Sql запрос join: Оператор SQL INNER JOIN: синтаксис, примеры
Содержание
sql — Оптимизация запроса с inner join самой первой записи
Вопрос задан
Изменён
6 месяцев назад
Просмотрен
132 раза
Всем привет, есть таблица «А» которая содержит +11тыс, и есть таблица «Б» которая содержит +400 миллионов записей, получается что таблица «Б» кол. записей / кол. записей «А» = на каждый внешний ключ таблицы «А»
Задача вытащить с лимитом от 10шт до 5000тыс штук из таблицы «А» с привязкой самой 1-ой записи таблицы «Б», накидал запрос, но после 10 минут ожидания сбросил, так и не дождавшись окончания.
select "a".*, b.col1, b.col2, b.col3 from "a" inner join b on b.col_table_a_id = a.id and b.id = (select min(id) from b where a.id = b.col_table_a_id) limit 100 offset 0;
Есть идея создать в таблице «Б» поле first и установить туда значение в true у первой записи, но мне кажется это како-то костыль прям жесткий. ..
..
- sql
- laravel
- postgresql
15
А если как-то так попробовать, чтобы без подзапроса было, а просто ещё один inner join вместо этого:
select a.*, b.col1, b.col2, b.col3 from a inner join (select min(b.id) min_b_id, a.id a_id from a inner join b on b.col_table_a_id = a.id group by a.id) j on a.id = j.a_id inner join b on b.col_table_a_id = j.a_id and b.id = j.min_b_id limit 100 offset 0;
Я не настоящий сварщик, может это и хуже будет или вообще не то, но просто как вариант. 🙂
Кстати, индексы все ли нужные созданы, чтобы нормально джойнилось, и план выполнения смотрели?
1
Вы стартуете от таблицы a и все тормоз из-за join. Поиграться бы, но генерить 400 лямов строк не охота..
При индексе по полям col_table_a_id, id в таблице b попробуйте:
select a.*, b.* from( select row_number()over(partition by col_table_a_id order by id)rn,* from b )b join a.id = b.col_table_a_id where b.rn=1
 *, b.*
from(
select row_number()over(partition by col_table_a_id order by id)rn,*
from b
)b
join a.id = b.col_table_a_id
where b.rn=1
*, b.*
from(
select row_number()over(partition by col_table_a_id order by id)rn,*
from b
)b
join a.id = b.col_table_a_id
where b.rn=1
Неуверен что оптимизатор постгреса сделает с row_number, можно ещё попробовать с группировкой
select a.*, b.* from( select min(id)id, col_table_a_id from b group by col_table_a_id )t join a on a.id = t.col_table_a_id join b on b.id = t.id
Попробуйте взять не 400 миллионов строк, а лимит, скажем, в 1 миллион в подзапросе на таблицу b.
Сможете спокойно поэкспериментировать с разными вариантами. Не жидая каждую попытку по 10+ минут.
пс: Специально не указал limit, т.к. вы не сказали порядок сортировки.
ппс: Сделать битовую метку не такая уж и плохая идея. При условии, что из таблицы b не будут удаляться записи.
пппс: А ещё можно хранить ссылку из таблички a на первую «свою» строку в табличке b
2
В общем нашел быстрый способ и без особой заморочки, для этого нужно создать materialized view, запросом выбираем все первые id и заполняем таблицу, дальше в самом запросе меняем таблицу на нашу вьюху и получаем скорость выборку от 500mc до 1 минуты в моем случаи, что на много быстрее чем было, я ждал 10минут и запрос не был завершен.
select "a".*, b.col1, b.col2, b.col3 from "a" inner join b_view as b on b.col_table_a_id = a.id limit 100 offset 0;
Может что-то типа такого
SELECT
"a".*,
b.col1,
b.col2,
b.col3
FROM
"a"
INNER JOIN (
SELECT
b.col_table_a_id,
b.col1,
b.col2,
b.col3
FROM
b
WHERE
a.id = b.col_table_b_id
LIMIT
100
) bb ON bb.col_table_a_id = a.id
1
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
Как собрать данные из нескольких связанных таблиц с помощью Join
Реляционная модель данных подразумевает отдельное хранение и
возможность независимой обработки данных для каждой сущности.
Вместе с тем, часто возникает потребность собрать данные из нескольких связанных таблиц.
Как правило, сущности (таблицы) связаны друг с другом
внешними связями по принципу (primary key — foreign key).
Связи могут быть типа «1 к 1» или «1
ко многим» (с вариантами «1 к 0 или 1», «1 к
0 или более», «1 к 2» и пр).
Связь «многие-ко-многим»
в реляционной модели обеспечивается с помощью дополнительной таблицы связей
(другие названия: Link-таблица, Bridge-таблица, xref-таблица).
В зависимости от характера связей между таблицами, операция соединения может быть:
- внутренним соединением (INNER JOIN). При этом:
- если для описания связи между наборами данных используются корреляционные подзапросы, то такой INNER JOIN называют CROSS APPLY
- если условие соединения отсутствует, то такой INNER JOIN называют “декартовым произведением” (CROSS JOIN, CARTESIAN PRODUCT)
- внешним соединением (OUTER JOIN). Разновидности — LEFT JOIN, RIGHT JOIN, FULL JOIN
- если для описания связи между наборами данных используются корреляционные подзапросы, то такой OUTER JOIN называют OUTER APPLY
 При этом:
При этом:Новичку порой
трудно разобраться, когда и какой тип джоинов нужно использовать и чем одни из
них лучше других.
В этой статье мы попробуем решить разными способами несколько практических задач, отмечая плюсы и минусы каждого решения.
Пример логической модели данных:
Обратите внимание на характер данных в наших таблицах.
У некоторых спортсменов нет категории, клуба или тренера (возможно, они
неизвестны).
Встречаются
спортсмены, которых ведёт несколько тренеров.
Про одни сущности есть чуть больше информации чем про другие.
Знакомство с данными.
In [1]:
use tempdb go --содержимое таблиц: select * from dbo.SwimmingClub select * from dbo.Swimmer select * from dbo.Category (3 rows affected) (7 rows affected) (3 rows affected)Out [1]:
Пример #1. Найти всех спортсменов из клуба Янтарь, имеющих II спортивный разряд.
Используя старую нотацию:
In [2]:
use tempdb go select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.[Name] Club, sc.City, c.[Name] Category from dbo.SwimmingClub sc, dbo.Swimmer s, dbo.Category c where sc.[Name] like N'%Янтарь%' and sc.SwimmingClubID = s.SwimmingClubID and s.CategoryID = c.CategoryID and c.[Name] = N'II' (1 row affected)Out [2]:
В этой форме записи WHERE-часть перегружена
условиями.
логике текущей задачи (у. 1 и 4).В сложных запросах WHERE-часть может стать просто огромной!
