Sql запрос вложенный запрос: Подзапросы в SQL
Содержание
azure-docs.ru-ru/sql-query-subquery.md at master · MicrosoftDocs/azure-docs.ru-ru · GitHub
| title | description | author | ms.service | ms.subservice | ms.topic | ms.date | ms.author | ms.openlocfilehash | ms.sourcegitcommit | ms.translationtype | ms.contentlocale | ms.lasthandoff | ms.locfileid |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Вложенные запросы SQL для Azure Cosmos DB | Сведения о вложенных запросах SQL и их типичных сценариях использования и различных типах вложенных запросов в Azure Cosmos DB | timsander1 | cosmos-db | cosmosdb-sql | conceptual | 12/02/2019 | tisande | f5f209229d17a2587258d21ee90e7560e629d082 | 867cb1b7a1f3a1f0b427282c648d411d0ca4f81f | MT | ru-RU | 03/19/2021 | 93340861 |
[!INCLUDEappliesto-sql-api]
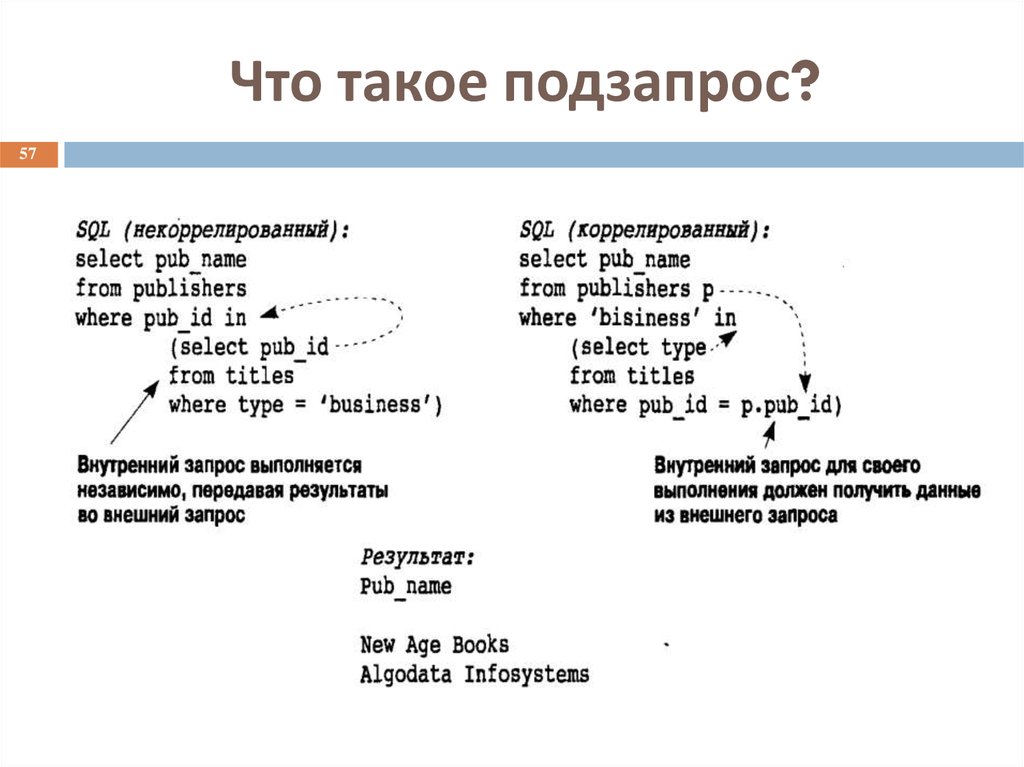
Вложенный запрос — это запрос, расположенный в другом запросе. Вложенный запрос также называется внутренним запросом или внутренней выборкой. Инструкция, содержащая вложенный запрос, обычно называется внешним запросом.
Вложенный запрос также называется внутренним запросом или внутренней выборкой. Инструкция, содержащая вложенный запрос, обычно называется внешним запросом.
В этой статье описываются вложенные запросы SQL и их распространенные варианты использования в Azure Cosmos DB. Все примеры запросов в этом документе можно выполнить для набора данных информации питании, который предварительно загружен на Площадка для тестирования запросов Azure Cosmos DB.
Типы вложенных запросов
Существует два основных типа вложенных запросов:
- Коррелированный: вложенный запрос, который ссылается на значения из внешнего запроса. Вложенный запрос вычисляется один раз для каждой строки, обрабатываемой внешним запросом.
- Некоррелированный: вложенный запрос, который не зависит от внешнего запроса. Его можно выполнять самостоятельно, не полагаясь на внешний запрос.
[!NOTE]
Azure Cosmos DB поддерживает только коррелированные вложенные запросы.
Вложенные запросы можно дополнительно классифицировать на основе числа возвращаемых строк и столбцов. Здесь возможны три варианта:
- Table: возвращает несколько строк и несколько столбцов.
- Множественное значение: возвращает несколько строк и один столбец.
- Scalar: Возвращает одну строку и один столбец.
SQL-запросы в Azure Cosmos DB всегда возвращают один столбец (простое значение или сложный документ). Таким образом, в Azure Cosmos DB применимы только многозначные и скалярные вложенные запросы. Вложенный запрос с несколькими значениями можно использовать только в предложении FROM в качестве реляционного выражения. Скалярный вложенный запрос можно использовать в качестве скалярного выражения в предложении SELECT или WHERE или в качестве реляционного выражения в предложении FROM.
Вложенные запросы с несколькими значениями
Вложенные запросы с несколькими значениями возвращают набор документов и всегда используются в предложении FROM. Они используются для:
Они используются для:
- Оптимизация выражений соединений.
- Оценка дорогостоящих выражений один раз и многократная ссылка.
Выражения оптимизации соединений
Вложенные запросы с несколькими значениями могут оптимизировать выражения объединения, помещая предикаты после каждого выражения SELECT-many, а не после всех перекрестных соединений в предложении WHERE.
Обратите внимание на следующий запрос:
SELECT Count(1) AS Count FROM c JOIN t IN c.tags JOIN n IN c.nutrients JOIN s IN c.servings WHERE t.name = 'infant formula' AND (n.nutritionValue > 0 AND n.nutritionValue < 10) AND s.amount > 1
Для этого запроса индекс будет соответствовать любому документу с тегом с именем «Формула новорожденный». Это элемент нутриент со значением от 0 до 10 и обслуживающим элементом с суммой больше 1. Выражение JOIN здесь выполняет перекрестное произведение всех элементов тегов, нутриентс и обслуживает массивы для каждого соответствующего документа до применения любого фильтра.
Затем предложение WHERE применит предикат фильтра для каждого <ного кортежа c, t, n, s>. Например, если в соответствующем документе в каждом из трех массивов было 10 элементов, оно будет расширено до 1 x 10 x 10 x 10 (то есть 1 000) кортежей. С помощью вложенных запросов можно фильтровать соединяемые элементы массива перед присоединением к следующему выражению.
Этот запрос эквивалентен предыдущему, но использует вложенные запросы:
SELECT Count(1) AS Count FROM c JOIN (SELECT VALUE t FROM t IN c.tags WHERE t.name = 'infant formula') JOIN (SELECT VALUE n FROM n IN c.nutrients WHERE n.nutritionValue > 0 AND n.nutritionValue < 10) JOIN (SELECT VALUE s FROM s IN c.servings WHERE s.amount > 1)
Предположим, что только один элемент в массиве Tags соответствует фильтру, а для нутриентс и обслуживания массивов существует пять элементов. Затем выражения объединения разворачиваются до 1 x 1 x 5 x 5 = 25 элементов, а не 1 000 элементов в первом запросе.
Многократное вычисление и ссылка
Вложенные запросы могут помочь оптимизировать запросы с дорогостоящими выражениями, такими как определяемые пользователем функции (UDF), сложные строки или арифметические выражения. Можно использовать вложенный запрос вместе с выражением объединения для вычисления выражения, но ссылаться на него много раз.
Следующий запрос дважды запускает определяемую пользователем функцию GetMaxNutritionValue :
SELECT c.id, udf.GetMaxNutritionValue(c.nutrients) AS MaxNutritionValue FROM c WHERE udf.GetMaxNutritionValue(c.nutrients) > 100
Ниже приведен эквивалентный запрос, запускающий UDF только один раз:
SELECT TOP 1000 c.id, MaxNutritionValue FROM c JOIN (SELECT VALUE udf.GetMaxNutritionValue(c.nutrients)) MaxNutritionValue WHERE MaxNutritionValue > 100
[!NOTE]
Учитывайте поведение перекрестного произведения выражений JOIN.Если выражение UDF может принимать значение undefine, следует убедиться, что выражение JOIN всегда создает одну строку, возвращая объект из вложенного запроса, а не значение напрямую.
 Если выражение UDF может принимать значение undefine, следует убедиться, что выражение JOIN всегда создает одну строку, возвращая объект из вложенного запроса, а не значение напрямую.
