Sql server заполнение таблицы: MS SQL Server и T-SQL
Содержание
Обработка данных MS SQL Server средствами Python — Разработка на vc.ru
Не всякие данные можно обработать с помощью старого доброго Excel или SQL. Впервые с проблемой нехватки стандартных средств анализа и обработки данных мы столкнулись при разработке модуля для анализа рекламы нашей компании на ТВ. Необходимо было хранить большой объём кадров прямого эфира каналов и информации о них. Поэтому было принято решение о интеграции возможностей языка python c языком SQL.
12 975
просмотров
Для работы импортируем необходимые библиотеки:
import pyodbc
В случае, если данная библиотека отсутствует на устройстве, в командной строке запустите команду:
pip install pyodbc
Данный модуль упрощает доступ к базам данных через программный интерфейс ODBC (Open Database Connectivity).
Далее создаём строку подключения к нашей базе данных:
connectionString = («Driver = {SQL Server Native Client 11.0};»»Server =YOUR SERVER;»
«Database = audTv;»»Trusted_Connection=yes»)
где Driver – драйвер Microsoft ODBC для SQL Server. Обеспечивает возможность подключения к Microsoft SQL Server из Windows.
Обеспечивает возможность подключения к Microsoft SQL Server из Windows.
Server – указание сервера, на котором будут храниться (хранятся) наши таблицы:
Trusted Connection – указывает на способ подключения пользователей к БД. В случае, если указано значение «yes», для проверки подлинности используется учётная запись Windows, а ключи UID и PWD игнорируются, и наоборот, при выборе значения «no».
После заполнения строки подключения данными, выполним соединение к нашей базе данных:
connection = pyodbc.connect(connectionString, autocommit=True)
Создадим курсор, с помощью которого, посредством передачи запросов будем оперировать данными в нашей таблице:
dbCursor = connection.cursor()
Теперь можно написать наш первый запрос! Допустим, у нас есть таблица с данными о книгах, связанных с проектированием баз данных. Данная таблица будет содержать следующие данные: название книги, имя(имена) автора(ов) книги, год издания и краткое описание.
Добавим данные в нашу таблицу с помощью кода на python:
requestString = ””” INSERT INTO Books(name,author,publicationYear,descript) VALUES
(‘Рефакторинг баз данных. Эволюционное проектирование’,’Скотт В. Эмблер, Прамодкумар Дж. Садаладж’,2007,’В книге представлены советы по улучшению кода для баз данных’),
Эволюционное проектирование’,’Скотт В. Эмблер, Прамодкумар Дж. Садаладж’,2007,’В книге представлены советы по улучшению кода для баз данных’),
(‘Базы данных. Проектирование и разработка’,’Рэймонд Фрост, Джон Дей, Крейг Ван Слайк’,2007,’Довольно популярная книга по проектированию и рефакторингу’)
”””
dbCursor.execute(requestString)
connection.commit()
Проверим нашу таблицу (для проверки использовался SQL Server Management Studio):
Наш запрос успешно выполнен, но стоит отметить, что возможности использования библиотеки pyodbc не ограничиваются заполнением таблиц данными. Попробуем выбрать данные из нашей таблицы:
requestString2 = ”””select name,author from Books where publicationYear=2007”””
dbCursor.execute(requestString)
for row in dbCursor:
print(“Название книги: ” + row.name + “Автор(ы) книги: ” + row.author)
Результат работы программы:
Так же есть возможность сохранения результата запроса в объект DataFrame, для дальнейшей обработки средствами библиотеки pandas:
import pandas as pd
from IPython. display import display
display import display
df = pd.read_sql_query(requestString,connection)
display(df.head())
Результат работы программы:
Таким образом, сегодня мы научились с помощью скриптов на языке python посредством библиотеки pyodbc создавать запросы для работы с SQL серверами, что может быть использовано для удобства работы с данными в повседневной деятельности аудитора.
Построение таблиц базы данных
На
предыдущем этапе мы построили схему
базы данных, воспользовавшись общими
правилами перехода к реляционной модели
данных. Она является корректной, поскольку
в ней отсутствуют нежелательные
отношения. Ставится вопрос, а какую же
СУБД использовать? Выбор остановим на
реляционной СУБД MS
SQL
Server.
Microsoft
SQL
Server
– система управления реляционными
базами данных, разработанная корпорацией
Microsoft,
основной используемый язык запросов –
Transact-SQL,
создан совместно Microsoft
и Sybase,
который является реализацией стандарта
ANSI/ISO (American
National
Standards
Institute/International
Organization
for
Standardization)
по структурированному языку запросов
SQL
с расширениями.
