Table sql: SQL CREATE TABLE Statement
Содержание
Введение в таблицы SQL
В этой статье мы изучим концепцию таблиц SQL, а затем поработаем над тем, как мы можем создавать таблицы с помощью различных методов в SQL Server.
Реляционная модель базы данных является одной из наиболее часто используемых моделей данных для хранения и обработки данных. Таблицы являются важными элементами базы данных. В этом контексте таблицы — это объекты базы данных, содержащие данные в реляционных базах данных. База данных содержит одну или несколько таблиц, и эти таблицы можно смоделировать как реляционные. Таблицы возникают из столбцов, и каждый столбец должен иметь имя и тип данных. Эти столбцы хранят данные в соответствии с определенными типами данных, и эти записи данных называются строками. На следующем рисунке показан пример структуры таблицы.
Как мы видим, таблица Persons состоит из столбцов Id , Name , Surname и Age . Эти столбцы содержат числовые или текстовые данные в соответствии с определенными типами данных. Теперь мы научимся создавать таблицы с помощью различных методов.
Эти столбцы содержат числовые или текстовые данные в соответствии с определенными типами данных. Теперь мы научимся создавать таблицы с помощью различных методов.
Создайте таблицу с помощью SQL Server Management Studio (SSMS)
SQL Server Management Studio — это IDE (интегрированная среда разработки), которая помогает управлять SQL Server и создавать T-SQL.
запросы. Таким образом, создать таблицу с помощью SSMS очень просто. После подключения к базе данных, мы нажимаем правой кнопкой мыши на Tables и выберите New во всплывающем меню и щелкните параметр Table .
Новая таблица настраиваемое окно будет показано для быстрого создания таблицы. В то же время мы можем найти свойства выбранного столбца внизу того же экрана.
В окне «Новая таблица» мы можем определить столбцы с именами и типами данных. Каждый столбец должен иметь тип данных и уникальное имя.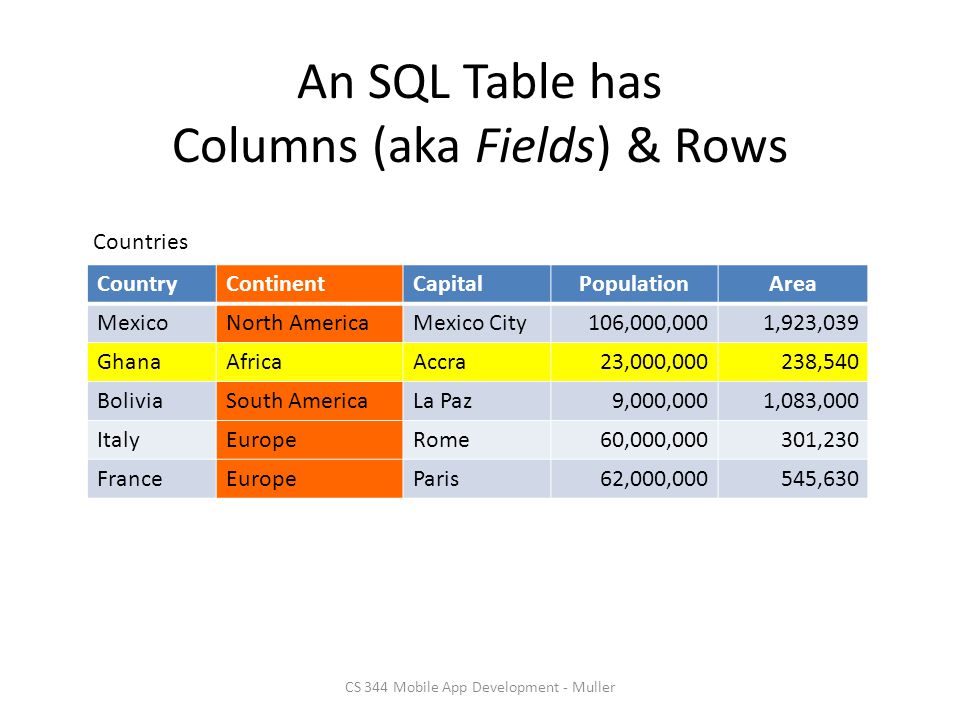
Совет: Когда мы установили флажок Разрешить пустые значения, мы можем сохранять нулевые значения в связанном столбце.
