Взаимодействие сервера и клиента: Клиент-сервер — Изучение веб-разработки | MDN
Что такое взаимодействие Клиент-Сервер? | Info-Comp.ru
Сегодня речь пойдет о так называемом взаимодействии Клиент-Сервер, так как практически все программное обеспечение построено на данном принципе. А как Вы помните, что у нас сайт для начинающих программистов и понимание данного взаимодействия обязательно для новичка в программирование. Поэтому в данном материале мы рассмотрим, что это такое и для чего это нужно.
Как я уже сказал, если Вы хотите стать программистом то Вы должны понимать принцип данного взаимодействия, потому что хотите Вы или нет, Вам придется столкнуться с этим, так как это встречается практически везде, например все сайты в Интернете построены на этом, все программы которые используют базу данных, сюда также можно и отнести и автоматическое обновление программ, и многое другое.
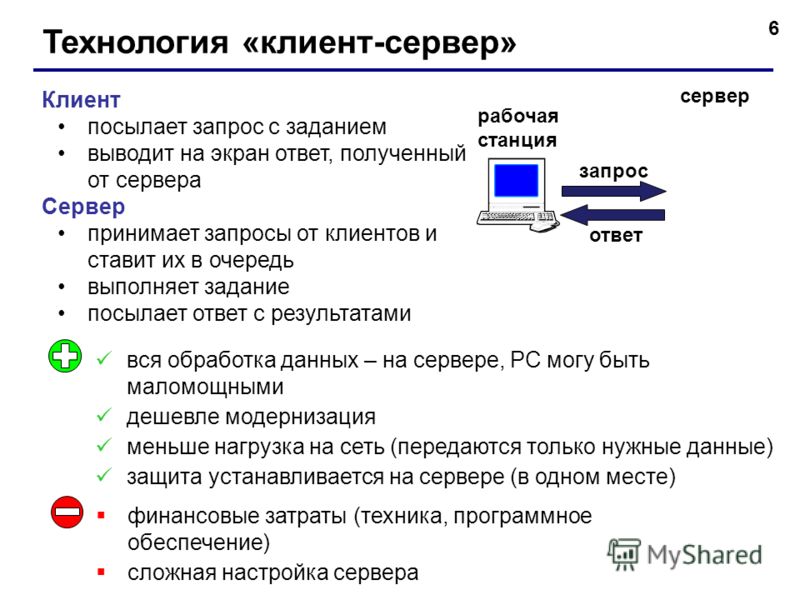
Теперь поговорим подробней. Что такое взаимодействие Клиент-сервер? Это взаимодействие двух программных продуктов между собой, один из которых выступает в качестве сервера, а другой соответственно в качестве клиента. Клиент посылает запрос, а сервер отвечает ему. А что такое клиент и что такое сервер? Спросите Вы. Клиент это программная оболочка, с которой взаимодействует пользователь. А сервер это та часть программного обеспечения, которая выполняет все основные функции (хранит данные, выполняет расчеты). Другими словами, пользователь видит программу, которая, допустим, работает с какими-то данными, которые хранятся в базе данных, тем самым он видит всего лишь интерфейс этой программы, а все самое основное выполняет сервер, и процесс когда пользователь оперирует данными через интерфейс программы, при котором клиентская часть взаимодействует с серверной, и называется Клиент-Сервер. В качестве клиента не обязательно должен выступать интерфейс, который видит пользователь, в некоторых случаях в качестве клиента может выступать и просто программа или скрипт, например, данные на сайте хранятся в базе данных, соответственно скрипты, которые будут обращаться к базе данных и будут являться клиентом в данном случае, хотя и сами эти скрипты являются сервером для клиентской часть сайта (интерфейса).
Клиент посылает запрос, а сервер отвечает ему. А что такое клиент и что такое сервер? Спросите Вы. Клиент это программная оболочка, с которой взаимодействует пользователь. А сервер это та часть программного обеспечения, которая выполняет все основные функции (хранит данные, выполняет расчеты). Другими словами, пользователь видит программу, которая, допустим, работает с какими-то данными, которые хранятся в базе данных, тем самым он видит всего лишь интерфейс этой программы, а все самое основное выполняет сервер, и процесс когда пользователь оперирует данными через интерфейс программы, при котором клиентская часть взаимодействует с серверной, и называется Клиент-Сервер. В качестве клиента не обязательно должен выступать интерфейс, который видит пользователь, в некоторых случаях в качестве клиента может выступать и просто программа или скрипт, например, данные на сайте хранятся в базе данных, соответственно скрипты, которые будут обращаться к базе данных и будут являться клиентом в данном случае, хотя и сами эти скрипты являются сервером для клиентской часть сайта (интерфейса).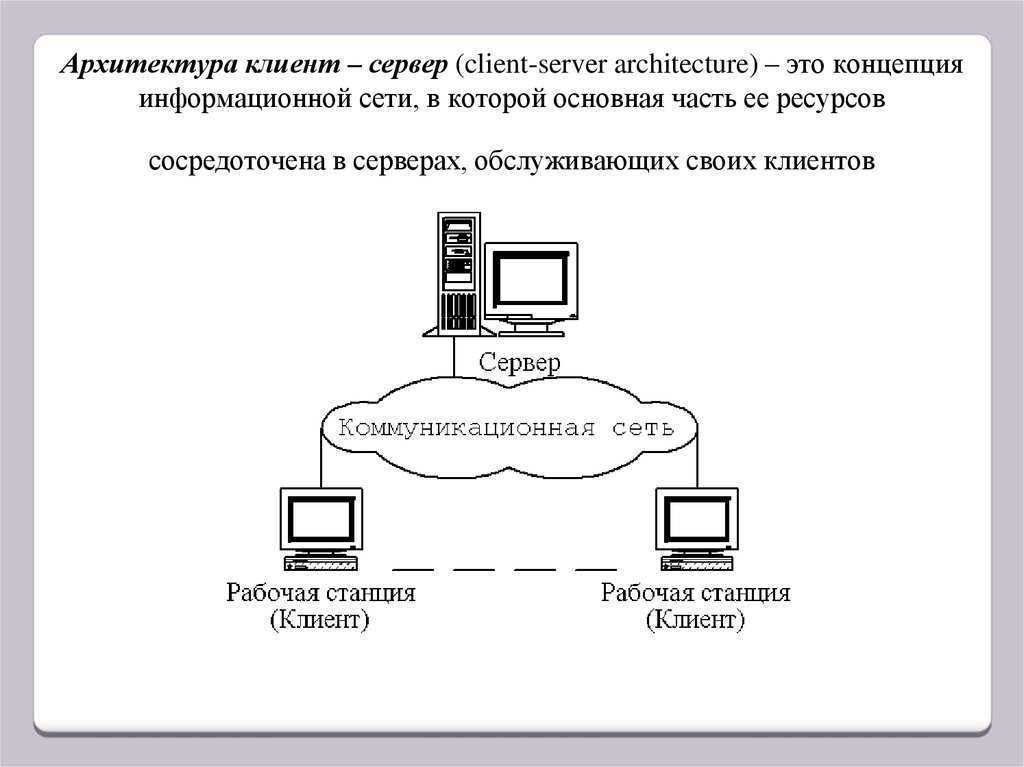
Это лучше объяснить на примере.
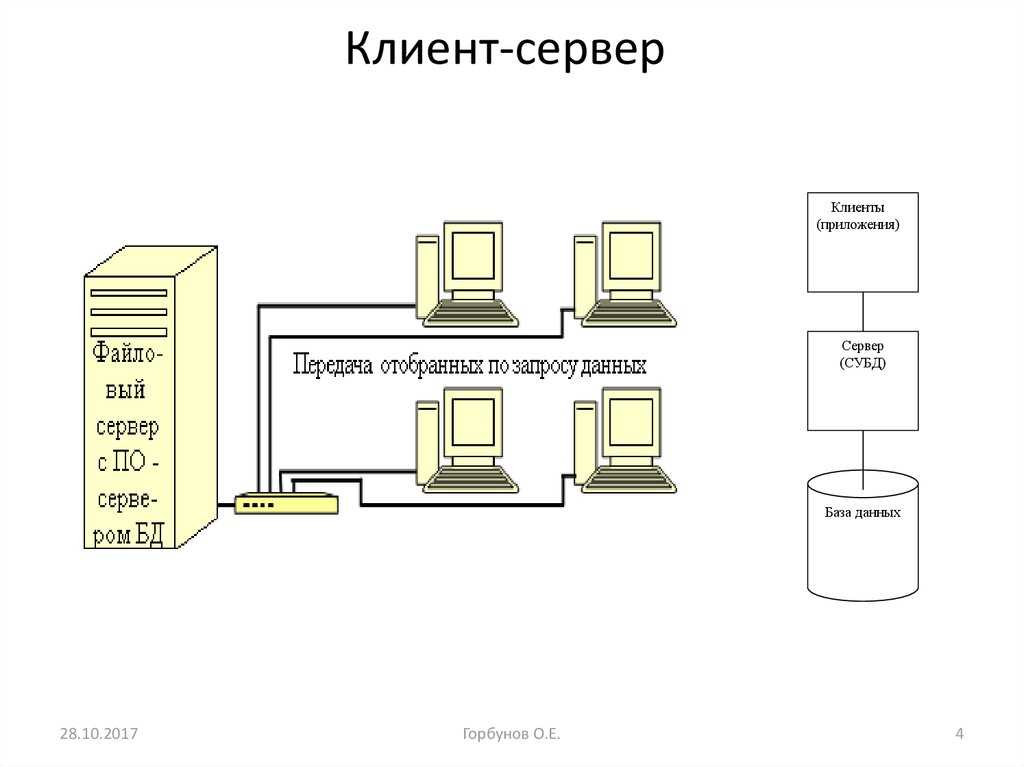
Допустим, Вы написали программу, которая умеет работать с некими данными и установили ее пользователю, все замечательно работает, пока другой пользователь не скажет, а я хочу такую же программу, но чтобы данные у нас были одни, и при редактировании одним пользователем другой мог увидеть это изменение. И для этого Вам необходимо сделать какую-то базу данных доступ, к которой можно получить через интерфейс Вашей программы, причем данная база должна располагаться на отдельном сервере, для того чтобы все пользователи могли получить к ней доступ, конечно, которым Вы разрешите.
