Типы данных sql server: Типы данных SQL, MySQL, Oracle, Access, Microsoft SQL Server, PostgreSQL, DB2
Содержание
НОУ ИНТУИТ | Лекция | Определение структуры данных
< Лекция 18 || Лекция 2: 1234
Аннотация: Рассматриваются поддерживаемые в SQL типы данных и преобразование типов. Описывается создание пользовательских типов данных. Дается понятие выражения и оператора в SQL. Приводится определение основных объектов базы данных: таблиц, представлений, индексов, ограничений, правил, хранимых процедур, функций пользователя, триггеров.
Ключевые слова: данные, тип данных, SQL, символьный тип, битовый тип, точное число, округленное число, тип дата/время, EBCDIC, time zone, домен, оператор, пользовательский тип данных, целочисленный тип, выражение, нецелочисленный тип, денежный тип, специальный тип данных, объект базы данных, переменная, параметр хранимой процедуры, преобразование типов, управляющая конструкция, операнд, константы, server, значение, блок операторов, команда, оператор поливариантных ветвлений, условный оператор, оператор цикла, синтаксис, множества, логическая структура, список, ограничения целостности данных, реальная таблица
Типы данных языка SQL, определенные стандартом
intuit.ru/2010/edi»> Данные – это совокупная информация, хранимая в базе данных в виде одного из нескольких различных типов . С помощью типов данных устанавливаются основные правила для данных, содержащихся в конкретном столбце таблицы, в том числе размер выделяемой для них памяти.
В языке SQL имеется шесть скалярных типов данных, определенных стандартом. Их краткое описание представлено в таблице.
| Тип данных | Объявления |
|---|---|
| Символьный | CHAR | VARCHAR |
| Битовый | BIT | BIT VARYING |
| Точные числа | NUMERIC | DECIMAL | INTEGER | SMALLINT |
| Округленные числа | FLOAT | REAL | DOUBLE PRECISION |
| Дата/время | DATE | TIME | TIMESTAMP |
| Интервал | INTERVAL |
Символьные данные
 intuit.ru/2010/edi»> Символьные данные состоят из последовательности символов, входящих в определенный создателями СУБД набор символов. Поскольку наборы символов являются специфическими для различных диалектов языка SQL, перечень символов, которые могут входить в состав значений данных символьного типа, также зависит от конкретной реализации. Чаще всего используются наборы символов ASCII и EBCDIC. Для определения данных символьного типа используется следующий формат:
intuit.ru/2010/edi»> Символьные данные состоят из последовательности символов, входящих в определенный создателями СУБД набор символов. Поскольку наборы символов являются специфическими для различных диалектов языка SQL, перечень символов, которые могут входить в состав значений данных символьного типа, также зависит от конкретной реализации. Чаще всего используются наборы символов ASCII и EBCDIC. Для определения данных символьного типа используется следующий формат:
<символьный_тип>::=
{ CHARACTER [ VARYING][длина] | [CHAR |
VARCHAR][длина]}При определении столбца с символьным типом данных параметр длина применяется для указания максимального количества символов, которые могут быть помещены в данный столбец (по умолчанию принимается значение 1 ). Символьная строка может быть определена как имеющая фиксированную или переменную ( VARYING ) длину. Если строка определена с фиксированной длиной значений, то при вводе в нее меньшего количества символов значение дополняется до указанной длины пробелами, добавляемыми справа. Если строка определена с переменной длиной значений, то при вводе в нее меньшего количества символов в базе данных будут сохранены только введенные символы, что позволит достичь определенной экономии внешней памяти.
Если строка определена с переменной длиной значений, то при вводе в нее меньшего количества символов в базе данных будут сохранены только введенные символы, что позволит достичь определенной экономии внешней памяти.
Битовые данные
Битовый тип данных используется для определения битовых строк, т.е. последовательности двоичных цифр (битов), каждая из которых может иметь значение либо 0, либо 1 . Данные битового типа определяются при помощи следующего формата:
<битовый_тип>::= BIT [VARYING][длина]
Точные числа
Тип точных числовых данных применяется для определения чисел, которые имеют точное представление, т.е. числа состоят из цифр, необязательной десятичной точки и необязательного символа знака. Данные точного числового типа определяются точностью и длиной дробной части. Точность задает общее количество значащих десятичных цифр числа, в которое входит длина как целой части, так и дробной, но без учета самой десятичной точки. Масштаб указывает количество дробных десятичных разрядов числа.
Масштаб указывает количество дробных десятичных разрядов числа.
<фиксированный_тип>::=
{NUMERIC[точность[,масштаб]]|{DECIMAL|DEC}
[точность[, масштаб]]
| {INTEGER |INT}| SMALLINT}Типы NUMERIC и DECIMAL предназначены для хранения чисел в десятичном формате. По умолчанию длина дробной части равна нулю, а принимаемая по умолчанию точность зависит от реализации. Тип INTEGER ( INT ) используется для хранения больших положительных или отрицательных целых чисел. Тип SMALLINT – для хранения небольших положительных или отрицательных целых чисел; в этом случае расход внешней памяти существенно сокращается.
Округленные числа
Тип округленных чисел применяется для описания данных, которые нельзя точно представить в компьютере, в частности действительных чисел. Округленные числа или числа с плавающей точкой представляются в научной нотации, при которой число записывается с помощью мантиссы, умноженной на определенную степень десяти (порядок), например: 10Е3, +5. 2Е6, -0.2Е-4 . Для определения данных вещественного типа используется формат:
2Е6, -0.2Е-4 . Для определения данных вещественного типа используется формат:
<вещественный_тип>::=
{ FLOAT [точность]| REAL |
DOUBLE PRECISION}Параметр точность задает количество значащих цифр мантиссы. Точность типов REAL и DOUBLE PRECISION зависит от конкретной реализации.
Дата и время
Тип данных «дата/время» используется для определения моментов времени с некоторой установленной точностью. Стандарт SQL поддерживает следующий формат:
<тип_даты/времени>::=
{DATE | TIME[точность][WITH TIME ZONE]|
TIMESTAMP[точность][WITH TIME ZONE]}Тип данных DATE используется для хранения календарных дат, включающих поля YEAR (год), MONTH (месяц) и DAY (день). Тип данных TIME – для хранения отметок времени, включающих поля HOUR (часы), MINUTE (минуты) и SECOND (секунды). Тип данных TIMESTAMP – для совместного хранения даты и времени. Параметр точность задает количество дробных десятичных знаков, определяющих точность сохранения значения в поле SECOND. Если этот параметр опускается, по умолчанию его значение для столбцов типа TIME принимается равным нулю (т.е. сохраняются целые секунды), тогда как для полей типа TIMESTAMP он принимается равным 6. Наличие ключевого слова WITH TIME ZONE определяет использование полей TIMEZONE HOUR и TIMEZONE MINUTE, тем самым задаются час и минуты сдвига зонального времени по отношению к универсальному координатному времени (Гринвичскому времени).
Параметр точность задает количество дробных десятичных знаков, определяющих точность сохранения значения в поле SECOND. Если этот параметр опускается, по умолчанию его значение для столбцов типа TIME принимается равным нулю (т.е. сохраняются целые секунды), тогда как для полей типа TIMESTAMP он принимается равным 6. Наличие ключевого слова WITH TIME ZONE определяет использование полей TIMEZONE HOUR и TIMEZONE MINUTE, тем самым задаются час и минуты сдвига зонального времени по отношению к универсальному координатному времени (Гринвичскому времени).
Данные типа INTERVAL используются для представления периодов времени.
Понятие домена
Домен – это набор допустимых значений для одного или нескольких атрибутов. Если в таблице базы данных или в нескольких таблицах присутствуют столбцы, обладающие одними и теми же характеристиками, можно описать тип такого столбца и его поведение через домен, а затем поставить в соответствие каждому из одинаковых столбцов имя домена. Домен определяет все потенциальные значения, которые могут быть присвоены атрибуту.
Домен определяет все потенциальные значения, которые могут быть присвоены атрибуту.
Стандарт SQL позволяет определить домен с помощью следующего оператора:
<определение_домена>::= CREATE DOMAIN имя_домена [AS] тип_данных [ DEFAULT значение] [ CHECK (допустимые_значения)]
Каждому создаваемому домену присваивается имя, тип данных, значение по умолчанию и набор допустимых значений. Следует отметить, что приведенный формат оператора является неполным. Теперь при создании таблицы можно указать вместо типа данных имя домена.
Удаление доменов из базы данных выполняется с помощью оператора:
DROP DOMAIN имя_домена [ RESTRICT | CASCADE]
В случае указания ключевого слова CASCADE любые столбцы таблиц, созданные с использованием удаляемого домена, будут автоматически изменены и описаны как содержащие данные того типа, который был указан в определении удаляемого домена.
