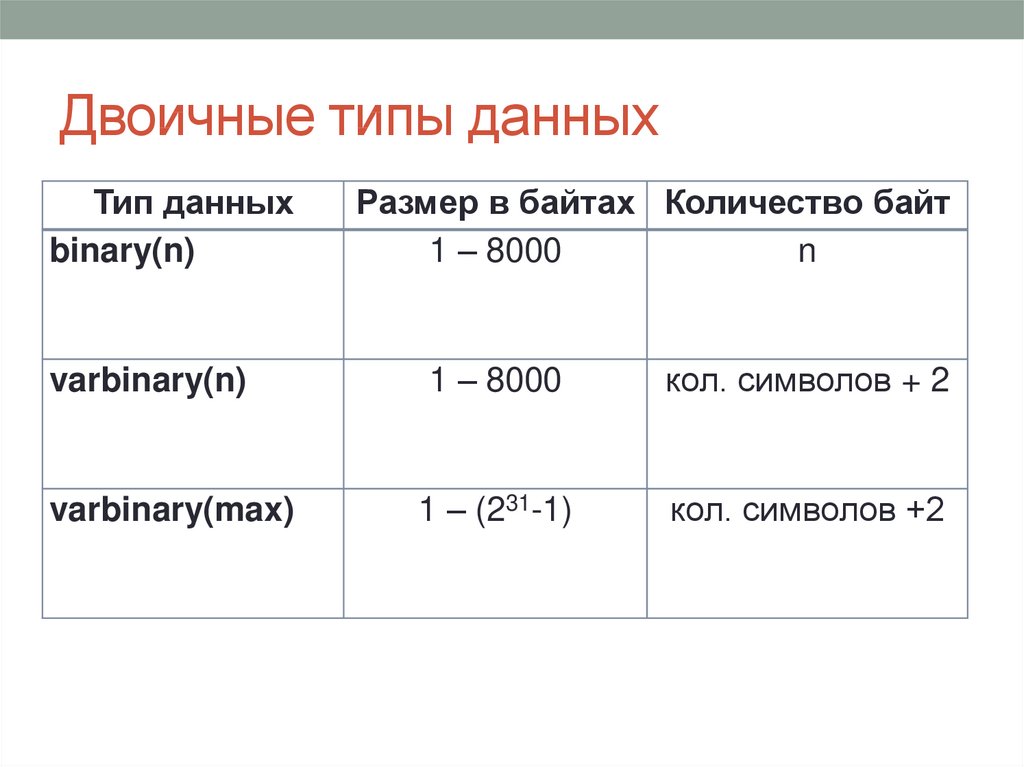
Varbinary тип данных: binary и varbinary (Transact-SQL) — SQL Server
Содержание
Строковые и двоичные типы — SQL Server
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 2 мин
-
Применимо к:база данныхSQL Server Azure SQL Управляемый экземпляр SQL Azure
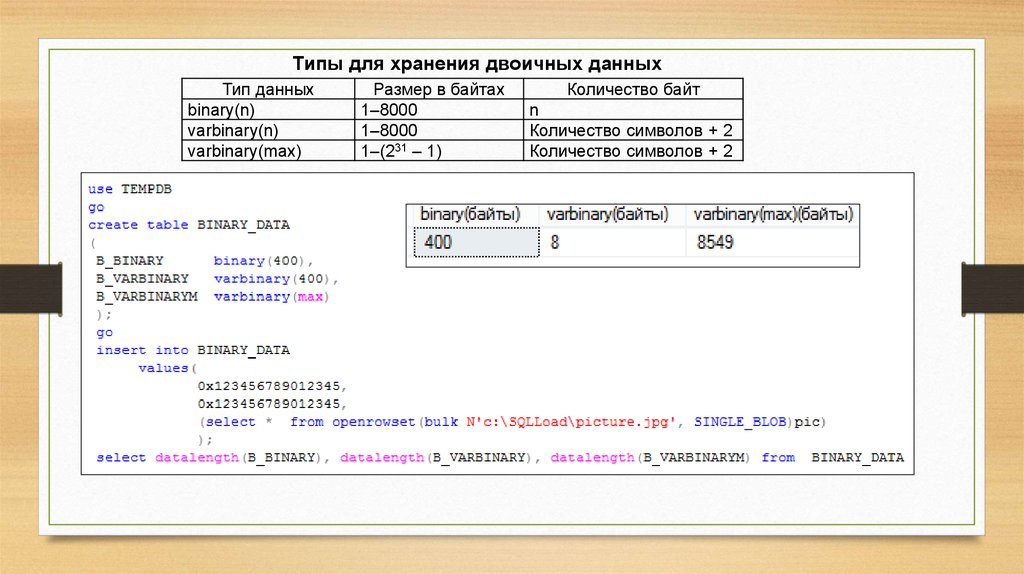
SQL Server поддерживает следующие двоичные и строковые типы.
