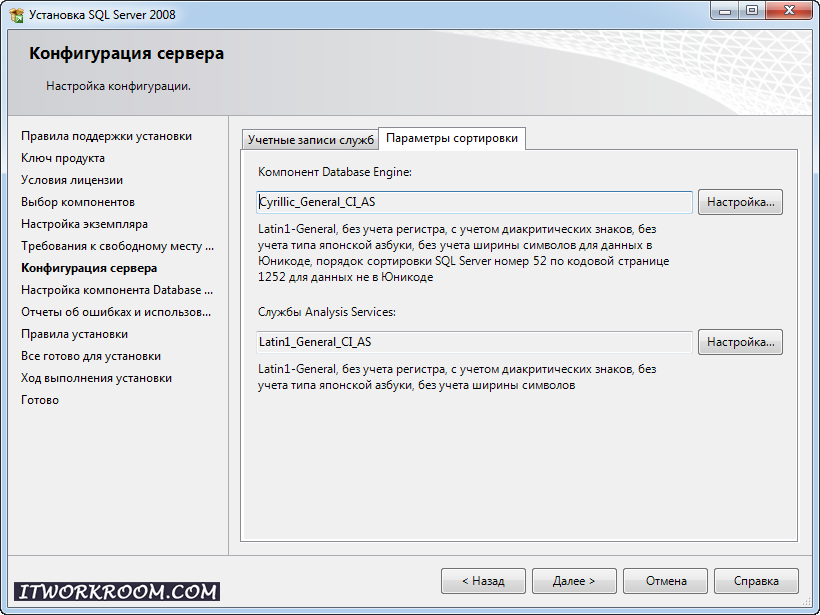
В том же окне, переходим во вкладку Collation.
Collation — это настройка таблицы кодировок. А так же, выполнять сортировку, как учитывать верхний и нижний регистр, как реагировать на символы, и т.п.
9) Следующим пунктом нам предлагают выбрать серверную конфигурацию. Здесь предлагают выбрать, что вы сможете подключиться только с Windows логинами к SQL Серверу, либо Mixed, что вы сможете еще подключиться внутренними учетными записями SQL Server, создав их в SQL Server.
После на данном этапе имеет смысл нажать кнопку «Add Current User» и добавить текущего пользователя, а так же Вы можете добавить учетную запись Вашего домена.
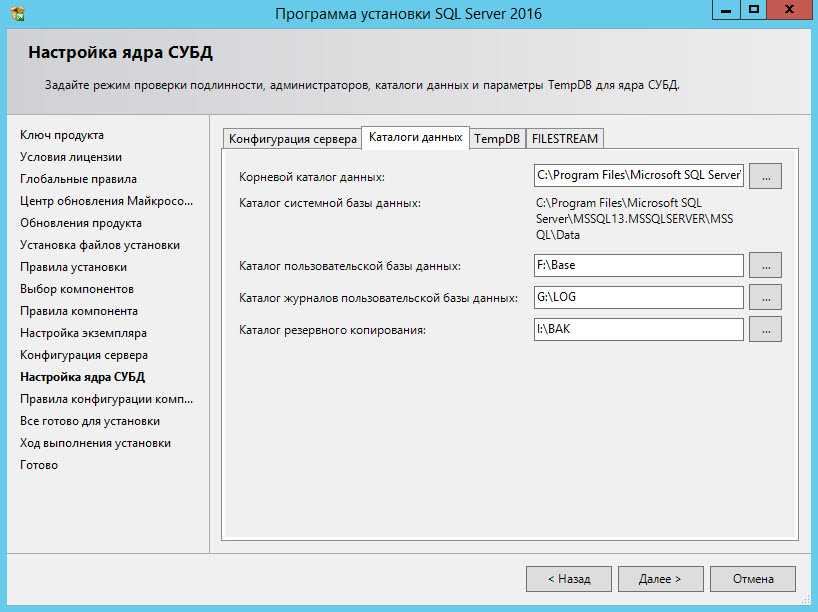
В том же окне переходим во вкладку «Data Directories». В этом пункте Вы можете выбрать Root директорию, директорию куда будут по умолчанию создаваться базы данных, директорию лог файлов и директорию для бекапов. Соответственно желательно, чтобы все директории были на разных жестких дисках.
В следующей вкладке переходим к настройках базы TempDB. Это системная база, которая используется для хранения временных объектов.
Количество файлов прописано по умолчанию от кол-ва ядер.
Инициализиционный размер в мегабайтах — здесь имеет смысл прибавить размер хотя бы до 16, или 32 мб.
Autogrowth MB — Это то кол-во мегабайт, которое будет приращиваться, если файл будет заполнен на 100%. Выбираем на свое усмотрение, в зависимости от Ваших задач и размер БД, по умолчанию средний размер 64мб, но лучше, чтобы было не более 1гб, дабы не страдала производительность. Если не знаете какая будет нагрузка на Вашу базу, то оставьте как есть.
Если не знаете какая будет нагрузка на Вашу базу, то оставьте как есть.
Директория для временных файлов в идеале должна быть отдельным диском.
Следующая вкладка это настройки Filestream — это настройка, которая позволяет хранить файлы в файловой системе NTFS, она может быть как активирована, так и нет, опционально.
10) В разделе Ready to Install Вы можете наблюдать все те настройки, которые ранее прописали.
Нажимаем Next и ждем пока все установится.