Если выражение UDF может принимать значение undefine, следует убедиться, что выражение JOIN всегда создает одну строку, возвращая объект из вложенного запроса, а не значение напрямую.Вот похожий пример, возвращающий объект, а не значение:
SELECT TOP 1000 c.id, m.MaxNutritionValue FROM c JOIN (SELECT udf.GetMaxNutritionValue(c.nutrients) AS MaxNutritionValue) m WHERE m.MaxNutritionValue > 100
Этот подход не ограничивается UDF. Он применяется к любому потенциально дорогостоящему выражению. Например, можно использовать тот же подход с математической функцией avg :
SELECT TOP 1000 c.id, AvgNutritionValue FROM c JOIN (SELECT VALUE avg(n.nutritionValue) FROM n IN c.nutrients) AvgNutritionValue WHERE AvgNutritionValue > 80
Имитировать соединение с внешними эталонными данными
Часто бывает необходимо ссылаться на статические данные, которые редко изменяются, например единицы измерения или коды стран. Лучше не дублировать эти данные для каждого документа. Избежание этого дублирования позволит экономить место на хранении и повышать производительность операций записи, сохраняя размер документа. Вложенный запрос можно использовать для имитации семантики внутреннего объединения с помощью коллекции ссылочных данных.
Лучше не дублировать эти данные для каждого документа. Избежание этого дублирования позволит экономить место на хранении и повышать производительность операций записи, сохраняя размер документа. Вложенный запрос можно использовать для имитации семантики внутреннего объединения с помощью коллекции ссылочных данных.
Например, рассмотрим следующий набор ссылочных данных:
| Единица измерения | имя; | Множитель | Базовая единица |
|---|---|---|---|
| NG | Микрограмматика | 1,00 e-09 | Gram |
| μг | микрограм | 1,00 e-06 | Gram |
| mg | миллиграм | 1,00 e-03 | Gram |
| н | Gram | 1,00 e + 00 | Gram |
| кг | Килограмм | 1,00 e + 03 | Gram |
| MG | мегаграм | 1,00 e + 06 | Gram |
| GG | гигаграм | 1,00 e + 09 | Gram |
| nJ | наножауле | 1,00 e-09 | жауле |
| μж | микрожауле | 1,00 e-06 | жауле |
| mJ | миллижауле | 1,00 e-03 | жауле |
| J | жауле | 1,00 e + 00 | жауле |
| kJ | киложауле | 1,00 e + 03 | жауле |
| MJ | мегажауле | 1,00 e + 06 | жауле |
| гж | гигажауле | 1,00 e + 09 | жауле |
| Cal | калорие | 1,00 e + 00 | калорие |
| ккал | калорие | 1,00 e + 03 | калорие |
| IU | Международные единицы |
Следующий запрос имитирует соединение с этими данными, чтобы добавить в выходные данные имя единицы измерения:
SELECT TOP 10 n.
 id, n.description, n.nutritionValue, n.units, r.name
FROM food
JOIN n IN food.nutrients
JOIN r IN (
SELECT VALUE [
{unit: 'ng', name: 'nanogram', multiplier: 0.000000001, baseUnit: 'gram'},
{unit: 'µg', name: 'microgram', multiplier: 0.000001, baseUnit: 'gram'},
{unit: 'mg', name: 'milligram', multiplier: 0.001, baseUnit: 'gram'},
{unit: 'g', name: 'gram', multiplier: 1, baseUnit: 'gram'},
{unit: 'kg', name: 'kilogram', multiplier: 1000, baseUnit: 'gram'},
{unit: 'Mg', name: 'megagram', multiplier: 1000000, baseUnit: 'gram'},
{unit: 'Gg', name: 'gigagram', multiplier: 1000000000, baseUnit: 'gram'},
{unit: 'nJ', name: 'nanojoule', multiplier: 0.000000001, baseUnit: 'joule'},
{unit: 'µJ', name: 'microjoule', multiplier: 0.000001, baseUnit: 'joule'},
{unit: 'mJ', name: 'millijoule', multiplier: 0.001, baseUnit: 'joule'},
{unit: 'J', name: 'joule', multiplier: 1, baseUnit: 'joule'},
{unit: 'kJ', name: 'kilojoule', multiplier: 1000, baseUnit: 'joule'},
{unit: 'MJ', name: 'megajoule', multiplier: 1000000, baseUnit: 'joule'},
{unit: 'GJ', name: 'gigajoule', multiplier: 1000000000, baseUnit: 'joule'},
{unit: 'cal', name: 'calorie', multiplier: 1, baseUnit: 'calorie'},
{unit: 'kcal', name: 'Calorie', multiplier: 1000, baseUnit: 'calorie'},
{unit: 'IU', name: 'International units'}
]
)
WHERE n.
id, n.description, n.nutritionValue, n.units, r.name
FROM food
JOIN n IN food.nutrients
JOIN r IN (
SELECT VALUE [
{unit: 'ng', name: 'nanogram', multiplier: 0.000000001, baseUnit: 'gram'},
{unit: 'µg', name: 'microgram', multiplier: 0.000001, baseUnit: 'gram'},
{unit: 'mg', name: 'milligram', multiplier: 0.001, baseUnit: 'gram'},
{unit: 'g', name: 'gram', multiplier: 1, baseUnit: 'gram'},
{unit: 'kg', name: 'kilogram', multiplier: 1000, baseUnit: 'gram'},
{unit: 'Mg', name: 'megagram', multiplier: 1000000, baseUnit: 'gram'},
{unit: 'Gg', name: 'gigagram', multiplier: 1000000000, baseUnit: 'gram'},
{unit: 'nJ', name: 'nanojoule', multiplier: 0.000000001, baseUnit: 'joule'},
{unit: 'µJ', name: 'microjoule', multiplier: 0.000001, baseUnit: 'joule'},
{unit: 'mJ', name: 'millijoule', multiplier: 0.001, baseUnit: 'joule'},
{unit: 'J', name: 'joule', multiplier: 1, baseUnit: 'joule'},
{unit: 'kJ', name: 'kilojoule', multiplier: 1000, baseUnit: 'joule'},
{unit: 'MJ', name: 'megajoule', multiplier: 1000000, baseUnit: 'joule'},
{unit: 'GJ', name: 'gigajoule', multiplier: 1000000000, baseUnit: 'joule'},
{unit: 'cal', name: 'calorie', multiplier: 1, baseUnit: 'calorie'},
{unit: 'kcal', name: 'Calorie', multiplier: 1000, baseUnit: 'calorie'},
{unit: 'IU', name: 'International units'}
]
)
WHERE n. units = r.unit
units = r.unitскалярные вложенные запросы;
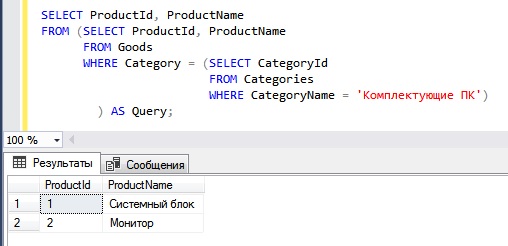
Скалярное выражение вложенного запроса — это вложенный запрос, результатом которого является единственное значение. Значением скалярного выражения вложенного запроса является значение проекции (предложение SELECT) вложенного запроса. Можно использовать скалярное выражение вложенного запроса во многих местах, где допустимо использование скалярного выражения. Например, можно использовать скалярный вложенный запрос в любом выражении в предложениях SELECT и WHERE.
Однако использование скалярного вложенного запроса не всегда помогает оптимизировать. Например, передача скалярного вложенного запроса в качестве аргумента в системную или определяемую пользователем функцию не дает никаких преимуществ в использовании единицы ресурсов (RU) или задержке.
Скалярные вложенные запросы можно дополнительно классифицировать следующим образом:
- Скалярные вложенные запросы в простых выражениях
- Агрегирование скалярных вложенных запросов
Скалярные вложенные запросы в простых выражениях
Скалярный вложенный запрос с простым выражением — это Коррелированный вложенный запрос, имеющий предложение SELECT, которое не содержит статистических выражений. Эти вложенные запросы не дают никаких преимуществ оптимизации, поскольку компилятор преобразует их в одно более крупное простое выражение. Нет коррелированного контекста между внутренними и внешними запросами.
Эти вложенные запросы не дают никаких преимуществ оптимизации, поскольку компилятор преобразует их в одно более крупное простое выражение. Нет коррелированного контекста между внутренними и внешними запросами.
Рассмотрим несколько примеров.
Пример 1
SELECT 1 AS a, 2 AS b
Можно переписать этот запрос с помощью скалярного вложенного запроса простого выражения, чтобы:
SELECT (SELECT VALUE 1) AS a, (SELECT VALUE 2) AS b
Эти выходные данные создаются в обоих запросах:
[
{ "a": 1, "b": 2 }
]Пример 2
SELECT TOP 5 Concat('id_', f.id) AS id
FROM food fМожно переписать этот запрос с помощью скалярного вложенного запроса простого выражения, чтобы:
SELECT TOP 5 (SELECT VALUE Concat('id_', f.id)) AS id
FROM food fВыходные данные запроса:
[
{ "id": "id_03226" },
{ "id": "id_03227" },
{ "id": "id_03228" },
{ "id": "id_03229" },
{ "id": "id_03230" }
]Пример 3
SELECT TOP 5 f.
 id, Contains(f.description, 'fruit') = true ? f.description : undefined
FROM food f
id, Contains(f.description, 'fruit') = true ? f.description : undefined
FROM food fМожно переписать этот запрос с помощью скалярного вложенного запроса простого выражения, чтобы:
SELECT TOP 10 f.id, (SELECT f.description WHERE Contains(f.description, 'fruit')).description FROM food f
Выходные данные запроса:
[
{ "id": "03230" },
{ "id": "03238", "description":"Babyfood, dessert, tropical fruit, junior" },
{ "id": "03229" },
{ "id": "03226", "description":"Babyfood, dessert, fruit pudding, orange, strained" },
{ "id": "03227" }
]Агрегирование скалярных вложенных запросов
Статистический скалярный вложенный запрос — это вложенный запрос, имеющий агрегатную функцию в проекции или фильтре, результатом которой является единственное значение.