| Тип | Описание |
|---|---|
| binary и varbinary | Типы двоичных данных фиксированной или переменной длины. Если для обмена данными лучше всего подходит тип binary, то другие типы данных удобнее всего будет преобразовать в binary и varbinary. |
| char и varchar | Символьные типы данных имеют фиксированный (char) или переменный (varchar) размер. Начиная с SQL Server 2019 (15.x) при использовании параметров сортировки с поддержкой UTF-8 эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-8. |
| nchar и nvarchar | Символьные типы данных Юникода, которые имеют фиксированный размер, nchar или переменный размер, nvarchar. Начиная с SQL Server 2012 (11.x) при использовании параметров сортировки с поддержкой дополнительных символов эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-16. |
| ntext, text, и image | Эти типы данных фиксированной и переменной длины предназначены для хранения символьных и двоичных данных в формате Юникод и иных форматах. Данные Юникода используют набор символов Юникода UCS-2. Типы данных ntext, textи image будут исключены из следующей версии SQL Server. Следует избегать использования этих типов данных при новой разработке и запланировать изменение приложений, использующих их в настоящий момент. |
- Типы данных (Transact-SQL)
- Числовые типы
- Строковые функции
MS SQL Server и T-SQL
Последнее обновление: 12.07.2017
При создании таблицы для всех ее столбцов необходимо указать определенный тип данных. Тип данных определяет, какие значения могут храниться в столбце,
сколько они будут занимать места в памяти.
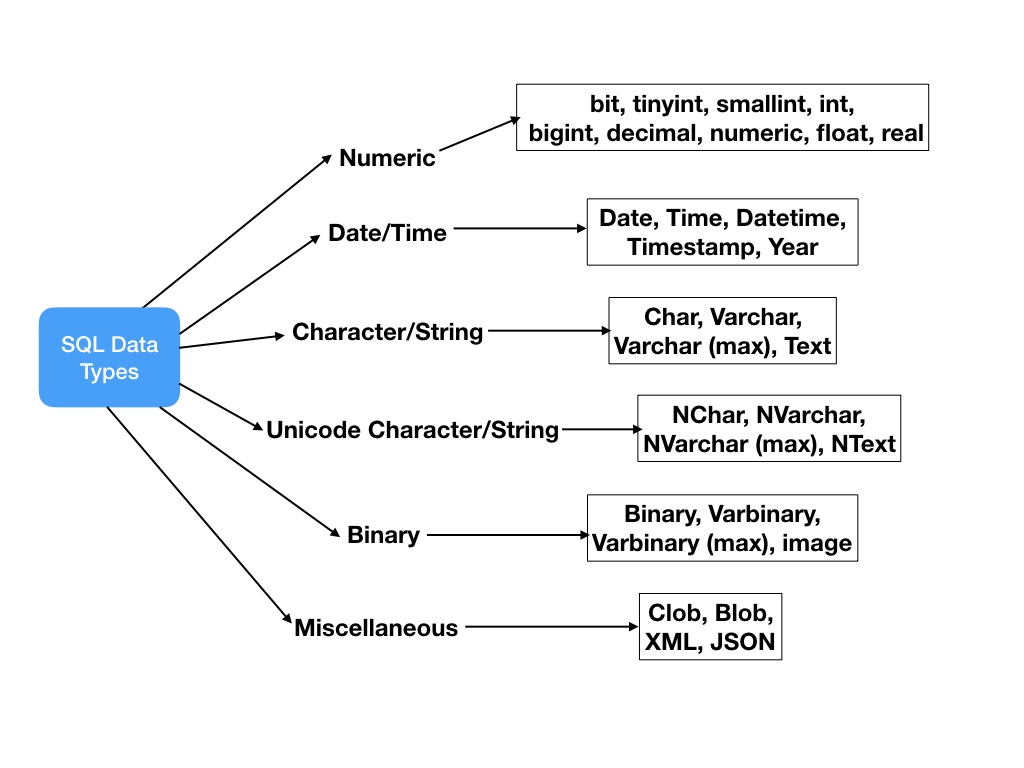
Язык T-SQL предоставляет множество различных типов. В зависимости от характера значений все их можно разделить на группы.
В зависимости от характера значений все их можно разделить на группы.
