Sql создание таблицы запрос: SQL запрос для создания таблицы базы данных
Содержание
SQL-Урок 14. Создание таблиц (CREATE TABLE)
ВВЕРХ
❮
❯
Язык SQL используется не только для обработки информации, но и предназначена для выполнения всех операций с базами данных и таблицами, включая также создание таблиц и работа с ними.
Существует два способа создания таблиц:
- 1) большинство СУБД обладают визуальным интерфейсом для интерактивного создания таблиц и управление ими;
- 2) таблицами можно манипулировать, используя операторы SQL.
Стоит отметить, что, когда вы используете интерактивный инструментарий СУБД, на самом деле вся работа выполняется операторами SQL, т.е. интерфейс сам создает эти команды незаметно для пользователя (это подобно на запись макроса в Excel, когда макрорекодер записывает ваши действия и преобразует их в команды VBA).
1. Создание таблиц
Для создания таблиц программным способом используют оператор CREATE TABLE. Для этого нужно указать следующие данные:
Для этого нужно указать следующие данные:
Давайте создадим новую таблицу и назовем ее Customers:
CREATE TABLE Customers ( ID CHAR(10) NOT NULL Primary key, Custom_name CHAR(25) NOT NULL, Custom_address CHAR(25) NULL, Custom_city CHAR(25) NULL, Custom_Country CHAR(25) NULL, ArcDate CHAR(25) NOT NULL, DEFAULT NOWO)
Так мы сначала указываем название новой таблицы, затем в скобках перечисляем столбцы, которие будем создавать, причем их названия не могут повторяться в пределах одной таблицы. После названий столбцов указывается тип данных для каждого поля (CHAR (10)), затем отмечаем может ли поле содержать пустые значения (NULL или NOT NULL), а также нужно указать поле, которое будет первичным ключом (Primary key).
Язык SQL также позволяет определять для каждого поля значение по умолчанию, то есть, если пользователь не укажет значение определенного поля — оно будет автоматически проставлено СУБД. Значение по умолчанию определяется ключевым словом DEFAULT при определении столбцов оператором CREATE TABLE.
2. Обновление таблиц
Для того, чтобы изменить таблицу в SQL используется оператор ALTER TABLE. При использовании данного оператора необходимо ввести следующую информацию:
- — имя таблицы, которую мы хотим изменить
- — перечень изменений, которые мы хотим сделать.
Для примера давайте добавим новую колонку в таблицу Sellers, в которой будем указывать телефон реализатора:
ALTER TABLE Sellers ADD Phone CHAR (20)
Кроме добавления столбцов, мы можем их удалять. Давайте теперь удалим поле Phone. Для этого пропишем следующий запрос:
ALTER TABLE Sellers DROP COLUMN Phone
3.
 Удаление таблиц
Удаление таблиц
Удаление таблиц осуществляется с помощью оператора DROP TABLE. Чтобы удалить таблицу Sellers_new, мы можем прописать следующий запрос:
DROP TABLE Sellers_new
Во многих СУБД применяются правила, предотвращающие удаление таблиц, которые являются уже связаны с другими таблицами.
Если эти правила действуют и вы удаляете такую таблицу, то СУБД блокирует операцию удаления до тех пор, пока не будет удалена связь.
Такие меры предотвращают случайное удаление нужных таблиц.
Статьи по теме:
Курс SQL & Hibernate — Лекция: Создание таблиц
SQL & Hibernate
5 уровень
,
5 лекция
Открыта
Создание таблицы
Список таблиц у нас пуст, так что пришло время создать нашу первую таблицу. Для этого есть три способа:
- Кнопка Create Table в верхнем toolbar
- Локальное меню
- SQL-скрипт
Давай в этот раз воспользуемся локальным меню. Просто кликни правой кнопкой мышки на поле Tables и получи такую картинку:
Просто кликни правой кнопкой мышки на поле Tables и получи такую картинку:
Дальше ты увидишь панель для создания таблицы – она страшнее, чем кажется:
Тебе тут нужно всего 2 места:
- Указать имя таблицы в поле сверху.
- Указать имя и тип колонок в поле в центре.
Проектирование: как правильно выбирать имена и типы колонок
Давай создадим таблицу, которая будет хранить пользователей. В Java мы бы написали что-то типа такого:
class User {
public int userId;
public String name;
public int level;
public Date createdDate;
}
Как нам создать такую таблицу в SQL?