Пример 1.
Вот вложенный запрос с одним выражением агрегатной функции в его проекции:
SELECT TOP 5
f. id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg'
) AS count_mg
FROM food f id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg'
) AS count_mg
FROM food f
id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg'
) AS count_mg
FROM food fВыходные данные запроса:
[
{ "id": "03230", "count_mg": 13 },
{ "id": "03238", "count_mg": 14 },
{ "id": "03229", "count_mg": 13 },
{ "id": "03226", "count_mg": 15 },
{ "id": "03227", "count_mg": 19 }
]Пример 2
Вот вложенный запрос с несколькими выражениями агрегатных функций:
SELECT TOP 5 f.id, (
SELECT Count(1) AS count, Sum(n.nutritionValue) AS sum
FROM n IN f.nutrients
WHERE n.units = 'mg'
) AS unit_mg
FROM food fВыходные данные запроса:
[
{ "id": "03230","unit_mg": { "count": 13,"sum": 147.072 } },
{ "id": "03238","unit_mg": { "count": 14,"sum": 107.385 } },
{ "id": "03229","unit_mg": { "count": 13,"sum": 141.579 } },
{ "id": "03226","unit_mg": { "count": 15,"sum": 183.91399999999996 } },
{ "id": "03227","unit_mg": { "count": 19,"sum": 94. 788999999999987 } }
] 788999999999987 } }
]
788999999999987 } }
]Пример 3
Вот запрос со статистическим вложенным запросом как в проекции, так и в фильтре:
SELECT TOP 5
f.id,
(SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg') AS count_mg
FROM food f
WHERE (SELECT VALUE Count(1) FROM n IN f.nutrients WHERE n.units = 'mg') > 20Выходные данные запроса:
[
{ "id": "03235", "count_mg": 27 },
{ "id": "03246", "count_mg": 21 },
{ "id": "03267", "count_mg": 21 },
{ "id": "03269", "count_mg": 21 },
{ "id": "03274", "count_mg": 21 }
]Более оптимальный способ написания этого запроса — соединение во вложенном запросе и ссылка на псевдоним вложенного запроса в предложениях SELECT и WHERE. Этот запрос более эффективен, поскольку необходимо выполнить вложенный запрос только внутри инструкции JOIN, а не в проекции и фильтре.
SELECT TOP 5 f.id, count_mg FROM food f JOIN (SELECT VALUE Count(1) FROM n IN f.
 nutrients WHERE n.units = 'mg') AS count_mg
WHERE count_mg > 20
nutrients WHERE n.units = 'mg') AS count_mg
WHERE count_mg > 20Выражение EXISTs
Azure Cosmos DB поддерживает выражения EXISTs. Это совокупный скалярный вложенный запрос, встроенный в Azure Cosmos DB API SQL. EXISTs является логическим выражением, которое принимает выражение вложенного запроса и возвращает значение true, если вложенный запрос возвращает какие-либо строки. В противном случае возвращается значение false.
Так как API Azure Cosmos DB SQL не различает логические выражения и другие скалярные выражения, можно использовать в предложениях SELECT и WHERE. Это отличается от T-SQL, где логическое выражение (например, EXISTs, BETWEEN и IN) ограничено фильтром.
Если вложенный запрос EXISTs возвращает одиночное значение, которое не определено, то параметр EXISTs принимает значение false. Например, рассмотрим следующий запрос, результатом которого является значение false:
SELECT EXISTS (SELECT VALUE undefined)
Если ключевое слово VALUE в предыдущем вложенном запросе опущено, результатом вычисления запроса будет значение true:
SELECT EXISTS (SELECT undefined)
Вложенный запрос будет заключать список значений в выбранном списке в объекте.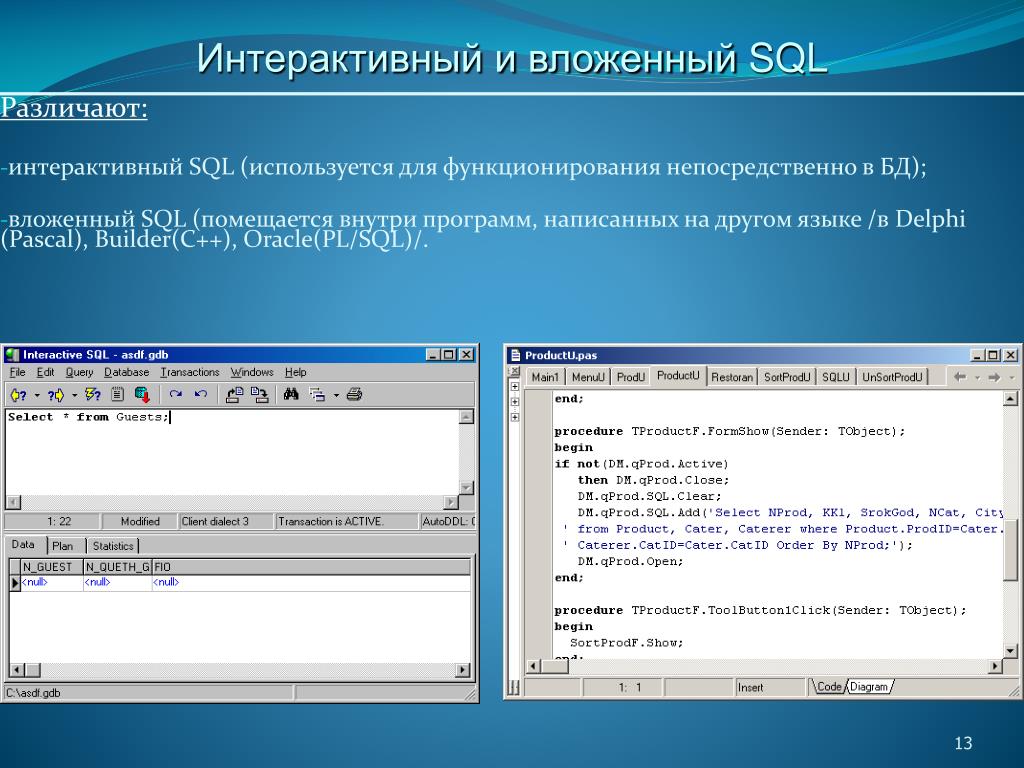 Если выбранный список не содержит значений, вложенный запрос возвратит единственное значение » {} «. Это значение определено, поэтому EXISTs вычисляется как true.
Если выбранный список не содержит значений, вложенный запрос возвратит единственное значение » {} «. Это значение определено, поэтому EXISTs вычисляется как true.
Пример: перезапись ARRAY_CONTAINS и присоединение как существует
Распространенным вариантом использования ARRAY_CONTAINS является фильтрация документа по существованию элемента в массиве. В этом случае мы проверяя, содержит ли массив Tags элемент с именем «оранжевый».
SELECT TOP 5 f.id, f.tags
FROM food f
WHERE ARRAY_CONTAINS(f.tags, {name: 'orange'})Вы можете переписать тот же запрос, чтобы использовать EXISTs:
SELECT TOP 5 f.id, f.tags FROM food f WHERE EXISTS(SELECT VALUE t FROM t IN f.tags WHERE t.name = 'orange')
Кроме того, ARRAY_CONTAINS может проверять, равно ли значение любому элементу в массиве. Если требуются более сложные фильтры для свойств массива, используйте JOIN.
Рассмотрим следующий запрос, который фильтруется на основе единиц и nutritionValue свойств в массиве:
SELECT VALUE c.
 description
FROM c
JOIN n IN c.nutrients
WHERE n.units= "mg" AND n.nutritionValue > 0
description
FROM c
JOIN n IN c.nutrients
WHERE n.units= "mg" AND n.nutritionValue > 0Для каждого документа в коллекции перекрестное произведение выполняется с элементами массива. Эта операция объединения позволяет фильтровать свойства в массиве. Однако этот запрос будет иметь большое количество запросов. Например, если в 1 000 документах в каждом массиве содержалось 100 элементов, оно будет расширено до 1 000 x 100 (т. е. 100 000) кортежей.
Использование EXISTs может помочь избежать этого дорогостоящего перекрестного произведения:
SELECT VALUE c.description
FROM c
WHERE EXISTS(
SELECT VALUE n
FROM n IN c.nutrients
WHERE n.units = "mg" AND n.nutritionValue > 0
)В этом случае вы фильтруете элементы массива внутри вложенного запроса EXISTs. Если элемент массива соответствует фильтру, то его проект и EXISTs будут иметь значение true.
Псевдоним также может существовать и ссылаться на него в проекции:
SELECT TOP 1 c.
 description, EXISTS(
SELECT VALUE n
FROM n IN c.nutrients
WHERE n.units = "mg" AND n.nutritionValue > 0) as a
FROM c
description, EXISTS(
SELECT VALUE n
FROM n IN c.nutrients
WHERE n.units = "mg" AND n.nutritionValue > 0) as a
FROM cВыходные данные запроса:
[
{
"description": "Babyfood, dessert, fruit pudding, orange, strained",
"a": true
}
]Выражение массива
Можно использовать выражение массива для проецирования результатов запроса в виде массива. Это выражение можно использовать только в предложении SELECT запроса.