Альтернативой доменам в среде SQL Server являются пользовательские типы данных.
Дальше >>
< Лекция 18 || Лекция 2: 1234
Подробно о типах данных | SQL
0 ∞
- Правильный выбор типов данных — важный этап проектирования таблиц
- Столбцам необходимы типы данных
- Типы данных, предусмотренные в системе
- Символьные данные
- Целые
- Точные числовые данные
- Приближенные числовые данные
- Двоичные
- Денежные
- Даты
- Тексты и образы
- Специальные типы данных
- Определяемые пользователями типы данных
- Выберите правильный тип
- Об авторе
- Листинг 1. Создание таблицы авторов книг Authors с использованием только системных типов данных.
- Листинг 2.
 Определение типов данных и последующее создание таблицы авторов книг Authors.
Определение типов данных и последующее создание таблицы авторов книг Authors.
 Определение типов данных и последующее создание таблицы авторов книг Authors.
Определение типов данных и последующее создание таблицы авторов книг Authors.В следующих выпусках рубрики «T-SQL для начинающих» будет рассказано о применении синтаксиса T-SQL для построения таблиц. Но прежде чем начинать строить таблицы, необходимо поговорить о типах данных. Для каждого столбца таблицы должен быть определен некоторый тип данных, например, целые (integer) или символьные (character). Это позволяет системе в последующем контролировать данные, которые будут помещаться в этот столбец. В предлагаемой статье автор рассматривает предусмотренные в системе типы данных и рассказывает о том, как создавать собственные типы данных. Подобные дополнительные типы данных следует создать до того как начнется построение таблиц, ведь при создании таблиц могут понадобиться ссылки на эти типы данных. Определяемые пользователями типы данных позволят существенно усилить контроль над данными и повысить их целостность, особенно в проектах, в которых с базами данных параллельно работают несколько разработчиков.
При создании таблицы необходимо указать тип данных для каждого столбца. Любые данные, помещаемые в столбец, должны отвечать этому типу данных. В некоторых случаях следует указывать и допустимую длину данных в столбце. В листинге 1 приведен оператор SQL, который создает таблицу авторов Authors в базе данных публикаций Pubs, спользуя только предусмотренные в системе типы данных.
Большинство столбцов в этой таблице являются текстовыми полями. Номер телефона, обозначение штата и почтовый индекс всегда имеют постоянную длину, поэтому соответствующие им столбцы phone, state и ZIP удобнее объявить символьными (char). Имя автора, его адрес и город, где он живет, могут различаться по длине, поэтому для них предпочтительнее использовать тип символьных данных переменной длины (varchar). Столбец contract с информацией о наличии контракта с автором, в котором данные представляются в форме да/нет, целесообразно отнести к двоичному типу данных bit, у которого имеется два возможных значения — 0 и 1. Теперь остановимся подробнее на системных типах данных.
Теперь остановимся подробнее на системных типах данных.
В версии SQL Server 6.0 определено 19 типов данных, а в версии SQL Server 7.0 добавлено еще 4 типа для удобства работы с закодированными с помощью Unicode данными, а также для поддержки приложений, основанных на использовании хранилищ данных. Каждый тип данных имеет ряд разновидностей, отличающихся возможным набором значений. Знание этих значений облегчит выбор подходящего типа данных.
Символьные данные типа char предсавляют собой один из наиболее распространенных типов данных. К этому типу относятся такие символьные данные, как имена или адреса. В версии SQL Server 6.5 длина любого столбца с символьными данными ограничивалась 255 знаками. Если же информация оказывалась длиннее, к примеру, если в столбец предполагалось вводить свободный комментарий по поводу контракта, то тогда следовало использовать текстовый тип данных (text). В SQL Server 7.0 это ограничение отменено, так что символьное поле может содержать до 8000 байтов. Верхняя граница обусловлена размером страницы памяти, поскольку ни одна запись не может располагаться в памяти на нескольких страницах. В тех случаях, когда для столбца определен тип данных char, данные следует помещать в одинарных кавычках, как показано в следующем примере:
Верхняя граница обусловлена размером страницы памяти, поскольку ни одна запись не может располагаться в памяти на нескольких страницах. В тех случаях, когда для столбца определен тип данных char, данные следует помещать в одинарных кавычках, как показано в следующем примере:
UPDATE..... SET..... WHERE.....
Как отмечалось в статье «Работа с символьными данными», помещенной в майском номере журнала, можно выбрать символьный тип данных либо фиксированной длины, char, либо переменной длины, varchar. Фиксированный размер оказывается предпочтительным в тех случаях, когда данные имеют одинаковую или сходную длину, например, при вводе идентификатора автора (часто в этом качестве используют индивидуальный номер системы социальной безопасности, что, кстати, является плохим примером для подражания). В большинстве ситуаций применение переменной длины данных не приводит к сколько-нибудь заметному увеличению времени обработки. В то же время фамилия автора может быть очень длинной, так что использование типа varchar оказывается вполне оправданным. Применительно к подавляющему большинству фамилий фиксированная длина поля означает потерю значительного объема памяти, поэтому лучше использовать тип данных varchar. При выборе того или иного типа данных всегда следует искать компромисс с учетом двух аспектов: с одной стороны, потери полезного объема памяти при использовании данных фиксированной длины, а с другой стороны, увеличения времени обработки в случае применения данных переменной длины.
Применительно к подавляющему большинству фамилий фиксированная длина поля означает потерю значительного объема памяти, поэтому лучше использовать тип данных varchar. При выборе того или иного типа данных всегда следует искать компромисс с учетом двух аспектов: с одной стороны, потери полезного объема памяти при использовании данных фиксированной длины, а с другой стороны, увеличения времени обработки в случае применения данных переменной длины.
SQL Server 7.0 поддерживает набор символов Unicode. В связи с этим, чтобы воспользоваться всеми преимуществами, предоставляемыми расширенными возможностями Unicode, необходимо было ввести дополнительный тип данных.Если вам захочется использовать символьные данные Unicode, то следует указать тип данных Nchar или, если это информация переменной длины, то Nvarchar. При вводе данных Unicode их следует заключать в одиночные кавычки, причем непосредственно перед ними необходимо поставить заглавную латинскую букву N. Если в рассмотренном ранее примере имя автора отнесено к типу данных Unicode, то предыдущий оператор обновления примет следующий вид:
UPDATE.
 ....
SET.....
WHERE.....
....
SET.....
WHERE.....Ограничение максимальной длины информации при работе с типом данных Unicode составляет 4000 знаков. Это объясняется тем, что для хранения каждого символа Unicode требуется два байта памяти. Поэтому на стандартную страницу памяти размером 8К можно поместить в два раза меньше символов Unicode, чем при использовании обычных символов.
Базовый тип целых чисел integer охватывает диапазон от -2 147 483 638 до 2 147 483 647. Уменьшенные целые smallint включают числа от -32 768 до 32767. Зачастую, когда точно известно, что диапазон возможных числовых значений данных невелик, лучше применять тип данных smallint. К примеру, в базе данных личной коллекции компакт-дисков при выборе типа данных для первичного ключа целесообразно использовать тип данных smallint. Ведь предположение о том, что число компакт-дисков в такой коллекции превысит 32 676 единиц, кажется неправдоподобным. В этой ситуации не следует для оптимизации памяти использовать тип данных tinyint, поскольку он позволяет обрабатывать только значения от 0 до 255. Такой тип данных можно было бы применить для нумерации депозитных сертификатов, а для коллекции компакт-дисков он может оказаться недостаточным.
Такой тип данных можно было бы применить для нумерации депозитных сертификатов, а для коллекции компакт-дисков он может оказаться недостаточным.
Если приложение таково, что необходимо получать из базы данных числовое значение в строго указанном формате, то для этого следует выбрать один из точных числовых типов данных. Существуют два точных числовых типа данных: десятичный (decimal) и числовой (numeric), которые по существу совпадают друг с другом. Для них можно задать требуемые точность p и масштаб s в формате decimal (p,s). Точность представляет собой число значащих символов по обе стороны от десятичной запятой, а масштаб — количество символов справа от нее. Например, число 123,4567 можно хранить в столбце, для которого тип данных задан в виде (7,4). Если число, которое должно быть помещено в столбец с точным числовым типом данных, содержит больше десятичных знаков, чем указано в типе данных, то такое число округляется до требуемой точности. Числовые типы данных могут использовать для хранения значений от 2 до 17 байтов.
