Union sql select: | SQL | SQL-tutorial.ru
Содержание
Команда UNION — слияние таблиц
Команда UNION объединяет данные из
нескольких таблиц в одну при выборке. При
объединении количество столбцов во всех таблицах
должно совпадать, иначе будет ошибка Имена
столбцов будут такие же, как в основной таблице,
в которую добавляются данные из других таблиц.
Внимание: если не используется ключевое
слово ALL для UNION, все возвращенные строки
будут уникальными, так как по умолчанию подразумевается
DISTINCT,
который удаляет неуникальные значения. Чтобы
отменить такое поведение — нужно указать
ключевое слово ALL, вот так: UNION
ALL.
Синтаксис
С удалением дублей:
SELECT * FROM имя_таблицы1 WHERE условие
UNION SELECT * FROM имя_таблицы2 WHERE условие
Без удаления дублей:
SELECT * FROM имя_таблицы1 WHERE условие
UNION ALL SELECT * FROM имя_таблицы2 WHERE условие
Можно объединять не две таблицы, а три или более:
SELECT * FROM имя_таблицы1 WHERE условие
UNION SELECT * FROM имя_таблицы2 WHERE условие
UNION SELECT * FROM имя_таблицы3 WHERE условие
UNION SELECT * FROM имя_таблицы4 WHERE условие
Таблицы для примеров
| id айди | name название |
|---|---|
| 1 | Беларусь |
| 2 | Россия |
| 3 | Украина |
| id айди | name название | country_id айди страны |
|---|---|---|
| 1 | Минск | 1 |
| 2 | Минск | 1 |
| 3 | Москва | 2 |
| 4 | Киев | 3 |
Пример
В данном примере объединяются записи из двух
таблиц:
SELECT id, name FROM countries UNION ALL SELECT id, name FROM cities
Результат выполнения кода:
| id айди | name название |
|---|---|
| 1 | Беларусь |
| 2 | Россия |
| 3 | Украина |
| 1 | Минск |
| 2 | Минск |
| 3 | Москва |
| 4 | Киев |
Пример
В данном примере отсутствует ключевое слово
ALL, однако дубли не будут удалены, так как
дублями считается полное совпадение строк:
SELECT id, name FROM countries UNION SELECT id, name FROM cities
Результат выполнения кода:
| id айди | name название |
|---|---|
| 1 | Беларусь |
| 2 | Россия |
| 3 | Украина |
| 1 | Минск |
| 2 | Минск |
| 3 | Москва |
| 4 | Киев |
Пример
А вот теперь дубли будут удалены (из двух
Минсков останется один), так как будет иметь
место полное совпадение строк (потому что
поле осталось одно, но это не обязательно):
SELECT name FROM countries UNION SELECT name FROM cities
Результат выполнения кода:
| name название |
|---|
| Беларусь |
| Россия |
| Украина |
| Минск |
| Москва |
| Киев |
Пример
А теперь добавим слово ALL — и дубли не будут
удалятся:
SELECT name FROM countries UNION ALL SELECT name FROM cities
Результат выполнения кода:
| name название |
|---|
| Беларусь |
| Россия |
| Украина |
| Минск |
| Минск |
| Москва |
| Киев |
Пример
В данном примере демонстрируется работа условий
WHERE
в комбинации с UNION:
SELECT id, name FROM countries WHERE id>=2
UNION SELECT id, name FROM cities WHERE id<=2
Результат выполнения кода:
| id айди | name имя |
|---|---|
| 2 | Россия |
| 3 | Украина |
| 1 | Минск |
| 2 | Минск |
Пример
Имена колонок берутся из первой таблицы (то
есть имена колонок таблиц, подключенных через
UNION нигде себя не проявят):
SELECT id as country_id, name as country_name FROM countries
UNION SELECT id, name FROM cities
Результат выполнения кода:
| country_id айди | country_name имя | |
|---|---|---|
| 1 | Беларусь | |
| 2 | Россия | |
| 3 | Украина | |
| 1 | Минск | 1 |
| 2 | Минск | 1 |
| 3 | Москва | 2 |
| 4 | Киев | 3 |
Пример
Такой запрос выдаст ошибку, так как в таблицах
не совпадает количество колонок:
SELECT id, name FROM countries UNION SELECT id, name, country_id FROM cities
И такой запрос тоже выдаст ошибку в нашем
случае — количество колонок в обеих таблицах
не совпадает:
SELECT * FROM countries UNION SELECT * FROM cities
Пример
Если нам очень надо забрать из какой-либо
таблицы столько полей, что в другой таблице
столько и нет, можно создавать дополнительные
поля вручную.
