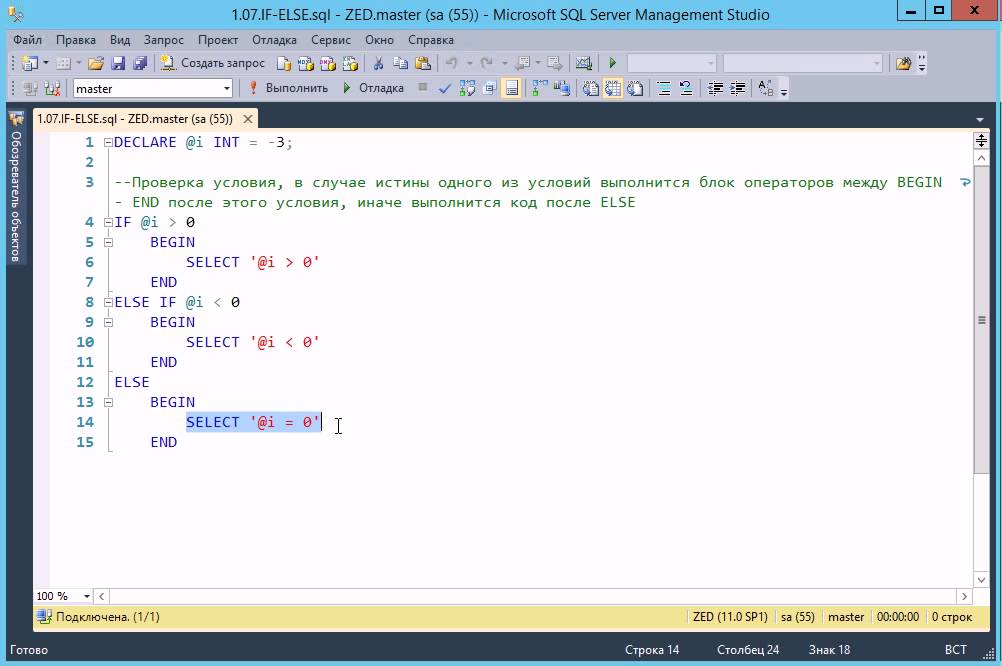
Цикл ms sql: MS SQL Server и T-SQL
Содержание
Циклы в ассемблере. — it-black.ru
Циклы в ассемблере. — it-black.ru
Перейти к содержимому
В любом языке программирования, как и в языке Assembler, циклом называется повторяющееся выполнение последовательности команд. Рассмотрим сегодня как организовывать циклы в Assemblere.
Команда LOOP
Для организации цикла предназначена команда LOOP. У этой команды один операнд — имя метки, на которую осуществляется переход. В качестве счётчика цикла используется регистр CX. Команда LOOP выполняет декремент CX, а затем проверяет его значение. Если содержимое CX не равно нулю, то осуществляется переход на метку, иначе управление переходит к следующей после LOOP команде.
Содержимое CX интерпретируется командой как положительное число. В CX нужно помещать число, равное требуемому количеству повторений цикла. Метка должна находиться в диапазоне -127…+128 байт от команды LOOP (иначе будет ошибка).
Метка представляет собой символическое имя, вместо которого компилятор подставляет адрес. Имена переменных, объявленных с помощью директив объявления данных, тоже являются метками. Но с ними компилятор дополнительно связывает размер переменной. Метка объявляется очень просто: достаточно в начале строки написать имя и поставить двоеточие. Например:
m1: mov ax,4C00h
int 21h
Теперь вместо имени m1 компилятор везде будет подставлять адрес команды mov ax,4C00h. Имя метки может состоять из латинских букв, цифр и символов подчёркивания, но должно начинаться с буквы. Имя метки должно быть уникальным. В качестве имени метки нельзя использовать директивы и ключевые слова компилятора, названия команд и регистров.
Пример цикла
В качестве примера напишем простую программу, которая будет печатать все буквы английского алфавита. ASCII-коды этих символов расположены последовательно, поэтому можно выводить их в цикле. Для вывода символа на экран используется функция DOS 02h (выводимый байт должен находиться в регистре DL).
Для вывода символа на экран используется функция DOS 02h (выводимый байт должен находиться в регистре DL).
use16 ;Генерировать 16-битный код
org 100h ;Программа начинается с адреса 100h
mov ah,02h ;Для вызова функции DOS 02h - вывод символа
mov dl,'A' ;Первый выводимый символ
mov cx,26 ;Счётчик повторений цикла
metka:
int 21h ;Обращение к функции DOS
inc dl ;Следующий символ
loop metka ;Команда цикла
mov ah,09h ;Функция DOS 09h - вывод строки
mov dx,press ;В DX адрес строки
int 21h ;Обращение к функции DOS
mov ah,08h ;Функция DOS 08h - ввод символа без эха
int 21h ;Обращение к функции DOS
mov ax,4C00h ;\
int 21h ;/ Завершение программы
;-------------------------------------------------------
press:
db 13,10,'Press any key. ..$'
..$'
 ..$'
..$'
Команды «int 21h» и «inc dl» будут выполняться в цикле 26 раз. Для того, чтобы программа не закрылась сразу, используется функция DOS 08h — ввод символа с клавиатуры без эха, то есть вводимый символ не отображается.
