Sql запросы join: SQL: оператор JOIN. Основные типы объединения
Содержание
mysql — SQL join исключить результаты
Вопрос задан
Изменён
1 год 8 месяцев назад
Просмотрен
279 раз
Есть 2 таблицы: applications (id, name), responses (id, master_id, application_id)
Мне нужно сделать выборку applications, исключив все записи c master_id = 2, и при этом нужно, чтобы выборка состояла еще и из тех записей, которых нет в таблице 2.
Я достигаю этого результата двумя запросами:
select DISTINCT app.*, res.master_id
from applications app, responses res
where res.application_id = app.id
and app.id not in
(select responses.application_id from responses where responses.master_id = 2)
select app.*, res.master_id
from applications app
LEFT join responses res
on res. application_id = app.id
where res.id is null
application_id = app.id
where res.id is null
 application_id = app.id
where res.id is null
application_id = app.id
where res.id is null
Вопрос заключается в том чтобы сделать эту выборку одним запросом?
Пробовал такой запрос, но выборка неверная:
select DISTINCT app.*, res.master_id
from applications app
LEFT join responses res
on res.application_id = app.id
and app.id <>
(select responses.application_id from responses where responses.master_id = 2)
- mysql
- sql
- postgresql
- join
Мне нужно сделать выборку applications, исключив все записи c master_id = 2, и при этом нужно, чтобы выборка состояла еще и из тех записей, которых нет в таблице 2.
SELECT a.* FROM applications a LEFT JOIN responses r ON a.id = r.application_id AND r.master_id = 2 WHERE r.application_id IS NULL
1
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
JOIN – соединение таблиц.
 Курс «Введение в реляционные базы данных»
Курс «Введение в реляционные базы данных»
При выборке данных из таблицы pages мы можем увидеть номер темы, к которой относится та или иная страницы, но не название темы. Чтобы увидеть названия тем, надо вывести вторую таблицу.
Как получить сводную таблицу, в которой для каждой страницы будет указано название ее темы? Фактически нам надо вывести два столбца. Столбец title из таблицы pages и столбец name из таблицы sections.
При этом должно быть выполнено сопоставление по номеру темы, который в одной таблице является внешним ключом, а в другой – первичным. Так, если в записи таблицы pages в поле theme указан внешний ключ 1, то из таблицы sections должна выбираться запись, чье значение поля первичного ключа _id равно 1. Далее из этой записи берется значение поля name.
В SQL для соединения данных из разных таблиц используется оператор JOIN. В случае с нашим примером запрос будет выглядеть так:
sqlite> SELECT pages.title, ...> sections.
 name AS theme
...> FROM pages JOIN sections
...> ON pages.theme == sections._id;
name AS theme
...> FROM pages JOIN sections
...> ON pages.theme == sections._id;Подвыражение AS theme можно опустить. Тогда в качестве заголовка столбца будет указано его оригинальное имя – name.
После SELECT указываются столбцы, которые необходимо вывести. Перед именем столбца пишется имя таблицы. Указывать таблицу не обязательно, если имя столбца уникальное:
sqlite> SELECT title, name ...> FROM pages JOIN sections ...> ON theme = sections._id;
Здесь имя таблицы используется только с _id, так как столбец с таким именем есть в обоих таблицах.
Если после SELECT будет стоять звездочка, будут выведены все столбцы из обоих таблиц.
После FROM указываются обе сводимые таблицы через JOIN. В данном случае неважно, какую указывать до JOIN, какую после.
После ключевого слова ON записывается условие сведения. Условие сообщает, как соединять строки разных таблиц. В данном случае каждая запись из таблицы pages дополняется полями той записи из таблицы sections, чье поле _id содержит такое же значение, какое содержит поле theme таблицы pages.
Если записать команду без части ON, то каждая строка первой таблицы будет соединена по очереди со всеми строками второй. В сводной таблице каждое соединение будет отдельной записью.
Однако если часть ON заменить на WHERE с тем же условием, то соединение таблиц вернет нужный нам результат.
sqlite> SELECT pages.title, sections.name ...> FROM sections JOIN pages ...> WHERE pages.theme == sections._id; title name ------------------- ----------- What is Information Information Amount of Informati Information Binary System Digital Sys Boolean Lows Boolean Alg
На самом деле здесь выполняется фильтрация результата предыдущего примера.
