Таблица хэшей PowerShell или массив для сравнения строк. Сравнение строк powershell
Оптимизация работы со строками в Powershell / Хабрахабр
Вызов конструктора System.Text.StringBuilder:
$SomeString = New-Object System.Text.StringBuilder Обратное преобразование в String:$Result = $Str.ToString() Во время написании скрипта, обрабатывающего много текстовых файлов, была обнаружена особенность работы со строками в powershell, а именно — значительно снижается скорость парсинга, если пытаться обработать строки при помощи стандартного объекта string.Исходные данные — файл забитый строками по типу:
key;888;0xA9498353,888_FilialName
В сырой версии скрипта для контроля обработки применялись промежуточные текстовые файлы, потери времени на обработку файла в 1000 строк — 24 секунды, при увеличении размера файла задержка быстро растет. Пример:
99 строк — 1,8 секунды 1000 строк — 24,4 секунды 2000 строк — 66,17 секунды
Оптимизация №1
Ясно, что это никуда не годится. Заменяем выгрузку в файл операциями в памяти:function test { $Path = 'C:\Powershell\test\test.txt' $PSGF = Get-Content $Path $Result = '' # foreach ($Key in $PSGF) { $Val = $Key.ToString().Split(';') $test = $val[2] $Val = $test.ToString().Split(',') $test = $Val[0] $Result = $Result + "$test`r`n" } return $Result } Measure-Command { test } Результат прогона:Вроде бы все хорошо, ускорение получено, но давайте посмотрим что происходит если строк в объекте больше:
10000 строк — 1,92 секунды 20000 строк — 8,07 секунды 40000 строк — 26,01 секунд
Такой метод обработки подходит для списков не более чем 5-8 тысяч строк, после начинаются потери на конструкторе объекта, менеджер памяти постоянно выделяет новую память при добавлении строки и копирует объект.
Оптимизация №2
Попробуем сделать лучше, используем «программистский» подход:function test { $Path = 'C:\Powershell\test\test.txt' $PSGF = Get-Content $Path # берем объект из дотнета $Str = New-Object System.Text.StringBuilder foreach ($Key in $PSGF) { $Val = $Key.ToString().Split(';') $temp = $val[2].ToString().Split(',') $Val = $temp $temp = $Str.Append( "$Val`r`n" ) } $Result = $Str.ToString() } Measure-Command { test } Результат прогона: 40000 строк — 1,8 секунды.Дальнейшие улучшения типа замены foreach на for, выбрасывание внутренней переменной $test не дали значимого прироста скорости.
Кратко:
Для эффективной работы с большим количеством строк используйте объект System.Text.StringBuilder. Вызов конструктора:
$SomeString = New-Object System.Text.StringBuilder Преобразование в строку:$Result = $Str.ToString() Объяснение работы StringBuilder (весь секрет в более эффективной работе менеджера памяти).habr.com
powershell - Используя Powershell для сравнения двух файлов, а затем выводятся только разные имена строк
Поэтому я полный новичок в Powershell, но мне нужно написать сценарий, который возьмет файл, сравнит его с другим файлом и скажет мне, какие строки отличаются в первом по сравнению со вторым. Я пошел на это, но я борюсь с выходами, так как мой скрипт в настоящее время только скажет мне, по какой строке все по-другому, но также, кажется, также подсчитывает и пустые строки.
Чтобы дать некоторый контекст для того, чего я пытаюсь достичь, я хотел бы иметь статический файл известных хороших процессов Windows ($ Authorized), и я хочу, чтобы мой скрипт вытащил список текущих запущенных процессов, отфильтруйте столбец с именем процесса, чтобы просто вытащить строки имени процесса, затем сопоставить что-либо более одного символа, отсортировать файл по уникальным значениям и затем сравнить его с $ Authorized, плюс, наконец, либо вывести различные строки процесса, найденные в $ Processes (в ISE Output Pane), либо просто для вывода различных имен процессов в файл.