Вложенные циклы
Вложенный цикл — это цикл внутри другого цикла. Чтобы сделать вложенный цикл необходимо сохранить значение CX перед началом вложенного цикла и восстановить после его завершения (перед командой LOOP внешнего цикла). Сохранить значение можно в другой регистр, во временную переменную или в стек. Следующая программа выводит все доступные ASCII-символы в виде таблицы 16×16. Значение счётчика внешнего цикла сохраняется в регистре BX.
use16 ;Генерировать 16-битный код
org 100h ;Программа начинается с адреса 100h
mov ah,02h ;Для вызова функции DOS 02h - вывод символа
sub dl,dl ;Первый выводимый символ
mov cx,16 ;Счётчик внешнего цикла (по строкам)
lp1:
mov bx,cx ;Сохраняем счётчик в BX
mov cx,16 ;Счётчик внутреннего цикла (по столбцам)
lp2:
int 21h ;Обращение к функции DOS
inc dl ;Следующий символ
loop lp2 ;Команда внутреннего цикла
mov dh,dl ;Сохраняем значение DL в DH
mov dl,13 ;\
int 21h ; \
mov dl,10 ; / Переход на следующую строку
int 21h ;/
mov dl,dh ;Восстанавливаем значение DL
mov cx,bx ;Восстанавливаем значение счётчика
loop lp1 ;Команда внешнего цикла
mov ah,09h ;Функция DOS 09h - вывод строки
mov dx,press ;В DX адрес строки
int 21h ;Обращение к функции DOS
mov ah,08h ;Функция DOS 08h - ввод символа без эха
int 21h ;Обращение к функции DOS
mov ax,4C00h ;\
int 21h ;/ Завершение программы
;-------------------------------------------------------
press db 13,10,'Press any key. ..$'
 ..$'
..$'
Виктор Черемных
16 августа, 2017
One Comment
Группа в VK
Обнаружили опечатку?
Сообщите нам об этом, выделите текст с ошибкой и нажмите Ctrl+Enter, будем очень признательны!
Свежие статьи
Облако меток
Похожие статьи
Команды работы с битами.
Работать с отдельными битами операндов можно, используя логические операции и сдвиги. Также в системе команд x86 существуют специальные команды для работы с битами: это команды
Основы создания макросов в Assembler.
Макросы — это шаблоны для генерации кода. Один раз создав макрос, можно использовать его во многих местах в коде программы. Макросы делают процесс программирования на
Один раз создав макрос, можно использовать его во многих местах в коде программы. Макросы делают процесс программирования на
Синтаксис объявления меток.
Метка в ассемблере – это символьное имя, обозначающее ячейку памяти, которая содержит некоторую команду. Метка может содержать следующие символы: Буквы (от A до Z и
Локальные переменные.
Локальные переменные в Assembler используются для хранения промежуточных результатов во время выполнения процедуры. В отличие от глобальных, эти переменные являются временными и создаются при запуске
Vk
Youtube
Telegram
Odnoklassniki
Полезно знать
Рубрики
Авторы
Что может подстерегать новичков при работе с SQL Server
В свое время я зачитывался Рихтером и усиленно штудировал Шилдта. Думал, что буду заниматься разработкой под .NET, но судьба на первом месяце работы распорядилась иначе. Один из сотрудников неожиданно покинул проект, и во вновь образовавшуюся дыру докинули свежего людского материала. Именно тогда и началось мое знакомство с SQL Server.
Думал, что буду заниматься разработкой под .NET, но судьба на первом месяце работы распорядилась иначе. Один из сотрудников неожиданно покинул проект, и во вновь образовавшуюся дыру докинули свежего людского материала. Именно тогда и началось мое знакомство с SQL Server.
С тех пор прошло чуть меньше 6 лет, и вспомнить можно многое… Про бывшего клиента Джозефа из Англии, который переосмыслил жизнь за время отпуска в Таиланде, и в моем скайпе стал подписываться Жозефиной. Про веселых соседей по офису, с которыми приходилось сидеть в одной комнате: один страдал от аллергии на свежий воздух, а другой маялся от неразделенной любви к С++, дополняя это аллергией на солнечный свет. Чего только не было… Один раз по команде свыше пришлось на время стать Александром, отцом двух детей, и изображать из себя обросшего скилами сениора по JS. Но самый лютый треш, наверное, связан с историей про резиновую утку-пищалку. Один коллега снимал ею стресс и, однажды, в порыве эмоций, отгрыз ей голову. С тех пор уточка потеряла прежний лоск и вскоре была заменена на мячик, который он пытался иногда грызть… увы, уже безуспешно.
С тех пор уточка потеряла прежний лоск и вскоре была заменена на мячик, который он пытался иногда грызть… увы, уже безуспешно.
К чему это было рассказано? Если хотите посвятить свою жизнь работе с базами данных, то первое чему нужно научиться — это стрессоустойчивости. Второе — взять на вооружение несколько правил при написании запросов на T-SQL, которые многие из начинающих разработчиков не знают или игнорируют, а потом сидят и ломают голову: «Почему что-то не работает?»
NOT IN vs NULL
Долго думал, с какого примера стоило бы начать. Бесспорный лидер среди вопросов на собеседовании Junior DB Developer — конструкция NOT IN.
Например, нужно написать запрос, который вернет всем записи из первой таблицы, которых нет во второй. Очень часто начинающие разработчики не заморачиваются и используют NOT IN:
DECLARE @t1 TABLE (a INT) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (b INT) INSERT INTO @t2 VALUES (1) SELECT * FROM @t1 WHERE a NOT IN (SELECT b FROM @t2)
Запрос вернул нам двойку. Давайте теперь во вторую таблицу добавим еще одно значение — NULL:
Давайте теперь во вторую таблицу добавим еще одно значение — NULL:
INSERT INTO @t2 VALUES (1), (NULL)
При выполнении мы не получим никаких результатов. Поменяем NOT IN на IN и сможем увидеть какую-то магию — IN работает, а NOT IN отказывается. Это первое, что нужно «понять и простить» при работе с SQL Server, который при операции сравнения руководствуется третичной логикой: TRUE, FALSE, UNKNOWN.
