Sql with пример: WITH обобщенное_табличное_выражение (Transact-SQL) — SQL Server
Содержание
Табличные выражения SQL
Прием № 1, чтобы писать хорошие читаемые SQL-запросы — это табличные выражения (CTE). Люди их боятся, а зря. Давайте разберемся за три минуты, читать увесистую книгу по SQL или проходить курсы не придется.
Проблема
Допустим, у нас есть таблица продаж по месяцам за два года:
┌──────┬───────┬───────┬──────────┬─────────┐ │ year │ month │ price │ quantity │ revenue │ ├──────┼───────┼───────┼──────────┼─────────┤ │ 2019 │ 1 │ 60 │ 200 │ 12000 │ │ 2019 │ 2 │ 60 │ 660 │ 39600 │ │ 2019 │ 3 │ 60 │ 400 │ 24000 │ │ 2019 │ 4 │ 60 │ 300 │ 18000 │ │ 2019 │ 5 │ 60 │ 440 │ 26400 │ │ 2019 │ 6 │ 60 │ 540 │ 32400 │ │ 2019 │ 7 │ 60 │ 440 │ 26400 │ │ 2019 │ 8 │ 60 │ 440 │ 26400 │ │ 2019 │ 9 │ 60 │ 250 │ 15000 │ │ 2019 │ 10 │ 60 │ 420 │ 25200 │ │ ... │ ... │ ... │ ... │ ... │ └──────┴───────┴───────┴──────────┴─────────┘
песочница
Мы хотим выбрать только те месяцы, выручка за которые превысила среднемесячную за год.
Для начала посчитаем среднемесячную выручку по годам:
select year, avg(revenue) as avg_rev from sales group by year;
┌──────┬─────────┐ │ year │ avg_rev │ ├──────┼─────────┤ │ 2019 │ 25125.0 │ │ 2020 │ 48625.0 │ └──────┴─────────┘
Теперь можно выбрать только те записи, revenue в которых не уступает avg_rev:
select
sales.year,
sales.month,
sales.revenue,
round(totals.avg_rev) as avg_rev
from sales
join (
select
year,
avg(revenue) as avg_rev
from sales
group by year
) as totals
on sales.year = totals.year
where sales.revenue >= totals.avg_rev;
┌──────┬───────┬─────────┬─────────┐ │ year │ month │ revenue │ avg_rev │ ├──────┼───────┼─────────┼─────────┤ │ 2019 │ 2 │ 39600 │ 25125.0 │ │ 2019 │ 5 │ 26400 │ 25125.0 │ │ 2019 │ 6 │ 32400 │ 25125.0 │ │ 2019 │ 7 │ 26400 │ 25125.0 │ │ ... │ ... │ ... │ ... │ └──────┴───────┴─────────┴─────────┘
Решили с помощью подзапроса:
- внутренний запрос считает среднемесячную выручку;
- внешний соединяется с ним и фильтрует результаты.


Запрос в целом получился сложноват. Если вернетесь к нему спустя месяц — наверняка потратите какое-то время на «распутывание». Проблема в том, что такие вложенные запросы приходится читать наоборот:
- найти самый внутренний запрос, осознать;
- мысленно присоединить к более внешнему;
- присоединить к следующему внешнему, и так далее.
Хорошо, когда вложенных уровня два, как в нашем примере. На практике же я часто встречаю трех- и четырехуровневые подзапросы. Форменное издевательство над читателем.
Решение
Вместо подзапроса можно использовать табличное выражение (common table expression, CTE). Любой подзапрос X:
select a, b, c from (X) where e = f
Механически превращается в CTE:
with cte as (X) select a, b, c from cte where e = f
В нашем примере:
with totals as (
select
year,
avg(revenue) as avg_rev
from sales
group by year
)
select
sales. year,
sales.month,
sales.revenue,
round(totals.avg_rev) as avg_rev
from sales
join totals on totals.year = sales.year
where sales.revenue >= totals.avg_rev;
 year,
sales.month,
sales.revenue,
round(totals.avg_rev) as avg_rev
from sales
join totals on totals.year = sales.year
where sales.revenue >= totals.avg_rev;
year,
sales.month,
sales.revenue,
round(totals.avg_rev) as avg_rev
from sales
join totals on totals.year = sales.year
where sales.revenue >= totals.avg_rev;
С табличным выражением запрос становится одноуровневым — так воспринимать его намного проще. Кроме того, табличное выражение можно переиспользовать в пределах запроса, как будто это обычная таблица:
with totals as (...) select ... from sales_ru join totals ... union all select ... from sales_us join totals ...
Табличные выражения SQL чем-то похожи на функции в обычном языке программирования — они уменьшают общую сложность:
- Можно написать нечитаемую простыню кода, а можно разбить код на понятные отдельные функции и составить программу из них.
- Можно возвести башню из пяти этажей подзапросов, а можно вынести подзапросы в CTE и составить общий запрос из них.
CTE против подзапроса
Существует миф, что «CTE медленные». Он пришел из старых версий PostgreSQL (11 и раньше), которые всегда материализовали CTE — вычисляли полный результат табличного выражения и запоминали до конца запроса.
Обычно это хорошо: один раз вычислил результат, и дальше используешь его несколько раз по ходу основного запроса. Но иногда материализация мешала движку оптимизировать запрос:
with cte as (select * from foo) select * from cte where id = 500000;
Здесь выбирается ровно одна запись по идентификатору, но материализация создает в памяти копию всей таблицы — из-за этого запрос отработает очень медленно.
PostgreSQL 12+ и другие современные СУБД поумнели и больше так не делают. Материализация применяется, когда от нее больше пользы, чем вреда. Плюс, многие СУБД позволяют явно управлять этим поведением через инструкции MATERIALIZED / NOT MATERIALIZED.
Так что CTE не медленнее подзапросов. А если сомневаетесь, всегда можно сделать два варианта — подзапрос и табличное выражение — и сравнить план и время выполнения.
Как понять, когда использовать подзапрос, а когда CTE? Я вывел для себя простое правило, которое пока ни разу не подвело:
Всегда использовать CTE
Чего и вам желаю.
Подписывайтесь на канал, чтобы не пропустить новые заметки 🚀
Пример записи информации в txt файл из SQL запроса — О системах планирования ресурсов предприятия Scala, iScala
Автор Алексей Васильев
По просьбе одного из участников публикую пример запроса для записи информации в текстовый файл.
Эта хранимая процедура сначала записывает во временную таблицу содержимое будущего XML файла, а затем пишет построчно это содержимое в файл. Файл дальше обрабатывается механизмом Epicor Service Connect.
Вы можете весь кусок, начиная с
exec('declare @RqNo nchar(10)
select @RqNo=PCR2001 from PCR2'+@CC+'00 (nolock)и по
INSERT INTO #XMLCONTENT exec(@SQL)
выкинуть, а ниже создаваемый курсор
declare @LINETEXT nvarchar(max) declare text_lines cursor for select * from #XMLCONTENT (nolock)
заменить на свой 🙂
Ниже полный текст хранимой процедуры:
CREATE procedure [dbo].