SELECT TOP 1 f.id, ARRAY(SELECT VALUE t.name FROM t in f.tags) AS tagNames FROM food f
Выходные данные запроса:
[
{
"id": "03238",
"tagNames": [
"babyfood",
"dessert",
"tropical fruit",
"junior"
]
}
]Как и в случае с другими вложенными запросами, возможны фильтры с выражением массива.
SELECT TOP 1 c.id, ARRAY(SELECT VALUE t FROM t in c.
 tags WHERE t.name != 'infant formula') AS tagNames
FROM c
tags WHERE t.name != 'infant formula') AS tagNames
FROM cВыходные данные запроса:
[
{
"id": "03226",
"tagNames": [
{
"name": "babyfood"
},
{
"name": "dessert"
},
{
"name": "fruit pudding"
},
{
"name": "orange"
},
{
"name": "strained"
}
]
}
]Выражения массива могут также следовать после предложения FROM во вложенных запросах.
SELECT TOP 1 c.id, ARRAY(SELECT VALUE t.name FROM t in c.tags) as tagNames FROM c JOIN n IN (SELECT VALUE ARRAY(SELECT t FROM t in c.tags WHERE t.name != 'infant formula'))
Выходные данные запроса:
[
{
"id": "03238",
"tagNames": [
"babyfood",
"dessert",
"tropical fruit",
"junior"
]
}
]Дальнейшие действия
- Примеры . NET для Azure Cosmos DB
- Данные документов модели
 NET для Azure Cosmos DB
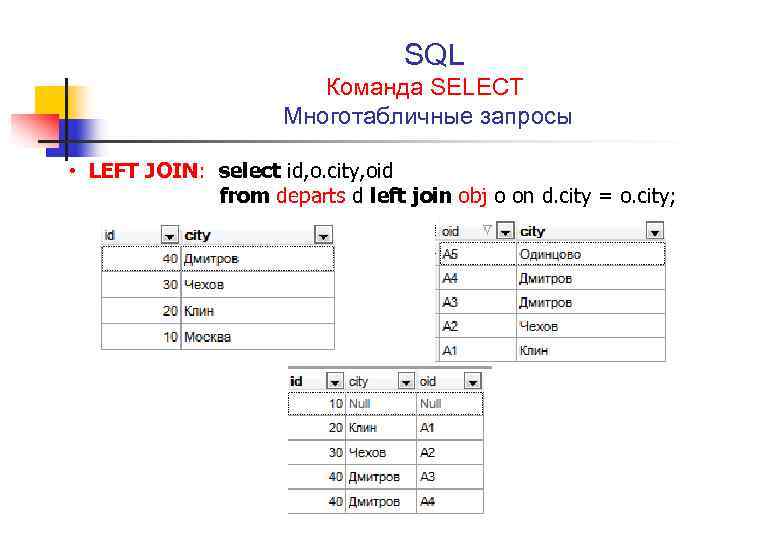
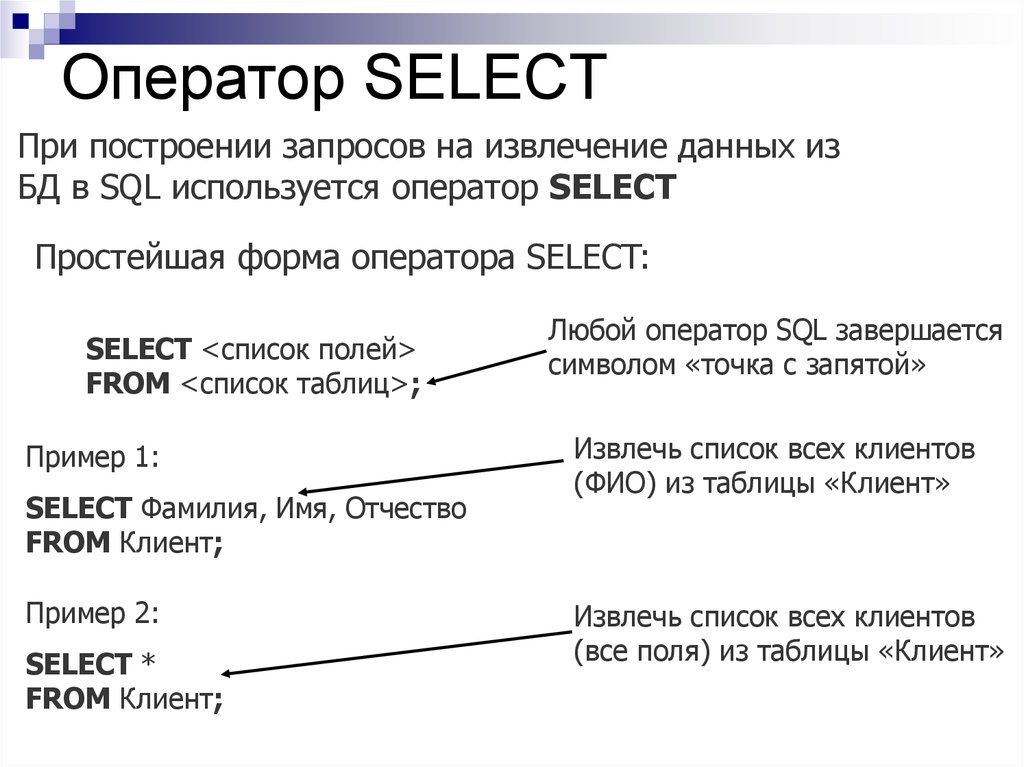
NET для Azure Cosmos DBМноготабличные и вложенные запросы — Проектирование баз данных на SQL (Информатика и программирование)
Лекция 22. Многотабличные и вложенные запросы
Как правило, запросы выполняют обработку данных, расположенных во множестве таблиц. Попытка соединить таблицы по «умолчанию», приведет к декартовому произведению двух таблиц и вернет бессмысленный результат, например, если построить запрос по таблицам 7.3 и 7.4, следующим образом:
SELECT *
FROM А, В
Из раздела реляционной алгебры известно, что под соединением двух таблиц (будем рассматривать экви-соединение) понимается последовательность выполнения операции декартового произведения и выборки, т.е.:
SELECT *
FROM А, В
WHERE А.Код_товара = В.Код_тов
Использование подобного метода возвратит верный результат, приведенный в таблице 7.6. Описанный способ соединения, был единственным в первом стандарте языка SQL.
Стандарт SQL2 расширил возможности соединения до так называемого внешнего соединения (внутренним принято считать соединение с использованием предложения WHERE).
В общем случае синтаксис внешнего соединения выглядит следующим образом:
FROM <Таблица1> <вид соединения> JOIN <Таблица2> ON <Условие соединения>
Вид соединения определяет главную (ведущую) таблицу в соединении и может определяться следующими служебными словами:
§ LEFT – левое внешнее соединение, когда ведущей является таблица слева от вида соединения;
§ RIGHT – правое внешнее соединение, когда ведущей является таблица справа от вида соединения;
§ FULL — полное внешнее соединение, когда обе таблица равны в соединении;
§ INNER – вариант внутреннего соединения.
По правилу внешних соединений, ведущая таблица должна войти в результат запроса всеми своими записями, независимо от наличия соответствующих записей в присоединяемой таблице.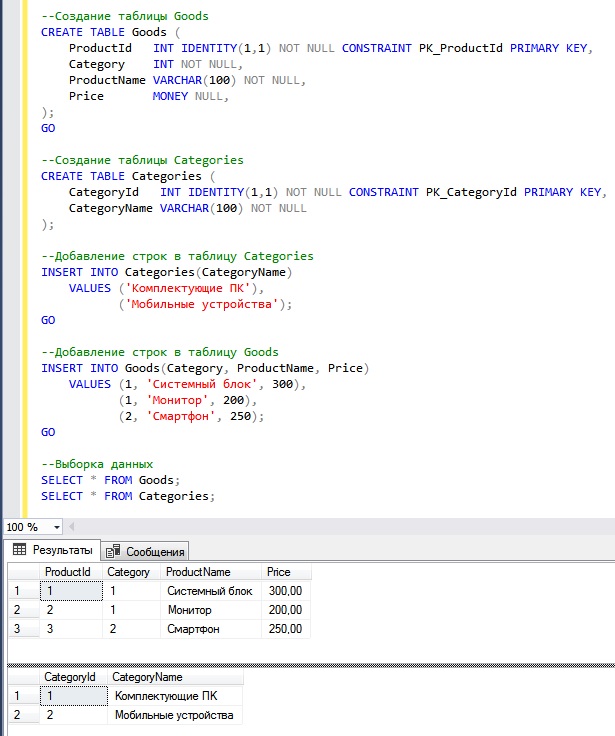
Приведем пример реализации внутреннего соединения для стандарта SQL2:
SELECT *
FROM А INNER JOIN В ON А.Код_товара = В.Код_тов
Вариант внешнего соединения, когда левая таблица является главной (ведущей):
SELECT *
FROM А LEFT JOIN В ON А.Код_товара = В.Код_тов
Продемонстрируем соединение нескольких таблиц на основе проекта «Библиотека». Пусть требуется получить информацию о принадлежности книг к тем или иным предметным областям. Известно, что каталог областей знаний и таблица «Книга» соединяются через промежуточную таблицу «Связь», в этом случае запрос может выглядеть следующим образом:
SELECT Каталог.Наименование as Область_знаний, Книги. ISBN, Книги.Название as Книга
ISBN, Книги.Название as Книга
FROM Книги INNER JOIN (Каталог INNER JOIN Связь ON Каталог.Код_ОЗ = Связь.Код_ОЗ) ON Книги.ISBN = Связь.ISBN;
Группировка по соединяемым таблицам не отличается от группировки по данным одной таблицы. Пусть требуется отобразить перечень читателей библиотеки с указанием количества книг, находящихся у них на руках, тогда запрос может выглядеть следующим образом:
SELECT DISTINCT Читатели.ФИО, Count(*) AS (Количество_книг)
FROM Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ
GROUP BY Читатели.ФИО, Читатели.Номер_ЧБ, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No;
Следующий запрос возвращает информацию о должниках и книгах, которые они должны были сдать в библиотеку с сортировкой по дате возврата:
SELECT Книги. Название, Книги.Автор, Экземпляры.Инв_номер, Экземпляры.Дата_возврата, Читатели.Номер_ЧБ, Читатели.ФИО, Читатели.Тел_дом, Читатели.Тел_раб
Название, Книги.Автор, Экземпляры.Инв_номер, Экземпляры.Дата_возврата, Читатели.Номер_ЧБ, Читатели.ФИО, Читатели.Тел_дом, Читатели.Тел_раб
FROM Книги INNER JOIN (Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ) ON Книги.ISBN = Экземпляры.ISBN
WHERE Экземпляры.Дата_возврата < Now() AND Экземпляры.Наличие=No
ORDER BY Экземпляры.Дата_возврата;
Вложенные запросы
Язык SQL позволяет вкладывать запросы друга в друга, это относится к оператору SELECT. Оператор SELECT, вложенный в другой оператор SELECT, INSERT, UPDATE или DELETE., называется вложенным запросом.