JOIN писать не обязательно. После FROM таблицы можно перечислить через запятую (это верно как при использовании WHERE, так и ON):
sqlite> SELECT pages.title, sections.name ...> FROM pages, sections ...> WHERE pages.theme == sections._id;
Можно комбинировать WHERE и JOIN ON. Например, мы хотим вывести страницы только второй и третьей тем:
Например, мы хотим вывести страницы только второй и третьей тем:
sqlite> SELECT pages.title, sections.name ...> FROM pages JOIN sections ...> ON pages.theme == sections._id ...> WHERE pages.theme == 2 ...> OR pages.theme == 3; title name ------------- --------------- Binary System Digital Systems Boolean Lows Boolean Algebra
Соединение можно использовать совместно с группировкой. Узнаем, сколько в каждой теме статей:
sqlite> SELECT sections.name AS theme, ...> count() AS qty_articles ...> FROM pages JOIN sections ...> ON pages.theme == sections._id ...> GROUP BY sections.name ...> ORDER BY sections._id; theme qty_articles ----------- ------------ Information 2 Digital Sys 1 Boolean Alg 1
В этом запросе сначала была получена сводная таблица, в которой была выполнена группировка по столбцу name и с помощью функции count() посчитано количество записей в каждой группе.
Допустим, мы хотим получить данные только по первой теме:
sqlite> SELECT sections.name AS theme, ...> count() AS qty_articles ...> FROM pages JOIN sections ...> ON pages.theme == sections._id ...> GROUP BY sections.name ...> WHERE sections._id == 1; Error: near "WHERE": syntax error
С условием WHERE запрос возвращает ошибку, потому что WHERE выполняется до агрегации и группировки.
В этих случаях вместо WHERE используется условие HAVING:
sqlite> SELECT sections.name AS theme, ...> count() AS qty_articles ...> FROM pages JOIN sections ...> ON pages.theme == sections._id ...> GROUP BY sections.name ...> HAVING sections._id == 2 ...> OR sections._id == 3; theme qty_articles --------------- ------------ Boolean Algebra 1 Digital Systems 1
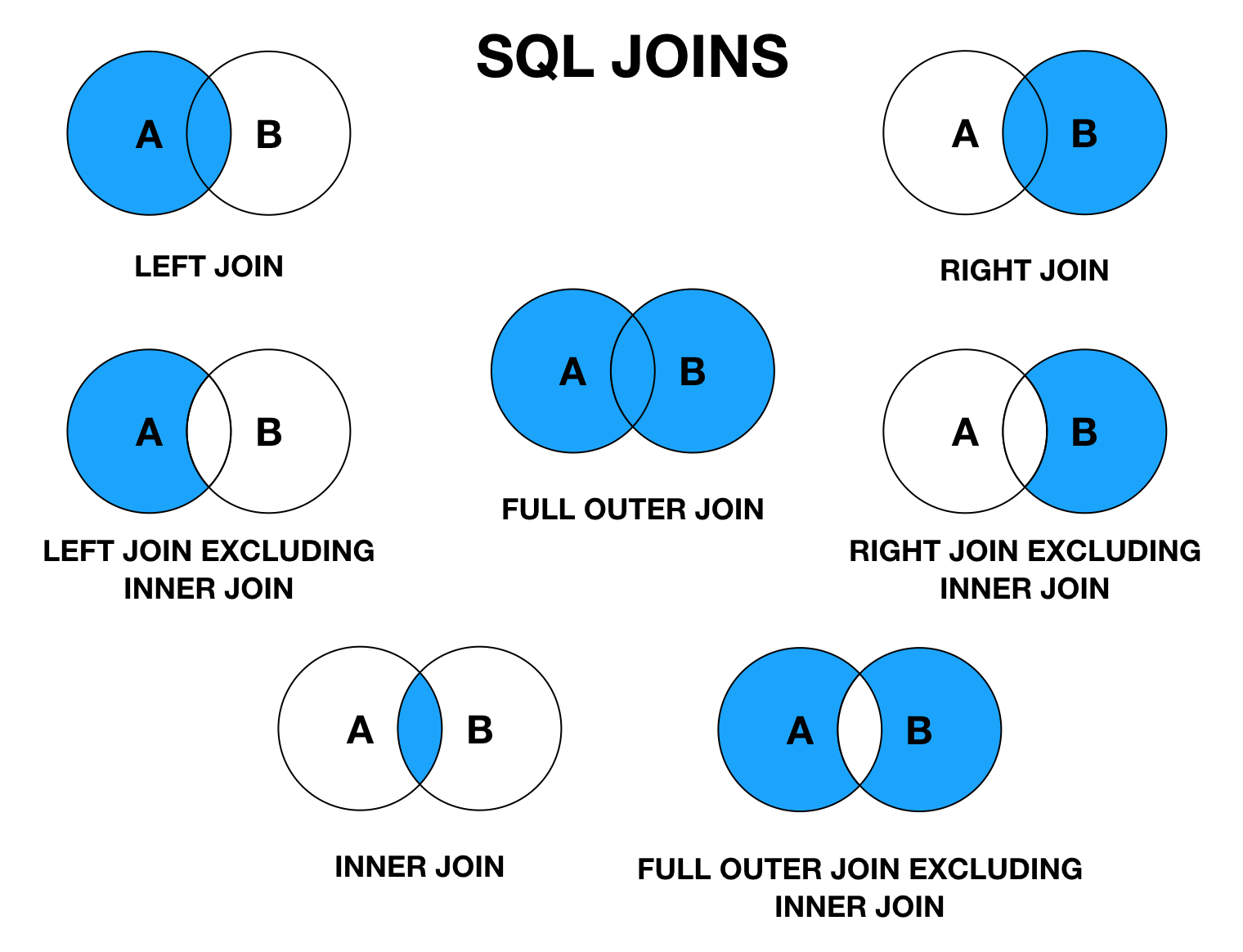
Существует несколько разновидностей оператора JOIN. Для простого JOIN (на самом деле это сокращение от INNER JOIN) условие (pages.) работало так, что в результате запроса было только то, что однозначно соответствует условию. Однако JOIN может быть внешним левосторонним или внешним правосторонним. theme = sections._id