И тем самым всем пользователям, которым нужна эта программа, Вы устанавливаете только клиентскую часть и настраиваете взаимодействие с сервером. В данном случае подразумевается, что Вы на сервере установите СУБД (Система управления базами данных).
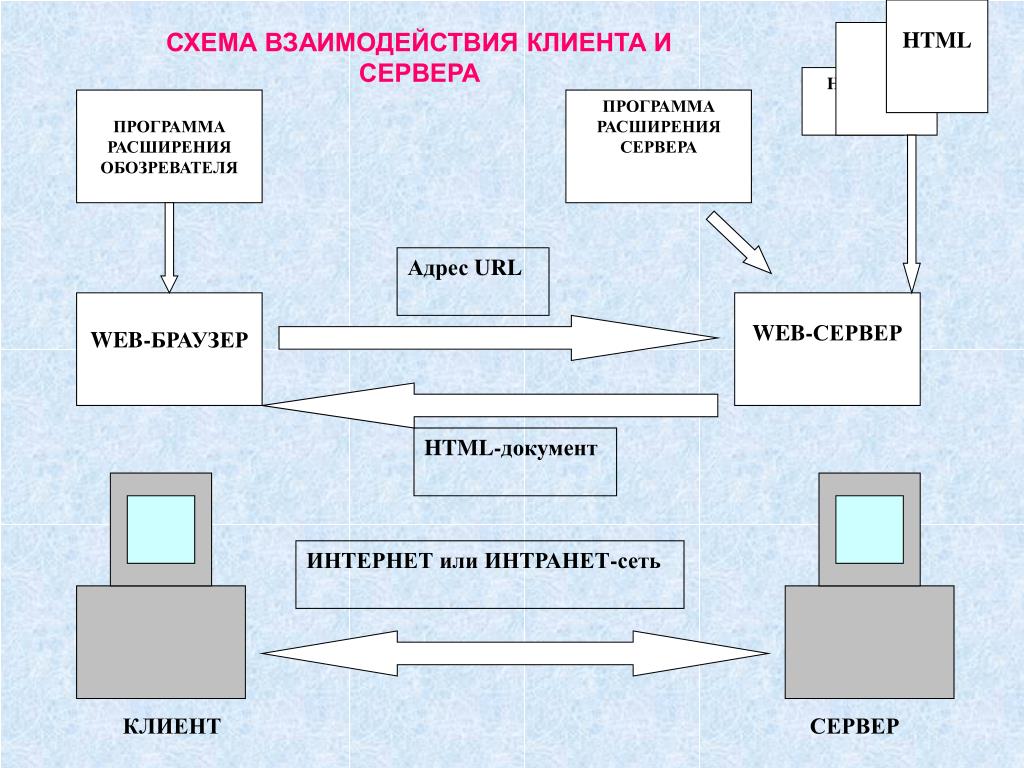
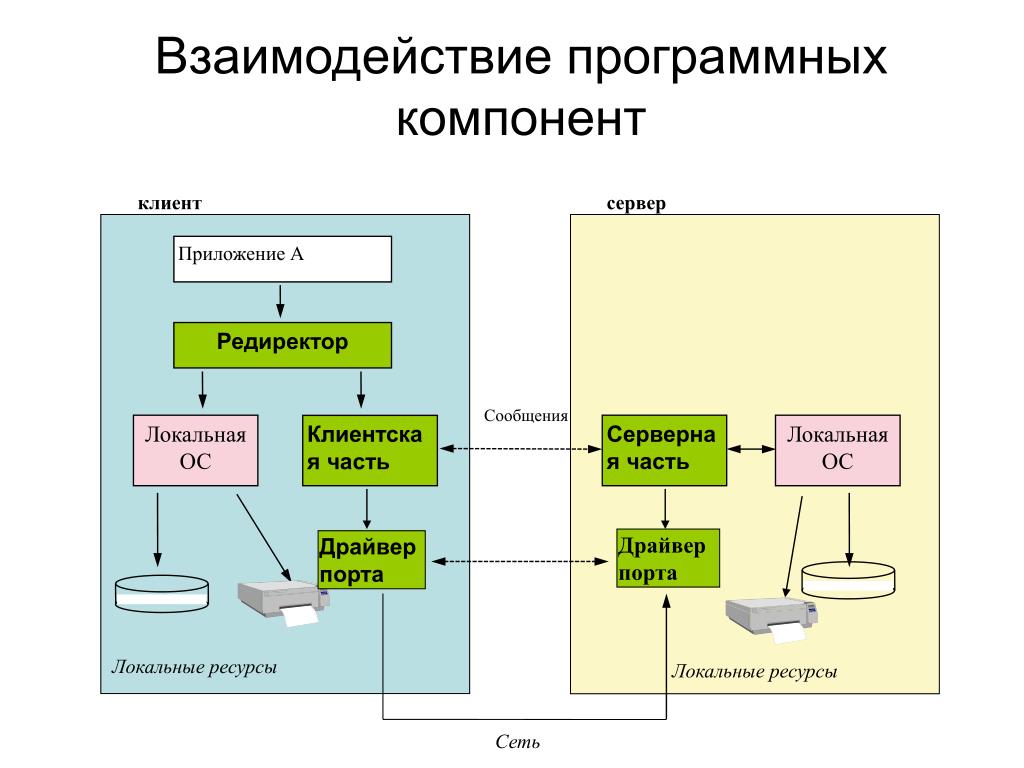
Где под клиентом понимается клиентская часть приложения, которая взаимодействует с серверной частью приложения по средствам сети.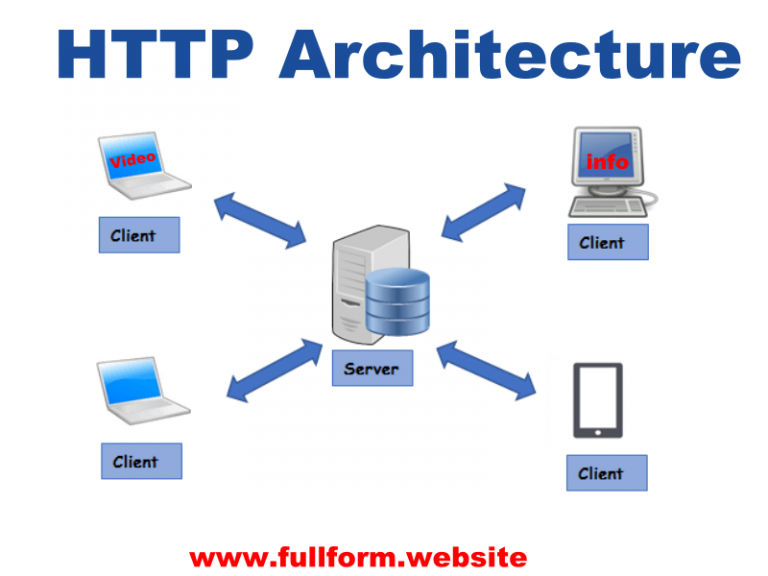
Другой пример.
Все сайты в Интернете располагаются где-то на серверах (хостинге), а Вы соответственно хотите получить доступ к ним и для этого используете браузер и в данном случае браузер и есть клиент, а файлы на хостинге сервер. Если разбирать отдельно взятый сайт, то здесь также присутствует данное взаимодействие, к примеру, в браузере Вы видите всего лишь интерфейс приложения и при любых Ваших действиях на этом сайте данный интерфейс будет отправлять запрос серверу который выполнит все что Вы запросили и пришлет ответ, а клиент в свою очередь отобразит этот ответ, для того чтобы пользователь смог увидеть его.
