T sql pivot: Использование операторов PIVOT и UNPIVOT — SQL Server
Содержание
Оператор PIVOT / Хабр
По материалам статьи Craig Freedman: The PIVOT Operator
Несколько статей будут посвящены тому как в SQL Server реализован оператор PIVOT и UNPIVOT. Начнем с оператора PIVOT. Оператор PIVOT берет нормализованную таблицу и преобразует ее в другой вид, в котором столбцы результирующей таблицы получаются из значений исходной таблицы. Например, предположим, что мы хотим хранить данные о суммарной выручке от продаж за год по каждому из сотрудников. Для этих целей можно создать следующую таблицу:
CREATE TABLE Sales (EmpId INT, Yr INT, Sales MONEY) INSERT Sales VALUES(1, 2005, 12000) INSERT Sales VALUES(1, 2006, 18000) INSERT Sales VALUES(1, 2007, 25000) INSERT Sales VALUES(2, 2005, 15000) INSERT Sales VALUES(2, 2006, 6000) INSERT Sales VALUES(3, 2006, 20000) INSERT Sales VALUES(3, 2007, 24000)
Обратите внимание, что в этой таблице на одного сотрудника приходится одна строка на каждый год. Кроме того, сотрудники 2 и 3 имеют данные о продажах только за два года из трех. Теперь предположим, что мы хотим показать эти данные в табличном виде с одной строкой на каждого сотрудника и данными о продажах за все три года в этой строке. Мы можем очень легко добиться этого, используя оператор преобразования PIVOT:
Теперь предположим, что мы хотим показать эти данные в табличном виде с одной строкой на каждого сотрудника и данными о продажах за все три года в этой строке. Мы можем очень легко добиться этого, используя оператор преобразования PIVOT:
SELECT EmpId, [2005], [2006], [2007] FROM (SELECT EmpId, Yr, Sales FROM Sales) AS s PIVOT (SUM(Sales) FOR Yr IN ([2005], [2006], [2007])) AS p
Я не буду углубляться в синтаксис PIVOT, который хорошо описан в электронной документации. Достаточно сказать, что использование этого оператора позволяет суммировать продажи по каждому сотруднику за каждый год, перечисленный в списке, и представить результат в виде одной строки для каждого сотрудника. Ниже представлена результирующая выборка:
EmpId 2005 2006 2007 ----------- --------------------- --------------------- --------------------- 1 12000.00 18000.00 25000.00 2 15000.00 6000.00 NULL 3 NULL 20000.00 24000.00
 00 NULL
3 NULL 20000.00 24000.00
00 NULL
3 NULL 20000.00 24000.00Обратите внимание, что SQL Server выводит NULL для отсутствующих данных о продажах сотрудников 2 и 3.
Ключевое слово SUM (или либо другой агрегат) является обязательным. Если таблица «Sales» содержит для сотрудника за какой-то год несколько строк, PIVOT в результате объединяет их (в данном случае путем суммирования) в одну строку данных. Разумеется, поскольку в этом примере запись в каждой «ячейке» выборки является результатом суммирования одной строки, мы также легко могли бы использовать и другой агрегат, например, MIN или MAX. Я использовал SUM, поскольку он более интуитивно понятен.
Этот пример с PIVOT является обратимым. Информацию из выборки можно использовать для восстановления исходной таблицы с помощью оператора UNPIVOT (о котором я расскажу в следующей статье). Однако не все операции с PIVOT являются обратимыми. Чтобы быть обратимой, операция с PIVOT должна соответствовать следующим критериям:
Все входные данные должны подпадать под преобразование.
Если будет использоваться какой-либо фильтр, в том числе предложение IN, некоторые данные могут быть исключены из результата PIVOT. Например, если бы мы в приведенном выше примере выбирали данные о продажах только за 2006 и 2007 годы, очевидно, что мы не смогли бы восстановить из выборки данные о продажах за 2005 год.Каждая ячейка результирующей таблицы должна быть получена из одной строки таблицы на входе. Если в одну ячейку будут объединены несколько строк таблицы на входе, восстановить исходные входные строки будет невозможно.
Агрегатная функция должна быть реверсивной (при использовании одной строки на входе). SUM, MIN, MAX и AVG возвращают одно, полученное из таблицы на входе значение без изменений и, таким образом, могут быть реверсированы. COUNT не возвращает свое входное значение без изменений и, следовательно, не может быть обратимо.