Сегодня я провел в PowerShell ISE, а также Googling, чтобы попытаться найти решения. Я слышал, что "fc" - лучший выбор вместо Compare-Object, но я не мог заставить это работать. Мне до сих пор удалось заставить его работать, но в финальной части, где он сравнивает два файла, которые, по-видимому, сравниваются по строкам, для которых всегда давались бы ложные срабатывания, так как позиция строк имен процессов в файле, кроме того, я хочу видеть только измененные имена процессов, а не номера строк, которые он сообщает ("Процесс в строке 34 является выбросом" - это то, что в настоящее время выводится).
Надеюсь, это имеет смысл, и любая помощь в этом будет очень оценена.
Get-Process | Format-Table -Wrap -Autosize -Property ProcessName | Outfile c:\users\me\Desktop\Processes.txt $Processes = 'c:\Users\me\Desktop\Processes.txt' $Output_file = 'c:\Users\me\Desktop\Extracted.txt' $Sorted = 'c:\Users\me\Desktop\Sorted.txt' $Authorized = 'c:\Users\me\Desktop\Authorized.txt' $regex = '.{1,}' select-string -Path $Processes -Pattern $regex |% { $_.Matches } |% { $_.Value } > $Output_file Get-Content $Output_file | Sort-Object -Unique > $Sorted $dif = Compare-Object -ReferenceObject $(Get-Content $Sorted) -DifferenceObject $(get-content $Authorized) -IncludeEqual $lineNumber = 1 foreach ($difference in $dif) { if ($difference.SideIndicator -ne "==") { Write-Output "The Process at Line $linenumber is an Outlier" } $lineNumber ++ } Remove-Item c:\Users\me\Desktop\Processes.txt Remove-Item c:\Users\me\Desktop\Extracted.txt Write-Output "The Results are Stored in $Sorted"powershell - Powershell Сравните две строки
cls $logFile = "C:\test\output1.txt" Function LogWrite { Param ([string]$logstring) Add-content $Logfile -value $logstring } LogWrite "DocumentID|Correct|Wrong|UDI|Number of Errors|Line Number" LogWrite "------------------------------------------" $file = "C:\test\test\Birth records evt logging.txt" $pattern = "^(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(COB Reviewed)$" $pattern2 = "^(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(DocSecID)$" $pattern3 = "^(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)'t(.*)$" $errorCountTotal = 0 $linecount = 0 $line2Count = 0 Get-Content $file| ForEach-Object{ $errorCountLine = 0 $linecount++ $transposition = $false if($_ -match $pattern){ }elseif($_ -match $pattern2){ }elseif($_ -match $pattern3){ $line2Count++ if($matches[6].Length -eq $matches[7].length){ $wrong = $matches[6] $correct = $matches[7] $documentID = $matches[3] $UDI = $matches[8] $a = [char[]]$Matches[6] $b = [char[]]$matches[7] # for($i = 0; $i -lt $a.Length; $i++){ # for($x = 1; $x -lt $a.Length; $x++){ # if($a[$i] -eq $b[$i+$x] -and $a[$i+$x] -eq $b[$i]){ # if($a[$i] -eq $a[$i+$x]){ # write-host "same letter" # }else{ # $errorCountLine += 2 # } # } # } #} #Compare-Object $a $b |Format-List |Out-File "C:\test\test3.txt" $errorCountLine += (@(Compare-Object $a $b -SyncWindow 0).count /2) $errorCountTotal +=$errorCountLine Write-Host $matches[6] " - " $matches[7] " - " $errorCountLine " - " $linecount Write-Host $errorCountTotal LogWrite "$documentID|$wrong|$correct|$UDI|$errorCountLine|$linecount" }else{ $a = [char[]]$Matches[6] $b = [char[]]$matches[7] for($i = 0; $i -lt $a.Length; $i++){ for($x = 1; $x -lt $a.Length; $x++){ if($a[$i] -eq $b[$i+$x] -and $a[$i+$x] -eq $b[$i]){ if($a[$i] -eq $a[$i+$x]){ # write-host "same letter" }else{ $errorCountLine += 2 } } } } $diffL = [math]::Abs($Matches[7].Length - $Matches[6].Length) $errorCountLine = (((@(Compare-Object $a $b).count-$diffL) /2) + $diffL) $test = @(Compare-Object $a $b).count $errorCountTotal += $errorCountLine Write-Host $matches[6] " - " $matches[7] " - " $errorCountLine " - " $linecount $wrong = $matches[6] $correct = $matches[7] $documentID = $matches[3] $UDI = $matches[8] LogWrite "$documentID|$wrong|$correct|$UDI|$errorCountLine|$linecount" Write-Host $errorCountTotal } } } Write-Host $line2Count #number of lines that the program looks at. passes through pattern3. LogWrite 'n LogWrite "The total number of errors is $errorCountTotal"qaru.site
PowerShell — массивы (часть 2, последняя)
В прошлый раз мы рассмотрели основные вопросы массивов и управления ими в Windows PowerShell. Мы теперь знаем, как они создаются, как изменять их размер (ресайзить) и какие математические операции можно проводить над массивами. В этой части я расскажу о сравнении массивов, поиске элементов и т.д.
Сравнение массивов
Как известно, в PowerShell есть куча операторов (или групп операторов) сравнения, как –eq и –like. Но здесь у нас сразу появляется проблема — эти операторы нельзя использовать для сравнения массивов. Давайте посмотрим, что получится:
[↓] [vPodans] "abc" -eq "abc" True [↓] [vPodans] 1,2,3 -eq 1,2,3 [↓] [vPodans]Оператор –eq ничего не вернул. Дело в том, что справа от оператора –eq может быть только один объект, буква, строка, число и т.д. В контексте массивов оператор –eq можно использовать для получения элементов массива, содержащих конкретное значение. Например, у нас есть массив из нескольких чисел и мы хотим узнать сколько раз конкретное число использовано в массиве. Вот простой пример:
[↓] [vPodans] 2,8,5,6,2,5,4,2,7 -eq 2 2 2 2 [↓] [vPodans] 2,8,5,6,2,5,4,2,7 -eq 5 5 5 [↓] [vPodans] 2,8,5,6,2,5,4,2,7 -eq 1 [↓] [vPodans] (2,8,5,6,2,5,4,2,7 -eq 2).Length 3 [↓] [vPodans] (2,8,5,6,2,5,4,2,7 -eq 5).Length 2 [↓] [vPodans] (2,8,5,6,2,5,4,2,7 -eq 1).Length 0 [↓] [vPodans]Из показанных примеров мы видим, что оператор –eq возвращает элементы, которые соответствуют сравниваемому объекту. Поэтому при помощи оператора –eq можно узнать, содержит ли массив конкретное значение или нет и если да, то сколько раз. То же самое относится и к оператору –like, который больше подходит для сравнения строк по маске:
[↓] [vPodans] "abc","cba","bac","bca" -like "a*" abc [↓] [vPodans] "abc","cba","bac","bca" -like "?b?" abc cba [↓] [vPodans]Здесь используется тот же принцип, что и с использованием оператора –eq, только с разницей, что оператор –like сравнивает по маске (нестрогое соответствие).
Для точного сравнения двух массивов следует использовать командлет Compare-Object:
[↓] [vPodans] Compare-Object 1,2,3 1,2,3 [↓] [vPodans] Compare-Object 1,2,3 1,2 InputObject SideIndicator ----------- ------------- 3 <= [↓] [vPodans] Compare-Object 1,2,3 1,2,2 InputObject SideIndicator ----------- ------------- 2 => 3 <= [↓] [vPodans]Если массивы одинаковые, командлет ничего не вернёт. Если же есть различия, вы увидите, какие элементы отсутствуют в одном массиве (направление стрелочки указывает от массива с недостающим элментом). Может быть и так, что оба массива одинаковы по размеру, но какие-то элементы имеют разные значения. Тогда вы увидите стрелочки в оба направления. Командлет Compare-Object может выводить и одинаковые элементы:
[↓] [vPodans] Compare-Object -ref 1,2,3 -dif 1,2,2 -IncludeEqual InputObject SideIndicator ----------- ------------- 1 == 2 == 2 => 3 <= [↓] [vPodans]В одинаковых элементах SideIndicator будет показывать двойной знак равенства (==).