Язык
SQL
был первоначально разработан компанией
IBM,
а в настоящее время поддерживается
большинством коммерческих СУБД,
представленных на рынке, и является
официальным стандартом языка для работы
с реляционными базами данных. Само,
название SQL,
является аббревиатурой, образованной
от Structured
Query
Language
(язык структурированных запросов).
Итак,
нужно решить вопрос о назначении типа
данных для каждого атрибута каждой
сущности, размера данных, присвоении
свойств уникальности и обязательности
поля, назначении ключевых полей.
Далее
представлены все таблицы, в режиме
Design
(Конструктор).
Рисунок
6/1
– Таблица tb_worker
Рисунок
6/2 – Таблица tb_uchastok
Рисунок
6/3 – Таблица tb_podrazdeleniye
Рисунок
6/4 – Таблица tb_dvizeniye
Рисунок
6/5 – Таблица
tb_occupation
Рисунок
6/6 – Таблица
tb_pas_department
Рисунок
6/7 – Таблица
tb_passport
Рисунок
6/8 – Таблица
tb_prikaz
Итак,
мы привели основные таблицы с приведением
типов полей. Ключевые поля имеют тип
Ключевые поля имеют тип
int,
и в параметрах имеют свойство
IdentitySpecification=’Yes’,
что позволяет СУБД, автоматически, по
мере добавления записей в таблицу,
наращивать идентификатор.
Заполнение таблиц
Работники:
Рисунок
7/1 – Заполнение таблицы tb_worker
Таблица,
в которой содержится список паспортных
столов:
Рисунок
7/2 – Заполнение таблицы tb_pas_department
Паспортные
данные работников:
Рисунок
7/3 – Заполнение таблицы tb_passport
Страны,
области, города, районы:
Рисунок
7/4 – Заполнение
таблиц:
«tb_country, tb_region, tb_city, tb_district»
Список
подразделений и участков:
Рисунок
7/5 – Заполнение таблицы «tb_podrazdeleniye»
Рисунок
7/6 – Заполнение таблицы «tb_uchastok»
Согласно
Законодательной базе Украины, указание
национальности в анкете работники не
является обязательным условием, но, тем
не менее, была создана таблица, в которой
хранится список национальностей, на
случай модификации законов:
Рисунок
7/7 – Заполнение таблиц:
«tb_nationality,
tb_gender»
Список
профессий:
Рисунок
7/7 – Заполнение таблицы «tb_occupation»
Признаки
карьерного движения:
Рисунок
7/8 – Заполнение
таблицы «tb_priznak»
Журнал
карьерного движения:
Рисунок
7/9 – Заполнение таблицы «tb_dvizeniye»
Список
приказов, которые сопровождают любое
карьерное движение работника:
Рисунок
7/10 – Заполнение таблицы «tb_prikaz»
Создание запросов
Для
создания и тестирования запросов, была
выбрана среда разработки MS
WebMatrix,
которая позволяет создавать веб-приложения
с помощью технологии ASP. NET,
NET,
которая является составной частью
платформы Microsoft
.NET.
.NET
Framework — программная
платформа,
выпущенная компанией Microsoft в 2002
году.
Основой платформы является исполняющая
среда Common
Language
Runtime
(CLR),
способная выполнять как обычные
программы, так и серверные веб-приложения.
.NET Framework
поддерживает создание программ,
написанных на разных языках программирования.
Рассмотрим
примеры с комбинацией языков C#
и HTML.