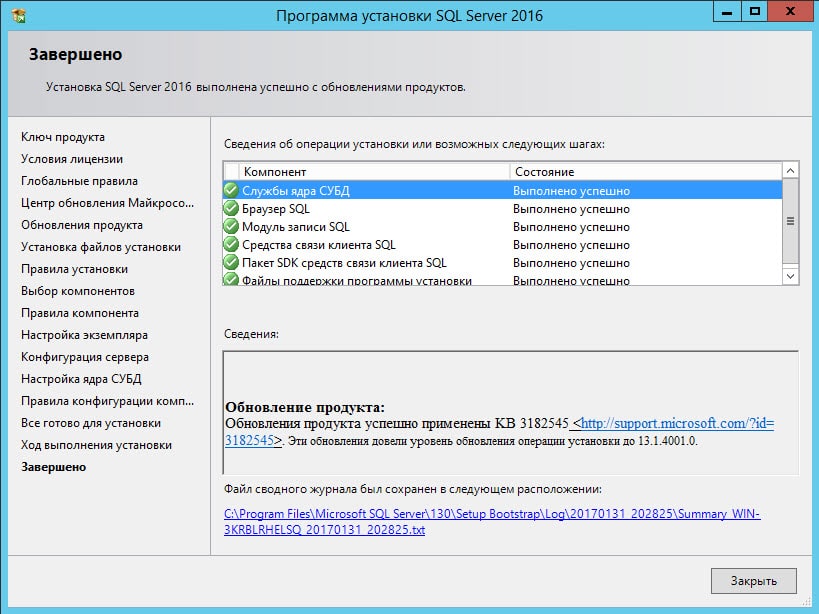
Если все установилось успешно, то в конце все компоненты будут «Succeeded».
Interpos | Помощь | Установка системы
Краткое содержание
- Установка новой базы данных
- Подключение к существующей базе данных
- Использование внешнего подключения к базе данных (БЫСТРАЯ УСТАНОВКА)
После того, как будет установлена система Interpos, или один из дополнительных модулей, необходимо запустить исполняемый файл необходимого модуля и дождаться отображения окна «Мастера установки системы Interpos». Окно мастера установки системы, представлено на рисунке 1.
Окно мастера установки системы, представлено на рисунке 1.
Рисунок 1 – Мастер установки системы Interpos
После нажатия на кнопку «Далее», будет открыто окно выбора действия. Данное окно представлено на рисунке 2. В открывшемся окне необходимо выбрать одно из действий для осуществления подключения к базе данных. Возможны 3 способа подключения:
- Установка новой базы данных
- Подключение к существующей базе данных
- Использование внешнего подключения к базе данных
Рисунок 2 – Окно выбора действия
При установке переключателя в положение «Установка новой базы данных», будет осуществлена установка базы данных на локальном сервере SQL Server.
При установке переключателя в положение «Подключение к существующей базе данных», будет осуществлено подключение к существующей базе данных на сервере.
При установке переключателя в положение «Использовать внешнее подключение к базе данных», будет осуществлено подключение к базе данных на сервере Interpos.
Прежде чем приступить установке базы данных системы Interpos рассмотрим основные способы взаимодействия системы и базы данных.
Использование локальной базы данных позволяет осуществлять работу без использования Интернета. Данный способ будет предпочтителен для организаций, в которых имеются проблемы с обеспечением бесперебойного соединения с сетью Интернет, а также для организаций имеющих 3 и более точек продаж в рамках одной организации. Основная особенность данного способа – это установка и настройка сервера SQL Server для работы с локальной базой.
Использование базы данных в облаке позволяет настроить работу с программой в течение 15 минут. Данный способ подключения предпочтителен для организаций имеющих хорошее и стабильное подключение к сети Internet, а также для организаций, осуществляющих розничную торговлю и имеющих 1 точку продаж. Основная особенность данного способа подключения — это обеспечение бесперебойной работы сети.
После того как будет выбран один из способов подключения к базе данных, необходимо выбрать соответствующий переключатель и нажать на кнопку «Далее».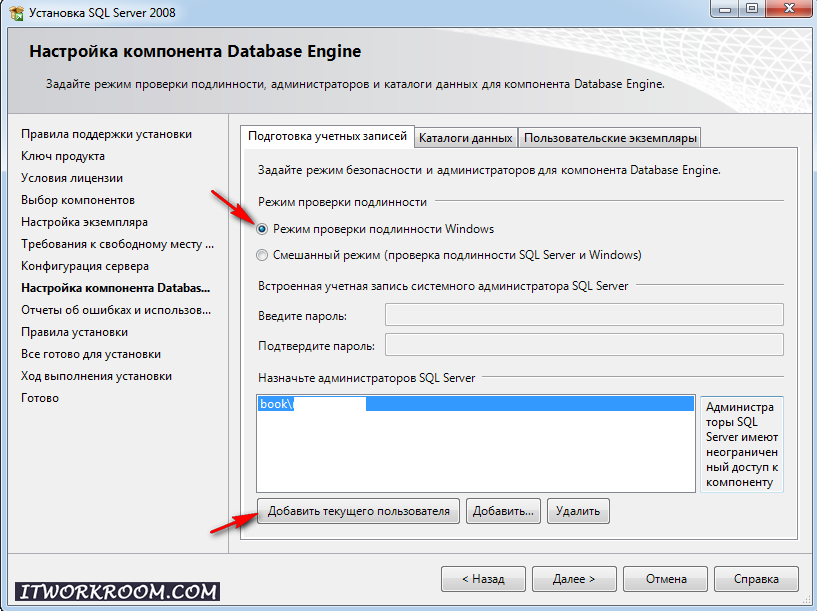
Установка новой базы данных
В случае выбора значения «Установка новой базы данных», будет открыто окно, представленное на рисунке 3. В данном окне необходимо ввести следующие значения: «Сервер» — IP-адрес или наименование экземпляра установленного SQL Server; «Пользователь» — имя пользователя SQL Server, под которым будет осуществляться соединение с базой данных; «Пароль» — пароль пользователя SQL Server под которым будет осуществляться соединение с базой данных;
Рисунок 3 – Окно ввода подключения к базе данных
После того, как значения будут заполнены, нажмите на кнопку «Далее». В случае успешного соединения с сервером, будет открыто окно, представленное на рисунке 4, в котором необходимо ввести значение параметра «База данных» — имя новой базы данных, по умолчанию равное «Interpos». После того, как данный параметр будет заполнен, нажмите на кнопку «Далее».
