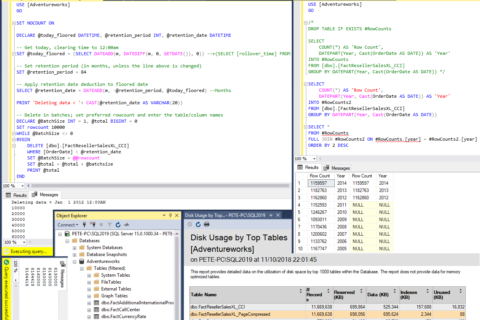
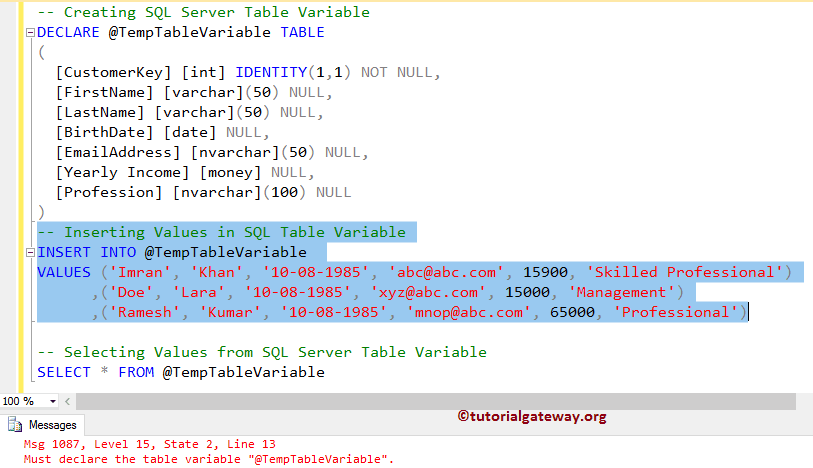
T sql table create: Инструкция CREATE TABLE (Transact-SQL) — SQL Server
Содержание
CHECK CONSTRAINT в MS SQL — Грабли по которым мы прошлись / Хабр
Данная статья будет про то, как одна дружная команда веб разработчиков, не имея в своём составе опытного SQL разработчика, добавила Check Constraint в таблицу и прошлась по нескольким простым, но не сразу очевидным граблям. Будут разобраны особенности синтаксиса T-SQL, а также нюансы работы ограничений (СONSTRAINT’ов), не зная которые, можно потратить не мало времени на попытки понять, почему что-то работает не так. Так же будет затронута особенность работы SSDT, а именно как генерируется миграционный скрипт, при необходимости добавить или изменить ограничения (CONSTRAINT’ы).
Дабы читатель поскорей понял, стоит читать статью или нет, я сначала рассмотрю абстрактную задачу, по ходу решения которой будут заданы вопросы «А почему так?». Если вы сразу будете знать ответ, то смело бросайте чтение и переходите к следующей статье.
Разработаем гарем?
«Гарем» — система, которая будет позволять вести учёт людей в «храме любви».
Для простоты разработки примем следующее:
- гости в гареме запрещены и, соответственно, в базе не хранятся, т. е. хранятся только «хозяева» и их жёны
- у жён и их «хозяина» фамилия совпадает
- по фамилии можно уникально идентифицировать каждый гарем, т. е. одна и та же фамилия в разных гаремах встретиться не может.
Для хранения людей создаётся таблица Persons:
В последний момент, приходит озарение, что на уровне схемы базы мы не гарантируем существование только одного мужчины в гареме. Решаем это исправить путём добавления проверочного ограничения (check constraint):
основанного на скалярной пользовательской функции (scalar-valued Function):
«А почему так?» №1.
При попытке вставить абсолютно валидные данные (как женщин, так и мужчин), понимаем, что мы всё поломали. Insert валится со следующей ошибкой:
«А почему так?» №2.
После того как побороли проблему вставки данных, решаем задеплоиться в QA окружение. Создаём миграционный скрипт при помощи SSDT, быстро просматриваем его. Находим какую-то не очень понятную строку (выделена красной рамкой).
Из комментария в инструкции PRINT кажется, что это запуск проверки ограничения на уже существующих строках. Но при создании ограничения мы же указали, что существующие строки проверять не нужно («Check Existing Data On Creation Or Re-Enabling» был установлен в “No”). Поэтому начинаем гуглить и находим «полезный» пост. Прочитав ответ и все комментарии к нему, обретаем глубокую уверенность, что эта инструкция включает проверку при вставке новых строк, а не валидирует существующие, т. е. нам обязательно нужно оставить эту строку, иначе ограничение вообще никогда не будет проверяться.
С гордостью за проделанную работу, отправляем скрипт, ждёмс… Спустя Х часов приходит отчёт, что наш миграционный скрипт успешно провалился.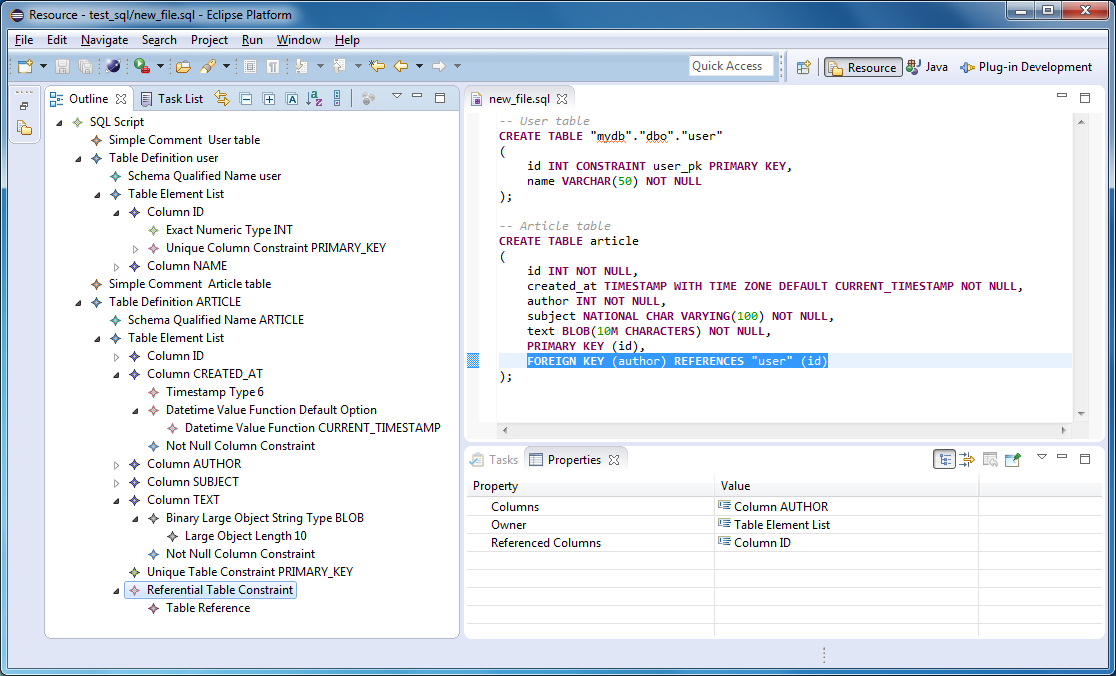 Смотрим отчёт.
Смотрим отчёт.
Понимаем, что именно подозрительная инструкция провалила миграцию.
«А почему так?» №1 – Объяснение.
Тут всё предельно просто. Мы забыли, что проверка условий CHECK CONSTRAINT’а происходит уже после вставки строки в таблицу и в момент вставки первого мужчины в гарем, правильным условием будет равенство единице, а не нулю. В итоге функция была переписана на много проще.
Вычисляемые колонки (Computed column)
В выражении ограничения можно использовать вычисляемые колонки, но только если они физически сохраняются, т.е. у них свойство IsPersited установлено в Yes. На этапе выполнения проверки, все вычисляемые колонки будут иметь правильные значения и если вы обновите значения, от которых зависит вычисляемое значение, то в выражении CHECK CONSTRAINT’а будут переданы уже пересчитанные значения.
Оправдание
Дабы хоть как-то оправдать такую невнимательность скажу, что в нашем случае условия проверки ограничения были на много более витиеватые, и далеко не все были связаны с количеством строк в обновляемой таблице. А данные вставлялись в таблицу только в результате запуска сложного скрипта, разобраться с которым было крайне непросто.
А данные вставлялись в таблицу только в результате запуска сложного скрипта, разобраться с которым было крайне непросто.
«А почему так?» №2 – Объяснение.
Тут всё оказалось не столь прозрачно. Сначала пришлось всё-таки разобраться в истинном назначении упавшей инструкции. И, к превеликому нашему удивлению, мы поняли, что она делает именно то, что сказано в комментарии, а не то, что описано в найденном «полезном» посте (разбор синтаксиса будет ниже).