Некоторые числа нельзя точно представить в десятичном виде с ограниченным числом знаков, например, одну треть или число пи. Для записи таких чисел используются действительный (real) или плавающий (float) типы данных. Данные действительного типа хранятся с точностью от 1 до 7 знаков. Плавающий формат, который иногда называют еще форматом двойной точности, может хранить числа, содержащие от 8 до 15 значащих цифр. Действительный и плавающий типы данных применяются в научных приложениях для хранения чисел, не требующих точного двоичного выражения. Одна-две последние цифры могут не вполне точно сохраняться при преобразованиях в двоичный формат. Поэтому такие числа не следует использовать в операциях точного сравнения, применяемых для формулирования условий оборота WHERE.
Предположим, что в базе данных необходимо хранить двоичную информацию. В этой ситуации имеется выбор между двумя форматами представления: c фиксированной или переменной длиной. Данным фиксированной длины соответствует тип данных binary, а двоичным данным переменной длины соответствует тип данных varbinary.
Для представления денежных значений используются два типа данных: денежный (money) и малый денежный (smallmoney). Тип данных денежный применяется для хранения значений от плюс до минус 922 триллионов. Большинство из нас вполне может пользоваться малым денежным типом данных, который перекрывает диапазон значений от -214 748,3648 до +214 748,3647. По существующей договоренности денежный тип данных при хранении имеет четыре десятичных знака после запятой, а для его представления пользователям требуется только два знака . Отметим, что многие финансовые транзакции не используют денежный тип данных. Например, в биржевыех торговых операциях применяются 1/32 доли, для хранения которых необходимо пять десятичных мест.
В SQL Server и дата и время хранятся в одном столбце, так что если с помощью функции GETDATE() запросить текущую дату, то при этом система сообщит и время. Для дат применяются два типа данных, datetime и smalldatetime. Тип данных smalldatetime охватывает период времени от 1 января 1900 года до 6 июня 2079 года и включает время с точностью до минуты. Такого диапазона достаточно для подавляющего большинства проектов. Тип данных datetime годен для использования до 31 декабря 9999 года (это следует учитывать при решении проблемы 10К года). Начало диапазона этого типа данных датируется 1 января 1753 года. Почему 1753? Это связано с переходом с юлианского на грегорианский календарь. Несмотря на то, что грегорианский календарь был предложен некоторое время назад, процесс его принятия продолжался в течение приблизительно 30 лет. На протяжении этого периода некоторые страны уже приняли грегорианский, а другие еще нет. Поэтому для того, чтобы дата воспринималась однозначно, надо знать географическое положение объекта. Кроме того, год начинался не 1 января, а 1 марта. Поэтому такая дата, как 15 января 1792 года, может интерпретироваться и как середина первого месяца 1492 года, и как середина 11-го месяца 1793 года. Создатели SQL Server решили не рисковать, и поэтому приняли решение не воспринимать даты, относящиеся к периоду времени до начала 1753 года.
Такого диапазона достаточно для подавляющего большинства проектов. Тип данных datetime годен для использования до 31 декабря 9999 года (это следует учитывать при решении проблемы 10К года). Начало диапазона этого типа данных датируется 1 января 1753 года. Почему 1753? Это связано с переходом с юлианского на грегорианский календарь. Несмотря на то, что грегорианский календарь был предложен некоторое время назад, процесс его принятия продолжался в течение приблизительно 30 лет. На протяжении этого периода некоторые страны уже приняли грегорианский, а другие еще нет. Поэтому для того, чтобы дата воспринималась однозначно, надо знать географическое положение объекта. Кроме того, год начинался не 1 января, а 1 марта. Поэтому такая дата, как 15 января 1792 года, может интерпретироваться и как середина первого месяца 1492 года, и как середина 11-го месяца 1793 года. Создатели SQL Server решили не рисковать, и поэтому приняли решение не воспринимать даты, относящиеся к периоду времени до начала 1753 года. Следует отметить также, что тип данных datetime показывает тысячные доли секунды, хотя точность гарантируется только до 1/300 части секунды.
Следует отметить также, что тип данных datetime показывает тысячные доли секунды, хотя точность гарантируется только до 1/300 части секунды.
Для символьных данных длиннее, чем 255 знаков, в SQL Server 6.5 следует применять тип данных текст (text). В SQL Server 7.0 граница применимости этого типа данных отодвигается до 8000 знаков. Для больших двоичных объектов (BLOB), таких как цифровые образы, используется тип данных образ (image). ?анные типа текст или образ не хранятся в строках, поэтому к ним не применимо ограничение на размер страницы памяти. В строках хранятся лишь указатели на страницы базы данных, в которых находится информация. Для обновления этих типов данных необходимы специальные процедуры, которые выходят за рамки рассмотрения настоящей статьи. (Более подробно об этом написано в статье Майкла Оути «Нам не страшен огромный BLOB», опубликованной в апрельском номере журнала.) Здесь необходимо отметить только то, что изменения текстовых данных или образов не фиксируются в журнале, а указатели не обновляются. Изменяются только сами поля, содержащие текст или образ.
Изменяются только сами поля, содержащие текст или образ.
Некоторые типы данных трудно отнести к какой-либо категории. Один из таких типов — битовые данные (bit). Это целое число, которое может принимать только два значения — 0 и 1 (в одном байте можно хранить восемь подобных величин). Битовые значения часто применяются в качестве флагов, принимающих значения истина или ложь. Их можно использовать, например, для хранения сведений о том, заключен ли контракт с автором, или принадлежат ли его книги к бестселлерам, или для чего-либо аналогичного. Одно незначительнгое отличие версии SQL Server 7.0 состоит в том, что для столбцов с битовыми данными теперь разрешены и неопределенные значения, в то время как в версии SQL Server 6.5 допустимы были только значения 0 и 1.
Для внутренних целей в SQL Server используется тип данных метка времени (timestamp). Этот тип данных генерирует уникальное значение, которое обновляется каждый раз, когда модифицируется информация в строке таблицы. Метки времени являются внутренними значениями, поддерживаемыми в SQL Server. Они не соответствуют реальным датам и времени.
Они не соответствуют реальным датам и времени.
В SQL Server 7.0 введены два новых типа данных, которые более подробно будут рассмотрены в последующих публикациях. тип данных уникальный идентификатор (uniqueidentifier) позволяет присвоить столбцу уникальное в глобальном масштабе значение. Глобальная уникальность означает неповторимость не только в рамках конкретной базы данных или в пределах одного компьютера, но вообще везде. Этот тип данных играет важную роль при работе с хранилищами данных, когда информация собирается в него из множества разнообразных источников. Тип данных курсор (cursor) применяется для переменных курсора. Использование курсора — отдельная большая тема, которой автор собирается посвятить целую статью.
SQL Server позволяет пользователям определять собственные типы данных, которые являются комбинацией системных типов данных. Как правило, они базируются на системном типе данных определенной длины (имеются в виду числовые и символьные значения), для которого назначаются правила и значения по умолчанию. Например, можно определить тип данных Почтовый индекс как char(10), а тип данных Телефонный номер как char(14). Тогда тип данных Почтовый индекс будет гарантировать целостность форматов почтовых индексов во всех столбцах, для любого клиента, поставщика, служащего или контактного лица где угодно по всему миру.
Например, можно определить тип данных Почтовый индекс как char(10), а тип данных Телефонный номер как char(14). Тогда тип данных Почтовый индекс будет гарантировать целостность форматов почтовых индексов во всех столбцах, для любого клиента, поставщика, служащего или контактного лица где угодно по всему миру.
Но в тех случаях, когда пользователь хочет создать тип данных, имея лишь набросок желаемого, SQL Server оказывается не слишком полезным. К примеру, нельзя создать новый тип данных, обладающий целым набором связанных с ним свойств, для таких понятий как широта или долгота для географических приложений. Ведь для него пришлось бы прибегнуть к методам сферической тригонометрии для вычисления расстояния между двумя точками. Возможно, когда-нибудь SQL Server станет настолько гибким, что сможет помочь и в таких ситуациях.
На данный момент добавлять новые типы данных можно с помощью SQL Server Enterprise Manager или из анализатора запросов Query Analyzer (в версии SQL Server 6. 5 это производится из окна ISQL/w). Каждый тип данных, который добавляют пользователи, действует только в пределах конкретной базы данных. Если же необходимо создать тип данных для всех баз, то его следует поместить в базу данных моделей Model. С момента создания в этой базе данных новый тип данных будет доступен во всех остальных базах. Существует другой способ решения этой проблемы — написать сценарий или сгенерировать его с помощью утилиты генерации сценариев Generate SQL Script, входящей в состав SQL Server. Тогда этот сценарий можно будет запускать из любой базы данных. В Enterprise Manager следует дважды щелкнуть правой кнопкой мыши на названии базы данных, а затем последовательно выбрать из меню Все задачи (All tasks), Генерировать сценарий SQL (Generate SQL Script) и наконец, выбрать пункт создания сценария для всех типов данных.