Для начала определимся с конвенцией имен. В Java используется camelCase, но так как SQL по большей части регистронезависимый, то тут обычно используется нижнее подчеркивание. Поэтому userId превращается в user_id, а createdDate в created_date.
Дальше нужно определиться с типами. Давай создадим таблицу по имени user, которая будет содержать 4 колонки:
- id типа INT
- name типа VARCHAR(100)
- level типа INT
- created_date типа DATE
Вместо user_id мы написали id, так как именно так принято в SQL, user_id мы бы написали, если бы где-то в другой таблице ссылались на колонку id таблицы user.
Также мы установили ограничение в 100 символов для поля name. Мы же не хотим, чтобы кто-то сохранил туда пару миллионов символов и что-то нам поломал. Надежность наше все.
Указываем имена полей
Теперь давай добавим нужные колонки – их всего 4:
Обрати внимание на две колонки слева сверху:
- Column Name – это имена колонок.
- DataType – это типы колонки.
Все как мы и планировали.
А в нижней половине картинки мы видим детальную расшифровку текущей строки таблицы, которая описывает колонку таблицы user. Надеюсь, все понятно.
Важно! Если ты считаешь, что значения какой-то колонки точно не должны быть NULL, тогда тебе нужно пометить ее как Not Null (в правом нижнем углу). При этому MySQL-сервер будет следить за тем, чтобы так всегда и было.
Также у нас id отмечена как Primary Key, который как ты помнишь, обозначает, что это уникальные Id записи.
SQL-запрос на создание таблицы
Нажимаем Apply и получаем такой чудесный SQL-запрос:
Чем-то похоже на объявление класса в Java, да?
Кликаем Apply и видим нашу первую созданную таблицу:
Что такое оператор SQL Create Table? + How to Create One
В этой статье Что такое элемент языка оператора SQL Create Table Clause вы узнаете, как создать таблицу в базе данных, используя оператор Create Table .
Как мы упоминали ранее, наша тестовая база данных, используемая в этой серии статей, называется realparsmodel .
С помощью Entity Relationship Diagram или ERD мы можем увидеть, как таблицы связаны друг с другом в базе данных.
До сих пор на уроках SQL мы работали с операторами типа SQL Data Manipulation . Чтобы продолжить работу с расширенными операторами типа SQL Data Manipulation , нам необходимо понять операторы Data Definition .
Определение данных Операторы
Определение данных Операторы позволяют создавать дополнительные таблицы и столбцы. С помощью этих операторов мы создадим новые таблицы и столбцы.
С помощью этих операторов мы создадим новые таблицы и столбцы.
SQL CREATE TABLE Утверждения
Эта инструкция CREATE TABLE создаст новую таблицу под названием Lessons .
Типы данных SQL
Новые созданные столбцы будут содержать определенные типы данных, определяющие, являются ли они числовыми , строковыми или датами и временем , а также объемом занимаемого ими пространства.
Подобно типам данных ПЛК, MySQL использует типы данных в запросах. В этом запросе столбец с именем Lesson_ID использует Тип данных INT , а столбец с именем Status использует тип данных TINYINT .
Имя столбца Subject будет использовать тип данных VARCHAR , а столбец с именем Description будет использовать тип данных TEXT или string данные типа .
Чтобы создать таблицу Lessons , в программе MySQL Workbench введите оператор SQL в окно запроса.
Затем нажмите кнопку Execute Query , чтобы запустить Создать таблицу выписка.
Обновите панель Navigator , нажав кнопку Refresh .
Поскольку мы создали таблицу с оператором Data Definition и не использовали оператор Select Data для отображения на панели вывода, результаты отображаться не будут.
Вместо этого мы сможем увидеть в списке на панели Navigator новую таблицу под названием Lessons и столбцы, которые мы добавили в Lessons таблица.
Присоединиться Проверка команды
Столбцы внешнего ключа
Теперь давайте рассмотрим команду Присоединить . Реляционная база данных состоит из нескольких связанных таблиц, связанных вместе с помощью общих столбцов. Эти столбцы называются столбцами внешнего ключа .
Из-за такого реляционного расположения данные в каждой таблице являются неполными и не содержат всех данных, необходимых с точки зрения пользователя и бизнеса.