Используя новую нотацию:
In [3]:
use tempdb go select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.[Name] Club, sc.City, c.[Name] Category from dbo.SwimmingClub sc inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID inner join dbo.Category c on s.CategoryID = c.CategoryID where sc.[Name] like N'%Янтарь%' and c.[Name] = N'II' (1 row affected)Out [3]:
Преимуществом этой формы записи
является “разгрузка” WHERE-части от условий, определенных логической моделью данных, при этом четко
видно какое из условий используется для реализации связи между какими
таблицами.В сложных запросах новая форма записи позволяет добиться существенно лучшей читаемости кода (а, как увидим позже, еще и лучшей готовности кода к рефакторингу).
Используя CROSS JOIN:
In [4]:
use tempdb go select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.[Name] Club, sc.City, c.[Name] Category from dbo.SwimmingClub sc cross join dbo.Swimmer s cross join dbo.Category c where sc.[Name] like N'%Янтарь%' and sc.SwimmingClubID = s.SwimmingClubID and s.CategoryID = c.CategoryID and c.[Name] = N'II' (1 row affected)Out [4]:
Обратите внимание на то, как запрос с CROSS JOIN похож на вариант решения в старой нотации!
На самом деле, ничего удивительного, т. к. логически они выражают один и тот же подход к решению задачи: “все источники данных — в FROM, все условия — в WHERE. При отсутствии условий каждая таблица декартово перемножается с каждой”.Вообще, вариантов решения задачи много. Но, как можно догадаться, не все они оптимальны;).
Например, порой начинающие программисты для решения первой задачи создают что-то вроде этого:
In [5]:
use tempdb go declare @ClubId int, @ClubCity nvarchar(30), @ClubName nvarchar(100), @CategoryId int set @ClubId = ( select SwimmingClubId from dbo.Out [5]:
Идея за этим кодом такова.
Чтобы найти всех спортсменов из клуба Янтарь, имеющих II спортивный разряд, нужно:
- dbo.SwimmingClub
найти код клуба Янтарь (значение внешнего ключа SwimmingClubId)
2. dbo.Category
найти код категории, указывающей на II разряд (значение внешнего ключа CategoryId)
3. dbo.Swimmer
зная эти два значения, найти соответствующих пловцов
Приведенный выше алгоритм “напрашивается” сам собой.
Недостатком этого подхода являются:
 Часть из них относятся к логической модели данных (у. 2 и 3), часть – к
Часть из них относятся к логической модели данных (у. 2 и 3), часть – к
 SwimmingClub where [Name] like N'%Янтарь%'
)
set @ClubCity = (
select City from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @ClubName = (
select [Name] from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @CategoryId = (
select CategoryId from dbo.Category where [Name] = N'II'
)
select SwimmerID, FirstName, LastName, YearOfBirth, Gender,
@ClubName Club, @ClubCity City, N'II' Category
from dbo.Swimmer
where SwimmingClubID = @ClubId and CategoryId = @CategoryId
(1 row affected)
SwimmingClub where [Name] like N'%Янтарь%'
)
set @ClubCity = (
select City from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @ClubName = (
select [Name] from dbo.SwimmingClub where [Name] like N'%Янтарь%'
)
set @CategoryId = (
select CategoryId from dbo.Category where [Name] = N'II'
)
select SwimmerID, FirstName, LastName, YearOfBirth, Gender,
@ClubName Club, @ClubCity City, N'II' Category
from dbo.Swimmer
where SwimmingClubID = @ClubId and CategoryId = @CategoryId
(1 row affected)
 Именно поэтому разработчики, далекие от SQL, пишут такие решения.
Именно поэтому разработчики, далекие от SQL, пишут такие решения.- длинный код (объявление переменных + 5 инструкций SELECT)
- худшая производительность (пять селектов явно медленнее одного)
- неизолированность от конкурирующих транзакций (пока мы рассчитываем значения переменных, данные в любой из таблиц могут быть изменены кем-то другим)
- если есть несколько клубов со словом “Янтарь” в названии, любой из трех первых селектов упадет.
Пример #2. Вывести спортсменов из клуба Янтарь с теми же атрибутами что и выше, но без требования иметь II спортивный разряд.
Используя старую нотацию:
In [6]:
use tempdb go --это код с багом! в случае если у спортсмена нет разряда, запись о нем не выводится select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.[Name] Club, sc.City, c.[Name] Category from dbo.SwimmingClub sc, dbo.Out [6]:
Интуитивно напрашивающееся решение
адаптировать старый код под новые требования удалением соответствующего условия
не работает!В старой нотации нужно существенно менять сам код при незначительных изменениях в требованиях.
Используя новую нотацию:
In [7]:
use tempdb go select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.Out [7]:
В отличии от старой, после удаления уже ненужного требования, в новой
нотации нужно лишь поменять слово inner на left.Вот и все!
Вариант решения задачи с outer apply:
In [8]:
use tempdb go select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.[Name] Club, sc.City, c.[Name] Category from dbo.SwimmingClub sc inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID outer apply (select [Name] from dbo.Category c where c.CategoryID = s.CategoryId) c where sc.[Name] like N'%Янтарь%' (3 rows affected)Out [8]:
Несмотря на запись запроса, похожую на вариант с LEFT JOIN, этот способ не
оптимален из-за имеющегося корреляционного подзапроса.
Последний приводит к тому, что выполнение идет по принципу row—by—row вместо set—based. Логически, мы
выполняем корреляционный подзапрос с внешним параметром s.CategoryId столько раз, сколько строчек в таблице dbo.Swimmer.Корреляционные запросы существенно ухудшают производительность!
