Sql запрос в sql запросе: Вложенные запросы (SQL Server) — SQL Server
Содержание
PANDAS VS SQL
Время прочтения: 10 мин.
Еще порядка 10 лет назад для работы по исследованию данных было достаточно SQL как инструмента для выборки данных и формирования отчетов по ним. Но время не стоит на месте, и примерно в 2012 году стала стремительно набирать популярность Python-библиотека Pandas. И вот сегодня уже сложно представить работу Data Scientist’а без данного модуля.
Не буду подробно углубляться в то, что предоставляют из себя оба инструмента ввиду их популярности среди аналитиков и исследователей данных, но небольшую справку все-таки оставим:
Итак, SQL (язык структурированных запросов — от англ. Structed Query Language) — это декларативный язык программирования, применяемый для получения и обработки данных с помощью создания запросов внешне похожих по синтаксису на предложения, написанные на английском языке.
Pandas — это модуль для обработки и анализа данных в табличном формате и формате временн́ых рядов на языке Python. Библиотека работает поверх математического модуля более низкого уровня NumPy. Название модуля происходит от эконометрического понятия «панельные данные» (или как его еще называют «лонгитюдные данные» — это данные, которые состоят из повторяющихся наблюдений одних и тех же выбранных единиц, при этом наблюдения производятся в последовательные периоды времени).
Название модуля происходит от эконометрического понятия «панельные данные» (или как его еще называют «лонгитюдные данные» — это данные, которые состоят из повторяющихся наблюдений одних и тех же выбранных единиц, при этом наблюдения производятся в последовательные периоды времени).
Теперь можно приступить к рассмотрению обоих инструментов для работы с данными, при анализе буду сравнивать следующие моменты:
- синтаксис запросов;
- время исполнения запросов;
- сложность понимания/восприятия структуры запроса.
Для анализа рассматрим один из самых популярных датасетов — описание пассажиров Титаника. Датасет можно скачать с ресурса Kaggle. Общий объем данных по пассажирам представляет менее 1500 строк, но, чтобы мой эксперимент был более наглядным и показательным, все данные я продублировала до 40 000 строк.
По получившемуся датасету я создала базу данных. Использовалась одна из наиболее популярных систем управления базами данных – MySQL. Также данные были считаны в DataFrame – тип данных библиотеки Pandas, который представляет собой проиндексированный многомерный массив.
Также данные были считаны в DataFrame – тип данных библиотеки Pandas, который представляет собой проиндексированный многомерный массив.
Взаимодействовать с данными буду следующими методами:
- через SQL-консоль СУБД;
- также подключусь к БД через встроенные инструменты среды разработки и буду отправлять запросы через SQL-консоль;
- с помощью Pandas через настроенный коннектор и метод Pandas.read_SQL() – данный способ позволяет обращаться к БД с помощью привычных SQL-запросов, результат записывается сразу в DataFrame;
- с помощью методов библиотеки Pandas для работы с DataFrame.
Итак, приступим:
Выполняем основные импорты:
# импорт для работы с библиотекой Pandas import Pandas as pd # импорт для настройки подключения к БД import pymySQL
Подготовка данных:
# записываем данных в DataFrame
titanic_df = pd.read_csv('DATA_PATH')
# настраиваем подключение к БД
conn = pymySQL.connect(host='HOST',port='PORT',user='USER',
passwd='PASSWORD',db='titanic_db')Здесь:
- titanic_db – база данных, в которой хранится информация;
- titanic_data – таблица, из которой мы получаем данные;
- titanic_df – DataFrame, в котором хранится датасет.

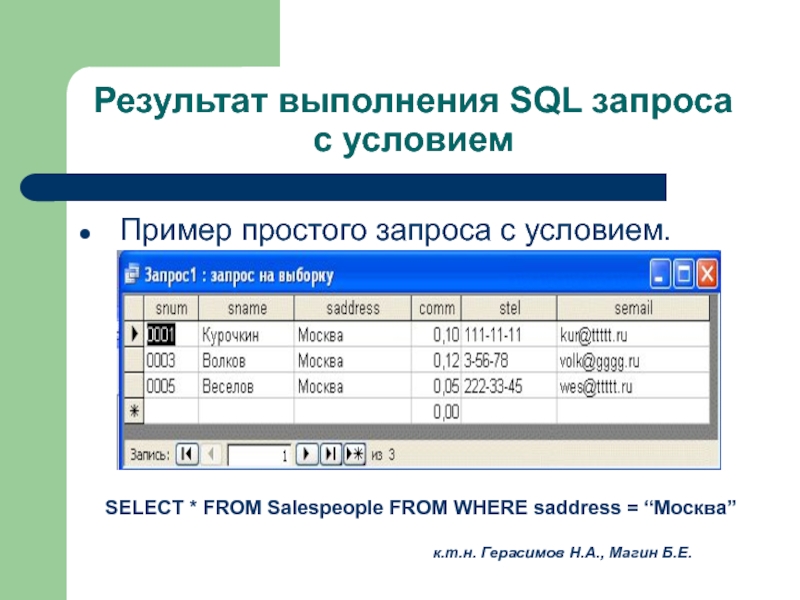
Напомню, что данные в таблице titanic_data и в DataFrame titanic_df – полностью идентичны. Начну с первого самого простого запроса – выведу всю таблицу:
| # | Способ обращения | Запрос | Время исполнения |
| 1 | SQL | SELECT * FROM titanic_data | 0.063s |
| 2 | SQL консоль (IDE) | SELECT * FROM titanic_data | 0.218s |
| 3 | Pandas.read_SQL() | pd.read_SQL(«SELECT * FROM titanic_data «,conn) | 1.39s |
| 4 | DataFrame-методы | titanic_df | менее 1ms |
Уже на этом этапе можно увидеть различия в синтаксисе обращений: при вызове DataFrame-объекта можно обойтись без “select” и “from”, без которых невозможно представить ни один SQL-запрос, а это в свою очередь позволяет сделать запрос короче. Время исполнения запросов, как видно, отличается, но вопрос идет о миллисекундах, полагаю, что в обычной ситуации этой разницы можно и не заметить, но просто вывод DataFrame все-таки оказывается самым быстрым вариантом.