Поиск по массиву
Иногда бывает очень нужным найти индекс элемента массива, значение которого совпадает с какой-то величиной. К сожалению, в PowerShell нет стандартного механизма поиска индексов. Во времена, когда я в повершеле был ещё совсем чайником, Вася Гусев написал мне простенький ванлайнер, который выводит индексы элементов массивов, значения которых совпали по какой-то маске:
function findinarr ($array, $value) {for ($i=0; $i -lt $array.count;$i++){if($array[$i] -eq $value){$i}}}или более развёрнутый вариант:
function findinarr ($array, $value) { for ($i=0; $i -lt $array.count;$i++) { if($array[$i] -eq $value){$i} } }Например, узнать, индекс (или индексы) элемента массива, который содержит цифру 2 и 5:
[↓] [vPodans] $a = 2,8,5,6,2,5,4,2,7 [↓] [vPodans] findinarr $a 2 0 4 7 [↓] [vPodans] findinarr $a 5 2 5 [↓] [vPodans]Мы видим, что цифра 2 в указанном массиве содержится в элементах с индексами 0, 4 и 7, а цифра 5 в элементах с индексами 2 и 5. Не забудьте, что индексы в массивах начинаются с нуля.
Форматирование массивов
PowerShell отображает массивы в столбик, т.е. каждый элемент массива показывается на новой строке. А если вы хотите показать массив так, чтобы все элементы были в строчку, разделённой пробелами? Можно извратиться конструкцией вида:
$a = 1..100 $string = "" $a | ForEach-Object {$string += "$_" + " "} [↓] [vPodans] $a = 1..100 [↓] [vPodans] $string = "" [↓] [vPodans] $a | ForEach-Object {$string += "$_" + " "} [↓] [vPodans] $string 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 8 3 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 [↓] [vPodans]Но можно сделать ещё круче — заключить переменную с массивом в двойные кавычки:
[↓] [vPodans] $a = 1..100 [↓] [vPodans] "$a" 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 8 3 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 [↓] [vPodans]как видите, результат точно такой же, только кода израсходовано куда меньше.
Преобразование строк в массивы и обратно
Далеко не всегда мы имеем возможность получить готовый массив, наоборот, нам нужно разбить одну строку на массив строк. Для этого можно использовать метод Split() класса System.String или оператор –split:
[↓] [vPodans] "this is a single string".split() this is a single string [↓] [vPodans] -split "this is a single string" this is a single string [↓] [vPodans]По умолчанию, строка разбивается на массив строк по пробелу и разделителю строк. Если вы хотите разделить по другому разделителю можно его указать явно. Например, разбить MAC адрес сетевой карты на октеты:
[↓] [vPodans] "00-18-DE-54-57-8E" -split "-" 00 18 DE 54 57 8E [↓] [vPodans]Причём, обратите внимание, что оператор –split может быть как унарным (когда всё располагается только справа от оператора), так и бинарным (когда исходная строка находится слева от оператора, остальное располагается справа). Более подробно про оператор –split лучше всего прочитать в справке: http://technet.microsoft.com/en-us/library/dd347708.aspx. Функционал оператора достаточно интересен, но выходит за рамки рассматриваемой статьи.