Вариант решения задачи с пользовательской скалярной функцией:
In [9]:
use tempdb go create or alter function dbo.fn_GetCategoryName(@CategoryID int) returns nvarchar as begin return (select [Name] from dbo.Category where CategoryId = @CategoryID) end go select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender, sc.[Name] Club, sc.City, dbo.fn_GetCategoryName(s.CategoryId) Category from dbo.SwimmingClub sc inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID where sc.[Name] like N'%Янтарь%' (3 rows affected)Out [9]:
Использование
пользовательской функции, на первый взгляд, помогает упростить решение задачи
и, опять же, масса разработчиков идет этим путем, следуя привычке разбивать
сложный функционал на отдельные блоки.Вместе с тем, это решение в условиях баз данных, скорее всего, еще хуже предыдущего:
 Swimmer s, dbo.Category c
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
and s.CategoryID = c.CategoryID
--подправленный код (один из вариантов)
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City,
(select c.[Name] from dbo.Category c where c.CategoryID = s.CategoryID) Category
from dbo.SwimmingClub sc, dbo.Swimmer s
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
(2 rows affected)
(3 rows affected)
Swimmer s, dbo.Category c
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
and s.CategoryID = c.CategoryID
--подправленный код (один из вариантов)
select s.SwimmerID, s.FirstName, s.LastName, s.YearOfBirth, s.Gender,
sc.[Name] Club, sc.City,
(select c.[Name] from dbo.Category c where c.CategoryID = s.CategoryID) Category
from dbo.SwimmingClub sc, dbo.Swimmer s
where sc.[Name] like N'%Янтарь%'
and sc.SwimmingClubID = s.SwimmingClubID
(2 rows affected)
(3 rows affected)
 [Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc
inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID
left join dbo.Category c on s.CategoryID = c.CategoryID
where sc.[Name] like N'%Янтарь%'
(3 rows affected)
[Name] Club, sc.City, c.[Name] Category
from dbo.SwimmingClub sc
inner join dbo.Swimmer s on s.SwimmingClubID = sc.SwimmingClubID
left join dbo.Category c on s.CategoryID = c.CategoryID
where sc.[Name] like N'%Янтарь%'
(3 rows affected)


- корреляционный подзапрос никуда не делся, он лишь мигрировал в тело функции
- в ходе выполнения запроса функция будет вызвана множество раз, что негативно влияет на производительность (из-за особенностей работы СУБД и интерпретатора языка SQL)
- для решения одной конкретной задачи понадобилось создать дополнительный постоянный объект БД – пользовательскую скалярную функцию.
Если пользоваться таким подходом постоянно, то скоро БД будет завалена множеством непонятных программных объектов!
Вывод.
В рассмотренных примерах победителем стал запрос, созданный в новой нотации без использования корреляционных подзапросов. Он максимально читабельный, легко меняется в случае изменения требований, производительный и не требует создания дополнительных объектов в БД.
Автор материала – Тимофей Гавриленко, преподаватель Тренинг центра ISsoft.
Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.
SQL JOIN — Расширенный SQL
Этот урок охватывает, пожалуй, самый важный элемент языка SQL: операцию SQL JOIN . Как известно, база данных хранит данные в нескольких таблицах. Когда вам нужно объединить данные из нескольких таблиц, вы выполняете JOIN между таблицами, в которых хранятся данные.
В этой статье представлены примеры использования предложения SQL JOIN .
Образцы таблиц
Есть два примера таблиц: туры и города .
Таблица туров
| Tour_Name | Лучший сезон | Цена | Продолжительность (дни) |
|---|---|---|---|
| США и Канада | с марта по сентябрь | 3600 | 8 |
| Крупные города США | Весь год | 4300 | 12 |
| Африканский тур | Весь год | 2100 | 7 |
| Пляжи Бразилии | с декабря по март | 1800 | 8 |
Таблица городов
| City_Name | Тип_города | Tour_Name | Дней Постановка |
|---|---|---|---|
| Вашингтон | культура | США и Канада | 5 |
| Вашингтон | культура | Большие города США | 5 |
| Каир | культура | Африканский тур | 4 |
| Рио-де-Жанейро | пляж | Пляжи Бразилии | 4 |
| Йоханнесбург | сафари | Африканский тур | 3 |
| Флорианополис | пляж | Пляжи Бразилии | 4 |
| Квебек | культура | США и Канада | 3 |
| Нью-Йорк | культура | Большие города США | 7 |
Чтобы использовать предложение JOIN для объединения двух таблиц, в обеих таблицах должен быть общий столбец. В этой базе данных столбец
В этой базе данных столбец tour_name . Общий столбец легко идентифицировать, потому что он имеет одинаковое имя в обеих таблицах. В других базах данных вы должны смотреть на значения, так как общий столбец может иметь разные имена. Важным моментом являются значения столбцов, поскольку оператор JOIN создает пары записей для тех записей, которые имеют одинаковое значение в общем столбце.
Представлены два типа операторов JOIN : INNER JOIN и LEFT OUTER JOIN .
Оператор SQL INNER JOIN
Вот простой запрос SQL JOIN для получения пар:
ВЫБИРАТЬ
имя_тура,
лучший_сезон,
цена,
название города,
тип_города,
days_staging
ИЗ туров ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ городов НА tours.tour_name = city.tour_name
Как создается пара записей Оператор SQL INNER JOIN ?. Для каждой записи в первой таблице ( туров ) каждая запись во второй таблице ( города ), имеющая одинаковое значение в столбцах, указанных в предложении ON ( имя_тура ), сопоставляется с записью из первой таблицы. .
.
Вот результат:
| имя_тура | лучший_сезон | цена | имя_города | тип_города | дней_постановка |
|---|---|---|---|---|---|
| США Канада | с марта по сентябрь | 3600 | Квебек | культура | 3 |
| США Канада | с марта по сентябрь | 3600 | Вашингтон | культура | 5 |
| Крупные города США | Весь год | 4300 | Нью-Йорк | культура | 7 |
| Большие города США | Весь год | 4300 | Вашингтон | культура | 5 |
| Африканский тур | Весь год | 2100 | Йоханнесбург | сафари | 3 |
| Африканский тур | Весь год | 2100 | Каир | сафари | 4 |
| Пляжи Бразилии | с декабря по март | 1800 | Флорианополис | пляж | 4 |
| Пляжи Бразилии | с декабря по март | 1800 | Рио-де-Жанейро | пляж | 4 |
Предположим, вы хотите узнать, какие туры доступны для культурного города менее чем за 3000 долларов.
Вот запрос:
ВЫБИРАТЬ
имя_тура,
цена
ИЗ туров ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ городов НА tours.tour_name = city.tour_name
ГДЕ цена < 3000
И type_of_city = «культура»
Результат:
| имя_тура | цена |
|---|---|
| Африканский тур | 2100.00 |
Оператор SQL OUTER JOIN
В некоторых случаях запись в первой таблице не имеет дублирующей записи во второй таблице, чтобы образовать пару. Например, может быть tour_name , не связанный ни с одним городом, возможно, потому, что это тур в джунгли или недельное морское путешествие.