Когда мы щелкаем правой кнопкой мыши по любому столбцу, мы можем установить некоторые параметры для этого столбца. Стрелка вправо указывает, над каким столбцом мы работаем.
Установить первичный ключ: Первичный ключ — это значение или комбинация значений, которые помогают
уникально идентифицировать каждую строку в таблице. Для этой таблицы мы установим Столбец с идентификатором в качестве основного
ключ. После установки столбца в качестве первичного ключа на столбце появится знак ключа.
Когда мы пытаемся проверить параметр Allow Nulls для столбца, который был установлен в качестве первичного ключа, SSMS возвращает ошибку.
Как мы уже говорили, таблицы SQL позволяют нам указывать составные первичные ключи.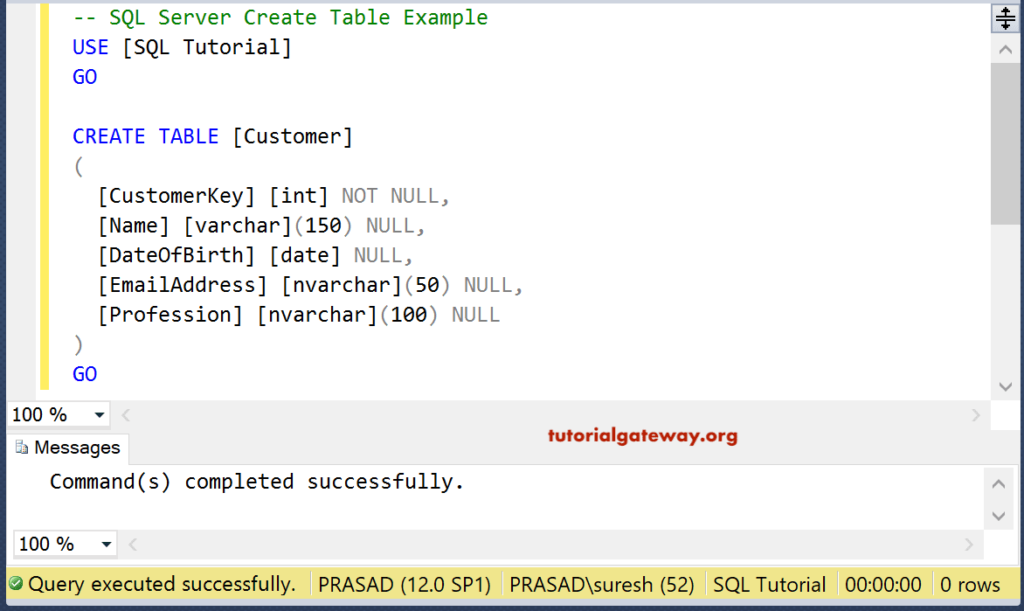 Только нам нужно выбрать более одного столбца
Только нам нужно выбрать более одного столбца
с помощью клавиши Shift и выберите опцию «Установить первичный ключ».
Знак ключа будет показан для этих нескольких столбцов.
Отношения: Этот параметр позволяет определить связь внешнего ключа с другими таблицами.
Индексы/ключи: С помощью этой опции мы можем создавать индексы или устанавливать уникальные ограничения для столбцов.
Проверочные ограничения: Проверочные ограничения используются для контроля в соответствии с указанным правилом данных, которые будут храниться в столбцах.
Эта опция позволяет создать этот тип правил (ограничений).
Свойства: Когда мы выбираем эту опцию для любого столбца, мы можем получить доступ к окнам свойств таблицы.