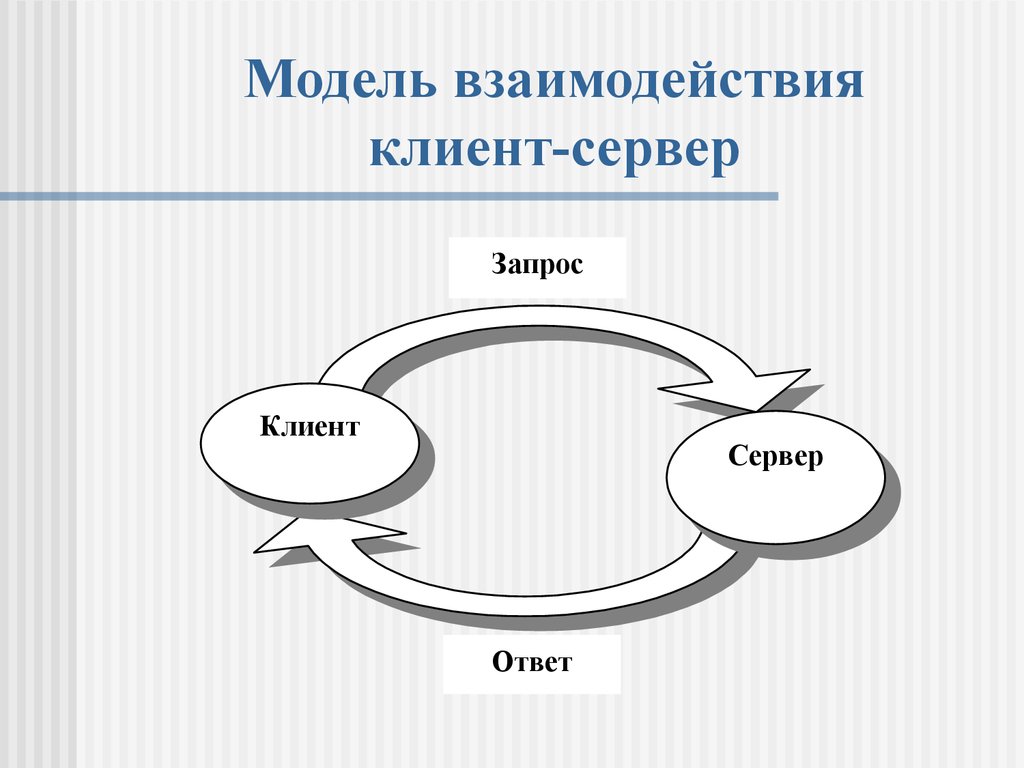
Другими словами принцип клиент-сервер основан на том, что клиент отправляет запрос серверу, а сервер отвечает ему. И данные запрос-ответы могут выглядеть по-разному, могут использоваться разные протоколы, такие как tcp/ip, http, rdp и много других.
Теперь надеюсь, стало понятно, что такое Клиент-сервер, теперь давайте немного поговорим о том, как лучше реализовывать данное взаимодействие.
Как уже говорилось выше, если Вы захотели хранить данные в базе данных то лучше всего использовать СУБД, такие как MSSql, MySQL, Oracle, PostgreSQL так как данные СУБД предоставляют огромные возможности для серверной разработки. Так как, когда Вы будете разрабатывать программное обеспечение по такому принципу, Вам лучше всего четко разграничить клиент и сервер, т.е. клиент выполняет только роль интерфейса, из которого можно будет посылать запросы серверу на запуск процедур или функций, а соответственно сервер будет выполнять эти процедуры и функции и посылать результат их выполнения клиенту, предварительно, конечно же, Вы должны будете написать эти самые процедуры и функции, что и позволяют делать данные СУБД. Этим Вы упростите разработку и увеличите производительность Вашего программного обеспечения. Поэтому запомните клиент, во всех случаях, при взаимодействии Клиент-Сервер должен выполнять только лишь функцию интерфейса, и не нужно на него возлагать какие-то там другие задачи (обработка данных и другое), все, что можно перенести на сервер переносите, а пользователю предоставьте всего лишь интерфейс.
В связи с этим пришло время поговорить о преимуществах данной технологии:
- Низкие требования к компьютерам клиента, так как вся нагрузка должна возлагаться на сервер и серверную часть приложения, в некоторых случаях можно значительно сэкономить затраты на приобретение вычислительной техники в организациях;
- Многопользовательский режим. Ресурсами сервера могут пользоваться неограниченное число пользователей, при том что данные располагаются в одном месте;
- Целостность данных. Вывести из строя компьютер клиента гораздо проще, и чаще встречается, чем компьютер, который выполняет роль сервера. Как Вы знаете, проблемы с компьютерами у пользователей встречаются достаточно часто, так как они сами их себе и создают.
- Внесение изменений. Проще внести изменения один раз в серверной части, чем вносить их на каждом клиенте.
Есть также пару недостатков:
- Для быстродействия требуется приобрести достаточно мощный сервер, но как было уже сказано выше, это может и окупится, за счет компьютеров пользователей;
- Выход из строя серверной части прекратит работу всех клиентов, в связи с этим возникает необходимость постоянного мониторинга серверной части.

Перед тем как заняться разработкой приложения Вы должны знать, на чем Вы это будете реализовывать, так как существуют разные технологии и языки, например, при взаимодействии с СУБД Вам придется изучить SQL, хотя бы основы SQL, но лучше, если Вы будете знать, как написать функцию или процедуру, так как без этого Вам не обойтись, ну если конечно не разделить обязанности между программистами, например, один специалист разрабатывает серверную часть, а другой клиентскую, так, кстати, все и делают, потому что сами понимаете, что все знать просто невозможно.
Или на примере сайта в Интернете, существуют как серверные языки программирования, например PHP так и клиентские, например JavaScript, поэтому, если Вы решили сами создать нормальный сайт в Интернете, то учтите, что Вам придется с этим столкнуться и проще говоря, Вы должны будете стать Web-мастером который должен знать ой как много:).
Подведем итог.
Как Вы уже поняли, что взаимодействие Клиент-Сервер используется практически везде, и можно сказать, сеть построена, для того чтобы пользователь, по средствам программного обеспечения, мог взаимодействовать с другими пользователями или удаленными ресурсами, так как все что Вы запрашиваете или отправляете по сети основано на взаимодействие запрос-ответ. Поэтому начинающий программист должен понимать данное взаимодействие и в последствие реализовывать его.
Поэтому начинающий программист должен понимать данное взаимодействие и в последствие реализовывать его.
О модели взаимодействия клиент-сервер простыми словами. Архитектура «клиент-сервер» с примерами
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем рубрику Сервера и протоколы. В этой записи мы поговорим о том, как работают приложения и сайты в сети Интернет, да и вообще в любой компьютерной сети. В основе работы приложения лежит так называемая модель взаимодействия клиент-сервер, которая позволяет разделять функционал и вычислительную нагрузку между клиентскими приложениями (заказчиками услуг) и серверными приложениями (поставщиками услуг).
Модель взаимодействия клиент-сервер. Архитектура «клиент-сервер».
Итак, небольшая аннотация к записи: сначала мы разберемся с концепцией взаимодействия клиент сервер. Затем поговорим о том зачем вообще веб-мастеру нужно понимать модель клиент-сервер. Далее мы посмотрим на архитектуру приложений, которые работают по принципу клиент-сервер и в завершении рассмотрим преимущества и недостатки данной модели.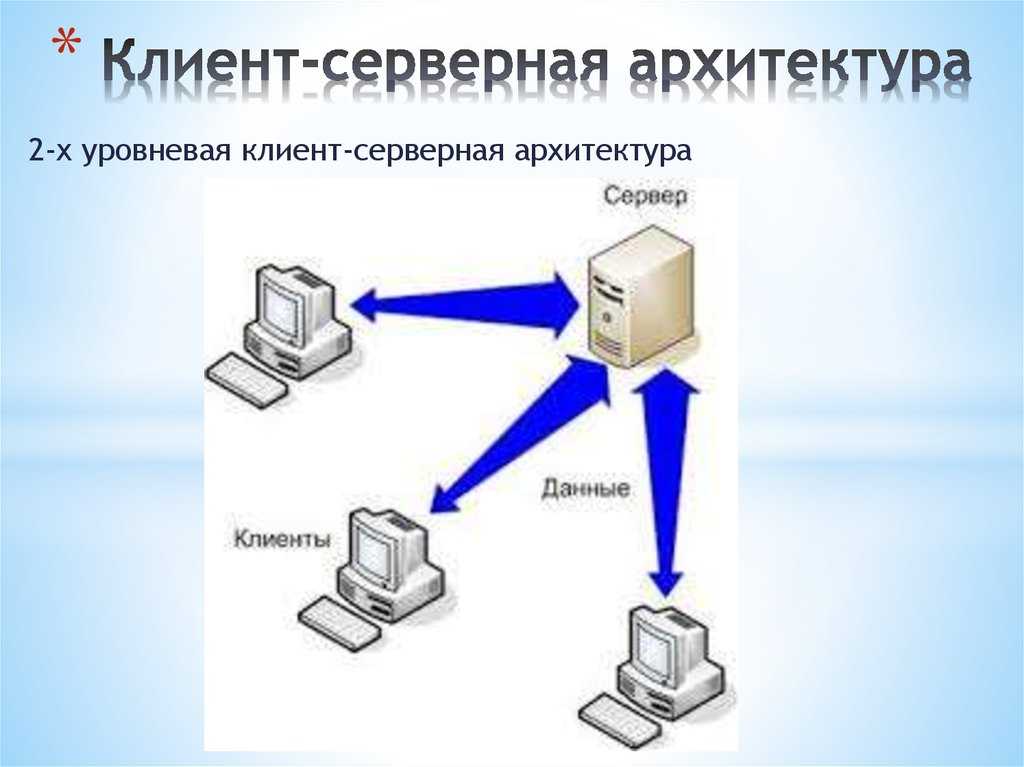
Концепция взаимодействия клиент-сервер
Содержание статьи:
- Концепция взаимодействия клиент-сервер
- Почему веб-мастеру нужно понимать модель взаимодействия клиент-сервер
- Архитектура «клиент-сервер»
- Преимущества и недостатки архитектуры клиент-сервер
Миллионы людей каждый день выходят в сеть Интернет, чтобы почитать новости, пообщаться с друзьями, получить полезную информацию, совершить покупку или оплатить счет. Но большая часть рядовых пользователей даже не догадывается о том, как и с помощью чего они всё это делают, да на самом деле большинству людей это и не нужно, главное, чтобы они получали услугу вовремя и качественно.