5 это производится из окна ISQL/w). Каждый тип данных, который добавляют пользователи, действует только в пределах конкретной базы данных. Если же необходимо создать тип данных для всех баз, то его следует поместить в базу данных моделей Model. С момента создания в этой базе данных новый тип данных будет доступен во всех остальных базах. Существует другой способ решения этой проблемы — написать сценарий или сгенерировать его с помощью утилиты генерации сценариев Generate SQL Script, входящей в состав SQL Server. Тогда этот сценарий можно будет запускать из любой базы данных. В Enterprise Manager следует дважды щелкнуть правой кнопкой мыши на названии базы данных, а затем последовательно выбрать из меню Все задачи (All tasks), Генерировать сценарий SQL (Generate SQL Script) и наконец, выбрать пункт создания сценария для всех типов данных.
В окне Enterprise Manager следует выбрать пункт Базы данных (Databases), выбрать конкретную базу из списка, а затем перейти к пункту Определяемые пользователем типы данных (User-Defined Data Types). Щелкните правой кнопкой мыши и выберите пункт Свойства новых определяемых пользователем типов данных (New User-defined Datatype Properties). После этого приступайте к определению типа данных.
Щелкните правой кнопкой мыши и выберите пункт Свойства новых определяемых пользователем типов данных (New User-defined Datatype Properties). После этого приступайте к определению типа данных.
Как принято в SQL Server, добавить новый тип данных можно также с помощью анализатора запросов Query Analyzer. Обратите внимание на то, что кавычки заключают название системного типа данных, но вокруг названия вновь создаваемого типа данных их не ставят. Кроме того, полезно сразу указать, допускает ли создаваемый тип данных неопределенные значения. Для конкретного столбца можно будет в последующем переопределить эту установку, но первоначальная спецификация допустимых возможностей облегчает введение стандартов. А это и является той целью, ради которой вводятся новые типы данных.
При определении типов данных оператор создания таблицы может выглядеть так, как показано на листинге 2. Для тех столбцов, к которым применяются определенные пользователем типы данных, не требуется указывать длину помещаемых в него сведений, — ведь она уже была определена при создании типа данных. Можно также не сообщать системе о том, допустимы ли в рассматриваемом столбце неопределенные значения, поскольку это задано в спецификации типа данных. Хотя не повредит включить такое упоминание и в этот оператор.
Можно также не сообщать системе о том, допустимы ли в рассматриваемом столбце неопределенные значения, поскольку это задано в спецификации типа данных. Хотя не повредит включить такое упоминание и в этот оператор.
Правильный подбор типов данных является частью проектирования таблицы. В SQL Server 6.5 очень трудно изменить свойства столбца после того, как он был создан. В версии SQL Server 7.0 это возможно, но проводить такую процедуру следует с крайней осторожностью.
Введение определяемых пользователем типов данных является одним из способов обеспечения целостности информации в различных приложениях, над которыми трудятся разные команды разработчиков. При этом предполагается , что все они используют SQL Server. Однако при перенесении кода SQL в другие СУБД целесообразно избегать применения определяемых пользователем типов данных.
Майкл Д. Рейли (mdreilly@compuserve.com) является одним из основателей и вице президентом компании Mount Vernon Data Systems, которая занимается консалтингом по Windows NT и SMS, а также разработкой приложений,широко использующих базы данных. Он обладает сертификатами MCSE и MCT по Windows NT, SQL Server и SMS.
Он обладает сертификатами MCSE и MCT по Windows NT, SQL Server и SMS.
au_id varchar(11) NOT NULL , aulname varchar (40) NOT NULL , au_fname varchar (20) NOT NULL , phone char (12) NOT NULL , address varchar (40) NULL , city varchar (20) NULL , state char (2) NULL , zip char (5) NULL , contract bit NOT NULL)
SP_ADDTYPE id, `char(11)`, `not null`
GO
SP_ADDTYPE phonenumber, `char(12)`, `not null`
GO
SP_ADDTYPE statecode, `char(2)`, `null`
GO
SP_ADDTYPE zipcode, `char(10)`, `null`
GO
CREATE TABLE dbo. authors (
au_id id NOT NULL ,
au_lname varchar (40) NOT NULL ,
au_fname varchar (20) NOT NULL ,
phone phonenumber(12) ,
address varchar (40) NULL ,
city varchar (20) NULL ,
state statecode,
zip zipcode,
contract bit NOT NULL )Какие типы данных поддерживает SQL Server?
Существует много типов данных, совместимых с SQL Server, и важно понимать, что это такое, чтобы избежать проблем с несовместимыми типами данных.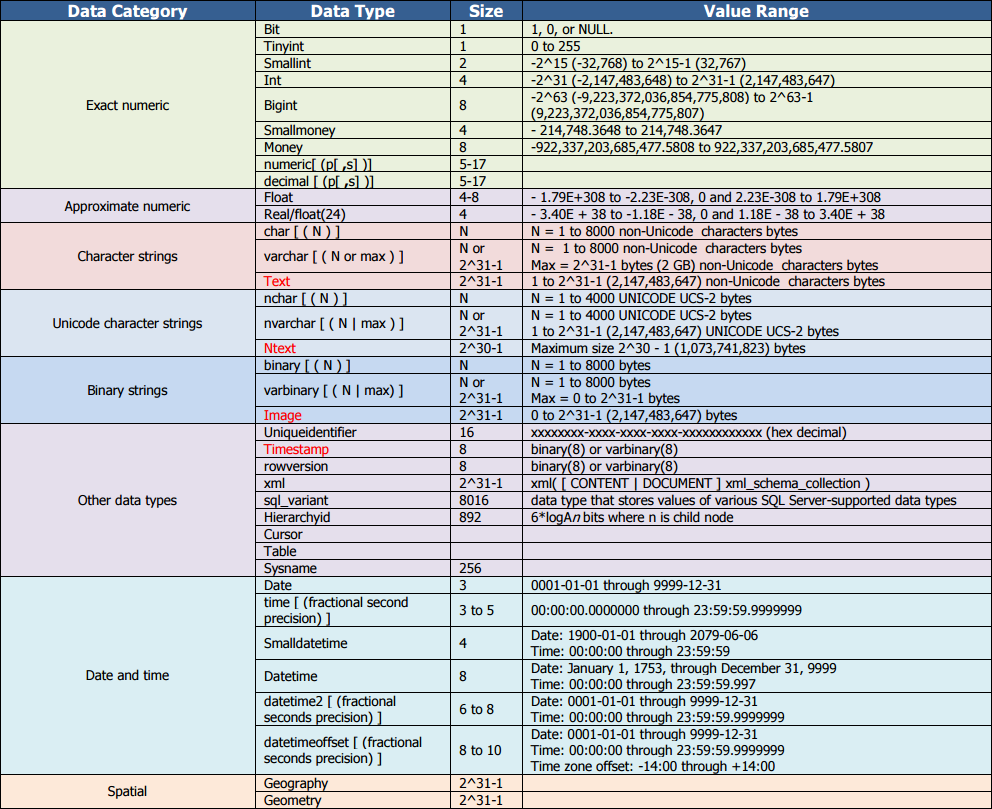 Понимание совместимых типов данных также имеет основополагающее значение для понимания приоритета типа данных, который определяет, какой тип данных будет получен при работе с объектами двух разных типов.
Понимание совместимых типов данных также имеет основополагающее значение для понимания приоритета типа данных, который определяет, какой тип данных будет получен при работе с объектами двух разных типов.
В этом руководстве мы рассмотрим все типы данных, которые поддерживает SQL Server, а также процесс определения пользовательских типов данных с помощью Transact-SQL или Microsoft .NET Framework.
Содержание
- Что такое SQL Server?
- Почему важны типы данных?
- Какие существуют категории данных?
- Определение пользовательских типов данных
- Выбор правильного типа данных
Что такое SQL Server?