При выполнении SQL Server интерпретирует условие IN:
a IN (1, NULL) === a=1 OR a=NULL
NOT IN:
a NOT IN (1, NULL) === a<>1 AND a<>NULL
При сравнении любого значения с NULL возвращается UNKNOWN. 1=NULL, NULL=NULL. Результат будет один — UNKNOWN. А поскольку у нас в условии используется оператор AND, то все выражение вернет неопределенное значение.
Скажу честно, написано реально скучно. Но важно понимать, что такая ситуация встречается достаточно часто. Хороший пример из жизни: раньше колонка была NOT NULL, потом какой-то добрый человек разрешил записывать в нее NULL значение. Итог: у клиента перестает работать отчет после того, как в таблицу попадет хотя бы одно NULL значение.
Итог: у клиента перестает работать отчет после того, как в таблицу попадет хотя бы одно NULL значение.
Что делать? Можно явно отбрасывать NULL значения:
SELECT * FROM @t1 WHERE a NOT IN ( SELECT b FROM @t2 WHERE b IS NOT NULL )
Можно использовать EXCEPT:
SELECT * FROM @t1 EXCEPT SELECT * FROM @t2
Если нет желания много думать, то проще использовать NOT EXISTS:
SELECT * FROM @t1 WHERE NOT EXISTS( SELECT * FROM @t2 WHERE a = b )
Какой вариант запроса более оптимальный? Чуточку предпочтительнее выглядит последний вариант с NOT EXISTS, который генерирует более оптимальный predicate pushdown оператор при доступе к данным из второй таблицы.
Date Format
Еще часто спотыкаются на различных нюансах с типами данных. Например, нужно получить текущее время. Выполнили функцию GETDATE. Скопировали результат и вставили его в запрос. Корректно ли так делать? Дата задается строковой константой, и в некоторой степени SQL Server позволяет вольности при ее написании:
SET DATEFORMAT DMY DECLARE @d1 DATETIME = '05/12/2016' , @d2 DATETIME = '2016/12/05' , @d3 DATETIME = '2016-12-05' , @d4 DATETIME = '05-dec-2016' SELECT @d1, @d2, @d3, @d4
Все значения однозначно интерпретируются:
----------- ----------- ----------- ----------- 2016-12-05 2016-05-12 2016-05-12 2016-12-05
И это не будет приводить к проблемам до тех пор, пока бизнес-логику не начнут выполнять на другом сервере, на котором настройки могут отличаться:
SET DATEFORMAT DMY DECLARE @d1 DATETIME = '05/12/2016' , @d2 DATETIME = '2016/12/05' , @d3 DATETIME = '2016-12-05' , @d4 DATETIME = '05-dec-2016' SELECT @d1, @d2, @d3, @d4
Первый вариант может привести к неверному толкованию даты:
----------- ----------- ----------- ----------- 2016-05-12 2016-12-05 2016-12-05 2016-12-05
Более того, подобный код может привести к ошибке. Например, нам нужно вставить данные в таблицу. На тестовом сервере все прекрасно работает:
Например, нам нужно вставить данные в таблицу. На тестовом сервере все прекрасно работает:
DECLARE @t TABLE (a DATETIME)
INSERT INTO @t VALUES ('05/13/2016')А у клиента, из-за разницы настройках сервера, вот такой запрос будет приводить к проблемам:
DECLARE @t TABLE (a DATETIME)
SET DATEFORMAT DMY
INSERT INTO @t VALUES ('05/13/2016')Msg 242, Level 16, State 3, Line 28The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
Так в каком же формате задавать константы для дат? Давайте посмотрим на еще один пример:
SET DATEFORMAT YMD SET LANGUAGE English DECLARE @d1 DATETIME = '2016/01/12' , @d2 DATETIME = '2016-01-12' , @d3 DATETIME = '12-jan-2016' , @d4 DATETIME = '20160112' SELECT @d1, @d2, @d3, @d4 GO SET LANGUAGE Deutsch DECLARE @d1 DATETIME = '2016/01/12' , @d2 DATETIME = '2016-01-12' , @d3 DATETIME = '12-jan-2016' , @d4 DATETIME = '20160112' SELECT @d1, @d2, @d3, @d4 GO
В зависимости от установленного языка, константы также могут по-разному интерпретироваться:
----------- ----------- ----------- ----------- 2016-01-12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- ----------- 2016-12-01 2016-12-01 2016-01-12 2016-01-12
И напрашивается вывод использовать последние два варианта. Сразу скажу, что задавать месяц явно — это хорошая возможность наткнуться на «же не манж па сис жур» ошибку:
Сразу скажу, что задавать месяц явно — это хорошая возможность наткнуться на «же не манж па сис жур» ошибку:
SET LANGUAGE French DECLARE @d DATETIME = '12-jan-2016'
Msg 241, Level 16, State 1, Line 29Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Итого — остается последний вариант. Если хотите, чтобы константы с датами однозначно толковались в системе вне зависимости от настроек и фазы Луны, то указывайте их в формате ISO (yyyyMMdd) без всяких тильд, кавычек и слешей.