К примеру, мы хотим забрать 3 поля
из второй таблицы, а в первой таблице полей
только 2. Решим эту проблему создав
поле с именем country_id и содержимым 0
для первой таблицы (вот так: 0 as country_id):
SELECT id, name, 0 as country_id FROM countries
UNION SELECT id, name, country_id FROM cities
Результат выполнения кода:
| id айди | name имя | country_id айди страны |
|---|---|---|
| 1 | Беларусь | 0 |
| 2 | Россия | 0 |
| 3 | Украина | 0 |
| 1 | Минск | 1 |
| 2 | Минск | 1 |
| 3 | Москва | 2 |
| 4 | Киев | 3 |
Смотрите также
- команду
JOIN,
которая объединяет связанные таблицы
union (all, order by), intersect, except.

UNION
применяется для объединения результатов
двух SQL-запросов в единую таблицу,
состоящую из схожих строк.
Оба запроса должны возвращать одинаковое
число столбцов
и совместимые типы
данных
в соответствующих столбцах.
По
умолчанию любые дублирующие записи
автоматически скрываются, если не
использовано выражение UNION
ALL.
SELECT
*
FROM
pupils
UNION
SELECT
*
FROM
people
SELECT
*
FROM
pupils
UNION
ALL
SELECT
*
FROM
people
Необходимо
отметить, что UNION
сам по себе не гарантирует порядок
строк. Строки из второго запроса могут
оказаться в начале, в конце или вообще
перемешаться со строками из первого
запроса. В случаях, когда требуется
определенный порядок, необходимо
использовать выражение ORDER
BY.
Intersect
— пересечение (возвращает все значения,
которые содержатся как в первом, так и
во втором запросах).
Except
— разность (возвращает
все уникальные значения одного запроса,
которые также не находятся во втором
запросе).
SELECT
*
FROM
pupils
INTERSECT
SELECT
*
FROM
people
SELECT
*
FROM
pupils
EXCEPT
SELECT
*
FROM
people
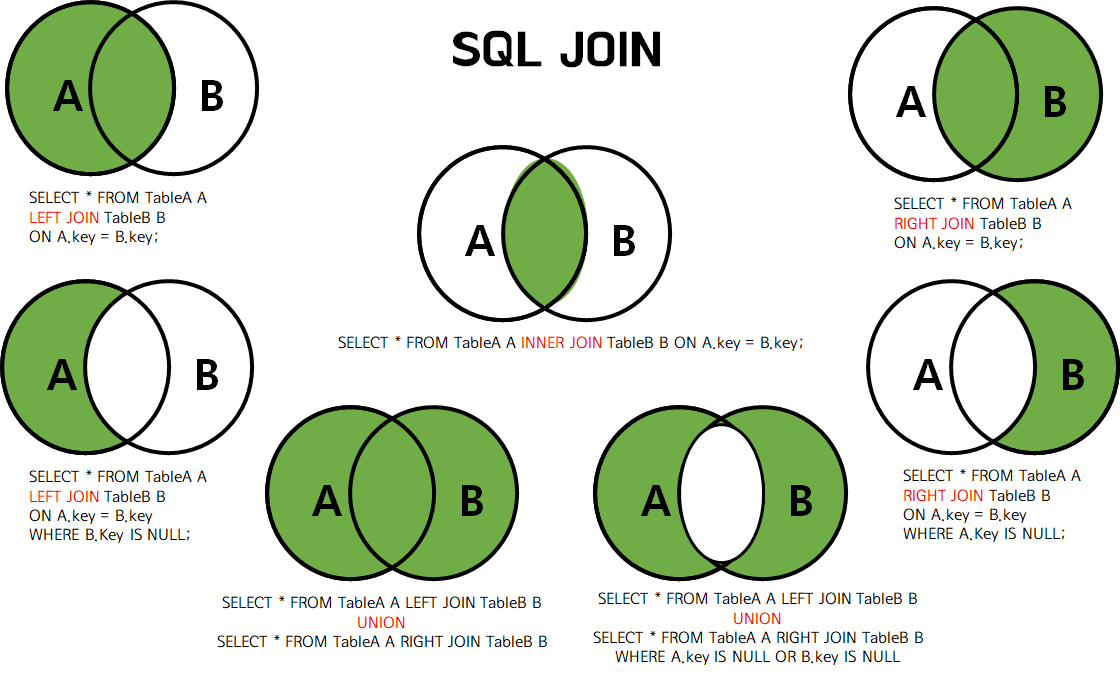
15. Внутреннее соединение таблиц: естественное, inner join, многотабличный запрос.
Естественное
