Временные таблицы sql: MS SQL Server и T-SQL
Содержание
[ Вопрос дня ] Для чего и когда нужно удалять временные таблицы? – Проект ‘Курсы 1С’
Доброго дня, коллеги!
При работе с конструктором запроса у разработчика может возникнуть вопрос – для чего нужна настройка «Уничтожение временной таблицы»?
Слушатель курса Разработка и оптимизация запросов в 1С:Предприятие 8 попросил тренера помочь разобраться с этим вопросом. Он получил развернутый ответ и теперь пользуется этой возможностью для оптимизации запросов к базе данных. Теперь и вы тоже можете воспользоваться этой информацией 🙂
Вопрос
Почему в примерах с временными таблицами не используется уничтожение самой временной таблицы? Да и почти нигде не вижу, чтобы эту возможность использовали.
Ответ
По коду типовых конфигураций скорее не используется явное уничтожение временных таблиц.
Они явно удаляются, например, если возникает необходимость в менеджере временных таблиц создать повторно таблицу с таким же именем.
Значит, платформа автоматически следит за временем жизни временных таблиц.
Если в запросе явно не установлен менеджер временных таблиц, то платформа самостоятельно будет удалять временные таблицы из tempdb.
Для оптимизации SQL-сервер может использовать команду TRUNCATE TABLE вместо DELETE для ускорения операции.
Время жизни временной таблицы должно определяться временем жизни менеджера временных таблиц. Как только менеджер перестает существовать, можно удалять таблицы. Но существует явление, называемое «утечка памяти» – когда уже ненужные приложению участки памяти не освобождаются. При возникновении такой ситуации на сервере 1С временные таблицы могут подвиснуть в tempdb. Поэтому, я думаю, есть смысл явно удалять временные таблицы, если в них помещаются огромные объемы данных, чтобы застраховаться от утечки памяти. Точных числовых показателей таких размеров не встречал.
Размеры tempdb явно задаются в настройках MS SQL Server Management Studio. Их можно изменить в зависимости от имеющихся ресурсов.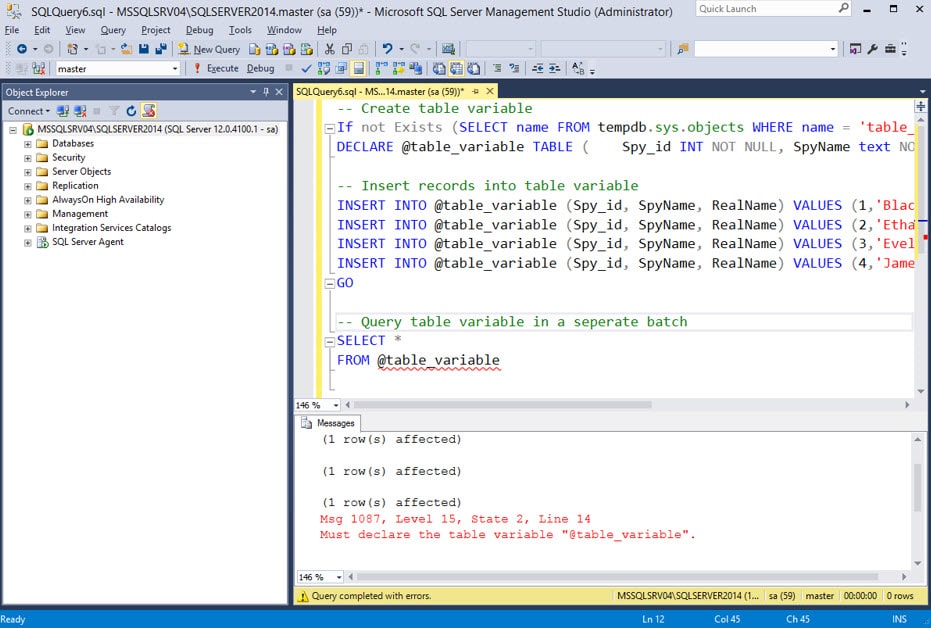 Можно установить, что размер этой базы данных будет неограничен. По умолчанию размер этой базы данных как раз неограничен.