На этом экране мы можем изменить имя таблицы и другие свойства таблицы.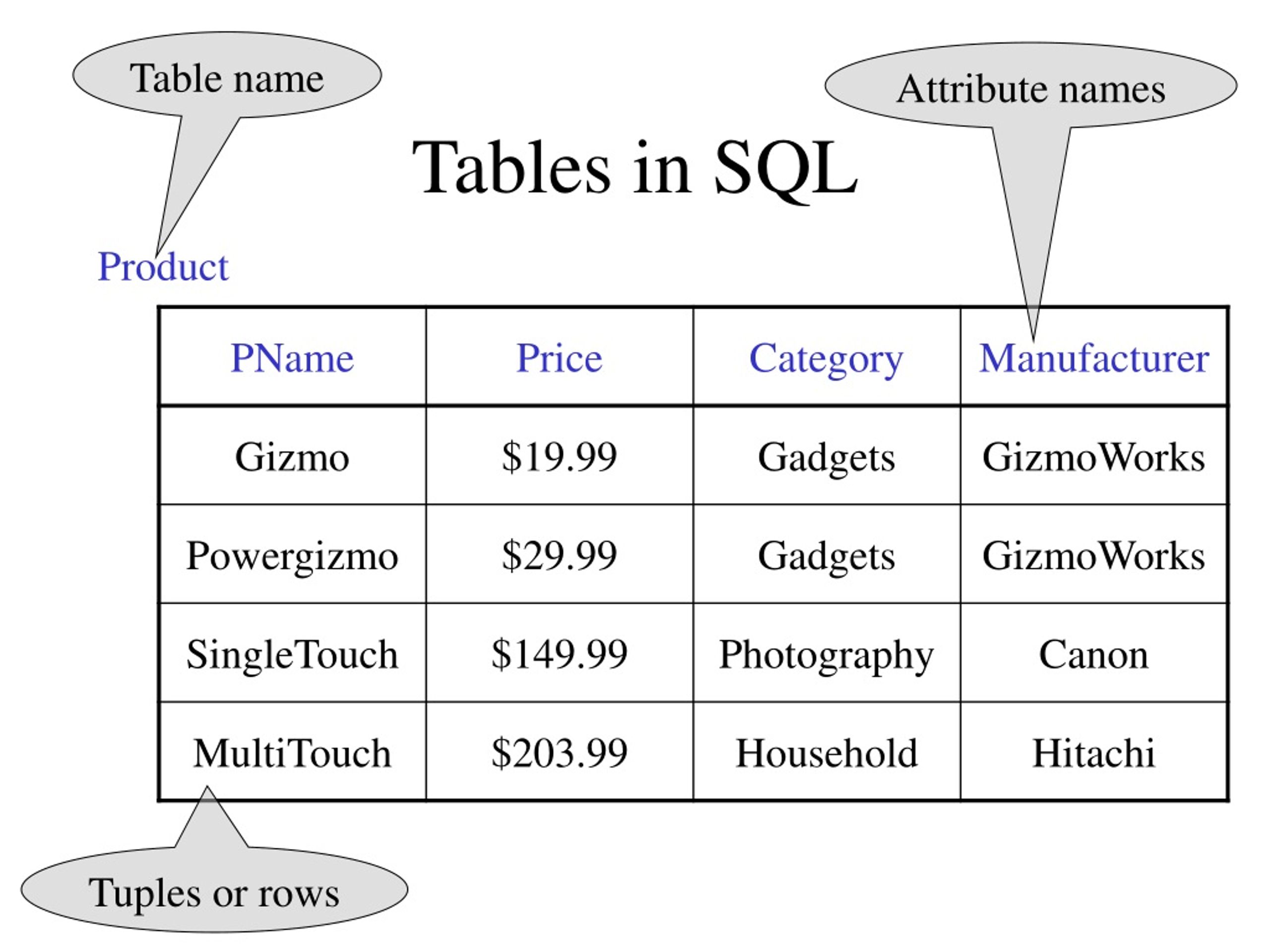 В качестве последнего шага мы нажмем кнопку
В качестве последнего шага мы нажмем кнопку
кнопку сохранения или комбинацию клавиш CTRL+S. Созданная таблица будет отображаться в папке Tables .
Создать таблицу с помощью T-SQL
Оператор CREATE TABLE используется для создания новой таблицы в SQL Server. Приведенный ниже запрос создает
Таблица лиц. После оператора CREATE TABLE мы определяем имя таблицы. В скобках указываем имена столбцов и типы данных. Кроме того, мы устанавливаем столбец Id в качестве первичного ключа.