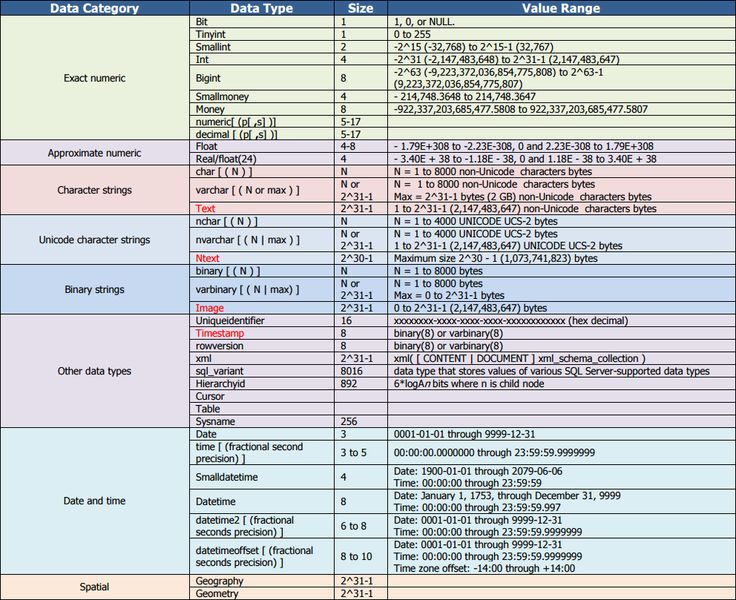
Числовые типы данных
BIT: хранит значение от 0 до 16. Может выступать аналогом булевого типа в языках программирования (в этом случае значению true соответствует 1, а
значению false — 0). При значениях до 8 (включительно) занимает 1 байт, при значениях от 9 до 16 — 2 байта.TINYINT: хранит числа от 0 до 255. Занимает 1 байт. Хорошо подходит для хранения небольших чисел.
SMALLINT: хранит числа от –32 768 до 32 767. Занимает 2 байта
INT: хранит числа от –2 147 483 648 до 2 147 483 647. Занимает 4 байта. Наиболее используемый тип для хранения чисел.
BIGINT: хранит очень большие числа от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807, которые
занимают в памяти 8 байт.DECIMAL: хранит числа c фиксированной точностью.
Занимает от 5 до 17 байт в зависимости от количества чисел после запятой.
Данный тип может принимать два параметра precision и scale:
DECIMAL(precision, scale).Параметр precision представляет максимальное количество цифр, которые может хранить число.
Это значение должно находиться в диапазоне от 1 до 38. По умолчанию оно равно 18.Параметр scale представляет максимальное количество цифр, которые может содержать число после запятой.
Это значение должно находиться в диапазоне от 0 до значения параметра precision. По умолчанию оно равно 0.NUMERIC: данный тип аналогичен типу DECIMAL.
SMALLMONEY: хранит дробные значения от -214 748.3648 до 214 748.3647. Предназначено для хранения денежных величин.
Занимает 4 байта. Эквивалентен типуDECIMAL(10,4).MONEY: хранит дробные значения от -922 337 203 685 477.5808 до 922 337 203 685 477.5807. Представляет денежные величины
и занимает 8 байт. Эквивалентен типуDECIMAL(19,4).FLOAT: хранит числа от –1.79E+308 до 1.79E+308.
Занимает от 4 до 8 байт в зависимости от дробной части.Может иметь форму опредеения в виде
FLOAT(n), где n представляет число бит, которые используются для хранения десятичной части числа (мантиссы).
По умолчанию n = 53.REAL: хранит числа от –340E+38 to 3.40E+38. Занимает 4 байта. Эквивалентен типу
FLOAT(24).
Примеры числовых столбцов:
Salary MONEY, TotalWeight DECIMAL(9,2), Age INT, Surplus FLOAT
Типы данных, представляющие дату и время
DATE: хранит даты от 0001-01-01 (1 января 0001 года) до 9999-12-31 (31 декабря 9999 года). Занимает 3 байта.
TIME: хранит время в диапазоне от 00:00:00.0000000 до 23:59:59.9999999. Занимает от 3 до 5 байт.
Может иметь форму
TIME(n), где n представляет количество цифр от 0 до 7 в дробной части секунд.DATETIME: хранит даты и время от 01/01/1753 до 31/12/9999. Занимает 8 байт.
DATETIME2: хранит даты и время в диапазоне от 01/01/0001 00:00:00.0000000 до 31/12/9999 23:59:59.9999999. Занимает от 6 до 8 байт в
зависимости от точности времени.Может иметь форму
DATETIME2(n), где n представляет количество цифр от 0 до 7 в дробной части секунд.SMALLDATETIME: хранит даты и время в диапазоне от 01/01/1900 до 06/06/2079, то есть ближайшие даты.
Занимает от 4 байта.DATETIMEOFFSET: хранит даты и время в диапазоне от 0001-01-01 до 9999-12-31. Сохраняет детальную
информацию о времени с точностью до 100 наносекунд. Занимает 10 байт.

Распространенные форматы дат:
yyyy-mm-dd—2017-07-12dd/mm/yyyy—12/07/2017mm-dd-yy—07-12-17В таком формате двузначные числа от 00 до 49 воспринимаются как даты в диапазоне 2000-2049.