Еще стоит обратить внимание на различие в поведении некоторых типов данных:
SET LANGUAGE English SET DATEFORMAT YMD DECLARE @d1 DATE = '2016-01-12' , @d2 DATETIME = '2016-01-12' SELECT @d1, @d2 GO SET LANGUAGE Deutsch SET DATEFORMAT DMY DECLARE @d1 DATE = '2016-01-12' , @d2 DATETIME = '2016-01-12' SELECT @d1, @d2
Тип DATE, в отличие от DATETIME, корректно интерпретируется при различных настройках на сервере:
---------- ---------- 2016-01-12 2016-01-12 ---------- ---------- 2016-01-12 2016-12-01
Но нужно ли держать этот нюанс в голове? Вряд ли. Главное помните, что задавать даты нужно в формате ISO, остальное уже от лукавого.
Главное помните, что задавать даты нужно в формате ISO, остальное уже от лукавого.
Date Filter
Далее рассмотрим, как фильтровать эффективно данные. Почему-то на DATETIME столбцы приходится наибольшее число костылей, так что с этого типа данных мы и начнем:
USE AdventureWorks2014 GO UPDATE TOP(1) dbo.DatabaseLog SET PostTime = '20140716 12:12:12'
Теперь попробуем узнать, сколько строк вернет запрос за определенный день:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime = '20140716'
Запрос вернет 0. Почему? При построении плана SQL Server пытается преобразовать строковую константу к типу данных столбца, по которому идет фильтрация:
Есть правильные и неправильные варианты вывести требуемые данные. Например, обрезать время:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CAST(PostTime AS DATE) = '20140716'
Или задать диапазон:
SELECT COUNT_BIG(*) FROM dbo.
 DatabaseLog
WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140716' AND PostTime < '20140717'
DatabaseLog
WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'
SELECT COUNT_BIG(*)
FROM dbo.DatabaseLog
WHERE PostTime >= '20140716' AND PostTime < '20140717'Именно последние два запроса более правильными с точки зрения оптимизации. И дело в том, что все преобразования и вычисления на колонках, по которым идет поиск, может резко снижать производительность, но об этом чуть позже.
Поле PostTime не входит в индекс, и особого эффекта от использования «правильного» подхода при фильтрации нам не увидеть. Другое дело, когда нам нужно вывести данные за месяц. Чего только не приходилось видеть:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE DATEPART(YEAR, PostTime) = 2014 AND DATEPART(MONTH, PostTime) = 7 SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE YEAR(PostTime) = 2014 AND MONTH(PostTime) = 7 SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE EOMONTH(PostTime) = '20140731' SELECT COUNT_BIG(*) FROM dbo.
 DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'
DatabaseLog
WHERE PostTime >= '20140701' AND PostTime < '20140801'И опять же, последний вариант более приемлем, чем все остальные. Кроме того, всегда можно сделать вычисляемое поле и создать на его основе индекс:
ALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED GO CREATE INDEX ix ON dbo.DatabaseLog (MonthLastDay) GO SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE MonthLastDay = '20140731'
В сравнении с прошлым запросом разница в логических чтениях будет очень существенная:
Table 'DatabaseLog'. Scan count 1, logical reads 782, ...Table 'DatabaseLog'. Scan count 1, logical reads 7, ...
Но суть не в этом. Как я уже говорил, любые вычисления на индексных полях снижают производительность и приводят к увеличению логических чтений:
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID * 2 = 10000 SELECT BusinessEntityID FROM Person.
 Person
WHERE BusinessEntityID = 5000
Person
WHERE BusinessEntityID = 5000Table 'Person'. Scan count 1, logical reads 67, ...Table 'Person'. Scan count 0, logical reads 3, ...
Если взглянуть на планы выполнения, то в первом случае SQL Server приходится выполнить IndexScan:
Во втором же случае мы увидим IndexSeek:
Convert Implicit
Теперь поговорим про такую редиску, как convert implicit, но для начала пример:
USE AdventureWorks2014 GO SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 30845 SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = '30845'
Смотрим на планы выполнения:
В первом случае — предупреждение и IndexScan, во втором — все хорошо. Что произошло? Столбец NationalIDNumber имеет тип данных NVARCHAR(15). Константу, по значению которой необходимо отфильтровать данные, мы передаем как INT. В итоге получаем неявное преобразование типов, которые может снижать производительность.
Решение достаточно простое — нужно контролировать, чтобы типы данных при сравнении совпадали. Особенно это актуально при использовании EntityFramework.
LIKE ’%…%’
Что еще нужно знать? Даже когда у вас есть покрывающий индекс, еще не факт что он будет эффективно использоваться. Классический пример: вывести все строки, которые начинаются с …
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT AddressLine1 FROM Person.[Address] WHERE SUBSTRING(AddressLine1, 1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE LEFT(AddressLine1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE CAST(AddressLine1 AS CHAR(3)) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '100%'
Логические чтения:
Table 'Address'. Scan count 1, logical reads 216, ...Table 'Address'. Scan count 1, logical reads 216, ...Table 'Address'. Scan count 1, logical reads 216, ...Table 'Address'. Scan count 1, logical reads 4, ...
Scan count 1, logical reads 4, ...
Планы выполнения, по которым можно быстро найти победителя:
Результат является итогом, о чем мы говорили до этого. Если есть индекс, то на нем не должно быть никаких вычислений и преобразований типов, функций и прочего. Только тогда он будет эффективно использоваться при выполнении запроса.
Но что если нужно найти все вхождения подстроки в строку? Это задачка уже явно интереснее:
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
Но сначала нам нужно узнать много чего занимательного про строки и их свойства.