соединение
– соединение, которое строит декартово
произведение, а потом строки отбирает
по некоторому условию.
Внутреннее
соединение
— соединение, в котором отображаются
только строки, имеющие соответствие в
обеих соединенных таблицах.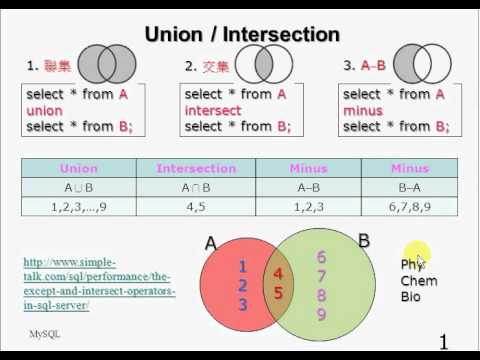
Естесстваенное
соединение:
SELECT
users.name,
phones.phone
FROM
users,
phones
WHERE
users.id
=
phones.id
Inner join
SELECT
users.name,
phones.phone
FROM
users
JOIN
phones
ON
users.id
=
phones.id
Сложные
(многотабличные запросы)
В
SQL сложные запросы являются комбинацией
простых SQL-запросов.
В
SQL сложные запросы получаются из других
запросов следующими способами:
вложением
SQL-выражения запроса в SQL-выражение
другого запроса. Первый из них называют
подзапросом, а второй — внешним или
основным запросом;применением
к SQL-запросам операторов объединения
и соединения наборов записей, возвращаемых
запросами. Эти операторы называют
теоретико-множественными или
реляционными.
Многотабличный
запрос:
SELECT
topics.title,
posts.content
FROM
topics,
posts
16.
 Внешнее соединение таблиц: outher join (left, right, full, cross).
Внешнее соединение таблиц: outher join (left, right, full, cross).
 Внешнее соединение таблиц: outher join (left, right, full, cross).
Внешнее соединение таблиц: outher join (left, right, full, cross). Внешние
соединения возвращают все строки,
удовлетворяющие условиям поиска. Все
строки, получаемые из левой таблицы,
образуют левое внешнее соединение (LEFT
OUTER JOIN),
а строки, получаемые из правой таблицы,
— правое внешнее соединение (RIGHT
OUTER JOIN
— Берём все строки правой таблицы и
присоединяем в соответствии с условием
все строки, которые есть в левой, а те
строки, для которых не выполняется
условие, заполняем null). Все строки их
обеих таблиц возвращаются в полном
внешнем соединении.