 Если будет использоваться какой-либо фильтр, в том числе предложение IN, некоторые данные могут быть исключены из результата PIVOT. Например, если бы мы в приведенном выше примере выбирали данные о продажах только за 2006 и 2007 годы, очевидно, что мы не смогли бы восстановить из выборки данные о продажах за 2005 год.
Если будет использоваться какой-либо фильтр, в том числе предложение IN, некоторые данные могут быть исключены из результата PIVOT. Например, если бы мы в приведенном выше примере выбирали данные о продажах только за 2006 и 2007 годы, очевидно, что мы не смогли бы восстановить из выборки данные о продажах за 2005 год.Ниже представлен пример необратимой операции PIVOT. В нём рассчитывается общий объем продаж для всех сотрудников за все три года, но результат не детализируется по сотруднику.
SELECT [2005], [2006], [2007] FROM (SELECT Yr, Sales FROM Sales) AS s PIVOT (SUM(Sales) FOR Yr IN ([2005], [2006], [2007])) AS p
Результат исполнения запроса показан ниже. Каждая ячейка представляет собой сумму двух или трех строк таблицы на входе.
2005 2006 2007 --------------------- --------------------- --------------------- 27000.00 44000.00 49000.00
PIVOT и UNPIVOT в Transact-SQL – описание и примеры использования операторов | Info-Comp.ru
Сегодня мы поговорим о таких операторах Transact-SQL как PIVOT и UNPIVOT, узнаем, для чего они нужны, рассмотрим синтаксис написания запросов, и, конечно же, разберем примеры использования их на практике.
В Transact-SQL для написания перекрестных запросов или кросс табличных выражений существует специальный оператор, я бы сказал даже целая конструкция под названием PIVOT, которая имеет достаточно специфический синтаксис, также существует оператор, который делает и обратное действие он называется как не странно UNPIVOT. Эти операторы мы сейчас подробно рассмотрим, и для начала давайте я расскажу, как будет выглядеть данная статья.
Эти операторы мы сейчас подробно рассмотрим, и для начала давайте я расскажу, как будет выглядеть данная статья.
Сначала мы поговорим об операторе PIVOT, узнаем, что он делает, для чего он нужен, где он может пригодиться, рассмотрим синтаксис и разберем пример, а затем мы перейдем к оператору UNPIVOT.
Примечание! Все примеры мы будем рассматривать в СУБД MS SQL Server 2014 Express с использованием Management Studio.
Содержание
- Оператор PIVOT
- Синтаксис оператора PIVOT
- Пример использования оператора PIVOT
- Оператор UNPIVOT
- Пример использования UNPIVOT
- Видеоурок
Оператор PIVOT
PIVOT – это оператор Transact-SQL, который поворачивает результирующий набор данных, т.е. происходит транспонирование таблицы, при этом используются агрегатные функции, и данные соответственно группируются. Другими словами, значения, которые расположены по вертикали, мы выстраиваем по горизонтали.
Данный оператор может потребоваться тогда, когда необходимо, например, предоставить какой либо отчет в наглядной форме по годам, допустим для бухгалтеров и экономистов, так как именно они любят представления данных в таком виде. Также он может пригодиться и просто для преставления какой-либо статистики, но в любом случае из собственного опыта могу сказать, что оператор PIVOT будет требоваться достаточно редко, но когда он потребуется он будет просто незаменим и очень полезен, поэтому Вы должны знать, как и когда его можно использовать.
Результат, который мы получим при использовании оператора PIVOT, можно также получить и с использованием известной конструкции select…case, а до появления MS SQL сервера 2005 только с использованием этой конструкции, как Вы правильно поняли, оператор PIVOT можно использовать, только начиная с 2005 sql сервера.
У данного оператора очень специфический, непривычный и некоторые даже скажут сложный синтаксис, как для написания, так и для простого понимания.