Время исполнения запросов, как видно, отличается, но вопрос идет о миллисекундах, полагаю, что в обычной ситуации этой разницы можно и не заметить, но просто вывод DataFrame все-таки оказывается самым быстрым вариантом.
На предыдущем шаге я выводила все столбцы, теперь попробую вывести только имя, возраст, пол и, например, данные о билете пассажира:
| # | Способ обращения | Запрос | Время исполнения |
| 1 | SQL | SELECT Name, Age, Sex, Ticket FROM titanic_db.titanic_data; | 0.047s |
| 2 | SQL консоль (IDE) | SELECT Name, Age, Sex, Ticket FROM titanic_db.titanic_data; | 0.172s |
| 3 | Pandas.read_SQL() | pd.read_SQL(«SELECT Name, Age, Sex, Ticket FROM titanic_db.titanic_data;»,conn) | 1.06s |
| 4 | DataFrame-методы | titanic_df. loc[:, [‘Name’, ‘Sex’, ‘Age’, ‘Ticket’]] loc[:, [‘Name’, ‘Sex’, ‘Age’, ‘Ticket’]] | менее 1ms |
В SQL-запросе легко можно получить необходимые колонки из датасета просто перечислив их наименования после “select”. С помощью Pandas-запроса одну колонку, например «Name», можно получить вызвав её так: titanic_df[‘Name’]. Но если же необходимо больше одного столбца, то это делается с помощью метода «dataframe.loc[…]» (от англ. location), который дает доступ к группам строк и столбцов по меткам. Запрос получился примерно таким же по длине, но вот для понимания он уже не так прост. С помощью этого запроса, во-первых, можно прописать промежуток строк, которые необходимо вывести, для этого в первой части квадратных скобок стоит знак «:». Можно границы не вписывать, тогда в выводе увидим весь DataFrame. Во-вторых, во второй части квадратных скобок после запятой прописывается список требуемых имен столбцов. Таким образом, можно сказать, что SQL-запрос в данной ситуации оказывается более читабельным, но по скорости Pandas-запрос оказывается быстрее.
Теперь попробую немного усложнить запросы, добавив условия:
В первом случае выведу данные всех пассажиров женского пола (выводить будем колонки, содержащие информацию имени и пола пассажира):
| # | Способ обращения | Запрос | Время исполнения |
| 1 | SQL | SELECT Name, Sex FROM titanic_db.titanic_data WHERE Sex = ‘female’ | 0.015s |
| 2 | SQL консоль (IDE) | SELECT Name, Sex FROM titanic_db.titanic_data WHERE Sex = ‘female’ | 0.203s |
| 3 | Pandas.read_SQL() | pd.read_SQL(«SELECT * FROM titanic_data «,conn) | 0.344s |
| 4 | DataFrame-методы | titanic_df[titanic_df.Sex == ‘female’].loc[:, [‘Name’, ‘Sex’]] | 0.031s |
Обратиться к конкретной колонке DataFrame можно несколькими способами:
- dataframe.Column_name – способ, используемый в примере запроса;
- dataframe[‘Column_name’].

Пожалуй, с этим проблем для восприятия не должно возникать, тем более, что и в SQL похожим образом можно обращаться к столбцам, например, в случае если в запросе фигурирует несколько таблиц с одинаковыми названиями полей.
И опять же, как и в предыдущем запросе в Pandas иногда приходится использовать метод «dataframe.loc[…]», из-за чего вновь страдает читабельность кода. На этот раз SQL-запрос выигрывает по скорости примерно в 2 раза относительно Pandas-запроса.