 [usr_CopyRequisitionLines]
@CC nchar(2)='TR',--Код компании
@ReqNo nchar(10)='0000011990',--Номер требования
@CATALOG_NAME varchar(255)='D:\TEMP'--Название каталога
as
declare @bFolder int
DECLARE @FS int, @OLEResult int, @FileID int
DECLARE @hr int, @source varchar(30), @desc varchar (200)
declare @TEXT_FILE_NAME varchar(255)
DECLARE @PATH_AND_FILE varchar(255)
-- Зададим имя файла с расширением .xml
set @TEXT_FILE_NAME='CopyRequisitionLines.xml'
-- ОПРЕДЕЛИМ ИМЯ ФАЙЛА С КАТАЛОГОМ
set @CATALOG_NAME =
case
when len(@CATALOG_NAME)>0 and left(reverse(@CATALOG_NAME),1)<>'\' then @CATALOG_NAME+'\'
else @CATALOG_NAME
end
set @PATH_AND_FILE = @CATALOG_NAME + '\' + @TEXT_FILE_NAME
print @PATH_AND_FILE
-- CREATE FSO-OBJECT
EXEC @OLEResult = sys.sp_OACreate 'Scripting.FileSystemObject', @FS OUTPUT
IF @OLEResult <> 0 GOTO Error_Handler
--проверить - существует ли заданная директория, для этого вызовем функцию 'FolderExists'
--ранее созданного OLE объекта--------------------------------------------------------
execute @OLEResult = sp_OAMethod @FS,'FolderExists',@bFolder OUT, @CATALOG_NAME
IF @OLEResult <> 0 Or @bFolder = 0
BEGIN
--а если не существует - то создать её--------------------------------------------
execute @OLEResult = sp_OAMethod @FS,'CreateFolder',@bFolder OUT, @CATALOG_NAME
IF @OLEResult <> 0 And @bFolder = 0
BEGIN
GOTO Error_Handler
END
END
-- CREATE FILE-OBJECT
EXEC @OLEResult = sys.
[usr_CopyRequisitionLines]
@CC nchar(2)='TR',--Код компании
@ReqNo nchar(10)='0000011990',--Номер требования
@CATALOG_NAME varchar(255)='D:\TEMP'--Название каталога
as
declare @bFolder int
DECLARE @FS int, @OLEResult int, @FileID int
DECLARE @hr int, @source varchar(30), @desc varchar (200)
declare @TEXT_FILE_NAME varchar(255)
DECLARE @PATH_AND_FILE varchar(255)
-- Зададим имя файла с расширением .xml
set @TEXT_FILE_NAME='CopyRequisitionLines.xml'
-- ОПРЕДЕЛИМ ИМЯ ФАЙЛА С КАТАЛОГОМ
set @CATALOG_NAME =
case
when len(@CATALOG_NAME)>0 and left(reverse(@CATALOG_NAME),1)<>'\' then @CATALOG_NAME+'\'
else @CATALOG_NAME
end
set @PATH_AND_FILE = @CATALOG_NAME + '\' + @TEXT_FILE_NAME
print @PATH_AND_FILE
-- CREATE FSO-OBJECT
EXEC @OLEResult = sys.sp_OACreate 'Scripting.FileSystemObject', @FS OUTPUT
IF @OLEResult <> 0 GOTO Error_Handler
--проверить - существует ли заданная директория, для этого вызовем функцию 'FolderExists'
--ранее созданного OLE объекта--------------------------------------------------------
execute @OLEResult = sp_OAMethod @FS,'FolderExists',@bFolder OUT, @CATALOG_NAME
IF @OLEResult <> 0 Or @bFolder = 0
BEGIN
--а если не существует - то создать её--------------------------------------------
execute @OLEResult = sp_OAMethod @FS,'CreateFolder',@bFolder OUT, @CATALOG_NAME
IF @OLEResult <> 0 And @bFolder = 0
BEGIN
GOTO Error_Handler
END
END
-- CREATE FILE-OBJECT
EXEC @OLEResult = sys. sp_OAMethod @FS,'CreateTextFile', @FileID OUTPUT, @PATH_AND_FILE, true, true
IF @OLEResult <> 0 GOTO Error_Handler
exec('declare @RqNo nchar(10)
select @RqNo=PCR2001 from PCR2'+@CC+'00 (nolock)
where PCR2001='''+@ReqNo+''' and PCR2037=''1''')
IF @@ROWCOUNT<>0
begin
create table #XMLCONTENT (
[LINETEXT] [nvarchar] (max) NOT NULL
)
declare @SQL nvarchar(max)
set @SQL='select ''<?xml version="1.0"?>
<msg:msg xsi:schemaLocation="http://Epicor.com/InternalMessage/1.1 http://scshost/schemas/Epicor/ScaInternalMsg.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:msg="http://Epicor.com/InternalMessage/1.1">
<msg:req tag="Requisition In">
<msg:dta>
<dta:Requisition xmlns:dta="http://www.scala.net/Requisition/1.1">
<dta:RqsnNum>''+convert(nchar(3),convert(int,isnull([MaxPrefix],''899''))+1)+substring(OLD.PCR1001,4,7)+''</dta:RqsnNum>
<dta:DeptCode>C''+replace(OLD.
sp_OAMethod @FS,'CreateTextFile', @FileID OUTPUT, @PATH_AND_FILE, true, true
IF @OLEResult <> 0 GOTO Error_Handler
exec('declare @RqNo nchar(10)
select @RqNo=PCR2001 from PCR2'+@CC+'00 (nolock)
where PCR2001='''+@ReqNo+''' and PCR2037=''1''')
IF @@ROWCOUNT<>0
begin
create table #XMLCONTENT (
[LINETEXT] [nvarchar] (max) NOT NULL
)
declare @SQL nvarchar(max)
set @SQL='select ''<?xml version="1.0"?>
<msg:msg xsi:schemaLocation="http://Epicor.com/InternalMessage/1.1 http://scshost/schemas/Epicor/ScaInternalMsg.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:msg="http://Epicor.com/InternalMessage/1.1">
<msg:req tag="Requisition In">
<msg:dta>
<dta:Requisition xmlns:dta="http://www.scala.net/Requisition/1.1">
<dta:RqsnNum>''+convert(nchar(3),convert(int,isnull([MaxPrefix],''899''))+1)+substring(OLD.PCR1001,4,7)+''</dta:RqsnNum>
<dta:DeptCode>C''+replace(OLD. PCR1003,''C'','''')+''</dta:DeptCode>
<dta:WhCode>''+OLD.PCR1006+''</dta:WhCode>
<dta:RqsnType>''+OLD.PCR1007+''</dta:RqsnType>
<dta:InitiateApprovalProcess>1</dta:InitiateApprovalProcess>
<dta:RqsnLines>'' as Text
from PCR1'+@CC+'00 (nolock) OLD
LEFT JOIN (select max(left(PCR1001,3)) as MaxPrefix, substring(PCR1001,4,7) as Suffix from PCR1'+@CC+'00 (nolock) where left(PCR1001,1)=''9'' group by substring(PCR1001,4,7)) PRFX ON substring(PCR1001,4,7)=Suffix
where OLD.PCR1001='''+@ReqNo+'''
union all
select ''
<dta:RqsnLine>
<dta:LineNum>''+OLD.PCR2002+''</dta:LineNum>
<dta:StockCode>''+replace(replace(replace(OLD.PCR2007,char(185),''1''),''&'',''&''),''"'',''"'')+''</dta:StockCode>
<dta:StockDescr>''+replace(replace(replace(OLD.PCR2008,char(185),''1''),''&'',''&''),''"'',''"'')+''</dta:StockDescr>
<dta:StockDescr2>''+replace(replace(replace(OLD.