Есть ещё один трюк, как разделить строку на массив символов. Для этого используется метод ToCharArray():
[↓] [vPodans] "00-18-DE-54-57-8E".tochararray() 0 0 - 1 8 - D E - 5 4 - 5 7 - 8 E [↓] [vPodans]Есть ещё один трюк, как разбить строку на массив символов. Для этого надо строку привести к массиву символов (char[]) и результат будет точно такой же:
[char[]]"00-18-DE-54-57-8E"Если у вас есть массив и его нужно преобразовать в одну строку, можно воспользоваться статическим методом Join() класса System.String или оператором –join:
[↓] [vPodans] $a = 1..10 [↓] [vPodans] $a 1 2 3 4 5 6 7 8 9 10 [↓] [vPodans] [string]::Join(",",$a) 1,2,3,4,5,6,7,8,9,10 [↓] [vPodans] $a -join "," 1,2,3,4,5,6,7,8,9,10 [↓] [vPodans] -join $a 12345678910 [↓] [vPodans]Как видно из примера, оператор –join так же, как и –split бывает унарным и бинарным. Бинарная форма всегда используется, когда нужно явно указать разделитель или другие параметры оператора –join. Если оператор унарный, он не принимает явный разделитель и просто последовательно пристыковывает элементы массива в строку. Если вам нужно преобразовать несколько массивов в строки с использованием одного и того же разделителя, в PowerShell можно использовать специальную переменную $ofs и массив явно привести к типу string:
[↓] [vPodans] $ofs = "+" [↓] [vPodans] [string]$a 1+2+3+4+5+6+7+8+9+10 [↓] [vPodans] iex ([string]$a) 55 [↓] [vPodans]Как можно видеть из примеров, с массивами в PowerShell можно делать что угодно (кроме вычитания и деления). Причём, зачастую, существует несколько способов выполнить одну и ту же задачу.
Реверсирование массивов
Вообще это используется не так часто, что можно было бы и опустить, но я достаточно часто работаю с CryptoAPI и бывает нужным первернуть массив. Дело в том, что CryptoAPI до мозга костей little-endian, а остальные API (даже тот же .NET) как правило big-endian. И чтобы перевернуть массив верх тормашками можно использовать статический метод Reverse() класса System.Array:
[↓] [vPodans] $a = 1..5 [↓] [vPodans] $a 1 2 3 4 5 [↓] [vPodans] [array]::Reverse($a) [↓] [vPodans] $a 5 4 3 2 1 [↓] [vPodans]Следует учитывать, что этот метод меняет порядок следования элементов в самой перменной и не образует выходной информации.
Эпилог
В качестве эпилога скажу, что я рассмотрел лишь самые популярные действия с массивами и это составляет лишь малую часть того, что с ними можно сделать в реальности. Но этого материала (включая предыдущую статью) вам хватит на 95% случаев. И на этом всё.
www.sysadmins.lv
powershell - PowerShell Сравните содержимое двух строк
Я пытаюсь сравнить значения двух переменных, но содержимое этих двух строк находится в разных порядках
Пример:
$Var1 = "item1" $Var1 += "item2" $Var2 = "item2" $Var2 = "item1"Как сравнить эти две переменные, чтобы убедиться, что они оба равны?
===== ОБНОВЛЕНО ПРИМЕР ===== ПРИМЕР: Получить объекты и отсортировать их.
$Computers = (Get-Content "$PWD\Computers.txt").GetEnumerator() | Sort-Object {"$_"}ПРИМЕР: добавьте результаты и отсортируйте их.
$Successful += $Computer $Successful = $Successful.GetEnumerator() | Sort-Object {"$_"}ПРИМЕР SCRIPT: Используется приведенные выше примеры для создания следующего сценария. Пример позволил мне проверить результаты, а не счет, но по содержанию, что позволило мне получить более точное сравнение. До того, как я использовал "Successful.count -eq Computers.count", который не проверял, был ли компьютер дважды введен.