Запрос
№1.Выведем на экран список профессий,
с названием подразделения к которому
они относятся, и ставкой/должностным
окладом на том или ином участке. Код
приведен в Листинге 1. Результатом будет
таблица вида:
Запрос
№2. Выведем на экран основные данные о
работниках предприятия. Код представлен
в Листинге 2. Результатом работы запроса
будет:
Запрос
№3. В данном запросе выведем полную
информацию о работнике «Пронякин Дмитрий
Богданович», нам известен его табельный
номер «8508».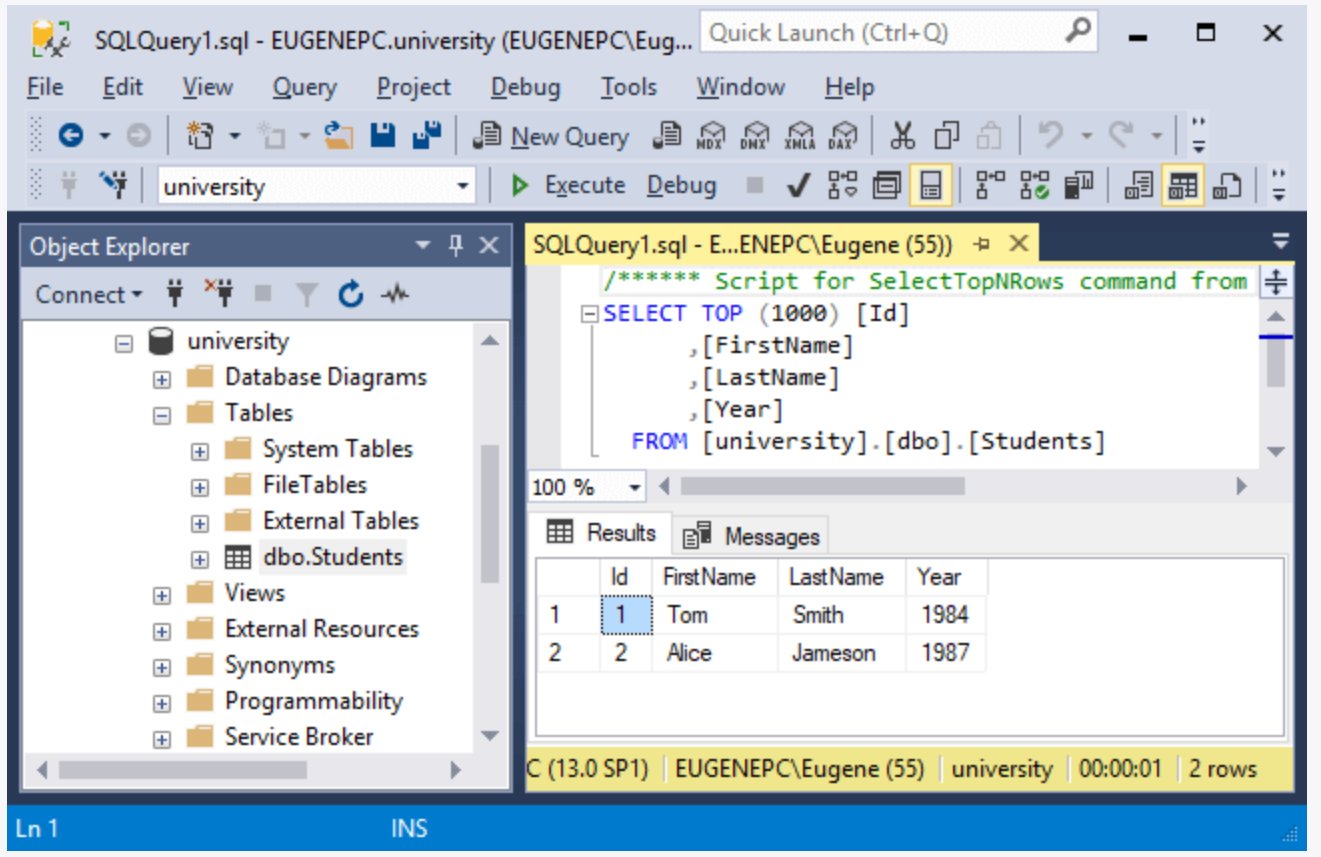 Нас интересует базовая
Нас интересует базовая
информация, указанная в анкете, должность,
карьерные движения:
sql server — ежедневное заполнение таблицы другим SQL
спросил
Изменено
3 года, 11 месяцев назад
Просмотрено
63 раза
Я хочу заполнить таблицу другой таблицей (которая после этого будет усечена), однако, когда я использовал это, это только ОДИН выстрел, потому что SQL говорит, что таблица уже существует. Я просто хочу добавить строки в эту таблицу Альберты.