1 2 3 4 5 6 7 | CREATE TABLE [Persons] ([Id] [INT] PRIMARY KEY, [Name] [VARCHAR](50) NOT NULL, [Sur03] [VARCHAR] NOT NULL, 50 [Возраст] [SMALLINT] NOT NULL ) |
Мы получаем ошибку после выполнения запроса, потому что таблица с таким именем существует в той же схеме. Для этого
Для этого
Причина, прежде чем создавать таблицу, нам нужно проверить существование таблицы, чтобы избежать ошибок такого типа.
Условие DROP TABLE будет выполнено, если таблица Persons уже существует в базе данных.
1 2 3 4 5 6 7 8 10 110003 12 13 14 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 9000 3 | ЕСЛИ СУЩЕСТВУЕТ (ВЫБЕРИТЕ * ИЗ INFORMATION_SCHEMA.TABLES ГДЕ TABLE_NAME = N’Persons’) Begin Drop Table Persons END GO CREATE TABLE [Persons] ([ID] [Int] Первичный ключ, [имя] [VARCHAR] (50) Не нулевой, [Фамилия] [VARCHAR](50) NOT NULL, [Возраст] [SMALLINT] NOT NULL )
GO SELECT * FROM Persons |
Создать таблицу из существующей таблицы
Мы можем создать новую таблицу из существующей таблицы. Оператор SELECT INTO создает новую таблицу и
Оператор SELECT INTO создает новую таблицу и
вставляет набор результатов запроса SELECT в новую таблицу. Однако, если мы хотим создать пустой
копию таблицы мы можем использовать следующий метод. Этот метод использует условие WHERE, которое приводит к пустому набору результатов.
для возврата из запроса.
ВЫБРАТЬ * INTO CopyPersons FROM Persons ГДЕ 1=0 GO SELECT * FROM CopyPersons |
Недостатком этого метода является то, что он не копирует индексы и ограничения из исходной таблицы в
целевая (новая) таблица. Например, мы знаем, что столбец Id является первичным ключом для Person .
таблица, но этот атрибут не передается в таблицу CopyPerson .
Создайте таблицу с помощью Azure Data Studio
Azure Data Studio — это новый легкий инструмент, который позволяет нам выполнять запросы локально или в облаке.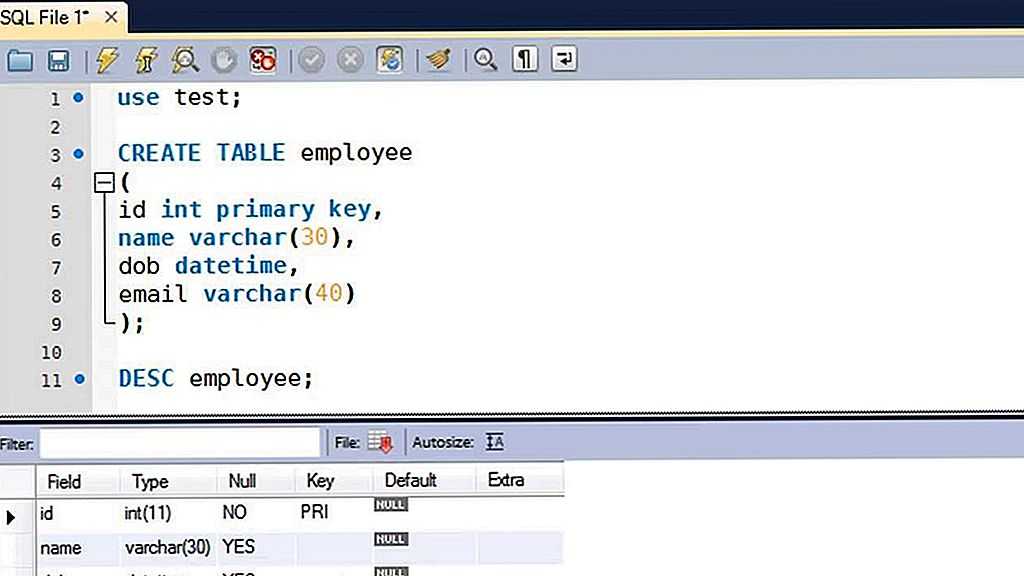
базы данных, а также помогает управлять базами данных. Фрагменты кода являются одним из основных
преимущества Azure Data Studio, эти шаблоны помогают нам вводить запросы для простого создания правильного синтаксиса.