Узнав это, было логично предположить, что при создании миграционного скрипта была выбрана база, в которой на CK_Persons значение «Check Existing Data On Creation Or Re-Enabling» было “Yes”, а не “No”. Но эта теория провалилась. Меняя это значение и генерируя новый скрипт, стало понятно, что SSDT, вообще игнорируют это значение. Начали грешить на наличие бага в SSDT.
Очередной этап поисков навёл нас на следующий пост, из которого мы уже поняли, что это «фича, а не баг».
Согласно дизайна SSDT, при создании скрипта всегда создаётся ограничение, которое включено, т.е. проверяется для всех будущих INSERT/UPDATE. За это отвечает первая инструкция ALTER в нашем миграционном скрипте.
Вторая же инструкция ALTER (выделена красной рамкой) отвечает за валидацию существующих данных и является опциональной. За то будет ли эта инструкция добавлена в миграционный скрип, отвечает специальная опция генерации скрипта:
Включив её, мы для каждого нового миграционного скрипта активируем валидацию существующих данных, т.е. в него будет вставлена опциональная инструкция (второй ALTER). Иначе, инструкция попросту отсутствует и на существующих данных проверка не выполняется. Как это не прискорбно получается, но SSDT генерирует миграционный скрипт по принципу всё или ничего. Можно либо для всех вновь добавляемых ограничений включить проверку на существующих данных, либо для всех её пропустить. Для более тонкой настройки поведения придётся править скрипт вручную.
Ограничения (Constraints) в MS SQL
Как уже говорилось выше, в данной статье осталось разобраться с премудростями синтаксиса создания и обновления проверочных ограничений. Но прежде чем мы приступим, давайте для полноты картины вспомним немного общей информации об ограничениях в MS SQL Server.
Ограничения – механизм, который позволяет задавать набор правил, направленных на поддержание целостности данных. Правила могут быть заданы как на уровне колонки в таблице, так и на уровне всей таблицы.
MS SQL Server поддерживает следующие виды ограничений:
- NULL / NOT NULL ограничение – задаётся на уровне какого-то столбца и определяет, может ли хранится значение NULL в колонке.
- UNIQUE ограничение – позволяет обеспечить уникальность значений в одном или нескольких столбцах.
- PRIMARY KEY ограничение – практически тоже самое, что и UNIQUE ограничение, но в отличие от него, PRIMARY KEY не позволяет хранить NULL.

- CHECK ограничение – позволяет задать некое логическое условие, которое должно быть истинным (TRUE) при вставке или обновлении данных в таблице. Может быть задано как на уровне одного столбца, так и на уровне таблицы.
- FOREIGN KEY ограничение – позволяет обеспечить ссылочную связность двух таблиц. При вставке значения в колонку (или колонки) с FOREIGN KEY ограничением, будет производится проверка на наличие такого же значения в таблице, на которую указывает FOREIGN KEY. Если значения нет, то обновление или вставка строки завершается с ошибкой. Исключением может быть только значение NULL, если на колонке не задано ограничение NOT NULL. Кроме того, ссылаться можно только на колонку с уникальными значениями, т.е. с UNIQUE или PRIMARY KEY ограничением. Так же можно задать поведение, на случай обновления или удаления строки, в «отцовской» таблице:
- NO ACTION – отцовскую таблицу запрещено менять
- CASCADE – подчинённые строки будут обновлены или удалены, в зависимости от выполняемого действием над отцовской таблицей
- SET NULL – значение в подчинённой таблице будет установлено в NULL
- SET DEFAULT — значение в подчинённой таблице будет установлено в значение по умолчанию.


Теперь немного подробней о CHECK CONSTRAINT’ах. Рассмотрим ограничение, которое было упомянуто выше. Ниже представлено окно свойств этого ограничения в Management Studio:
Основными свойствами являются:
- Expression – любое допустимое T-SQL выражение в котором можно ссылаться на значения в проверяемой строке по имени столбцов
- Name – имя, уникально идентифицирующее ограничение в пределах базы данных
- Check Existing Data On Creation Or Re-Enabling – если ограничение создаётся на уже существующей таблице, то это значение “No” позволяет не пропустить валидацию существующих строк; в виду того, что существующую проверку можно временно выключить, то данное свойство так же определяет будет ли проводиться валидация имеющихся строк при включении ограничения.
- Enforce For INSERTs And UPDATEs – включает (Yes) или выключает (No) ограничение
- Enforce For Replication – позволяет пропустить проверку при вставке или обновлении строк агентом репликации
Вся эта информация доступна нам так же из системного представления (view) sys.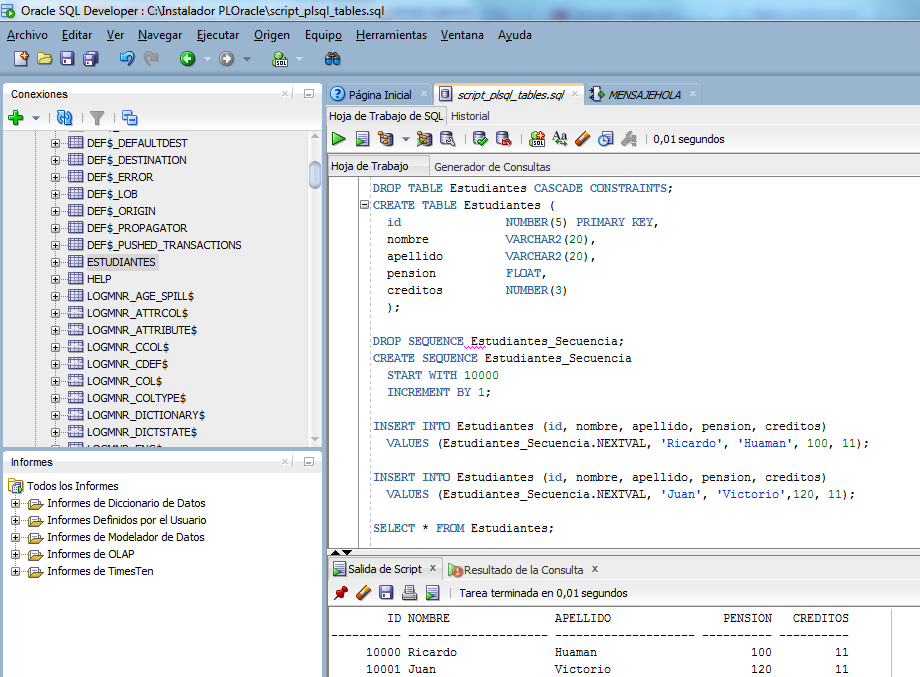 check_constraints. Оно содержит по одной строке для каждого CHECK CONSTRAINT в базе данных. Мы его иногда используем в миграционных скриптах, когда нужно убедится в существовании или в отсутствии какого-либо ограничения.
check_constraints. Оно содержит по одной строке для каждого CHECK CONSTRAINT в базе данных. Мы его иногда используем в миграционных скриптах, когда нужно убедится в существовании или в отсутствии какого-либо ограничения.
Примеры использования sys.check_constraints
Sql
DECLARE @name NVARCHAR(128) = 'CK_Persons' SELECT CASE [is_not_trusted] WHEN 1 THEN 'No' ELSE 'Yes' END AS [Check Existing Data], CASE [is_disabled] WHEN 1 THEN 'No' ELSE 'Yes' END AS [Enabled], CASE [is_not_for_replication] WHEN 1 THEN 'NO' ELSE 'YES' END AS [Enforce For Replication] FROM [sys].[check_constraints] WHERE name = @name
Можно получить ответ в более привычном формате, воспользовавшись оператором UNPIVOT:
Sql
DECLARE @name NVARCHAR(128) = 'CK_Persons' SELECT [Properties], [Values] FROM (SELECT CAST([definition] AS VARCHAR(MAX)) AS [Expression], CAST(CASE [is_not_trusted] WHEN 1 THEN 'No' ELSE 'Yes' END AS VARCHAR(MAX)) AS [Check Existing Data On Creation Or Re-Enabling], CAST(CASE [is_disabled] WHEN 1 THEN 'No' ELSE 'Yes' END AS VARCHAR(MAX)) AS [Enforce For INSERTs And UPDATEs], CAST(CASE [is_not_for_replication] WHEN 1 THEN 'NO' ELSE 'YES' END AS VARCHAR(MAX)) AS [Enforce For Replication], CAST([create_date] AS VARCHAR(MAX)) as [Created], CAST([modify_date] AS VARCHAR(MAX)) as [Modified] FROM [sys].