Теперь добавлю еще одно условие для пассажиров женского пола, посмотрим, у кого в поле Tikcet(Билет) стоит значение более 30 000:
| # | Способ обращения | Запрос | Время исполнения |
| 1 | SQL | SELECT Name, Ticket, Sex FROM titanic_db.titanic_data WHERE sex = ‘female’ and Ticket >= 30000; | 0.047s |
| 2 | SQL консоль (IDE) | SELECT Name, Ticket, Sex FROM titanic_db. titanic_data titanic_dataWHERE sex = ‘female’ and Ticket >= 30000; | 0.141s |
| 3 | Pandas.read_SQL() | pd.read_SQL(«SELECT Name, Ticket, Sex FROM titanic_db.titanic_data « «where sex = ‘female’ and Ticket >= 30000;»,conn) | 0.297s |
| 4 | DataFrame-методы | titanic_df[(titanic_df.Ticket >= 30000) & (titanic_df.Sex == ‘female’) ].loc[:, [‘Name’, ‘Sex’, ‘Ticket’]] | 0.016s |
С подобными запросами нужно соблюдать определённую осторожность. При считывании данных в DataFrame не напрямую из базы данных, а, например, из csv-файла, часто возникает ошибка несоответствия типов. Это может быть вызвано тем, что где-то неверно по разделителям считался датасет, во время манипуляции с данными произошла замена значений в ячейке или в исходном файле оказалось несколько незаполненных ячеек. Все описанные случаи можно запросто не заметить и словить ошибку. Чтобы узнать тип данных колонки, например, ‘Ticker’, в DataFrame достаточно в консоли прописать titanic_df. Ticket или titanic_df[‘Ticket’] и увидеть следующую информацию: Name: Ticket, Length: 40000, dtype: int64. Тип данных в столбце ‘Ticket’ — int64. Если известно, что во всех ячейках колонки DataFrame хранится просто int и при преобразовании int64 к int значения не обрежутся, то все что нужно, чтобы исправить ошибку, это выполнить преобразование типов с помощью запроса: titanic_df[‘Ticket’].astype(‘int’). Либо int’овое значение «30 000» преобразовать к NumPy-типу следующим образом: numpy.int64(30000). Имея опыт работы с данной библиотекой, Data Scientist будет знать, как исправлять подобного рода ошибки, а вот на начальных этапах это может оказаться большим затруднением в работе.
Ticket или titanic_df[‘Ticket’] и увидеть следующую информацию: Name: Ticket, Length: 40000, dtype: int64. Тип данных в столбце ‘Ticket’ — int64. Если известно, что во всех ячейках колонки DataFrame хранится просто int и при преобразовании int64 к int значения не обрежутся, то все что нужно, чтобы исправить ошибку, это выполнить преобразование типов с помощью запроса: titanic_df[‘Ticket’].astype(‘int’). Либо int’овое значение «30 000» преобразовать к NumPy-типу следующим образом: numpy.int64(30000). Имея опыт работы с данной библиотекой, Data Scientist будет знать, как исправлять подобного рода ошибки, а вот на начальных этапах это может оказаться большим затруднением в работе.
Долго рассуждая о проблеме типов, чуть не забыла упомянуть еще одно отличие синтаксиса. Для записи сложных условий в SQL используются AND, OR, NOT, соответственный эквивалент им в Pandas будут «&», «|», «!». По скорости выполнения Pandas-запрос оказался быстрее почти в 3 раза, но если вспомнить, что мне еще пришлось решать ошибку, а на начальных этапах на это может уйти как минимум минут 10-15, то полученные 16 миллисекунд уже могут казаться не такими привлекательными.
С условиями стало понятнее, осталось только разобраться с объединением таблиц. Для этого имеющийся датасет я разбила на 2 таблицы. В первой (passengers_table) будет храниться ключ и имя пассажира, а во второй (passengers_data) ключ, пол пассажира и его возраст.
| # | Способ обращения | Запрос | Время исполнения |
| 1 | SQL | SELECT * FROM titanic_db.passengers_table passenger JOIN titanic_db.passengers_data pas_data ON passenger.ID = pas_data.ID | 0.11s |
| 2 | SQL консоль (IDE) | SELECT * FROM titanic_db.passengers_table passenger JOIN titanic_db.passengers_data pas_data ON passenger.ID = pas_data.ID | 0.219s |
| 3 | Pandas.read_SQL() | pd.read_SQL(«SELECT * FROM titanic_db.passengers_table passenger JOIN titanic_db.passengers_data pas_data ON passenger. ID = pas_data.ID”, conn) ID = pas_data.ID”, conn) | 1.11s |
| 4 | DataFrame-методы | pd.merge(left=people_table, right=people_data, on=’ID’) | 0.047s |
Как можно заметить, чтобы объединить данные в Pandas я воспользовалась методом pd.merge(…) (от англ. объединять, сливать). Метод оказался короче SQL-запроса, да и к тому же довольно приятным для восприятия. Отмечу, что ключевые слова (“left”, “right” и др) указывать необязательно, но поскольку данный метод позволяет указывать ряд других параметров, чтобы просто не запутать себя и вас, в коде они прописаны. Но если честно, с этими параметрами может оказаться, так сказать, палка о двух концах, то есть чем больше параметров придется указать, тем более нагруженным станет код, что вновь приведет к потере читабельности кода. Короткий Pandas-запрос оказался примерно в 2 раза медленнее, чем объединение таблиц в SQL.