Синтаксис оператора PIVOT
SELECT столбец для группировки, [значения по горизонтали],…
FROM таблица или подзапрос
PIVOT(агрегатная функция
FOR столбец, содержащий значения, которые станут именами столбцов
IN ([значения по горизонтали],…)
)AS псевдоним таблицы (обязательно)
в случае необходимости ORDER BY;
Вот такой вот синтаксис, помимо всего прочего значения, которые будут выступать в качестве названия колонок по горизонтали, необходимо писать вручную, т.е. мы должны знать их заранее, другими словами, динамический запрос построить, не получиться. На самом деле можно, с помощью динамического формирования строки запроса, а потом исполнение этой строки через специальную команду EXECUTE, но как говорится это уже совсем другая история.
Заметка! Начинающим рекомендую посмотреть мой видеокурс по T-SQL.
Пример использования оператора PIVOT
С теорией я думаю достаточно, поэтому давайте переходить к практике, тем более что на примерах лучше понять, как же работает этот оператор.
И для начала давайте разберем исходные данные.
Допустим, у нас есть таблица вот с такой структурой:
CREATE TABLE [dbo].[test_table_pivot](
[fio] [varchar](50) NULL,
[god] [int] NULL,
[summa] [float] NULL
) ON [PRIMARY]
GO
Где, fio — это ФИО сотрудника, god – год, в котором он получал премию, summa — соответственно сумма премии, вот такой незамысловатый пример, так как в плоскости времени наглядней видна работа оператора PIVOT.
И в данной таблице у нас есть тестовые данные, для просмотра этих данных напишем простой запрос на выборку, т.е. select
SELECT * FROM dbo.test_table_pivot
А теперь представим, что нам необходимо сделать отчет, скажем для начальника, о размере премии, которую получал каждый сотрудник за год, в течение нескольких лет.
Самым простым способом будет конечно просто использовать конструкцию GROUP BY, например
SELECT fio, god, sum(summa) AS summa FROM dbo.
 test_table_pivot
GROUP BY fio, god
test_table_pivot
GROUP BY fio, god
На что нам начальник скажет, что это такое? ничего не понятно? не наглядно? Улучшить ситуацию можно, добавив еще и сортировку ORDER BY, допустим сначала по фамилии, а затем по году
SELECT fio, god, sum(summa) as summa FROM dbo.test_table_pivot GROUP BY fio, god ORDER BY fio, god
но это все равно не то. А вот если мы будем использовать оператор PIVOT, например вот таким образом
SELECT fio, [2011], [2012], [2013], [2014], [2015]
FROM dbo.test_table_pivot
PIVOT (SUM(summa)for god in ([2011],[2012],[2013],[2014],[2015])
) AS test_pivot
то у нас получится вот такой результат
Я думаю, Вы согласитесь, что так намного наглядней и понятней.
Здесь у нас:
- fio — столбец, по которому мы будем осуществлять группировку;
- [2011],[2012],[2013],[2014],[2015] — названия наших столбцов по горизонтали, ими выступают значения из колонки god;
- sum(summa) — агрегатная функция по столбцу summa;
- for god in ([2011],[2012],[2013],[2014],[2015]) — тут мы указываем колонку, в которой содержатся значения, которые будут выступать в качестве названия наших результирующих столбцов, по факту в скобках мы указываем то же самое, что и чуть выше в select;
- as test_pivot — это обязательный псевдоним, не забывайте его указывать, иначе будет ошибка.

Переходим к UNPIVOT.
Оператор UNPIVOT
UNPIVOT – это оператор Transact-SQL, который выполняет действия, обратные PIVOT. Сразу скажу, что да он разворачивает таблицу в обратную сторону, но в отличие от оператора PIVOT он ничего не агрегирует и уж тем более не раз агрегирует.
UNPIVOT требуется еще реже, чем PIVOT, но о нем также необходимо знать.
Здесь я думаю, давайте сразу перейдем к рассмотрению примера.
Пример использования UNPIVOT
Допустим, таблица имеет следующую структуру:
CREATE TABLE [dbo].[test_table_unpivot](
[fio] [varchar](50) NULL,
[number1] [int] NULL,
[number2] [int] NULL,
[number3] [int] NULL,
[number4] [int] NULL,
[number5] [int] NULL,
) ON [PRIMARY]
GO
Где, fio — ФИО сотрудника, а number1, number2… и так далее это какие-то номера этого сотрудника:)
Данные будут, например, такие:
И допустим, нам необходимо развернуть эту таблицу, для этого мы будем использовать оператор UNPIVOT, а запрос будет выглядеть следующим образом:
SELECT fio, column_name, number FROM dbo.