 [check_constraints]
WHERE name = @name) p
UNPIVOT
(
[Values] FOR [Properties]
IN (
[Expression],
[Check Existing Data On Creation Or Re-Enabling] ,
[Enforce For INSERTs And UPDATEs],
[Enforce For Replication],
[Created],
[Modified]
)
) AS unpvt;
[check_constraints]
WHERE name = @name) p
UNPIVOT
(
[Values] FOR [Properties]
IN (
[Expression],
[Check Existing Data On Creation Or Re-Enabling] ,
[Enforce For INSERTs And UPDATEs],
[Enforce For Replication],
[Created],
[Modified]
)
) AS unpvt;
Особенности работы CHECK CONSTRAINT:
- Срабатывает только при INSERT и UPDATE операциях, при выполнении DELETE условие не проверяется
- Если проверочное условие равно NULL, то считается, что CHECK CONSTRAINT не нарушен
Синтаксис CHECK CONSTRAINT
У проверочного ограничения есть ряд свойств, которые необходимо задать при создании. Некоторые из них можно задать только при создании, а некоторые доступны для изменения, только на уже созданном ограничении. В таблице ниже отображены эти особенности.
| “…ADD CONSTRAINT…” (создание) | “ALTER…CONSTRAINT…” (изменение) | |
|---|---|---|
| Name | + | — |
| Expression | + | — |
| Check Existing Data On Creation Or Re-Enabling | + | + |
| Enforce For INSERTs And UPDATEs | — | + |
| Enforce For Replication | + | — |
Добавление нового CHECK CONSTRAINT
Основы синтаксиса шаблонов T-SQL
- В квадратных скобках «[ ]» – указываются опциональные конструкции и могут быть опущены из конечного выражения
- В фигурных скобках «{ }» — указывается список возможных конструкций, из которых необходимо выбрать одну
- Вертикальная черта «|» — отделяет элементы в фигурных скобках, среди которых необходимо выбрать единственный элемент
Опциональные секции:
- [ WITH { CHECK | NOCHECK } ] – в случае отсутствия применяется значение WITH CHECK
- [ NOT FOR REPLICATION ] – если конструкция указана, то ограничение не проверяется при вставке или обновлении данных в момент репликации; если конструкция пропущена –ограничение проверяется.

Примечание: шаблон приведён для случая создания ограничения на существующей таблице. Также можно создать ограничение в момент создания таблицы, тогда команда будет начинаться со слова CREATE и до слова WITH будет идти описание колонок таблицы.
Примеры:
Таблица для примеров
Примеры команд будут приведены для простейшей таблицы Employees, которая выглядит следующим образом:
Изменение существующего CHECK CONSTRAINT
Для обновления существующего проверочного ограничения используется конструкция ALTER TABLE. Для изменения доступны только следующие свойства:
- Check Existing Data On Creation Or Re-Enabling
- Enforce For INSERTs And UPDATEs
Опциональные секции:
- [ WITH { CHECK | NOCHECK } ] – в случае отсутствия применяется значение WITH NOCHECK
- [, …n] – позволяет задать имя более чем одного ограничения, к которым будут применены изменения; использование слова ALL изменения применятся ко всем проверочным ограничениям на таблице
Примечание 1: хоть имя и нельзя переименовать при помощи синтаксиса ALTER TABLE, это всё же возможно сделать, используя системную хранимую процедуру sp_rename.
Примечание 2: при необходимости изменить свойства «Expression» или «Enforce For Replication», необходимо сначала удалить существующее ограничение, а потом заново его создать с нужными значениями этих свойств.
Примеры:
Недокументированное поведение
Есть ряд случаев, когда выполнение команд приводит к неожиданным результатам. Причём я не смог найти объяснение на сайте msdn.
Что бы это увидеть, необходимо рассмотреть все возможные комбинации состояний в сочетании со всеми возможными вариантами команд. Тогда будет видно, что в 5-ти случаях получаемое значение свойства «Check Existing Data» не соответствует ожиданиям.
| Состояние до выполнения команды | T-SQL команда | Состояние после выполнения команды | ||
|---|---|---|---|---|
| Check Existing Data | Enforce For INSERTs And UPDATEs | Check Existing Data | Enforce For INSERTs And UPDATEs | |
| No | No | NOCHECK | No | No |
| No | Yes | NOCHECK | No | No |
| Yes | Yes | NOCHECK | No | No |
| No | No | CHECK | No | Yes |
| No | Yes | CHECK | No | Yes |
| Yes | Yes | CHECK | Yes* | Yes |
| No | No | WITH NOCHECK NOCHECK | No | No |
| No | Yes | WITH NOCHECK NOCHECK | No | No |
| Yes | Yes | WITH NOCHECK NOCHECK | No | No |
| No | No | WITH NOCHECK CHECK | No | Yes |
| No | Yes | WITH NOCHECK CHECK | No | Yes |
| Yes | Yes | WITH NOCHECK CHECK | Yes* | Yes |
| No | No | WITH CHECK NOCHECK | No** | No |
| No | Yes | WITH CHECK NOCHECK | No** | No |
| Yes | Yes | WITH CHECK NOCHECK | No** | No |
| No | No | WITH CHECK CHECK | Yes | Yes |
| No | Yes | WITH CHECK CHECK | Yes | Yes |
| Yes | Yes | WITH CHECK CHECK | Yes | Yes |
(*) Значение свойства «Check Existing Data» может быть переведено из значения «Yes» в значение «No», только если текущее значение свойства «Enforce For INSERTs And UPDATEs» отличается от заданного в команде.
(**) «Check Existing Data» может быть «Yes», только если ограничение включено (Enforce For INSERTs And UPDATEs = “Yes”). Т. е. в команде WITH CHECK NOCHECK часть WITH CHECK будет проигнорирована и «Check Existing Data» не будет установлено в «Yes». Это так же объясняет почему в качестве начальных состояний есть только 3 варианта для каждой команды (а не 4).
Удаление существующего CHECK CONSTRAINT
Команда очень проста и не требует дополнительных объяснений. Ещё шаблон:
Заключение
Искренне надеюсь, что после прочтения данной статьи, вы не пройдётесь по граблям, набившие нам пару неприятных шишек. А так же вы сможете комфортно создавать и поддерживать миграционные скрипты, в которых есть логика по работе с CHECK CONSTRAINT. Удачи!
Инструкция CREATE TABLE (Transact-SQL)
Default – задает значение по умолчанию для
входных параметров.
OUTPUT – ключевое слово, которое определяет, что
данный параметр является выходным.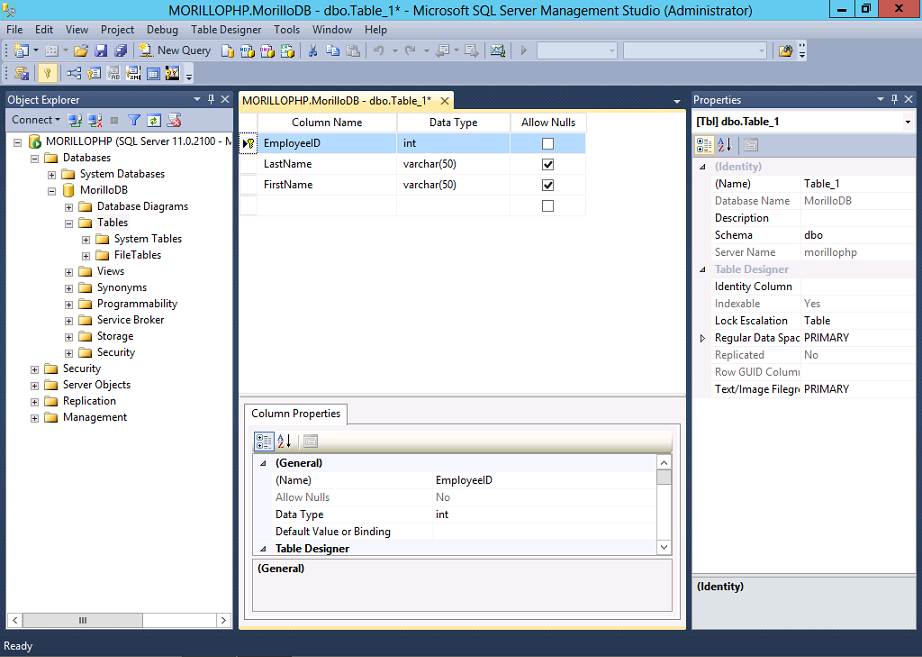 Параметр, описанный этим словом возвращает
Параметр, описанный этим словом возвращает
информацию при выполнении хранимой процедуры (выполнении оператора execute).
{RECOMPILE | ENCRYPTION | RECOMPILE, ENCRYPTION}
RECOMPILE – ключевое слово, которое заставляет SQL Server каждый
раз при вызове данной хранимой процедуры на исполнение заново ее перекомпилировать
и строить новый план исполнения.
ENCRYPTION – ключевое
слово, которое обеспечивает кодирование текста хранимой процедуры и он
становится недоступным другим пользователям системы.
Надо помнить, что при восстановлении БД после
сбоев требуется заново компилировать тексты хранимых процедур.
FOR REPLICATION
– ключевое слово, которое определяет, что данная процедура будет использована
при репликации. Существует специальный режим репликации, которые позволяет не
пересылать данные по сети, а послать процедуру, которая в результате своего
выполнения сгенерирует новые данные. Этот режим не может быть использован совместно
с опцией RECOMPILE (перекомпиляции).