Здесь мы разберемся с концепцией, которая позволяет нам выполнять все эти действия в сети Интернет. Данная концепция получила название «клиент-сервер». Как понятно из названия, в данной концепции участвуют две стороны: клиент и сервер. Здесь всё как в жизни: клиент – это заказчик той или иной услуги, а сервер – поставщик услуг. Клиент и сервер физически представляют собой программы, например, типичным клиентом является браузер. В качестве сервера можно привести следующие примеры: все HTTP сервера (в частности Apache), MySQL сервер, локальный веб-сервер AMPPS или готовая сборка Denwer (последних два примера – это не проста сервера, а целый набор серверов).
Клиент и сервер физически представляют собой программы, например, типичным клиентом является браузер. В качестве сервера можно привести следующие примеры: все HTTP сервера (в частности Apache), MySQL сервер, локальный веб-сервер AMPPS или готовая сборка Denwer (последних два примера – это не проста сервера, а целый набор серверов).
Клиент и сервер взаимодействую друг с другом в сети Интернет или в любой другой компьютерной сети при помощи различных сетевых протоколов, например, IP протокол, HTTP протокол, FTP и другие. Протоколов на самом деле очень много и каждый протокол позволяет оказывать ту или иную услугу. Например, при помощи HTTP протокола браузер отправляет специальное HTTP сообщение, в котором указано какую информацию и в каком виде он хочет получить от сервера, сервер, получив такое сообщение, отсылает браузеру в ответ похожее по структуре сообщение (или несколько сообщений), в котором содержится нужная информация, обычно это HTML документ.
Сообщения, которые посылают клиенты получили названия HTTP запросы. Запросы имеют специальные методы, которые говорят серверу о том, как обрабатывать сообщение. А сообщения, которые посылает сервер получили название HTTP ответы, они содержат помимо полезной информации еще и специальные коды состояния, которые позволяют браузеру узнать то, как сервер понял его запрос.
Запросы имеют специальные методы, которые говорят серверу о том, как обрабатывать сообщение. А сообщения, которые посылает сервер получили название HTTP ответы, они содержат помимо полезной информации еще и специальные коды состояния, которые позволяют браузеру узнать то, как сервер понял его запрос.
Сейчас мы схематично описали, как взаимодействуют клиент и сервер на седьмом уровне модели OSI, но, на самом деле это взаимодействие происходит на всех семи уровнях. Когда клиент отправляет запрос, сообщение упаковывается, можно представить, что сообщение заворачивается в семь оберток (хотя их может быть намного больше или же меньше), а когда сообщение получает сервер, он начинает эти обертки разворачивать.
Также стоит заметить, что в основе взаимодействия клиент-сервер лежит принцип того, что такое взаимодействие начинает клиент, сервер лишь отвечает клиенту и сообщает о том может ли он предоставить услугу клиенту и если может, то на каких условиях. Клиентское программное обеспечение и серверное программное обеспечение обычно установлено на разных машинах, но также они могут работать и на одном компьютере.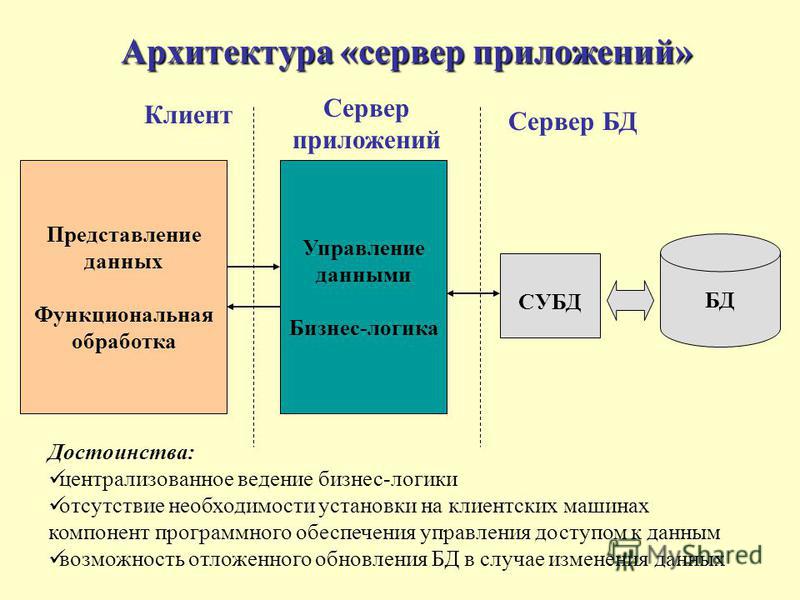
Данная концепция взаимодействия была разработана в первую очередь для того, чтобы разделить нагрузку между участниками процесса обмена информацией, а также для того, чтобы разделить программный код поставщика и заказчика. Ниже вы можете увидеть упрощенную схему взаимодействия клиент-сервер.
Простая схема взаимодействия клиент-сервер
Мы видим, что к одному серверу может обращаться сразу несколько клиентов (действительно, на одном сайте может находиться несколько посетителей). Также стоит заметить, что количество клиентов, которые могут одновременно взаимодействовать с сервером зависит от мощности сервера и от того, что хочет получить клиент от сервера.
Многие сетевые протоколы построены на архитектуре клиент-сервер, поэтому в их основе обычно лежат одинаковые или схожие принципы взаимодействия, а разницу мы видим лишь в деталях, которые обусловлены особенностями и спецификой области, для которой разрабатывался тот или иной сетевой протокол.
Почему веб-мастеру нужно понимать модель взаимодействия клиент-сервер
Давайте теперь ответим на вопрос: «зачем веб-мастеру или веб-разработчику понимать концепцию взаимодействия клиент-сервер?». Ответ, естественно, очевиден. Чтобы что-то делать своими руками нужно понимать, как это работает. Чтобы сделать сайт и, чтобы он правильно работал в сети Интернет или хотя бы просто работал, нам нужно понимать, как работает сеть Интернет.
Ответ, естественно, очевиден. Чтобы что-то делать своими руками нужно понимать, как это работает. Чтобы сделать сайт и, чтобы он правильно работал в сети Интернет или хотя бы просто работал, нам нужно понимать, как работает сеть Интернет.
Мы уже упоминали, что большая часть сетевых протоколов имеют архитектуру клиент-сервер. Например, веб-мастеру или веб-разработчику будут интересны протоколы седьмого и шестого уровня эталонной модели. Сетевым администраторам важно понимать, как происходит взаимодействие на уровнях с пятого по второй. Для инженеров связи наибольший интерес представляют протоколы с четвертого по первый уровень модели OSI.
Поэтому если вы действительно хотите быть профессионалом в сфере web, то сперва вам необходимо понимать, как происходит взаимодействии в сети (именно на седьмом уровне), а уже потом начинать изучать инструменты, которые позволят создавать сайты.