Прежде чем мы углубимся во многие типы данных, поддерживаемые SQL Server, кратко рассмотрим, что такое SQL Server. Microsoft разработала SQL Server для использования в качестве системы управления реляционными базами данных (RDBMS). SQL Server использует SQL, стандартный язык для использования реляционных баз данных всех типов.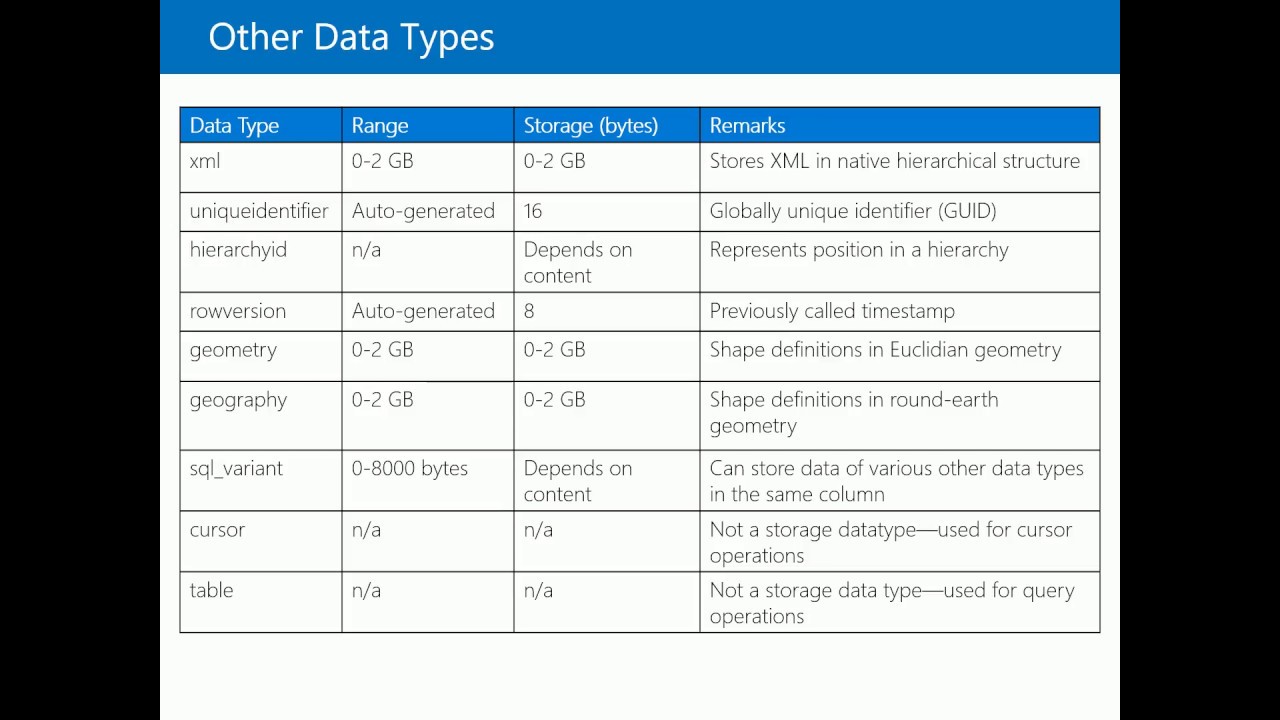
Microsoft SQL Server больше не является эксклюзивным для среды Windows и теперь доступен в Linux, что является отличной новостью для тех, кто заинтересован в использовании SQL Server. Кроме того, облачная платформа Microsoft, известная как Azure, поддерживает SQL Server. Итак, если вам нужно место для его размещения, нет лучшего места, чем собственное решение.
Microsoft позиционирует его как «облако, которое лучше всех знает SQL Server», и Azure SQL Server действительно выигрывает от бесшовной интеграции, простоты и надежности, поскольку и сервер, и облачная инфраструктура разрабатываются и обслуживаются одной и той же компанией.
Однако независимо от того, где вы размещаете SQL Server, важно отметить, что SQL Server использует немного другой язык SQL. Microsoft разработала Transact-SQL (T-SQL), который очень похож на стандартный SQL, но определяет набор собственных концепций, необходимых для программирования SQL Server.
Если вы знакомы с SQL, использование Transact-SQL не составит труда, и вы сможете легко использовать SQL Server. Но еще одним важным аспектом эффективного использования SQL Server является понимание всех типов данных, которые он поддерживает.
Но еще одним важным аспектом эффективного использования SQL Server является понимание всех типов данных, которые он поддерживает.
Почему важны типы данных?
Неправильный тип данных может привести к проблемам с производительностью базы данных, оптимизацией запросов и усечением данных. Эти проблемы часто первыми осознаются командой разработчиков, поскольку именно они отслеживают скорость и производительность. Тем не менее, проблемы могут распространяться на всю организацию, вызывая проблемы с целостностью данных и другие серьезные проблемы.
Если вы новичок в SQL Server, то огромное количество типов данных может показаться ошеломляющим. Тем не менее, они аккуратно организованы и хорошо документированы, что упрощает поиск того, что вам нужно, если вы понимаете, какой тип данных вы планируете хранить. Конечно, несмотря на то, что вы можете обращаться к ним по мере продвижения, получение знаний о типах данных SQL Server имеет первостепенное значение для эффективности и оптимизации в долгосрочной перспективе. Как только вы погрузитесь, вы увидите, что есть некоторое совпадение, и знание того, когда выбрать плавающую точку вместо десятичной или выбрать переменную длину вместо фиксированной, возможно только в том случае, если вы полностью понимаете все свои варианты.
Как только вы погрузитесь, вы увидите, что есть некоторое совпадение, и знание того, когда выбрать плавающую точку вместо десятичной или выбрать переменную длину вместо фиксированной, возможно только в том случае, если вы полностью понимаете все свои варианты.
Какие существуют категории данных?
Ниже представлен обзор каждой категории данных в SQL Server, а также всех типов данных, подходящих для каждой из них.
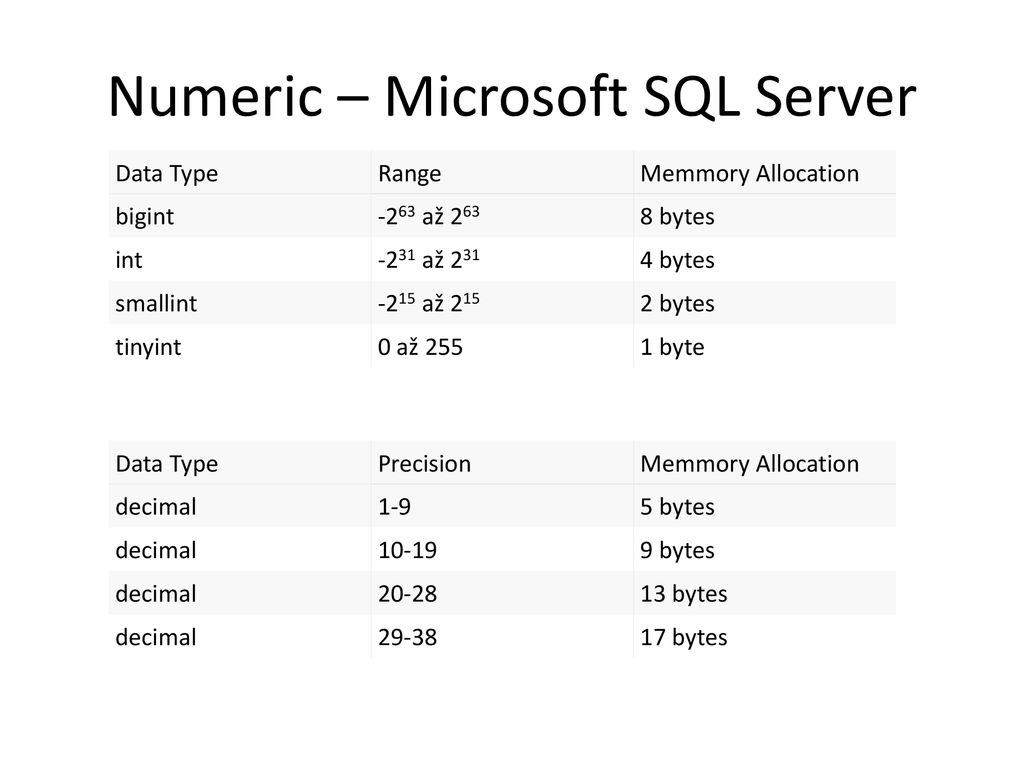
Exact Numerics
При использовании точного числового типа данных важно понимать доступные варианты, чтобы можно было выбрать наименьший тип данных, подходящий для вашего варианта использования. Также необходимо выбрать тип данных, соответствующий типу числа, которое вы храните, например деньги или маленькие деньги для валют.
- tinyint : Наименьший целочисленный тип хранения, способный хранить числа от 0 до 255.
- smallint : Целочисленный тип хранения с удвоенным размером, до 2 байт.
- int: Целочисленный тип хранения до 4 байт.
- bigint : Самый большой целочисленный тип хранилища, способный хранить до 8 байтов данных.
- десятичный и числовой: Эти синонимичные термины относятся к одному и тому же типу данных, который характеризуется фиксированным масштабом и точностью.
- бит : Этот тип данных всегда имеет значение 1, 0 или NULL. Вы можете преобразовать данные true/false в бит, где 1 равно True, а 0 равно False.
- smallmoney : Этот тип данных представляет денежные значения и допускает до двух знаков после запятой.
- деньги: это еще один тип денежных данных, но он допускает до четырех знаков после запятой.