theme = sections._id
В таблице sections есть четвертая тема, но страниц на эту тему в таблице pages нет. Когда мы соединяли таблицы и считали количество статей, четвертая тема просто отбрасывалась, потому что ее запись ни разу не удовлетворяла условию pages.theme = sections._id.
Как быть если надо увидеть, что в базе данных есть темы, в некоторых нет статей? В таком случае мы должны одну из таблиц сделать как бы основной, более главной. Сводная таблица будет содержать все записи, удовлетворяющие условию, плюс записи «главной» таблицы, для которой не нашлось соответствий во второй. То есть в результирующей таблице будут представлены все строки одной из таблиц.
Поскольку SQLite не поддерживает RIGHT JOIN, то «главную» таблицу следует указывать до LEFT JOIN. Так как нам важны все темы из таблицы sections, именно она будет первой.
sqlite> SELECT sections.name, ...> count(pages.title) ...> FROM sections LEFT JOIN pages ...> ON pages.theme == sections._id ...> GROUP BY sections.name; name count(pages.title) ---------- ------------------ Algorithm 0 Boolean Al 1 Digital Sy 1 Informatio 2
Обратите внимание, что также в функцию count() мы передаем имя столбца. В этом случае будут считаться количество его не NULL значений в каждой группе. Если аргумент не передать, то напротив Algorithm будет стоять число 1, потому что без группировки сводная таблица содержит одну запись, где тема – Algorithm.
Функция count() без аргумента просто посчитает количество строк в каждой группе. Передавая ей имя столбца, мы заставляем ее считать не NULL значения в этом столбце в каждой группе.
Кроме оператора JOIN в SQL есть оператор UNION. Если JOIN выполняет соединение по горизонтали, то есть добавляет столбцы одной таблице к столбцам другой, то UNION – это объединение таблиц по вертикали, когда строки одной таблицы добавляются к строкам другой. Так объединяют похожие таблицы, имеющие одинаковые или почти одинаковые схемы.
Так объединяют похожие таблицы, имеющие одинаковые или почти одинаковые схемы.
SQL JOIN (с примерами)
В этом руководстве вы узнаете об операторе SQL JOIN с помощью примеров.
SQL JOIN объединяет две таблицы на основе общего столбца и выбирает записи, имеющие совпадающие значения в этих столбцах.