SELECT
*
FROM
nameone
SELECT
*
FROM
surnameone
SELECT
n.name,
s.surname
FROM
nameone
n
RIGHT
OUTER
JOIN
surnameone
s
ON
n.id
=
s.id
SELECT
n.name,
s.surname
FROM
nameone
n
LEFT
OUTER
JOIN
surnameone
s
ON
n. id
id
=
s.id
SELECT
n.name,
s.surname
FROM
nameone
n
FULL
OUTER
JOIN
surnameone
s
ON
n.id
=
s.id
Перекрестное
соединение
выполняет полное декартово произведение
двух таблиц. То есть это соответствие
каждой строки одной таблицы — каждой
строке другой таблицы. Перекрестные
соединения используются довольно редко.
Никогда не стоит пересекать две большие
таблицы, поскольку это задействует
очень дорогие операции и получится
очень большой результирующий набор.
SELECT
*
FROM
nameone
SELECT
*
FROM
surnameone
SELECT
n.name,
s.surname
FROM
nameone
n
CROSS
JOIN
surnameone
s
UNION и UNION ALL в SQL Server
Автор: Грег Робидоукс |
Комментарии (9) | Связанный: Подробнее > JOIN Tables
Проблема
Иногда возникает необходимость объединить данные из нескольких таблиц или представлений в
один всеобъемлющий набор данных. Это может быть для таблиц с похожими данными в одном и том же
Это может быть для таблиц с похожими данными в одном и том же
базы данных или, возможно, есть необходимость объединить аналогичные данные в разных базах данных или даже
по серверам.
В этом совете мы рассмотрим, как использовать UNION против UNION
ВСЕ команды и чем они отличаются.
Решение
В SQL Server у вас есть возможность объединять несколько наборов данных в один всеобъемлющий
набор данных с помощью операторов UNION или UNION ALL . Есть большая разница в
как они работают, а также окончательный набор результатов, который возвращается, но в основном эти
Команды объединяют несколько наборов данных с похожей структурой в один комбинированный набор данных.
СОЕДИНЕНИЕ
Эта операция позволит вам присоединиться к нескольким
наборы данных в один набор данных и удалит все существующие дубликаты. По сути
он выполняет операцию DISTINCT для всех столбцов результирующего набора.
СОЕДИНЕНИЕ ВСЕ
Эта операция снова позволяет присоединиться
несколько наборов данных в один набор данных, но не удаляет повторяющиеся строки.
Поскольку это не удаляет повторяющиеся строки, этот процесс выполняется быстрее, но если вы
не хотите дублировать записи, вам нужно будет вместо этого использовать оператор UNION.
Правила для данных UNION
- Каждый запрос должен иметь одинаковое количество столбцов
- Каждый столбец должен иметь совместимые типы данных
- Имена столбцов для окончательного набора результатов берутся из первого запроса.
- Предложения ORDER BY и COMPUTE могут использоваться только для общего набора результатов.
а не в каждом отдельном наборе результатов - Предложения GROUP BY и HAVING могут использоваться только для каждого отдельного результата.
набор, а не для общего набора результатов
Совет: Если у вас нет одинаковых столбцов во всех запросах, используйте значение по умолчанию или значение NULL, например:
ВЫБЕРИТЕ имя, фамилию, компанию ИЗ бизнес-контактов СОЮЗ SELECT firstName, lastName, NULL FROM nonBusinessContacts или ВЫБЕРИТЕ имя, фамилию, дату создания ИЗ бизнес-контактов СОЮЗ ВСЕХ SELECT firstName, lastName, getdate() FROM nonBusinessContacts
UNION против UNION ALL Примеры
Давайте рассмотрим несколько простых примеров того, как работают эти команды и как
они отличаются. Как вы увидите, окончательные наборы результатов будут отличаться, но есть некоторые
Как вы увидите, окончательные наборы результатов будут отличаться, но есть некоторые
интересная информация о том, как SQL Server фактически завершает процесс.