И интереса ради можно проверить конкатенацию/объединение таблиц. Для этого разобью таблицу с информацией о пассажирах (passengers_data) на 2 равные таблицы по 20000 строк.
| # | Способ обращения | Запрос | Время исполнения |
| 1 | SQL | SELECT * FROM titanic_db.passengers_data1 UNION all SELECT * FROM titanic_db.passengers_data2 | 0.031s = 31ms |
| 2 | SQL консоль (IDE) | SELECT * FROM titanic_db.passengers_data1 UNION all SELECT * FROM titanic_db.passengers_data2 | 0.109s = 109ms |
| 3 | Pandas.read_SQL() | pd.read_SQL(«select * from titanic_db.passengers_data1 union all select * from titanic_db.passengers_data2»,pd_conn) | 1s = 1000ms |
| 4 | DataFrame-методы | pd.concat([people_data[0:20000], people_data[20001:]]) | 0.016s = 16ms |
Относительно синтаксиса замечу интересный момент: в Pandas всегда можно получить n подряд идущих строк с помощью записи dataframe[start:end], кроме того можно указывать отрицательные значения. Например, запрос df[:-n] выведет все строки, кроме n последних, а запрос df[-n:] вернет только n последних записей. В SQL для этого существует возможность воспользоваться записью «limit start, end». Чтобы объединить все таблицы в Pandas, просто запишу в лист внутри метода concat, согласитесь, что выглядит довольно просто и понятно. А вот SQL предлагает обращаться к каждой таблице отдельно, да и кроме того проигрывает по времени почти в два раза.
Например, запрос df[:-n] выведет все строки, кроме n последних, а запрос df[-n:] вернет только n последних записей. В SQL для этого существует возможность воспользоваться записью «limit start, end». Чтобы объединить все таблицы в Pandas, просто запишу в лист внутри метода concat, согласитесь, что выглядит довольно просто и понятно. А вот SQL предлагает обращаться к каждой таблице отдельно, да и кроме того проигрывает по времени почти в два раза.
С пассажирами Титаника понятно, но как работают SQL и Pandas с реальной базой данных? Для оценки скорости инструментов использовался датасет клиентов банка размером 100000 строк на 30 столбцов.
| Операция с таблицей | Способ обращения | Запрос | Время исполнения |
| Вызов всей таблицы | SQL | SELECT * FROM database.table | 2.367s |
| Вызов всей таблицы | DataFrame-методы | table_df | 0. 112s 112s |
| Вызов нескольких столбцов | SQL | SELECT column_1, column_2, column_3, column_4 FROM database.table | 0.923s |
| Вызов нескольких столбцов | DataFrame-методы | table_df.loc[:,[‘column_1’, ‘column_2’, ‘column_3’, ‘column_4’]] | 0.019s |
| Вызов нескольких столбцов с условием | SQL | SELECT column_1, column_2, column_3, column_4 FROM database.table WHERE column_1 = ‘value’ | 0.717s |
| Вызов нескольких столбцов с условием | DataFrame-методы | table_df[table_df[‘column_1’] == ‘value’].loc[:, [‘Name’, ‘Sex’]] | 0.073s |
Как видно из таблицы Pandas работает с данными быстрее от 5 до 20 раз в зависимости от операции. Но не стоит забывать, что предварительно Pandas’у необходимо время для сохранения датасета в объект типа DataFrame, для чего в нашем случаем для таблицы 100000х30 потребовалось 30,587 секунды, что очень много.
Какие выводы можно сделать? В сравнительной таблице у нас было указано 4 способа взаимодействия с данными, но речь всегда велась только о двух. Я не говорила о запросах через SQL-консоль внутри IDE и SQL-запрос внутри Pandas, по причине того, что они практически аналогичны обычному SQL-запросу, но требуют дополнительной подготовки для работы, это, во-первых. А во-вторых, они всегда оказывались на порядок дольше, поскольку данные способы как минимум работают не напрямую с данными, а через коннекторы обращаются к БД. Но, как и говорилось ранее, в данном сравнении речь шла о миллисекундах, велика вероятность, что при работе с подобной, не особо большой БД, разницы по времени выполнения запросов можно и не заметить. Если вы адепт SQL-запросов, но обстоятельства вынуждают работать с Pandas, не унывайте!
К тому же результаты работы методов Pandas’а не могут не радовать! Если нужно много обработки в рамках одних и тех же таблиц, и мы без проблем их можем выгрузить, то эта библиотека незаменима!
А теперь вернусь к основному сравнению. SQL-запросы все-таки зачастую оказывались хоть и более громоздкими, но более понятными для восприятия. Да, чтобы спокойно работать с Pandas, скорее всего, придется потратить много времени на изучение и борьбу с непонятно откуда взявшимися ошибками. Но за это можно получить неплохую скорость, краткость кода, гибкое изменение формата и формы данных, удобное манипулированные индексами и данными, а также мощный инструмент для агрегаций и преобразований. Помимо прочего, Pandas дает возможность работы с разными форматами (xlsx, csv, pickle, sql и др), а также встроенные методы работы с датой и временем.