Например, в нашей тестовой базе данных таблицы Orders и OrderDetails связаны с помощью столбца OrderNumber .
Чтобы получить полные данные о заказах, нам потребуется запросить данные из обеих таблиц Orders и OrderDetails , и здесь в игру вступает JOIN .
JOIN — это метод связывания данных между одной или несколькими таблицами на основе значений общего столбца между таблицами.
CROSS JOIN, INNER JOIN, LEFT JOIN, RIGHT JOIN
Для соединения таблиц можно использовать CROSS JOIN , INNER JOIN , 9 0003 LEFT JOIN или RIGHT JOIN пункт для эквивалентный тип соединения. Предложение соединения используется в инструкции SELECT, которая стоит после предложения FROM .
Предложение соединения используется в инструкции SELECT, которая стоит после предложения FROM .
Чтобы ознакомиться с командой JOIN , давайте создадим несколько простых таблиц с именами t1 и 9.0003 t2 , используя операторы Create Table , которые я пишу на вкладке SQL Query.
Как видно, обе таблицы t1 и t2 имеют общий столбец с именем Pattern .
Оператор INSERT INTO
Теперь напишите операторы INSERT INTO на вкладке SQL Query, которые добавят данные в таблицы.
Давайте попробуем это утверждение. Нажмите кнопку Execute SQL Query , чтобы запустить операторы Create Table.
Обновите панель Navigator , нажав кнопку Refresh . Затем разверните элементы таблицы t1 и t2 , чтобы увидеть столбцы, созданные для этих таблиц.
При выполнении запроса операторы Create Table создают две новые таблицы со столбцами ID и Pattern . Затем операторы INSERT INTO добавляют данные в каждую из таблиц t1 и t2 .
Хорошо, как мы видим, 9Вместе с новыми столбцами были добавлены таблицы 0003 t1 и t2 .
Щелкните правой кнопкой мыши элемент таблицы t1 на панели навигации и выберите Select Rows — Limit 1000.
Сделав это, вы увидите записи таблицы t1 .
Выполните ту же процедуру, что и для таблицы t1 , чтобы просмотреть записи для таблицы t2 .
Чтобы узнать больше о MySQL и дополнительных операторах SQL, мы рекомендуем вам посетить веб-сайт MySQL. На этом статья заканчивается, Что такое элемент языка оператора SQL Create Table Clause .
Следующие уроки SQL
Наша серия последующих статей будет состоять из следующих уроков.
Обязательно прочитайте эти статьи, предлагающие предварительное обучение для начинающих, а затем более продвинутые инструкции по изучению SQL.
Следующий урок SQL, который скоро будет доступен:
— Элементы языка операторов Cross Join, Inner Join и Union Clause
Если вы хотите пройти дополнительное обучение по аналогичной теме, сообщите нам об этом в разделе комментариев.
Вернитесь к нам в ближайшее время, чтобы узнать о других темах автоматизации управления.
У вас есть друг, клиент или коллега, которым может пригодиться эта информация? Пожалуйста, поделитесь этой статьей.
Команда RealPars
Уроки SQL Серия статей
Поиск:
Инженер по автоматизации
Опубликовано 2 марта 2020 г.0007
By Wally Gastreich
Инженер по автоматизации
Опубликовано 2 марта 2020 г.
Таблицы и данные | Supabase Docs
В таблицах хранятся ваши данные.
Таблицы аналогичны электронным таблицам Excel. Они содержат столбцы и строки.
Например, эта таблица имеет 3 «столбца» ( id , имя , описание ) и 4 «строки» данных:
идентификатор | имя | описание |
|---|---|---|
| 1 | Скрытая угроза | Два джедая спасаются от враждебной блокады, чтобы найти союзников и встретить мальчика, который может восстановить баланс Силы. |
| 2 | Атака клонов | Через десять лет после вторжения на Набу Галактическая Республика столкнулась с движением сепаратистов. |
| 3 | Месть ситхов | Пока Оби-Ван преследует новую угрозу, Энакин действует как двойной агент между Советом джедаев и Палпатином, и его заманивают в зловещий план по управлению галактикой. |
| 4 | Звездные войны | Люк Скайуокер объединяет усилия с рыцарем-джедаем, дерзким пилотом, вуки и двумя дроидами, чтобы спасти галактику от разрушительной боевой станции Империи. |
Есть несколько важных отличий от электронных таблиц, но это хорошая отправная точка, если вы новичок в реляционных базах данных.