PCR1003,''C'','''')+''</dta:DeptCode>
<dta:WhCode>''+OLD.PCR1006+''</dta:WhCode>
<dta:RqsnType>''+OLD.PCR1007+''</dta:RqsnType>
<dta:InitiateApprovalProcess>1</dta:InitiateApprovalProcess>
<dta:RqsnLines>'' as Text
from PCR1'+@CC+'00 (nolock) OLD
LEFT JOIN (select max(left(PCR1001,3)) as MaxPrefix, substring(PCR1001,4,7) as Suffix from PCR1'+@CC+'00 (nolock) where left(PCR1001,1)=''9'' group by substring(PCR1001,4,7)) PRFX ON substring(PCR1001,4,7)=Suffix
where OLD.PCR1001='''+@ReqNo+'''
union all
select ''
<dta:RqsnLine>
<dta:LineNum>''+OLD.PCR2002+''</dta:LineNum>
<dta:StockCode>''+replace(replace(replace(OLD.PCR2007,char(185),''1''),''&'',''&''),''"'',''"'')+''</dta:StockCode>
<dta:StockDescr>''+replace(replace(replace(OLD.PCR2008,char(185),''1''),''&'',''&''),''"'',''"'')+''</dta:StockDescr>
<dta:StockDescr2>''+replace(replace(replace(OLD. PCR2024,char(185),''1''),''&'',''&''),''"'',''"'')+''</dta:StockDescr2>
<dta:QtyOrdered unitName="''+rtrim(SCUN003)+''">''+convert(nvarchar,OLD.PCR2009)+''</dta:QtyOrdered>
</dta:RqsnLine>'' as Text
from PCR2'+@CC+'00 (nolock) OLD
join SCUN'+@CC+'00 (nolock)
on SCUN001=OLD.PCR2020 and SCUN002=''*''
where OLD.PCR2001='''+@ReqNo+''' and OLD.PCR2037=''1''
union all
select ''
</dta:RqsnLines>
</dta:Requisition>
</msg:dta>
<msg:ctx>
<SrvLocation/>
<UserName>ServiceConnect</UserName>
<UserPwd>******</UserPwd>
<CompanyCode>'+@CC+'</CompanyCode>
<FiscalYear>2018</FiscalYear>
<AllowRaisingBusinessEvents>1</AllowRaisingBusinessEvents>
<Options>
<!-- RqsnTemplateMode: defines if incoming data is processed as requisitions or requisition templates
0 = requisition mode (default)
1 = requisition template mode -->
<RqsnTemplateMode>0</RqsnTemplateMode>
<!-- AllowRqsnAdd: defines if adding new requisitions (requisition templates) is allowed
1 = allowed (default)
0 = not allowed -->
<AllowRqsnAdd>1</AllowRqsnAdd>
<!-- AllowRqsnChange: defines if changing existent requisitions (requisition templates) is allowed
1 = allowed (default)
0 = not allowed -->
<AllowRqsnChange>1</AllowRqsnChange>
<!-- AllowRqsnDelete: defines if deleting existent requisitions (requisition templates) is allowed
1 = allowed (default)
0 = not allowed -->
<AllowRqsnDelete>1</AllowRqsnDelete>
</Options>
</msg:ctx>
</msg:req>
</msg:msg>'' as Text'
INSERT INTO #XMLCONTENT
exec(@SQL)
declare @LINETEXT nvarchar(max)
declare text_lines cursor
for
select *
from #XMLCONTENT (nolock)
open text_lines
FETCH NEXT FROM text_lines
INTO @LINETEXT
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC @OLEResult = sys.
PCR2024,char(185),''1''),''&'',''&''),''"'',''"'')+''</dta:StockDescr2>
<dta:QtyOrdered unitName="''+rtrim(SCUN003)+''">''+convert(nvarchar,OLD.PCR2009)+''</dta:QtyOrdered>
</dta:RqsnLine>'' as Text
from PCR2'+@CC+'00 (nolock) OLD
join SCUN'+@CC+'00 (nolock)
on SCUN001=OLD.PCR2020 and SCUN002=''*''
where OLD.PCR2001='''+@ReqNo+''' and OLD.PCR2037=''1''
union all
select ''
</dta:RqsnLines>
</dta:Requisition>
</msg:dta>
<msg:ctx>
<SrvLocation/>
<UserName>ServiceConnect</UserName>
<UserPwd>******</UserPwd>
<CompanyCode>'+@CC+'</CompanyCode>
<FiscalYear>2018</FiscalYear>
<AllowRaisingBusinessEvents>1</AllowRaisingBusinessEvents>
<Options>
<!-- RqsnTemplateMode: defines if incoming data is processed as requisitions or requisition templates
0 = requisition mode (default)
1 = requisition template mode -->
<RqsnTemplateMode>0</RqsnTemplateMode>
<!-- AllowRqsnAdd: defines if adding new requisitions (requisition templates) is allowed
1 = allowed (default)
0 = not allowed -->
<AllowRqsnAdd>1</AllowRqsnAdd>
<!-- AllowRqsnChange: defines if changing existent requisitions (requisition templates) is allowed
1 = allowed (default)
0 = not allowed -->
<AllowRqsnChange>1</AllowRqsnChange>
<!-- AllowRqsnDelete: defines if deleting existent requisitions (requisition templates) is allowed
1 = allowed (default)
0 = not allowed -->
<AllowRqsnDelete>1</AllowRqsnDelete>
</Options>
</msg:ctx>
</msg:req>
</msg:msg>'' as Text'
INSERT INTO #XMLCONTENT
exec(@SQL)
declare @LINETEXT nvarchar(max)
declare text_lines cursor
for
select *
from #XMLCONTENT (nolock)
open text_lines
FETCH NEXT FROM text_lines
INTO @LINETEXT
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC @OLEResult = sys. sp_OAMethod @FileID, 'Write', NULL, @LINETEXT
--print @str
FETCH NEXT FROM text_lines
INTO @LINETEXT
end
CLOSE text_lines
DEALLOCATE text_lines
select 'Lines are copied' as Text
end
else
begin
select 'No lines to copy' as Text
end
GOTO Done -- EXIT PROCEDURE
Error_Handler:
EXEC @hr = sys.sp_OAGetErrorInfo null, @source OUT, @desc OUT
SELECT hr = CONVERT (binary(4), @hr), source = @source, description = @desc
Done:
EXEC @OLEResult = sys.sp_OADestroy @FileID
EXEC @OLEResult = sys.sp_OADestroy @FS
RETURN @@error + @OLEResult
sp_OAMethod @FileID, 'Write', NULL, @LINETEXT
--print @str
FETCH NEXT FROM text_lines
INTO @LINETEXT
end
CLOSE text_lines
DEALLOCATE text_lines
select 'Lines are copied' as Text
end
else
begin
select 'No lines to copy' as Text
end
GOTO Done -- EXIT PROCEDURE
Error_Handler:
EXEC @hr = sys.sp_OAGetErrorInfo null, @source OUT, @desc OUT
SELECT hr = CONVERT (binary(4), @hr), source = @source, description = @desc
Done:
EXEC @OLEResult = sys.sp_OADestroy @FileID
EXEC @OLEResult = sys.sp_OADestroy @FS
RETURN @@error + @OLEResultНе забудьте посмотреть заметку «SQL Server: OLE Automation Procedures», а также комментарии ниже списка опубликованных процедур.
Список опубликованных процедур:
- Как организовать рассылку напоминаний о просроченной задолженности?
- Как настроить Service Connect для автоматического импорта Заказов на Закупку из XLS файла?
- Как сделать многоуровневое утверждение заявок с помощью механизма отчётов MS SQL Server Reporting Services?
- Как создать и привязать к полю составной (иерархический) быстрый поиск (Composite Snap Search)?