Можно установить, что размер этой базы данных будет неограничен. По умолчанию размер этой базы данных как раз неограничен.
Важно, что tempdb создается заново при каждом перезапуске Microsoft SQL Server. После перезапуска не будет «подвисших» временных таблиц.
А вы сталкивались с утечкой памяти из-за помещения огромных объемов данных во временные таблицы? Пишите в комментариях!
Понимать, как работают запросы и уметь их строить — обязательный навык для всех, кто дорабатывает и внедряет 1С.
Специальный курс для этой задачи: Запросы в 1С 8.3, Базовый курс (с нуля до уровня Специалист по платформе).
После курса Вы сможете:
- Строить сложные запросы с несколькими источниками данных
- Уверенно задействовать вложенные запросы и временные таблицы
- Использовать встроенный язык для обработки результатов запроса
- Учитывать особенности соединений и объединений нескольких таблиц.

- Разрабатывать запросы на уровне задач Аттестации 1С:Специалист по платформе.
Программа, стоимость, условия и регистрация в группу:
«Запросы в 1С 8.3, Базовый курс (с нуля до уровня Специалист по платформе)»
Для всех, кто внедряет и дорабатывает 1С.
Смотреть
Сравнение временных таблиц, табличных переменных и обобщенных табличных выражений (CTE)
Последнее время стали часто обсуждать временные таблицы, табличные переменные и cte. По этой причине было принято решение вынести это обсуждение в отбельную статью.
Временные таблицы. Производительность (temporal tables)
Существует несколько основных моментов, на которые стоит обратить внимание:
- Перемещение данных во временную таблицу может вызвать большую нагрузку на дисковую подсистему, где она лежит tempdb.
- SQL Server очень плотно работает с tempdb и бывает сложно гарантировать время выполнения запросов, которые активно её используют, так как может быть существенная конкуренция за эту БД
Большим преимуществом временных таблиц является то, что на них можно создавать индексы и статистику. Это может существенно ускорить выполнение запросов.
Это может существенно ускорить выполнение запросов.
Табличные переменные. Производительность
Самое большие заблуждение, связанное с табличными переменными это то, что многие полагают, что они всегда располагаются в памяти, но это не так. Табличные переменные, как и временные таблицы в последних версиях SQL Server, располагаются в памяти до того момента, пока размер выборки не станет слишком большим, после чего он непременно будет сброшен в tempdb. Если памяти недостаточно или SQL Server испытывает давление на память, то сброс в tempdb происходит чаще.
На что стоит обратить внимание:
- Табличные переменные не позволяют выполнять DDL операции, поэтому вы не можете создать индексы, для улучшения выполнения запросов. Создание UNIQUE constraint позволяет обойти это ограничение.
- Если вопросы с индексами решить как-то возможно, то отсутствие статистики на табличных переменных никак не побороть. На средних и больших выборка это приведёт к проблемам с производительностью.

Создавайте табличные переменные только на малом объёме данных, где нет необходимости в индексах и статистике. Никогда не пользуйтесь табличными переменными, если выборка может содержать более 1000 строк. Я рекомендую не пользоваться табличными переменными уже начиная с 50-100 строк.
Обобщённое табличное выражение. Производительность (CTE)
CTE — это на самом деле только синтаксический способ разбить запрос, который работает в рамках одного запроса. Внутри SQL Server это похоже на создание VIEW «на лету», к которому можно обратиться несколько раз в рамках одного запроса. Вот когда Microsoft рекомендует использовать CTE:
- Создания рекурсивных запросов. Дополнительные сведения см. в разделе Рекурсивные запросы, использующие обобщенные табличные выражения.
- Замены представлений в тех случаях, когда использование представления не оправдано, то есть тогда, когда нет необходимости сохранять в метаданных базы его определение.
- Группирования по столбцу, производного от скалярного подзапроса выборки или функции, которая недетерминирована или имеет внешний доступ.
- Многократных ссылок на результирующую таблицу из одной и той же инструкции.