А числа от 50 до 99 как диапазон чисел 1950 — 1999.Month dd, yyyy—July 12, 2017
 А числа от 50 до 99 как диапазон чисел 1950 — 1999.
А числа от 50 до 99 как диапазон чисел 1950 — 1999.
Распространенные форматы времени:
hh:mi—13:21hh:mi am/pm—1:21 pmhh:mi:ss—1:21:34hh:mi:ss:mmm—1:21:34:12hh:mi:ss:nnnnnnn—1:21:34:1234567
Строковые типы данных
CHAR: хранит строку длиной от 1 до 8 000 символов. На каждый символ выделяет по 1 байту.
Не подходит для многих языков, так как хранит символы не в кодировке Unicode.Количество символов, которое может хранить столбец, передается в скобках. Например, для столбца с типом
CHAR(10)будет выделено 10 байт. И если мы сохраним в столбце строку менее 10 символов, то она будет дополнена пробелами.VARCHAR: хранит строку. На каждый символ выделяется 1 байт. Можно указать конкретную длину для столбца —
от 1 до 8 000 символов, например,VARCHAR(10).
Если строка должна иметь больше 8000 символов, то задается размер MAX, а на хранение строки может выделяться до
2 Гб:VARCHAR(MAX).Не подходит для многих языков, так как хранит символы не в кодировке Unicode.
В отличие от типа CHAR если в столбец с типом
VARCHAR(10)будет сохранена строка в 5 символов, то в столце будет сохранено именно пять символов.NCHAR: хранит строку в кодировке Unicode длиной от 1 до 4 000 символов. На каждый символ выделяется 2 байта. Например,
NCHAR(15)NVARCHAR: хранит строку в кодировке Unicode. На каждый символ выделяется 2 байта.Можно задать конкретный размер от 1 до 4 000 символов:
.
Если строка должна иметь больше 4000 символов, то задается размер MAX, а на хранение строки может выделяться до
2 Гб. 31–1 байт при использовании
значения MAX (VARBINARY(MAX)).
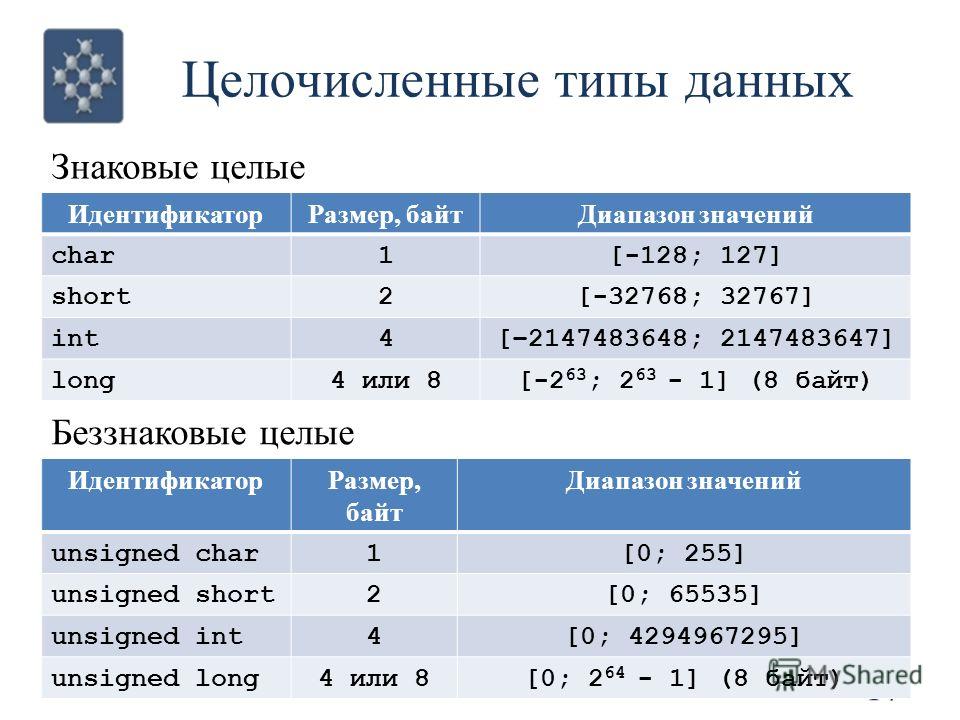
 31–1 байт при использовании
31–1 байт при использовании
Еще один бинарный тип — тип IMAGE является устаревшим, и вместо него рекомендуется применять тип VARBINARY.
Остальные типы данных
UNIQUEIDENTIFIER: уникальный идентификатор GUID (по сути строка с уникальным значением), который занимает 16 байт.
TIMESTAMP: некоторое число, которое хранит номер версии строки в таблице.
Занимает 8 байт.CURSOR: представляет набор строк.
HIERARCHYID: представляет позицию в иерархии.
SQL_VARIANT: может хранить данные любого другого типа данных T-SQL.