Архитектура «клиент-сервер»
Архитектура клиент-сервер определяет лишь общие принципы взаимодействия между компьютерами, детали взаимодействия определяют различные протоколы.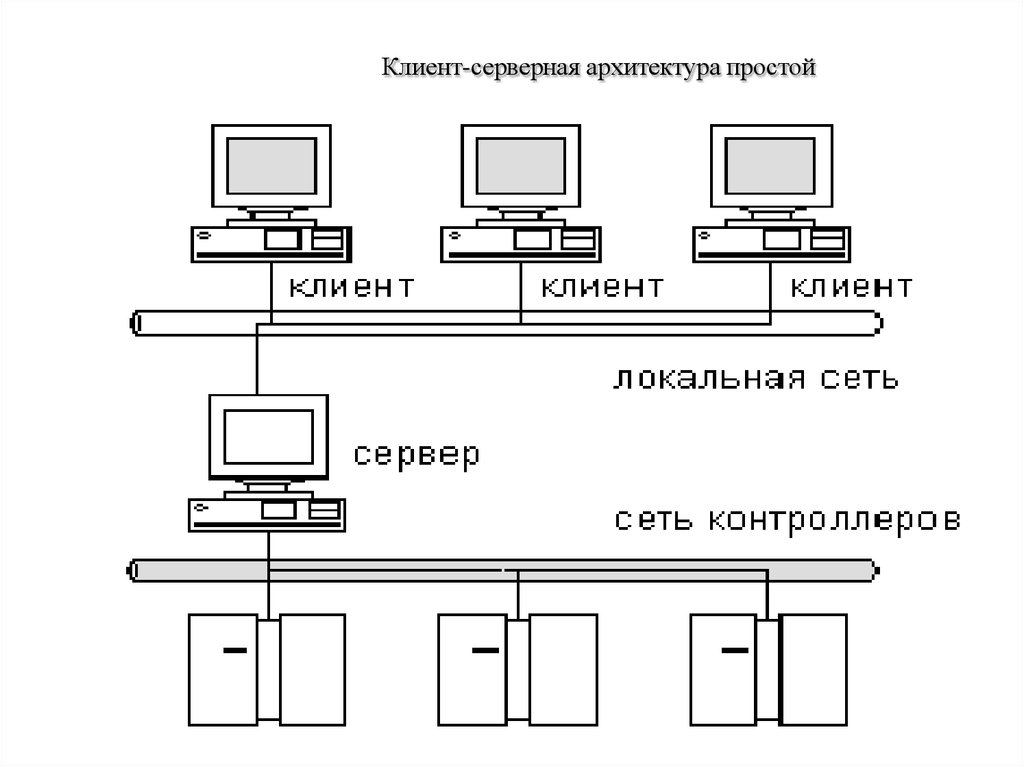 Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
Данная концепция нам говорит, что нужно разделять машины в сети на клиентские, которым всегда что-то надо и на серверные, которые дают то, что надо. При этом взаимодействие всегда начинает клиент, а правила, по которым происходит взаимодействие описывает протокол.
Существует два вида архитектуры взаимодействия клиент-сервер: первый получил название двухзвенная архитектура клиент-серверного взаимодействия, второй – многоуровневая архитектура клиент-сервер (иногда его называют трехуровневая архитектура или трехзвенная архитектура, но это частный случай).
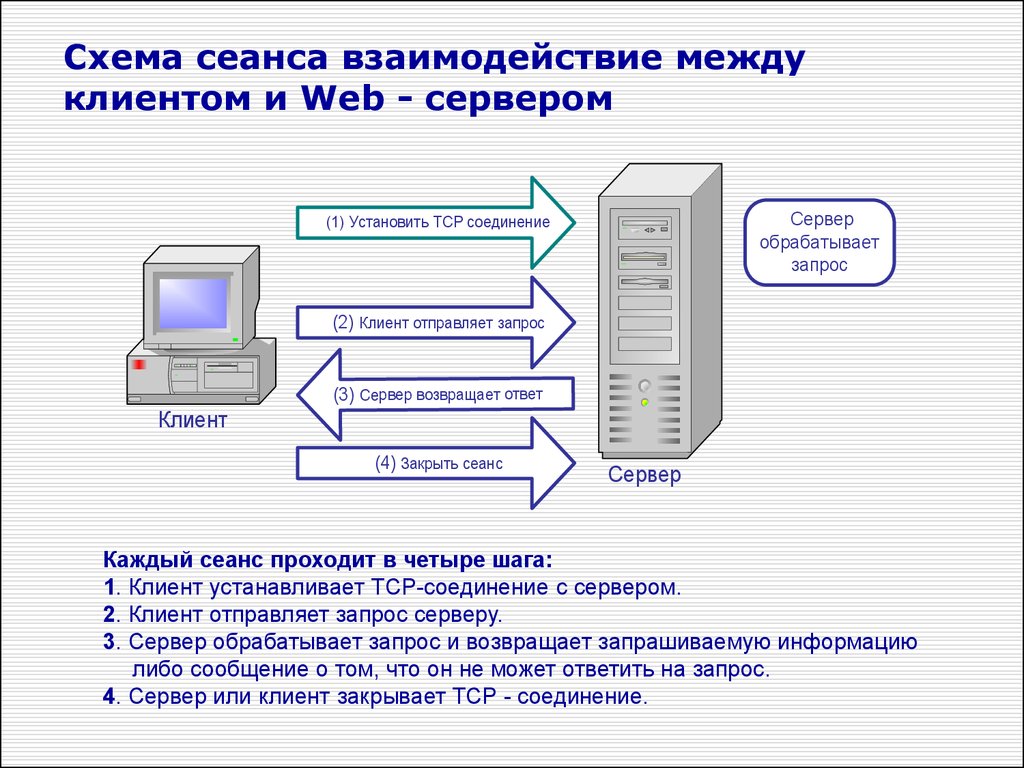
Принцип работы двухуровневой архитектуры взаимодействия клиент-сервер заключается в том, что обработка запроса происходит на одной машине без использования сторонних ресурсов. Двухзвенная архитектура предъявляет жесткие требования к производительности сервера, но в тоже время является очень надежной. Двухуровневую модель взаимодействия клиент-сервер вы можете увидеть на рисунке ниже.
Двухуровневая модель взаимодействия клиент-сервер
Здесь четко видно, что есть клиент (1-ый уровень), который позволяет человеку сделать запрос, и есть сервер, который обрабатывает запрос клиента.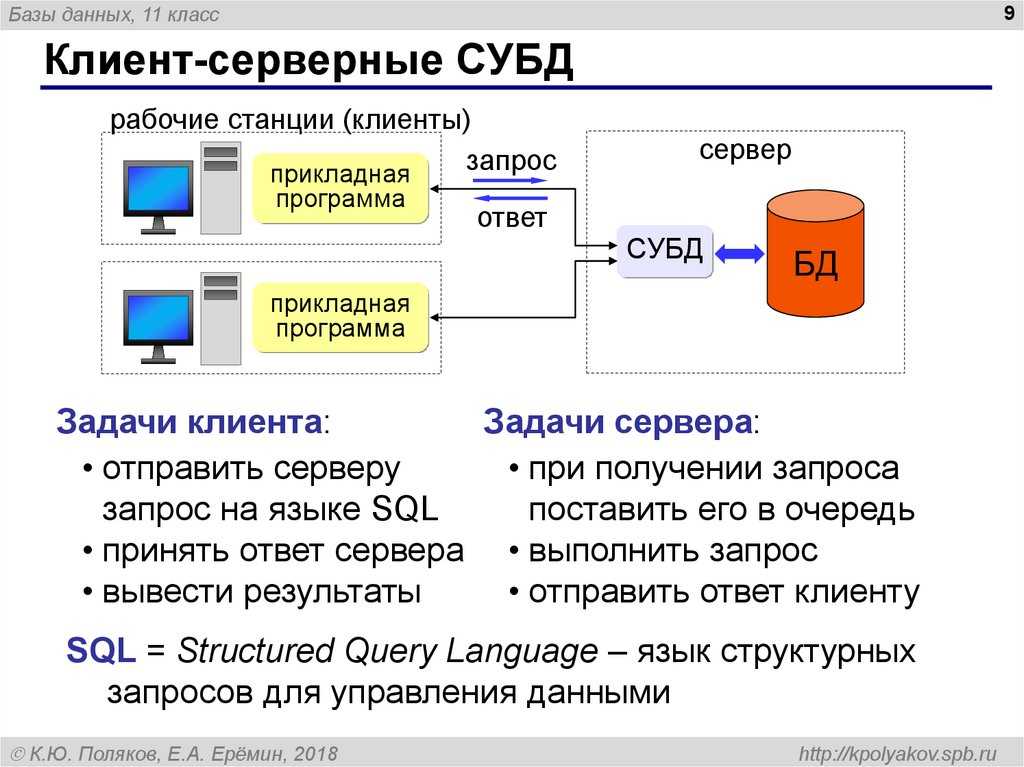
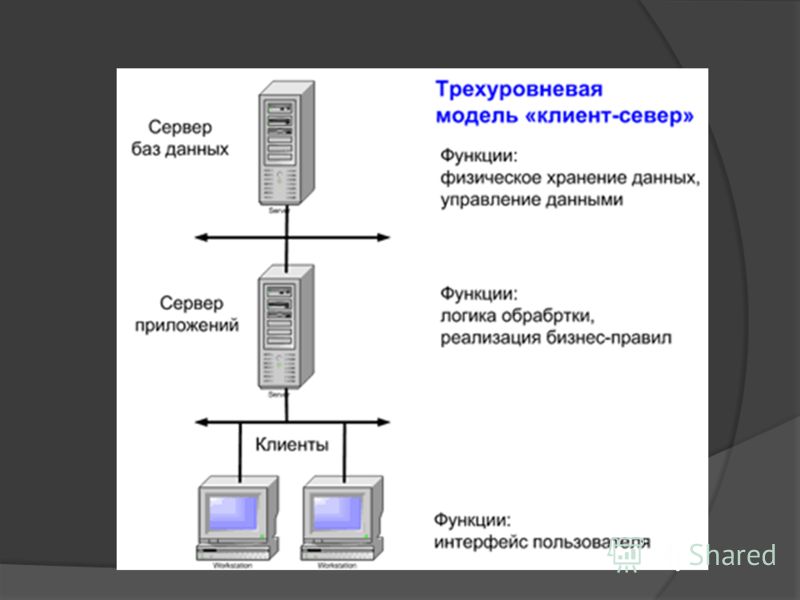
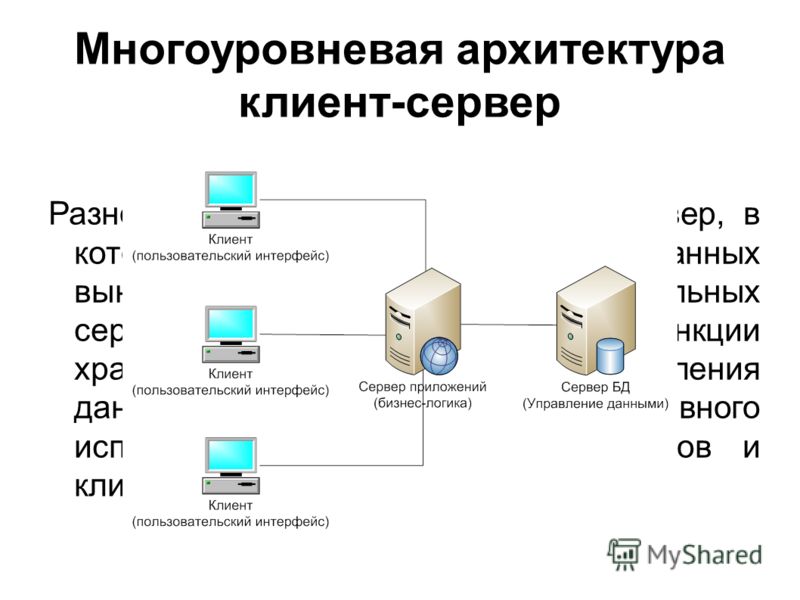
Если говорить про многоуровневую архитектуру взаимодействия клиент-сервер, то в качестве примера можно привести любую современную СУБД (за исключением, наверное, библиотеки SQLite, которая в принципе не использует концепцию клиент-сервер). Суть многоуровневой архитектуры заключается в том, что запрос клиента обрабатывается сразу несколькими серверами. Такой подход позволяет значительно снизить нагрузку на сервер из-за того, что происходит распределение операций, но в то же самое время данный подход не такой надежный, как двухзвенная архитектура. На рисунке ниже вы можете увидеть пример многоуровневой архитектуры клиент-сервер.
Многоуровневая архитектура взаимодействия клиент-сервер