При создании таблицы рекомендуется добавлять столбцы одновременно.
Вы должны определить «тип данных» каждого столбца при его создании. Вы можете добавлять и удалять столбцы в любое время после создания таблицы.
Supabase предоставляет несколько вариантов создания таблиц. Вы можете использовать Dashboard или создавать их непосредственно с помощью SQL.
Мы предоставляем редактор SQL на панели инструментов, или вы можете подключиться к своей базе данных.
и запускать SQL-запросы самостоятельно.
- Перейдите на страницу редактора таблиц на панели инструментов.
- Нажмите Новая таблица и создайте таблицу с именем
todos.
- Щелкните Сохранить .
- Нажмите New Column и создайте столбец с именем
задачаи введитетекст. - Щелкните Сохранить .

При именовании таблиц используйте строчные буквы и знаки подчеркивания вместо пробелов (например, имя_таблицы , а не Имя таблицы ).
При создании столбца необходимо определить «тип данных».
Типы данных#
Каждый столбец имеет предопределенный тип. PostgreSQL предоставляет множество типов по умолчанию, и вы даже можете создавать свои собственные (или использовать расширения).
если типы по умолчанию не соответствуют вашим потребностям. Вы можете использовать любой тип данных, поддерживаемый Postgres, через редактор SQL. Мы поддерживаем только некоторые из них в редакторе таблиц, чтобы упростить работу для людей с меньшим опытом работы с базами данных.
Показать/скрыть типы данных по умолчанию
Имя | Псевдонимы | Описание | bigint | int8 | восьмибайтовое целое со знаком |
|---|---|---|
| bigserial | serial8 | автоинкрементное восьмибайтовое целое |
| бит | битовая строка фиксированной длины | |
| переменная битовая | varbit | битовая строка переменной длины |
| логическое значение | логическое значение | логическое логическое значение (истина/ложь) |
| поле | 90 311 прямоугольная коробка на плоскости | |
| bytea | двоичные данные («byte array”) | |
| символ | char | строка символов фиксированной длины |
| символ Variable | varchar | строка символов переменной длины |
| cidr | Сетевой адрес IPv4 или IPv6 | |
| круг | круг на плоскости | |
| календарная дата (год, месяц, день) | ||
| двойная точность | float8 | число двойной точности с плавающей запятой (8 байтов) |
| inet | адрес хоста IPv4 или IPv6 | |
| целое число | int, int4 | Четырехбайтовое целое со знаком |
| интервал [ поля ] | временной интервал | |
| json | текстовые данные JSON | jsonb | двоичные данные JSON, декомпозированные |
| строка | бесконечная линия на плоскости | |
| lseg | сегмент линии на плоскости | |
| macaddr | MAC-адрес (управление доступом к среде) | |
| macaddr8 | MAC-адрес (Media Access Control) (формат EUI-64) | |
| деньги | сумма в валюте | числовой | десятичный | точный числовой с выбираемой точностью |
| path | геометрический путь на плоскости | |
| pg_lsn | Порядковый номер журнала PostgreSQL | |
| pg_snapshot | Моментальный снимок идентификатора транзакции на уровне пользователя | |
| точка | геометрическая точка на плоскости | |
| многоугольник | замкнутая геометрическая траектория на плоскости | |
| вещественная | float4 | число с плавающей запятой одинарной точности (4 байта) |
| smallint | int2 | двухбайтовое целое со знаком |
| smallserial | serial2 | автоинкрементное двухбайтовое целое |
| серийный номер | серийный номер4 | автоинкрементное четырехбайтовое целое число |
| текст | строка символов переменной длины | |
| время [без часового пояса] 90 312 | время суток (без часового пояса) | |
| время с часовым поясом | timetz | время суток, включая часовой пояс |
| метка времени [ без часового пояса ] | дата и время (без часового пояса) | |
| метка времени с часовым поясом | метка времени tz | дата и время, включая часовой пояс |
| tsquery | текстовый поисковый запрос | |
| документ текстового поиска | ||
| txid_snapshot | пользователь- моментальный снимок идентификатора транзакции уровня (устаревший; см. pg_snapshot) pg_snapshot) | |
| uuid | универсальный уникальный идентификатор | |
| xml | Данные XML |
Вы можете «преобразовать» столбцы из одного типа в другой, однако между типами могут быть некоторые несовместимости.