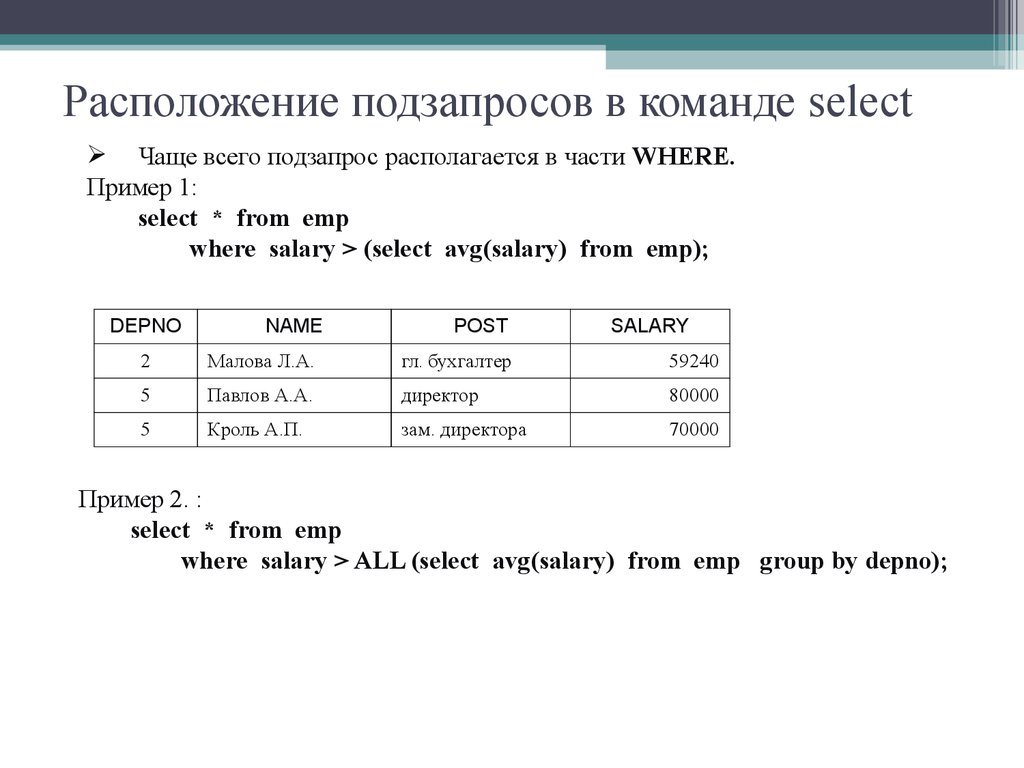
Вложенный оператор SELECT может употребляться в разделах WHERE или HAVING основного запроса и возвращать наборы данных, которые будут использоваться для формирования условий выборки требуемых значений основным запросом.
Средства языка SQL для создания и использования вложенных запросов можно считать избыточными, т.е. вложенность может быть реализована разными способами.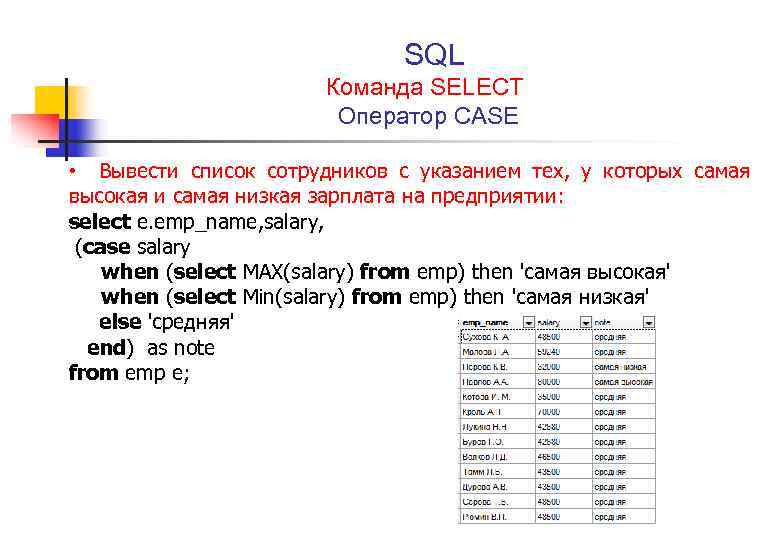
Если вложенный запрос возвращает одно значение (например, агрегат), то оно может использоваться в любом месте, где применяется подобное значение соответствующего типа. Если вложенный запрос возвращает один столбец, то его можно использовать только в директиве WHERE. Во многих случаях вместо вложенного запроса используется оператор объединения, однако некоторые задачи выполняются только с помощью вложенных запросов.
Вложенный запрос всегда заключается в скобки и, если только это не связанный вложенный запрос, завершает выполнение раньше, чем внешний запрос. Вложенный запрос может содержать другой вложенный запрос, который, в свою очередь, тоже может содержать вложенный запрос, и так далее. Глубина вложенности ограничивается только ресурсами системы. Синтаксис вложенного оператора SELECT более короткий и имеет следующий вид:
(SELECT [ALL | DISTINCT] слисок_ столбцов _вложенного_запроса
[FROM список_ таблиц]
[WHERE директива]
[GROUP BY директива]
[HAVING директива])
Приведем пример сложного вложенного запроса. Пусть необходимо получить список читателей имеющих максимальное число книг на руках, при условии, что максимальное количество книг у читателя не ограничено:
Пусть необходимо получить список читателей имеющих максимальное число книг на руках, при условии, что максимальное количество книг у читателя не ограничено:
SELECT Читатели.Номер_ЧБ, Читатели.ФИО, COUNT(*) AS Количество
FROM Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ
GROUP BY Читатели.Номер_ЧБ, Читатели.ФИО, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No AND COUNT(*) =
(SELECT MAX(Количество)
FROM
(SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Экземпляры.Номер_ЧБ, Экземпляры.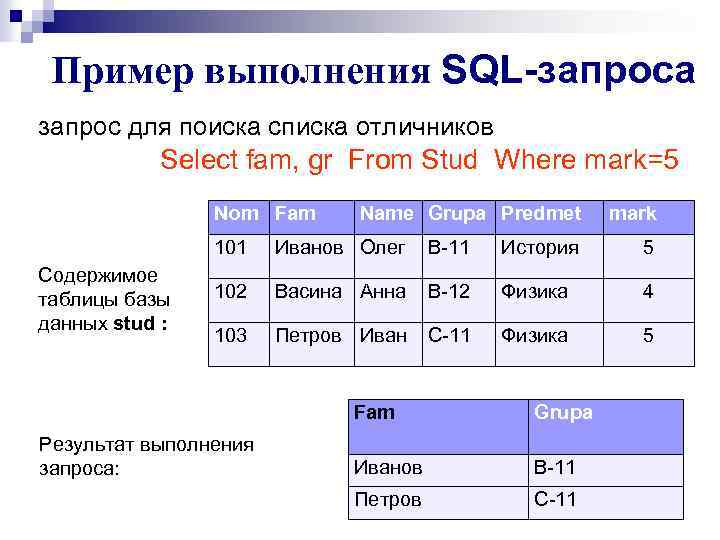 Наличие
Наличие
HAVING Экземпляры.Наличие = No))
Как и положено вложенным запросом первым выполняется самый «глубокий» по уровню вложенности подзапрос, который определяет количество книг на руках у каждого читателя:
SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Экземпляры.Номер_ЧБ, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No
Результат работы этого подзапроса список – количество книг по каждому номеру читательского билета. Особенным является то, что результат этого запроса используется в качестве источника строк для запроса более высокого уровня, который находит максимальное значение в этом списке, соответствующее максимальному количеству книг на руках у одного из читателей:
(SELECT MAX(Количество) FROM (SELECT …))
И, наконец, внешний запрос, выполняется в последнюю очередь, подсчитывает количество книг на руках у конкретного читателя и сравнивает его с максимальным количеством книг, полученным в результате работы вложенного запроса.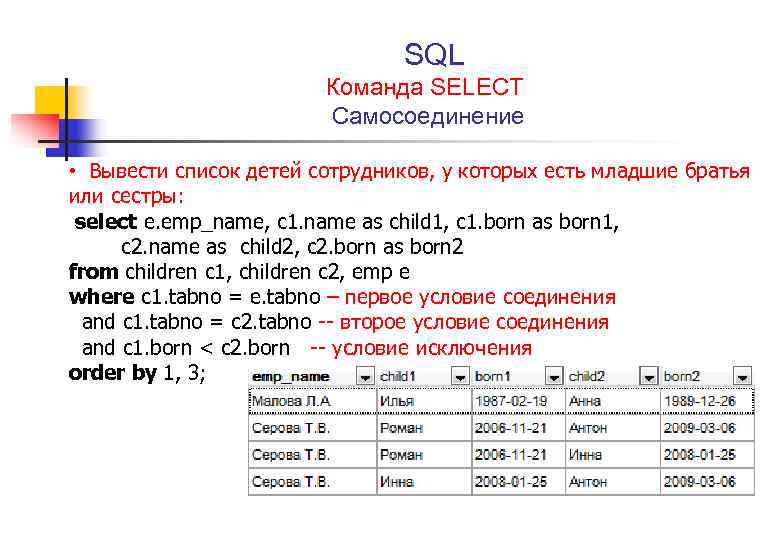 Таким образом, может оказаться несколько читателей имеющих на руках максимальное количество книг.
