Вырезать часть строки sql: SUBSTRING (Transact-SQL) — SQL Server
Содержание
Разбить строку ABAP SUBSTRING | Блог ABAP YouCoder
Артур Оставить комментарий
Разбить строку ABAP SUBSTRING можно множеством вариантов. Разбиения строки на части в зависимости от поставленной задачи.
Есть задачи в которых есть необходимость выделить подстроку из строки по определённым критериям. Для решения данной задачи отлично подходит функция substring с множеством своих вариантов. Рассмотрим подробнее каждый из них:
Разбиение строки ABAP с примерами
SUBSTRING ABAP Разделение строки на подстрокиSUBSTRING – Обрезать строку SAP
Функция SUBSTRING возвращает подстроку длины равной len при этом берёт данную строку с отступом равным off.
lv_substring = substring( val = ‘ABCDEFGH’ off = 2 len = 2 ). » CD
lv_substring = substring( val = ‘ABCDEFGH’ off = 2 len = 2 ). » CD |
В нашем случае результатом выполнения функции будет: CD
Есть более краткая форма записи этого выражения, если входящий параметр для обработки это переменная, а не статическая строка.
DATA(lv_text) = |20-04-2020|.
DATA(lv_youcoder) = lv_text+6(4).
lv_youcoder = substring( val = lv_text off = 6 len = 4 ).
DATA(lv_text) = |20-04-2020|. DATA(lv_youcoder) = lv_text+6(4). lv_youcoder = substring( val = lv_text off = 6 len = 4 ). |
Результатом выделения подстроки будет строка: 2020. Как для первого так и для второго выражения.
Важным ограничением этого способа является то, что если при обращении к строке происходит выход за её границы произойдёт ошибка.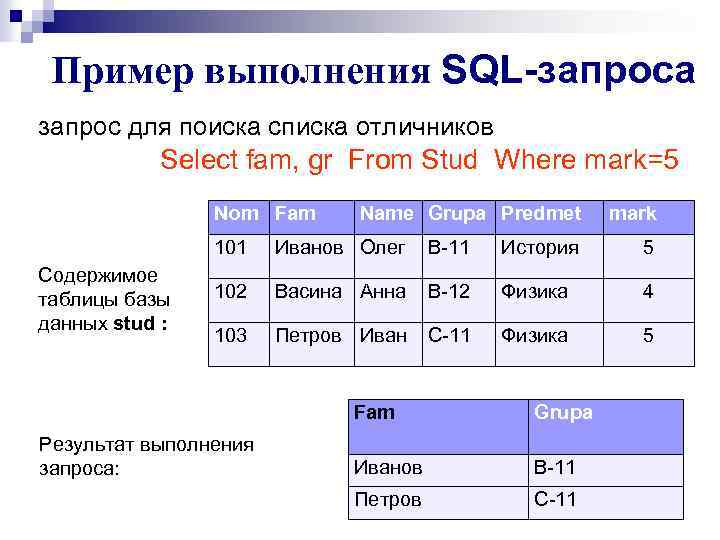 Пример ошибочного обращения:
Пример ошибочного обращения:
lv_youcoder = substring( val = lv_text off = 6 len = 5 ).
lv_youcoder = substring( val = lv_text off = 6 len = 5 ). |
SUBSTRING_FROM – выделить подстроку ABAP начиная с символа
Возвращает подстроку начиная с первого вхождения символов sub включая эти символы и до конца строки. По результату получим: EFGH
lv_substring = substring_after( val = ‘ABCDEFGH’ sub = ‘CD’ ). » EFGH
lv_substring = substring_after( val = ‘ABCDEFGH’ sub = ‘CD’ ). » EFGH |
SUBSTRING_BEFORE – обрезать строку ABAP
Возвращает подстроку начиная с первого символа строки до первого вхождения символов sub НЕ включая эти символы.
По результату получим: AB
lv_substring = substring_before( val = ‘ABCDEFGH’ sub = ‘CD’ ). » AB
lv_substring = substring_before( val = ‘ABCDEFGH’ sub = ‘CD’ ). |
 » AB
» ABSUBSTRING_TO – обрезать строку ABAP
Возвращает подстроку начиная с первого символа строки до первого вхождения символов sub включая эти символы.