XML: хранит документы XML или фрагменты документов XML. Занимает в памяти до 2 Гб.
TABLE: представляет определение таблицы.
GEOGRAPHY: хранит географические данные, такие как широта и долгота.
GEOMETRY: хранит координаты местонахождения на плоскости.
НазадСодержаниеВперед
SQL Server IMAGE и VARBINARY Типы данных
Автор: James Miller
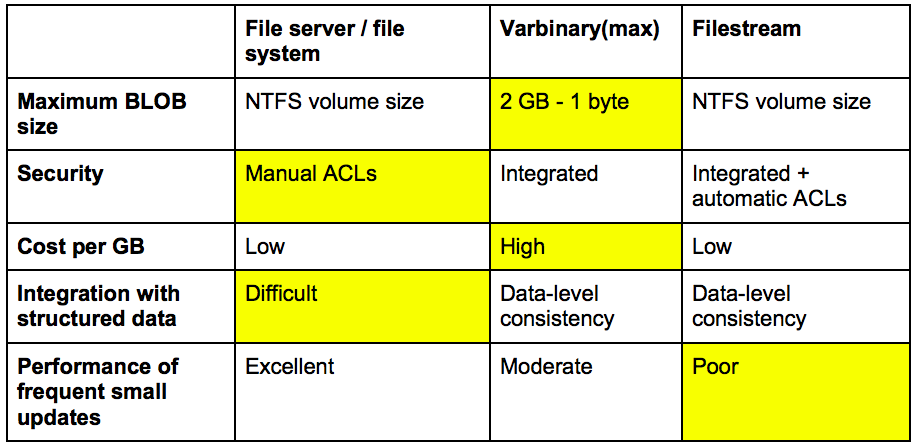
7 мая 2021 г. Недавно Microsoft начала предлагать использовать VARBINARY(MAX) вместо IMAGE для хранения большого объема данных в одном столбце, поскольку IMAGE будет упразднен в будущей версии MS SQL Server.
Иллюстрация
Как всегда, я думаю, что лучший способ понять что-либо — это рассмотреть рабочий пример. Здесь давайте представим базу данных сотрудников, в которой вместе с идентификационной информацией содержится уникальный образ человека. Я хотел бы импортировать изображения для каждого сотрудника из исходного местоположения в таблицу, а затем иметь возможность экспортировать изображение для последующей обработки.
Azure Data Studio
В этом упражнении я решил использовать Azure Data Studio и локальную базу данных SQL Server, но вы также можете легко использовать SQL Server Management Studio (SSMS).
Не знаете, какой инструмент использовать? Сравните инструменты здесь.
В этом упражнении я предполагаю, что у вас есть базовые знания об использовании Azure Data Studio (вход и подключение к базе данных, выполнение запросов и т. д.), но если нет, воспользуйтесь полезным кратким руководством.
Настройка
Есть предварительный шаг, который я должен сделать, чтобы этот пример заработал. То есть параметр OLE Automation Procedures должен быть «установлен и активен» на экземпляре SQL Server, который будет использоваться для действия по экспорту изображения, которое я буду использовать, а роль сервера bulkadmin (которая предоставляет массовое копирование и другие массовые операции) должна будет предоставлен пользователю, который будет импортировать и экспортировать изображения.
Параметр процедур автоматизации Ole SQL Server определяет, могут ли объекты OLE-автоматизации создаваться в пакетах Transact-SQL. Это расширенные хранимые процедуры, которые позволяют пользователям SQL Server выполнять функции, внешние по отношению к SQL Server, в контексте безопасности SQL Server.
Это расширенные хранимые процедуры, которые позволяют пользователям SQL Server выполнять функции, внешние по отношению к SQL Server, в контексте безопасности SQL Server.
Вот сценарий T-SQL, который предоставляет эти привилегии (я назначаю себе роль bulkadmin):
Создание таблицы
таблица, в которой будут храниться изображения. Таблица будет иметь «типичный» идентификатор сотрудника (определяемый как IDENTITY) и имя (NVARCHAR), но также будет включать два дополнительных столбца, которые будут содержать имя файла физического образа, хранящегося как тип данных NVARCHAR, а также двоичные данные этого файла изображения , хранящиеся как тип данных VARBINARY (ранее вы могли использовать тип данных IMAGE).