- Как добавить шаблон документа для выходного канала MSRS?
- Имеется отчёт AFR для одной из компаний группы, он подходит для всех остальных компаний. Как его распространить?
- Как сделать отчёт с бюджетами для iScala по дням?
- Как сделать отчёт с бюджетами по дням? Варианты 1 и 2
- Как сделать отчёт с бюджетами по дням? Отдельная «бюджетная» компания
- Использование внешней таблицы с первичными данными. Как сделать отчёт с бюджетами по дням?
- Как сделать отчёт AFR в 2-х валютах с пересчётом по фиксированному курсу?
- How can I create an AFR report in 2 currencies using fixed rate?
- How to create AFR report with daily budgets from iScala?
- Usage of external tables with primary data. How to design Daily Budget Report.
- Как установить и каким образом можно использовать значение минимально допустимого остатка на складе?
- Как перенести отчёт MS SQL Server Reporting Services на другой сервер?
- Как получить, отредактировать и обновить отчёт MS SQL Server Reporting Services?
- Как сделать отчёт AFR в разных валютах с пересчётом по фиксированному курсу и выбором валюты?
- Как дать доступ к отчётам SQL Server Reporting Services?
- Как создать виртуальную машину для изучения MS SQL Server Reporting Services?
- Установка Microsoft SQL Server 2014 Express для будущей работы с iScala
- Добавление Microsoft SQL Server Data Tools — Business Intelligence for Visual Studio 2013 к текущей инсталляции MS SQL Server 2014 Express
- Бэкап SQL 2008 R2 не восстановить на SQL 2008, что делать?
- Пытаемся перетащить бэкап SQL 2008 R2 на SQL 2008
- Пытаемся перетащить бэкап SQL 2008 R2 на SQL 2008 — шаг 2
- Пытаемся перетащить бэкап SQL 2008 R2 на SQL 2008 — шаг 3
- Пример записи информации в txt файл из SQL запроса
- SQL Server: OLE Automation Procedures
- Как проконтролировать ввод новых, изменения и удаления существующих карточек покупателей, поставщиков, запасов?
- «Если это невозможно сделать, но очень хочется?» или «Как ввести примечание к строке требования?»
- Как разграничить доступ пользователей на сервере отчётов?
- How to delimit user access on the Reporting Server?
- Имеется шаблонная настройка для одной из компаний группы, она подходит для всех остальных компаний. Как её распространить?
- Выверяем данные между модулями УЗ и ГК
- Список проводок по запасам, для которых не созданы проводки ГК
- Проверяем отсутствие пропусков складских проводок и наличия других «вмешательств»
- Проводки истории Журнала Главной Книги модуля УЗ, имеющие иной период, чем в ГК
- Проводки ГК по счетам учёта запасов не из модуля УЗ
- Несоответствие истории проводок ГК модуля УЗ автоучёту
- Проводки ГК без соответствующих аналитических проводок
- How to add a document template for MSRS Output Channel
- Как зафиксировать заголовок отчёта на сервере отчётов (SSRS)?
- Многоуровневое утверждение заявок в Epicor iScala: как это работает? Доклад на конференции клиентов Эпикор в Москве 12.09.2017
- Multi Level Approvals for Requisitions: How it works?
- Как с помощью T-SQL прочитать список файлов в выбранной папке и отфильтровать нужные?
- Жизнь на Марсе есть! или Для модуля «Заработная плата» канал MSRS использовать можно, проверено!
- Электронные счета-фактуры как требования российского законодательства: доклад на конференции клиентов Эпикор 23. 05.2013
- Как создать макрос в Excel и добавить его в меню надстроек?
- Как создать виртуальную машину VM Ware с ознакомительной версией Windows Server 2016 или Windows Server 2019?
- Как пользоваться сервером отчётности MS SQL Server Reporting Services (SSRS)?
- Как установить SQL Server Data Tools (SSDT) для Visual Studio 2019 и добавить проект Report Server?
- Что должно быть настроено в системе, чтобы при печати счетов-фактур в модуле «Заказы на Продажу» создавались XML файлы? / What should be configured in the system if we want XML files to be created when printing invoices in the Sales Orders module?
- Как автоматически загрузить курсы валют с сайта ЦБР?
- Как автоматически загрузить акт или УПД поставщика из системы ЭДО?
- Как совместить старую версию Scala/iScala с ЭДО?
- Как создать новый выходной канал для сохранения файла в папку EDI?
- Как проверить работоспособность рабочего потока Epicor Service Connect?
- Как установить и подключить готовый рабочий поток Epicor Service Connect?
- Как изменить настройки выходного канала для печати?
- Как организовать автоматическое создание проводок для массового списания основных средств?
- Как проверить соответствие исходящего сальдо предыдущего года и входящего сальдо текущего года?
- Как сделать вывод логотипа зависимым от кода компании?
 Как его распространить?
Как его распространить? Как её распространить?
Как её распространить? 05.2013
05.2013Агрегированные функции SQL: SUM(), COUNT(), AVG(), Functions
Агрегатная функция в SQL выполняет вычисление нескольких значений и возвращает одно значение. SQL предоставляет множество агрегатных функций, включая среднее, подсчет, сумму, минимум, максимум и т. д. Агрегатная функция игнорирует значения NULL при выполнении вычислений, за исключением функции подсчета.
SQL предоставляет множество агрегатных функций, включая среднее, подсчет, сумму, минимум, максимум и т. д. Агрегатная функция игнорирует значения NULL при выполнении вычислений, за исключением функции подсчета.
Что такое агрегатная функция в SQL?
Агрегатная функция в SQL возвращает одно значение после вычисления нескольких значений столбца. Мы часто используем агрегатные функции с предложениями GROUP BY и HAVING оператора SELECT.
Различные типы агрегатных функций SQL:
- Счет()
- Сумма()
- Среднее()
- Мин()
- Макс()
Ссылки на столбцы
В SQL агрегатные функции используются для вычисления набора значений и возврата одного значения. При использовании агрегатных функций в SQL очень важно понимать ссылки на столбцы. Ссылка на столбец — это имя, содержащее данные, которые вы хотите агрегировать. Чтобы использовать агрегатную функцию со ссылкой на столбец, укажите имя столбца в скобках функции.
Например, чтобы найти среднюю заработную плату сотрудников в таблице «сотрудники», можно использовать функцию AVG со ссылкой на столбец «зарплата» следующим образом:
ВЫБЕРИТЕ СРЕДНЮЮ (зарплата)
ОТ сотрудников;
Использование псевдонимов столбцов вместо ссылок на столбцы также возможно для более читаемого кода. Однако понимание ссылок на столбцы необходимо при работе с агрегатными функциями SQL.
Зачем использовать агрегатные функции?
Агрегированные функции являются жизненно важным компонентом систем управления базами данных. Они позволяют нам быстро и эффективно выполнять вычисления на больших наборах данных. Например, эти функции создают статистические отчеты, выполняют финансовый анализ и управляют уровнями запасов.
Кроме того, мы можем лучше понять данные, с которыми работаем, используя агрегатные функции.
Например, мы можем легко рассчитать среднюю цену всех товаров в нашем инвентаре или найти общий объем продаж за определенное время. Без агрегатных функций нам пришлось бы вручную сортировать каждую точку данных, что отнимало бы много времени и чревато ошибками.
Без агрегатных функций нам пришлось бы вручную сортировать каждую точку данных, что отнимало бы много времени и чревато ошибками.