AS – ключевое слово, после которого идет собственно
текст процедуры.
Создание триггера
CREATE TRIGGER trigger_name
ON { table | view }
[ WITH ENCRYPTION ]
{
{ { FOR | AFTER | INSTEAD OF } { [
INSERT ] [ , ] [ UPDATE ] }
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
AS
[ { IF UPDATE ( column
)
[ { AND
| OR } UPDATE ( column ) ]
[
…n ]
| IF ( COLUMNS_UPDATED (
) { bitwise_operator } updated_bitmask )
{
comparison_operator } column_bitmask [ …n ]
} ]
sql_statement […n
]
}
}
Описание
аргументов:
INSTEAD OF
– определяет триггер, который запускается вместо операции его вызвавшей. Этот
тип триггера имитирует работу стандартных триггеров типа Befor (предшествующих событию.)
Триггер типа INSTEAD OF для операций INSERT,
UPDATE или DELETE может быть задан как для таблицы так и для представления. Возможно
Возможно
даже определить триггеры для представления, которое само было создано на базе
представления, и при этом у каждого будут свои собственные триггеры.
INSTEAD OF триггеры не поддерживают
обновление представлений с WITH CHECK OPTION.
Для триггеров типа INSTEAD OF операция
DELETE не поддерживается для таблиц, которые связаны ссылочной
целостностью с установленным свойством каскадирования при удалении (cascade action ON DELETE). Аналогично, для операций UPDATE
не поддерживается создание триггеров данного типа для таблиц, где задана
каскадная операция обновления ( cascade action ON UPDATE).
Для описания внешних моделей в
реляционной модели могут использоваться представление. Представление (View) – это SQL-запрос на выборку,
который пользователь воспринимает как некоторое виртуальное отношение.
Создание представления:
CREATEVIEW <имя представления>
[ (<список
столбцов>)] AS <SQL-запрос>
Представления могут использоваться
для выполнения операций манипулирования данными над реальными таблицами, однако
в этом случае не допустимо использовать в представлении операции группировки,
упорядочения и агрегатные функции.
Оператор изменения структуры таблицы
ALTER TABLE table
{ [ ALTER COLUMN column_name — изменить описание
столбца
{ new_data_type [ (
precision [ , scale ] ) ]
[ COLLATE < collation_name
> ] — указывает новое сопоставление для столбцов
[ NULL | NOT NULL ]
| {ADD | DROP } ROWGUIDCOL } —
предписывает установить или удалить
] столбецсуникальнымидентификатором
|
ADD — добавить
новый столбец
{ [
< column_definition > ]
| column_name AS computed_column_expression
} [ ,…n ]
| [ WITH CHECK | WITH NOCHECK ] ADD
{ < table_constraint > }
[ ,…n ]
| DROP —
удалить
{ [
CONSTRAINT ] constraint_name — удалить ограничение
|
COLUMN column } [ ,.![]() ..n ] — удалить
..n ] — удалить
столбец
| { CHECK | NOCHECK }
CONSTRAINT — обеспечить или отменить проверку
{ ALL | constraint_name [
,…n ] }
| { ENABLE | DISABLE } TRIGGER — разрешить
или запретить выполнение триггера
{ ALL | trigger_name [ ,…n
] }
}
Удаление объектов
Удаление таблиц
Drop table
<имя таблицы>
Операция удаления таблицы не |
Как создать временную таблицу в SQL Server — данные для сбора данных
Вот два подхода к созданию временной таблицы в SQL Server:
(1) Подход SELECT INTO :
SELECT column_1, column_2, column_3, .
 ..
INTO #name_of_temp_table
ОТ имя_таблицы
ГДЕ условие
..
INTO #name_of_temp_table
ОТ имя_таблицы
ГДЕ условие
(2) Подход CREATE TABLE :
CREATE TABLE #name_of_temp_table (
тип данных столбец_1,
тип данных column_2,
тип данных столбец_3,
.
.
столбец_n тип данных
)
Обратите внимание, что после того, как вы создали таблицу в соответствии со вторым подходом, вам нужно будет вставить записи в таблицу, используя запрос INSERT INTO :
INSERT INTO #name_of_temp_table (column_1, column_2, column_3,...) ВЫБЕРИТЕ столбец_1, столбец_2, столбец_3,... ОТ имя_таблицы ГДЕ условие
При обоих подходах перед именем временной таблицы необходимо включить символ решетки (#).
Вы можете удалить временную таблицу, используя DROP TABLE запрос (или просто закрыв соединение, которое использовалось для создания временной таблицы):
DROP TABLE #name_of_temp_table
В следующем разделе вы увидите, как создать временную таблицу в SQL Server, используя два описанных выше подхода.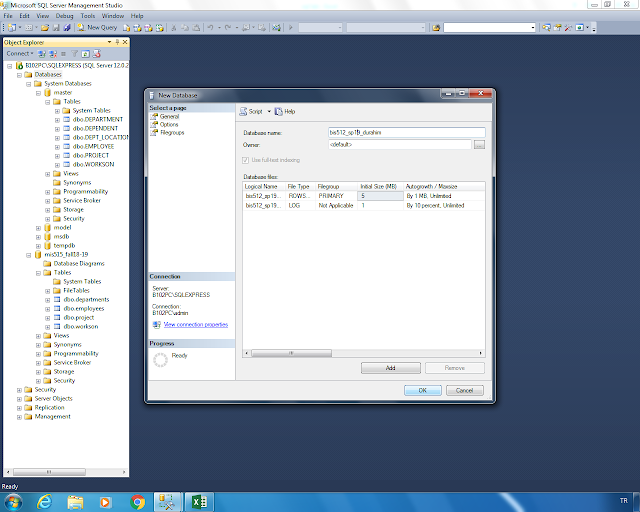 Вы также узнаете, как создать глобальную временную таблицу .
Вы также узнаете, как создать глобальную временную таблицу .
(1) Создание временной таблицы в SQL Server с использованием подхода SELECT INTO
В приведенном ниже примере показано, как создать временную таблицу из существующей таблицы с именем 9.0005 продукты .
Текущая таблица «products» содержит следующие столбцы и данные:
| product_id | имя_продукта | цена |
| 1 | Ноутбук | 1200 |
| 2 | Принтер | 200 |
| 3 | Планшет | 350 |
| 4 | Клавиатура | 80 |
| 5 | Монитор | 400 |
Конечной целью является создание временной таблицы (из таблицы «продукты») для всех записей , где цена больше 300.
Затем вы можете создать временную таблицу (называемую #products_temp_table ) с использованием подхода SELECT INTO :
SELECT product_id, product_name, price INTO #products_temp_table ИЗ продуктов ГДЕ цена > 300
После выполнения запроса вы заметите, что затронуты 3 строки:
(затронуты 3 строки)
Вы можете проверить содержимое временной таблицы, выполнив следующий запрос SELECT:
SELECT * FROM #products_temp_table
Как видите, сейчас в таблице есть 3 строки, где цена больше 300:
| product_id | имя_продукта | цена |
| 1 | Ноутбук | 1200 |
| 3 | Планшет | 350 |
| 5 | Монитор | 400 |
Вы можете удалить временную таблицу с помощью запроса DROP TABLE:
DROP TABLE #products_temp_table
После удаления таблицы попробуйте снова выполнить запрос SELECT:
SELECT * FROM #products_temp_table
Обратите внимание, что таблицы больше не существует:
Сообщение 208, уровень 16, состояние 0, строка 1 Недопустимое имя объекта '#products_temp_table'.

(2) Создание временной таблицы в SQL Server с использованием подхода CREATE TABLE
Давайте воссоздадим временную таблицу, используя второй подход CREATE TABLE :
CREATE TABLE #products_temp_table ( product_id int первичный ключ, product_name nvarchar(50), цена инт )
После того, как вы создали временную таблицу, вам нужно будет вставить записи в таблицу, используя ВСТАВИТЬ В запрос:
ВСТАВИТЬ В #products_temp_table (product_id, product_name, price) ВЫБЕРИТЕ product_id, product_name, цена ИЗ продуктов ГДЕ цена > 300
Вы заметите, что были затронуты 3 записи:
(затронуты 3 строки)
Повторно запустите запрос SELECT, чтобы проверить содержимое таблицы:
SELECT * FROM #products_temp_table
Как видите, есть 3 записи, где цена больше 300:
| product_id | имя_продукта | цена |
| 1 | Ноутбук | 1200 |
| 3 | Планшет | 350 |
| 5 | Монитор | 400 |
Чтобы удалить таблицу, используйте:
DROP TABLE #products_temp_table
Создание глобальной временной таблицы в SQL Server
Вы также можете создать глобальную временную таблицу, поместив двойную решетку (##) перед именем временной таблицы.
Глобальная временная таблица будет доступна через различные соединения.