 test_table_unpivot
UNPIVOT(
number for column_name in (
[number1],[number2],[number3],[number4],[number5]
)
)AS test_unpivot
test_table_unpivot
UNPIVOT(
number for column_name in (
[number1],[number2],[number3],[number4],[number5]
)
)AS test_unpivot
Где,
- fio – столбец с ФИО, он в принципе не изменился;
- column_name – псевдоним столбца, который будет содержать названия наших колонок;
- number – псевдоним для значений из столбцов number1, number2…
Заметка! Начинающим программистам рекомендую почитать мою книгу «SQL код», которая поможет Вам изучить язык SQL как стандарт, в ней рассматриваются все базовые конструкции языка SQL, приводится много примеров и скриншотов.
Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Видеоурок
 Уровень 3 – Эксперт» – пример видеоурока» src=»https://www.youtube.com/embed/Fg32AhWp-qQ?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
Уровень 3 – Эксперт» – пример видеоурока» src=»https://www.youtube.com/embed/Fg32AhWp-qQ?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
На этом все, удачи!
Динамические сводные таблицы в SQL Server
В этой статье я собираюсь объяснить, как мы можем создать динамическую сводную таблицу в SQL Server. Сводные таблицы представляют собой часть сводной информации, созданной из большого базового набора данных. Обычно он используется для создания отчетов по конкретным измерениям из обширных наборов данных. По сути, пользователь может преобразовывать строки в столбцы. Это дает пользователям возможность легко переносить столбцы из таблицы SQL Server и создавать отчеты в соответствии с требованиями.
Некоторые сводные таблицы также создаются, чтобы помочь в анализе данных, в основном для нарезки данных и создания аналитических запросов. Если вы видите рисунок ниже, у вас будет некоторое представление о том, как сводная таблица создается из таблицы.
Рисунок 1 – Пример сводной таблицы
Если вы посмотрите на рисунок выше, то увидите, что там две таблицы. Таблица слева — это фактическая таблица, содержащая исходные записи. Таблица справа представляет собой сводную таблицу, созданную путем преобразования строк исходной таблицы в столбцы. По сути, сводная таблица будет содержать три определенные области, в основном — строки, столбцы и значения. На приведенном выше рисунке ряды взяты из 9Столбец 0015 Студент , столбцы берутся из столбца Тема, , а значения создаются путем агрегирования столбца Оценки .
Создание образца данных
Теперь, когда у нас есть некоторое представление о том, как работает сводная таблица, давайте продолжим и попробуем на практике. Вы можете выполнить приведенный ниже скрипт для создания демонстрационных данных, и мы попытаемся реализовать приведенную выше иллюстрацию здесь.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Создание табличных классов ( [Студент] VARCHAR (50), [Субъект] VARCHAR (50), [Marks] INT ) GO Вставка в значения сорта (» Джейкоб», «Математика», 100), («Джейкоб», «Наука», 95), («Джейкоб», «География», 90), («Амили», «Математика», 90), («Амили», «Наука», 90), («Амили», ‘,’География’,100) GO |
Давайте попробуем выбрать данные из таблицы, которую мы только что создали, как показано ниже.
Рисунок 2 – Пример набора данных для сводной таблицы
Применение оператора PIVOT
Теперь, когда у нас есть готовые данные, мы можем приступить к созданию сводной таблицы в SQL Server. Учитывая ту же иллюстрацию, что и выше, мы сохраним 9Столбец 0015 Student в качестве строк и возьмите Subject для столбцов. Кроме того, еще один важный момент, на который следует обратить внимание, заключается в том, что при написании запроса для сводной таблицы в SQL Server нам необходимо предоставить отдельный список значений столбцов, которые мы хотели бы визуализировать в сводной таблице. Для этого скрипта мы видим, что в исходном наборе данных доступны три различных субъекта, поэтому мы должны указать эти три в списке при создании сводной таблицы.
1 2 3 4 5 6 7 8 10 110003 12 13 14 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 | Выберите * Из ( SELECT [Студент], [Субъект], [Marks] из классов ) Студенты Pivot ( Сумма (Марки]) 0003 для [субъекта] в ( [Математика], [Science], [География] ) ) как Pivottable |
Рисунок 3 – Применение оператора PIVOT
Как вы можете видеть на рисунке выше, сводная таблица была создана, и мы преобразовали строки для субъектов в отдельные столбцы.