В целом, агрегатные функции важны для всех, кто работает с большими объемами данных и хочет извлечь из них ценную информацию.
СЧЕТ() Функция
Функция COUNT() возвращает количество строк в таблице базы данных.
Синтаксис:
СЧЁТ(*)
или
COUNT(выражение [ALL|DISTINCT] )
Пример:
Для демонстрации мы будем использовать таблицу «products» из примера базы данных.
Следующая инструкция SQL извлекает количество продуктов в таблице.
Это приведет к следующему результату.
Приведенная ниже команда отобразит те идентификаторы продуктов, цена за единицу которых больше 4.
Это покажет следующий результат.
Давайте посмотрим, как мы можем использовать функции GROUP BY и HAVING с функцией COUNT.
Рассмотрим следующий набор данных:
Приведенная ниже команда SQL выведет список клиентов в каждом городе.
Это даст следующие результаты:
Читайте также: Полное руководство по основам SQL
Функция SUM()
Функция SUM() возвращает общую сумму числового столбца.
Синтаксис:
СУММ()
или
СУММ(выражение [ALL|DISTINCT] )
Пример:
Следующая инструкция SQL находит сумму полей «цена за единицу» в таблице «продукты»:
Это приведет к следующему результату.
Давайте посмотрим, как мы можем использовать функции GROUP BY и HAVING с функцией SUM.
Рассмотрим следующий набор данных:
Приведенная ниже команда SQL выведет список клиентов в каждом городе, сумма баллов которых превышает 3000.
Это даст следующий результат:
Функция AVG()
Функция AVG() вычисляет среднее значение набора значений.
Синтаксис:
АВГ()
или
AVG(выражение [ALL|DISTINCT] )
Пример:
Следующая команда SQL вычисляет среднее количество на складе.
Это приведет к следующему результату.
МИН() Функция
Агрегатная функция MIN() возвращает наименьшее значение (минимум) в наборе значений, отличных от NULL.
Синтаксис:
МИН()
или
МИН(выражение [ALL|DISTINCT] )
Пример:
Приведенный выше код даст нам минимальное количество на складе в таблице продуктов.
Читайте также: Как агрегировать данные с помощью группировки в SQL?
Функция МАКС()
Агрегатная функция MAX() возвращает наибольшее значение (максимум) в наборе значений, отличных от NULL.
Синтаксис:
АВГ()
или
AVG(выражение [ALL|DISTINCT] )
Пример:
Код, изображенный ниже, даст нам максимальное количество на складе в таблице продуктов.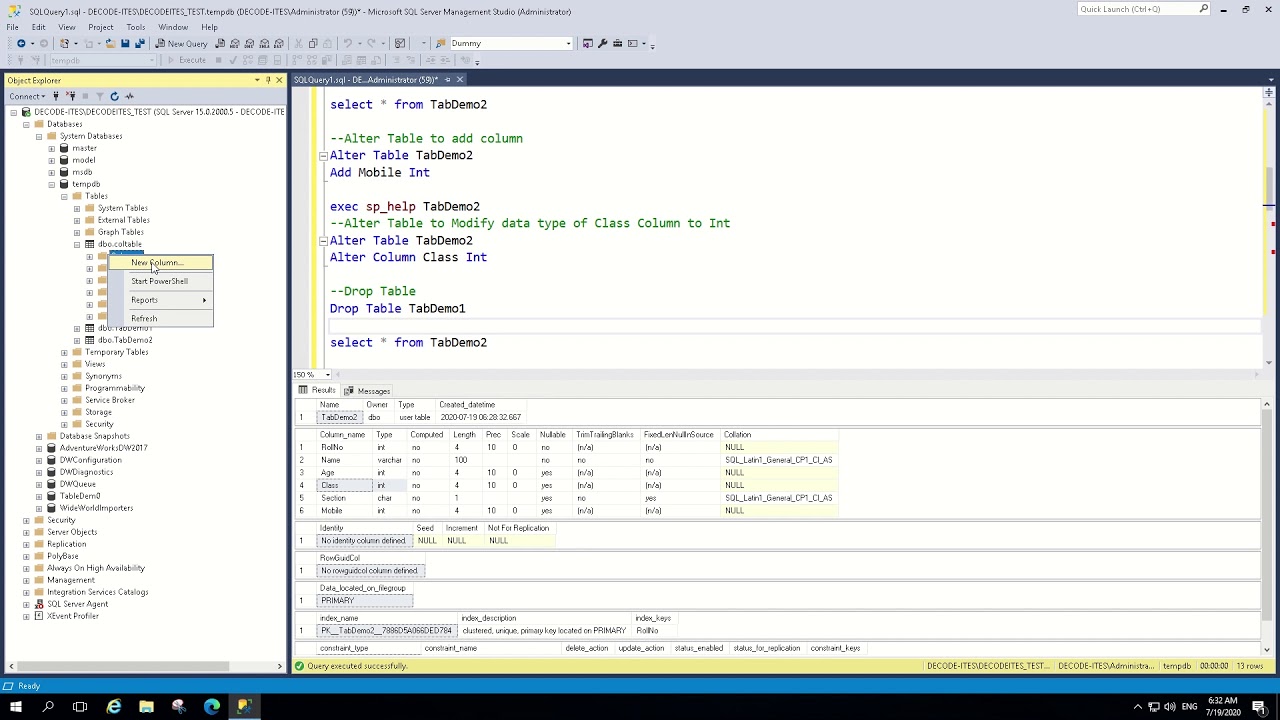
Это приведет к следующему результату.
Синтаксис агрегатной функции SQL Server
Агрегатные функции SQL Server
используются для вычисления набора значений и возврата одного значения. Эти функции обычно используются в SQL-запросах для обобщения данных и получения ценной информации. Синтаксис использования агрегатных функций в SQL Server прост.
Синтаксис агрегатной функции в SQL Server следующий:
ВЫБЕРИТЕ агрегатную_функцию (имя_столбца)
ОТ имя_таблицы
[ГДЕ условие];
Эти функции полезны при работе с большими наборами данных, поскольку они могут помочь упростить и ускорить процесс анализа. SUM, COUNT, AVG и MAX — часто используемые агрегатные функции.
Таким образом, понимание синтаксиса агрегатных функций SQL Server очень важно для всех, кто работает с базами данных и хочет эффективно анализировать данные.
APPROX_COUNT_DISTINCT
Агрегатная функция SQL APPROX_COUNT_DISTINCT оценивает количество уникальных значений, присутствующих в определенном столбце таблицы. Эта функция удобна в тех случаях, когда не требуется точного подсчета различных значений и достаточно приблизительной оценки. Кроме того, это удобно при работе с большими наборами данных, где расчет точного количества может занимать много времени и ресурсов.
Эта функция удобна в тех случаях, когда не требуется точного подсчета различных значений и достаточно приблизительной оценки. Кроме того, это удобно при работе с большими наборами данных, где расчет точного количества может занимать много времени и ресурсов.
Функция APPROX_COUNT_DISTINCT использует статистические алгоритмы для оценки количества различных значений. В результате оценка, предоставляемая этой функцией, может быть частично точной, но обычно она находится в приемлемом диапазоне для большинства случаев использования.
В целом, функция APPROX_COUNT_DISTINCT является ценным дополнением к любому инструментарию разработчика SQL, предлагая удобный способ быстро и эффективно оценить количество различных значений в столбце.