SQL-запросы все-таки зачастую оказывались хоть и более громоздкими, но более понятными для восприятия. Да, чтобы спокойно работать с Pandas, скорее всего, придется потратить много времени на изучение и борьбу с непонятно откуда взявшимися ошибками. Но за это можно получить неплохую скорость, краткость кода, гибкое изменение формата и формы данных, удобное манипулированные индексами и данными, а также мощный инструмент для агрегаций и преобразований. Помимо прочего, Pandas дает возможность работы с разными форматами (xlsx, csv, pickle, sql и др), а также встроенные методы работы с датой и временем.
Как в SQL получить первые (или последние) строки запроса? TOP или OFFSET? | Info-Comp.ru
Всем привет, сегодня мы поговорим о том, как в Microsoft SQL Server на языке T-SQL можно оставить только определенное количество первых строк результирующего набора данных. При этом мы рассмотрим два способа реализации этой простой задачи. Также я покажу Вам, как можно вывести, наоборот, только последние строки SQL запроса.
В языке T-SQL существует две стандартные возможности, которые позволяют нам применить фильтр к результирующему набору данных, иными словами, оставить в результате только определённое количество строк. Это могут быть первые строки, с учётом сортировки, что достаточно часто требуется при работе с базами данных на SQL, или последние строки, а также существует возможность вывести любой набор строк, например, пропустить первые строки и вывести определённое количество следующих строк.
Как я уже отметил, существует два способа фильтрации результирующего набора данных, первый – это использование фильтра TOP, и второй – это использование конструкции OFFSET-FETCH, которую мы подробно рассмотрели в отдельном материале — «OFFSET-FETCH в T-SQL – описание и примеры использования».
Заметка! Профессиональный видеокурс по T-SQL для начинающих.
Содержание
- Получаем первые строки результата SQL запроса
- Исходные данные для примеров
- Получаем первые строки запроса с помощью TOP
- Получаем первые строки запроса с помощью OFFSET-FETCH
- Как вывести последние строки SQL запроса?
- Получаем последние строки SQL запроса с помощью TOP
- Получаем последние строки SQL запроса с помощью OFFSET-FETCH
Получаем первые строки результата SQL запроса
Сейчас давайте я покажу, как можно вывести первые строки результирующего набора данных, сначала мы рассмотрим пример с использованием TOP, а затем сделаем то же самое только с помощью OFFSET-FETCH.
Но для начала давайте определимся с исходными данными, чтобы Вы понимали, какие данные у нас есть и что мы получаем в итоге.
Исходные данные для примеров
В качестве сервера у меня выступает Microsoft SQL Server 2016 Express. А теперь давайте представим, что у нас есть таблица TestTable и в ней содержатся следующие данные (перечень товаров с указанием цены).
--Создание таблицы
CREATE TABLE TestTable(
[ProductId] [INT] IDENTITY(1,1) NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [Money] NULL
)
GO
--Добавление строк в таблицу
INSERT INTO TestTable(ProductName, Price)
VALUES ('Системный блок', 300),
('Монитор', 200),
('Клавиатура', 100),
('Мышь', 50),
('Принтер', 200),
('Сканер', 150),
('Телефон', 250),
('Планшет', 300)
GO
--Выборка данных
SELECT * FROM TestTable
Получаем первые строки запроса с помощью TOP
TOP – это инструкция T-SQL, с помощью которой можно ограничить число строк в результирующем наборе данных SQL запроса.
Синтаксис
TOP (Число строк) [PERCENT]
[ WITH TIES ]
У инструкции TOP несколько параметров:
- Число строк – сразу после ключевого слова TOP в скобочках мы указываем число, которое будет означать количество строк в итоговом результате. В инструкции SELECT допускается указание данного числа без скобочек, однако это не рекомендуется;
- PERCENT – параметр, который говорит, что в запросе необходимо оставить не фактическое количество строк, а процент строк от общего количества, т.е. число, указанное ранее, будет означать процент, а не количество;
- WITH TIES – параметр, который говорит, что в результирующий набор необходимо включить и записи с тем же значением, что и последняя строка, в случае наличия подобных записей. Например, если Вам нужно получить 5 самых дорогих товаров, при этом на пятом месте запись с ценой 100, а на шестом месте также цена 100, так вот, без параметра WITH TIES Вам вернётся 5 строк, а если данный параметр указать — вернется 6 строк.
Фильтр TOP обычно применяется с сортировкой данных (ORDER BY), однако это необязательно, можно применять данный фильтр и без сортировки данных, только в этом случае строки будут возвращаться в произвольном порядке (так, как они хранятся).
Пример SQL запроса с TOP – выводим первые 5 строк
Допустим, нам нужно получить 5 самых дорогих товаров, для этого пишем следующий запрос.