По результату получим: ABCD
lv_substring = substring_to( val = ‘ABCDEFGH’ sub = ‘CD’ ). » ABCD
lv_substring = substring_to( val = ‘ABCDEFGH’ sub = ‘CD’ ). » ABCD |
SPLIT – разбить строку ABAP на несколько
Так же бывают задачи разбиения одной строки на несколько подстрок.
Разбиение строки оператором SPLIT по заданному разделителю
DATA(lv_dom_http) = ‘https://youcoder.ru’. SPLIT lv_img_http AT ‘://’ INTO: DATA(lv_http) DATA(lv_dom_http).
DATA(lv_dom_http) = ‘https://youcoder.ru’. SPLIT lv_img_http AT ‘://’ INTO: DATA(lv_http) DATA(lv_dom_http). |
По итогу выполнения программы переменным будут присвоены следующие значения:
lv_http = ‘https’. lv_dom_http = ‘youcoder.ru’.
lv_dom_http = ‘youcoder.ru’.
lv_http = ‘https’. lv_dom_http = ‘youcoder.ru’. |
Шаблоны как азбить строку ABAP SUBSTRING на подстроки определённой длины.
Рассмотрим пример использования в задаче. Часто бывает, что стандартный метод или ФМ принимает на вход не строку, а таблицу с последовательностями символов определённой длины. Пример использования конструкции для решения задачи в статье: Вывод текста в окне, а так это подробно разобрано в видео к этой статье.
Шаблон как разбить строку ABAP
SUBSTRING:
DATA:
lt_text_table TYPE STANDARD TABLE OF text120.
» lv_text — это произвольная строка, которую разбиваем
» Получаем длину строки
DATA(lv_strlen) = strlen( lv_text ).
» Длина подстрок разбиения
DATA(lv_sep) = 120.
DATA(lv_count) = 0.
» Пока длина остатка подстроки меньше длины разбиения
WHILE lv_strlen — lv_count > lv_sep.
» Выделяем подстроку с lv_count длиной lv_sep.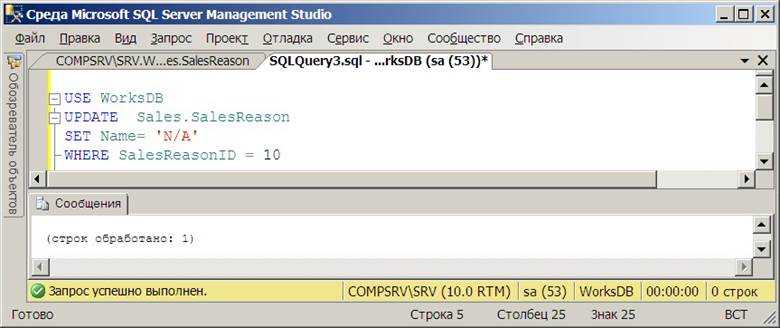
DATA(lv_substr) = CONV ( substring( val = lv_text off = lv_count len = lv_sep ) ).
» Добавляем подстроку в таблицу для дальнейшего использования
APPEND lv_substr TO lt_text_table.
» Добавляем к счётчику длину отрезанной строки
lv_count = lv_count + lv_sep.
ENDWHILE.
» Делаем действие аналогичное, но для последней части строки
lv_substr = substring( val = lv_text off = lv_count ).
APPEND lv_substr TO lt_text_table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | DATA: lt_text_table TYPE STANDARD TABLE OF text120.
» lv_text — это произвольная строка, которую разбиваем
» Получаем длину строки DATA(lv_strlen) = strlen( lv_text ).
» Длина подстрок разбиения DATA(lv_sep) = 120.
DATA(lv_count) = 0. » Пока длина остатка подстроки меньше длины разбиения WHILE lv_strlen — lv_count > lv_sep.
» Выделяем подстроку с lv_count длиной lv_sep. DATA(lv_substr) = CONV ( substring( val = lv_text off = lv_count len = lv_sep ) ).