Строки символов Unicode
Если вы не знакомы с Unicode, это универсальный стандарт, который присваивает уникальный номер каждому символу, что позволяет последовательно кодировать и представлять написанный текст. Например, «привет» в Юникоде будет разбито следующим образом: U+0048 («H»), U+0065 («E») и U+0059. («Я»).
(«Я»).
SQL Server поддерживает весь диапазон символьных данных Unicode, используя эти строки символов. Они могут быть фиксированными или переменными.
- nchar : фиксированный размер, рекомендуется для использования, когда размеры данных в столбце совпадают.
- nvarchar : переменный размер, рекомендуется для использования, когда размеры данных в столбце значительно различаются.
- ntext : планируется удалить в будущих версиях SQL Server, разработан как тип данных переменной длины для Unicode. Вместо этого Microsoft рекомендует использовать nvarchar(max).
Приблизительные числовые значения
Когда числовые данные не могут быть представлены точно, они называются числовыми данными с плавающей запятой, и для их хранения следует использовать типы данных с приблизительными числами. Для типов данных с плавающей запятой число записывается с использованием экспоненциальной записи, поэтому 825 000 будет храниться как 8,5 x 10 5 .
Числа с плавающей запятой могут быть невероятно большими или невероятно маленькими. Как с плавающей запятой, так и с десятичным типом данных можно хранить число с десятичной дробью — разница в том, что для плавающей запятой требуется меньше места для хранения, а десятичная — более точная. SQL Server поддерживает два типа приблизительных числовых значений с типами данных float и real.
- float : число с плавающей запятой двойной точности, которое соответствует 8 байтам или 64 битам.
real : число одинарной точности с плавающей запятой, которое соответствует 4 байтам или 32 битам.
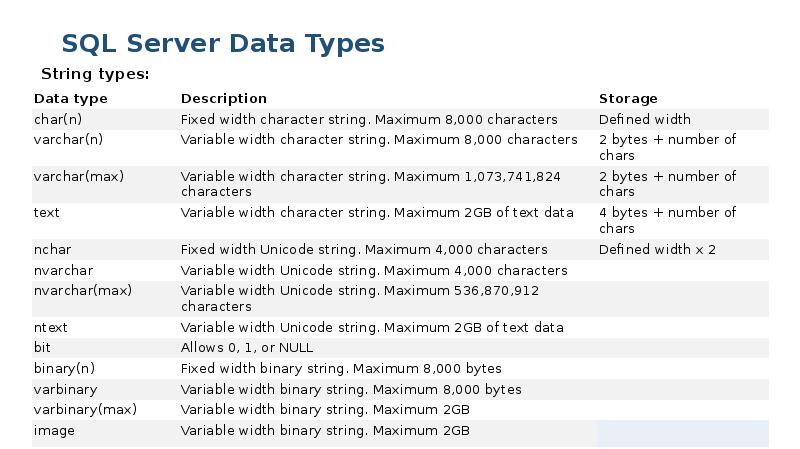
Строки символов
Строки символов имеют говорящее название: Эти типы данных используются для хранения символов. Они могут быть фиксированными или переменными по размеру.
- char : Строковые данные фиксированного размера, использующие статическую ячейку памяти. Идеально, когда вы знаете длину строки и все строки в столбце будут одинаковыми
- varchar : Строковые данные переменного размера, использующие расположение в динамической памяти. Используйте, если вы не уверены в длине строки или когда длина строк в столбце будет значительно различаться.
- текст : планируется удалить в будущих версиях SQL Server, разработан как тип данных переменной длины для данных, отличных от Unicode. Microsoft рекомендует заменить его на varchar (max).
 Используйте, если вы не уверены в длине строки или когда длина строк в столбце будет значительно различаться.
Используйте, если вы не уверены в длине строки или когда длина строк в столбце будет значительно различаться.Двоичные строки
Двоичные типы данных поддерживают фиксированные или переменные строки данных. Разница между символьными строками и двоичными строками заключается в данных, которые они содержат: символьные строки обычно хранят текст, но также могут хранить числа или символы. Двоичные строки обычно хранят нетрадиционные данные в виде байтов, например изображения.
- двоичный : Фиксированная длина, идеально подходит для использования, когда размеры данных в столбце согласованы.
- varbinary : Переменная длина идеальна, когда размеры данных в столбце значительно различаются. Изображение
- : планируется удалить в будущих версиях SQL Server, предназначенных для хранения двоичных данных переменной длины. Microsoft рекомендует заменить его на varbinary (max).
 Microsoft рекомендует заменить его на varbinary (max).
Microsoft рекомендует заменить его на varbinary (max).Дата и время
Эти типы данных специально предназначены для хранения даты и времени. Некоторые поддерживают знание часового пояса, а другие нет. При работе с датами и временем крайне важно выбрать тип данных, обеспечивающий единообразие формата записей, и тип данных, который достаточно гибок, чтобы поддерживать необходимый уровень детализации (например, время суток, часовой пояс и т. д.).
- дата : Определяет дату. Формат по умолчанию — ГГГГ-ММ-ДД, но его можно отформатировать более чем 20 различными способами, включая ДМГ, ДГМ и ГМД.
- datetimeoffset : Определяет дату и время суток. Этот тип данных учитывает часовой пояс.
- datetime2: расширение указанного выше типа данных с дополнительной точностью до долей секунды.
- datetime : Аналогично datetime2, но с меньшей точностью до долей секунды.
- малая дата и время : Определяет дату и время дня, но секунды всегда равны нулю.
- time: Определяет время суток, но без учета часового пояса.

Другие типы данных
В SQL Server существуют дополнительные типы данных, но они не вписываются ни в одну из вышеперечисленных категорий. По этой причине эти типы данных просто существуют под «другим». К другим типам данных относятся следующие:
- rowversion : используется для отметки версий строк в таблице. Простое возрастающее число, не сохраняющее дату и время.
- иерархический идентификатор : Тип системных данных переменной длины, используемый для представления положения в иерархии.
- uniqueidentifier : глобальный уникальный идентификатор (GUID), способный хранить до 16 байтов.
- sql_variant : Хранит различные типы данных, поддерживаемые SQL. Наиболее важной частью sql_variant является то, что она является переменной. Например, один столбец sql_variant может содержать целое число в одной строке и двоичное значение в другой. Для применения арифметических операций, таких как SUM или PRODUCT, тип должен быть сначала приведен к чему-то, что работает с этой операцией.
- xml : Хранит XML-данные.
- Типы пространственной геометрии : Представляет данные в плоской системе координат.
- Типы пространственной географии : Представляет данные в земной системе координат.
- таблица: специальный тип данных, используемый для хранения результатов для последующей обработки.
 Для применения арифметических операций, таких как SUM или PRODUCT, тип должен быть сначала приведен к чему-то, что работает с этой операцией.
Для применения арифметических операций, таких как SUM или PRODUCT, тип должен быть сначала приведен к чему-то, что работает с этой операцией.Определение пользовательских типов данных
Если у вас есть пользовательский тип данных, не относящийся ни к одной из перечисленных выше категорий, вы все равно можете перенести его на SQL Server, если вы настроили его заранее. Используя Transact-SQL или Microsoft .NET Framework, разработчики могут определять пользовательские типы данных для своих проектов.
При создании пользовательского типа данных в интерфейсе SQL Server есть несколько инструментов, помогающих создавать Transact-SQL. Поля, которые вам нужно будет указать, — это схема, имя, базовый тип данных, длина, допустимые значения NULL, размер в байтах, необязательные поля в значении по умолчанию и любые правила, которым должен следовать тип данных. Например, поле электронной почты, скорее всего, будет использовать базовый тип varchar и должно содержать символы @ и ., а также список запрещенных символов. Затем вы устанавливаете максимальную длину, соответствующую вашим потребностям, и количество байтов автоматически заполняется в интерфейсе.
Поля, которые вам нужно будет указать, — это схема, имя, базовый тип данных, длина, допустимые значения NULL, размер в байтах, необязательные поля в значении по умолчанию и любые правила, которым должен следовать тип данных. Например, поле электронной почты, скорее всего, будет использовать базовый тип varchar и должно содержать символы @ и ., а также список запрещенных символов. Затем вы устанавливаете максимальную длину, соответствующую вашим потребностям, и количество байтов автоматически заполняется в интерфейсе.
Microsoft предлагает дополнительную информацию, если вам нужно создать собственный тип данных.
Выбор правильного типа данных
При работе с SQL Server крайне важно выбрать правильный тип данных для любых данных, с которыми вы работаете. В противном случае это может привести к проблемам с качеством данных или потере данных, например, в случаях, когда вы используете тип данных для хранения даты и времени, когда он не предназначен для этого. Неправильный тип данных также может отрицательно сказаться на запросах и производительности.