Рисунок 4 – Окно ввода наименования новой базы данных
В случае успешного выполнения операции, база данных будет создана и будет выдано сообщение об успехе выполненной операции. Нажмите на кнопку «Завершить» для выхода из мастера установки системы и перейти к началу работы.
Нажмите на кнопку «Завершить» для выхода из мастера установки системы и перейти к началу работы.
Подключение к существующей базе данных
В случае выбора значения «Подключение к существующей базе данных», будет открыто окно, представленное на рисунке 5. Обращаем Ваше внимание, что подключение к существующей базе данных необходимо осуществлять для тех модулей системы Interpos, для которых необходима работа в рамках одной организации.
Рисунок 5 – Окно ввода данных для подключения к существующей базе данных
В данном окне необходимо ввести значения параметров: «Сервер» — IP-адрес или наименование экземпляра установленного SQL Server где расположена база данных; «Пользователь» — имя пользователя SQL Server, под которым будет осуществляться соединение с базой данных; «Пароль» — пароль пользователя SQL Server под которым будет осуществляться соединение с базой данных; «База данных» — имя базы данных с которой необходимо ввести соединение.
Если значение параметра «База данных» будет не известно, Вы можете выбрать данное значение из списка. Для этого заполните параметры «Сервер», «Пользователь», «Пароль» и нажмите на кнопку «Получить список». В случае успешного выполнения операции, в поле «Базы данных» будет отображен перечень всех баз данных на указанном сервере.
Для этого заполните параметры «Сервер», «Пользователь», «Пароль» и нажмите на кнопку «Получить список». В случае успешного выполнения операции, в поле «Базы данных» будет отображен перечень всех баз данных на указанном сервере.
После того, как все параметры будут заполнены, нажмите на кнопку «Подключиться». В случае успешного выполнения операции будет осуществлено подключение к существующей базе данных и Вы можете приступить к работе.
Использование внешнего подключения к базе данных
В случае выбора значения «Использовать внешнее подключение к базе данных», будет открыто окно, представленное на рисунке 6, в котором необходимо ввести значение параметра «Ключ организации». Значение данного параметра Вы можете получить в настройках Вашей организации в личном кабинете пользователя системы Interpos. Личный кабинет пользователя расположен по адресу http://account.interpos.pro. Для осуществления подключения к личному кабинету, а также создать и настроить организацию для работы, воспользуйтесь руководством пользователя, расположенным в Электронной документации в разделе «Interpos Кабинет».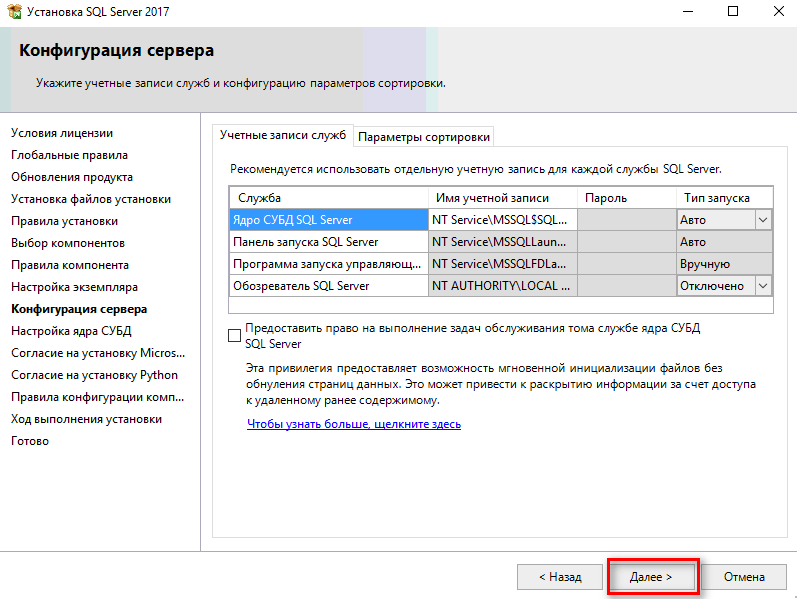
Рисунок 6 – Окно ввода информации по ключу кабинета
После заполнения ключа кабинета, нажмите на кнопку «Подключиться». В случае успешного выполнения операции, настройка системы будет завершена и Вы можете приступить к работе.
Дата создания: 03.09.2020 в 15:38:45
Архитектура SQL Server (объяснение)
MS SQL Server представляет собой архитектуру клиент-сервер. Процесс MS SQL Server начинается с того, что клиентское приложение отправляет запрос. SQL Server принимает, обрабатывает и отвечает на запрос обработанными данными. Давайте подробно обсудим всю архитектуру, показанную ниже:
Как показано на диаграмме ниже, в архитектуре SQL Server есть три основных компонента:
- Уровень протокола
- Реляционная машина
- Механизм хранения
Давайте подробно обсудим все три вышеуказанных основных модуля. В этом уроке вы узнаете.
- Уровень протокола — SNI
- Общая память
- TCP/IP
- Именованные каналы
- Что такое TDS?