ИСПОЛЬЗОВАТЬ [ХРАНИЛИЩЕ ДАННЫХ] ИДТИ УСТАНОВИТЕ ANSI_NULLS ВКЛ. ИДТИ УСТАНОВИТЕ QUOTED_IDENTIFIER НА ИДТИ ALTER Процедура [dbo].[prcAlberta] As ( Выбирать * INTO AlbertaData_Storing ОТ dbo.AlbertaData_import где имя не равно null ) обрезать таблицу AlbertaData_import ИДТИ
- sql-server
- tsql
- хранимые процедуры
Произошла ошибка, потому что команда вставляет все в «TableName» из другой таблицы, создает новую таблицу со схемой.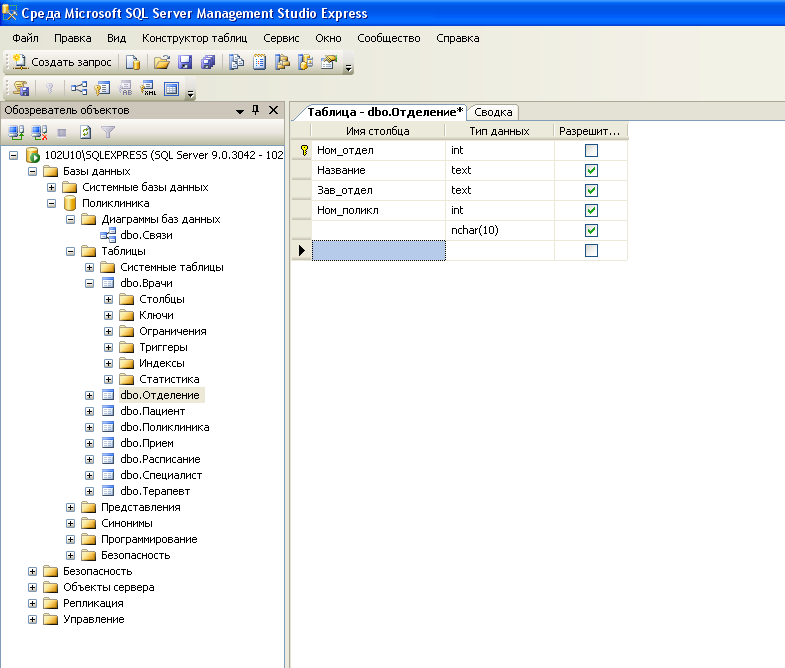 Так что нужно изменить запрос следующим образом.
Так что нужно изменить запрос следующим образом.
ИСПОЛЬЗОВАТЬ [ХРАНИЛИЩЕ ДАННЫХ]
ИДТИ
УСТАНОВИТЕ ANSI_NULLS ВКЛ.
ИДТИ
УСТАНОВИТЕ QUOTED_IDENTIFIER НА
ИДТИ
ИЗМЕНИТЬ ПРОЦЕДУРУ [dbo].[prcAlberta]
КАК
НАЧИНАТЬ
/* Если таблица не существует, создайте пустую таблицу */
ЕСЛИ OBJECT_ID('AlbertaData_Storing') IS NULL
НАЧИНАТЬ
SELECT * INTO AlbertaData_Storing
ОТ dbo.AlbertaData_import ГДЕ 1 <> 1
КОНЕЦ
/*
Лучше использовать только обязательный столбец Like :
ВСТАВИТЬ В AlbertaData_Storing (Столбец1,Столбец2,Столбец3,...)
ВЫБЕРИТЕ Column1, Column2, Column3,... ИЗ dbo.AlbertaData_import
ГДЕ Имя НЕ НУЛЕВОЕ
*/
ВСТАВИТЬ В AlbertaData_Storing
ВЫБЕРИТЕ * ИЗ dbo.AlbertaData_import
ГДЕ Имя НЕ НУЛЕВОЕ
TRUNCATE TABLE AlbertaData_import
КОНЕЦ
ИДТИ
Я бы предложил удалить таблицу, а затем вставить в нее:
ALTER Процедура [dbo].[prcAlberta] A
как
начинать
начать пробовать
удалить таблицу AlbertaData_Storing;
конец попытки
начать ловить -- ничего не делать
концевой захват;
выбирать *
в AlbertaData_Storing
из dbo. AlbertaData_import
где имя не равно null
обрезать таблицу AlbertaData_import
конец;
ИДТИ
AlbertaData_import
где имя не равно null
обрезать таблицу AlbertaData_import
конец;
ИДТИ
 AlbertaData_import
где имя не равно null
обрезать таблицу AlbertaData_import
конец;
ИДТИ
AlbertaData_import
где имя не равно null
обрезать таблицу AlbertaData_import
конец;
ИДТИ
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Заполнение интерполяционных таблиц в SQL Server DataTools (SSDT) | Бенджамин Кэмпбелл
Данные поиска никогда не казались мне данными
Benjamin Campbell
·
Читать
4 минуты чтения
·
20 ноября 2017 г.