Первое, что нужно помнить — строки бывают UNICODE и ANSI. Для первых предусмотрены типы данных NVARCHAR/NCHAR (по 2 байта на символ). Для хранения ANSI строк — VARCHAR/CHAR (1 байт — 1 символ). Есть еще TEXT/NTEXT, но про них лучше забыть изначально. И вроде бы на этом можно было закончить, но нет…
Если в запросе задается юникодная константа, то перед ней нужно обязательно ставить символ N. Чтобы показать разницу, достаточно простого запроса:
Чтобы показать разницу, достаточно простого запроса:
SELECT '致死罪 ANSI', N'致死罪 UNICODE'
---------- ------------- ??? ANSI 致死罪 UNICODE
Если не указывать N перед константой, то SQL Server будет пытаться искать подходящий символ в ANSI кодировке. Если не найдет, то подставит знак вопроса.
COLLATE
Вспомнился один очень интересный пример, который любят спрашивать при собеседовании на позицию Middle/Senior DB Developer. Вернет ли данные следующий запрос?
DECLARE @a NCHAR(1) = 'Ё' , @b NCHAR(1) = 'Ф' SELECT @a, @b WHERE @a = @b
И да… и нет… Тут как повезет. Обычно я так отвечаю.
Почему такой неоднозначный ответ? Во-первых, перед строковым константами не стоит N, поэтому они будут толковаться как ANSI. Второе — очень многое зависит от текущего COLLATE, который является набором правил при сортировки и сравнении строковых данных.
USE [master]
GO
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CI_AS
GO
USE test
GO
DECLARE
@a NCHAR(1) = 'Ё'
, @b NCHAR(1) = 'Ф'
SELECT @a, @b
WHERE @a = @bПри таком COLLATE вместо кириллицы мы получим знаки вопросов, потому что символы знака вопроса равны между собой:
---- ---- ? ?
Стоит нам поменять COLLATE на какой-нибудь другой:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
И запрос уже не вернет ничего, потому что кириллица будет правильно интерпретироваться. Поэтому мораль тут простая: если строковая константа должна принимать UNICODE, то не надо лениться ставить N перед ней. Есть еще и обратная сторона медали, когда N лепиться везде, где можно, и оптимизатору приходится выполнять преобразования типов, которые, как я уже говорил, приводят к неоптимальным планам выполнения.
Поэтому мораль тут простая: если строковая константа должна принимать UNICODE, то не надо лениться ставить N перед ней. Есть еще и обратная сторона медали, когда N лепиться везде, где можно, и оптимизатору приходится выполнять преобразования типов, которые, как я уже говорил, приводят к неоптимальным планам выполнения.
Что еще я забыл упомянуть про строки? Еще один хороший вопрос из цикла «давайте проведем собеседование»:
DECLARE @a VARCHAR(10) = 'TEXT' , @b VARCHAR(10) = 'text' SELECT IIF(@a = @b, 'TRUE', 'FALSE')
Эти строки равны? И да… и нет… Опять ответил бы я.
Если мы хотим однозначного сравнения, то нужно явно указывать COLLATE:
DECLARE @a VARCHAR(10) = 'TEXT' , @b VARCHAR(10) = 'text' SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Потому что COLLATE могут быть как регистрозависимыми (CS), так и не учитывать регистр (CI) при сравнении и сортировке строк. Разные COLLATE у клиента и на тестовой базе — это потенциальный источник не только логических ошибок в бизнес-логике. .. Еще веселее, когда COLLATE между целевой базой и tempdb не совпадают.
.. Еще веселее, когда COLLATE между целевой базой и tempdb не совпадают.
Создадим базу с COLLATE, отличным от дефолтного:
USE [master]
GO
IF DB_ID('db') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Albanian_100_CS_AS
GO
USE test
GO
CREATE TABLE t (c CHAR(1))
INSERT INTO t VALUES ('a')
GO
IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL
DROP TABLE #t1
IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL
DROP TABLE #t2
IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL
DROP TABLE #t3
GO
CREATE TABLE #t1 (c CHAR(1))
INSERT INTO #t1 VALUES ('a')
CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)
INSERT INTO #t2 VALUES ('a')
SELECT 'a' AS c
INTO #t3
DECLARE @t TABLE (c VARCHAR(100))
INSERT INTO @t VALUES ('a')
SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation')
UNION ALL
SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')
UNION ALL
SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t
UNION ALL
SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1
UNION ALL
SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2
UNION ALL
SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3
UNION ALL
SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @tПри создании таблицы COLLATE наследуется от базы данных. Единственное отличие — для первой временной таблицы, для которой мы явно определяем структуру без указания COLLATE. В этом случае она наследует COLLATE от базы tempdb.
Единственное отличие — для первой временной таблицы, для которой мы явно определяем структуру без указания COLLATE. В этом случае она наследует COLLATE от базы tempdb.
Сейчас остановимся на нашем примере, потому что если COLLATE не совпадают — это может привести к потенциальным проблемам. Например, данные не будут правильно фильтроваться из-за того, что COLLATE может не учитывать регистр:
SELECT * FROM #t1 WHERE c = 'A'
Либо SQL Server будет ругаться на невозможность соединения таблиц из-за различающихся COLLATE:
SELECT * FROM #t1 JOIN t ON [#t1].c = t.c
Последний пример очень часто встречается. На тестовом сервере все идеально, а когда развернули бэкап на сервере клиента, то получаем ошибку:
Msg 468, Level 16, State 9, Line 93Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.