Таким образом, может оказаться несколько читателей имеющих на руках максимальное количество книг.
В данном примере вложенный запрос возвращает агрегированное значение, полученное в результате итоговой функции MAX, поэтому условное выражение COUNT(*) = (SELECT MAX(Количество)…) имеет смысл. Если вложенный подзапрос может вернуть множество значений, то простое сравнение не подходит, необходимо использование служебных слов ANY или предиката IN, множество значений которого будет формировать вложенный подзапрос. Служебное слово ANY указывает на необходимость использования условного выражения для каждого значения, полученного во вложенном запросе.
Контрольные вопросы
1. Как можно получить декартово произведение двух таблиц?
2. Чем отличается соединение от объединения?
3. Какие виды соединений предусмотрены первым стандартом SQL?
4. Какой синтаксис имеют соединения?
5. Какие виды соединений вы знаете?
6. Для чего необходимы вложенные запросы?
Для чего необходимы вложенные запросы?
7. Какие ограничения налагаются на вложенные запросы?
8. Как можно использовать предикат IN или служебное слово ANY?
Задания для самостоятельной работы
Рекомендуем посмотреть лекцию «3.4. Примеры по прогнозированию инженерной обстановки».
Задание 1. Запишите запрос для определения:
1. к каким предметным областям относится какая-либо книга;
2. какие книги относятся к определенной предметной области.
Задание 2. Дана таблица «Книг_у_читателей», содержащая поля «ФИО_читателя» и «Книг_на_руках». Запишите текст запроса для определения:
1. читателей держащих больше всего книг на руках;
2. читателей держащих меньше всего книг на руках.
соединений и подзапросов в SQL
Оператор SQL Join используется для объединения данных или строк из двух или более таблиц на основе общего поля между ними. Подзапрос — это запрос, вложенный в инструкцию SELECT, INSERT, UPDATE или DELETE или в другой подзапрос.
Узнайте все, что вам нужно знать о соединениях и подзапросах SQL, и многое другое!
Продолжайте читать…
Оператор соединения SQL используется для объединения данных или строк из двух или более таблиц на основе общего поля между ними.
Подзапрос — это запрос, вложенный в инструкцию SELECT , INSERT , UPDATE или DELETE или внутри другого подзапроса.
Соединения и подзапросы используются для объединения данных из разных таблиц в один результат.
Первичный ключ – это столбец в таблице, который используется для уникальной идентификации строки в этой таблице.
А 9Внешний ключ 0036 используется для формирования связи между двумя таблицами. Например, предположим, что у вас есть отношение «один ко многим» между клиентами в таблице CUSTOMER и заказами в таблице ORDER. Чтобы связать две таблицы, вы должны определить столбец ORDER_ID в таблице CUSTOMER, который соответствует столбцу ORDER_ID в таблице ORDER.
Чтобы связать две таблицы, вы должны определить столбец ORDER_ID в таблице CUSTOMER, который соответствует столбцу ORDER_ID в таблице ORDER.
Примечание. Имя столбца внешнего ключа не обязательно должно совпадать с именем столбца первичного ключа.
Значения, определенные в столбце внешнего ключа, ДОЛЖНЫ соответствовать значениям, определенным в столбце первичного ключа. Это называется ссылочной целостностью и обеспечивается реляционной СУБД. Если первичный ключ для таблицы является составным ключом, внешний ключ также должен быть составным ключом.
Загрузить эту статью в формате PDF
1.2
Внутренние Соединения
Внутренние соединения используются для объединения связанной информации из нескольких таблиц. внутреннее соединение извлекает совпадающие строки между двумя таблицами. Совпадения обычно выполняются на основе существующих отношений между первичным и внешним ключами.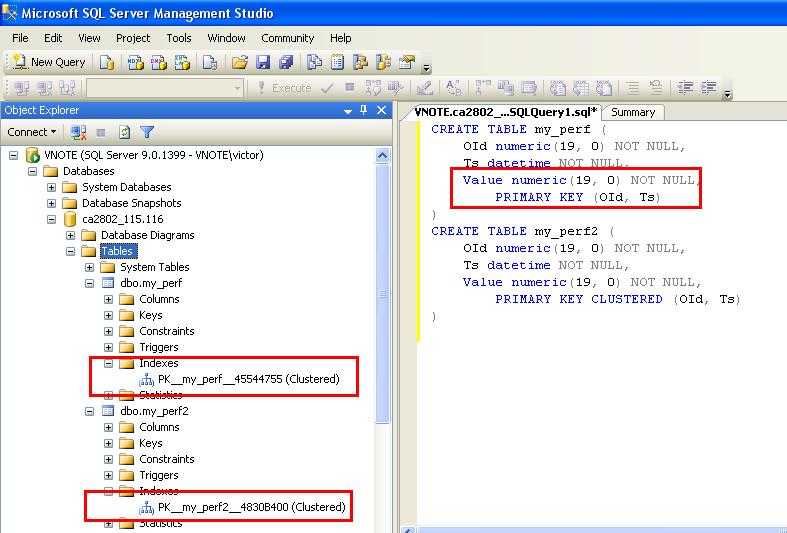 Если есть совпадение, строка включается в результаты. В противном случае это не так.
Если есть совпадение, строка включается в результаты. В противном случае это не так.
Синтаксис:
Выбрать <столбцы>
Из
соединение
на <Таблица1>.
Если первичный ключ и внешний ключ являются составными ключами, то при указании соединения вы должны объединить И вместе с любыми дополнительными столбцами.
Например, если у вас есть составной ключ из двух столбцов, синтаксис будет следующим: = <таблица2>.<столбецB>
И <таблица1>.<столбецC> = <таблица2>.<столбецD>
Схема базы данных представляет организацию и структуру базы данных. Он содержит таблицы и другие объекты базы данных (например, представления, индексы, хранимые процедуры). База данных может иметь более одной схемы, как в данном случае. База данных AdventureWorks на самом деле имеет 6 схем (dbo, HumanResources, Person, Production, Purchases и Sales). В SQL Server dbo является схемой по умолчанию. С другой стороны, Northwind имеет только схему dbo.
База данных может иметь более одной схемы, как в данном случае. База данных AdventureWorks на самом деле имеет 6 схем (dbo, HumanResources, Person, Production, Purchases и Sales). В SQL Server dbo является схемой по умолчанию. С другой стороны, Northwind имеет только схему dbo.
В приведенном выше примере идентификатор HumanResources.Employee означает, что HumanResources — это имя схемы, а Employee — имя таблицы. Персона. Идентификатор человека означает, что Person — это имя схемы, а Person — имя таблицы.
1.3 Внутреннее соединение
Примеры
Объединение 2 таблиц:
SELECT Персона.Имя, Персона.Фамилия, Сотрудник.ДатаРождения, Сотрудник.НаемДата ОТ HumanResources.Employee ПРИСОЕДИНЯЙТЕСЬ к Человеку.Человеку ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
Объединение N таблиц:
SELECT Person.FirstName, Person.LastName, Employee.BirthDate, Employee.HireDate, EmailAddress.EmailAddress ОТ HumanResources.
 Employee
ПРИСОЕДИНЯЙТЕСЬ к Человеку.Человеку
ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
ПРИСОЕДИНЯЙТЕСЬ к Person.EmailAddress
ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
Employee
ПРИСОЕДИНЯЙТЕСЬ к Человеку.Человеку
ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
ПРИСОЕДИНЯЙТЕСЬ к Person.EmailAddress
ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
Эта статья была адаптирована из нашего курса Введение в обучение SQL .
Узнайте все о соединениях и подзапросах в SQL и многое другое!
Свяжитесь с нами для
СКИДКА 50%
код скидки на этот курс.