Например, если вы приведете отметку времени к дате , вы потеряете всю информацию о времени, которая была ранее сохранена.
Первичные ключи#
Таблица может иметь «первичный ключ» — уникальный идентификатор для каждой строки данных. Несколько советов по первичным ключам:
- Рекомендуется создать первичный ключ для каждой таблицы в вашей базе данных.
- В качестве первичного ключа можно использовать любой столбец, если он уникален для каждой строки.
- Обычно в качестве первичного ключа используется тип
uuidили пронумерованный столбецidentity.
_
10
создание фильмов таблицы (
_
10
id bigint генерируется всегда как первичный ключ идентификации
9 0752
В приведенном выше примере у нас есть:
- создал столбец с именем
идентификатор - присвоен тип данных
bigint - проинструктировал базу данных, что
всегда должен генерироваться как идентификатор, что означает, что Postgres автоматически присвоит этому столбцу уникальный номер. - Поскольку он уникален, мы также можем использовать его в качестве
первичного ключа.

Мы также могли бы использовать , сгенерированный по умолчанию, как идентификатор , что позволило бы нам вставлять наши собственные уникальные значения.
_
10
создать таблицу фильмов (
_
10
id bigint генерируется по умолчанию как первичный ключ идентификации
9 0007
Существует несколько способов загрузки данных в Supabase. Вы можете загружать данные непосредственно в базу данных или с помощью API.
Используйте инструкции «Массовая загрузка», если вы загружаете большие наборы данных.
Загрузка основных данных#
_
11
вставка в ролики
_
11
(наименование, описание)
_
11
значения
_
11
'Империя наносит ответный удар',
_
11
'После того, как повстанцы жестоко подавленный Империей на ледяной планете Хот, Люк Скайуокер начинает обучение джедаям с Йодой».
_
11
«Возвращение джедая»,
_
11
«После дерзкой миссии по спасению Хана Соло от Джаббы Хатта, повстанцы отправляются на Эндор, чтобы уничтожить вторую Звезду Смерти».
Массовая загрузка данных#
При вставке больших наборов данных лучше всего использовать команду COPY PostgreSQL.
Это загружает данные непосредственно из файла в таблицу. Для копирования данных доступно несколько форматов файлов: текстовый, csv, двоичный, JSON и т. д.
Например, если вы хотите загрузить CSV-файл в таблицу фильмов:
./movies.csv
_
10
«Империя наносит ответный удар», «После того, как повстанцы жестоко подавлены Империей на ледяной планете Хот, Люк Скайуокер начинает обучение джедаям с Йодой».
_
10
«Возвращение джедая», «После дерзкой миссии по спасению Хана Соло от Джаббы Хатта повстанцы отправляются на Эндор, чтобы уничтожить вторую Звезду Смерти».
Вы должны подключиться к своей базе данных напрямую и загрузить файл с помощью команды COPY:
_
10
psql -h DATABASE_URL -p 5432 -d postgres -U postgres \
_
10
9000 2 -c "\ КОПИРОВАТЬ фильмы ИЗ '. /movies.csv';"
/movies.csv';"
Дополнительно используйте параметры DELIMITER , HEADER и FORMAT , как определено в документации PostgreSQL COPY.
_
10
psql -h DATABASE_URL -p 5432 -d postgres -U postgres \
_
10
9000 2 -c "\ КОПИРОВАТЬ фильмы ИЗ './movies.csv' С РАЗДЕЛИТЕЛЕМ ', "ЗАГОЛОВОК CSV"
Если вы получили сообщение об ошибке FATAL: аутентификация пароля не удалась для пользователя "postgres" , сбросьте пароль базы данных в настройках базы данных и повторите попытку.
Таблицы можно «соединять» вместе с помощью внешних ключей.
Отсюда и происходит «реляционное» именование, поскольку данные обычно формируют какие-то отношения.
В приведенном выше примере с фильмами мы могли бы добавить «категорию» для каждого фильма (например, «Действие» или «Документальный фильм»).
Давайте создадим новую таблицу с именем категорий и «свяжем» нашу таблицу фильмов .