После открытия нового окна запроса мы набираем « CREATE TABLE », чтобы создать таблицу SQL, и выбираем фрагмент sqlCreateTable .
После выбора шаблона таблица запроса будет автоматически введена в окно запроса.
После изменения необходимых полей шаблона оператор CREATE TABLE будет завершен.
Заключение
В этой статье мы изучили основы таблиц SQL в реляционных базах данных, а затем
различные методы, используемые для создания таблиц. Мы можем использовать самый простой и удобный для нас способ.
- Автор
- Последние сообщения
Esat Erkec
Esat Erkec — специалист по SQL Server, который начал свою карьеру более 8 лет назад в качестве разработчика программного обеспечения.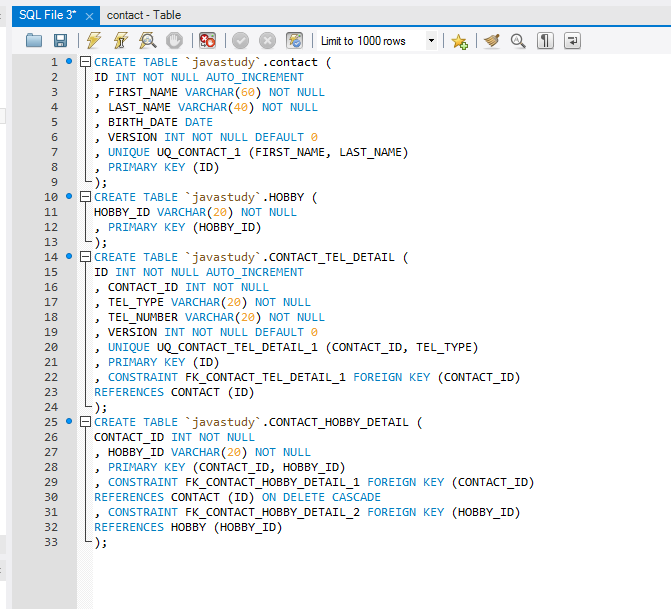 Он является сертифицированным экспертом по решениям Microsoft для SQL Server.
Он является сертифицированным экспертом по решениям Microsoft для SQL Server.
Большая часть его карьеры была посвящена администрированию и разработке баз данных SQL Server. Его текущие интересы связаны с администрированием баз данных и бизнес-аналитикой. Вы можете найти его в LinkedIn.
Просмотреть все сообщения от Esat Erkec
Последние сообщения от Esat Erkec (посмотреть все)
Таблицы — SQL Server | Microsoft Узнайте
Редактировать
Твиттер
Фейсбук
Электронная почта
- Статья
- 6 минут на чтение
Применимо к:
SQL Server 2016 (13.x) и более поздние версии База данных SQL Azure Управляемый экземпляр Azure SQL Azure Synapse Analytics Analytics Platform System (PDW)
Таблицы — это объекты базы данных, содержащие все данные в базе данных. В таблицах данные логически организованы в виде строк и столбцов, как в электронных таблицах. Каждая строка представляет собой уникальную запись, а каждый столбец представляет собой поле в записи. Например, таблица, содержащая данные о сотрудниках компании, может содержать строку для каждого сотрудника и столбцы, представляющие информацию о сотруднике, такую как номер сотрудника, имя, адрес, должность и номер домашнего телефона.
В таблицах данные логически организованы в виде строк и столбцов, как в электронных таблицах. Каждая строка представляет собой уникальную запись, а каждый столбец представляет собой поле в записи. Например, таблица, содержащая данные о сотрудниках компании, может содержать строку для каждого сотрудника и столбцы, представляющие информацию о сотруднике, такую как номер сотрудника, имя, адрес, должность и номер домашнего телефона.
Количество таблиц в базе данных ограничено только допустимым количеством объектов в базе данных (2 147 483 647). Стандартная определяемая пользователем таблица может содержать до 1024 столбцов. Количество строк в таблице ограничено только емкостью хранилища сервера.
Вы можете назначить свойства таблице и каждому столбцу в таблице, чтобы контролировать разрешенные данные и другие свойства. Например, вы можете создать ограничения для столбца, чтобы запретить пустые значения или предоставить значение по умолчанию, если значение не указано, или вы можете назначить ключевое ограничение для таблицы, которое обеспечивает уникальность или определяет связь между таблицами.