СОЕДИНЕНИЕ ВСЕ
В этом первом примере мы используем оператор UNION ALL для оператора Employee.
таблицу из базы данных AdventureWorks. Это, вероятно, не то, что вы бы
do, но это помогает проиллюстрировать различия этих двух операторов.
В таблице dbo.Employee 290 строк.
ВЫБЕРИТЕ * ИЗ HumanResources.Employee СОЮЗ ВСЕХ ВЫБЕРИТЕ * ОТ HumanResources.Employee СОЮЗ ВСЕХ ВЫБЕРИТЕ * ОТ HumanResources.Employee
При выполнении этого запроса результирующий набор содержит 870 строк. Это возвращенные 290 строк
3 раза. Данные просто объединяются в один набор данных поверх другого набора данных.
Вот план выполнения этого запроса. Мы видим, что таблица была запрошена
3 раза, и SQL Server выполнил шаг конкатенации, чтобы объединить все данные.
СОЕДИНЕНИЕ
В следующем примере мы используем оператор UNION для таблицы Employee.
снова из базы данных AdventureWorks.
ВЫБЕРИТЕ * ИЗ HumanResources.Employee СОЮЗ ВЫБЕРИТЕ * ОТ HumanResources.Employee СОЮЗ ВЫБЕРИТЕ * ОТ HumanResources.Employee
При выполнении этого запроса результирующий набор содержит 290 строк. Несмотря на то, что мы объединили
data трижды оператор UNION удалял повторяющиеся записи и, следовательно,
возвращает только 290 уникальных строк.
Вот план выполнения этого запроса. Мы видим, что SQL Server сначала запросил
2 таблицы, затем выполнил операцию слияния для объединения первых двух таблиц.
а затем он выполнил еще одно объединение слиянием вместе с запросом третьей таблицы в запросе.
Итак, мы видим, что для получения такого результата нужно было проделать гораздо больше работы.
поставил по сравнению с СОЮЗОМ ВСЕ.
Примеры UNION и UNION ALL с сортировкой по столбцу кластеризованного индекса
Если мы сделаем еще один шаг и выполним СОРТИРОВКУ данных с помощью кластеризованного
Индекс столбца мы получаем эти планы выполнения. Отсюда мы видим, что выполнение
Отсюда мы видим, что выполнение
план, который использует SQL Server, идентичен для каждой из этих операций, хотя
окончательные наборы результатов по-прежнему будут содержать 870 строк для UNION ALL и 290 строк
для СОЮЗА.
UNION ALL план выполнения с сортировкой по столбцу кластеризованного индекса
План выполнения UNION с сортировкой по столбцу кластеризованного индекса
Примеры UNION и UNION ALL с сортировкой по неиндексированному столбцу
Вот еще один пример, делающий то же самое, но на этот раз выполняющий СОРТИРОВКУ
неиндексированный столбец. Как видите, планы выполнения снова идентичны для этих
два запроса, но на этот раз вместо использования MERGE JOIN, CONCATENATION и SORT
используются операции.
UNION ALL план выполнения с сортировкой по неиндексированному столбцу
План выполнения UNION с сортировкой по неиндексированному столбцу
Следующие шаги
- Ознакомьтесь с другими советами, которые могут быть полезны при использовании операторов объединения.
- Сравнение нескольких наборов данных с INTERSECT
и КРОМЕ операторов - SQL Server Именование из четырех частей
Сравните результаты двух запросов SQL Server с использованием UNION
- Сравнение нескольких наборов данных с INTERSECT

Об авторе
Грег Робиду является президентом и основателем Edgewood Solutions, компании, предоставляющей технологические услуги и предоставляющей услуги и решения для Microsoft SQL Server. Он также является одним из соучредителей MSSQLTips.com. Грег работает с SQL Server с 1999 года, является автором множества статей по базам данных и выступил с несколькими презентациями, связанными с SQL Server. До SQL Server он работал над многими платформами данных, такими как DB2, Oracle, Sybase и Informix.