- Реляционная машина
- Парсер CMD
- Оптимизатор
- Исполнитель запросов
- Механизм хранения
- Типы файлов
- Метод доступа
- Менеджер буфера
- Кэш планов
- Анализ данных: буферный кэш и хранилище данных
- Менеджер транзакций
Уровень протокола – SNI
УРОВЕНЬ ПРОТОКОЛА MS SQL SERVER поддерживает 3 типа архитектуры клиент-сервер.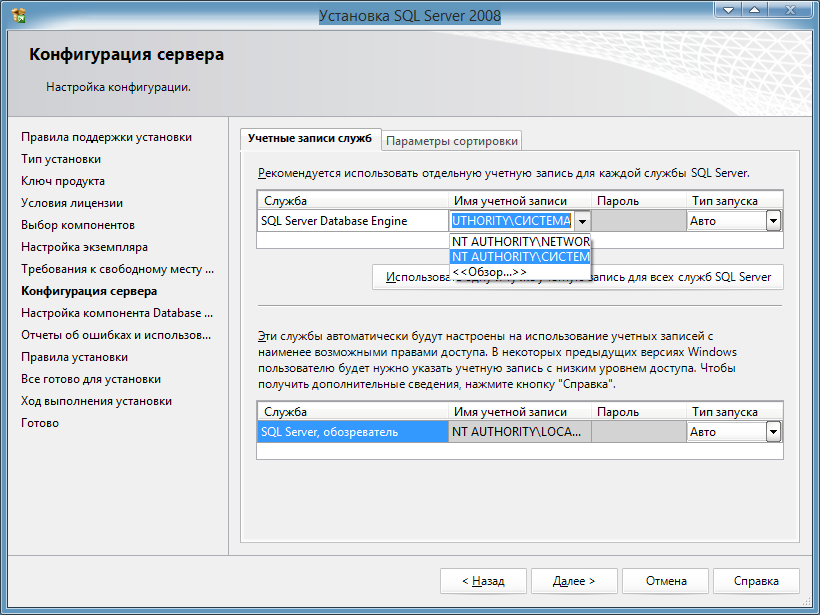 Мы начнем с « Three Type of Client Server Architecture» , которую поддерживает MS SQL Server.
Мы начнем с « Three Type of Client Server Architecture» , которую поддерживает MS SQL Server.
Общая память
Давайте еще раз рассмотрим сценарий раннего утреннего разговора.
МАМА и ТОМ – Здесь Том и его Мама были в одном и том же логическом месте, то есть у себя дома. Том смог попросить кофе, а мама смогла подать его горячим.
СЕРВЕР MS SQL – Здесь Сервер MS SQL предоставляет ПРОТОКОЛ ОБЩЕЙ ПАМЯТИ . Здесь КЛИЕНТ и сервер MS SQL работают на одной машине. Оба могут обмениваться данными по протоколу Shared Memory.
Аналогия: Позволяет отображать объекты в двух приведенных выше сценариях. Мы можем легко сопоставить Тома с клиентом, маму с SQL-сервером, дом с машиной и вербальное общение с протоколом общей памяти.
Из отдела настройки и установки:
Для подключения к локальной базе данных — в SQL Management Studio параметр «Имя сервера» может быть
«. »
»
«localhost»
«127.0.0.1»
«Машина\Экземпляр»
TCP/IP
Вечером у Тома праздничное настроение. Он хочет кофе, заказанный в известной кофейне. Кофейня находится в 10 км от его дома.
Здесь Том и Старбак находятся в разных физических местах. Том дома и Старбакс на оживленном рынке. Они общаются через сотовую сеть. Точно так же MS SQL SERVER обеспечивает возможность взаимодействия по протоколу TCP/IP, где CLIENT и MS SQL Server удалены друг от друга и установлены на отдельной машине.
Аналогия: Позволяет отображать объекты в двух приведенных выше сценариях. Мы можем легко сопоставить Tom с клиентом, Starbuck с SQL-сервером, Home/Market Place с удаленным местоположением и, наконец, сотовую сеть с протоколом TCP/IP.
Примечания из отдела настройки/установки:
- В SQL Management Studio — для подключения через TCP\IP параметр «Имя сервера» должен быть «Машина\Экземпляр сервера».

- SQL-сервер использует порт 1433 в TCP/IP.

Named Pipes
Теперь, наконец, ночью Том захотел выпить светло-зеленого чая, который очень хорошо готовит ее соседка Сьерра.
Здесь Том и его Сосед , Сьерра, находятся в одном и том же физическом местоположении, являясь соседями друг друга. Они общаются через внутреннюю сеть . Аналогично, MS SQL SERVER обеспечивает возможность взаимодействия по протоколу Named Pipe . Здесь КЛИЕНТ и MS SQL SERVER подключен через LAN .
Аналогия: Позволяет отображать сущности в двух приведенных выше сценариях. Мы можем легко сопоставить Tom с Client, Sierra с SQL-сервером, Neighbor с LAN и, наконец, Intra network с протоколом Named Pipe.
Примечания отдела настройки/установки:
- Для подключения через именованный канал. Этот параметр отключен по умолчанию и должен быть включен диспетчером конфигурации SQL.
 Этот параметр отключен по умолчанию и должен быть включен диспетчером конфигурации SQL.
Этот параметр отключен по умолчанию и должен быть включен диспетчером конфигурации SQL.Что такое TDS?
Теперь, когда мы знаем, что существует три типа клиент-серверной архитектуры, давайте взглянем на TDS:
- TDS означает поток табличных данных.
- Все 3 протокола используют пакеты TDS. TDS инкапсулируется в сетевые пакеты. Это позволяет передавать данные с клиентского компьютера на серверный компьютер.
- TDS была впервые разработана Sybase и теперь принадлежит Microsoft
Реляционный механизм
Реляционный механизм также известен как процессор запросов. В нем есть компоненты SQL Server, которые определяют, что именно должен делать запрос и как это лучше всего сделать. Он отвечает за выполнение пользовательских запросов, запрашивая данные у механизма хранения и обрабатывая возвращаемые результаты.
Как показано на архитектурной схеме, существует 3 основных компонента реляционной машины. Давайте подробно изучим компоненты:
Давайте подробно изучим компоненты:
CMD Parser
Данные, полученные от уровня протокола, затем передаются в реляционный механизм. «Синтаксический анализатор CMD» — это первый компонент реляционного механизма, который получает данные запроса. Основная задача CMD Parser — проверить запрос на наличие синтаксической и семантической ошибки . Наконец, генерирует дерево запросов . Обсудим подробно.
Проверка синтаксиса:
- Как и любой другой язык программирования, MS SQL также имеет предопределенный набор ключевых слов. Кроме того, SQL Server имеет собственную грамматику, которую понимает SQL Server.
- SELECT, INSERT, UPDATE и многие другие принадлежат предопределенным спискам ключевых слов MS SQL.