Ниже приведен простой сценарий T-SQL, который я использовал для создания таблицы:
Сортировка изображений
В моем небольшом примере я предполагаю, что у меня есть список имен сотрудников, каждый из которых предоставил « селфи», сохраненный в формате jpg:
Я сохранил файлы изображений в следующей локальной папке:
Что я хочу сделать, так это сохранить фактическое предоставленное изображение в таблице базы данных в виде двоичных данных (а не ссылки на расположение файла) вместе с именем сотрудника.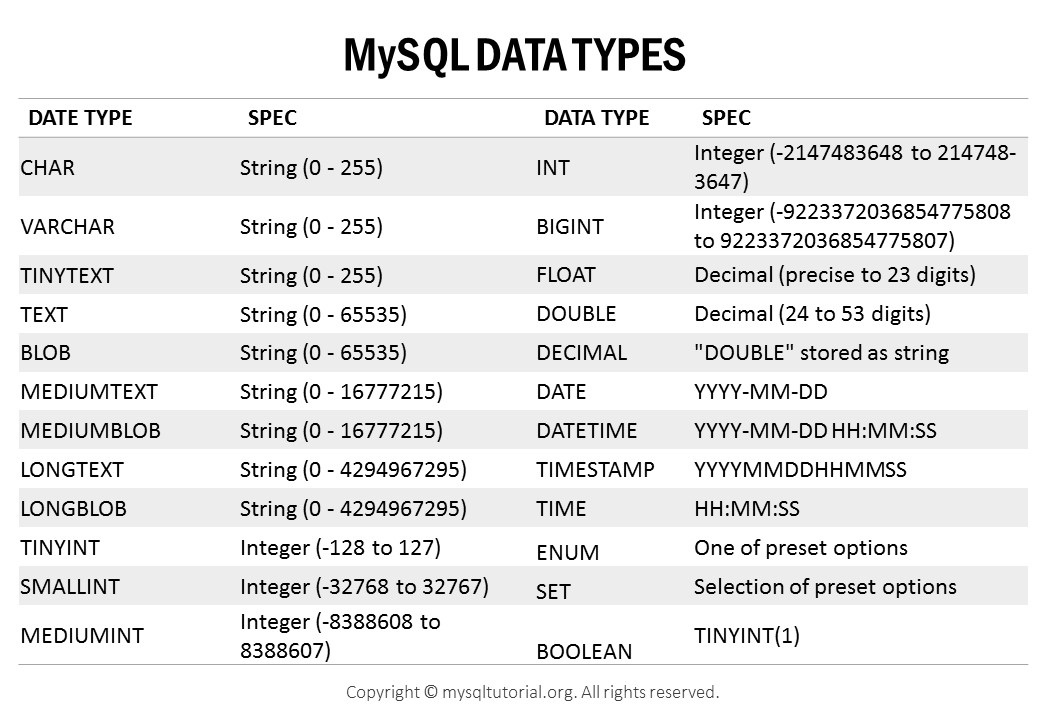
Импорт изображений
Так как я собираюсь загружать изображения по мере найма новых сотрудников, я могу использовать удобную хранимую процедуру, как показано ниже. Процедура (в общих чертах основанная на концепции, предложенной онлайн на сайте msqltips.com) вставляет запись в нашу таблицу EmployeeDetails, преобразуя и сохраняя файл физического изображения в виде двоичных данных с помощью SQL-функции OPENROWSET:0005
Создав хранимую процедуру, я могу выполнить следующие операторы запроса T-SQL (по одному для каждого из наших сотрудников):
table (используя следующую команду T-SQL select), я увижу, что наша таблица EmployeeDetails была загружена с идентификатором каждого сотрудника, именем, именем файла изображения или изображения (селфи), а также изображение было преобразовано и сохранено:
выберите * из EmployeeDetails
Экспорт изображений
Теперь, когда данные успешно сохранены, нет необходимости хранить исходные физические файлы изображений, поскольку они сохранены в таблице базы данных в виде двоичных данных. . Чтобы использовать эти данные позже, мне нужна вторая хранимая процедура, которая может «преобразовывать» двоичные данные обратно в физическое изображение «на лету», чтобы его можно было просмотреть.
. Чтобы использовать эти данные позже, мне нужна вторая хранимая процедура, которая может «преобразовывать» двоичные данные обратно в физическое изображение «на лету», чтобы его можно было просмотреть.
Ниже приведена хранимая процедура, использующая для этого объект ADO Stream. Объект ADO Stream используется для чтения, записи и управления потоком двоичных данных или текста.
Эта хранимая процедура будет считывать двоичные данные из таблицы, преобразовывать их обратно в файл .jpg и затем сохранять в нужную папку. Вы можете запустить процедуру с помощью следующей команды T-SQL:
exec dbo.usp_ExportEmployeeImage ‘Brad Pitt’,’C:\MyPictures\Output’,’BP.jpg’
Viewer
Теперь, когда я видели, как преобразовывать изображения в двоичные данные, сохранять их и извлекать из таблицы SQL Server, используя T-SQL, было бы неплохо иметь возможность просматривать изображения с помощью простого табличного запроса, однако это невозможно. Помните, что данные (изображения), хранящиеся в столбцах VARBINARY, хранятся в двоичном формате, поэтому при выборе данных в AZURE или SSMS они не преобразуются, а отображаются с использованием шестнадцатеричного представления двоичных данных (как показано ранее).