Пример
-- объединение таблиц "Клиенты" и "Заказы" -- на основе общих значений их столбцов customer_id ВЫБЕРИТЕ Customers.customer_id, Customers.first_name, Orders.item ОТ клиентов ПРИСОЕДИНЯЙТЕСЬ к заказам ON Customers.customer_id = Orders.customer_id;
Здесь команда SQL объединяет таблицы Customers и Orders на основе общих значений в столбцах customer_id обеих таблиц.
Набор результатов будет состоять из
-
столбцов customer_idиfirst_nameиз таблицыCustomers -
позициястолбец из таблицыOrders
Синтаксис SQL JOIN
Синтаксис SQL Оператор JOIN :
SELECT columns_from_both_tables ИЗ таблицы1 ПРИСОЕДИНЯЙТЕСЬ к таблице2 ON table1.
 column1 = table2.column2
column1 = table2.column2 Здесь
- table1 и table2 — две таблицы, которые должны быть объединены
- столбец 1 — это столбец в table1 , связанный с column2 в table2
Примечание: В SQL существует 4 типа JOIN. Но ВНУТРЕННЕЕ СОЕДИНЕНИЕ и JOIN относятся к одному и тому же.
Пример 1: SQL JOIN
-- объединение таблиц Customers и Orders на основе -- customer_id столбца "Клиенты" и столбца "Заказы" ВЫБЕРИТЕ Customers.customer_id, Customers.first_name, Orders.amount ОТ клиентов ПРИСОЕДИНЯЙТЕСЬ к заказам ON Customers.customer_id = Orders.customer;
Вот как работает этот код:
Пример: SQL JOIN
Здесь команда SQL выбирает customer_id и first_name столбцы (из таблицы Клиенты ) и столбец сумма (из таблицы Заказы ).
Набор результатов будет содержать те строки, в которых есть совпадение между customer_id (из таблицы Customers ) и customer (из таблицы Orders ).
Типы SQL JOIN
Как мы упоминали, команда JOIN , которую мы выполнили в этой статье, называется INNER JOIN 9.0006 .
В SQL у нас есть четыре основных типа соединений:
- INNER JOIN
- ЛЕВОЕ СОЕДИНЕНИЕ
- ПРАВОЕ СОЕДИНЕНИЕ
- ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
SQL JOIN и псевдонимы
Мы можем использовать псевдонимы AS с именами таблиц, чтобы сделать наш запрос коротким и понятным. Например,
-- используйте псевдоним C для таблицы "Клиенты". -- использовать псевдоним O для таблицы Orders ВЫБЕРИТЕ C.customer_id, C.first_name, O.amount ОТ клиентов AS C ПРИСОЕДИНЯЙТЕСЬ к заказам КАК O ON C.customer_id = O.customer;
Здесь команда SQL объединяет таблицы Customers и Orders , присваивая им псевдонимы C и O соответственно.
Кроме того, мы можем временно изменить имена столбцов, используя псевдонимы AS . Например,
-- используйте псевдоним C для таблицы "Клиенты". -- использовать псевдоним O для таблицы Orders ВЫБЕРИТЕ C.customer_id AS cid, C.first_name AS имя, O.amount ОТ клиентов AS C ПРИСОЕДИНЯЙТЕСЬ к заказам КАК O ON C.customer_id = O.customer;
Помимо предоставления псевдонимов таблицам, приведенная выше команда SQL также назначает псевдонимы столбцам таблицы Customers :
-
столбец customer_idимеет псевдонимcid -
first_nameстолбец имеет псевдонимимя
Содержание
PostgreSQL: Документация: 15: 2.6. Соединения между таблицами
До сих пор наши запросы обращались только к одной таблице за раз. Запросы могут обращаться к нескольким таблицам одновременно или обращаться к одной и той же таблице таким образом, что несколько строк таблицы обрабатываются одновременно. Запросы, которые обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы) одновременно, называются присоединиться к запросам. Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить столбец
Запросы, которые обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы) одновременно, называются присоединиться к запросам. Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить столбец city каждой строки таблицы Weather со столбцом name всех строк в городах. и выберите пары строк, в которых эти значения совпадают. [4] Это можно сделать с помощью следующего запроса:
ВЫБЕРИТЕ * ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ON city = name;
город | temp_lo | temp_hi | пркп | дата | имя | расположение
---------------+---------+----------+------+------- -----+---------------+-----------
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(2 ряда)
Обратите внимание на две особенности результирующего набора:
Нет строки результатов для города Хейворд.