- CMD Parser выполняет синтаксическую проверку. Если пользовательский ввод не соответствует этому синтаксису или правилам грамматики языка, он возвращает ошибку.

Пример: Допустим, русский зашел в японский ресторан. Он заказывает фаст-фуд на русском языке. К сожалению, официант понимает только по-японски. Какой будет самый очевидный результат?
Ответ — официант не может дальше обрабатывать заказ.
Не должно быть никаких отклонений в грамматике или языке, который принимает SQL-сервер. Если они есть, SQL-сервер не сможет их обработать и, следовательно, вернет сообщение об ошибке.
Мы узнаем больше о запросах MS SQL в следующих руководствах. Тем не менее, рассмотрим ниже самый простой синтаксис запроса как
SELECT * from;
Теперь, чтобы получить представление о том, что делает синтаксис, скажем, если пользователь выполняет базовый запрос, как показано ниже:
SELECR * from
Обратите внимание, что вместо «SELECT» пользователь набрал «SELECR».
Результат: Парсер CMD проанализирует этот оператор и выдаст сообщение об ошибке. Поскольку «SELECR» не соответствует предварительно определенному имени ключевого слова и грамматике. Здесь CMD Parser ожидал «SELECT».
Поскольку «SELECR» не соответствует предварительно определенному имени ключевого слова и грамматике. Здесь CMD Parser ожидал «SELECT».
Семантическая проверка:
- Выполняется нормализатором .
- В своей простейшей форме он проверяет, существуют ли имя запрашиваемого столбца и таблицы в схеме. И если он существует, привяжите его к Query. Это также известно как Binding .
- Сложность увеличивается, когда пользовательские запросы содержат VIEW. Нормализатор выполняет замену внутренне сохраненным определением представления и многое другое.
Давайте разберемся с этим на примере ниже –
SELECT * from USER_ID
Результат: Парсер CMD проанализирует этот оператор для семантической проверки. Парсер выдаст сообщение об ошибке, так как Normalizer не найдет запрошенную таблицу (USER_ID), так как она не существует.
Создать дерево запросов:
- На этом шаге создается другое дерево выполнения, в котором может выполняться запрос.
- Обратите внимание, что все разные деревья имеют одинаковый желаемый результат.
Оптимизатор
Работа оптимизатора заключается в создании плана выполнения запроса пользователя. Это план, который определит, как будет выполняться пользовательский запрос.
Обратите внимание, что не все запросы оптимизированы. Оптимизация выполняется для команд DML (язык модификации данных), таких как SELECT, INSERT, DELETE и UPDATE. Такие запросы сначала помечаются, а затем отправляются оптимизатору. Команды DDL, такие как CREATE и ALTER, не оптимизированы, а компилируются во внутреннюю форму. Стоимость запроса рассчитывается на основе таких факторов, как использование ЦП, использование памяти и потребности ввода/вывода.
Роль оптимизатора состоит в том, чтобы найти самый дешевый, а не самый лучший, рентабельный план выполнения.
Прежде чем мы перейдем к более техническим деталям оптимизатора, рассмотрим ниже пример из реальной жизни:
Пример:
Допустим, вы хотите открыть счет в онлайн-банке. Вы уже знаете об одном банке, в котором открытие счета занимает максимум 2 дня. Но у вас также есть список из 20 других банков, которые могут занять или не занять менее 2 дней. Вы можете начать взаимодействие с этими банками, чтобы определить, какие банки занимают менее 2 дней. Теперь вы можете не найти банк, который занимает менее 2 дней, и есть дополнительные потери времени из-за самой поисковой активности. Лучше было бы открыть счет в самом первом банке.
Вы уже знаете об одном банке, в котором открытие счета занимает максимум 2 дня. Но у вас также есть список из 20 других банков, которые могут занять или не занять менее 2 дней. Вы можете начать взаимодействие с этими банками, чтобы определить, какие банки занимают менее 2 дней. Теперь вы можете не найти банк, который занимает менее 2 дней, и есть дополнительные потери времени из-за самой поисковой активности. Лучше было бы открыть счет в самом первом банке.
Вывод: Важнее выбирать с умом. Если быть точным, выбирайте, какой вариант лучше, а не самый дешевый.
Точно так же MS SQL Optimizer работает со встроенными исчерпывающими/эвристическими алгоритмами. Цель состоит в том, чтобы свести к минимуму время выполнения запроса. Все алгоритмы оптимизатора являются собственностью Microsoft и являются секретом. Хотя , ниже приведены высокоуровневые шаги, выполняемые оптимизатором MS SQL. Поиски оптимизации проходят в три этапа, как показано на диаграмме ниже:
Поиски оптимизации проходят в три этапа, как показано на диаграмме ниже:
Фаза 0: Поиск тривиального плана:
- Также известна как Этап предварительной оптимизации .
- В некоторых случаях может быть только один практичный, работающий план, известный как тривиальный план. Нет необходимости создавать оптимизированный план. Причина в том, что поиск большего количества результатов приведет к нахождению того же плана выполнения во время выполнения. Это также с дополнительными затратами на поиск оптимизированного плана, который вообще не требовался.
- Если Тривиальный план не найден, то 1 st Фаза начинается.
Этап 1: Поиск планов обработки транзакций
- Сюда входит поиск Простой и Сложный план .
- Простой план поиска: прошлые данные столбца и индекса, задействованные в запросе, будут использоваться для статистического анализа. Обычно это состоит, но не ограничивается одним индексом на таблицу.
- Тем не менее, если простой план не найден, то ищется более сложный план. Он включает несколько индексов для каждой таблицы.

Фаза 2: Параллельная обработка и оптимизация.
- Если ни одна из вышеперечисленных стратегий не работает, оптимизатор ищет возможности параллельной обработки. Это зависит от возможностей обработки и конфигурации Машины.
- Если это по-прежнему невозможно, начинается финальная фаза оптимизации. Теперь конечной целью оптимизации является поиск всех других возможных вариантов выполнения запроса наилучшим образом. Заключительный этап оптимизации. Алгоритмы являются собственностью Microsoft.