Синтаксис:
APPROX_COUNT_DISTINCT (выражение)
СРЕДНИЙ
AVG — это агрегатная функция SQL, используемая для вычисления среднего значения набора числовых значений в таблице или столбце. Эта функция особенно полезна в задачах анализа данных, где необходимо определить среднее значение определенного набора данных. Функцию AVG можно использовать вместе с другими агрегатными функциями SQL, такими как COUNT, SUM, MAX и MIN.
Функцию AVG можно использовать вместе с другими агрегатными функциями SQL, такими как COUNT, SUM, MAX и MIN.
Одним из ключевых преимуществ использования AVG является то, что он может помочь выявить выбросы в наборе данных, значения которых значительно выше или ниже среднего. Выявляя эти выбросы, аналитики данных могут получить ценную информацию о распределении данных и принимать более обоснованные решения на основе полученных сведений.
Итак, AVG — это мощная функция SQL, которая может выполнять широкий спектр задач анализа данных, что делает ее важным инструментом для всех, кто работает с большими наборами данных в системе управления базами данных.
Синтаксис:
AVG (выражение [ALL | DISTINCT] )
[ПЕРЕВЕРНИТЕ ([partition_by_clause] order_by_clause )]
КОНТРОЛЬНАЯ СУММА_AGG
CHECKSUM_AGG — это агрегатная функция SQL, которая генерирует хэш-значение для заданного набора данных. Эта функция принимает столбец или выражение в качестве входных данных и возвращает одно значение контрольной суммы, представляющее данные в этом столбце или выражении. Значение контрольной суммы — это целое число, которое можно использовать для сравнения двух наборов данных на равенство или для обнаружения изменений в данных.
Значение контрольной суммы — это целое число, которое можно использовать для сравнения двух наборов данных на равенство или для обнаружения изменений в данных.
CHECKSUM_AGG часто используется в хранилищах данных и других приложениях, где важна целостность данных. Это мощный инструмент для обнаружения изменений данных и обеспечения точности и актуальности данных в базе данных.
Синтаксис:
CHECKSUM_AGG ([ALL | DISTINCT] выражение)
COUNT_BIG
COUNT_BIG — это агрегатная функция SQL, используемая для подсчета количества строк в таблице. Эта функция похожа на функцию COUNT, но возвращает тип данных bigint вместо int. Функция COUNT_BIG полезна при подсчете больших наборов данных, в которых количество строк превышает максимальное значение типа данных int. Эту функцию можно использовать с другими функциями SQL для выполнения сложных запросов и анализа. Синтаксис COUNT_BIG прост, что упрощает его включение в операторы SQL.
Синтаксис:
COUNT_BIG ({[[ALL | DISTINCT] выражение] | *})
ГРУППА
Одной из наиболее часто используемых агрегатных функций в SQL является функция GROUP BY. Эта функция позволяет группировать строки данных на основе одного или нескольких столбцов, а затем выполнять агрегированные вычисления для каждой группы. Например, вы можете использовать функцию ГРУППИРОВАТЬ ПО, чтобы сгруппировать данные о продажах по месяцам или регионам, а затем рассчитать общий объем продаж для каждой группы. Функция GROUP BY обычно используется с другими агрегатными функциями, такими как COUNT, SUM, AVG и MAX/MIN. Используя функцию GROUP BY, вы можете быстро анализировать большие наборы данных и осмысленно обобщать результаты.
Эта функция позволяет группировать строки данных на основе одного или нескольких столбцов, а затем выполнять агрегированные вычисления для каждой группы. Например, вы можете использовать функцию ГРУППИРОВАТЬ ПО, чтобы сгруппировать данные о продажах по месяцам или регионам, а затем рассчитать общий объем продаж для каждой группы. Функция GROUP BY обычно используется с другими агрегатными функциями, такими как COUNT, SUM, AVG и MAX/MIN. Используя функцию GROUP BY, вы можете быстро анализировать большие наборы данных и осмысленно обобщать результаты.
Синтаксис:
ГРУППИРОВКА ( <выражение_столбца> )
GROUPING_ID
GROUPING_ID — это агрегатная функция SQL, которая определяет уровень группировки строки в операторе SELECT. Он возвращает уникальное целочисленное значение, представляющее уровень группировки строки. Значение, возвращаемое GROUPING_ID, основано на столбцах группировки, используемых в предложении GROUP BY оператора SELECT. Функция возвращает 0 для строк, не входящих ни в одну группу, и ненулевое значение для строк, входящих в группу.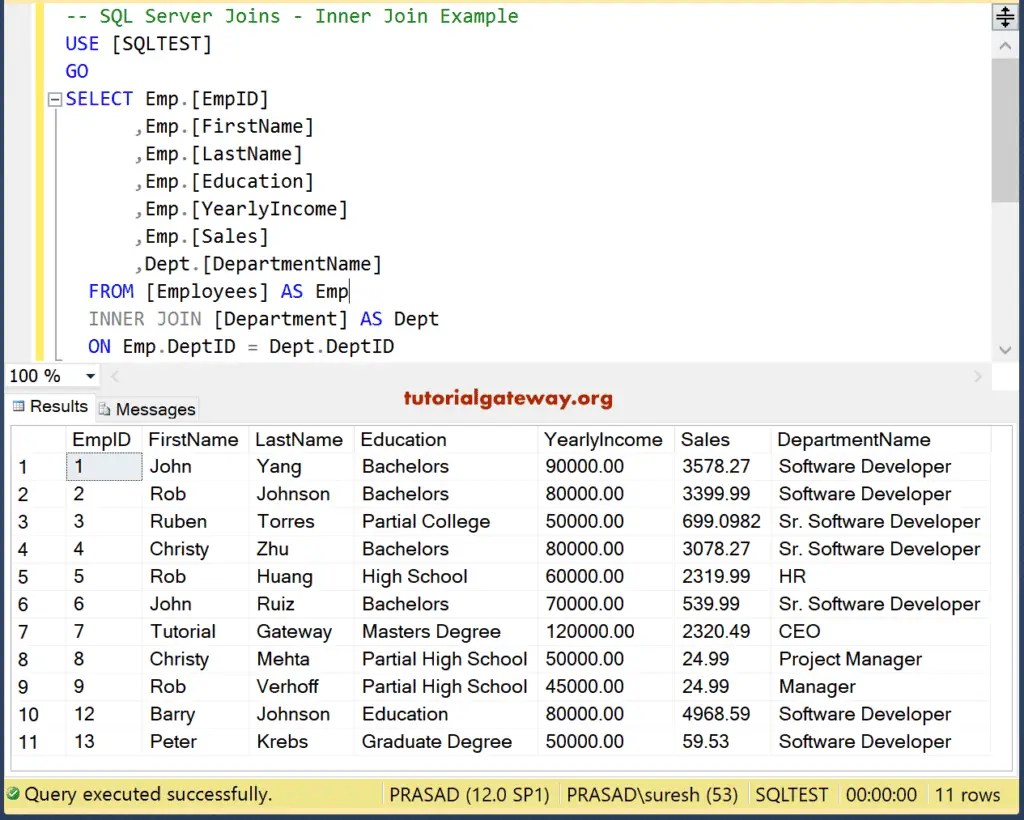
GROUPING_ID — мощная функция, которую можно использовать для выполнения сложных агрегаций на больших наборах данных. Это позволяет пользователям легко группировать данные таким образом, чтобы это имело смысл для их анализа, и определять уровень группировки для каждой строки. Эта функция удобна для аналитиков данных и специалистов по бизнес-аналитике, которые выполняют сложные вычисления с большими наборами данных.