1.4
Префикс столбцов с именами таблиц
Обычно рекомендуется ставить имена столбцов с именами таблиц, чтобы было ясно, из какой таблицы взяты столбцы. Однако, если нет двусмысленности, т. е. в обеих таблицах нет одних и тех же столбцов, их можно опустить.
Пример:
ВЫБОР Имя Фамилия, Дата Рождения, Дата Найма ОТ HumanResources.Employee ПРИСОЕДИНЯЙСЯ ON Сотрудник.
 BusinessEntityID = Person.BusinessEntityID
BusinessEntityID = Person.BusinessEntityID Запрос транзакционных и аналитических баз данных с использованием SQL , MDX и DAX
Посмотрите наше видео на YouTube прямо сейчас!
Транзакционные базы данных (также известные как OLTP) оптимизированы для большого объема транзакций, таких как вставка, обновление и удаление.
В основном они используются приложениями для ввода данных.
Аналитические базы данных (также известные как OLAP) оптимизированы для больших объемов данных, которые часто запрашиваются для принятия бизнес-решений/отчетности. Вам нужно использовать различные языки запросов для запросов к этим разным типам баз данных.
Присоединяйтесь к нам в этом часовом видеоролике, в котором будут изучены такие языки запросов, как SQL , MDX и DAX .
1.5 Использование псевдонимов таблиц
Чтобы сделать имена столбцов более короткими и более читабельными при объединении двух таблиц, мы можем использовать псевдонимы таблиц. Псевдонимы таблиц аналогичны псевдонимам столбцов. Вместо сокращения имени столбца мы сокращаем имя таблицы. Часто псевдонимы таблиц имеют длину в один или два символа. Псевдонимы таблиц можно использовать, даже если вы не объединяете таблицы.
Синтаксис:
Выбрать <столбцы>
из
<Таблица 2>
JOIN
на 1,1>
. columnA> =
1.6 Использование таблицы
Псевдонимы
Пример:
SELECT р. Имя, стр. Фамилия, е. Дата рождения, e. Дата найма ОТ HumanResources.Employee e СОЕДИНИТЬ Person.
 Person p
ПО эл. BusinessEntityID = р. BusinessEntityID
Person p
ПО эл. BusinessEntityID = р. BusinessEntityID
Загрузить эту статью в формате PDF
1.7 Альтернативный
Внутренний синтаксис соединения
Существует альтернативный синтаксис соединения, в котором используется условие соединения WHERE. Вы можете увидеть, что этот стиль соединения используется в устаревшем коде SQL.
Синтаксис:
ВЫБЕРИТЕ
ИЗ ,
ГДЕ . «=»
Пример:
ВЫБОР Персона.Имя, Персона.Фамилия, Сотрудник.ДатаРождения, Сотрудник.НаемДата ОТ HumanResources.Сотрудник, Человек.Человек WHERE Employee.BusinessEntityID = Person.BusinessEntityID
Чтобы указать внешние соединения, необходимо использовать синтаксис, специфичный для поставщика. Например, в Oracle вам нужно использовать оператор (+), а в SQL Server вам нужно использовать операторы *= и =*.
1.8
Внешнее Соединения
Что произойдет, если вы выполняете внутреннее соединение, а одной из записей в таблице не соответствует запись в другой таблице?
Тогда в результирующем наборе не появится ни одной строки. Однако вы можете по-прежнему захотеть увидеть эту строку в своем отчете.
Однако вы можете по-прежнему захотеть увидеть эту строку в своем отчете.
Например, у вас может быть клиент, но он еще не размещал заказы. Вы все еще хотите перечислить клиента.
Здесь внешний присоединяется к приходит на помощь. Существует несколько типов внешних соединений, которые мы обсудим далее.
Свяжитесь с Web Age Solutions, чтобы получить
СКИДКА 50%
Скидка на курс «Введение в SQL» операции с базами данных —
необходим для всех, кто разрабатывает приложения для баз данных.
Научитесь использовать все возможности языка SQL.
В этом учебном курсе «Введение в SQL» вы узнаете, как оптимизировать доступность и обслуживание данных с помощью языка программирования SQL, а также получите прочную основу для создания баз данных, выполнения запросов и управления ими.
Узнайте, как быстро и эффективно извлекать большие объемы данных.
Начните работу с Web Age Введение в SQL Обучение сегодня!
Посмотреть сведения о курсе
1.9
Левое Внешнее соединение
A левое внешнее соединение возвращает все записи из таблицы слева и соответствующие записи из таблицы справа.
Если соответствующей записи нет, то для любых столбцов, выбранных из таблицы справа, возвращается NULL.
Это эквивалент внутреннего соединения плюс несопоставленные строки из таблицы слева.
Синтаксис:
SELECT
FROM
LEFT JOIN
ON
1.10 Левое внешнее соединение идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов) и любые соответствующие идентификаторы заказов на покупку.
ВЫБОР e.
 BusinessEntityID,
p.PurchaseOrderID
ОТ HumanResources.Employee e
LEFT JOIN Purchasing.PurchaseOrderHeader p
ON e.BusinessEntityID = p.EmployeeID
BusinessEntityID,
p.PurchaseOrderID
ОТ HumanResources.Employee e
LEFT JOIN Purchasing.PurchaseOrderHeader p
ON e.BusinessEntityID = p.EmployeeID Получить обратно все идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов) и любые соответствующие идентификаторы кандидатов на работу и резюме
SELECT e.BusinessEntityID, j.JobCandidateID, j.Resume ОТ HumanResources.Employee e LEFT JOIN HumanResources.JobCandidate j ON e.BusinessEntityID = j.BusinessEntityID ЗАКАЗАТЬ ПО j.JobCandidateID DESC
1.11
Правый Внешние соединения
A правое внешнее соединение является противоположностью левому внешнему соединению.
Правое внешнее соединение возвращает все записи из таблицы справа и соответствующие записи из таблицы слева. Если соответствующей записи нет, то для любых столбцов, выбранных из таблицы слева, возвращается NULL.
Эквивалент внутреннего соединения плюс несовпадающие строки из таблицы справа .
Синтаксис:
Выберите <столбцы>
из
Правое соединение
на <Таблица1>.
SELECT e.BusinessEntityID, j.JobCandidateID, j.Resume ОТ HumanResources.Employee e ПРАВОЕ ПРИСОЕДИНЕНИЕ HumanResources.JobCandidate j ON e.BusinessEntityID = j.BusinessEntityID ЗАКАЗ ПО e.BusinessEntityID DESC
Хотите попрактиковаться в работе с соединениями и подзапросами SQL
?
Загрузите нашу БЕСПЛАТНУЮ практическую лабораторию
Соединения SQL — внутренние и внешние соединения
Бесплатно для вас!
1.
 12 Полное Внешние соединения
12 Полное Внешние соединения
Полное внешнее соединение возвращает все совпадающие записи между таблицами слева и справа, а также все несовпадающие записи с обеих сторон. Это эквивалент внутреннего соединения плюс несовпадающие строки из таблицы слева и несовпадающие строки из таблицы справа.
Синтаксис:
Выбрать <столбцы>
из
Полное соединение <Таблица2>
на <Таблица1>.
Пример:
Получить все идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов), а также идентификаторы и резюме всех кандидатов на работу. Сопоставьте вместе любые записи.
ВЫБЕРИТЕ e.BusinessEntityID, j.JobCandidateID, j.Resume ОТ HumanResources.Employee e ПОЛНОЕ СОЕДИНЕНИЕ HumanResources.JobCandidate j ON e.BusinessEntityID = j.BusinessEntityID ORDER BY e.BusinessEntityID DESC
1.
 13 Strong Соединения
13 Strong Соединения
A самосоединение – это объединение, при котором таблица объединяется сама с собой. Обычно он используется, когда существует иерархическая связь между сущностями (например, сотрудник-менеджер) или вы хотите сравнить строки в одной таблице. Он использует синтаксис либо внутреннего соединения, либо левого внешнего соединения. Псевдонимы таблиц используются для присвоения разных имен одной и той же таблице в запросе.
Синтаксис:
SELECT
FROM
 City = a2.City
City = a2.City  Продукт
ГДЕ ProductID В
(ВЫБЕРИТЕ ProductID
ОТ Purchasing.PurchaseOrderDetail
ГДЕ OrderQty > 5)
Продукт
ГДЕ ProductID В
(ВЫБЕРИТЕ ProductID
ОТ Purchasing.PurchaseOrderDetail
ГДЕ OrderQty > 5) 
 Внутренний запрос оценивает каждую строку, чтобы увидеть, составляет ли их процент комиссии 1%.
Внутренний запрос оценивает каждую строку, чтобы увидеть, составляет ли их процент комиссии 1%.