_
10
создание категорий таблиц (
_
10
id bigint генерируется всегда как первичный ключ идентификации,
_
10
текст имени -- название категории
_
10
изменить таблицу фильмов
_
10
добавить столбец category_id bigint ссылки на категории
Вы также можете создать отношения «многие ко многим», создав таблицу «объединения».
Например, если у вас были следующие ситуации:
- У вас есть список из
фильмов. - В фильме может быть несколько
актеров. -
Актерможет сниматься в нескольких фильмах.
Таблицы относятся к схемам . Схемы — это способ организации ваших таблиц, часто из соображений безопасности.
Если вы не передаете схему явно при создании таблицы, Postgres будет считать, что вы хотите создать таблицу в общедоступной схеме .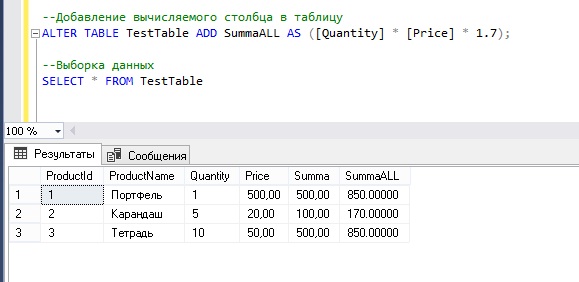
Мы можем создавать схемы для организации таблиц. Например, нам может понадобиться частная схема, скрытая от нашего API:
.
_
10
создать частную схему;
Теперь мы можем создавать таблицы внутри частной схемы :
_
10
создать таблицу private.salaries (
_
10
id bigint генерируется по умолчанию как первичный ключ идентификации,
_
10
зарплата bigint не нуль,
_
10
act_id bigint не нуль ссылки public.actors
900 07
Представление — это удобный ярлык для запроса. Создание представления не требует новых таблиц или данных. При запуске выполняется базовый запрос, возвращающий результаты пользователю.
осторожность
По умолчанию представления PostgreSQL обходят защиту на уровне строк, если вы не измените их владельца (см. https://github.com/supabase/supabase/discussions/901). PostgreSQL v15 (скоро) будет иметь более интуитивно понятный контроль для этого с помощью представлений вызывающего устройства безопасности, и предыдущий шаг не потребуется.
Допустим, у нас есть следующие таблицы из базы данных университета:
студенты
| id | имя | тип |
|---|---|---|
| 1 | принцесса Лея | бакалавриат 90 312 |
| 2 | Йода | выпускник |
| 3 | Энакин Скайуокер | выпускник |
курсы 90 007
| id | title | code |
|---|---|---|
| 1 | Введение в Postgres | PG1 01 |
| 2 | Теории аутентификации | AUTh305 |
| 3 | Основы Supabase | SUP412 |
сорта
| id | id_студента | id_курса | результат |
|---|---|---|---|
| 1 | 1 | 1 | В+ |
| 2 | 1 | 3 | А+ |
| 3 9 0312 | 2 | 2 | А |
| 4 | 3 | 1 | А- |
| 5 | 3 | 2 | А |
| 6 | 3 | 3 |
Создание представления, состоящего из всех трех таблиц, будет выглядеть так:
_
12
создать протокол просмотра как
_
12
выбрать
_
9 0750 12
имя_студента,
_
12
тип_студента,
_
12
курсы. название,
название,
_
12
курсы.код,
_
12 900 07
оценки.результат
_
12
из оценок
_
12
левый присоединяйтесь к учащимся по классам.student_id = student.id
_
12
левый присоединяйтесь к курсам по классам.course_id = курсы.id;
_
12
изменить владельца транскриптов просмотра на аутентифицированный;
После этого мы можем получить доступ к базовому запросу с помощью:
_
10
выбрать * из расшифровок;
Когда использовать представления#
Представления
обеспечивают несколько преимуществ:
- Простота
- Консистенция
- Логическая организация
- Безопасность
Простота
По мере того, как запрос становится сложным, его вызов становится проблематичным. Особенно, когда мы запускаем его регулярно. В приведенном выше примере вместо многократного запуска:
_
10
выбрать
_
10
имя_студента,
_
90 750 10
студенты. тип,
тип,
_
10
курсы.название,
_
10
курсы.код,
_
10
оценки.результат
_
10
из 90 007 _
10
марки
_
10
левое присоединение к учащимся по классам.student_id = student.id
_
10
левое присоединение к курсам по классам.course_id = курсы.id;
Вместо этого мы можем запустить это:
_
10
выбрать * из расшифровок;
Кроме того, представление ведет себя как обычная таблица. Мы можем безопасно использовать его в таблице JOIN или даже создавать новые представления, используя существующие представления.