Например, если вам нужно хранить целые числа, вы можете предположить, что не ошибетесь, просто выбрав точный числовой тип данных. Однако излишнее использование типа bigint для хранения небольшого простого числа, такого как возраст, приведет к напрасной трате ресурсов.
Большинство сказали бы вам выбирать между smallint, integer, bigint или decimal всякий раз, когда вы работаете с числовыми данными. Если вы имеете дело с очень большими числами, они могут предложить decfloat или float. Но этот совет слишком упрощенный и общий, когда вы имеете дело с конкретными вариантами использования.
Например, вы можете работать с системой инвентаризации, которая требует четырехзначных значений и ведущих нулей. Или вы можете хранить номера социального страхования, которые должны быть правильно отформатированы с дефисами как XXX-XX-XXXX. Как вы понимаете, существует множество сложных приложений для SQL Server, в которых общих рекомендаций недостаточно для выбора правильного типа данных.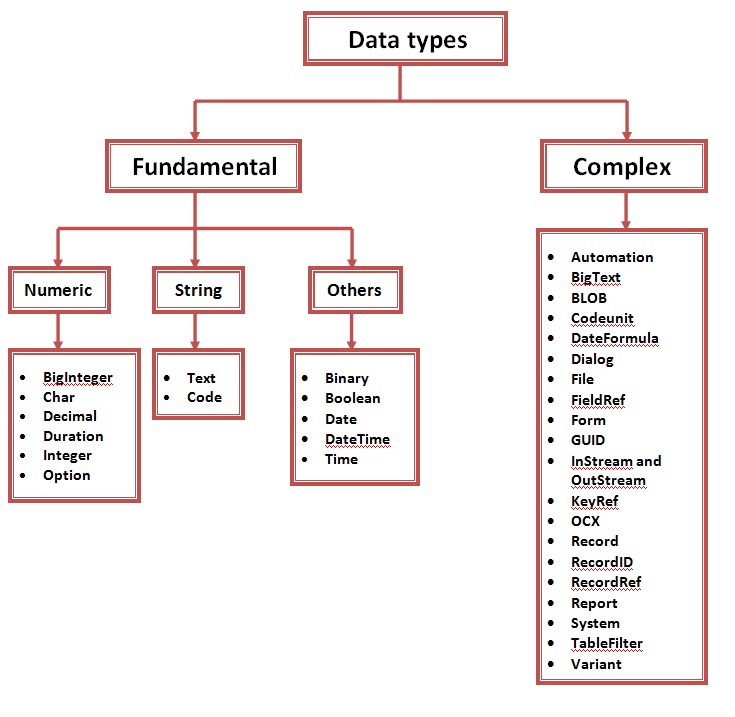 По этой причине знание всех доступных типов данных является первым шагом в выборе наилучшего типа данных для любой информации, которую вам нужно хранить. К счастью, вам не нужно запоминать все типы данных и их диапазон информации. У Microsoft есть отличная документация, которая проведет вас по всем обсуждаемым здесь типам данных, если вам когда-нибудь понадобится более подробная информация в будущем.
По этой причине знание всех доступных типов данных является первым шагом в выборе наилучшего типа данных для любой информации, которую вам нужно хранить. К счастью, вам не нужно запоминать все типы данных и их диапазон информации. У Microsoft есть отличная документация, которая проведет вас по всем обсуждаемым здесь типам данных, если вам когда-нибудь понадобится более подробная информация в будущем.
Влияние выбора типа данных SQL Server на производительность базы данных
Почему выбор типа данных SQL Server имеет значение
Энди Юн
Старший инженер по решениям
Знаете ли вы, что неправильный выбор типа данных может существенно повлиять на структуру и производительность вашей базы данных? Разработчики и администраторы баз данных могут повысить производительность базы данных, поняв типы данных, поддерживаемые SQL Server, и последствия выбора различных типов. Лучшей практикой является «правильный размер» типов данных, задавая бизнес-вопросы и определяя типы данных, которые лучше всего подходят для нужд организации и приложения.
Правильное определение размера может привести к значительной экономии памяти, что может привести к повышению производительности базы данных. Другими соображениями, которые следует учитывать, являются ограничение размера страницы данных SQL Server 8 КБ и условия, которые могут привести к разбиению страницы. Также следите за неявными преобразованиями, неприятным побочным продуктом несоответствия типов данных. Принятие мер по предотвращению несоответствий и разделения страниц может значительно повысить производительность.
Ниже приведены некоторые рекомендации по выбору правильного размера типов данных и повышению производительности базы данных.
Во-первых, давайте рассмотрим некоторые ключевые моменты, касающиеся типов данных SQL Server.
№1. В SQL Server типы данных с фиксированной и переменной длиной имеют разные требования к хранению
- Типы данных с фиксированной длиной всегда требуют одинакового объема памяти, независимо от значения, хранящегося в этих столбцах или переменных.

- Типы данных переменной ширины всегда имеют два дополнительных байта служебных данных.
- Для типов данных, начинающихся с N (NCHAR и NVARCHAR), N обозначает количество сохраняемых символов. Это N x 2. Поскольку NCHAR и NVARCHAR могут хранить информацию в формате Unicode, для каждого символа требуется два байта памяти.
- Если вы сохраняете значение, строковое значение, которое всегда будет коротким, или односимвольное значение, с точки зрения хранения лучше использовать CHAR(1) вместо VARCHAR(1). Даже если поле VARCHAR(1) пусто, для него все равно потребуется два байта памяти.
На следующей диаграмме представлена удобная сводка требований к хранилищу для типов данных фиксированной ширины и переменной длины:
#2. Формат FIXVAR — это фактический физический формат, который SQL Server использует для хранения записи 9.0021
#3. Столбцы с фиксированной шириной легко находят данные в записях, поскольку размер F-данных легко вычисляется.

Когда используются столбцы переменной ширины, SQL Server использует указатели, чтобы облегчить поиск данных. Если таблица полностью состоит из типов данных фиксированной ширины, для одной записи в этой таблице всегда будет требоваться определенный объем памяти.
#4. При выборе правильного размера типов данных рекомендуется проанализировать, является ли тип данных подходящим контейнером для значения, которое будет храниться.
Важно задать бизнес-вопросы о будущем направлении организации. Цель определения правильного размера — определить, подходит ли тип данных для приложения или бизнеса.
В следующей таблице приведены требования к хранилищу и диапазоны значений для различных типов данных:
Ниже приведены несколько примеров типов данных правильного размера для различных ситуаций:
#5. Правильный размер таблицы может привести к огромной экономии памяти
В приведенном ниже примере минимальный размер таблицы сотрудников правильного размера составляет 104 байта по сравнению с 1304 байтами в таблице сотрудников, размер которой не соответствует размеру.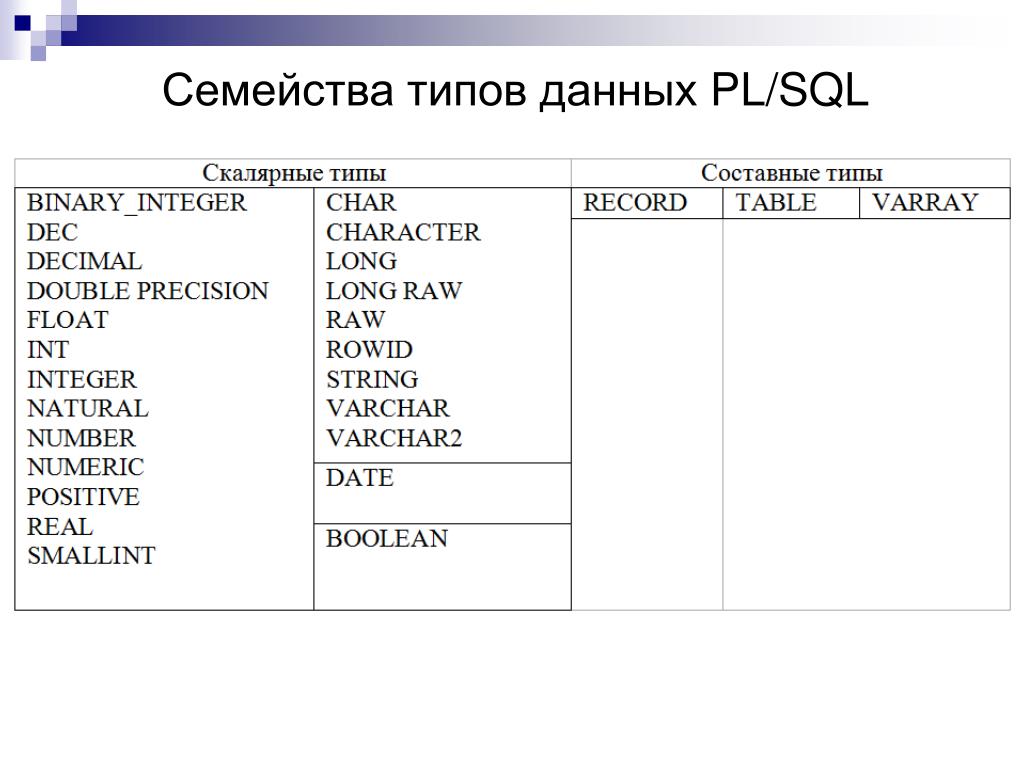
Вот таблица сотрудников правильного размера:
#6. SQL Server использует собственный контейнер, называемый страницей данных, для хранения записей на диске 9.0021
Существует три типа страниц данных: 1) данные в строке, 2) данные переполнения строки и 3) данные больших объектов. Все страницы имеют фиксированный размер 8 КБ или 8 192 байта.