Таблицы сравнения
| Temp Table | Global Temp Table | Table Variable | CTE |
| CREATE TABLE #t (ID INT) | CREATE TABLE ##t (ID INT) | DECLARE @t TABLE (ID INT) | ;WITH CTE_T AS (SELECT ID FROM table) |
| Создаётся в tempdb | Создаётся в tempdb | Создаётся в tempdb, но ведёт себя как переменная | Создаётся в памяти, при недостаткте которой, данные помещаются в tempdb |
| Доступна только в текущей сессии | Доступна всем сессиям | Доступна только в текущем батче текущей сессии | Доступна только в текущем запросе текущей сесcии |
| Доступна пока работает активная сессия | Доступна всем сессиям пока активна сессия, создавшая таблицу | Автоматические уничтожается когда сессия отключается/переходит на другой батч | Автоматически уничтожается, после перехода на другой запрос |
| Могут быть созданы: Primary key, индексы, статистика, ограничения | Могут быть созданы: Primary key, индексы, статистика, ограничения | Кластерные и некластерные индексы могут быть созданы с помощью первичного ключа | Не поддерживается |
| Может быть изменена после создания | Может быть изменена после создания | Не может быть изменена после создания | Не может быть изменена после создания |
| Не может использоваться во VIEW | Не может использоваться во VIEW | Не может использоваться во VIEW | Может использоваться во VIEW |
| Используйте для больших объёмов данных | Используйте для больших объёмов данных, но будьте аккуратны с именами, так как невозможно создать 2 одинаковых названия | Используйте для малого набора данных | Используйте для малого набора данных или когда необходима рекурсия |
Запись опубликована в рубрике Полезно и интересно с метками compare. Добавьте в закладки постоянную ссылку.
Добавьте в закладки постоянную ссылку.
CTE, просмотров или временных таблиц?
Давиде Маури
20 января 2023 6 1
Я только что закончил смотреть видео от @GuyInACube о Common Table Expressions
и заметил, что в нескольких комментариях была просьба объяснить, в чем разница между Common Table Expressions , представления и временные таблицы.
Это довольно распространенный вопрос, и пришло время дать на него простой, лаконичный и ясный ответ раз и навсегда.
Common Table Expressions
Common Table Expression (CTE) можно рассматривать как табличный подзапрос. Подзапрос таблицы, также иногда называемый производной таблицей , представляет собой запрос, который используется в качестве отправной точки для построения другого запроса. Как и подзапрос, он будет существовать только на время выполнения запроса. CTE упрощают написание кода, так как вы можете написать CTE в верхней части вашего запроса — у вас может быть более одного CTE, и CTE могут ссылаться на другие CTE — а затем вы можете использовать определенные CTE в своем основном запросе.
CTE упрощают написание кода, так как вы можете написать CTE в верхней части вашего запроса — у вас может быть более одного CTE, и CTE могут ссылаться на другие CTE — а затем вы можете использовать определенные CTE в своем основном запросе.
CTE облегчают чтение кода и способствуют повторному использованию: представьте, что в каждом CTE вы определяете подмножество данных, с которыми хотите работать в основном запросе, и даете ему метку. В основном запросе вы можете просто сослаться на это подмножество, используя его метку, вместо того, чтобы писать весь подзапрос.
CTE также позволяют выполнять некоторые сложные сценарии, например рекурсивные запросы.
Представления
Представления — это объекты метаданных, которые позволяют сохранять определение (и только определение, а не результат!) запроса, а затем использовать его позже, ссылаясь на его имя. Процитирую книгу, которую я написал пару лет назад: «Представление — это не что иное, как определение запроса, помеченное именем и используемое как таблица. На самом деле просмотры также известны как 9 0018 виртуальные таблицы , даже если это имя используется редко». могут выполнить некоторую специальную оптимизацию, зная, что они эфемерны, которые будут автоматически удалены после выхода из области действия (например, когда соединение, которое их создало, разрывается).