Исполнитель запросов
Исполнитель запросов вызывает Метод доступа. Предоставляет план выполнения логики выборки данных, необходимой для выполнения. После получения данных от Storage Engine результат публикуется на уровне протокола. Наконец, данные отправляются конечному пользователю.
Storage Engine
Работа Storage Engine заключается в хранении данных в системе хранения, такой как Disk или SAN, и извлечении данных при необходимости. Прежде чем мы углубимся в механизм хранения, давайте посмотрим, как данные хранятся в Доступны типы файлов базы данных и .
Файл данных и размер:
Файл данных физически хранит данные в виде страниц данных, причем каждая страница данных имеет размер 8 КБ, образуя наименьшую единицу хранения в SQL Server. Эти страницы данных логически сгруппированы в экстенты. Никакому объекту не назначается страница в SQL Server.
Обслуживание объекта осуществляется через экстенты. На странице есть раздел под названием «Заголовок страницы» размером 96 байтов, содержащих метаданные о странице, такие как тип страницы, номер страницы, размер используемого пространства, размер свободного пространства и указатель на следующую страницу и предыдущую страницу и т. д.
д.
- Каждая база данных содержит один первичный файл.
- Здесь хранятся все важные данные, связанные с таблицами, представлениями, триггерами и т. д.
- Расширение . мдф обычно но может быть любого удлинения.
- Вторичный файл
- База данных может содержать или не содержать несколько вторичных файлов.
- Это необязательный параметр, содержащий пользовательские данные.
- Расширение . обычно ndf , но может иметь любое расширение.
- Файл журнала
- Также известен как журнал упреждающей записи.
- Расширение . лдф
- Используется для управления транзакциями.
- Используется для восстановления после любых нежелательных экземпляров. Выполните важную задачу отката к незафиксированным транзакциям.

Storage Engine состоит из 3 компонентов; давайте рассмотрим их подробно.
Метод доступа
Действует как интерфейс между исполнителем запросов и диспетчером буферов/журналами транзакций.
Метод доступа сам по себе не выполняет никаких действий.
Первое действие — определить, является ли запрос:
- Оператор выбора (DDL)
- Оператор без выбора (DDL и DML)
В зависимости от результата метод доступа выполняет следующие шаги:
- Если запрос представляет собой DDL , оператор SELECT, запрос передается диспетчеру буфера для дальнейшей обработки.
- И если запрос, если DDL, оператор NON-SELECT , запрос передается диспетчеру транзакций. В основном это включает оператор UPDATE.
Менеджер буфера
Менеджер буфера управляет основными функциями следующих модулей:
- Кэш планов
- Анализ данных: буферный кеш и хранилище данных
- Грязная страница
В этом разделе мы изучим план, буфер и кэш данных. Мы расскажем о грязных страницах в разделе «Транзакции».
Мы расскажем о грязных страницах в разделе «Транзакции».
Кэш планов
- Существующий план запроса: Менеджер буфера проверяет наличие плана выполнения в сохраненном кэше планов. Если да, то используется кэш плана запроса и связанный с ним кэш данных.
- Первый план кэширования: Откуда берется существующий кэш плана? Если выполняется первый план выполнения запроса и он сложный, имеет смысл сохранить его в кэше плана. Это обеспечит более быструю доступность, когда SQL-сервер в следующий раз получит тот же запрос. Таким образом, это не что иное, как сам запрос, который План выполнения сохраняется, если он запускается в первый раз.
Анализ данных: буферный кэш и хранилище данных
Менеджер буфера обеспечивает доступ к необходимым данным. Ниже возможны два подхода в зависимости от того, существуют ли данные в кэше данных или нет:
Буферный кэш — Мягкий анализ:
Менеджер буфера ищет данные в буфере в кэше данных. Если они присутствуют, то эти данные используются исполнителем запросов. Это повышает производительность, поскольку количество операций ввода-вывода уменьшается при выборке данных из кэша по сравнению с выборкой данных из хранилища данных.
Если они присутствуют, то эти данные используются исполнителем запросов. Это повышает производительность, поскольку количество операций ввода-вывода уменьшается при выборке данных из кэша по сравнению с выборкой данных из хранилища данных.
Хранилище данных — Жесткий анализ:
Если данные отсутствуют в диспетчере буферов, поиск данных выполняется в хранилище данных. Если также сохраняет данные в кэше данных для будущего использования.
Грязная страница
Сохраняется как логика обработки диспетчера транзакций. Подробно мы узнаем в разделе «Менеджер транзакций».
Диспетчер транзакций
Диспетчер транзакций вызывается, когда метод доступа определяет, что запрос является оператором без выбора.
Диспетчер журналов
- Диспетчер журналов отслеживает все обновления, выполненные в системе, с помощью журналов в журналах транзакций.
- Журналы имеют Регистрирует порядковый номер транзакции с идентификатором транзакции и записью модификации данных .
- Используется для отслеживания подтвержденной транзакции и отката транзакции .
Диспетчер блокировки
- Во время транзакции связанные данные в хранилище данных находятся в состоянии блокировки. Этот процесс обрабатывается диспетчером блокировки.
- Этот процесс обеспечивает согласованность данных и изоляцию . Также известны как свойства ACID.
Процесс выполнения
- Диспетчер журналов начинает запись в журнал, и Диспетчер блокировки блокирует связанные данные.
- Копия данных хранится в кэше буфера.
- Копия данных, которые должны быть обновлены, сохраняется в буфере журнала, и все события обновляют данные в буфере данных.
- Страницы, на которых хранятся данные, также известны как Грязные страницы .
- Регистрация контрольной точки и упреждающей записи: Этот процесс запускается и помечает все страницы от грязных страниц до диска, но страница остается в кэше. Частота составляет примерно 1 запуск в минуту. Но страница сначала помещается на страницу данных файла журнала из журнала буфера. Это известно как Упреждающая запись в журнал.