Вот новая версия таблицы туры :
| Tour_Name | Лучший сезон | Цена | Продолжительность (дни) |
|---|---|---|---|
| США и Канада | с марта по сентябрь | 3600 | 8 |
| Крупные города США | Весь год | 4300 | 12 |
| Африканский тур | Весь год | 2100 | 7 |
| Пляжи Бразилии | с декабря по март | 1800 | 8 |
| Карибы: неделя парусного спорта | с мая по октябрь | 5300 | 7 |
| 5 дней в джунглях Амазонаса | Весь год | 900 | 5 |
Если вы хотите получить список доступных туров, вы можете выполнить первый INNER JOIN еще раз:
ВЫБИРАТЬ
имя_тура,
лучший_сезон,
цена,
название города,
тип_города,
days_staging
ИЗ туров ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ городов НА tours. tour_name = city.tour_name
 tour_name = city.tour_name
tour_name = city.tour_name
Туры Карибское море: парусная неделя и 5 дней в джунглях Амазонки не возвращаются в результатах, так как нет связанного города.
| имя_тура | лучший_сезон | цена | имя_города | type_of_city | дней_постановка |
|---|---|---|---|---|---|
| США Канада | с марта по сентябрь | 3600 | Квебек | культура | 3 |
| США Канада | с марта по сентябрь | 3600 | Вашингтон | культура | 5 |
| Крупные города США | Весь год | 4300 | Нью-Йорк | культура | 7 |
| Крупные города США | Весь год | 4300 | Вашингтон | культура | 5 |
| Африканский тур | Весь год | 2100 | Йоханнесбург | сафари | 3 |
| Африканский тур | Весь год | 2100 | Каир | сафари | 4 |
| Пляжи Бразилии | с декабря по март | 1800 | Флорианополис | пляж | 4 |
| Пляжи Бразилии | с декабря по март | 1800 | Рио-де-Жанейро | пляж | 4 |
Чтобы включить другие туры, используйте SQL LEFT OUTER JOIN .
SQL LEFT OUTER JOIN не отбрасывает строку, не имеющую аналога во второй таблице.
Вот запрос:
ВЫБИРАТЬ
имя_тура,
лучший_сезон,
цена,
название города,
тип_города,
days_staging
ИЗ туров НАЛЕВО ВНЕШНЕ СОЕДИНЯЙТЕ города НА tours.tour_name = city.tour_name
В результатах вы можете видеть, что включены туры без городов. Значения столбцов из второй таблицы NULL , так как это нормальное поведение оператора SQL LEFT OUTER JOIN .
| имя_тура | лучший_сезон | цена | имя_города | тип_города | дней_постановка |
|---|---|---|---|---|---|
| США Канада | с марта по сентябрь | 3600 | Квебек | культура | 3 |
| США Канада | с марта по сентябрь | 3600 | Вашингтон | культура | 5 |
| Крупные города США | Весь год | 4300 | Нью-Йорк | культура | 7 |
| Крупные города США | Весь год | 4300 | Вашингтон | культура | 5 |
| Африканский тур | Весь год | 2100 | Йоханнесбург | сафари | 3 |
| Африканский тур | Весь год | 2100 | Каир | сафари | 4 |
| Пляжи Бразилии | с декабря по март | 1800 | Флорианополис | пляж | 4 |
| Пляжи Бразилии | с декабря по март | 1800 | Рио-де-Жанейро | пляж | 4 |
| Карибы: неделя парусного спорта | с мая по октябрь | 5300 | |||
| 5 дней в джунглях Амазонаса | Весь год | 900 |
Заключительные слова
В этом уроке вы изучили два оператора SQL JOIN INNER JOIN и ЛЕВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ . Существуют и другие менее часто используемые операторы
Существуют и другие менее часто используемые операторы JOIN , которые вы можете изучить, когда разберетесь с основами. Продолжайте в том же духе, изучайте SQL и повышайте свои навыки!
Присоединение к SQL SFMC | Матеуш Домбровски
Расширения данных. Представления системных данных. С оператором JOIN используйте один запрос, чтобы управлять ими всеми.
Бывают случаи, когда все, что вам нужно, это извлечь (и, возможно, преобразовать) данные ИЗ одного расширения данных. Но настоящая магия SQL видна, когда вам нужно объединить информацию из нескольких точек данных. А вот и ПРИСОЕДИНЯЙТЕСЬ к оператору .
Проверьте, кто и когда открывал электронную почту, запросив _Open System Data View
SELECT
wel.SubscriberKey
, wel.EmailAddress
, o.EventDate AS OpenDate
FROM WelcomeCampaignSegment AS wel
JOIN _ Open AS o
ON o.SubscriberKey = wel.SubscriberKey
Давайте углубимся в детали того, что вы видите выше.
Типы JOIN
В приведенном выше примере вы можете увидеть слово JOIN . Есть много JOIN типов операторов, доступных в SQL. Соответствующее объединение позволит вам сегментировать ваши записи именно так, как вы хотите, и без необходимости использования обширных предложений WHERE . Понимание различий между различными типами и использование правильного для поставленной задачи сделает ваш код короче, легче для чтения и оптимизации. Давайте проверим, что находится в колчане:
Внутреннее соединение
Самое простое соединение — это INNER JOIN . Берет записи из первой таблицы ( Welcome-Campaign-Segment Data Extension в приведенном выше примере) и вторую таблицу ( _Open System Data View в данном случае) для вывода записей, доступных в обеих из них (на основе выбранного отношения).
В нашем запросе это будут контакты, которые находятся в расширении данных и в то же время некоторые сообщения электронной почты открываются в _Открыть Представление системных данных. Он будет игнорировать все контакты, которые не отображаются в представлении системных данных
Он будет игнорировать все контакты, которые не отображаются в представлении системных данных _Open , и все открытые сообщения электронной почты, не связанные с контактами в Welcome-Campaign-Segment Расширение данных.
Конечно, этот запрос в его текущем состоянии не идеален и может выдавать неверные результаты (например, отслеживание открытий для контактов из нашего расширения данных, но из совершенно другой кампании), поскольку он не ограничивает область действия только одним Кампания или Работа.
SELECT
wel.SubscriberKey
, wel.EmailAddress
, o.EventDate AS OpenDate
FROM WelcomeCampaignSegment AS wel
INNER JOIN _Open AS o
ON o.SubscriberKey = wel.Subscribe ключ
При использовании INNER JOIN вы можете написать просто слово JOIN , как в первом примере, чтобы получить тот же результат. Однако рекомендуется указывать этот тип явно, написав полное имя. Это облегчает дифференциацию от следующих типов JOIN .
Левое и правое соединения
Следующие соединения: ЛЕВОЕ СОЕДИНЕНИЕ (также известное как ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ) и ПРАВОЕ СОЕДИНЕНИЕ (также известное как ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ). Вместо того, чтобы ограничивать вывод записями, доступными в обеих таблицах, они берут полные данные из одной таблицы и добавляют дополнительную информацию из второй (если она доступна).
LEFT JOIN возьмет полные данные первой таблицы (в нашем примере расширение данных, выбранное FROM ) и дополнит их информацией из второй ( _Open Представление системных данных, объединенное с LEFT JOIN ) .
Вы можете пойти наоборот с RIGHT JOIN (в нашем примере это выведет все в _Open System Data View и добавит к нему данные из Data Extension - не очень полезно).
Тот же запрос, но на этот раз объединенный с помощью LEFT JOIN
SELECT
wel.SubscriberKey
, wel.