На самом деле просмотры также известны как 9 0018 виртуальные таблицы , даже если это имя используется редко». могут выполнить некоторую специальную оптимизацию, зная, что они эфемерны, которые будут автоматически удалены после выхода из области действия (например, когда соединение, которое их создало, разрывается).
Временные таблицы не имеют особых отношений с запросами: вы можете просто взять любой результат запроса и сохранить его во временную таблицу, используя, например, команду SELECT INTO.
После завершения команды SELECT INTO взаимосвязь между запросом, создавшим набор результатов, и временной таблицей, которая использовалась для хранения этого набора результатов, завершается. Думайте об этом как об очень простом процессе ETL. После его завершения ничто не будет автоматически обновлять или синхронизировать данные во временной таблице с набором результатов, сгенерированным запросом, используемым для перемещения данных во временную таблицу.
Когда что использовать?
Начнем с простого
Допустим, у вас есть сложный запрос, в котором вы должны собрать вместе несколько разных таблиц, чтобы получить нужный набор результатов.
👉 Первое, что важно иметь в виду, это то, что подзапросы, представления и CTE концептуально одинаковы для механизма запросов. SQL является декларативным языком, в котором, если нет каких-либо ограничений приоритета, налагаемых используемым оператором, все оценивается «все сразу» .
Это означает, что нет никакой гарантии, что подзапрос (или CTE, или представление) будет выполнен до запроса, который его использует.
Это очень важная концепция. Это может показаться вам странным, но это ключевая особенность SQL, так как оптимизатор запросов может принять решение — при условии, что конечный результат будет правильным — применить фильтры и оптимизацию там, где это более уместно.
Предположим, например, что у вас есть подзапрос, который фильтрует всех людей, живущих в Сиэтле. В этом подзапросе вы хотите добавить дополнительный фильтр, чтобы ограничить результирующий набор только теми людьми, которых зовут Давиде.
👉 Благодаря тому, что SQL является «все сразу», оптимизатор может протолкнуть внешний фильтр во внутренний подзапрос и тут же найти всех тех людей, которые живут в Сиэтле и зовут Давиде.
Если бы SQL не был «все сразу», механизм базы данных должен был бы сначала выполнить запрос, а затем искать среди результирующих строк только те, для которых имя — Давиде.
Это было бы невероятной тратой ресурсов — использовалось бы больше ЦП и памяти — и это дало бы гораздо худший результат производительности.
Вдобавок к этому использование индекса стало бы намного более сложным и менее вероятным. Если бы у нас был индекс по имени людей, он был бы полезен только в том случае, если бы мы могли фильтровать сначала по имени, а затем по городу. К счастью, оптимизатор может перемещать фильтры, учитывая, что запрос просто указывает, что вы хотите, а не как это получить. Если бы вместо этого нам нужно было сначала выполнить подзапрос, а затем внешний запрос, ну… вы можете догадаться, что индекс не был бы таким полезным, верно?
Давайте немного усложним
До сих пор из того, что только что было объяснено, кажется, что использование подзапроса, представления или CTE всегда является умной идеей, поскольку мы просто позволяем оптимизатору запросов выполнять свою работу наилучшим образом.
На бумаге да. На практике мы должны учитывать, что оптимизатор запросов на самом деле не знает точно , какие значения содержатся в каждой таблице и как распределяются данные. Имеет ли он нормальное распределение? Или смещено в сторону каких-то конкретных значений?
🚗 Вы можете думать об оптимизаторе запросов как о своей автомобильной навигационной системе. Когда он планирует маршрут, он будет делать это с учетом самой свежей и точной информации о трафике… но вы не будете на 100% уверены, что дорога, которую он вам предложит, будет лучшим выбором, пока вы не там. Что делать, если по какой-либо причине произошел внезапный всплеск трафика? Что ж, теперь вы там, и вам просто нужно подождать в очереди (или, конечно, выбрать другую дорогу).