Консистенция
Представления
гарантируют снижение вероятности ошибок при повторном выполнении запроса. В нашем примере выше мы можем решить, что хотим исключить курс Introduction to Postgres . Запрос будет выглядеть так:
_
11
выберите
_
11
имя_студента,
_
90 750 11
студенты. тип,
тип,
_
11
курсы.название,
_
11
курсы.код,
_
11
оценки.результат
_
11 90 007
из
_
11
сорта
_
11
слева присоединиться к учащимся в классах.student_id = student.id
_
11
оставить присоединиться к курсам в классах.course_id = курсы.id
_
11
где курсы.код != 'PG10 1 ';
Без представления нам пришлось бы обращаться к каждому зависимому запросу, чтобы добавить новое правило. Это увеличило бы вероятность ошибок и несоответствий, а также потребовало бы больших усилий от разработчика. С представлениями мы можем изменить только базовый запрос в расшифровке представлений . Изменение будет применено ко всем приложениям, использующим это представление.
Логическая организация
С представлениями мы можем дать нашему запросу имя. Это чрезвычайно полезно для групп, работающих с одной и той же базой данных. Вместо того, чтобы угадывать, что должен делать запрос, хорошо названное представление может легко объяснить это. Например, взглянув на имя представления стенограммы , мы можем сделать вывод, что базовый запрос может включать таблицы студентов , курсов и оценок .
Вместо того, чтобы угадывать, что должен делать запрос, хорошо названное представление может легко объяснить это. Например, взглянув на имя представления стенограммы , мы можем сделать вывод, что базовый запрос может включать таблицы студентов , курсов и оценок .
Безопасность
Представления могут ограничивать объем и тип данных, представляемых пользователю. Вместо предоставления пользователю прямого доступа к набору таблиц мы вместо этого предоставляем им представление. Мы можем запретить им читать конфиденциальные столбцы, исключив их из базового запроса.
материализованных представлений#
Материализованное представление — это форма представления, но оно также сохраняет результаты на диск. При последующих чтениях материализованного представления время, необходимое для возврата его результатов, будет намного меньше, чем при обычном представлении. Это связано с тем, что данные легко доступны для материализованного представления, в то время как обычное представление выполняет базовый запрос при каждом вызове.
Используя наш пример выше, можно создать материализованное представление следующим образом:
_
11
создать записи материализованного представления как
_
11
выбрать
_
11
имя_студента,
_
11
тип_студента,
_
11
курсы.название,
_
11
курсы.код,
_
11
оценки.результат
_
11
из
_
11
оценки
_
11
слева присоединиться к учащимся по классам.student_id = student.id
_
11
левые курсы присоединения к классам.course_id = курсы.id;
Чтение из материализованного представления такое же, как и из обычного представления:
_
10
выбрать * из расшифровок;
Обновление материализованных представлений#
К сожалению, есть компромисс — данные в материализованных представлениях не всегда актуальны. Нам нужно регулярно обновлять его, чтобы данные не стали слишком устаревшими. Для этого:
Нам нужно регулярно обновлять его, чтобы данные не стали слишком устаревшими. Для этого:
_
10
обновление протоколов материализованных представлений;
Вам решать, как часто обновлять ваши материализованные представления, и, вероятно, это будет отличаться для каждого представления в зависимости от его варианта использования.
Материализованные представления и обычные представления#
Материализованные представления полезны, когда время выполнения запросов или представлений слишком велико. Скорее всего, это может произойти в представлениях или запросах, включающих несколько таблиц и миллиарды строк. Однако при использовании такого представления должна быть терпимость к устаревшим данным. Некоторые варианты использования материализованных представлений — это внутренние информационные панели и аналитика.
Создание материализованного представления не является решением неэффективных запросов. Всегда следует стремиться оптимизировать медленно выполняющийся запрос, даже если вы реализуете материализованное представление.