SELECT TOP (5) ProductId, ProductName, Price FROM TestTable ORDER BY Price DESC
В данном случае мы указали сортировку по уменьшению цены (ORDER BY Price DESC), а также применили фильтр TOP (5), для ограничения вывода строк результирующего набора.
Пример SQL запроса с TOP и параметром WITH TIES
Сейчас давайте запустим два запроса, в обоих случаях мы будем запрашивать 4 самых дорогих товара, т.е. применим фильтр TOP (4), однако во втором запросе дополнительно мы укажем параметр WITH TIES и посмотрим на разницу итогового результата.
--Без WITH TIES SELECT TOP (4) ProductId, ProductName, Price FROM TestTable ORDER BY Price DESC --С WITH TIES SELECT TOP (4) WITH TIES ProductId, ProductName, Price FROM TestTable ORDER BY Price DESC
В итоге мы очень хорошо видим разницу, в первом случае вывелось 4 строки, а во втором 5, так как товар в 5 строке имеет точно такую же цену, как и товар в 4 строке.
Пример SQL запроса с TOP и параметром PERCENT
В этом примере давайте просто выведем 50 процентов итогового набора записей, т.е. половину. Для этого мы используем параметр PERCENT.
SELECT TOP (50) PERCENT ProductId, ProductName, Price FROM TestTable ORDER BY Price DESC
Так как у нас в таблице TestTable всего 8 записей, нам вывелось 4 строки, т.е. как раз 50 процентов.
Получаем первые строки запроса с помощью OFFSET-FETCH
Вторым способом получения первых строк является использование конструкции OFFSET-FETCH, однако она появилась только в 2012 версии SQL сервер, до этого, соответственно, этот способ использовать не получится.
У конструкции OFFSET-FETCH отсутствуют такие параметры, как PERCENT и WITH TIES, которые есть у фильтра TOP, однако у OFFSET-FETCH есть одно очень важное преимущество – это возможность пропускать определенное количество первых строк.
Примечание! OFFSET-FETCH — это часть конструкции ORDER BY, поэтому без сортировки использовать OFFSET-FETCH не удастся. Также не получится одновременно использовать OFFSET-FETCH и TOP в одном запросе SELECT.
Пример SQL запроса с OFFSET-FETCH — выводим первые 5 строк
Чтобы вывести первые строки с помощью конструкции OFFSET-FETCH, нам нужно в секции OFFSET указать 0, т.е. начинать вывод сразу с первой строки (если указать другое число, то именно такое количество строк будет пропущено). В секции FETCH мы соответственно указываем 5.
SELECT ProductId, ProductName, Price FROM TestTable ORDER BY Price DESC OFFSET 0 ROWS FETCH NEXT 5 ROWS ONLY;
Результат, мы видим, точно такой же, как и в случае с TOP.
Как вывести последние строки SQL запроса?
Если Вам нужно получить не первые строки результирующего набора данных, а последние (например, последние записи в таблице), причем с той же самой сортировкой, то Вы также можете использовать два способа, т.е. и TOP, и OFFSET. В обоих случаях нам нужно будет немного усложнить запросы.
Получаем последние строки SQL запроса с помощью TOP
В случае с TOP нам дополнительно потребуется использовать конструкцию WITH (CTE – обобщенное табличное выражение), для того чтобы выполнить сортировку по идентификатору для применения фильтра TOP, т.е. отобрать самые последние записи. А после этого мы уже можем отсортировать строки так, как нам нужно.
WITH SRC AS (
--Получаем 5 последних строк в таблице
SELECT TOP (5) ProductId, ProductName, Price
FROM TestTable
ORDER BY ProductId DESC
)
SELECT * FROM SRC
ORDER BY ProductId --Применяем нужную нам сортировку
Как видите, нам вывелись 5 последних строк.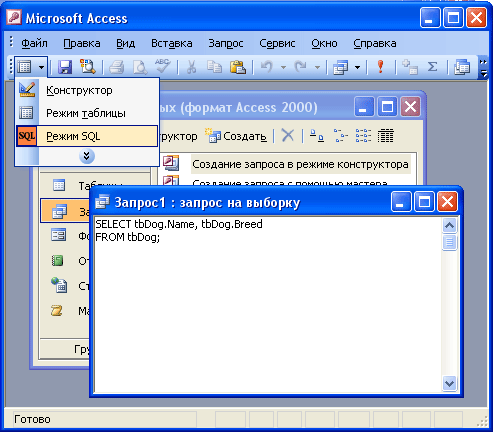
Получаем последние строки SQL запроса с помощью OFFSET-FETCH
Для получения последних строк с помощью OFFSET-FETCH нам потребуется предварительно узнать общее количество строк, для того чтобы определить, сколько строк нужно пропустить. Это можно сделать как с помощью вложенного запроса, так и с помощью предварительного сохранения нужного нам значения в переменной. Я покажу способ с использованием переменной.