, o.EventDate AS OpenDate
FROM WelcomeCampaignSegment AS wel
LEFT JOIN _Open AS 9 0791 ON o.SubscriberKey = wel. SubscriberKey
 EmailAddress
EmailAddress Как видите, единственное, что мы изменили в приведенном выше запросе, — это тип JOIN . Это простое изменение изменит наши результаты, чтобы показать полный список всех ключей подписчика и адресов электронной почты из Welcome-Campaign-Segment Расширение данных с датой открытия электронной почты для тех контактов, которые участвовали в общении. Незадействованные будут иметь нулевых значения в столбце OpenDate . Опять же, это неправильный способ построения такого отчета. Внизу будет готовый фрагмент.
Из-за схожести LEFT JOIN и RIGHT JOIN я настоятельно рекомендую выбрать один тип и использовать его последовательно, чтобы снизить риск ошибки.
Вы должны знать
Если вы хотите увидеть все контакты из нашего расширения данных, которые не открыли электронную почту, вы можете использовать LEFT JOIN с исключением (называемым LEFT EXCLUDING JOIN):
Пример исключения, примененного к LEFT JOIN
SELECT
wel.
, wel.EmailAddress
, o.EventDate AS OpenDate
FROM WelcomeCampaignSegment AS wel
LEFT JOIN _Open AS o
ON o.SubscriberKey = wel .SubscriberKey
ГДЕ o.SubscriberKey IS NULL
 SubscriberKey
SubscriberKey Узнайте больше об этом в руководстве по операторам WHERE.
Full Join
Последним классическим SQL JOIN является FULL JOIN (также известный как FULL OUTER JOIN ), который позволяет получать данные из обоих источников.
В нашем примере это будет означать все контакты из Welcome-Campaign-Segment Расширение данных и все записи из _Open Представление системных данных с нулевыми значениями в столбцах без совпадений. Контакты, которые не открывались и не отслеживались, не были связаны с контактами, доступными в выбранном нами расширении данных.
Не лучший вариант использования FULL JOIN
SELECT
wel.SubscriberKey
, wel.EmailAddress
, o.
FROM WelcomeCampaignSegment AS wel
FULL JOIN _Open AS o
ON o.SubscriberKey = wel.SubscriberKey
 EventDate AS OpenDate
EventDate AS OpenDate FULL JOIN — отличный инструмент, когда вы, например, хотите создать главный сегмент из нескольких меньших. Другой вариант использования — проверка нескольких точек данных отслеживания с четким представлением о том, чего не хватает (например, у каких пользователей отслеживается клик по электронной почте без открытия и наоборот).
Самосоединение
Затем следует Самосоединение. Это не отдельный тип оператора JOIN , а скорее конкретный вариант использования для вышеуказанных типов. Он соединяет таблицу сам с собой. Полезно, когда у вас есть столбцы в вашем расширении данных, которые указывают на другие столбцы в том же расширении.
Примером использования, который я могу придумать в мире Salesforce Marketing Cloud, может быть, например, расширение данных, в котором хранятся категории и подкатегории продуктов.
Расширение входных данных:
| CategoryName | CategoryID | ParentCategoryID |
|---|---|---|
| Наручные часы | 1 90 038 | |
| Часы для дайверов | 2 | 1 |
| Часы для пилотов | 3 | 1 |
В таком сценарии вы можете использовать самообъединение для создания более читаемой таблицы, которая может быть полезна для персонализации:
Самообъединение с использованием ВНУТРЕННЕГО СОЕДИНЕНИЯ выведет только категории, у которых есть родительская категория
SELECT
c.CategoryName AS Category
, pc.CategoryName AS ParentCategory
FROM WristwatchesDE AS c
INNER JOIN WristwatchesDE AS pc
ON pc.ParentCategoryID = c.CategoryID
901 99Расширение выходных данных:
| Категория | ParentCategory |
|---|---|
| Часы для дайвинга | Наручные часы |
| Часы для пилотов | Наручные часы | 9 0033
Другой вариант использования? У вас может быть таблица продуктов для электронной коммерции, в которой в одном столбце хранятся рекомендуемые продукты, которые часто покупаются вместе. Чтобы персонализировать электронное письмо с такими предложениями, самостоятельная регистрация в этой колонке была бы идеальной.
Чтобы персонализировать электронное письмо с такими предложениями, самостоятельная регистрация в этой колонке была бы идеальной.
Вы не будете часто использовать самосоединение, но при необходимости оно может значительно сэкономить время.
Вы должны знатьСамостоятельное присоединение может быть идеальным инструментом для работы с данными, поступающими из Salesforce через Marketing Cloud Connect to Synchronized Data Extensions.
Очень часто вы можете столкнуться с Учетными записями, связанными с другой Учетной записью. Эта иерархическая структура использует поле ParentId. Вы можете сгладить эту связь для использования в персонализации и поездках с самосоединением.
Сведение трех уровней иерархии учетных записей Salesforce
SELECT
a1.Id AS Level1AccountId
, a1.Name AS Level1AccountName
, a2.Id AS Level2AccountId
, a2.Name AS Level2AccountName
, a3.Id AS Level3AccountId
, a3. Имя КАК Level3AccountName
ОТ Account_Salesforce КАК a1
ЛЕВОЕ ПРИСОЕДИНЕНИЕ Account_Salesforce КАК a2
ВКЛ a2.
ЛЕВОЕ ПРИСОЕДИНЕНИЕ Account_Salesforce КАК a3
ВКЛ a3.Id = a2.ParentId
 Id = a1.ParentId
Id = a1.ParentId Think о том, насколько проще было бы с аккуратная визуальная шпаргалка? Отлично - я приготовил для вас один внизу 🙂
Присоединение к ON
Я много писал о различных операторах JOIN , но есть еще и элемент ON . Мы используем его для определения отношения между объединенными источниками данных. Он сообщает запросу, какое значение следует учитывать, чтобы решить, доступна ли запись в обоих столбцах.
В нашем примере мы использовали ON de.SubscriberKey = o.SubscriberKey , который берет SubscriberKey из расширения данных и представления системных данных и сопоставляет строки на его основе. Вы можете использовать любой другой, но всегда помните о крайних случаях. Адрес электронной почты всегда уникален? Это очень похоже на то, что вы делаете в Salesforce Marketing Cloud Data Designer.
Этот столбец не обязательно должен быть первичным ключом расширения данных или представления системных данных. Вы можете выбрать любой, если его значения совпадают во втором источнике.
Вы можете выбрать любой, если его значения совпадают во втором источнике.
Вы также можете добавить немного логики, используя операторы AND / OR . Это удобно, если:
- Вы не уверены, какой столбец будет иметь совпадение. Например, у вас есть отдельные столбцы для 15-символьного идентификатора Salesforce и 18-символьного идентификатора, и вы хотите сопоставить любой из них.
- Вы хотите соответствовать нескольким критериям. Например, не только поле
EmailAddress, но иLastNameдля покрытия общего адреса электронной почты. - Вы хотите объединить более двух источников данных, используя запутанную логику. Вскоре вы найдете пример в разделе «Несколько различных объединений».