Теперь давайте попробуем сломать приведенный выше скрипт и понять, как он работает. Если вы видите сценарий, ясно, что мы можем разделить его на две отдельные части: в первой части мы выбираем данные из исходной таблицы как есть, а во второй части мы определяем, как должна быть создана сводная таблица. В сценарии мы также упоминаем некоторые конкретные ключевые слова, такие как SUM , FOR и IN, , которые предназначены для использования только оператором PIVOT . Давайте быстро поговорим об этих ключевых словах.
Оператор SUM
В сценарии я использовал оператор SUM, который по существу агрегирует значения из столбца Marks , чтобы его можно было использовать в сводной таблице. Для оператора сводки обязательно использовать агрегированный столбец, который он может отображать для разделов значений.
Ключевое слово FOR
Ключевое слово FOR — это специальное ключевое слово, используемое для сводной таблицы в сценариях SQL Server. Этот оператор сообщает оператору поворота, к какому столбцу нам нужно применить функцию поворота. По сути, столбец, который нужно преобразовать из строк в столбцы.
Этот оператор сообщает оператору поворота, к какому столбцу нам нужно применить функцию поворота. По сути, столбец, который нужно преобразовать из строк в столбцы.
Ключевое слово IN
Ключевое слово IN, как уже объяснялось выше, перечисляет все отдельные значения из сводного столбца, которые мы хотим добавить в список столбцов сводной таблицы. В этом примере, поскольку у нас есть только три различных значения для столбца Subject , мы предоставляем все три в списке для ключевого слова IN .
Единственное ограничение в этом процессе заключается в том, что нам нужно указать жестко закодированные значения для столбцов, которые нам нужно выбрать из сводной таблицы. Например, если в таблицу вставлено новое значение субъекта, сводная таблица не сможет отобразить новое значение в виде столбца, поскольку оно не определено в списке для IN оператор. Давайте продолжим и вставим в таблицу несколько записей по другому предмету — « История ».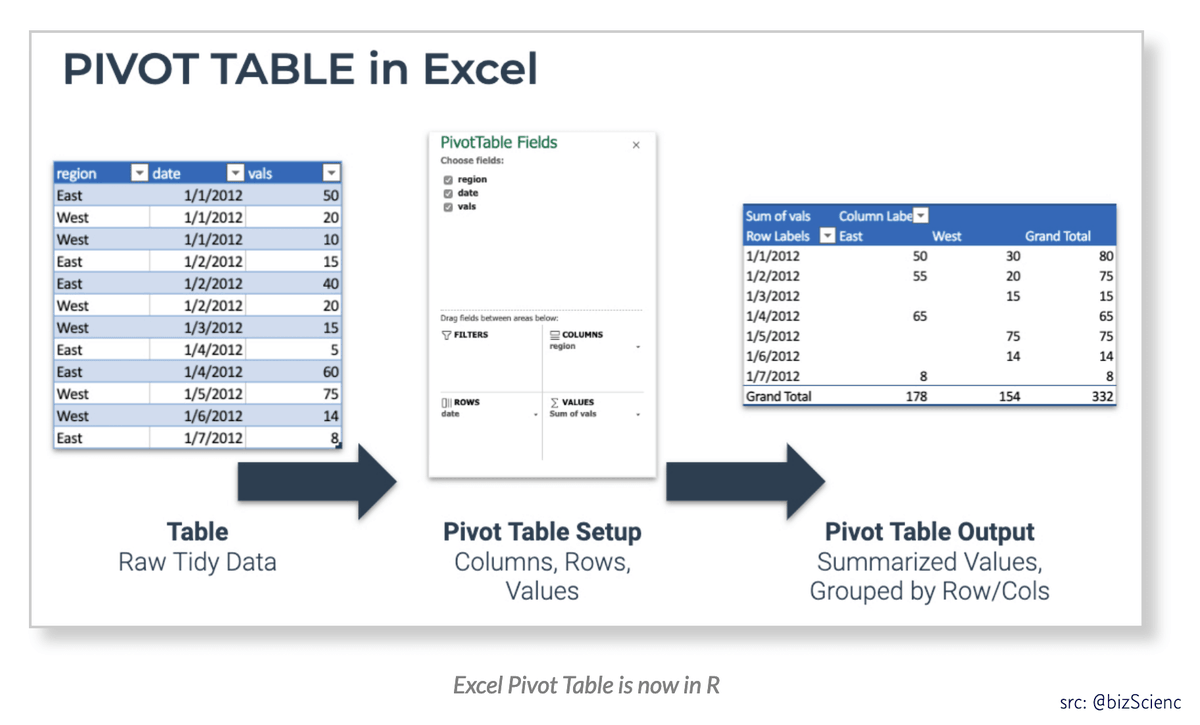
ВСТАВИТЬ В ЗНАЧЕНИЯ («Джейкоб», «История», 80), («Эмили», «История», 90) GO |
Давайте выполним запрос для отображения сводной таблицы, как мы это делали ранее.