Типичный пример трехуровневой модели клиент-сервер. Если говорить в контексте систем управления базами данных, то первый уровень – это клиент, который позволяет нам писать различные SQL запросы к базе данных. Второй уровень – это движок СУБД, который интерпретирует запросы и реализует взаимодействие между клиентом и файловой системой, а третий уровень – это хранилище данных.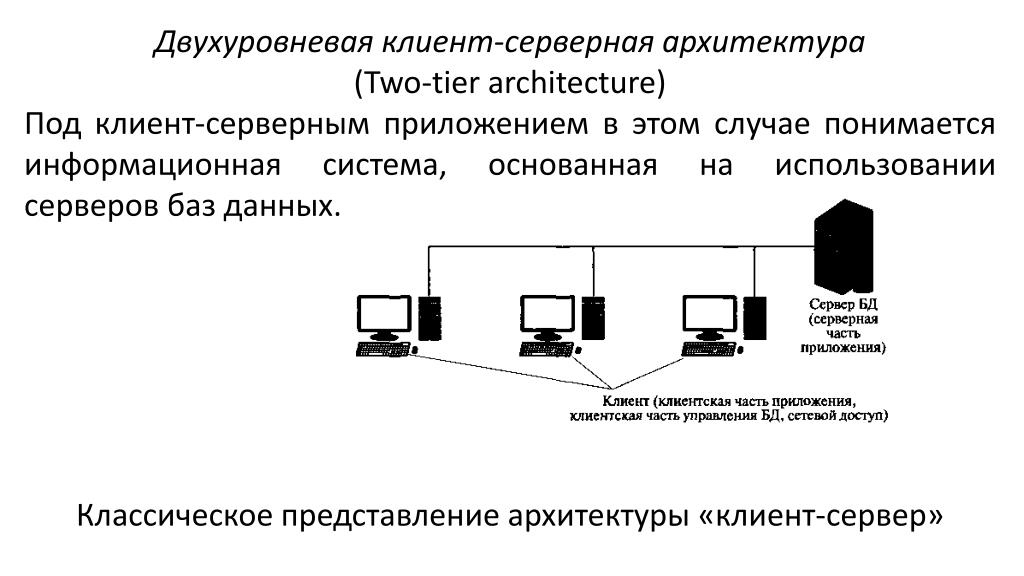
Если мы посмотрим на данную архитектуру с позиции сайта. То первый уровень можно считать браузером, с помощью которого посетитель заходит на сайт, второй уровень – это связка Apache + PHP, а третий уровень – это база данных. Если уж говорить совсем просто, то PHP больше ничего и не делает, кроме как, гоняет строки и базы данных на экран и обратно в базу данных.
Преимущества и недостатки архитектуры клиент-сервер
Преимуществом модели взаимодействия клиент-сервер является то, что программный код клиентского приложения и серверного разделен. Если мы говорим про локальные компьютерные сети, то к преимуществам архитектуры клиент-сервер можно отнести пониженные требования к машинам клиентов, так как большая часть вычислительных операций будет производиться на сервере, а также архитектура клиент-сервер довольно гибкая и позволяет администратору сделать локальную сеть более защищенной.
К недостаткам модели взаимодействия клиент-сервер можно отнести то, что стоимость серверного оборудования значительно выше клиентского. Сервер должен обслуживать специально обученный и подготовленный человек. Если в локальной сети ложится сервер, то и клиенты не смогут работать (в качестве частного случая можно привести пример: мощности сервера не всегда хватает, чтобы удовлетворит запросы клиентов, если вы хоть раз работали с биллинговыми системами, то понимаете о чем я: время ожидания ответа от сервера может быть очень большим).
Сервер должен обслуживать специально обученный и подготовленный человек. Если в локальной сети ложится сервер, то и клиенты не смогут работать (в качестве частного случая можно привести пример: мощности сервера не всегда хватает, чтобы удовлетворит запросы клиентов, если вы хоть раз работали с биллинговыми системами, то понимаете о чем я: время ожидания ответа от сервера может быть очень большим).
В качестве заключения нам стоит явно акцентировать внимание на том, что архитектура клиент-сервер не делит машины на только клиент или только сервер, а скорее позволяет распределить нагрузку и разделить функционал между клиентской частью и серверной.
Руководство для начинающих по взаимодействию клиент-сервер | by Shubhang Dixit
Связь RESTful в приложениях iOS
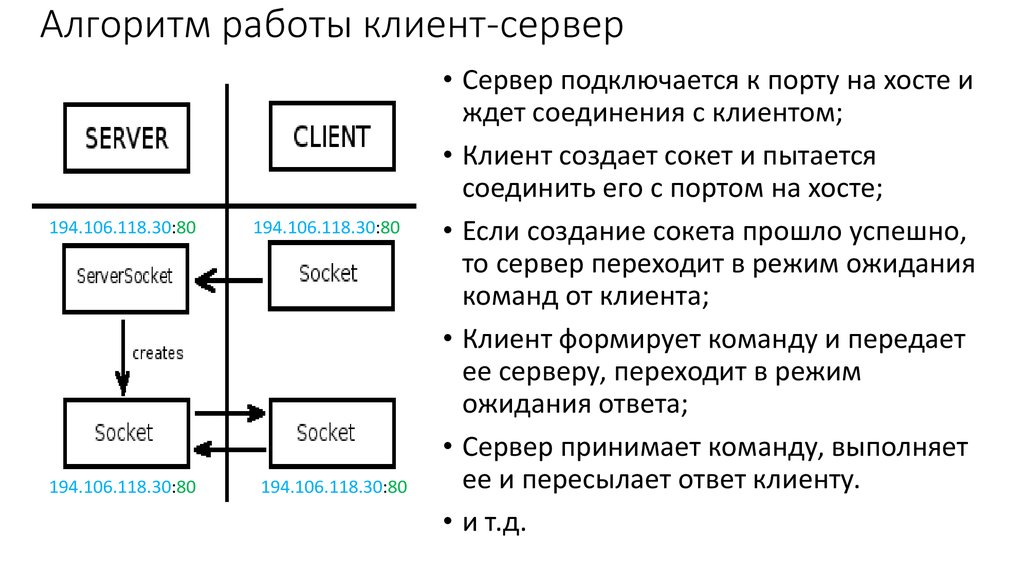
Что такое связь клиент-сервер?