- Ленивый писатель: Грязная страница может оставаться в памяти. Когда SQL-сервер наблюдает огромную нагрузку и для новой транзакции требуется буферная память, он освобождает грязные страницы из кеша. Работает на LRU — Наименее использовавшийся алгоритм очистки страницы из пула буферов на диск.
 Частота составляет примерно 1 запуск в минуту. Но страница сначала помещается на страницу данных файла журнала из журнала буфера. Это известно как Упреждающая запись в журнал.
Частота составляет примерно 1 запуск в минуту. Но страница сначала помещается на страницу данных файла журнала из журнала буфера. Это известно как Упреждающая запись в журнал. Сводка:
- Существуют три типа клиент-серверной архитектуры: 1) Общая память 2) TCP/IP 3) Именованные каналы
- TDS, разработанный Sybase и теперь принадлежащий Microsoft, представляет собой пакет, инкапсулированный в сетевые пакеты для передачи данных с клиентского компьютера на серверный.
- Relational Engine содержит три основных компонента: CMD Parser: Он отвечает за синтаксические и семантические ошибки и, наконец, генерирует дерево запросов.
Оптимизатор: Роль оптимизатора заключается в поиске самого дешевого, а не самого лучшего, экономичного плана выполнения.
Исполнитель запросов: Исполнитель запросов вызывает метод доступа и предоставляет план выполнения для логики выборки данных, необходимой для выполнения.
- Существует три типа файлов: первичный файл, вторичный файл и файлы журнала.
- Механизм хранения: содержит следующие важные компоненты Метод доступа: Этот компонент Определяет, является ли запрос оператором Select или Non-Select. Вызывает Buffer и Transfer Manager соответственно.
Менеджер буфера: Менеджер буфера управляет основными функциями кэширования планов, анализа данных и грязной страницы.
Менеджер транзакций: Управляет транзакциями без выбора с помощью менеджеров журналов и блокировок. Кроме того, облегчает важную реализацию ведения журнала с опережающей записью и отложенных писателей.

Что такое бизнес-аналитика? Определение, значение и пример бизнес-аналитики
Что такое бизнес-аналитика?
BI (Business Intelligence) — это набор процессов, архитектур и технологий, которые преобразуют необработанные данные в содержательную информацию, которая способствует прибыльным деловым действиям. Это набор программного обеспечения и услуг для преобразования данных в полезную информацию и знания.
BI оказывает непосредственное влияние на стратегические, тактические и оперативные бизнес-решения организации. BI поддерживает принятие решений на основе фактов с использованием исторических данных, а не предположений и интуиции.
Инструменты BI выполняют анализ данных и создают отчеты, сводки, информационные панели, карты, графики и диаграммы, чтобы предоставить пользователям подробные сведения о характере бизнеса.
В этом уроке вы узнаете:
- Что такое бизнес-аналитика?
- Почему бизнес-аналитика важна?
- Как внедряются системы Business Intelligence?
- Примеры системы бизнес-аналитики, используемой на практике
- Четыре типа пользователей BI
- Преимущества бизнес-аналитики
- Недостатки системы BI
- Тенденции в бизнес-аналитике
Почему бизнес-аналитика важна?
- Измерение: создание KPI (ключевых показателей эффективности) на основе исторических данных
- Определить и установить ориентиры для различных процессов.
- С помощью систем BI организации могут выявлять рыночные тенденции и выявлять бизнес-проблемы, которые необходимо решить.
- BI помогает в визуализации данных, что повышает качество данных и, следовательно, качество принятия решений.
- Системы BI могут использоваться не только предприятиями, но и МСП (малыми и средними предприятиями)
Как внедряются системы Business Intelligence?
Вот шаги:
Шаг 1 ) Извлекаются необработанные данные из корпоративных баз данных. Данные могут быть распределены по множеству гетерогенных систем.
Шаг 2) Данные очищаются и преобразуются в хранилище данных. Таблицу можно связать и сформировать кубы данных.
Шаг 3) Используя систему BI, пользователь может задавать вопросы, запрашивать специальные отчеты или проводить любой другой анализ.
Примеры системы бизнес-аналитики, используемой на практике
Пример 1:
В системе оперативной обработки транзакций (OLTP) информация, которая может быть введена в базу данных продуктов, может быть
- добавить линейку продуктов 9000 8
- изменить цену товара
Соответственно, в системе Business Intelligence запрос, который будет выполняться для предметной области продукта, может быть добавление новой линейки продуктов или изменение цены продукта, увеличение доходов
В рекламной базе данных OLTP системный запрос, который может быть выполнен
- Изменено в параметрах рекламы
- Увеличить бюджет радио
Соответственно, запрос системы BI, который может быть выполнен, будет следующим: количество новых клиентов, добавленных в связи с изменением бюджета радиосвязи.
Соответственно, в системном запросе OLAP, который может быть выполнен, будет: поддерживают ли изменения профиля клиента поддержку более высокой цены на продукт? Это помогает найти совокупный доход от номера.
Он также собирает статистические данные о доле рынка и данные опросов клиентов каждой гостиницы для определения ее конкурентной позиции на различных рынках.
Анализ этих тенденций из года в год, месяц за месяцем и день за днем помогает руководству предлагать скидки на аренду помещений.
Пример 3:
Банк предоставляет менеджерам филиалов доступ к приложениям BI. Это помогает менеджеру филиала определить, кто является наиболее прибыльным клиентом и с какими клиентами ему следует работать.
Использование инструментов BI освобождает специалистов по информационным технологиям от задачи создания аналитических отчетов для отделов. Это также дает персоналу отдела доступ к более богатому источнику данных.
Четыре типа пользователей BI
Ниже приведены четыре ключевых игрока, которые используют систему бизнес-аналитики:
1. Профессиональный аналитик данных:
Аналитик данных — это статистик, которому всегда нужно углубляться в данные. Система BI помогает им получать свежие идеи для разработки уникальных бизнес-стратегий.