Посмотреть все мои советы
Комментарии к этой статье
| Пятница, 25 марта 2022 г. — 9:32:29 — Джо Ф. Селко | Вернуться к началу (89926) |
Хотя SQL Server получает имена столбцов и набор результатов из первой таблицы объединения, стандарты ANSI/ISO не дают им имен. Вы должны написать «(<выражение объединения>) AS <таблица результатов>(список имен столбцов>)», что создаст новую таблицу со всеми именованными элементами. Вы должны написать «(<выражение объединения>) AS <таблица результатов>(список имен столбцов>)», что создаст новую таблицу со всеми именованными элементами. | |
| Четверг, 28 октября 2021 г. – 9:30:04 – Дэвид | Вернуться к началу (89375) |
| Перейдите к разделу «Как использовать шаблон для добавления таблиц с одинаковыми типами данных и именами столбцов?» Если я щелкну правой кнопкой мыши первую таблицу dbo.202005> Создать таблицу как> Если я сохраню этот шаблон в этой папке, Как использовать приведенный выше шаблон для добавления последующих плоских файлов с одинаковые типы данных во всех столбцах? Спасибо | |
Четверг, 28 октября 2021 г. — 8:40:51 — Дэвид — 8:40:51 — Дэвид | Вернуться к началу (89374) |
| Спасибо за оперативную помощь, мистер Грег Р. Это сработало после того, как я погуглил и исправил ошибку «Ошибка преобразования при преобразовании значения nvarchar« TA1307000121 »в тип данных int». Это заняло некоторое время, так как я не знаю, в каком столбце из 12 таблиц (по 13 столбцов в каждой таблице) находится значение. Затем я нашел этот скрипт на https://stackoverflow.com/questions/15757263/find-a- string-by-searching-all-tables-in-sql-server, Для справки в будущем, при импорте нескольких плоских файлов, есть ли способ принудительно использовать тип/шаблон оформления таблицы, если я уже указал свои типы данных в каждом столбце? Или я могу создать дизайн для первой таблицы, а затем импортировать другие таблицы, используя шаблон? Еще раз спасибо. | |

| , вторник, 26 октября 2021 г. — 15:53:59 — Грег Робиду | Вернуться к началу (89366) |
| Привет, Дэвид, , вы можете сделать что-то вроде этого: SELECT * INTO #temp FROM dbo.[202005] затем просто | |
| , вторник, 26 октября 2021 г. — 15:22:05 — Дэвид | Вернуться к началу (89365) |
| Я новичок в MS SQL Server и ценю все советы профессионалов mssqltips. У меня есть 12 таблиц с одинаковыми типами данных и именами столбцов в том же порядке. Я часами гуглил и не уверен, как правильно использовать UNION ALL для добавления таблиц. И создать и сохранить результаты во временной таблице, чтобы я мог проанализировать (удалить дубликаты, DISTINCT COUNT и т. д. оттуда? Это то, что у меня есть на данный момент Любые советы приветствуются. | |
 ride_id является первичным ключом во всех таблицах. Это данные о совместном использовании велосипедов divvy здесь — https://www.kaggle.com/yingwurenjian/chicago-divvy-bicycle-sharing-data
ride_id является первичным ключом во всех таблицах. Это данные о совместном использовании велосипедов divvy здесь — https://www.kaggle.com/yingwurenjian/chicago-divvy-bicycle-sharing-data [202102]
[202102] | Среда, 16 декабря 2020 г. — 12:55:25 — Джо Селко | Вернуться к началу (87919) |