Данные в таблице могут быть сжаты по строкам или по страницам. Сжатие данных позволяет хранить больше строк на странице. Дополнительные сведения см. в разделе Сжатие данных.

Типы таблиц
Помимо стандартной роли основных пользовательских таблиц, SQL Server предоставляет следующие типы таблиц, которые служат специальным целям в базе данных.
Многораздельные таблицы
Многораздельные таблицы — это таблицы, данные которых горизонтально разделены на блоки, которые могут быть распределены по нескольким файловым группам в базе данных. Секционирование делает большие таблицы или индексы более управляемыми, позволяя быстро и эффективно получать доступ к подмножествам данных или управлять ими, сохраняя при этом целостность всей коллекции. По умолчанию SQL Server поддерживает до 15 000 разделов. Дополнительные сведения см. в разделе Многораздельные таблицы и индексы.
Временные таблицы
Временные таблицы хранятся в базе данных tempdb . Существует два типа временных таблиц: локальные и глобальные. Они отличаются друг от друга своими именами, видимостью и доступностью. Локальные временные таблицы имеют один знак номера (#) в качестве первого символа их имен; они видны только текущему подключению пользователя и удаляются, когда пользователь отключается от экземпляра SQL Server. Глобальные временные таблицы имеют два знака номера (##) в качестве первых символов их имен; они видны любому пользователю после их создания и удаляются, когда все пользователи, ссылающиеся на таблицу, отключаются от экземпляра SQL Server.
Существует два типа временных таблиц: локальные и глобальные. Они отличаются друг от друга своими именами, видимостью и доступностью. Локальные временные таблицы имеют один знак номера (#) в качестве первого символа их имен; они видны только текущему подключению пользователя и удаляются, когда пользователь отключается от экземпляра SQL Server. Глобальные временные таблицы имеют два знака номера (##) в качестве первых символов их имен; они видны любому пользователю после их создания и удаляются, когда все пользователи, ссылающиеся на таблицу, отключаются от экземпляра SQL Server.
Уменьшено число повторных компиляций для рабочих нагрузок с использованием временных таблиц в нескольких областях
SQL Server 2019 (15.x) для всех уровней совместимости баз данных сокращает число повторных компиляций для рабочих нагрузок с использованием временных таблиц в нескольких областях. Эта функция также включена в базе данных SQL Azure на уровне совместимости базы данных 150 для всех моделей развертывания. До этой функции при ссылке на временную таблицу с оператором языка обработки данных (DML) (
До этой функции при ссылке на временную таблицу с оператором языка обработки данных (DML) ( SELECT , INSERT , UPDATE , DELETE ), если временная таблица была создана пакетом внешней области, это привело бы к повторной компиляции оператора DML при каждом его выполнении. Благодаря этому усовершенствованию SQL Server выполняет дополнительные упрощенные проверки, чтобы избежать ненужных повторных компиляций:
- Проверяет, является ли модуль внешней области, используемый для создания временной таблицы во время компиляции, тем же, что и для последовательных исполнений.
- Отслеживайте любые изменения языка определения данных (DDL), сделанные при начальной компиляции, и сравнивайте их с операциями DDL для последовательных исполнений.
Конечным результатом является сокращение лишних перекомпиляций и нагрузки на ЦП.
Системные таблицы
SQL Server хранит данные, определяющие конфигурацию сервера и всех его таблиц, в специальном наборе таблиц, известных как системные таблицы. Пользователи не могут напрямую запрашивать или обновлять системные таблицы. Информация в системных таблицах доступна через системные представления. Дополнительные сведения см. в разделе Системные представления (Transact-SQL).
Пользователи не могут напрямую запрашивать или обновлять системные таблицы. Информация в системных таблицах доступна через системные представления. Дополнительные сведения см. в разделе Системные представления (Transact-SQL).