Вот запрос для создания глобальной временной таблицы с использованием подхода SELECT INTO:
SELECT product_id, product_name, price INTO ##products_temp_table ИЗ продуктов ГДЕ цена > 300
Будут затронуты 3 записи:
(затронуты 3 строки)
Затем вы можете запустить следующий запрос SELECT:
SELECT * FROM ##products_temp_table
Вы получите те же 3 записи, где цена больше 300:
| product_id | имя_продукта | цена |
| 1 | Ноутбук | 1200 |
| 3 | Планшет | 350 |
| 5 | Монитор | 400 |
Чтобы удалить таблицу, используйте:
DROP TABLE ##products_temp_table
Дополнительно можно использовать подход CREATE TABLE для создания глобальной временной таблицы:
CREATE TABLE ##products_temp_table ( product_id int первичный ключ, product_name nvarchar(50), цена инт )
Затем выполните запрос INSERT INTO, чтобы вставить записи в таблицу:
ВСТАВИТЬ В ##products_temp_table (product_id, product_name, цена) ВЫБЕРИТЕ product_id, product_name, цена ИЗ продуктов ГДЕ цена > 300
3 записи будут вставлены в таблицу.
Повторите запрос SELECT:
SELECT * FROM ##products_temp_table
Как и прежде, вы увидите 3 записи, в которых цена больше 300:
| product_id | имя_продукта | цена |
| 1 | Ноутбук | 1200 |
| 3 | Планшет | 350 |
| 5 | Монитор | 400 |
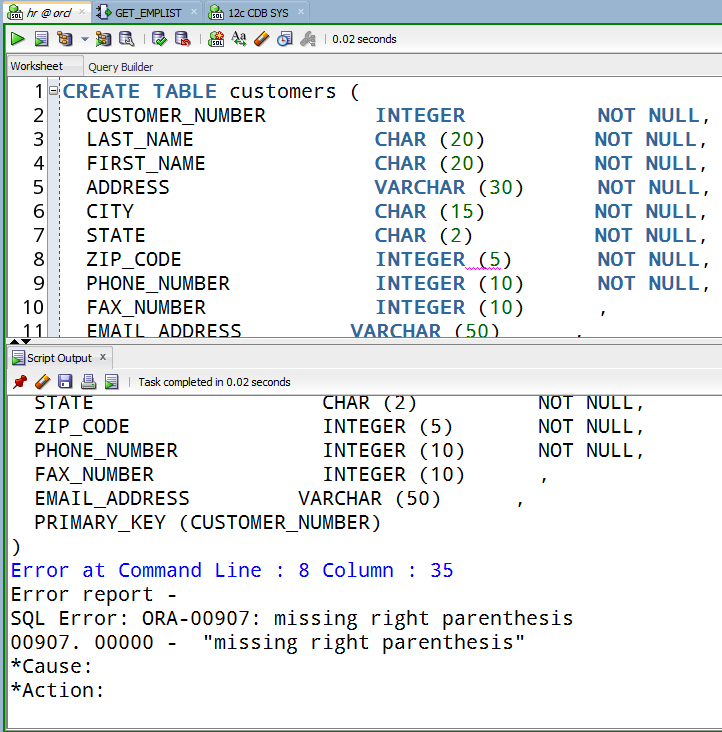
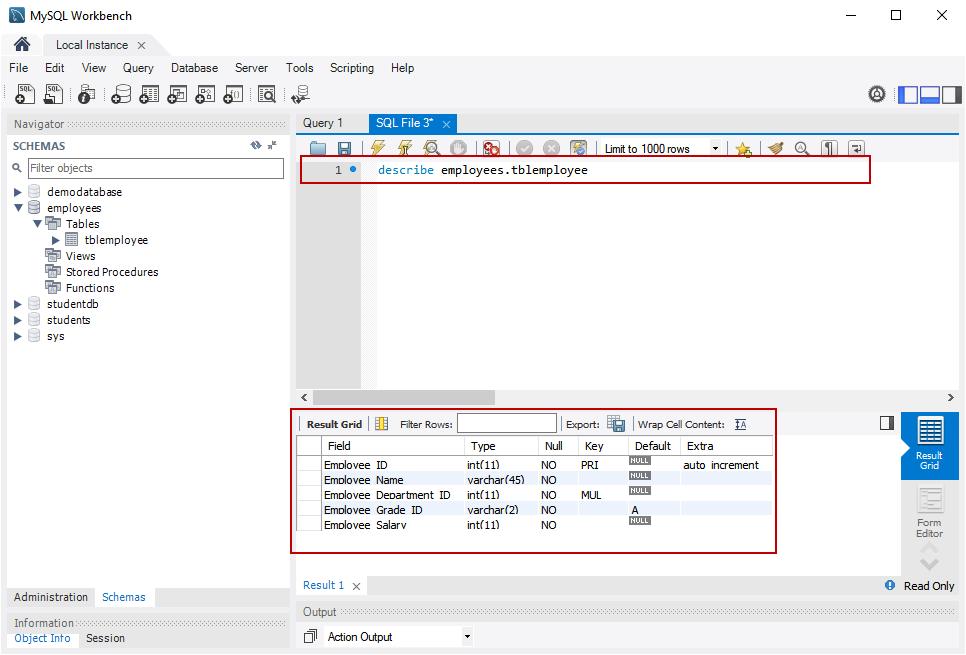
Создать таблицу DDL через TSQL – SQLServerCentral
Все заметили это: не существует простого способа получить определение таблицы через TSQL. Вы можете использовать sp_helptext для процедур/функций/представлений, но что делать, если вам нужно определение таблицы в TSQL?
В середине процедуры или в любом месте кода TSQL нет простой утилиты для определения таблицы. Да, есть пластыри и обходные пути, но ничего для простого встроенного SQL. Поскольку существует набор инструментов, таких как SMO и другие, и вы можете вызывать THAT из TSQL, никто на самом деле не прилагает усилий, чтобы выполнить черновую работу, чтобы получить определение таблицы через TSQL.
Дело в том, что иногда вам нужно это определение в TSQL. Может быть, вы хотите перебрать все таблицы, чтобы вставить их DDL в таблицу, или сгенерировать файл, или, может быть, вы хотите, чтобы этот DDL находился в середине триггера аудита. Есть много причин, почему вы можете этого хотеть.
Я составил хранимую процедуру, которая возвращает инструкцию CREATE TABLE через TSQL; возможно, это один из самых полезных фрагментов кода, которые я когда-либо писал, потому что он действительно познакомил меня с метаданными SQL Server.
Эта первая из моих статей познакомит вас с моей процедурой sp_GETDDL и расскажет, что она делает и чего она не делает. Результат процедуры основан на моих личных вкусах… вы можете адаптировать ее к вашим собственным требованиям . В последующих статьях будут показаны другие способы его использования, например, как использовать его для аудита изменений DDL.
Эта версия процедуры sp_GetDDL принимает один параметр — имя таблицы. Его цель состояла в том, чтобы создать хорошо отформатированный стандартизированный DDL таблицы для удобочитаемости и сравнения.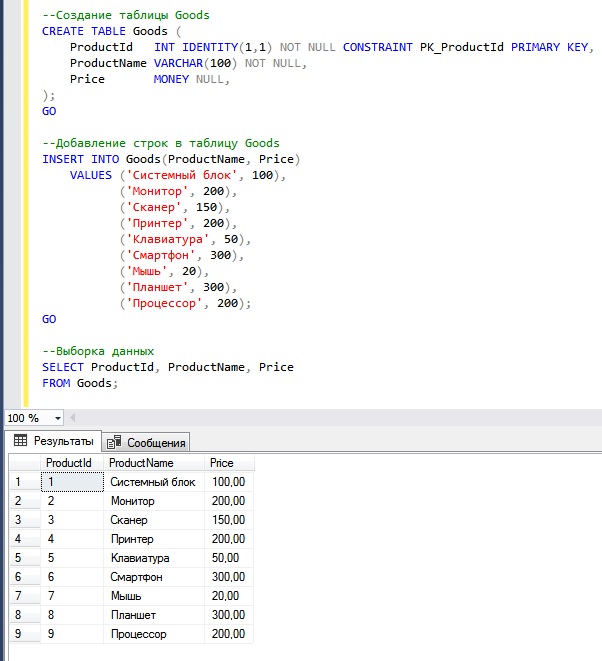 Я работаю в магазине с большим количеством разработчиков, и каждый разработчик использует разные стили определения таблиц. Поскольку я организую многие окончательные сценарии, пока разработчик создает свои объекты, я бы использовал эту процедуру для окончательного сценария.
Я работаю в магазине с большим количеством разработчиков, и каждый разработчик использует разные стили определения таблиц. Поскольку я организую многие окончательные сценарии, пока разработчик создает свои объекты, я бы использовал эту процедуру для окончательного сценария.
Вызвать очень просто, и имя схемы указывать необязательно.