$Computers = (Get-Content "$PWD\Computers.txt").GetEnumerator() | Sort-Object {"$_"} $HotFixes = Get-Content "$PWD\HotFixes.csv" CLS While (!$Successful -OR $Successful -ne $Computers) { foreach ($Computer in $Computers) { $MissingCount = 0 IF (!$Successful -NotLike "*$Computer*") { Write-Host "$Computer': Connecting" If (Test-Connection -ComputerName $Computer -Count 1 -quiet) { Write-Host "$Computer': Connected" [string]$Comparison = get-hotfix -ComputerName $Computer | Select -expand HotFixID ForEach ($HotFix in $HotFixes) { IF ($Comparison -NotLike "*$HotFix*") { $Results += "$Computer,$HotFix" $MissingCount++ } } Write-Host "$Computer': $MissingCount Patches Needed" $Successful += $Computer $Successful = $Successful.GetEnumerator() | Sort-Object {"$_"} } ELSE { Write-Host "$Computer': Unable to connect" } } ELSE { Write-Host "$Computer already completed" } Write-Host "$Computer': Complete" Write-Host } } $Results задан Nick W. 16 дек. '12 в 16:04 источник поделитьсяqaru.site
powershell - Таблица хэшей PowerShell или массив для сравнения строк
Я пытаюсь найти частоту имен папок, разбитых по уникальным каталогам, из текстового файла имен путей. Поэтому, используя этот набор данных, я хочу получить следующие результаты:
-
Данные
- C:\Project_1\Models\MapShedMaps\randomfilename.txt
- C:\Project_1\Models\MapShedMaps\randomfilename.txt
- C:\Project_1\Models\MapShedMaps\randomfilename.txt
- C:\Project_2\Models\MapShedMaps\randomfilename.txt
- C:\Project_3\Models\MapShedMaps\randomfilename.txt
- C:\Project_3\Models\MapShedMaps\randomfilename.txt
- C:\Project_3\Models\MapShedMaps\randomfilename.txt
-
Результаты
- Project_1 = 1
- Project_2 = 1
- Project_3 = 1
- Модели = 3
- MapShedMaps = 3
Моей первой идеей для этого было бы использовать Get-Content, а затем ForEach-Object, чтобы разбить каждое слово из пути и сохранить их в хеш-таблице, которая будет подсчитывать. Чтобы остановить дублирование, я думал о массиве или другой хеш-таблице для хранения пути объекта currnet до этой точки... Все это разваливается. Я не уверен, что лучший подход к хранению "родительских" членов пути - это знать, является ли это уникальным событием. Любое предложение о том, как это сделать, было бы здорово.
ОБНОВИТЬ:
Хорошо, я думаю что-то вроде хэш-таблицы $ SAVE и подсчитывает каждое значение unqiue, массив $ PREVIOUS, являющийся последним объектом из канала, и массив $ HAVESEEN, который захватывает трубу с самого начала.
SO первым объектом будет C, если строка будет разбита, затем Project_1 и C переместится в $ PREVIOUS и $ HAVESEEN. Я собираюсь попытаться написать это, я не уверен, что все это между хэш-таблицей и массивами будет работать.
задан Steve 28 сент. '12 в 20:00 источник поделитьсяqaru.site
- Пропускная способность материнской платы

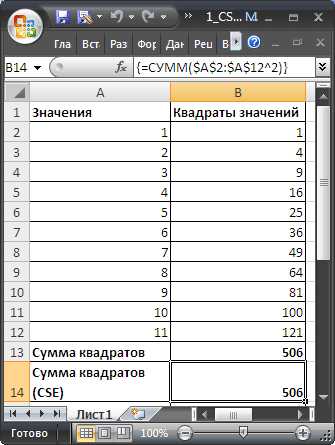
- Ctrl shift enter в excel
- Как включить джава скрипт в яндекс браузере

- Стоит ли переходить на windows 10 с windows 7 в 2018 году

- Как заархивировать файлы в zip

- Linux mint удаление программ

- Инструкция работы с программой torrent
- Видео не загружается
- Быстрая настройка роутера

- Какие бывают антивирусы для компьютера

- Браузер какой хороший