Вы должны знать
Вы не ограничены простым ON ColumnA = ColumnB . При необходимости вы можете использовать более динамичные соединения, использующие функции SQL:
Присоединение к нормализованному номеру телефона из представления данных и, возможно, к телефону с префиксом расширения данных JOIN _SMSSubscriptionLog AS sms
ON sms. MobileNumber LIKE CONCAT('%', wel.MobilePhone)
MobileNumber LIKE CONCAT('%', wel.MobilePhone)
Помните, что такой подход окажет значительное влияние на производительность.
Префикс имени таблицы
При объединении нескольких источников данных со столбцами с одинаковыми именами вам нужно указать SQL, из какого источника вы выбираете каждый столбец. Вы можете сделать это, используя префикс имени таблицы перед именем столбца:
Пример SQL с полным префиксом имени таблицы 0791
Впрочем, вы наверняка видели в предыдущих примерах что есть другой способ. Вам не нужно каждый раз писать полное имя источника данных. Вы можете использовать псевдонимы так же, как и столбцы, чтобы сделать их короче:
Пример SQL с префиксами имен таблиц с псевдонимами
SELECT
wel.SubscriberKey
, wel.EmailAddress
, o.EventDate AS OpenDate
FROM WelcomeCampaignSegment AS wel
INNER JOIN _Open AS o
ON o.SubscriberKey = wel.SubscriberKey
Все, что вам нужно сделать, это написать свой псевдоним после имени источника данных.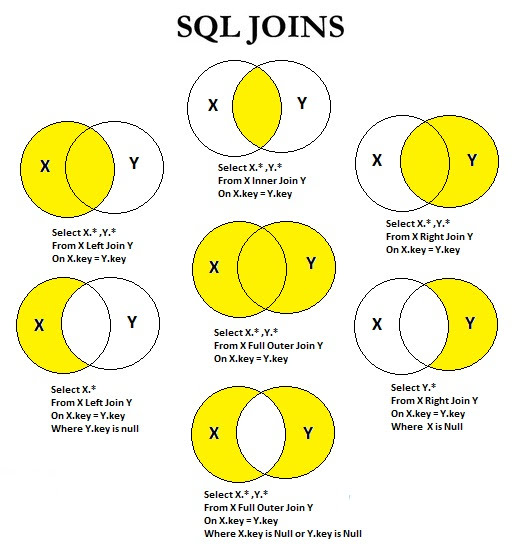 Для удобства чтения я рекомендую использовать ключевое слово
Для удобства чтения я рекомендую использовать ключевое слово AS между. Теперь вы можете использовать сокращенное имя для префикса выбранных столбцов. Это полезно при извлечении данных из нескольких расширений данных.
Использование префиксов имен таблиц не всегда требуется (например, когда два источника, которые вы СОЕДИНЯЕТЕ , не имеют столбцов с одинаковыми именами). Вы можете увидеть некоторые примеры без него. Однако рекомендуется использовать эту функцию для обеспечения согласованности, удобочитаемости и предотвращения ошибок.
Множественные соединения
Объединение двух таблиц — это только начало. Работа с несколькими столбцами может быть гораздо более ошеломляющей, и в некоторых случаях использование бумаги и карандаша для рисования некоторых диаграмм Венна может иметь огромное значение. Давайте проверим некоторые из наиболее популярных вариантов использования.
Вы должны знать
Порядок соединения таблиц всегда важен, но он имеет решающее значение для соединений с несколькими столами, так как может иметь огромное влияние на конечный результат:
Как видите, изменение порядка второго и третьего table создает значительно иной результат. И это еще не все — в зависимости от того, что вы используете в
И это еще не все — в зависимости от того, что вы используете в ON , порядок может также влиять на то, к каким записям применяются данные, обогащающие данные.
Например, если вы обогатите данные первой объединенной таблицы, а затем добавите несколько новых записей в другую — будут обогащены только записи из исходной таблицы. Те, что были добавлены на последнем шаге, не будут иметь этого добавленного контекста. Изменение порядка JOIN s может решить эту проблему.
Множественные внутренние соединения
Во многих случаях вам потребуется сегмент людей, которые одновременно выполняют несколько требований. Например, контакты, которые были частью трех разных кампаний ToFu, связанных с определенным продуктом. Такие данные могут стать идеальной аудиторией для вашей следующей кампании в маркетинговой воронке. Для такого сценария вы будете использовать несколько операторов INNER JOIN , связанных в один запрос:
Контакты, используемые для трех разных кампаний ToFu, которые готовы для кампании MoFu
SELECT
wel.
, wel.EmailAddress
, nsl.PhoneNumber
, ebo.EbookName
FROM WelcomeCampaignSegment AS wel
INNER JOIN NewsletterPromoCampaignSegment AS nsl 907 91 ON nsl.SubscriberKey = wel.SubscriberKey
INNER JOIN EbookDownloadCampaignSegment AS ebo
ON ebo.SubscriberKey = wel.SubscriberKey
 SubscriberKey
SubscriberKey Этот SQL даст вам только те контакты, которые были во всех трех расширениях данных.
Несколько левых соединений
Еще одна огромная группа случаев, с которыми вы можете столкнуться, — это запросы с несколькими операторами LEFT JOIN . Они отлично подходят, когда вы хотите расширить данные для вашего основного источника данных несколькими другими точками данных без потери записей, которые не имеют соответствия. Отлично подходит для создания сегмента для кампании из расширений данных с обширной персонализацией:
В список контактов добавьте информацию о продукте, который мы хотим использовать в содержимом электронной почты, вместе с описанием специального предложения
SELECT
up.
, up.EmailAddress
, prod.ProductName
, prod.ProductPrice
, promo.Offer
FROM UpSellCampaignSegment AS up
LEFT JOIN ProductDetailsList AS prod
ON product.ProductId = up.OfferedProduct
ЛЕВОЕ СОЕДИНЕНИЕ CustomOfferList AS promo
ON promo.PromotionId = up.OfferedPromotion
 SubscriberKey
SubscriberKey Обратите внимание, что в этом случае мы объединили дополнительные расширения данных в разных столбцах. Более того, нам не нужно SELECT эти столбцы для фильтрации по ним. Благодаря использованию LEFT JOIN вместо INNER JOIN этот запрос также вернет нам контакты, к которым не применено какое-либо специальное предложение (для них мы можем скрыть соответствующий блок контента с персонализацией).
Несколько различных объединений
При создании запроса вы не ограничены только одним типом объединения. Вы можете смешивать и сочетать различные типы соединений, чтобы извлекать именно те данные, которые вам нужны. Однако чем больше сложности вы добавляете (либо количеством источников, либо количеством различных соединений), тем более рекомендуемым будет рисование диаграмм Венна.
Однако чем больше сложности вы добавляете (либо количеством источников, либо количеством различных соединений), тем более рекомендуемым будет рисование диаграмм Венна.