Синтаксис:
GROUPING_ID ( <выражение_столбца>[…n] )
СТАНДОТКЛОН
СТАНДОТКЛОН (стандартное отклонение) — это важная агрегатная функция SQL, используемая для измерения вариации или дисперсии в наборе данных. Он вычисляет квадратный корень из дисперсии и является ценным инструментом для анализа тенденций данных. И это также может помочь в выявлении выбросов в наборе данных. Функция STDEV обычно используется в статистическом анализе, интеллектуальном анализе данных и науке о данных. Поняв, как использовать функцию СТАНДОТКЛОН, вы сможете получить ценную информацию о своих данных и принимать более обоснованные решения.
Синтаксис:
СТАНДОТКЛОН ([ALL | DISTINCT] выражение)
СТДЕВП
STDEVP — это агрегатная функция SQL, которая вычисляет стандартное отклонение генеральной совокупности для заданного набора значений. Эта функция часто используется в статистическом анализе для определения степени изменчивости или дисперсии набора данных. Функция STDEVP принимает числовые значения в качестве входных данных и возвращает одно значение, представляющее стандартное отклонение всей совокупности.
Эта функция полезна во многих приложениях, таких как финансы, инженерия и научные исследования. Важно отметить, что функция СТАНДОТКЛОН отличается от функции СТАНДОТКЛОН тем, что СТАНДОТКЛОН вычисляет стандартное отклонение выборки, а СТАНДОТКЛОН вычисляет стандартное отклонение генеральной совокупности.
В целом, STDEVP — это мощный инструмент SQL, который может помочь аналитикам и разработчикам получить ценную информацию о своих наборах данных.
Синтаксис:
STDEVP (выражение [ALL | DISTINCT])
STRING_AGG
STRING_AGG — это мощная агрегатная функция SQL, которая объединяет строки из нескольких строк в одну строку. Эта функция удобна, когда вам необходимо сгруппировать данные и отобразить их в удобочитаемом формате. Функция STRING_AGG доступна в большинстве современных систем управления базами данных SQL, включая Microsoft SQL Server, PostgreSQL и MySQL. С помощью этой функции вы можете легко объединять значения из нескольких строк в один столбец, разделенные указанным разделителем. Эта возможность упрощает создание отчетов, сводок и других визуализаций данных, требующих объединения данных из нескольких строк в одну строку.
Эта функция удобна, когда вам необходимо сгруппировать данные и отобразить их в удобочитаемом формате. Функция STRING_AGG доступна в большинстве современных систем управления базами данных SQL, включая Microsoft SQL Server, PostgreSQL и MySQL. С помощью этой функции вы можете легко объединять значения из нескольких строк в один столбец, разделенные указанным разделителем. Эта возможность упрощает создание отчетов, сводок и других визуализаций данных, требующих объединения данных из нескольких строк в одну строку.
В целом, STRING_AGG — бесценный инструмент для любого разработчика SQL или администратора базы данных, стремящегося оптимизировать свои процессы управления данными и создания отчетов.
Синтаксис:
STRING_AGG (выражение, разделитель) [
ВНУТРИ ГРУППЫ (ORDER BY
ВАР
Функция VAR — это мощный инструмент для анализа данных, и ее можно использовать в сочетании с другими функциями SQL для анализа больших наборов данных. Чтобы использовать функцию VAR в SQL, вы предоставляете столбец или выражение, содержащее значения, для которых вы хотите вычислить дисперсию. Результатом функции VAR является десятичное значение, представляющее дисперсию набора данных.
Чтобы использовать функцию VAR в SQL, вы предоставляете столбец или выражение, содержащее значения, для которых вы хотите вычислить дисперсию. Результатом функции VAR является десятичное значение, представляющее дисперсию набора данных.
Синтаксис:
VAR ([ALL | DISTINCT] выражение)
ВАРП
VARP, или дисперсионная совокупность, представляет собой агрегатную функцию SQL, используемую для расчета дисперсии заданного набора значений. Эта функция полезна, когда вы хотите проанализировать распространение данных в популяции. Вы также можете использовать этот процесс в сочетании с другими статистическими функциями SQL, такими как SUM, AVG и COUNT, для выполнения более сложных вычислений.
VARP — это мощный инструмент для анализа данных, который обычно используется в финансах, статистике и других областях, где необходимо анализировать большие объемы данных. Однако важно отметить, что VARP отличается от VAR, который представляет собой выборочную дисперсию. VARP вычисляет дисперсию всего населения, а VAR вычисляет дисперсию выборки населения.
VARP вычисляет дисперсию всего населения, а VAR вычисляет дисперсию выборки населения.
Синтаксис:
VARP ([ALL | DISTINCT] выражение)
ДИАПАЗОН
Функция RANGE — одна из важнейших агрегатных функций в SQL. А функция RANGE вычисляет диапазон набора значений. Диапазон — это разница между самым заметным и самым маленьким значениями набора.
Например, если набор значений содержит 5, 10, 15, 20 и 25, диапазон будет равен 20 (25-5). Функция RANGE обычно используется в статистическом анализе для измерения разброса данных.
Итак, функция RANGE — это мощный инструмент в SQL, который позволяет вам статистически анализировать ваши данные. Рассчитав диапазон ваших данных, вы можете получить представление о распространении и распределении ваших данных.
НАНМЕАН
NANMEAN — это агрегатная функция SQL, используемая для вычисления среднего значения набора чисел. Функция вычисляет средние значения, исключая любые значения NULL в наборе данных. Функция NANMEAN удобна при работе с большими наборами данных, содержащими отсутствующие или неполные данные. Исключая значения NULL из расчета, функция обеспечивает более точное представление данных.
Функция NANMEAN удобна при работе с большими наборами данных, содержащими отсутствующие или неполные данные. Исключая значения NULL из расчета, функция обеспечивает более точное представление данных.
Выход функции NANMEAN представляет собой одно значение, представляющее среднее значение ненулевых значений в наборе данных. Эта функция широко используется при анализе данных и является ценным инструментом для анализа сложных наборов данных.
МЕДИАНА
Медиана — это статистическая мера, представляющая медианное значение набора данных. В SQL медиану можно вычислить с помощью функции median(), агрегатной функции, которая возвращает медианное значение группы значений.
Синтаксис функции median() в SQL следующий:
ВЫБЕРИТЕ МЕДИАНУ (имя_столбца)
ОТ имя_таблицы
Здесь имя_столбца представляет имя столбца, содержащего значения, для которых необходимо вычислить медиану, а имя_таблицы представляет имя таблицы, содержащей данные.
Функцию median() можно комбинировать с другими агрегатными функциями, такими как COUNT, SUM, AVG и т. д., для выполнения более сложных вычислений с данными. В целом, функция median() в SQL является мощным инструментом для анализа данных и может предоставить ценную информацию о распределении данных в наборе данных.
д., для выполнения более сложных вычислений с данными. В целом, функция median() в SQL является мощным инструментом для анализа данных и может предоставить ценную информацию о распределении данных в наборе данных.
РЕЖИМ
Одной из наиболее часто используемых агрегатных функций является функция MODE. Функция MODE возвращает наиболее часто встречающееся значение в наборе значений. Эта функция удобна при работе с большими наборами данных, где необходимо выявить наиболее часто встречающиеся значения. Синтаксис функции MODE довольно прост. Функция принимает один параметр — имя столбца, содержащего анализируемые значения.
Синтаксис функции РЕЖИМ следующий:
РЕЖИМ (имя_столбца).
В целом, функция MODE является мощным инструментом для анализа данных в SQL и может использоваться в различных контекстах для выявления закономерностей и тенденций.