| Стоит отметить, что в соответствии со стандартами ANSI/ISO в результирующем наборе есть безымянные столбцы. Некоторые реализации SQL получают имена столбцов для окончательного набора результатов из первого запроса. Другие будут использовать последний запрос. Однако самый безопасный и стандартный подход — явно указать столбцы и результирующий набор. Вот скелет: ( ВЫБЕРИТЕ c1, c2, c3 ИЗ T1, ГДЕ … Фраза, которую мы используем для требования, чтобы столбцы совпадали по положению и типу данных, называется «совместимым с объединением», и существуют некоторые правила преобразования типов данных для получения всех запросов. в формат, совместимый с объединением. Эти же правила применяются к операторам INTERSECT [ALL] и EXCEPT [ALL]. | |
 x3)
x3)| Четверг, 5 декабря 2019 г. — 9:56:54 — Томас Франц | Вернуться к началу (83296) |
Короткое примечание: Вам не нужно ставить DISTINCT ни в один из подзапросов, если вы используете UNION (поскольку дублеты были удалены «снаружи» UNION и удаление дублетов два или три раза медленнее, чем однократное). Если вы знаете, что в обоих ваших наборах результатов не может быть дубликатов (например, потому что вы использовали жестко закодированный тип, как в SELECT ‘this stuff’ as type, col1, col2. | |
 .. или потому что вы запрашиваете разные таблицы), вы должны всегда используйте UNION ALL. Прирост производительности по сравнению с UNION может быть очень большим.
.. или потому что вы запрашиваете разные таблицы), вы должны всегда используйте UNION ALL. Прирост производительности по сравнению с UNION может быть очень большим.| пятница, 13 октября 2017 г. — 12:22:21 — гошо | Вернуться к началу (67291) |
Очень информативно и полезно. Продолжайте хорошую работу! | |
| Вторник, 7 февраля 2017 г. — 2:22:49 — Dipen Kenia | Вернуться к началу (46065) |
Это было очень полезно.
| |
7.4. Объединение запросов (UNION, INTERSECT, EXCEPT)
Результаты двух запросов могут быть объединены с помощью операций объединения, пересечения и разности над множествами. Синтаксис:
Синтаксис:
.запрос1ОБЪЕДИНЕНИЕ [ВСЕ]запрос2запрос1ПЕРЕСЕЧЕНИЕ [ВСЕ]запрос2запрос1КРОМЕ [ВСЕХ]запрос2
, где query1 и query2 — это запросы, которые могут использовать любые функции, обсуждавшиеся до этого момента.
UNION эффективно добавляет результат query2 к результату query1 (хотя нет никакой гарантии, что это именно тот порядок, в котором фактически возвращаются строки). Кроме того, он удаляет повторяющиеся строки из своего результата так же, как DISTINCT 9.0373 , если не используется UNION ALL .
INTERSECT возвращает все строки, которые есть как в результате query1 , так и в результате query2 . Повторяющиеся строки удаляются, если не используется
Повторяющиеся строки удаляются, если не используется ПЕРЕСЕЧАЕТ ВСЕ .
ЗА ИСКЛЮЧЕНИЕМ возвращает все строки, которые входят в результат query1 , но не в результат query2 . (Это иногда называют разница между двумя запросами.) Опять же, дубликаты удаляются, если не используется , КРОМЕ ВСЕХ .
Чтобы вычислить объединение, пересечение или разность двух запросов, два запроса должны быть «совместимы по объединению», что означает, что они возвращают одинаковое количество столбцов, а соответствующие столбцы имеют совместимые типы данных, как описано в разделе 10.5.
Набор операций можно комбинировать, например
запрос1СОЕДИНЕНИЕзапрос2КРОМЕзапрос3
, что эквивалентно
(запрос1ОБЪЕДИНЕНИЕзапрос2) КРОМЕзапрос3
Как показано здесь, вы можете использовать круглые скобки для управления порядком оценки.