--Объявляем переменную DECLARE @CNT INT; --Узнаем количество строк в таблице SELECT @CNT = COUNT(*) FROM TestTable; --Получаем 5 последних строк SELECT ProductId, ProductName, Price FROM TestTable ORDER BY ProductId OFFSET @CNT - 5 ROWS FETCH NEXT 5 ROWS ONLY;
Итоговый результат такой же, как и в запросе с TOP.
Теперь Вы знаете, как с помощью TOP и OFFSET получать первые и последние строки результирующего набора данных, который возвращает SQL запрос.
В данной статье мы затронули одну очень маленькую возможность языка T-SQL, но их, как Вы понимаете, гораздо больше, поэтому, если Вы начинающий программист и хотите изучить язык T-SQL, то рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL.
У меня на этом все, удачи в освоении языка T-SQL!
Логический поток SQL-запроса | SQL глазами базы данных | Манодж Бидади Раджу
Для всех аналитиков данных измените то, как вы смотрите на оператор SQL логически.
Маной Бидади Раджу
·
Читать
Опубликовано в
·
4 мин чтения
·
6, 2 сентября 020
Язык структурированных запросов (SQL) широко известен как романский язык данных. Даже мысль об извлечении единственного правильного ответа из терабайт реляционных данных кажется немного ошеломляющей. Поэтому понимание логической последовательности запросов очень важно.
Photo by Glenn Carstens-Peters on Unsplash
План выполнения запроса
SQL является декларативным языком, это означает, что запрос SQL логически описывает вопрос для оптимизатора запросов SQL, который позже выбирает лучший способ физического выполнения запроса. Этот метод выполнения называется планом выполнения запроса. Может быть более одного плана выполнения, поэтому, когда мы говорим «оптимизировать запрос», это, в свою очередь, означает сделать план выполнения запроса более эффективным.
Этот метод выполнения называется планом выполнения запроса. Может быть более одного плана выполнения, поэтому, когда мы говорим «оптимизировать запрос», это, в свою очередь, означает сделать план выполнения запроса более эффективным.
Рассмотрим 2 потока, через которые можно просмотреть SQL-запрос:
Оператор SELECT в основном сообщает базе данных, какие данные следует извлечь, а также из каких столбцов, строк и таблиц следует получить данные и как сортировать данные.
Сокращенный синтаксис для команды SELECT [1]
- Оператор SELECT начинается со списка столбцов или выражений.
- FROM Часть инструкции SELECT собирает все источники данных в результирующий набор, который используется остальной частью инструкции SELECT.
- ГДЕ 9Предложение 0033 воздействует на набор записей, собранный предложением FROM, для фильтрации определенных строк на основе условий.
- Предложение GROUP BY может группировать большой набор данных в меньшие наборы данных на основе указанных столбцов.
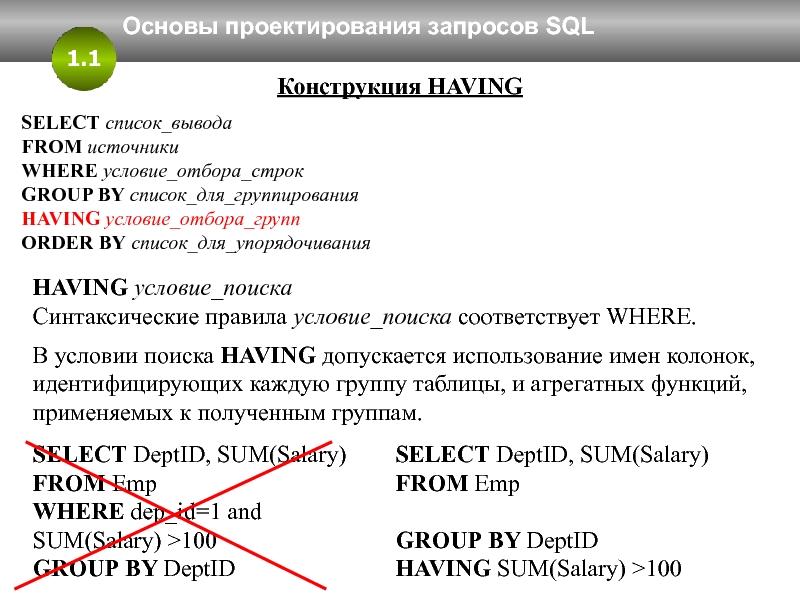
- Предложение HAVING может использоваться для ограничения результата агрегирования с помощью GROUP BY.
- Предложение ORDER BY определяет порядок сортировки набора результатов.

Простейший допустимый оператор SQL:
ВЫБРАТЬ 1; (Для этого Oracle a требует добавления FROM DUAL)
Хммм… В чем проблема в потоке «Syntactical Flow»? Можете ли вы ВЫБРАТЬ данные, не зная, ОТКУДА они берутся?? …Хммм.. Где-то там ЛОГИКА пропала ПРАВИЛЬНО!!! Soo..