Заключение
Агрегатная функция в SQL очень эффективна в базе данных. Он служит той же цели, что и их эквиваленты в MS Excel. В этой статье мы видели несколько примеров агрегатных функций.
В этой статье мы видели несколько примеров агрегатных функций.
Если вы хотите узнать больше о SQL, ознакомьтесь с нашей программой последипломного образования в области полнофункциональной веб-разработки.
Этот сертификационный курс SQL поможет вам правильно освоить основы с помощью практического обучения, необходимого для работы с базами данных SQL и их использования в приложениях, которые вы используете или создаете. По завершении курса у вас будет готовое к работе понимание того, как правильно структурировать вашу базу данных, создавать безошибочные и эффективные операторы и предложения SQL, а также проектировать и управлять своими базами данных SQL для масштабируемого роста.
Если у вас есть какие-либо вопросы, задавайте их в разделе комментариев, и наши специалисты оперативно ответят на них.
Следующая статья
функций SQL с примерами | Встроенные функции
SQL представляют собой предварительно написанные действия, которые можно вызывать для отдельных ячеек, нескольких ячеек в записи или нескольких записей.
3 типа функций SQL, определенные
Агрегатные функции SQL используются для суммирования набора значений и возврата одного значения.
Скалярные функции SQL — это определяемые пользователем или встроенные функции, которые принимают один или несколько параметров и возвращают одно значение.
Символьные функции SQL представляют собой тип скалярной функции, используемой для управления и преобразования символьных данных, таких как строки.
Существует два основных типа функций SQL: агрегатные и скалярные функции.
Еще от Макса РейнольдсаОбъяснение различий между SOQL и SQL
Агрегированные функции
Агрегированные функции используются для суммирования набора значений и возврата одного значения. Общие агрегатные функции включают COUNT , СУММ , СРЕДНЕЕ , МИН и МАКС . Эти функции можно использовать для быстрого расчета таких статистических данных, как количество строк в таблице, общее значение определенного столбца, среднее значение столбца, минимальное или максимальное значение в столбце или любая из этих статистических данных по условное подмножество записей.
Например, рассмотрим таблицу «Погода» со следующими столбцами:
- «Город» (varchar)
- «Штат» (varchar)
- «Weather_Date» (дата)
- «High_Temperature» (целое)
- «Low_Temperature» (целое)
- «Осадки» (float)
- «Description» (varchar) 900 12
AVG
Использование «Погода» , мы могли бы использовать функцию AVG для расчета средней максимальной температуры за все дни в таблице:
или средней высокой температуры за все дни в Финиксе.
СЧЕТ
Мы можем использовать функцию COUNT для подсчета количества записей в таблице:
или количество дождливых дней в Финиксе.
MIN/MAX
Мы можем использовать агрегатную функцию MIN , чтобы найти самую низкую зарегистрированную температуру:
и функцию MAX , чтобы найти самую высокую температуру в таблице:
Мы также можем используйте Предложение GROUP BY , чтобы сгруппировать записи в таблице по городам, а затем использовать агрегатные функции для нахождения суммы, средней, минимальной и максимальной высокой температуры для каждого города:
Скалярные функции
Скалярные функции — это определяемые пользователем или встроенные функции, которые принимают один или несколько параметров и возвращают одно значение. Скалярные функции можно использовать в предложениях
Скалярные функции можно использовать в предложениях SELECT , WHERE и HAVING для преобразования данных или выполнения над ними вычислений.
Пользовательские скалярные функции
Мы можем создать скалярную функцию для преобразования температуры из градусов Фаренгейта в градусы Цельсия, используя следующий код SQL:
Затем мы можем использовать эту скалярную функцию в операторе SELECT для отображения температуры в градусах Цельсия:
Другой пример: мы можем создать скалярную функцию для проверки того, шел ли дождь в определенный день, используя следующий SQL:
Затем мы можем использовать эту скалярную функцию в операторе SELECT , чтобы показать, шел ли дождь в определенный день:
Обратите внимание, что скалярные функции также могут принимать несколько параметров и обычно могут использоваться в WHERE , GROUP BY и HAVING .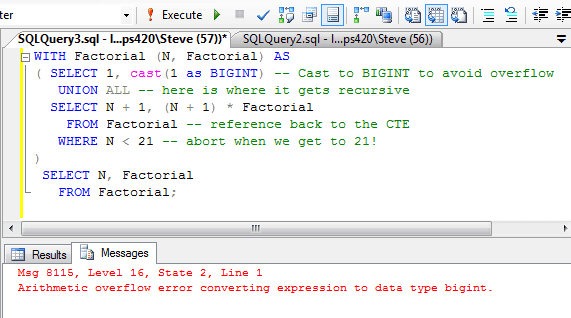 Кроме того, синтаксис пользовательских функций немного различается в разных системах управления базами данных (например, MySQL, SQL Server, PostgreSQL и т. д.).
Кроме того, синтаксис пользовательских функций немного различается в разных системах управления базами данных (например, MySQL, SQL Server, PostgreSQL и т. д.).
Символьные функции
В SQL символьные функции представляют собой тип скалярной функции, используемой для управления и преобразования символьных данных, таких как строки. Вот некоторые примеры символьных функций в SQL:
CONCAT
Эта функция CONCAT объединяет две или более строк. Например, мы можем использовать CONCAT для объединения столбцов города и штата в нашей таблице «Погода» :
LENGTH
Функция длины возвращает количество символов в строке. Например, мы можем использовать ДЛИНА , чтобы найти количество символов в столбце города:
ВЕРХНИЙ/НИЖНИЙ
ВЕРХНИЙ и LOWER functions переводит все символы строки в верхний регистр. Например, мы могли бы использовать LOWER для отображения названий городов в верхнем регистре:
Если столбец city имеет непоследовательный регистр заглавных букв, мы могли бы использовать UPPER в предложении GROUP BY .
SUBSTRING
Функция SUBSTRING возвращает часть строки, заданную начальной позицией и длиной. Например, мы могли бы использовать SUBSTRING для возврата первых трех символов названия города:
Параметры метода SUBSTRING — это строка, начальный символ ( 1 ) и длина подстроки ( 3 ).
REPLACE
Функция REPLACE заменяет все вхождения указанной строки другой строкой. Например, мы могли бы использовать ЗАМЕНИТЬ , чтобы заменить описание «Солнечно» на «Солнце» :
REPLACE также может быть вложенным, если у нас есть более сложная процедура:
Это заменяет все «Солнечных» подстрок на «Солнечных» и «Дождливых» подстрок на «Дождь» .
Числовые скалярные функции
Наконец, числовые скалярные функции — это функции, которые работают с одним значением и возвращают одно значение числового типа данных. Один из примеров скалярной числовой функции:
Один из примеров скалярной числовой функции:
ОКРУГЛ
ОКРУГЛ принимает числовые данные и целое число для количества знаков после запятой и возвращает округленные данные. Например, мы можем вернуть максимальную температуру во всех записях, округлив ее до ближайшего десятичного знака:
Другие числовые скалярные функции включают ABS для получения абсолютного значения числа, CEILING , FLOORbuit и SQRT .
Подробнее о SQLКак использовать SQL в Python
Краткий обзор функций SQL
Агрегатные и скалярные функции SQL являются важными инструментами, которые можно использовать для гибкого управления и извлечения информации из базы данных. Другие группы встроенных функций, которые воздействуют на определенные типы данных, такие как функции даты, такие как MONTH() , могут использоваться аналогично другим определяемым пользователем и встроенным скалярным функциям.