Рисунок 4. Выполнение запроса PIVOT
Как видите, новая тема, которую мы только что вставили в таблицу, недоступна в сводной таблице. Это потому, что мы не упомянули новый столбец в списке IN оператора PIVOT. Это одно из ограничений таблицы PIVOT в SQL. Каждый раз, когда мы хотим включить новый столбец в PIVOT, нам нужно будет пойти и изменить базовый код.
Другой сценарий был бы таким, как если бы требования изменились, и теперь нам нужно повернуть студентов вместо предметов, даже в таком случае нам нужно будет изменить весь запрос. Чтобы избежать этого, мы можем создать что-то динамическое, в котором мы можем настроить столбцы, для которых нам понадобится таблица PIVOT.![]() Давайте продолжим и поймем, как создать динамическую хранимую процедуру, которая будет возвращать сводную таблицу в SQL.
Давайте продолжим и поймем, как создать динамическую хранимую процедуру, которая будет возвращать сводную таблицу в SQL.
Создание динамической хранимой процедуры для сводных таблиц
Давайте инкапсулируем весь сценарий PIVOT в хранимую процедуру. Эта хранимая процедура будет иметь настраиваемые параметры, в которых мы сможем настроить наши требования, просто изменив некоторые параметризованные значения. Сценарий для динамической таблицы PIVOT в SQL приведен ниже.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | СОЗДАТЬ ПРОЦЕДУРУ dbo.DynamicPivotTableInSql @ColumnToPivot NVARCHAR(255), @ListToPivot NVARCHAR(255) AS Begin Объявление @SQLStatement NVARCHAR (MAX) SET @SQLSTATEMENT = N ‘ SELECT * Из ( SELECT [Студент], [Тюр От классов ) Студенты -сельские районы Pivot ( Sum ([Marks]) для [‘+@columntopivot+’] в ( ‘+@listtopivot+’ ) ) AS PivotTable ‘;
EXEC(@SqlStatement)
КОНЕЦ |
Как вы можете видеть в приведенном выше скрипте, у меня есть две параметризованные переменные. Детали этих двух параметров следующие.
Детали этих двух параметров следующие.
- @ColumnToPivot — этот параметр принимает имя столбца в базовой таблице, к которой будет применяться сводная таблица. Для текущего сценария это будет « Тема », потому что мы хотели бы повернуть базовую таблицу и отобразить все темы в столбцах
- @ListToPivot — этот параметр принимает список значений, которые мы хотим визуализировать в виде столбца сводной таблицы в SQL.
Выполнение динамической хранимой процедуры
Теперь, когда наша динамическая хранимая процедура готова, давайте продолжим и выполним ее. Давайте воспроизведем первый сценарий, где мы визуализировали все три предмета — математику, естествознание и географию в сводной таблице в SQL. Выполните скрипт, как показано ниже.
EXEC dbo.DynamicPivotTableInSql N’Subject’ ,N'[Математика],[Наука],[География]’ |
Рисунок 5 – Выполнение динамической хранимой процедуры
Как видите, теперь мы указали имя столбца « Subject » в качестве первого параметра и список сводных столбцов в качестве второго столбца.
Предположим, теперь мы хотели бы также включить отметки для столбца « History » в эту сводную таблицу, единственное, что вам нужно сделать, это добавить имя столбца во второй параметр и выполнить хранимую процедуру.