Помните, что данные (изображения), хранящиеся в столбцах VARBINARY, хранятся в двоичном формате, поэтому при выборе данных в AZURE или SSMS они не преобразуются, а отображаются с использованием шестнадцатеричного представления двоичных данных (как показано ранее).
Доступны сторонние средства просмотра изображений, такие как средство просмотра изображений SQL от YOHZ Software, которое можно загрузить и попробовать бесплатно. После его установки (сложной настройки не требуется) вы можете подключиться к своей базе данных SQL и выполнить простой запрос:
Хотя приведенный выше вариант довольно удобен, я всегда предпочитаю изучать создание собственного решения.
Простая альтернатива
В качестве простой альтернативы я буду использовать код Python с открытым исходным кодом для создания собственного «средства просмотра изображений». Я часто использовал pyodbc в прошлом, поэтому я могу снова использовать его здесь для подключения к базе данных SQL и, после подключения, для выполнения запросов, а также выполнения хранимых процедур, созданных ранее.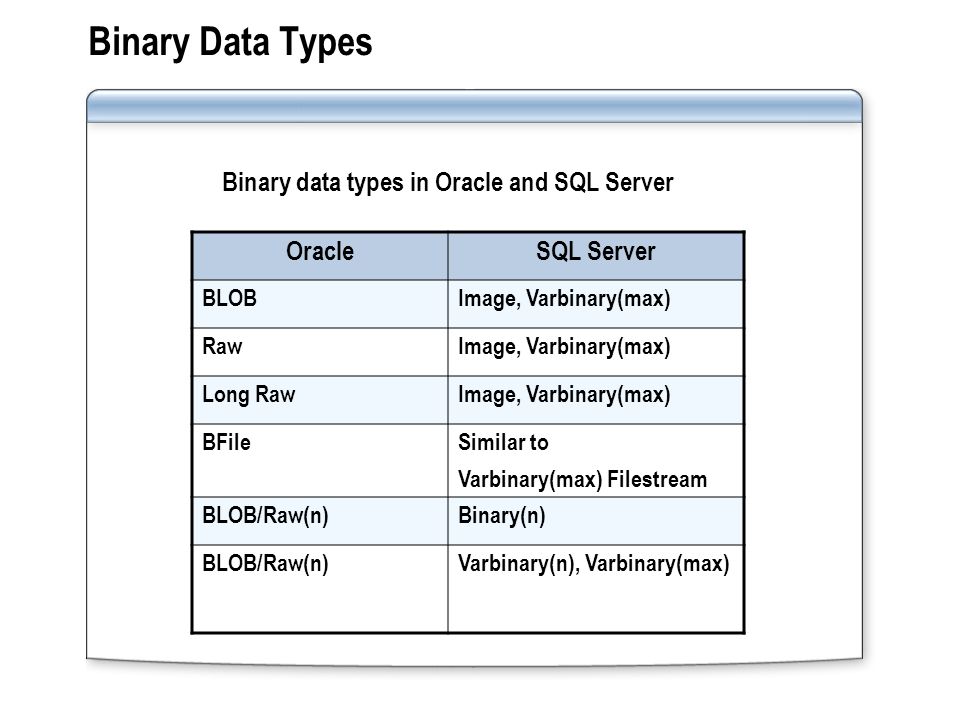 Ниже мой код:
Ниже мой код:
Для подключения используйте эту функцию:
Если я запускаю сценарий, он создает файл «employee_list.html», показанный ниже (открытый в веб-браузере):
Заключение
03 Упражнение исследовало множество тем, таких как переход от типа данных IMAGE к типу данных VARBINARY и способы преобразования, хранения и извлечения изображений с помощью объектов OLE Automation – все это путем выполнения операторов T-SQL в Azure Data Studio. Наконец, я использовал некоторый код Python для создания простой HTML-страницы для просмотра данных.
sql server 2008 — Есть ли большая техническая разница между типами данных VARBINARY (MAX) и IMAGE?
спросил
Изменено
7 лет, 9 месяцев назад
Просмотрено
21к раз
Я читал в Интернете эти заявления о SQL Server 931-1
(2 147 483 647) байт.
Есть ли действительно большая техническая разница между типами данных VARBINARY(MAX) и IMAGE ?
Если есть разница: нужно ли настраивать, как ADO.NET вставляет и обновляет поле данных изображения в SQL Server?
- image
- sql-server-2008
- ado.net
- varbinary
Они хранят одни и те же данные: на этом все.
» image » устарело и имеет ограниченный набор функций и операций, которые с ним работают. varbinary(max) можно использовать как более короткий varbinary (то же самое для text и varchar(max) ).
Не используйте изображение для любого нового проекта: просто найдите здесь проблемы, которые возникают у людей с типами данных изображение и текст из-за ограниченной функциональности.