После чего приходится везде делать костыли:
SELECT * FROM #t1 JOIN t ON [#t1].
 c = t.c COLLATE database_default
c = t.c COLLATE database_defaultBINARY COLLATE
Теперь, когда «ложка дегтя» пройдена, посмотрим, как можно использовать COLLATE с пользой для себя. Помните пример про поиск подстроки в строке?
USE AdventureWorks2014 GO SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
Данный запрос можно оптимизировать и сократить его выполнения. Но для того, чтобы была видна разница, нам нужно сгенерировать большую таблицу:
USE [master]
GO
IF DB_ID('db') IS NOT NULL BEGIN
ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE test
END
GO
CREATE DATABASE test COLLATE Latin1_General_100_CS_AS
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB)
GO
ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 40MB)
GO
USE test
GO
CREATE TABLE t (
ansi VARCHAR(100) NULL
, unicod NVARCHAR(100) NULL
)
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO t
SELECT v, v
FROM (
SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '')
FROM E8
) t
GOСоздадим вычисляемые столбцы с бинарными COLLATE, не забыв при этом создать индексы:
ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2 ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2 CREATE NONCLUSTERED INDEX ansi ON t (ansi) CREATE NONCLUSTERED INDEX unicod ON t (unicod) CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin) CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin) GO
Далее выполняем фильтрацию:
SET STATISTICS TIME ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME OFF
И можем увидеть результаты выполнения, которые приятно удивят:
SQL Server Execution Times: CPU time = 250 ms, elapsed time = 254 ms.
SQL Server Execution Times: CPU time = 235 ms, elapsed time = 255 ms.
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 17 ms.
SQL Server Execution Times: CPU time = 16 ms, elapsed time = 17 ms.
Вся суть в том, что поиск на основе бинарного сравнения происходит намного быстрее, и если нужно часто и быстро искать вхождение строк, то данные можно хранить с COLLATE, которые заканчивается на BIN.
ISNULL и COALESCE
Идем дальше. Что еще потенциально интересного? Есть две функции: ISNULL и COALESCE. С одной стороны все просто — если первый оператор NULL, то вернуть второй оператор или следующий, если мы говорим про COALESCE. С другой стороны, есть коварное различие между ними. Что вернут эти функции?
DECLARE @a CHAR(1) = NULL SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL') DECLARE @i INT = NULL SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.
 1)
1)Ответ и вправду не очень очевидный:
---- ---- N NULL ---- ---- 7 7.1
Почему? Функция ISNULL преобразует к наименьшему типу из двух операндов. COALESCE преобразует к наибольшему типу. Вот мы и получаем такую радость, над которой я в первый раз очень долго просидел в попытках понять, «что не так».
Math
Еще интереснее, когда сталкиваешься с математикой на SQL Server. Вроде бы разницы не должно быть:
SELECT 1 / 3 SELECT 1.0 / 3
Но по факту оказывается, что она есть — все зависит от того, какие данные участвуют в запросе. Если целочисленные, то и результат будет целочисленным:
----------- 0 ----------- 0.333333
Еще интересный пример, который часто встречается на собеседованиях в том или ином виде:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val) , AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) FROM ( VALUES (1), (2), (2), (NULL), (NULL) ) t (val)
Что вернет запрос? COUNT(*)/COUNT(1) вернет общее число строк. COUNT по столбцу вернет количество не NULL строк. Если добавить DISTINCT, то количество уникальных значений, которые не NULL.
COUNT по столбцу вернет количество не NULL строк. Если добавить DISTINCT, то количество уникальных значений, которые не NULL.
Интереснее с подсчетом среднего. Операция AVG раскладывается оптимизатором на SUM и COUNT. И тут мы вспомним про пример выше. Если значения целочисленные, то какой будет результат? Целочисленный. Об этом часто забывают.
UNION ALL
Еще стоит упомянуть про UNION с приставкой ALL. Тут все просто: если мы знаем, что данные не пересекаются, и нас не волнуют дубликаты, то, с точки зрения производительности, предпочтительнее использовать UNION ALL. Если нужно убрать дублирование, то смело используем UNION.
Но тут еще важно знать об интересном различии между этими двумя конструкциями: UNION выполняется параллельно, а UNION ALL — последовательно. И это не относится к параллельным планам, просто это такая особенность доступа к данным, которая может помочь при оптимизации.
Предположим, нам нужно вернуть 1 строку, исходя из разного набора условий:
USE AdventureWorks2014 GO DECLARE @AddressLine1 NVARCHAR(60) SET @AddressLine1 = '4775 Kentucky Dr.
 '
SELECT TOP(1) AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine1
OR (AddressLine2 IS NOT NULL AND AddressID > 1500)
'
SELECT TOP(1) AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE AddressLine1 = @AddressLine1
OR (AddressLine2 IS NOT NULL AND AddressID > 1500)Тогда за счет использования OR в условии у нас будет IndexScan:
Table 'Address'. Scan count 1, logical reads 6, ...
Перепишем запрос с использованием UNION ALL:
USE AdventureWorks2014 GO DECLARE @AddressLine1 NVARCHAR(60) SET @AddressLine1 = '4775 Kentucky Dr.' SELECT TOP(1) AddressID, AddressLine1, AddressLine2 FROM ( SELECT TOP(1) AddressID, AddressLine1, AddressLine2 FROM Person.[Address] WHERE AddressLine1 = @AddressLine1 UNION ALL SELECT TOP(1) AddressID, AddressLine1, AddressLine2 FROM Person.[Address] WHERE AddressLine2 IS NOT NULL AND AddressID > 1500 ) t
И посмотрим на план выполнения:
После выполнения первого подзапроса, SQL Server смотрит, что вернулась одна строка, которой достаточно, чтобы вернуть результат, и далее не продолжает искать по второму условию.