» Добавляем подстроку в таблицу для дальнейшего использования APPEND lv_substr TO lt_text_table.
» Добавляем к счётчику длину отрезанной строки lv_count = lv_count + lv_sep. ENDWHILE.
» Делаем действие аналогичное, но для последней части строки lv_substr = substring( val = lv_text off = lv_count ). APPEND lv_substr TO lt_text_table. |
Короткий шаблон получения подстрок ABAP определённой длины:
DATA:
lt_text_table TYPE STANDARD TABLE OF text40.
» lv_text — это произвольная строка, которую разбиваем
DATA(lv_strlen) = strlen( lv_text ).
DATA(lv_sep) = 40.
DATA(lv_count) = 0.
WHILE lv_strlen — lv_count > lv_sep.
APPEND lv_text+lv_count(lv_sep) TO lt_text_table.
lv_count = lv_count + lv_sep.
ENDWHILE.
APPEND lv_text+lv_count TO lt_text_table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | DATA: lt_text_table TYPE STANDARD TABLE OF text40.
» lv_text — это произвольная строка, которую разбиваем
DATA(lv_strlen) = strlen( lv_text ). DATA(lv_sep) = 40. DATA(lv_count) = 0.
WHILE lv_strlen — lv_count > lv_sep. APPEND lv_text+lv_count(lv_sep) TO lt_text_table. lv_count = lv_count + lv_sep. ENDWHILE.
APPEND lv_text+lv_count TO lt_text_table. |
Шаблон с использованием ФМ
HR_RU_SLPIT_STRING0:
Использование этого ФМ показано на примере заполнения полей имени при создании кредитора.
l_string = ‘ООО «ТЫ КОДЕР» загружено с сайта’.
CALL FUNCTION ‘HR_RU_SLPIT_STRING0’
EXPORTING
string = l_string
length = 40
separator = l_separator
TABLES
split = lt_split.
LOOP AT lt_split REFERENCE INTO DATA(lr_split).
CASE sy-tabix.
WHEN 1.
ls_data-name = lr_split->char255.
WHEN 2.
ls_data-name_2 = lr_split->char255.
WHEN 3.
ls_data-name_3 = lr_split->char255.
WHEN 4.
ls_data-name_4 = lr_split->char255.
ENDCASE.
ENDLOOP.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | l_string = ‘ООО «ТЫ КОДЕР» загружено с сайта’. CALL FUNCTION ‘HR_RU_SLPIT_STRING0’ EXPORTING string = l_string length = 40 separator = l_separator TABLES split = lt_split. LOOP AT lt_split REFERENCE INTO DATA(lr_split). CASE sy-tabix. WHEN 1. ls_data-name = lr_split->char255. WHEN 2. ls_data-name_2 = lr_split->char255. WHEN 3. ls_data-name_3 = lr_split->char255. WHEN 4. ls_data-name_4 = lr_split->char255. ENDCASE. ENDLOOP. |
ABAPСтроки
Сайт ABAP программирование YouCoder – это сборник статей и видео о языке программирования ABAP и работе в SAP системе. Есть как уроки abap для начинающих так и новый синтаксис в ABAP и SAP обучение для консультантов SAP.
SQL: вложенные операторы | Лаборатория качества
Всем привет!
Кому-то данный очерк покажется банальным и бесполезным, но, как показала практика, не все знают про этот, казалось бы, очевидный “лайфхак” — то, что результат работы одних операторов может быть операндом другого оператора.
Сложно и непонятно? Сейчас поясню на примере.
Вот, допустим, у нас есть массив однотипных строк. И нам нужно вырезать из каждой строки часть от одного символа до другого символа.
Что нам для этого надо сделать? Найти 2 значения, которые будут вычисляться динамически, на ходу, и будут уникальны для каждой отдельной строки в массиве.
Итого нам понадобится 2 команды — на вырезание подстроки и на определение позиции определённого символа.
Например, есть у нас строковое значение “[email protected]”. Из него будем вырезать часть, находящуюся между дефисом и @ (в нашем случае это будет “lab”).