EXEC sp_GetDDL YourTableName или EXEC sp_GetDDL 'bobsschema.YourTableName'
Возвращает одно поле, varchar(max) с определением таблиц. Он достаточно прост в использовании и, надеюсь, несколько удобочитаем, когда вы смотрите на саму процедуру.
Вот результаты простой таблицы:
CREATE TABLE [TBSTATE] ( [STATETBLKEY] INT NOT NULL, [КОД СОСТОЯНИЯ] CHAR (2) НЕ NULL, [STATENAME] VARCHAR (50) НЕ NULL, [FIPS] СИМВОЛ (3) NULL, ОГРАНИЧЕНИЕ [PK__TBSTATE__17A421EC] ПЕРВИЧНЫЙ КЛЮЧ ([STATETBLKEY]), ОГРАНИЧЕНИЕ STATECODEUNIQUE UNIQUE NONCLUSTERED(STATECODE)) Я упомянул, что он был построен в соответствии с моими требованиями, предпочтениями и антипатиями.
 Вот что делает процедура:
Вот что делает процедура: Я упомянул, что он был построен в соответствии с моими требованиями, предпочтениями и антипатиями. Вот что делает процедура:
- возвращает [имя схемы].[имя таблицы], по умолчанию используется dbo, если не указано иное.
- Имена таблиц и столбцов начинаются с верхнего регистра.
- столбцы выровнены для удобства чтения
- вычисляемые столбцы включены правильно.
- идентификатор с его начальным значением и приращением являются частью определения столбца
- значения по умолчанию соответствуют столбцу, для которого они установлены по умолчанию.
- Индексы PK и Уникальные индексы именуются и добавляются в конец скрипта таблицы.
- внешние ключи безымянные и добавляются в конец скрипта таблицы.
- любые другие индексы в таблице добавляются ПОСЛЕ сценария DDL.
- Создание правила и назначение столбцу добавляются ПОСЛЕ сценария DDL.
- все триггеры заскриптованы и добавляются ПОСЛЕ DDL-скрипта.
Не менее важно, что процедура не делает:
- не касается настроек ANSI, даже если столбец был создан с другими настройками.
- не беспокоится об операторах сопоставления, которые также очень легко добавить.
- не волнует, к какой файловой группе принадлежит таблица.
- тоже не парится с разделами.
Давайте на самом деле создадим довольно сложную тестовую таблицу со всеми функциями, которые мы хотели бы протестировать: скопируйте этот код для тестирования. В этой таблице есть все, что я мог придумать, что может нарушить сценарий таблицы:
CREATE RULE range_rule КАК @range>= $1000 И @range <$20000; ИДТИ CREATE TABLE WHATEVERREF(WHATEVERREFID INT IDENTITY(2,5) NOT NULL PRIMARY KEY, ОПИСАНИЕ VARCHAR(30) ) УДАЛИТЬ ТАБЛИЦУ СОЗДАЙТЕ ТАБЛИЦУ ( WHATEVERID INT IDENTITY(2,5) NOT NULL PRIMARY KEY, ОПИСАНИЕ VARCHAR(30) УНИКАЛЬНЫЙ, мой varbinary VARBINARY, mybinary БИНАРНЫЙ ПО УМОЛЧАНИЮ 42, мое изображение ИЗОБРАЖЕНИЕ, мойварчар ВАРЧАР, mymaxvarchar VARCHAR(MAX), mychar CHAR ПО УМОЛЧАНИЮ 'Y', мынварчар НВАРЧАР, мынчар НЧАР, мой текст ТЕКСТ, мой текст NTEXT, мой уникальный идентификатор UNIQUEIDENTIFIER, версия строки, мой бит бит, митиньинт тиниинт, мисмаллинт малинт, myint INT REFERENCES WHATEVERREF(WHATEVERREFID), мойбигинт, мои маленькие деньги маленькие деньги, мои деньги деньги, мой числовой номер, mydecimal DECIMAL NOT NULL ПО УМОЛЧАНИЮ 0, мой реал, мой поплавок ПОПЛАВОК, мое маленькое время даты и времени, ДАТАВРЕМЯ ДАТАВРЕМЯ, myCalculatedColumn КАК СЛУЧАЙ, КОГДА mydatetime < GETDATE() THEN 'Действителен' ELSE 'EXPIRED' END, вариант mysql SQL_VARIANT, xml XML ) CREATE INDEX IX_WHATEVER ON WHATEVER (mydatetime, myvarchar) СОЗДАТЬ ИНДЕКС IX_ANOTHERWHATEVER ON WHATEVER (mytinyint, myvarchar) --теперь привязать столбец к правилу EXEC sp_bindrule 'range_rule', 'WHATEVER.
 mymoney'
ВСТАВЬТЕ ВО ВСЁ (ОПИСАНИЕ)
ВЫБЕРИТЕ СОЮЗ «ЯБЛОКИ»
ВЫБЕРИТЕ СОЮЗ «АПЕЛЬСИНЫ»
ВЫБЕРИТЕ СОЮЗ «БАНАНЫ»
ВЫБЕРИТЕ СОЮЗ «ВИНОГРАД»
ВЫБЕРИТЕ СОЮЗ «ВИШНИ»
ВЫБЕРИТЕ 'КИВИ'
ИЗМЕНИТЬ ТАБЛИЦУ, НЕОБХОДИМО ДОБАВИТЬ INSERTDT DATETIME DEFAULT GETDATE() СО ЗНАЧЕНИЯМИ,
UPDATEDDT ДАТАВРЕМЯ ПО УМОЛЧАНИЮ GETDATE() СО ЗНАЧЕНИЯМИ
ВЫБЕРИТЕ * ИЗ НИЧЕГО
ИДТИ
СОЗДАТЬ ТРИГГЕР TR_WHATEVER
НА ЧЕМ
ДЛЯ ВСТАВКИ, ОБНОВЛЕНИЯ
КАК
ОБНОВЛЯЙТЕ ВСЁ
УСТАНОВИТЬ ОБНОВЛЕНИЕ = ПОЛУЧИТЬ ДАТУ ()
ИЗ ВСТАВЛЕННОГО
ГДЕ ЧТО-ТО.WHATEVERID=INSERTED.WHATEVERID
Вот пример вывода хранимой процедуры сложной таблицы.
mymoney'
ВСТАВЬТЕ ВО ВСЁ (ОПИСАНИЕ)
ВЫБЕРИТЕ СОЮЗ «ЯБЛОКИ»
ВЫБЕРИТЕ СОЮЗ «АПЕЛЬСИНЫ»
ВЫБЕРИТЕ СОЮЗ «БАНАНЫ»
ВЫБЕРИТЕ СОЮЗ «ВИНОГРАД»
ВЫБЕРИТЕ СОЮЗ «ВИШНИ»
ВЫБЕРИТЕ 'КИВИ'
ИЗМЕНИТЬ ТАБЛИЦУ, НЕОБХОДИМО ДОБАВИТЬ INSERTDT DATETIME DEFAULT GETDATE() СО ЗНАЧЕНИЯМИ,
UPDATEDDT ДАТАВРЕМЯ ПО УМОЛЧАНИЮ GETDATE() СО ЗНАЧЕНИЯМИ
ВЫБЕРИТЕ * ИЗ НИЧЕГО
ИДТИ
СОЗДАТЬ ТРИГГЕР TR_WHATEVER
НА ЧЕМ
ДЛЯ ВСТАВКИ, ОБНОВЛЕНИЯ
КАК
ОБНОВЛЯЙТЕ ВСЁ
УСТАНОВИТЬ ОБНОВЛЕНИЕ = ПОЛУЧИТЬ ДАТУ ()
ИЗ ВСТАВЛЕННОГО
ГДЕ ЧТО-ТО.WHATEVERID=INSERTED.WHATEVERID
Вот пример вывода хранимой процедуры сложной таблицы. Вот пример вывода хранимой процедуры сложной таблицы.