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Scalar func
О чем я еще забыл упомянуть? Специально для любителей ООП. Не используйте скалярные функции в запросах на T-SQL, которые оперируют большим числом строк.
Вот пример из жизни, которым я когда-то страдал, когда еще не знал о потенциальных минусах скалярных функций:
USE AdventureWorks2014
GO
UPDATE TOP(1) Person.[Address]
SET AddressLine2 = AddressLine1
GO
IF OBJECT_ID('dbo.isEqual') IS NOT NULL
DROP FUNCTION dbo.isEqual
GO
CREATE FUNCTION dbo.isEqual
(
@val1 NVARCHAR(100),
@val2 NVARCHAR(100)
)
RETURNS BIT
AS BEGIN
RETURN
CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2
THEN 1
ELSE 0
END
END
GOЗапросы возвращают идентичные данные:
SET STATISTICS TIME ON SELECT AddressID, AddressLine1, AddressLine2 FROM Person.[Address] WHERE dbo.
 isEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE ISNULL(AddressLine1, '') = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFF
isEqual(AddressLine1, AddressLine2) = 1
SELECT AddressID, AddressLine1, AddressLine2
FROM Person.[Address]
WHERE ISNULL(AddressLine1, '') = ISNULL(AddressLine2, '')
SET STATISTICS TIME OFFНо за счет, того что каждый вызов функции ресурсоемкий, получаем вот такую разницу:
SQL Server Execution Times: CPU time = 62 ms, elapsed time = 58 ms.
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
Кроме того, использование скалярных функций в запросе мешает SQL Server строить параллельные планы выполнения, что при больших объёмах данных может существенно подкосить производительность.
CURSORs
И самое важное, что нужно понимать при работе с SQL Server. Не используйте курсоры для модификации данных. Или используйте по минимуму их, когда других вариантов уже не остается. Часто можно встретить такой вот код:
DECLARE @BusinessEntityID INT DECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.
 Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE cur
Employee
OPEN cur
FETCH NEXT FROM cur INTO @BusinessEntityID
WHILE @@FETCH_STATUS = 0 BEGIN
UPDATE HumanResources.Employee
SET VacationHours = 0
WHERE BusinessEntityID = @BusinessEntityID
FETCH NEXT FROM cur INTO @BusinessEntityID
END
CLOSE cur
DEALLOCATE curКоторый лучше переписать вот так:
UPDATE HumanResources.Employee SET VacationHours = 0 WHERE VacationHours <> 0
Приводить время выполнения и число логических чтений не стоит, но поверьте, разница действительно есть. Как вариант, просто расскажу про недавний пример из жизни. Встретил скрипт, в котором было два вложенных курсора. При выполнении данный код приводил к таймауту на клиенте, а всего он выполнялся примерно 38 секунд. Переписал запрос без использования курсоров — 600 мс.
Что можно сказать для послесловия? Это мой первый опыт подготовки материала для DOU, и, наверное, вышло немного сумбурно. Однако, надеюсь, все, что здесь написано, будет кому-то полезным при написании запросов на T-SQL.
Продолжени: часть 2.
Все про українське ІТ в телеграмі — підписуйтеся на канал DOU
Теми:
junior, SQL Server, tech, розробка
Циклы в SQL Server
- « Предыдущая
- Далее »
1. Оператор SQL Server IF…..ELSE
В SQL Server операторы IF…..ELSE используются для выполнения кода, когда условие имеет значение TRUE, или выполнения другого кода, если условие оценивается как FALSE.
Синтаксис
IF условие
{….команды для выполнения, когда условие ИСТИНА…}
ELSE
{….команды для выполнения, когда условие ЛОЖЬ…}
Пример: Иллюстрация оператора IF….ELSE на сервере SQL.
DECLARE @Stud_value INT;
SET @stud_value = 8;
IF @stud_value <10
PRINT ‘Mark’
ELSE
PRINT ‘Andrew’;
ГО
В приведенном выше примере, если переменная @stud_value меньше 10, выведите значение «Mark».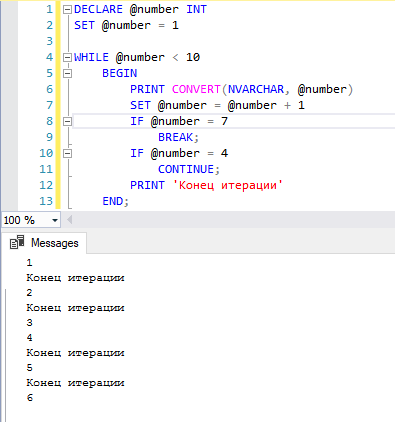 В противном случае выведите значение «Эндрю».
В противном случае выведите значение «Эндрю».
Пример: Иллюстрация вложенного оператора IF…..ELSE в SQL Server.
SET @Stud_value = 8;
IF @Stud_value < 10
PRINT ‘Mark’;
ELSE
BEGIN
IF @stud_value < 30
PRINT ‘Эндрю’;
ELSE
PRINT ‘Анна’;
КОНЕЦ;
GO
2. SQL Server WHILE LOOP
SQL Server WHILE LOOP используется, когда пользователь не уверен, сколько раз выполнять тело цикла.
Поскольку условие WHILE оценивается перед входом в цикл, возможно, что тело цикла.
Синтаксис
WHILE [условие]
BEGIN
{операторы}
END;
Пример: Иллюстрация использования цикла WHILE LOOP на сервере SQL.