Примеры из SO: One, Two
1
Я думаю, что технически они похожи, но важно отметить следующее из документации:
Типы данных ntext, text и image будут удалены в будущей версии MicrosoftSQL Server.
Типы данных фиксированной и переменной длины для хранения больших символов, отличных от Unicode и Unicode, и двоичных данных. Данные Unicode используют набор символов UNICODE UCS-2.
 Избегайте использования этих типов данных в новых разработках и планируйте модифицировать приложения, которые в настоящее время их используют. Вместо этого используйте nvarchar(max), varchar(max) и varbinary(max).
Избегайте использования этих типов данных в новых разработках и планируйте модифицировать приложения, которые в настоящее время их используют. Вместо этого используйте nvarchar(max), varchar(max) и varbinary(max).Они хранят одни и те же данные: на этом все.
«образ» устарел и имеет ограниченный набор функций и операций.
что с ним работают. varbinary(max) может работать как более короткий
varbinary (то же самое для текста и varchar(max)).Не используйте изображение для любого нового проекта: просто ищите проблемы здесь
люди имеют с изображениями и текстовыми типами данных из-за ограниченного
функциональность.
На самом деле VARBINARY может хранить любые данные, которые можно преобразовать в байтовый массив, например файлы, и это тот же процесс, что и IMAGE использует тип данных, поэтому, с этой точки зрения, оба типа данных могут хранить одни и те же данные.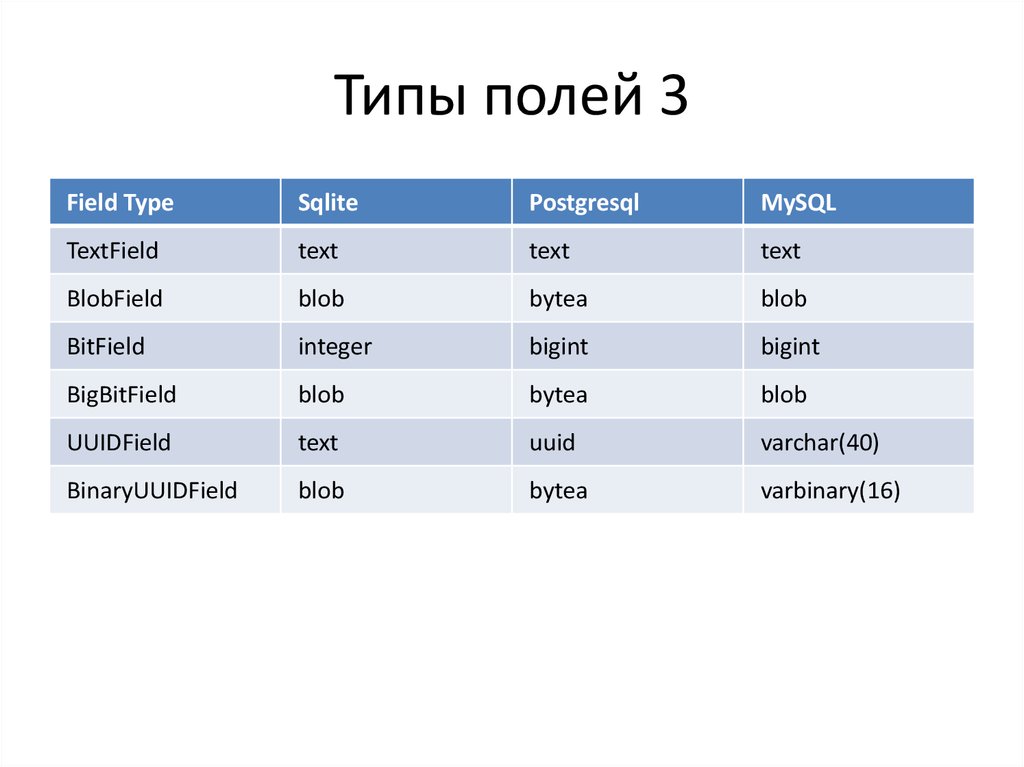
Но VARBINARY имеют свойство размера, а IMAGE принимает любой размер до ограничений типа данных, поэтому при использовании типа данных IMAGE вы потратите больше ресурсов для хранения тех же данных.
В Microsoft® SQL Server® тип данных IMAGE действительно устарел, поэтому вы должны сделать ставку на тип данных VARBINARY .
Но будьте осторожны: Microsoft® SQL Server® CE® (включая последнюю версию 4.0) по-прежнему использует тип данных IMAGE , и, вероятно, этот тип данных не «исчезнет» так скоро, потому что в версиях Compact Edition этот тип данных лучше любого другое для быстрого хранения файлов.
Я случайно нашел между ними одно различие. Вы можете вставить строку в тип изображения, но не в varbinary. Возможно, именно поэтому MS не рекомендует использовать тип изображения, поскольку на самом деле не имеет смысла устанавливать изображение со строкой.