Это связано с тем, что в таблице городовдля Хейворда нет соответствующей записи, поэтому объединение игнорирует несопоставленные строки в таблицеWeather. Вскоре мы увидим, как это можно исправить.Есть две колонки, содержащие название города. Это правильно, потому что списки столбцов из таблиц
Weatherиcityобъединены. На практике это нежелательно, поэтому вы, вероятно, захотите указать выходные столбцы явно, а не использовать*:ВЫБЕРИТЕ город, temp_lo, temp_hi, prcp, дату, местоположение ОТ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО city = name;
 Это связано с тем, что в таблице
Это связано с тем, что в таблице Поскольку все столбцы имели разные имена, синтаксический анализатор автоматически нашел, к какой таблице они принадлежат. Если бы в двух таблицах были повторяющиеся имена столбцов, вам нужно было бы квалифицировать имена столбцов, чтобы показать, какой из них вы имели в виду, например:
ВЫБЕРИТЕ погода.
 город, погода.temp_lo, погода.temp_hi,
погода.prcp, погода.дата, города.местоположение
ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО Weather.city = city.name;
город, погода.temp_lo, погода.temp_hi,
погода.prcp, погода.дата, города.местоположение
ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО Weather.city = city.name;
Считается хорошим стилем уточнять все имена столбцов в запросе на соединение, чтобы запрос не завершился ошибкой, если позже в одну из таблиц будет добавлено повторяющееся имя столбца.
Запросы на соединение того вида, который мы видели до сих пор, также можно записать в такой форме:
ВЫБИРАТЬ *
ОТ погоды, города
ГДЕ город = имя;
Этот синтаксис предшествует синтаксису JOIN / ON , который был введен в SQL-92. Таблицы просто перечислены в ОТ , а выражение сравнения добавляется к предложению WHERE . Результаты этого старого неявного синтаксиса и более нового явного синтаксиса JOIN / ON идентичны. Но для читателя запроса явный синтаксис облегчает понимание его смысла: условие соединения вводится собственным ключевым словом, тогда как ранее условие было смешано с предложением WHERE вместе с другими условиями.
Теперь мы выясним, как вернуть записи Хейворда. Мы хотим, чтобы запрос сканировал таблица погоды и для каждой строки найти соответствие городов строк. Если подходящая строка не найдена, мы хотим, чтобы некоторые «пустые значения» были заменены на столбцы таблицы городов . Такой запрос называется внешним соединением . (Соединения, которые мы видели до сих пор, — это внутренних соединения .) Команда выглядит так:
ВЫБИРАТЬ *
ОТ погоды ЛЕВЫЙ ВНЕШНИЙ СОЕДИНЯЙТЕ города НА Weather.city = city.name;
город | temp_lo | temp_hi | пркп | дата | имя | расположение
---------------+---------+----------+------+------- -----+---------------+-----------
Хейворд | 37 | 54 | | 1994-11-29 | |
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(3 ряда)
Этот запрос называется левым внешним соединением , потому что таблица, указанная слева от оператора соединения, будет иметь каждую из своих строк в выходных данных по крайней мере один раз, тогда как таблица справа будет иметь только те строки, которые соответствуют некоторую строку левой таблицы. При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
Упражнение: Существуют также правые внешние соединения и полные внешние соединения. Попробуйте узнать, что они делают.
Мы также можем объединить таблицу против себя. Это называется самосоединением . В качестве примера предположим, что мы хотим найти все записи о погоде, которые находятся в температурном диапазоне других записей о погоде. Поэтому нам нужно сравнить столбцы temp_lo и temp_hi каждой строки Weather с temp_lo и temp_hi 9.0006 столбцов всех остальных погодных строк. Мы можем сделать это с помощью следующего запроса:
ВЫБЕРИТЕ w1.city, w1.temp_lo как низкий, w1.temp_hi как высокий,
w2.city, w2.temp_lo низкий уровень AS, w2.temp_hi высокий уровень AS
ОТ погоды w1 ПРИСОЕДИНЯЙТЕСЬ к погоде w2
ON w1.