DECLARE @stud_value INT;
НАБОР @stud_value = 0;
WHILE @stud_value <= 10
BEGIN
PRINT ‘Mark’;
SET @stud_value = @stud_value + 1;
КОНЕЦ;
ПЕЧАТЬ ‘Эндрю’;
ГО
В этом примере WHILE LOOP цикл завершится, если @stud_value превысит 10, как указано:
WHILE @stud_value <= 10
3.
 Оператор SQL Server BREAK
Оператор SQL Server BREAK
Оператор SQL Server BREAK используется для выхода из цикла WHILE и выполнения следующего оператора после оператора цикла.
Синтаксис:
BREAK;
Пример: Иллюстрация инструкции BREAK в SQL Server.
DECLARE @stud_value INT;
НАБОР @stud_value = 0;
ПОКА @stud_value <= 10
НАЧАЛО
IF @stud_value = 2
ПЕРЕРЫВ;
ELSE
PRINT ‘Отметка’;
SET @stud_value = @stud_value + 1;
КОНЕЦ;
ПЕЧАТЬ ‘Эндрю’;
GO
4. Оператор SQL Server CONTINUE
Оператор CONTINUE SQL Server используется, когда пользователь хочет снова выполнить цикл WHILE LOOP.
Синтаксис:
ПРОДОЛЖИТЬ;
Пример: Иллюстрация инструкции CONTINUE в SQL Server.
DECLARE @stud_value INT;
НАБОР @stud_value = 0;
ПОКА @stud_value <= 10
НАЧАЛО
IF @stud_value = 2
ПЕРЕРЫВ;
ELSE
НАЧАЛО
SET @stud_value = @stud_value + 1;
ПЕЧАТЬ ‘Отметка’;
ПРОДОЛЖИТЬ;
КОНЕЦ;
ПЕЧАТЬ ‘Эндрю’;
ГО
В приведенном выше примере WHILE LOOP перезапустится, если переменная @stud_value не равна 2, как указано в операторе IF. ..ELSE.
..ELSE.
5. Оператор SQL Server GOTO
- Оператор SQL Server GOTO изменяет поток выполнения на метку.
- Операторы, следующие за GOTO, пропускаются, и обработка продолжается с метки.
- Операторы и метки GOTO можно использовать в любом месте внутри процедуры, пакета или блока операторов.
Синтаксис:
GOTO имя_метки;
Примечание:
- label_name должно быть уникальным в рамках кода.
- После объявления метки должен быть выполнен хотя бы один оператор.
Пример: Иллюстрация оператора GOTO в SQL Server.
DECLARE @stud_value INT;
НАБОР @stud_value = 0;
ПОКА @stud_value <= 10
НАЧАЛО
IF @stud_value = 2
GOTO ‘Mark;
SET @stud_value = @stud_value + 1;
КОНЕЦ;
Метка:
PRINT ‘ Метка’;
ГО
В приведенном выше примере оператор GOTO создается и помечается как «Отметить». Если @stud_value равно 2, то код будет переходить на метку ‘Mark’.
- « Предыдущий
- Далее »
цикл WHILE на сервере Sql
Sql ServerBREAK, ПРОДОЛЖИТЬ, цикл DO, цикл DO WHILE, цикл DO While в Sql Server, цикл FOR, цикл, цикл в Sql Server, циклическая конструкция в Sql, Sql, Sql Server, WHILE, WHILE BREAK CONTINUE , WHILE CONTINUE, WHILE LOOP, WHILE loop в Sql ServerBasavaraj Biradar
WHILE loop — это циклическая конструкция, поддерживаемая Sql Server. Сервер Sql не имеет for… цикл , do… цикл while и т. д., но с помощью цикла WHILE мы можем имитировать поведение этих отсутствующих циклических конструкций.
В этой статье рассматриваются следующие вопросы:
- Знакомство с циклом WHILE
- Заявление BREAK
- ПРОДОЛЖИТЬ Заявление
- DO WHILE цикл
- Перебор записей таблицы
WHILE LOOP
Цикл while сначала проверяет условие, а затем выполняет блок инструкций Sql внутри него, пока условие оценивается как истинное.
Синтаксис:
WHILE Условие
НАЧАЛО
Операторы Sql
КОНЕЦ 9 0011
Пример: Простой пример цикла while. Приведенный ниже цикл while выполняет операторы внутри него 4 раза.
DECLARE @LoopCounter INT = 1 ПОКА ( @LoopCounter <= 4) НАЧИНАТЬ ПЕЧАТЬ @LoopCounter УСТАНОВИТЬ @LoopCounter = @LoopCounter + 1 КОНЕЦ
РЕЗУЛЬТАТ:
1
2
3
4
Оператор BREAK
Если оператор BREAK выполняется в цикле WHILE, то он заставляет управление выйти из цикла while и начать выполнение первого оператора немедленно после цикла while.
Пример: цикл WHILE с оператором BREAK
DECLARE @LoopCounter INT = 1 ПОКА ( @LoopCounter <= 4) НАЧИНАТЬ ПЕЧАТЬ @LoopCounter ЕСЛИ(@LoopCounter = 2) ПЕРЕРЫВ УСТАНОВИТЬ @LoopCounter = @LoopCounter + 1 КОНЕЦ PRINT 'Утверждение после цикла while'
РЕЗУЛЬТАТ:
Оператор CONTINUE
Если оператор CONTINUE выполняется в цикле WHILE, то он пропускает выполнение следующих за ним операторов и передает управление в начало цикла while, чтобы начать выполнение следующей итерации.