🙀 База данных аналогична в том смысле, что в ней будет статистическая информация о том, как данные распределяются внутри таблицы. Это полезно, чтобы попытаться выбрать наилучшую стратегию для возврата данных, которые вы запрашиваете в запросе, но это также связано с тем фактом, что статистика поставляется с определенной степенью ошибки. Это означает, что обработчик запросов может оценить, что подзапрос вернет «X» строк, но при выполнении он действительно вернет «Y» строк. Если у вас есть вложенные подзапросы, ошибка будет распространяться и может усиливаться, вплоть до того, что — потенциально — оптимизатор запросов попытается использовать индекс «A», поскольку он думает, что в какой-то момент будет только — например — 10 строк задействовано, но на самом деле будет 10 КБ, что делает использование индекса потенциально плохим выбором.
Это означает, что обработчик запросов может оценить, что подзапрос вернет «X» строк, но при выполнении он действительно вернет «Y» строк. Если у вас есть вложенные подзапросы, ошибка будет распространяться и может усиливаться, вплоть до того, что — потенциально — оптимизатор запросов попытается использовать индекс «A», поскольку он думает, что в какой-то момент будет только — например — 10 строк задействовано, но на самом деле будет 10 КБ, что делает использование индекса потенциально плохим выбором.
Амплитуда распространения и усиления ошибки полностью зависит от самого запроса, данных в ваших таблицах и других факторов (обновляемая статистика, партиции и т.д.). Чем больше у вас ссылок на таблицы, тем больше вероятность того, что это произойдет. Представьте себе сложный запрос с использованием CTE, вызывающих несколько представлений, внутри которых есть подзапросы. Ошибки оценки могут накапливаться.
Как узнать, есть ли у вас ошибки оценки? Планы выполнения – ваши друзья. Они покажут, какие шаги будут предприняты для создания набора результатов, и для каждого шага они покажут предполагаемое и текущее количество затронутых строк.
Они покажут, какие шаги будут предприняты для создания набора результатов, и для каждого шага они покажут предполагаемое и текущее количество затронутых строк.
Если вы заметили, что оценка совершенно неверна (например, разница в несколько порядков), вам может потребоваться помощь оптимизатору запросов.
Временные таблицы в помощь?
Временные таблицы могут помочь значительно уменьшить или даже исправить плохую оценку строки из-за вышеупомянутого усиления ошибки. Как? Что ж, сохраняя результат подзапроса во временную таблицу, вы сбрасываете такое усиление ошибок, поскольку механизм запросов может использовать данные во временной таблице и, таким образом, убедиться, что он больше не угадывает слишком много.
Еще одна причина для использования временной таблицы — если у вас есть сложный запрос, который нужно использовать один или несколько раз на последующих шагах, и вы хотите избежать траты времени и ресурсов на выполнение этого запроса снова и снова (особенно если набор результатов мал по сравнению с исходными данными, и/или последующие запросы не смогут применить какую-либо оптимизацию к подзапросу, например, когда вы работаете с агрегированными данными)
Но универсального решения не существует » здесь. Вы должны попытаться увидеть, достаточно ли для вашего варианта использования подзапроса или нужна временная таблица, чтобы дать обработчику запросов некоторые рычаги для получения более точных оценок и, следовательно, лучшего плана выполнения.
Вы должны попытаться увидеть, достаточно ли для вашего варианта использования подзапроса или нужна временная таблица, чтобы дать обработчику запросов некоторые рычаги для получения более точных оценок и, следовательно, лучшего плана выполнения.
Имейте также в виду, что использование временных таблиц сопряжено с некоторыми накладными расходами. Помимо очевидного использования пространства, ресурсы — и, следовательно, время — будут потрачены только на их загрузку. Иногда вам даже может понадобиться создать индексы для временных таблиц, чтобы обеспечить максимальную производительность последующих запросов.
Данные, сохраненные во временной таблице, также не обновляются автоматически с учетом любых изменений, которые могут быть внесены в данные в таблицах, используемых в исходном запросе. Вы несете ответственность за обновление данных во временной таблице в любое время, когда вам это нужно (другим вариантом может быть использование индексированных представлений: см. ниже более подробную информацию об этой функции).