2. ИТ-пользователи:
ИТ-пользователи также играют доминирующую роль в обслуживании инфраструктуры BI.
3. Глава компании:
Генеральный директор или CXO может увеличить прибыль своего бизнеса за счет повышения операционной эффективности своего бизнеса.
4. Бизнес-пользователи
Пользователей бизнес-аналитики можно найти во всей организации. В основном существует два типа бизнес-пользователей
- Нерегулярный пользователь бизнес-аналитики
- Опытный пользователь.
Разница между ними заключается в том, что опытный пользователь имеет возможность работать со сложными наборами данных, в то время как потребности обычного пользователя заставят его использовать информационные панели для оценки заранее определенных наборов данных.
Преимущества Business Intelligence
Вот некоторые из преимуществ использования Business Intelligence System:
1. Повышение производительности
С помощью программы BI предприятия могут создавать отчеты одним щелчком мыши, что значительно экономит времени и ресурсов. Это также позволяет сотрудникам более продуктивно выполнять свои задачи.
2. Для улучшения видимости
BI также помогает улучшить видимость этих процессов и позволяет определить любые области, требующие внимания.
3. Исправить подотчетность
Система BI назначает подотчетность в организации, поскольку должен быть кто-то, кто должен нести ответственность и ответственность за работу организации по отношению к поставленным целям.
4. Это дает представление с высоты птичьего полета:
Система BI также помогает организациям, принимающим решения, получить общее представление с высоты птичьего полета с помощью типичных функций BI, таких как информационные панели и оценочные листы.
5. Оптимизирует бизнес-процессы:
BI устраняет все сложности, связанные с бизнес-процессами. Он также автоматизирует аналитику, предлагая прогнозный анализ, компьютерное моделирование, бенчмаркинг и другие методологии.
6. Позволяет легко проводить аналитику.
Программное обеспечение BI демократизировало свое использование, позволяя даже пользователям, не являющимся техническими специалистами или аналитиками, быстро собирать и обрабатывать данные. Это также позволяет использовать возможности аналитики из рук многих людей.
Недостатки системы BI
1. Стоимость:
Бизнес-аналитика может оказаться дорогостоящей как для малых, так и для средних предприятий. Использование такого типа системы может быть дорогостоящим для рутинных деловых операций.
2. Сложность:
Еще одним недостатком BI является сложность реализации хранилища данных. Он может быть настолько сложным, что может затруднить работу с бизнес-методами.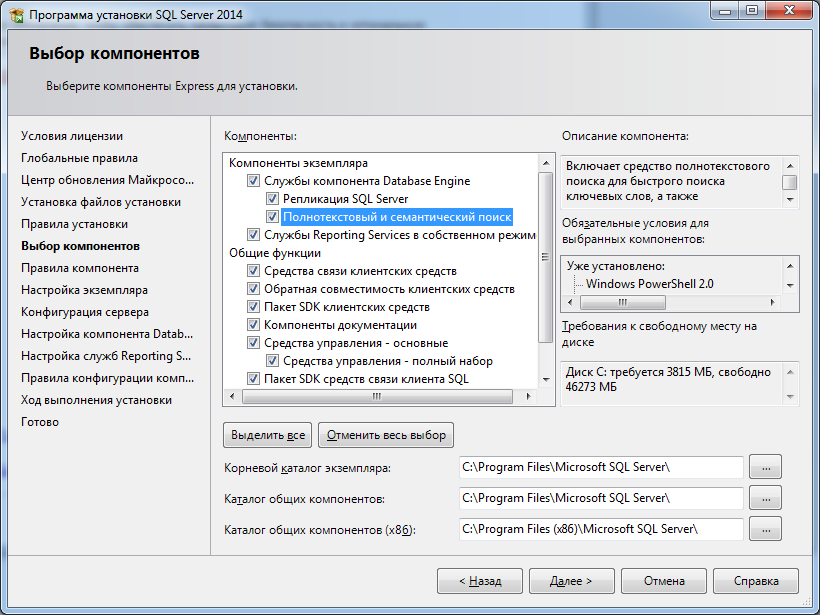
3. Ограниченное использование
Как и все усовершенствованные технологии, BI была впервые создана с учетом покупательной способности богатых фирм. Таким образом, система BI пока недоступна для многих малых и средних компаний.
4. Длительное внедрение
Полное внедрение системы хранения данных занимает почти полтора года. Поэтому это трудоемкий процесс.
Тенденции в области бизнес-аналитики
Ниже перечислены некоторые тенденции в области бизнес-аналитики и аналитики, о которых вам следует знать.
Искусственный интеллект: В отчете Gartner указывается, что ИИ и машинное обучение теперь берут на себя сложные задачи, выполняемые человеческим интеллектом. Эта возможность используется для анализа данных в реальном времени и составления отчетов на приборных панелях.
Collaborative BI: Программное обеспечение BI в сочетании с инструментами для совместной работы, включая социальные сети и другие новейшие технологии, улучшают работу и совместное использование команд для совместного принятия решений.
Embedded BI: Embedded BI позволяет интегрировать программное обеспечение BI или некоторые его функции в другое бизнес-приложение для улучшения и расширения его функций отчетности.
Облачная аналитика: BI-приложений скоро будут предлагаться в облаке, и все больше компаний перейдут на эту технологию. По их прогнозам, через пару лет расходы на облачную аналитику будут расти в 4,5 раза быстрее.
Резюме:
- BI — это набор процессов, архитектур и технологий, которые преобразуют необработанные данные в значимую информацию, которая способствует прибыльным деловым действиям.
- помогают предприятиям выявлять рыночные тенденции и выявлять проблемы бизнеса, которые необходимо решить.
- Технология BI может использоваться аналитиком данных, ИТ-специалистами, бизнес-пользователями и руководителями компаний.
- BI помогает организации улучшить видимость, производительность и исправить подотчетность.
Системы бизнес-аналитики
Система