СОЗДАТЬ ТАБЛИЦУ [НЕОБХОДИМО] (
[WHATEVERID] INT IDENTITY(3,5) NOT NULL,
[ОПИСАНИЕ] VARCHAR(30) NULL,
[MYVARBINARY] VARBINARY NULL,
[MYBINARY] ДВОИЧНЫЙ NULL ПО УМОЛЧАНИЮ ((42)),
[MYIMAGE] НУЛЕВОЕ ИЗОБРАЖЕНИЕ,
[MYVARCHAR] VARCHAR(1) NULL,
[MYMAXVARCHAR] VARCHAR(MAX) NULL,
[MYCHAR] CHAR(1) NULL ПО УМОЛЧАНИЮ ("Y"),
[MYNVARCHAR] NVARCHAR(1) NULL,
[MYNCHAR] NCHAR(1) NULL,
[MYTEXT] ТЕКСТ НУЛЬ,
[MYNTEXT] NTEXT NULL,
[MYUNIQUEIDENTIFIER] UNIQUEIDENTIFIER NULL,
[MYROWVERSION] TIMESTAMP НЕ NULL,
[MYBIT] БИТ НОЛЬ,
[MYTINYINT] TINYINT NULL,
[MYSMALLINT] SMALLINT NULL,
[MYINT] INT NULL,
[MYBIGINT] БОЛЬШОЙ NULL,
[MYSMALLMONEY] SMALLMONEY NULL,
[МОИ ДЕНЬГИ] ДЕНЬГИ НОЛЬ,
[MYNUMERIC] ЦИФРОВОЙ(18,0) NULL,
[MYDECIMAL] DECIMAL(18,0) NOT NULL ПО УМОЛЧАНИЮ ((0)),
[МИРЕАЛЬНЫЙ] РЕАЛЬНЫЙ (24) НУЛЬ,
[MYFLOAT] FLOAT NULL,
[MYSMALLDATETIME] SMALLDATETIME NULL,
[MYDATETIME] DATETIME NULL,
[MYCALCULATEDCOLUMN] КАК (СЛУЧАЙ, КОГДА [MYDATETIME]= 1000 долларов США И @диапазон <20000 долларов США;
EXEC sp_binderule range_rule, '[WHATEVER]. [UPDATEDDT]'
ИДТИ
СОЗДАТЬ ТРИГГЕР TR_WHATEVER
НА ЧЕМ
ДЛЯ ВСТАВКИ, ОБНОВЛЕНИЯ
КАК
ОБНОВЛЯЙТЕ ВСЁ
УСТАНОВИТЬ ОБНОВЛЕНИЕ = ПОЛУЧИТЬ ДАТУ ()
ИЗ ВСТАВЛЕННОГО
ГДЕ ЧТО-ТО.WHATEVERID=INSERTED.WHATEVERID
ИДТИ
 [UPDATEDDT]'
ИДТИ
СОЗДАТЬ ТРИГГЕР TR_WHATEVER
НА ЧЕМ
ДЛЯ ВСТАВКИ, ОБНОВЛЕНИЯ
КАК
ОБНОВЛЯЙТЕ ВСЁ
УСТАНОВИТЬ ОБНОВЛЕНИЕ = ПОЛУЧИТЬ ДАТУ ()
ИЗ ВСТАВЛЕННОГО
ГДЕ ЧТО-ТО.WHATEVERID=INSERTED.WHATEVERID
ИДТИ
[UPDATEDDT]'
ИДТИ
СОЗДАТЬ ТРИГГЕР TR_WHATEVER
НА ЧЕМ
ДЛЯ ВСТАВКИ, ОБНОВЛЕНИЯ
КАК
ОБНОВЛЯЙТЕ ВСЁ
УСТАНОВИТЬ ОБНОВЛЕНИЕ = ПОЛУЧИТЬ ДАТУ ()
ИЗ ВСТАВЛЕННОГО
ГДЕ ЧТО-ТО.WHATEVERID=INSERTED.WHATEVERID
ИДТИ
Надеюсь, вы видите, что большое внимание было уделено тому, чтобы сделать вывод удобочитаемым и хорошо отформатированным, но следует также отметить сложность вывода… все это есть. Использование этой процедуры для создания скриптов обеспечивает единообразное форматирование выходных данных.
Я не говорю, что это лучший способ получить определение таблицы через TSQL. Это просто мой путь, и единственный, который я знаю, который доступен сообществу. Кроме того, это работает довольно хорошо. Если вы хотите подробно изучить код, мы можем заняться этим в сообщении на форуме, связанном с этой статьей.
Есть много разных способов сделать это или улучшить эту идею. Эта процедура возникла в SQL 2000, поэтому она использует курсоры и будет давать усеченную информацию в SQL 2000 для больших таблиц из-за максимума varchar(8000).
Единственное, о чем я прошу, это если вы адаптируете мою процедуру или улучшите ее, просто пришлите мне ее копию на scripts *at* stormrage.com, чтобы я мог учиться на ваших улучшениях. Ваша обратная связь будет полезной для меня и будет передана сообществу SQL. Черт возьми, я сейчас работаю над улучшенной версией. Есть разделы, в которых курсоры можно заменить итоговыми таблицами, дополнительные вызовы, которые можно отбросить, просто присоединив системные столбцы к системным комментариям, и многое другое.
Если вы поместите эту процедуру в master, вы сможете вызывать ее из любой базы данных. если вы используете версию функции, функция должна быть создана в каждой используемой вами базе данных.
Экспорт всей вашей схемы через T-SQL
Хорошо, давайте заставим этого щенка работать и экспортируем всю нашу схему любой базы данных. Экспорт одной таблицы за раз не поможет. Давайте «закончим» и экспортируем всю схему базы данных: во-первых, нам нужно поместить все объекты нашей базы данных в таблицу, чтобы мы могли пройтись по ним и экспортировать их. Мы будем основывать все на встроенной хранимой процедуре sp_msdependencies; эта процедура получает все ваши объекты в порядке зависимости… вы знаете… родительские таблицы перед дочерними таблицами, которые ссылаются на родителя,
Мы будем основывать все на встроенной хранимой процедуре sp_msdependencies; эта процедура получает все ваши объекты в порядке зависимости… вы знаете… родительские таблицы перед дочерними таблицами, которые ссылаются на родителя,
Однако при использовании этой процедуры было немного проб и ошибок. Синонимы в базе данных отображаются как функция, но вы не можете использовать sp_helptext как синоним, поэтому их не следует экспортировать. Кроме того, есть синонимы в базе данных master, а также в текущей базе данных. Все это нужно было учитывать. Вот процедура:
СОЗДАТЬ ПРОЦЕДУРУ sp_export_all(@WithData int = 0)
КАК
НАЧИНАТЬ
УСТАНОВИТЬ NOCOUNT ON
СОЗДАТЬ ТАБЛИЦУ #MyObjectHierarchy
(
HID int identity(1,1) не нулевой первичный ключ,
Идентификатор объекта,
TYPE int,OBJECTTYPE AS CASE
КОГДА ТИП = 1, ТОГДА "ФУНКЦИЯ"
КОГДА ТИП = 4, ТОГДА 'ПРОСМОТР'
КОГДА ТИП = 8, ТОГДА 'ТАБЛИЦА'
КОГДА ТИП = 16, ТОГДА 'ПРОЦЕДУРА'
КОГДА ТИП = 128, ТОГДА ПРАВИЛО
ЕЩЕ ''
КОНЕЦ,
ОНАМЭ varchar(255),
ВЛАДЕЛЕЦ varchar(255),
SEQ цел.