Широкие столы
Широкие таблицы используют разреженные столбцы, чтобы увеличить общее количество столбцов, которые может иметь таблица, до 30 000. Разреженные столбцы — это обычные столбцы с оптимизированным хранилищем для нулевых значений. Разреженные столбцы сокращают требования к пространству для нулевых значений за счет увеличения накладных расходов на получение ненулевых значений. Широкая таблица определила набор столбцов, который представляет собой нетипизированное XML-представление, объединяющее все разреженные столбцы таблицы в структурированный вывод. Количество индексов и статистики также увеличено до 1000 и 30 000 соответственно. Максимальный размер широкой строки таблицы – 8 019.байт. Следовательно, большая часть данных в любой конкретной строке должна иметь значение NULL. Максимальное количество неразреженных столбцов плюс вычисляемые столбцы в широкой таблице остается равным 1024.
Максимальное количество неразреженных столбцов плюс вычисляемые столбцы в широкой таблице остается равным 1024.
Широкие таблицы влияют на производительность следующим образом.
Широкие таблицы могут увеличить стоимость поддержки индексов в таблице. Мы рекомендуем, чтобы количество индексов в широкой таблице было ограничено индексами, требуемыми бизнес-логикой. По мере увеличения количества индексов увеличивается время компиляции DML и требования к памяти. Некластеризованные индексы должны быть отфильтрованными индексами, которые применяются к подмножествам данных. Дополнительные сведения см. в разделе Создание отфильтрованных индексов.
Приложения могут динамически добавлять и удалять столбцы из широких таблиц. При добавлении или удалении столбцов скомпилированные планы запросов также становятся недействительными. Мы рекомендуем разработать приложение, соответствующее прогнозируемой рабочей нагрузке, чтобы свести к минимуму изменения схемы.
Когда данные добавляются и удаляются из широкой таблицы, это может повлиять на производительность. Приложения должны быть рассчитаны на прогнозируемую рабочую нагрузку, чтобы изменения в табличных данных были сведены к минимуму.
Ограничьте выполнение операторов DML для широкой таблицы, которые обновляют несколько строк ключа кластеризации. Эти операторы могут потребовать значительных ресурсов памяти для компиляции и выполнения.
Операции переключения разделов в широких таблицах могут быть медленными и могут потребовать больших объемов памяти для обработки. Требования к производительности и памяти пропорциональны общему количеству столбцов как в исходном, так и в целевом разделах.
Курсоры обновления, которые обновляют определенные столбцы в широкой таблице, должны явно перечислять столбцы в предложении FOR UPDATE. Это поможет оптимизировать производительность при использовании курсоров.

Общие задачи для таблиц
В следующей таблице приведены ссылки на общие задачи, связанные с созданием или изменением таблицы.
| Табличные задачи | Тема |
|---|---|
| Описывает, как создать таблицу. | Создание таблиц (модуль базы данных) |
| Описывает, как удалить таблицу. | Удалить таблицы (модуль базы данных) |
| Описывает, как создать новую таблицу, содержащую некоторые или все столбцы существующей таблицы. | Дублирование таблиц |
| Описывает, как переименовать таблицу. | Переименование таблиц (механизм базы данных) |
| Описывает, как просмотреть свойства таблицы. | Просмотр определения таблицы |
| Описывает, как определить, зависят ли другие объекты, такие как представление или хранимая процедура, от таблицы. | Просмотр зависимостей таблицы |
В следующей таблице приведены ссылки на общие задачи, связанные с созданием или изменением столбцов в таблице.
| Задачи столбца | Тема |
|---|---|
Описывает, как добавить столбцы в существующую таблицу. | Добавление столбцов в таблицу (механизм базы данных) |
| Описывает, как удалять столбцы из таблицы. | Удалить столбцы из таблицы |
| Описывает, как изменить имя столбца. | Переименование столбцов (модуль базы данных) |
| Описывает, как копировать столбцы из одной таблицы в другую, копируя либо только определение столбца, либо определение и данные. | Копирование столбцов из одной таблицы в другую (механизм базы данных) |
| Описывает, как изменить определение столбца путем изменения типа данных или другого свойства. | Изменение столбцов (модуль базы данных) |
| Описывает, как изменить порядок отображения столбцов. | Изменить порядок столбцов в таблице |
| Описывает, как создать вычисляемый столбец в таблице. | Указание вычисляемых столбцов в таблице |
Описывает, как указать значение по умолчанию для столбца.
|