EXEC dbo.DynamicPivotTableInSql N’Subject’ ,N'[Математика],[Наука],[География],[История]’ |
Рис. 6. Выполнение динамической хранимой процедуры изменено
Таким же простым образом вы можете добавить столько столбцов, сколько хотите, в список, и сводная таблица будет отображаться соответствующим образом.
Теперь давайте рассмотрим другой сценарий, в котором вам нужно отобразить имена учащихся в столбцах, а предметы в строках — это как раз наоборот сценарий того, что мы делали все это время. Решение также простое, как и следовало ожидать. Мы просто изменим значения обоих параметров таким образом, чтобы первый параметр указывал на столбец «9». 0015 Student », а второй параметр будет содержать список студентов, которых вы хотите, вместе со столбцами. Хранимая процедура выглядит следующим образом.
0015 Student », а второй параметр будет содержать список студентов, которых вы хотите, вместе со столбцами. Хранимая процедура выглядит следующим образом.
EXEC dbo.DynamicPivotTableInSql N’Student’ ,N'[Amilee],[Jacob]’ |
Рисунок 7 – Динамическая хранимая процедура
Как вы можете видеть на изображении выше, сводная таблица в SQL динамически модифицируется без необходимости изменения базового кода.
Заключение
В этой статье я объяснил, что такое сводная таблица в SQL и как ее создать. Я также продемонстрировал простой сценарий, в котором вы можете реализовать сводные таблицы. Наконец, я также показал, как параметризовать сценарий сводной таблицы таким образом, чтобы структуру таблицы значений можно было легко изменить без необходимости модификации базового кода.
- Автор
- Последние сообщения
Aveek Das
Aveek — опытный инженер по данным и аналитике, в настоящее время работает в Дублине, Ирландия. Его основные области технических интересов включают SQL Server, SSIS/ETL, SSAS, Python, инструменты для работы с большими данными, такие как Apache Spark, Kafka, и облачные технологии, такие как AWS/Amazon и Azure.
Его основные области технических интересов включают SQL Server, SSIS/ETL, SSAS, Python, инструменты для работы с большими данными, такие как Apache Spark, Kafka, и облачные технологии, такие как AWS/Amazon и Azure.
Он плодовитый автор, опубликовавший более 100 статей в различных технических блогах, включая собственный блог, и частый участник различных технических форумов.
В свободное время увлекается любительской фотографией, в основном уличными изображениями и натюрмортами. Некоторые проблески его работ можно найти в Instagram. Вы также можете найти его на LinkedIn
Просмотреть все сообщения от Aveek Das
Последние сообщения от Aveek Das (посмотреть все)
sql — TSQL Сводная таблица строк в столбцы
У меня есть некоторые данные в таблице, которая выглядит следующим образом. Я пытаюсь выполнить запрос, который будет получать мои данные в одной строке для каждого запроса. Мне не нужны даты или причина отказа, только eprojman и apvStatus для каждого groupId
requestId — projMan1 — apvStatus1 — projMan2 — apvStatus2 — projMan3 — apvStatus3 и т. д.
д.
Я пытался использовать таблицу PIVOT, но все примеры, которые я нашел, включают суммирование данных или что-то в этом роде. Я просто очень хочу взять 5 строк и превратить их в 1 для каждого идентификатора запроса
Я просто очень хочу взять 5 строк и превратить их в 1 для каждого идентификатора запроса
Единственное, что я смог придумать, это выбрать из одной и той же таблицы 5 раз для каждого идентификатора группы и объединить их, но это медленнее чем черт. Должен быть лучше
Спасибо.
Текущий запрос:
выберите group1.requestId
, group1.apvStatus как apvStatus1
, group1.projMan как projMan1
, group2.apvStatus как apvStatus2
, group2.projMan как projMan2
, group3.apvStatus как apvStatus3
, group3.projMan как projMan3
,group4.apvStatus как apvStatus4
, group4.projMan как projMan4
,group5.apvStatus как apvStatus5
, group5.projMan как projMan5
,group1.denialReason
INTO #TEMPBAОрганизованный
от (
выберите requestId, apvStatus, projMan, denialReason из #TEMPBULKAPPROVAL, где groupId = 1) group1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(выберите requestId, apvStatus, projMan, denialReason из #TEMPBULKAPPROVAL, где groupId = 2) group2
на group1.