Тот же запрос, что и выше, но на этот раз со смесью INNER JOIN и LEFT JOIN
SELECT
up.SubscriberKey
, up.EmailAddress
, prod.ProductName
, prod.ProductPrice
, promo.Offer 9 0791 ОТ UpSellCampaignSegment AS up
INNER JOIN ProductDetailsList AS prod
ON prod.ProductId = up.OfferedProduct
LEFT JOIN CustomOfferList AS promo
ON promo.PromotionId = up.OfferedPromotion
В приведенном выше примере мы взяли тот же запрос, что и для множественного левого соединения , но мы изменили первые ПРИСОЕДИНЯЙТЕ тип к ВНУТРЕННИЙ . Каково влияние? На этот раз мы получим только те контакты из Up-Sell-Campaign-Segment , у которых есть соответствующий продукт в Product-Details-List , и только тогда мы дополним их дополнительной информацией о специальном предложении.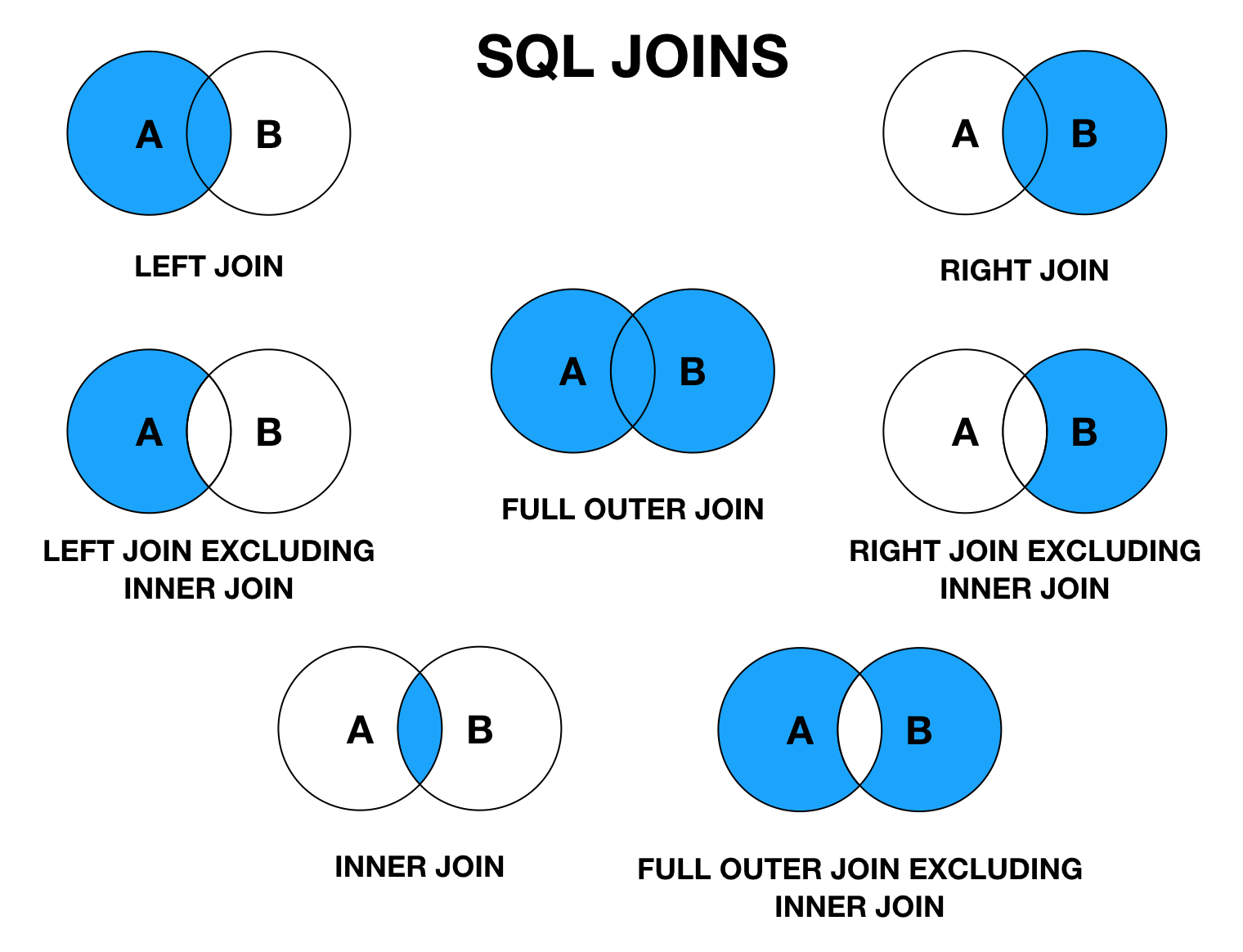
Этот подход может быть лучше для наших нужд, так как мы будем уверены, что все контакты имеют доступные данные для названия продукта и цены продукта. Отличный способ сделать наш контент лучше и удобнее для создания.
Насколько сложным может быть JOIN ? Очень. Вы столкнетесь с такими чудовищами, особенно в мире запросов отчетов, которые требуют информации из нескольких представлений системных данных — например, когда вы хотите отладить отправку электронной почты.
Следует помнить одну вещь: чем более сложный запрос вы создаете, тем больше он подвержен ошибкам и тем ближе вы к 30-минутному лимиту AutoKill для выполнения запроса. Всегда сводите свой запрос только к тем данным, которые вам действительно нужны.
UNION
Помимо оператора JOIN , аналогичной цели служит оператор UNION . Он объединяет результаты нескольких операторов SELECT .
Групповые подписчики из двух расширений данных
SELECT
jan.
, jan.EmailAddress
FROM JanuaryEventParticipants AS январьUNION
SELECT
feb.SubscriberKey 90 791 , feb.EmailAddress
FROM FebruaryEventParticipantsSegment AS 9 февраля0791
 SubscriberKey
SubscriberKey Как видно из приведенного выше примера, UNION не требует никакой связи между двумя запросами. Элемента НА нет. С другой стороны, UNION не может добавлять новые столбцы.
UNION работает, только если:
- Оба запроса имеют одинаковое количество столбцов.
- Оба запроса имеют одинаковый порядок столбцов.
- Столбцы в обоих запросах имеют одинаковые типы данных.
Имена не обязательно должны совпадать. Вам даже не нужно добавлять псевдонимы для статических значений. Однако рекомендуется сопоставлять псевдонимы во всех запросах для удобства чтения.
Чтобы упростить различие между JOIN и UNION :
- Если вы хотите добавить столбцы — используйте
JOIN. - Если вы хотите добавить строки — используйте
UNION. - Если хотите добавить оба — используйте оба (или
FULL JOIN)

Вы должны знать
По умолчанию UNION игнорирует дубликаты. Если вы хотите сохранить их, используйте UNION ALL .