Давайте начинать с малого: команды вырезания подстроки из строки в MySQL — это substr, и она имеет следующий формат: substr(a, b, c), где
a — строка, из которой вырезаем,
b — позиция, с которой вырезаем,
c — кол-во символов, которое вырезаем.
Дальше нам понадобится команда, которая ищет символ в строке и возвращает его позицию (первого вхождения) — locate. Она пишется так: locate(a,b), где
а — символ, который ищем,
b — строка, в которой ищем.
И этих инструментов нам будет, в принципе, достаточно. Что делаем дальше?
Что делаем дальше?
Ну, для начала, будем искать позицию, с которой начнём вырезать(substr) — это будет позиция символа “-”. Вот так будет выглядеть команда поиска позиции дефиса в строке:
locate(‘-‘, ‘[email protected]’),
а вот так:
select substr(‘[email protected]’, locate(‘-‘, ‘[email protected]’)), —
вся команда, вырезающая подстроку с дефиса и до конца (да, вы правильно поняли — substr можно применять и без последнего параметра, тогда будет вырезано всё до конца строки). И вот таким будет результат работы этого запроса: “[email protected]”
Почему туда попал дефис? Да потому, что мы искали позицию дефиса в строке, а начать вырезать нам нужно не с дефиса, а со следующего за ней символа. В итоге, приходим к следующему:
select substr(‘[email protected]’, locate(‘-‘,’[email protected]’)+1)
Этот запрос у нас возвращает строку без дефиса: “lab@mail. ru”.
ru”.
Полдела сделано, в принципе.
Едем дальше — теперь нам надо указать, сколько символов мы будем вырезать . Для этого мы будем делать “финт ушами” — из позиции символа “@” будем вычитать позицию символа “-” +1(нам же нужен не сам дефис, а следующий за ним символ). Делается это так:
select locate(‘@’, ‘[email protected]’) — (locate(‘-‘, ‘[email protected]’) + 1)
В результате получаем цифру 3 — это длина текста между дефисом и собакой. Теперь осталось это дело вставить в выражение substr. Получаем на выходе вот такую монструозную штуку:
select substr(‘[email protected]’, locate(‘-‘, ‘[email protected]’) + 1, locate(‘@’, ‘[email protected]’) — (locate(‘-‘, ‘[email protected]’)+1))
Итогом получаем вожделённое “lab”
Страшно? Понимаю, сам испугался. Давайте еще раз по кускам рассмотрим эту дичь:
substr(‘quality-lab@mail. ru’, — говорим, что будем вырезать подстроку из строки
ru’, — говорим, что будем вырезать подстроку из строки
locate(‘-‘, ‘[email protected]’) + 1, — в качестве параметра “с какого места начнём вырезать” указываем символ, следующий за дефисом;
locate(‘@’, ‘[email protected]’) — (locate(‘-‘, ‘[email protected]’)+1)) — в качестве параметра “сколько символов будем вырезать” указываем разницу в позициях между символом, следующим за дефисом и @.
Вот, в принципе, и всё. Здесь мы рассмотрели на примере, как можно одни операторы использовать внутри других. Надеюсь, материал был полезен).
Если вам стало интересно, что за зверь такой “sql” — приходите к нам на ПОИНТ, я вас научу росчерком пера писать запросы, жонглировать типами данных и вообще повелевать информацией!
sql — Я хочу удалить часть строки из строки
Заранее спасибо.
Я хочу удалить строку после . включая . , но длина переменная и строка может быть любой длины.
1)Пример:
Вход:- SCC0204.X и FRK0005.X и RF0023.X и ADF1010.A и HGT9010.V
Выход: SCC0204 и FRK0009 и HGT9010 и RF0010 и RF0023. 0013
Я пытался использовать charindex, но поскольку длина продолжает меняться, я не смог этого сделать. Я хочу обрезать значения, заканчивая только X
Будем признательны за любую помощь.