Другие вещи, которые вам могут быть интересны
Индексированные представления
Можно создать специальный вид представлений, Индексированные представления , чтобы полученный результат материализовался и сохранился в файле данных базы данных. С индексированными представлениями результат не нужно каждый раз пересчитывать, поэтому они отлично подходят для повышения производительности чтения. В сценариях HTAP они могут помочь значительно повысить производительность. Механизм базы данных также будет следить за тем, чтобы каждый раз, когда обновляются данные в одной из основанных таблиц, используемых в индексированном представлении, сохраняемый результат также обновлялся, чтобы у вас всегда были свежие и обновленные значения.
Встроенные функции с табличным значением (также называемые параметризованными представлениями)
Иногда вам может понадобиться представление с параметрами, чтобы упростить возврат только интересующего вас подмножества значений. В Azure SQL и SQL Server вы можете создавать параметризованные представления. Они попадают (точнее, ИМХО) под эгидой «Функций», и конкретно их можно создать с помощью встроенных функций с табличным значением:
В Azure SQL и SQL Server вы можете создавать параметризованные представления. Они попадают (точнее, ИМХО) под эгидой «Функций», и конкретно их можно создать с помощью встроенных функций с табличным значением:
Заключение
Теперь у вас должно быть четкое представление о том, в чем разница между CTE (или подзапросы), представления и временные таблицы.
Я рекомендую начать с CTE, а затем использовать временные таблицы по мере необходимости, чтобы вы могли получить желаемую производительность с минимально возможными накладными расходами. (Мне нравится говорить, что использование временного стола похоже на соль с едой. Вы всегда можете добавить его позже.)
Если у вас остались вопросы, не забудьте оставить их в комментариях, чтобы мы могли продолжить обсуждение!
Фото Pixabay с сайта Pexels
sql server — Как правильно проверить и удалить временную таблицу?
Подход 1:
ЕСЛИ OBJECT_ID('tempdb..#MyTempTbl') НЕ NULL
УДАЛИТЬ ТАБЛИЦУ #MyTempTbl;
Подход 2:
ЕСЛИ СУЩЕСТВУЕТ (ВЫБЕРИТЕ * ИЗ [tempdb].
 [sys].[objects]
ГДЕ [имя] = N'#MyTempTbl')
УДАЛИТЬ ТАБЛИЦУ [#MyTempTbl];
[sys].[objects]
ГДЕ [имя] = N'#MyTempTbl')
УДАЛИТЬ ТАБЛИЦУ [#MyTempTbl];
Как правильно проверить и удалить временную таблицу?
Контекст — это хранимая процедура, вызываемая заданием агента.
Я попытался выполнить запрос к [tempdb].[sys].[objects] и заметил, что глобальная временная таблица получает то же имя, а локальная временная таблица получает имя со знаком подчеркивания в конце, например MyTempTbl______. Поэтому мне было интересно, есть ли стандартный способ проверить, существует ли временная таблица, и если да, то ее удалить, я ищу синтаксис, который будет работать как для локальных, так и для глобальных временных таблиц.
- sql-server
- sql-server-2019
- временные таблицы
- drop-table
0
Подход 1 имеет то преимущество, что работает правильно.
Подход 2 не работает для локальных временных таблиц, поскольку запись в [tempdb].[sys].[objects] имеет внутреннее имя, сгенерированное системой. Это работает для глобальных временных таблиц.
Это работает для глобальных временных таблиц.
Вы также можете использовать DROP IF EXISTS, но в хранимых процедурах (и других модулях) это не нужно и даже потенциально опасно.
В хранимых процедурах временные таблицы автоматически удаляются в конце процедуры.
… явное удаление временной таблицы в хранимой процедуре не требуется и поэтому не рекомендуется…
Обратите внимание, что не имеет значения (с точки зрения кэширования), удаляете ли вы явным образом временную таблицу в конце процедуры или нет. В любом случае временную таблицу можно кэшировать.
Обычно не рекомендуется использовать общее имя, такое как #MyTemp для локальных временных таблиц в модулях. Используйте что-то конкретное для модуля, чтобы предотвратить проблемы, описанные в разделе Может ли имя временной таблицы вызвать раздувание кэша плана?
0
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.