Photo by Smart на Unsplash
Лучший способ думать, что оператор SQL — это логический поток запроса. Логический может не совпадать с физическим потоком, а также не совпадать с синтаксисом запроса. Подумайте о запросе в следующем порядке:
Упрощенное представление логического потока [1]
- FROM : Логический запрос начинается с предложения FROM путем сборки начального набора данных.
- WHERE : Затем применяется предложение where для выбора только тех строк, которые соответствуют критериям.
- Агрегации : Более поздняя агрегация выполняется для данных, таких как нахождение суммы, группировка значений данных в столбцах и фильтрация групп.
- Выражения столбцов : После вышеуказанных операций список SELECT обрабатывается вместе с вычислениями всех задействованных в нем выражений. (Кроме выражений столбца, все остальное в SQL-запросе является необязательным.)
- ORDER BY : После получения окончательных результирующих строк сортируются по возрастанию или убыванию по предложению ORDER BY.
- ПРЕВЫШЕНО: Функции управления окнами и ранжирования могут быть позже применены для получения отдельно упорядоченного представления результата с дополнительными функциями для агрегирования.
- DISTINCT : применяется для удаления любых повторяющихся строк, присутствующих в данных результатов.
- TOP: После всего этого процесса отбора данных, фильтрации, выполнения всех вычислений и их упорядочения SQL может ограничить результат несколькими верхними строками.
- ВСТАВКА, ОБНОВЛЕНИЕ, УДАЛЕНИЕ: Это последний логический шаг запроса на изменение данных с использованием полученных результатов.
- UNION : Вывод из нескольких запросов может быть объединен в стек с помощью команды UNION.

Для всех аналитиков данных, которые работают над проектами баз данных или хранилищ данных. Очень важно понимать логический поток и основную логику, стоящую за ним. В любом проекте анализа данных сбор данных будет первым шагом (FROM), после чего следует удаление ненужных данных (WHERE), а затем упорядочение данных (ORDER BY).
[1] Адам Йоргенсен, Патрик Леблан, Хосе Чиншилла, Хорхе Сегарра, Аарон Нельсон, Библия Microsoft® SQL Server® 2012,
sql:query — Drush
Выполнить запрос к базе данных.
Примеры
-
drush sql:query "SELECT * FROM users WHERE uid=1". Просмотр записи пользователя. Префиксы таблиц, если они используются, должны добавляться к именам таблиц вручную. -
drush sql:query --db-prefix "SELECT * FROM {users}". Просмотр записи пользователя. Префиксы таблиц учитываются. Внимание: все фигурные скобки будут удалены. -
$(drush sql:connect) < example.sql. Импорт операторов SQL из файла в текущую базу данных. -
drush sql:query --file=example.sql. Альтернативный способ импорта операторов SQL из файла. -
drush ev "return db_query('SELECT * FROM users')->fetchAll()" --format=json. Получить данные обратно в формате JSON. См. https://github.com/drush-ops/drush/issues/3071#issuecomment-347929777. -
драш sql: подключение-e "выбрать * из лимита пользователей 5;"

Аргументы
- [запрос] . SQL-запрос. Игнорируется, если указан --file.
Опции
- --файл-результата[=ФАЙЛ-РЕЗУЛЬТАТА] . Сохранить в файл. Файл должен относиться к корню Drupal.
- --file=ФАЙЛ . Путь к файлу, содержащему SQL для запуска. Файлы Gzip принимаются.
- --file-delete . Удалите --file после его запуска.
- --extra=ДОПОЛНИТЕЛЬНО . Добавьте пользовательские параметры в строку подключения (например, --extra=--skip-column-names)
- --db-префикс . Включите замену фигурных скобок в вашем запросе.
- --база данных[=БАЗА ДАННЫХ] . Ключ подключения к БД при использовании нескольких подключений в settings.php. [по умолчанию: по умолчанию ]
- --цель[=ЦЕЛЬ] . Имя цели в указанном соединении с базой данных. [по умолчанию: по умолчанию ]
- --db-url=DB-URL . URL-адрес базы данных в стиле Drupal 6. Например, mysql://root:pass@localhost:port/dbname
- --показать-пароли . Показать пароль в CLI. Полезно для отладки.
 URL-адрес базы данных в стиле Drupal 6. Например, mysql://root:pass@localhost:port/dbname
URL-адрес базы данных в стиле Drupal 6. Например, mysql://root:pass@localhost:port/dbname Общие параметры
- -v|vv|vvv, --verbose . Увеличьте уровень детализации сообщений: 1 для обычного вывода, 2 для более подробного вывода и 3 для отладки
- -у, --да . Автоматически принимать значения по умолчанию для всех пользовательских подсказок. Эквивалент --no-interaction.
- -l, --uri=URI . Базовый URL для создания ссылок и выбора мультисайта. По умолчанию https://по умолчанию .
- Чтобы увидеть все глобальные параметры, запустите
темуи выберите первый вариант.
Псевдонимы
- sqlq
- sql-запрос
Легенда
- Аргумент или параметр в квадратных скобках необязателен.
- Любое значение по умолчанию указано в конце описания аргумента/параметра.