- sql
- tsql
3
Предполагая, что есть только одна точка
ТАБЛИЦА ОБНОВЛЕНИЯ
SET имя_столбца = левое (имя_столбца, charindex ('.', имя_столбца) - 1)
Для SELECT
выберите left(column_name, charindex('.', column_name) - 1) AS col
из вашей_таблицы
Надеюсь, это поможет. Код обрезает строку только в том случае, если значение имеет десятичное "." в нем и если это значение равно . X
X
;С cte_TestData(Code) AS
(
ВЫБЕРИТЕ 'SCC0204.X' ОБЪЕДИНЕНИЕ ВСЕХ
ВЫБЕРИТЕ 'FRK0005.X' ОБЪЕДИНЕНИЕ ВСЕХ
ВЫБЕРИТЕ 'RF0023.X' ОБЪЕДИНЕНИЕ ВСЕХ
ВЫБЕРИТЕ 'ADF1010.A' СОЕДИНЕНИЕ ВСЕ
ВЫБЕРИТЕ 'HGT9010.V' СОЕДИНЕНИЕ ВСЕ
ВЫБЕРИТЕ 'SCC0204' ОБЪЕДИНЕНИЕ ВСЕХ
ВЫБЕРИТЕ «FRK0005»
)
ВЫБЕРИТЕ ДЕЛО
КОГДА CHARINDEX('.', Код) > 0 И ПРАВО(Код,2) = '.X'
THEN SUBSTRING(Code, 1, CHARINDEX('.', Code) - 1)
ЕЩЕ код
КОНЕЦ
ОТ cte_TestData
Если критерием является только замена удалить .X , то, вероятно, это также должно работать
;С cte_TestData(Code) AS ( ВЫБЕРИТЕ 'SCC0204.X' ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'FRK0005.X' ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'RF0023.X' ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ 'ADF1010.A' СОЕДИНЕНИЕ ВСЕ ВЫБЕРИТЕ 'HGT9010.V' СОЕДИНЕНИЕ ВСЕ ВЫБЕРИТЕ 'SCC0204' ОБЪЕДИНЕНИЕ ВСЕХ ВЫБЕРИТЕ «FRK0005» ) ВЫБЕРИТЕ ЗАМЕНИТЬ (Код,'.X','') ОТ cte_TestData
Использовать функцию LEFT String:
DECLARE @String VARCHAR(100) = 'SCC0204.XXXXX' ВЫБЕРИТЕ ВЛЕВО(@String,CHARINDEX('.', @String) - 1)
 XXXXX'
ВЫБЕРИТЕ ВЛЕВО(@String,CHARINDEX('.', @String) - 1)
XXXXX'
ВЫБЕРИТЕ ВЛЕВО(@String,CHARINDEX('.', @String) - 1)
Думаю, лучше всего здесь создать функцию, которая анализирует строку и использует регулярное выражение. Я надеюсь, что этот старый пост поможет:
Выполнить регулярное выражение (заменить) в SQL-запросе
Однако, если значение, которое вам нужно обрезать, постоянно равно «.X», вам следует использовать
выберите замену (строка, '.x', '')
1
Пожалуйста, проверьте приведенный ниже код. Я думаю, это поможет вам.
DECLARE @String VARCHAR(100) = 'SCC0204.X'
ЕСЛИ (ВЫБЕРИТЕ ПРАВО(@String,2)) = '.X'
ВЫБЕРИТЕ ВЛЕВО(@String,CHARINDEX('.', @String) - 1)
ЕЩЕ
ВЫБЕРИТЕ @String
Обновление: Я только что пропустил один из комментариев, где OP разъясняет требование. Ниже я собрал, как вы справитесь с требованием удалить все после первой точки в строках, заканчивающихся на X. Я оставлю это здесь для справки.