В общении клиент-сервер у нас есть прежде всего два очевидных партнера: клиент и сервер .
Чтобы понять связь между этими двумя партнерами, нам нужно знать несколько простых тем:
- Запросы : запросы отправляются от клиента, чтобы запросить у сервера некоторые данные, такие как файлы, или сообщить серверу о вещах. такое случается, например, пользователь хочет войти в систему со своими учетными данными
- Ответ : ответ отправляется с сервера клиенту и является реакцией сервера на запрос клиента. Это может быть, например, результат аутентификации.
- Служба : Служба — это определенная задача, которую сервер предоставляет клиенту для использования, например загрузка изображения
 такое случается, например, пользователь хочет войти в систему со своими учетными данными
такое случается, например, пользователь хочет войти в систему со своими учетными даннымиКогда нам нужна связь клиент-сервер?
Связь клиент-сервер всегда используется, когда кто-то запрашивает что-то из Интернета. Некоторыми примерами могут быть такие приложения, как Facebook, Twitter, Instagram, Карты или даже простые игры, такие как Temple Run и так далее.
Давайте сначала разберемся, что такое REST и RESTful Communication. Современные веб-сервисы часто основаны на архитектуре REST, которая опирается на протокол HTTP и возвращает данные в формате JSON.
Что такое RESTful-коммуникация?
Связь RESTful означает реализацию веб-сервиса с использованием принципов HTTP и REST .
Принципы REST:
- Состояние и функциональность приложения разделены на ресурсы, и приложение будет реагировать в зависимости от ресурса, на котором выполняется операция
- Ресурсы адресуются с использованием стандартных URI, которые можно использовать в качестве гипермедиа-ссылок, таких как http://example.com/resources/, и затем для каждого ресурса в URI добавляется тип ресурса, например http://example. ком/ресурсы/ресурс.
- Ресурсы предоставляют информацию с использованием типов MIME (многоцелевых расширений почты Интернета), поддерживаемых HTTP (например, JSON, XML, Atom и т. д.)
- Используйте только стандартные методы HTTP, GET , PUT , POST и УДАЛИТЬ .
- Протокол без сохранения состояния, кэшируемый и многоуровневый
Без сохранения состояния , что означает, что серверу не нужно запоминать какую-либо информацию о состоянии клиента, в то время как клиенту необходимо включать всю информацию в свой запрос.
REST позволяет кэшировать , что означает, что ответы должны быть определены как кэшируемые, что устранит некоторые взаимодействия между клиентом и сервером, дополнительно улучшив масштабируемость и производительность.
Многоуровневый означает, что клиент не знает, является ли отвечающий сервер конечным сервером, который обслуживает ресурс, что является отличным принципом для обеспечения балансировки нагрузки и предоставления общих кэшей.
Примечание . Большинство реализаций REST API полагаются на согласование содержимого, управляемое агентом. Согласование контента, управляемое агентом , зависит от использования заголовков HTTP-запросов или шаблонов URI ресурсов.
Согласование контента с использованием заголовков HTTP
На стороне сервера к входящему запросу может быть присоединен объект. Чтобы определить его тип, сервер использует заголовок HTTP-запроса Content-Type. Некоторыми распространенными примерами типов контента являются «text/plain», «application/xml», «text/html», «application/json», «image/gif» и «image/jpeg».
Некоторыми распространенными примерами типов контента являются «text/plain», «application/xml», «text/html», «application/json», «image/gif» и «image/jpeg».
REST клиент-серверная архитектура . У клиента и сервера разные задачи. Сервер хранит и/или обрабатывает информацию и делает ее доступной для пользователя эффективным образом. Клиент берет эту информацию и отображает ее пользователю и/или использует ее для выполнения последующих запросов информации. Такое разделение задач позволяет как клиенту, так и серверу развиваться независимо, поскольку требуется только, чтобы интерфейс оставался прежним.
REST не имеет состояния . Это означает, что связь между клиентом и сервером всегда содержит всю информацию, необходимую для выполнения запроса. На сервере нет состояния сеанса, оно полностью хранится на стороне клиента. Если доступ к ресурсу требует аутентификации, то клиент должен аутентифицировать себя при каждом запросе.
REST можно кэшировать . Клиент, сервер и любые промежуточные компоненты могут кэшировать ресурсы для повышения производительности.
REST обеспечивает единый интерфейс между компонентами. Это упрощает архитектуру, поскольку все компоненты следуют одним и тем же правилам, чтобы общаться друг с другом. Это также облегчает понимание взаимодействия между различными компонентами системы.
REST — это многоуровневая система . Отдельные компоненты не могут видеть дальше непосредственного слоя, с которым они взаимодействуют. Это означает, что клиент, подключающийся к промежуточному компоненту, такому как прокси, не знает, что находится за его пределами. Это позволяет компонентам быть независимыми и, таким образом, легко заменяемыми или расширяемыми.
Ресурс — это абстрактное понятие. В системе REST любая информация, которая может быть названа, может быть ресурсом. Сюда входят документы, изображения, коллекция ресурсов и любая другая информация. Любая информация, которая может быть целью гипертекстовой ссылки, может быть ресурсом.
Любая информация, которая может быть целью гипертекстовой ссылки, может быть ресурсом.
Ресурс — это концептуальное сопоставление с набором сущностей.
Ресурс — это концептуальное сопоставление с набором сущностей. Набор сущностей со временем меняется; ресурс — нет. Например, один ресурс может сопоставляться с «пользователями, которые вошли в систему в прошлом месяце», а другой — со «всеми пользователями». В какой-то момент времени они могут сопоставляться с одним и тем же набором сущностей, потому что все пользователи вошли в систему в прошлом месяце. Но это все же разные ресурсы. Точно так же, если в последнее время никто не входил в систему, первый ресурс может сопоставляться с пустым набором. Этот ресурс существует независимо от информации, на которую он сопоставляется.
Ресурсы идентифицируются унифицированными идентификаторами ресурсов, также известными как URI.
URL-адрес состоит из разных частей, но в контексте REST API нас обычно интересуют только три:
- Хост, который обычно представляет собой имя (или иногда IP-адрес), которое идентифицирует другую конечную точку, в которой мы находимся. собирается достичь через сеть
- Путь, который идентифицирует ресурс, который мы ищем
- Необязательный запрос для выражения дополнительных параметров, которые могут нам понадобиться для нашего запроса
 собирается достичь через сеть
собирается достичь через сетьЭти URL-адреса, тем не менее, являются лишь частью того, что вам нужно понять, чтобы общаться с REST API.
REST — это тип архитектуры для веб-сервисов. Но нам, разработчикам iOS, все равно, как вся архитектура REST работает на стороне сервера.
REST работает по протоколу передачи гипертекста (HTTP), изначально созданному для передачи веб-страниц через Интернет.
В HTTP сеанс обычно представляет собой последовательность сетевых запросов и ответов, хотя при выполнении вызовов из приложений iOS мы обычно используем один сеанс для каждого вызова, который мы делаем.
HTTP-запрос обычно содержит:
- URL-адрес ресурса, который нам нужен
- метод HTTP для определения действия, которое мы хотим выполнить
- необязательные параметры в виде заголовков HTTP
- некоторые необязательные данные, которые мы хотим отправить на сервер
В вызове REST API мы используем только подмножество методов HTTP для действий, которые нам необходимо выполнить:
- GET для извлечения ресурса
- POST для создания ресурса
- УДАЛИТЬ , чтобы удалить ресурс
Операции CRUD
В архитектуре RESTful операции CRUD соответствуют основным методам HTTP.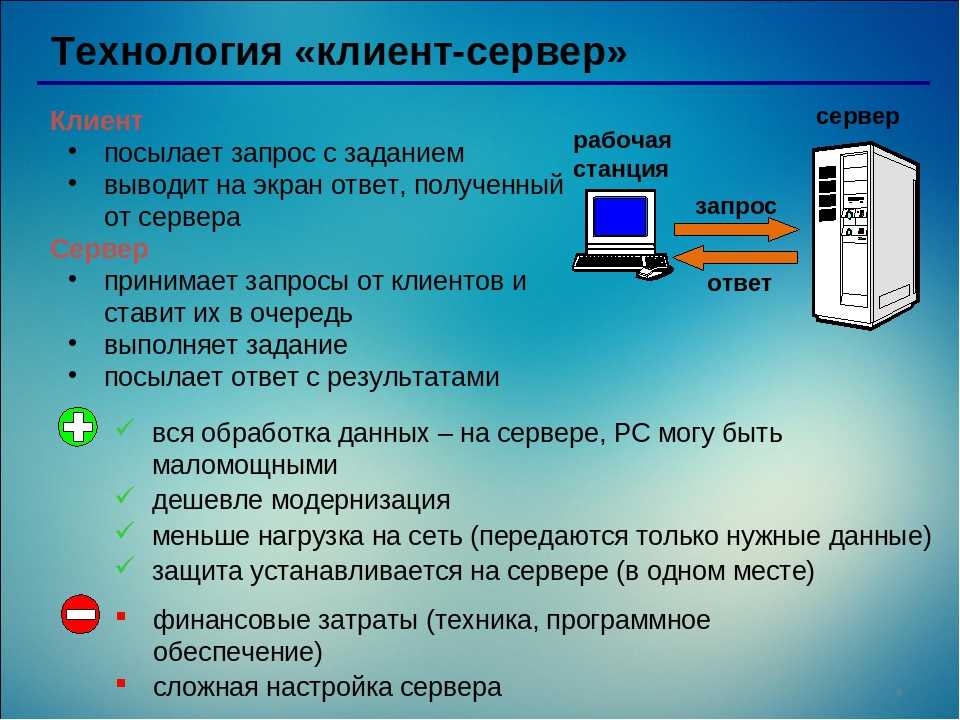 Создание выполняется с использованием метода POST , чтение с использованием метода GET , обновление с использованием метода PUT и DELETE с использованием метода DELETE .