| Subquery elements | Example |
|---|---|
| Enclosing parentheses | ✅ |
| Subquery name | all_orders |
SELECT statement | Select * From {{ref ('orders')}} |
Основной запрос. Когда этот запрос действительно выполняется, он сначала запустит самый внутренний запрос. В этом случае он сначала запустит select * from {{ ref('orders') }} . Затем он передаст эти результаты внешнему запросу, где вы получите количество заказов на 9.0017 идентификатор_клиента . Это относительно простой пример, но, надеюсь, он покажет вам, что подзапросы начинаются так же, как и большинство других запросов. По мере того, как вы вкладываете больше подзапросов вместе, вы раскрываете силу подзапросов, но также начинаете замечать некоторые компромиссы в отношении читабельности. В повседневной жизни вы обычно не формализуете имена различных типов подзапросов, которые вы можете написать, но когда кто-то использует термин «коррелированный подзапрос» на конференции по данным, вам нужно знать, что это значит! Вложенные подзапросыВложенные подзапросы — это подзапросы, подобные тому, который вы видели в первом примере: подзапрос, в котором внутренний запрос выполняется первым (и один раз) и передает свой результат основному запросу. Большинство подзапросов, которые вы увидите в реальном мире, скорее всего, будут вложенными подзапросами. Они наиболее полезны, когда вам нужно обрабатывать данные в несколько этапов. Совет по отладке подзапросов Важно отметить, что, поскольку внутренний запрос выполняется первым во вложенном подзапросе, внутренний запрос должен выполняться сам по себе. Связанный подзапрос является аналогом вложенного подзапроса. Если вложенные подзапросы сначала выполняют внутренний запрос и передают свой результат внешнему запросу, коррелированные подзапросы сначала выполняют внешний запрос и передают свой результат своему внутреннему запросу. Для коррелированных подзапросов полезно подумать о том, как на самом деле выполняется код. В коррелированном подзапросе внешний запрос будет выполняться построчно. Для каждой строки результат внешнего запроса будет передан внутреннему запросу. Сравните это с вложенными запросами: во вложенном запросе внутренний запрос выполняется первым и только один раз перед передачей во внешний запрос. Эти типы подзапросов наиболее полезны, когда вам нужно провести анализ на уровне строк. Скалярные и нескалярные подзапросы Скалярные подзапросы — это запросы, которые возвращают только одно значение. Вы можете использовать скалярный подзапрос, если хотите передать во внешний запрос только однострочное значение. Этот тип подзапроса может быть полезен, когда вы пытаетесь удалить или обновить значение определенной строки с помощью оператора языка манипулирования данными (DML). Вы можете часто видеть подзапросы в соединениях и операторах DML. Следующие разделы содержат примеры для каждого сценария. Подзапрос в соединении В этом примере вы хотите получить пожизненную ценность для каждого клиента, используя таблицу выберите | |
SELECT statement | select order_id, amount from {{ ref('raw_payments') }} |
| Main query it is nested in | select orders.user_id, sum(payments.amount) как life_value from {{ ref('raw_orders') }} как заказы... |
 Если вы регулярно используете подзапросы, вам нужно использовать отступы и строгие соглашения об именах для ваших подзапросов, чтобы четко различать функциональные возможности кода.
Если вы регулярно используете подзапросы, вам нужно использовать отступы и строгие соглашения об именах для ваших подзапросов, чтобы четко различать функциональные возможности кода. Если он не может успешно работать независимо, он не может передать результаты внешнему запросу.
Если он не может успешно работать независимо, он не может передать результаты внешнему запросу. В частности, это означает, что если вы выполните скалярный подзапрос, он вернет одно значение столбца одной конкретной строки. Однако нескалярные подзапросы могут возвращать одну или несколько строк и могут содержать несколько столбцов.
В частности, это означает, что если вы выполните скалярный подзапрос, он вернет одно значение столбца одной конкретной строки. Однако нескалярные подзапросы могут возвращать одну или несколько строк и могут содержать несколько столбцов.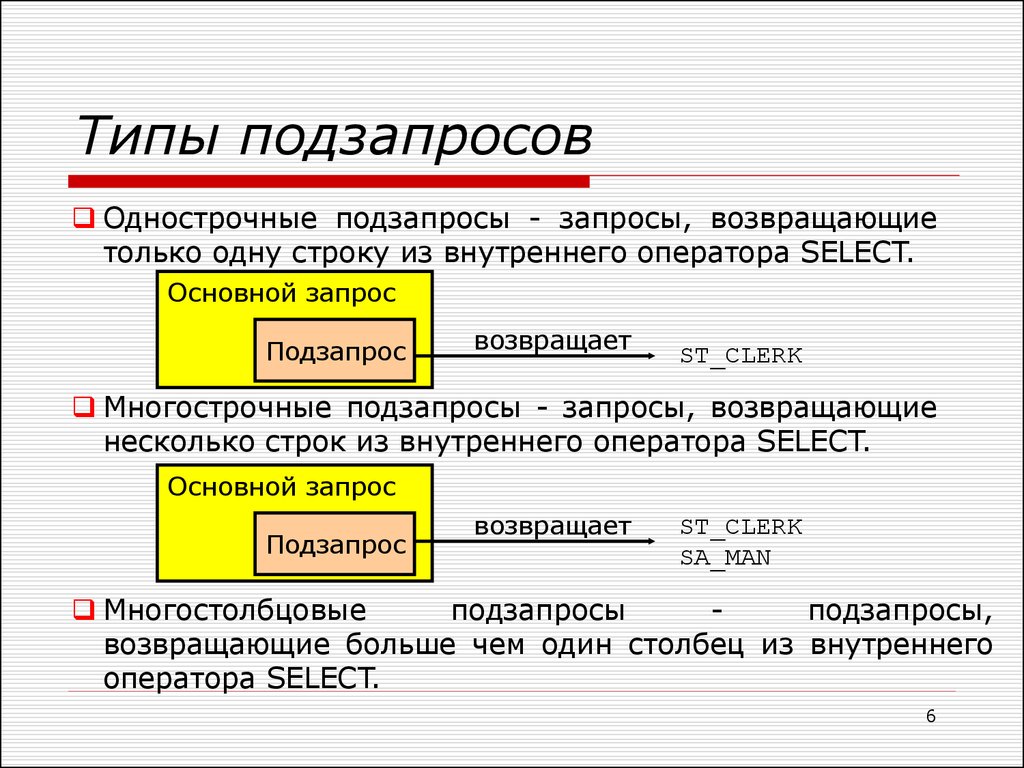 id = Payments.order_id
id = Payments.order_id В этом примере подзапрос all_payments будет выполняться первым. вы используете данные из этого запроса, чтобы присоединиться к raw_orders Таблица для расчета общей стоимости для каждого пользователя. В отличие от первого примера, подзапрос выполняется в операторе соединения. Подзапросы могут выполняться в предложениях JOIN , FROM и WHERE .
Подзапрос в команде DML
Вы также можете увидеть подзапросы, используемые в командах DML. В качестве бегунка команды DML представляют собой серию операторов SQL, которые вы можете написать для доступа и управления данными на уровне строк в объектах базы данных. Часто вам нужно использовать результат запроса с оценкой 9.0017 WHERE только для удаления, обновления или управления определенными строками данных.
В качестве бегунка команды DML представляют собой серию операторов SQL, которые вы можете написать для доступа и управления данными на уровне строк в объектах базы данных. Часто вам нужно использовать результат запроса с оценкой 9.0017 WHERE только для удаления, обновления или управления определенными строками данных.
В следующем примере вы попытаетесь обновить статус определенных заказов на основе метода оплаты, используемого в таблице raw_payments .
UPDATE raw_orders
set status = 'returned'
где order_id in (
выберите order_id
из raw_payments
где payment_method = 'bank_transfer')
Подзапрос — это вложенный запрос, который часто можно использовать вместо CTE. Подзапросы имеют другой синтаксис, чем CTE, но часто имеют схожие варианты использования. Контент не будет слишком углубляться в CTE здесь, но он выделит некоторые из основных различий между CTE и подзапросами ниже.
| CTE | SUBQUERY | |
|---|---|---|
| Обычно более читаемое, так как CTE можно использовать для того, чтобы дать ваш Query | . query query | Должен объявлять подзапрос каждый раз, когда он используется в запросе |
| Допускает рекурсивность | Не допускает рекурсивность | |
| CTE должны иметь уникальные CTE_EXPRESSION_NAMES при использовании в запросе | Подзапросы не всегда должны иметь явное имя | |
CTE нельзя использовать в предложении WHERE |
Пример подзапроса и CTE
В следующем примере показаны сходства и различия между подзапросами и CTE. Используя первый пример подзапроса, вы можете сравнить, как бы вы выполнили этот запрос, используя подзапрос или CTE:
- Subquery example
- CTE example
select customer_id, count(order_id) as cnt_orders
from (select * from {{ ref('orders') }}
) all_orders
group by 1
Хотя код для запроса, включающего CTE, может быть длиннее, он также позволяет нам явно определять функциональные возможности кода, используя имя CTE. В отличие от примера с подзапросом, в котором сначала выполняется внутренний запрос, а затем внешний запрос, запрос с использованием CTE выполняется с перемещением вниз по коду.
В отличие от примера с подзапросом, в котором сначала выполняется внутренний запрос, а затем внешний запрос, запрос с использованием CTE выполняется с перемещением вниз по коду.
Опять же, выбор использования CTE вместо подзапросов является личным выбором. Может помочь написать ту же функциональность кода в подзапросе и с CTE и посмотреть, что вам более понятно.
Подзапросы, скорее всего, будут поддерживаться в большинстве, если не во всех, современных хранилищах данных. Пожалуйста, используйте эту таблицу, чтобы увидеть больше информации об использовании подзапросов в вашем конкретном хранилище данных.
| Хранилище данных | Поддерживает подзапросы? |
|---|---|
| Snowflake | ✅ |
| Amazon Redshift | ✅ |
| Google BigQuery | ✅ |
| Databricks | ✅ |
| Postgres | ✅ |
I'm честно говоря, я не решался начать писать страницу глоссария для подзапросов SQL.