;С cte_TestData(код) КАК
(
SELECT 'SCC0204.X' UNION ALL -- заканчивается на '.X'
SELECT 'FRK.000.X' UNION ALL -- заканчивается на '.X', содержит несколько точек
SELECT 'RF0023.AX' UNION ALL -- заканчивается на '.AX'
SELECT 'ADF1010.A' UNION ALL -- заканчивается на '.A'
ВЫБЕРИТЕ 'HGT9010.V' UNION ALL -- оканчивается на '.V'
SELECT 'SCC0204.XF' UNION ALL -- заканчивается на '.XF'
SELECT 'FRK0005' UNION ALL -- полностью чистый
SELECT 'ABCX' -- заканчивается на 'X', а не на точки
)
ВЫБИРАТЬ
исходная_строка = код,
строка новостей =
ПОДСТРОКА
(
код, 1,
СЛУЧАЙ
КОГДА код LIKE '%X'
THEN ISNULL(NULLIF(CHARINDEX('.',code)-1, -1), LEN(code))
ИНАЧЕ LEN(код)
КОНЕЦ
)
ИЗ cte_TestData;
FYI — SQL Server 2012+ вы можете упростить этот код следующим образом:
ВЫБОР
исходная_строка = код,
строка новостей =
ПОДСТРОКА(код, 1,IIF(код LIKE '%X', ISNULL(NULLIF(CHARINDEX('.',код)-1,-1), LEN(код)), LEN(код)))
ИЗ cte_TestData;
0
С помощью SUBSTRING вы можете выполнить свои требования с помощью приведенного ниже кода.
ВЫБРАТЬ ПОДСТРОКУ (имя_столбца, 0, CHARINDEX ('.', имя_столбца)) КАК столбец
ОТ вашей_таблицы
Если вы хотите удалить фиксированный .X из строки, вы также можете использовать функцию REPLACE.
ВЫБЕРИТЕ ЗАМЕНУ (имя_столбца, '.X', '') КАК столбец
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
sql server - SQL как обрезать строку
спросил
Изменено
9лет, 10 месяцев назад
Просмотрено
34к раз
У меня есть столбец строк с городом, штатом и номером в каждом.
СПОКАН, Вашингтон 232/107 ЛАС-ВЕГАС, Невада 232/117 ПОРТЛЕНД, ИЛИ 232/128
Есть еще много чего, но мне интересно, как я могу отрезать числа в этом столбце и просто показать город и штат или, что еще лучше, отрезать числа и сделать город и штат отдельным столбцом.
Столбец имеет одинаковый формат для всех записей.
Спасибо!
- sql
- sql-сервер
- tsql
- строка
6
Не делая за вас всю работу...
Город: Подстрока столбца с позиции 0, до первого вхождения запятой - 1.
Состояние: Подстрока столбца с 2 позиции после первой появление запятой, в следующую позицию, которая является пробелом... обрезано.
см.: SUBSTRING() , CHARINDEX() , PATINDEX()
1
Я уже разобрался и написал SQL... затем я увидел ответ Фоско, но поскольку он у меня есть, я все равно могу опубликовать его:
SELECT
LEFT(yourcolumn, CHARINDEX(',', yourcolumn) - 1) КАК Город,
ВПРАВО(ВЛЕВО(ваш столбец, CHARINDEX(',', ваш столбец) + 3), 2) КАК Состояние
ОТ вашей таблицы
Отличие этого алгоритма от алгоритма Fosco состоит в том, что он предполагает, что состояние состоит ровно из двух букв. Если это не всегда так, вам следует использовать другой ответ.
Если это не всегда так, вам следует использовать другой ответ.
1
Чтобы удалить числа в конце, используйте метод подстроки, что-то вроде этого.
@str = ПОДСТРОКА(@str, LEN(@str)-7, 7)
Чтобы разделить город и штат, вам понадобится какая-то функция разделения, но я не могу вспомнить синтаксис навскидку, извините.
РЕДАКТИРОВАТЬ Упс. Просто увидел, что вопрос был в том, как, а не в том, стоит ли. Это то, что я получаю, я думаю.
Другие ответы здесь относятся к подстроке(), поэтому я оставлю эту часть вашего вопроса в покое.
Что касается разделения их в другой столбец: если xxx/yyy не имеет прямого отношения к городу и штату, то я определенно переместил бы их в другой столбец. Действительно, здесь у меня было бы как минимум три столбца: City, State, [WhateverYouCallThatCode]
Продолжение EDIT
Если они всегда будут справа от вашего столбца, как насчет Right(7, [Column]) ?
Я думаю, что это разрушит ваше поле всеми способами, предложенными до сих пор.