)
--наша таблица результатов
CREATE TABLE #Results(ResultsID int identity(1,1) not null,ResultsText varchar(max))
--наш список объектов в порядке зависимости
ВСТАВЬТЕ #MyObjectHierarchy (TYPE,ONAME,OWNER,SEQ)
EXEC sp_msdependencies @intrans = 1
Обновление #MyObjectHierarchy SET ObjectId = object_id (ВЛАДЕЛЕЦ + '.' + ONAME)
--synonyms являются функцией объекта типа 1?!?!... нужно их удалить
УДАЛИТЬ ИЗ #MyObjectHierarchy, ГДЕ идентификатор объекта в (
SELECT [object_id] FROM sys.synonyms UNION ALL
ВЫБЕРИТЕ [object_id] ИЗ master.sys.synonyms)
ЗАЯВИТЬ
@schemaname varchar(255),
@objname varchar(255),
@objecttype varchar(20),
@FullObjectName varchar(510)
ОБЪЯВИТЬ КУРСОР cur1 ДЛЯ
ВЫБЕРИТЕ ВЛАДЕЛЬЦА, ONAME, OBJECTTYPE ИЗ #MyObjectHierarchy ORDER BY HID
ОТКРЫТЫЙ курс1
FETCH NEXT FROM cur1 INTO @schemaname,@objname,@objecttype
ПОКА @@fetch_status <> -1
НАЧИНАТЬ
SET @FullObjectName = @имя_схемы + '.' + @objname
ЕСЛИ @objecttype = 'ТАБЛИЦА'
НАЧИНАТЬ
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_getddl @FullObjectName
ЕСЛИ @С данными > 0
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_export_data @table_name = @FullObjectName,@ommit_images = 1
КОНЕЦ
ELSE IF @objecttype IN('VIEW','FUNCTION','PROCEDURE') -- это FUNCTION/PROC/VIEW
НАЧИНАТЬ
--CREATE PROC/FUN/VIEW требуется оператор GO
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
ВЫБЕРИТЕ «ПЕРЕХОД»
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_helptext @FullObjectName
КОНЕЦ
FETCH NEXT FROM cur1 INTO @schemaname,@objname,@objecttype
КОНЕЦ
ЗАКРЫТЬ cur1
ОСВОБОДИТЬ cur1
SELECT ResultsText FROM #Results ORDER BY ResultsID
КОНЕЦ
ИДТИ
Процедура не очень захватывающая, но посмотрите, что она делает. Он перебирает все объекты в базе данных; если это таблица, она вызывает sp_GetDDL, если это процедура/функция/представление, она вызывает sp_helptext. Он помещает все во временную таблицу и в конце выбирает из этой временной таблицы. 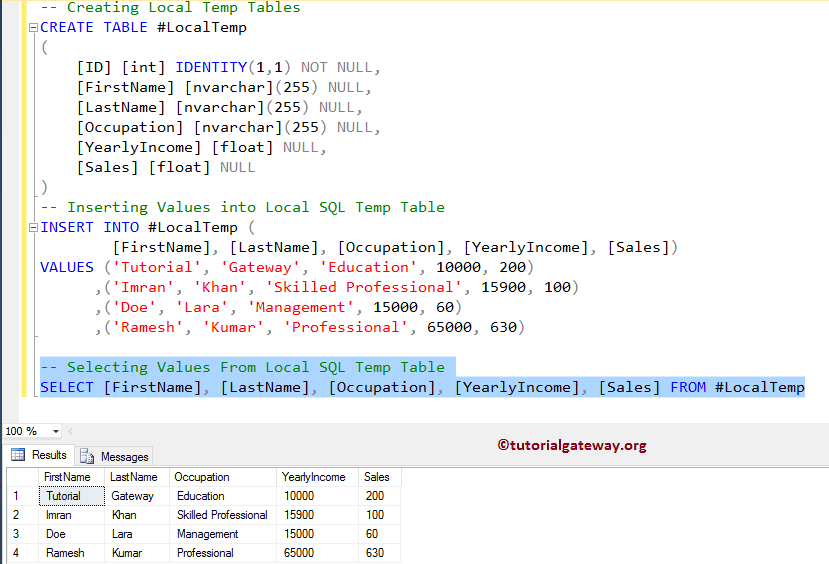 )
--наша таблица результатов
CREATE TABLE #Results(ResultsID int identity(1,1) not null,ResultsText varchar(max))
--наш список объектов в порядке зависимости
ВСТАВЬТЕ #MyObjectHierarchy (TYPE,ONAME,OWNER,SEQ)
EXEC sp_msdependencies @intrans = 1
Обновление #MyObjectHierarchy SET ObjectId = object_id (ВЛАДЕЛЕЦ + '.' + ONAME)
--synonyms являются функцией объекта типа 1?!?!... нужно их удалить
УДАЛИТЬ ИЗ #MyObjectHierarchy, ГДЕ идентификатор объекта в (
SELECT [object_id] FROM sys.synonyms UNION ALL
ВЫБЕРИТЕ [object_id] ИЗ master.sys.synonyms)
ЗАЯВИТЬ
@schemaname varchar(255),
@objname varchar(255),
@objecttype varchar(20),
@FullObjectName varchar(510)
ОБЪЯВИТЬ КУРСОР cur1 ДЛЯ
ВЫБЕРИТЕ ВЛАДЕЛЬЦА, ONAME, OBJECTTYPE ИЗ #MyObjectHierarchy ORDER BY HID
ОТКРЫТЫЙ курс1
FETCH NEXT FROM cur1 INTO @schemaname,@objname,@objecttype
ПОКА @@fetch_status <> -1
НАЧИНАТЬ
SET @FullObjectName = @имя_схемы + '.' + @objname
ЕСЛИ @objecttype = 'ТАБЛИЦА'
НАЧИНАТЬ
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_getddl @FullObjectName
ЕСЛИ @С данными > 0
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_export_data @table_name = @FullObjectName,@ommit_images = 1
КОНЕЦ
ELSE IF @objecttype IN('VIEW','FUNCTION','PROCEDURE') -- это FUNCTION/PROC/VIEW
НАЧИНАТЬ
--CREATE PROC/FUN/VIEW требуется оператор GO
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
ВЫБЕРИТЕ «ПЕРЕХОД»
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_helptext @FullObjectName
КОНЕЦ
FETCH NEXT FROM cur1 INTO @schemaname,@objname,@objecttype
КОНЕЦ
ЗАКРЫТЬ cur1
ОСВОБОДИТЬ cur1
SELECT ResultsText FROM #Results ORDER BY ResultsID
КОНЕЦ
ИДТИ
Процедура не очень захватывающая, но посмотрите, что она делает.
)
--наша таблица результатов
CREATE TABLE #Results(ResultsID int identity(1,1) not null,ResultsText varchar(max))
--наш список объектов в порядке зависимости
ВСТАВЬТЕ #MyObjectHierarchy (TYPE,ONAME,OWNER,SEQ)
EXEC sp_msdependencies @intrans = 1
Обновление #MyObjectHierarchy SET ObjectId = object_id (ВЛАДЕЛЕЦ + '.' + ONAME)
--synonyms являются функцией объекта типа 1?!?!... нужно их удалить
УДАЛИТЬ ИЗ #MyObjectHierarchy, ГДЕ идентификатор объекта в (
SELECT [object_id] FROM sys.synonyms UNION ALL
ВЫБЕРИТЕ [object_id] ИЗ master.sys.synonyms)
ЗАЯВИТЬ
@schemaname varchar(255),
@objname varchar(255),
@objecttype varchar(20),
@FullObjectName varchar(510)
ОБЪЯВИТЬ КУРСОР cur1 ДЛЯ
ВЫБЕРИТЕ ВЛАДЕЛЬЦА, ONAME, OBJECTTYPE ИЗ #MyObjectHierarchy ORDER BY HID
ОТКРЫТЫЙ курс1
FETCH NEXT FROM cur1 INTO @schemaname,@objname,@objecttype
ПОКА @@fetch_status <> -1
НАЧИНАТЬ
SET @FullObjectName = @имя_схемы + '.' + @objname
ЕСЛИ @objecttype = 'ТАБЛИЦА'
НАЧИНАТЬ
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_getddl @FullObjectName
ЕСЛИ @С данными > 0
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_export_data @table_name = @FullObjectName,@ommit_images = 1
КОНЕЦ
ELSE IF @objecttype IN('VIEW','FUNCTION','PROCEDURE') -- это FUNCTION/PROC/VIEW
НАЧИНАТЬ
--CREATE PROC/FUN/VIEW требуется оператор GO
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
ВЫБЕРИТЕ «ПЕРЕХОД»
ВСТАВИТЬ В #Результаты(ТекстРезультатов)
EXEC sp_helptext @FullObjectName
КОНЕЦ
FETCH NEXT FROM cur1 INTO @schemaname,@objname,@objecttype
КОНЕЦ
ЗАКРЫТЬ cur1
ОСВОБОДИТЬ cur1
SELECT ResultsText FROM #Results ORDER BY ResultsID
КОНЕЦ
ИДТИ
Процедура не очень захватывающая, но посмотрите, что она делает. Он перебирает все объекты в базе данных; если это таблица, она вызывает sp_GetDDL, если это процедура/функция/представление, она вызывает sp_helptext. Он помещает все во временную таблицу и в конце выбирает из этой временной таблицы.
Он перебирает все объекты в базе данных; если это таблица, она вызывает sp_GetDDL, если это процедура/функция/представление, она вызывает sp_helptext. Он помещает все во временную таблицу и в конце выбирает из этой временной таблицы. Процедура не самая захватывающая, но посмотрите, что она делает. Он перебирает все объекты в базе данных; если это таблица, она вызывает sp_GetDDL, если это процедура/функция/представление, она вызывает sp_helptext. Он помещает все во временную таблицу и в конце выбирает из этой временной таблицы.
Существует один необязательный параметр,
@WithData INT = 0
Если он не равен нулю, то после построения таблицы будет создано операторов INSERT INTO tablename! Это и хорошо, и плохо; если у вас есть стол с миллионов миллиардов строк , и вы пытаетесь сгенерировать эти утверждения… ну… это займет больше времени, чем оно того стоит.
Но если у вас есть пустая база данных, в которой есть только таблицы поиска, такие как статусы, округа, штаты, основные поисковые запросы, у вас есть готовый сценарий развертывания , и он выглядит ХОРОШО!.
Видите функцию sp_export_data? Это не что иное, как слегка измененная версия generate_inserts_2005.txt 9 Нараяны Вьяса Кондредди.0006 с http://vyaskn.tripod.com Я изменил некоторые операторы PRINT на операторы select, чтобы команды SET IDENTITY_INSERT были частью вывода, и сделал несколько полей, которые были varchar(8000) varchar(max) из-за некоторых ошибок. попал на некоторые действительно широкие столы. Я переименовал его, чтобы отразить изменения и сделать его логичным с остальным набором функций.
вы должны прочитать код и проверить результаты. Пишите отзывы, как хорошие, так и плохие, буду признателен!
Вот ссылка на zip-файл со следующими скриптами: Создать таблицу DDL с помощью T-SQL
- what_sample_tables.sql — содержит приведенный выше пример для создания тестовой таблицы или двух
- sp_GetDDL2005.sql — версия sp_GetDDL 2005 года для получения инструкций CREATE TABLE.
- sp_export_all.sql — создает таблицу с каждым объектом schema.