Страницы данных состоят из трех компонентов: 1) 96-байтового заголовка страницы, 2) записей данных и 3) массива записей или слотов, который занимает 2 байта на запись.
Разработчики и администраторы баз данных должны знать следующую информацию:
- Ограничение в 8 КБ влияет на то, что может поместиться на странице данных. Как правило, данные хранятся в строке. Однако, если запись длиннее 8 КБ, это представляет проблему. Одна запись не может охватывать несколько страниц данных. В результате необходимо использовать страницы данных row-overflow или LOB.
- VARCHAR(8000) и NVARCHAR(4000) используют страницы данных переполнения строки
- VARCHAR(MAX) и NVARCHAR(MAX) используют страницы данных LOB
- Если строка превышает значение второй страницы данных размером 8 КБ, SQL Server создаст цепочку разных страниц. Это может привести к дополнительным требованиям к хранилищу и дополнительным затратам на ввод-вывод.
 Это может привести к дополнительным требованиям к хранилищу и дополнительным затратам на ввод-вывод.
Это может привести к дополнительным требованиям к хранилищу и дополнительным затратам на ввод-вывод.Помните, что SQL Server работает в пределах 8 КБ страницы данных, потому что это имеет реальные последствия при настройке производительности.
№ 7. Ведение журнала транзакций может снизить производительность SQL Server
Еще один момент, о котором следует помнить, — это активность в журнале транзакций. SQL Server записывает в журнал транзакций каждый раз, когда есть инструкция INSERT, UPDATE или DELETE. Объем записанного журнала транзакций пропорционален объему работы, выполненной SQL Server.
Чем больше работы выполняется на сервере с ведением журнала транзакций, тем больше времени требуется для выполнения запросов. Том журнала транзакций также влияет на резервное копирование/восстановление, репликацию, доставку журналов, зеркалирование и группы доступности. В системах с большим количеством транзакций ведение журнала транзакций увеличивает конкуренцию за ресурсы. Важно помнить, что все операции ввода-вывода превращаются в дополнительную работу для SQL Server.
Важно помнить, что все операции ввода-вывода превращаются в дополнительную работу для SQL Server.
#8: Разбиение страниц требует больших затрат с точки зрения хранения, и его лучше по возможности избегать
Если таблица SQL Server кластеризована и имеет кластеризованный индекс, может произойти разбиение страниц. Если новая запись вставляется в уже заполненную страницу данных, SQL Server выделяет другую страницу в другом месте. Он берет около половины записей данных с исходной страницы, перемещает их на новую страницу и снова пытается вставить новую запись. Если новая запись по-прежнему не подходит, SQL Server создаст еще одно разделение страниц. Каскадные разбиения страниц могут быть очень дорогими с точки зрения хранения.
Хотя разделение страниц обычно происходит только в кластеризованных таблицах и только при выполнении операций INSERT, существуют ситуации, которые могут привести к непреднамеренному разбиению страниц. Например:
- Обновление столбца переменной длины . Разделение страниц также может произойти при обновлении столбца переменной длины. Если запись не может быть обновлена на месте или в другом месте на той же странице, операция UPDATE становится DELETE и INSERT. Затем операция INSERT запускает разделение страницы.
 Разделение страниц также может произойти при обновлении столбца переменной длины. Если запись не может быть обновлена на месте или в другом месте на той же странице, операция UPDATE становится DELETE и INSERT. Затем операция INSERT запускает разделение страницы.
Разделение страниц также может произойти при обновлении столбца переменной длины. Если запись не может быть обновлена на месте или в другом месте на той же странице, операция UPDATE становится DELETE и INSERT. Затем операция INSERT запускает разделение страницы.- Использование GUID для кластеризации ключей. Если выполняется много одноэлементных операций INSERT и для ключа кластеризации используется GUID, весьма вероятно, что разделение страниц будет происходить почти при каждой операции INSERT.
Я рекомендую создать следующие ключи кластеризации:
- Узкий . Это экономит место.
- Уникальный . Ключ кластеризации не должен повторяться.
- Статический . Ключ для данной записи всегда должен оставаться одним и тем же.
- Постоянно возрастающий . Если ключ кластеризации постоянно увеличивается, горячая точка находится в конце последовательности ключей кластеризации, поэтому разделение страниц не происходит в середине последовательности.

Автоматически увеличивающиеся целые числа и автоматически увеличивающиеся большие целые числа соответствуют этим четырем критериям.
У некоторых команд возникает соблазн использовать NEWSQUENTIALID(). Это приводит к автоинкрементному GUID. Когда организация устанавливает исправления для своих серверов SQL, она должна перезагрузить базовый сервер Windows. Затем начальная точка NEWSEQUENTIALID() сбрасывается на другое значение. Это потенциально опасно и очень рискованно. Если команда действительно хочет использовать идентификаторы GUID, рекомендуется разделить ключ кластеризации и первичный ключ.
#9: Неявные преобразования в SQL Server могут привести к снижению производительности
В SQL Server, если два поля имеют разные типы данных, их значения не считаются одинаковыми, даже если они кажутся идентичными для стороннего наблюдателя. Преобразования значений в SQL Server следуют предустановленным правилам приоритета. Небольшие типы данных всегда преобразуются с повышением частоты в более крупные типы данных. Затем SQL Server может сравнить значения. Это влияет на производительность кода T-SQL.
Затем SQL Server может сравнить значения. Это влияет на производительность кода T-SQL.
Вот таблица с описанием правил приоритета:
Ниже приведены некоторые дополнительные моменты, которые следует учитывать при неявных преобразованиях. При несоответствии типов данных SQL Server требует гораздо больше усилий для выполнения запросов. Если вы измените несколько типов данных и сопоставите их, вы сможете значительно повысить производительность.
- Некоторые преобразования бесплатны . К ним относятся преобразования между CHAR и VARCHAR, а также преобразования между NCHAR и NVARCHAR.
- Использовать UNICODE или не использовать UNICODE — все зависит от компромиссов . Если вы по умолчанию используете VARCHAR, данные могут быть потеряны, и вам может потребоваться рефакторинг. Если вы используете NVARCHAR, требования к хранилищу и вводу-выводу удваиваются.
- Использование NVARCHAR(500) может увеличить стоимость планов выполнения SQL Server . Когда SQL Server создает план выполнения, он использует затраты и оценки. Одной из оценок, используемых в алгоритме, является средний размер строки. С типом данных переменной ширины SQL Server не знает средний размер строки и не запрашивает данные. Вместо этого он принимает определение типа данных. Если вы используете NVARCHAR(500) в качестве определения типа данных, это может раздуть план выполнения.
 Когда SQL Server создает план выполнения, он использует затраты и оценки. Одной из оценок, используемых в алгоритме, является средний размер строки. С типом данных переменной ширины SQL Server не знает средний размер строки и не запрашивает данные. Вместо этого он принимает определение типа данных. Если вы используете NVARCHAR(500) в качестве определения типа данных, это может раздуть план выполнения.
Когда SQL Server создает план выполнения, он использует затраты и оценки. Одной из оценок, используемых в алгоритме, является средний размер строки. С типом данных переменной ширины SQL Server не знает средний размер строки и не запрашивает данные. Вместо этого он принимает определение типа данных. Если вы используете NVARCHAR(500) в качестве определения типа данных, это может раздуть план выполнения.- Существуют инструменты для поиска неявных преобразований . Джонатан Кехайяс написал код для сканирования кеша плана выполнения и поиска кода, который страдает от неявных преобразований. Хотя этот инструмент полезен, не рекомендуется запускать его для производственной базы данных.
Высокая производительность базы данных начинается с выбора правильного типа данных
Разработчики и администраторы баз данных могут повысить производительность базы данных, начав с типов данных правильного размера. Выбор подходящего типа данных может оказать существенное влияние на экономию памяти.