Определения
Таблица поиска : Таблица с минимум 2 полями, бессмысленным первичным ключом и текстовым значением используется при нормализации, чтобы избежать повторения текстовых значений и ссылок на внешние ключи в других таблицах. Я также слышал, что их называют справочными таблицами и доменными таблицами. Эти таблицы не изменяются в ходе обычной работы (в отличие от чего-то вроде ProductCategory, который выглядит так же, но я бы сказал, что это не таблица поиска). Это мое определение, так что не принимайте это как истину.
Примеры
Таблица состояний может быть любой. Это может поддерживаться вашим приложением.
SQL Server Data Tools (SSDT): Функциональность для разработки, тестирования, развертывания и рефакторинга баз данных SQL Server в Visual Studio, не требующая создания сценария изменения. Разработка выполняется просто путем определения желаемого конечного состояния базы данных, а развертывание выполняется путем сравнения схемы в проекте со схемой в цели развертывания.
SQL Server Data Tools — пользовательский интерфейс редактора таблиц
Действительно ли данные таблицы поиска являются данными?
Придумайте соответствующий код. Обычно это перечисление, верно? Иногда вы будете реализовывать это как класс и загружать данные поиска из базы данных, чтобы избежать двойного жесткого кодирования, но вы ищете функциональность, подобную перечислению. Вот еще несколько тестов…
- Будет ли работать ваше приложение, если эти таблицы будут пустыми? Я сомневаюсь в этом, если только вы не используете внешние ключи (что требует отдельного поста).
- Будет ли «пустая» копия базы данных полной без этих данных?
- Изменяются ли они без соответствующего нажатия кода?
Хорошо, я чувствую себя довольно комфортно, потому что мы имеем дело с действительно особым типом данных, который очень похож на схему. Что теперь? Мы должны получить контроль над исходным кодом и развернуть его.
Источник, управляющий данными таблицы поиска в SSDT
Прелесть SSDT в том, что мы создаем декларативную модель того, какой должна стать целевая база данных после развертывания, независимо от ее текущего состояния. Мы хотим, чтобы данные таблицы поиска обрабатывались одинаково как в системе управления версиями, так и во время развертывания.
Пример
Таблица поискаLookupTable.UserStatus.sql
Пара вещей, которые вы можете заметить…
Строки 5–10 представляют данные, которые являются желаемым конечным состоянием таблицы поиска
Строки 13–15 гарантируют, что мы только делаем обновление, когда что-то действительно изменилось. Строки 13–14 демонстрируют предикат для полей
Строки 13–14 демонстрируют предикат для полей NOT NULL , а строка 15 демонстрирует предикат для поля NULL . Если вы использовали структуру сущностей, вы можете быть знакомы с этой логикой. Это позволяет NULL == NULL == true тестов. Хотя этот раздел не является технически необходимым, приятно иметь его, чтобы вы могли видеть (0 затронутых строк) при запуске этого скрипта для целевой таблицы, которая ему соответствует.
Этот сценарий слишком подробный. Создание его вручную было бы подвержено ошибкам. Я использую скрипт, который автоматически генерирует его из метаданных и данных, уже находящихся в таблице. Первоначально в больших существующих БД, которые я переношу на SSDT, я использую сценарий PowerShell, который использует расширенные свойства для идентификации таблиц поиска, создает все эти сценарии в правильном порядке, выполняя поиск в глубину графа зависимостей FK, и предполагает, что вы всегда создаете данные, а не удаляете их (поскольку удаление должно происходить в обратном порядке. Подумайте о категории и подкатегории). Я могу опубликовать эти сценарии в будущем, но они еще не готовы к распространению. Что бы я действительно хотел увидеть, так это таблицы поиска, включая импорт существующих, в качестве первоклассной функции SSDT!
Подумайте о категории и подкатегории). Я могу опубликовать эти сценарии в будущем, но они еще не готовы к распространению. Что бы я действительно хотел увидеть, так это таблицы поиска, включая импорт существующих, в качестве первоклассной функции SSDT!
Развертывание
Мы хотим развернуть их с помощью сценария после развертывания. Поскольку у вас может быть только один, я использую следующую настройку:
Script.PostDeployment.sqlSolution Explorer
Создайте Script.PostDeployment.sql как Post-Deployment Script . Все сценарии таблицы поиска добавьте как Script (Not in Build) , чтобы избежать отладки во время компиляции и убедиться, что все они заканчиваются на GO .
Типы скриптов
Если вы случайно создали скрипт не того типа и получаете ошибки, вы можете изменить Build Action to None в свойствах:
Вы также можете создавать хранимые процедуры для заполнения таблиц поиска, чтобы ваши сценарии publish.