Групповые подписчики из двух расширений данных
SELECT
jan.SubscriberKey
, jan.EmailAddress
FROM JanuaryEventParticipantsSegment AS janUNION ALL
SELECT
feb.Subscriber Ключ
, февраль. Адрес электронной почты
ОТ февраля EventParticipantsSegment AS февраль
очевидный вариант использования для UNION собирает подписчиков из нескольких расширений данных для создания главного сегмента.
Однако есть еще один вариант использования, который я считаю идеальным для UNION — прикрепление списков семян.
Если вы используете пакет мониторинга доставляемости, вы, вероятно, используете список поиска. Если нет — список рассылки — это список адресов электронной почты ботов, используемый для оценки размещения вашего почтового ящика для сообщений.
Если нет — список рассылки — это список адресов электронной почты ботов, используемый для оценки размещения вашего почтового ящика для сообщений.
В большинстве случаев вы будете хранить свой список рассылки в отдельном расширении данных и будете иметь заполненные только столбцы «Адрес электронной почты» и «Поддельный ключ подписчика». Как быстро внедрить их в свой сегмент? С UNION , конечно:
Добавить Seedlist к вашему сегменту
SELECT
wel.SubscriberKey
, wel.EmailAddress
, wel.FirstName
, wel.Interest
FROM WelcomeC ampaignSegment AS welUNION
SELECT
sl.SubscriberKey
, sl.EmailAddress
, «Исходный» AS FirstName
, «Оценка» AS Interest
FROM Seedlist AS sl
персонализация.
Вы должны знать
Вы можете комбинировать JOIN и UNION , чтобы создать свой идеальный сегмент. И даже добавлять произвольные данные без ИЗ .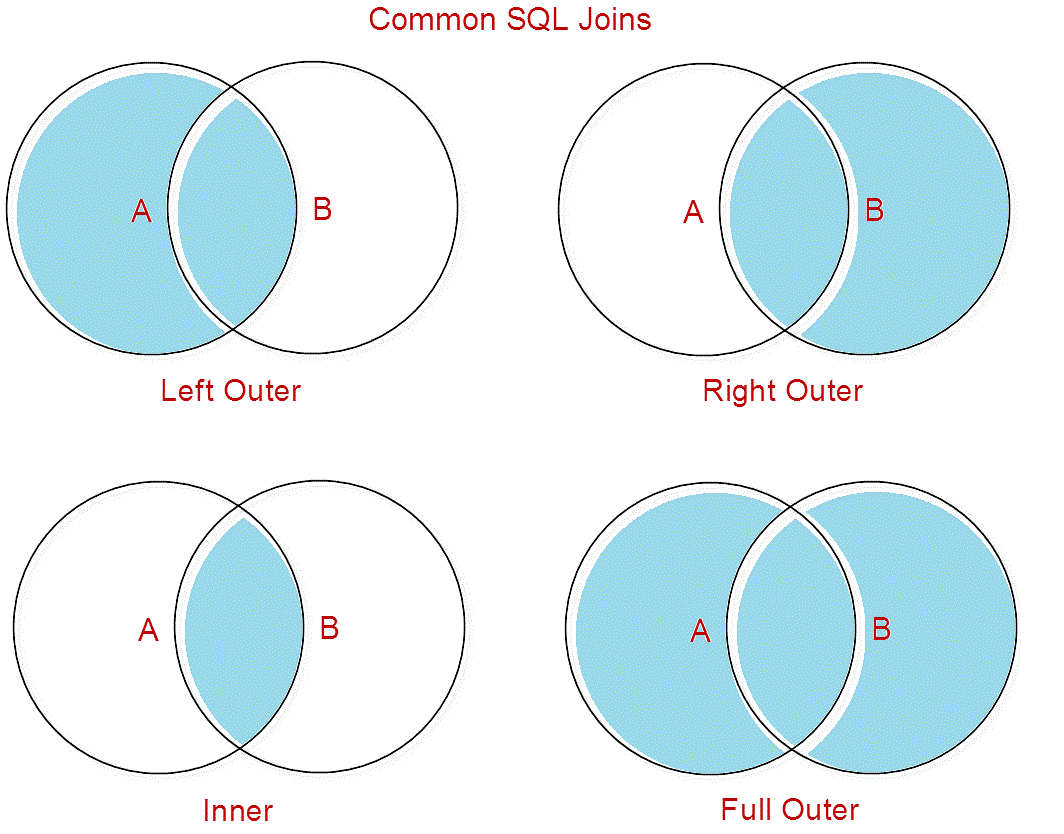
AutoKill — это предел вашего воображения
SELECT
wel.SubscriberKey
, wel.EmailAddress
, wel.FirstName
, i.Interest
FROM WelcomeCampaignSegment AS wel
LEFT JO IN InterestsDataPoint AS i
ON i.SubscriberKey = wel. Ключ подписчикаОБЪЕДИНЕНИЕ
SELECT
sl.SubscriberKey
, sl.EmailAddress
, 'Seed' AS Имя
, 'Estimate' AS Interest
FROM Seedlist AS slUNION ALL
SELECT
' 123456789987654321 'AS SubscriberKey
, '[электронная почта защищена] ' AS EmailAddress
, 'SalesDepartment' AS FirstName
, 'Leads' AS Interest
INTERSECT
Оператор INTERSECT очень похож в использовании на UNION , но вместо объединения результатов он выводит только те которые существуют в обоих запросах.
Давайте проверим, кто совершил конверсию благодаря нашей акции «Черная пятница»
ВЫБЕРИТЕ bf.SubscriberKey
ИЗ BlackFridayPromoSegment AS bfINTERSECT
ВЫБЕРИТЕ p.
ИЗ PurchasesDataPoint AS p
900 05
 SubscriberKey
SubscriberKey Как и UNION , INTERSECT работает только if:
- Оба запроса имеют одинаковое количество столбцов.
- Оба запроса имеют одинаковый порядок столбцов.
- Столбцы в обоих запросах имеют одинаковые типы данных.
Проверка наличия строк в обоих запросах выполняется с учетом данных во всех предоставленных столбцах.
Вы можете получить тот же результат с большим контролем над логикой сравнения, сочетая JOIN и WHERE .
EXCEPT
Оператор EXCEPT по использованию очень похож на UNION , но вместо объединения результатов он выводит только те, которые существуют в первом запросе.
Давайте проверим, кто не конвертировался в нашу акцию Черная пятница
ВЫБРАТЬ bf.SubscriberKey
ИЗ BlackFridayPromoSegment AS bfЗА ИСКЛЮЧЕНИЕМ
ВЫБРАТЬ p.SubscriberKey
ИЗ PurchasesDataPoint AS p
Как и в UNION , ЗА ИСКЛЮЧЕНИЕМ работает, только если:
- Оба запроса имеют одинаковый номер столбцов.