Создание выполняется с использованием метода POST , чтение с использованием метода GET , обновление с использованием метода PUT и DELETE с использованием метода DELETE .
ПРИМЕЧАНИЕ :
- строка запроса предназначена для параметров, связанных с ресурсом, к которому мы обращаемся
- заголовки HTTP предназначены для параметров, связанных с самим запросом, например заголовки аутентификации
Наконец, в разделе необязательных данных запроса мы помещаем данные, которые мы хотим отправить в API при создании или изменении resource..
Сообщения должны быть информативными. Это означает, что формат данных представления всегда должен сопровождаться типом носителя (аналогично запрос ресурса включает в себя выбор типа носителя возвращаемого представления). Если вы отправляете HTML, вы должны сказать, что это HTML, отправив тип мультимедиа с представлением.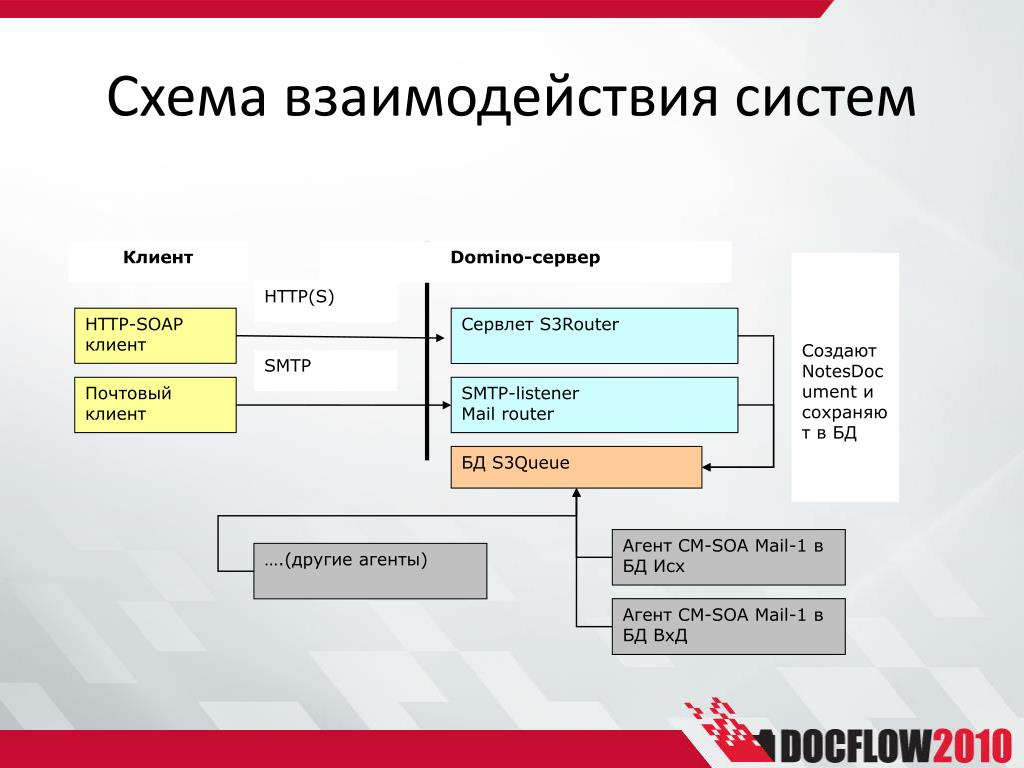 В HTTP это делается с помощью заголовка content-type.
В HTTP это делается с помощью заголовка content-type.
Когда мы делаем HTTP-запрос, мы получаем ответ от сервера. Этот ответ обычно содержит:
- код состояния , который является числом, которое говорит нам, был ли наш вызов в порядке или произошла какая-то ошибка
- некоторые заголовки HTTP, определяющие некоторую дополнительную информацию об ответе
- данные , если мы запросили некоторые. Данные могут быть запрошены с помощью Content-
Type в заголовке HTTP-запросаContent-Type. На стороне сервера к входящему запросу может быть прикреплен объект. Чтобы определить его тип, сервер использует заголовок HTTP-запросаТип содержимого. Некоторыми распространенными примерами типов контента являются «text/plain», «application/xml», «text/html», «application/json», «image/gif» и «image/jpeg».
После того, как вы поняли, как работают REST API и протокол HTTP, пришло время делать сетевые запросы из нашего приложения.
Для создания HTTP-запроса необходимо знать три класса:
- URLSession : как следует из названия, это соответствует сеансу HTTP. Поскольку сеанс HTTP группирует набор запросов и ответов, URLSession используется для создания разных запросов с одинаковой конфигурацией. Однако на практике вам не нужно повторно использовать URLSession, и вы можете создавать новый для каждого запроса.
- URLRequest : этот класс инкапсулирует метаданные одного запроса, включая URL-адрес, метод HTTP (GET, POST и т. д.), заголовки HTTP и т. д. Но для простых запросов вообще не нужно использовать этот класс.
- URLSessionTask : этот класс выполняет фактическую передачу данных. Он имеет разные подклассы для разных типов задач. Чаще всего вы будете использовать URLSessionDataTask , который извлекает содержимое URL-адреса как объект данных. На самом деле вы не создаете экземпляр задачи самостоятельно, класс URLSession делает это за вас. Но вы должны запомнить всем их метод возобновления(), иначе он не запустится.
 Но вы должны запомнить всем их метод возобновления(), иначе он не запустится.
Но вы должны запомнить всем их метод возобновления(), иначе он не запустится.Вот и все.
Таким образом, выполнение HTTP-запроса в iOS сводится к:
- созданию и настройке экземпляра URLSession для выполнения одного или нескольких HTTP-запросов
- созданию и настройке экземпляра URLRequest для ваших запросов, но только если вам нужны некоторые конкретные параметры. В противном случае вы можете пропустить это;
- Запуск URLSessionDataTask через экземпляр URLSession.
Для этого требуется всего несколько строк кода:
REST API обычно возвращают запрашиваемые вами данные в формате JSON. А JSON полезная нагрузка на самом деле является строкой. Итак, прежде чем вы сможете использовать данные, вы должны проанализировать эту строку и преобразовать ее в объекты.
iOS SDK предлагает класс JSONSerialization , который позаботится об этом.
После синтаксического анализа строки JSON этот класс возвращает структуру, очень похожую на список свойств. Единственное отличие состоит в том, что сериализация JSON может включать экземпляры класса NSNull для представления нулевых значений, которые приходят в ответ JSON (списки не могут иметь нулевых значений) (Примечание: Swift 4 представил лучший подход к декодированию JSON с использованием Codable протокол вместо класса JSONSerialization .)
Единственное отличие состоит в том, что сериализация JSON может включать экземпляры класса NSNull для представления нулевых значений, которые приходят в ответ JSON (списки не могут иметь нулевых значений) (Примечание: Swift 4 представил лучший подход к декодированию JSON с использованием Codable протокол вместо класса JSONSerialization .)
Допустим, мы хотим написать код, который извлекает список вопросов из переполнения стека.
Обычно так пишут.
class NetworkController {
func loadQuestions (с завершением завершения: @escaping ([Question]?) -> Void) {
let session = URLSession(configuration: .ephemeral, делегат: nil, delegateQueue .главное)
let url = URL (строка: «https://api.stackexchange.com/2.2/questions?order=desc&sort=votes&site=stackoverflow»)!
let task = session.dataTask(с: url , completeHandler: { (data: Data?, response: URLResponse?, error: Error?) -> Void in
guard let data = data else {
завершение (ноль)
return
}
Guard let json = try?JSONSerialization.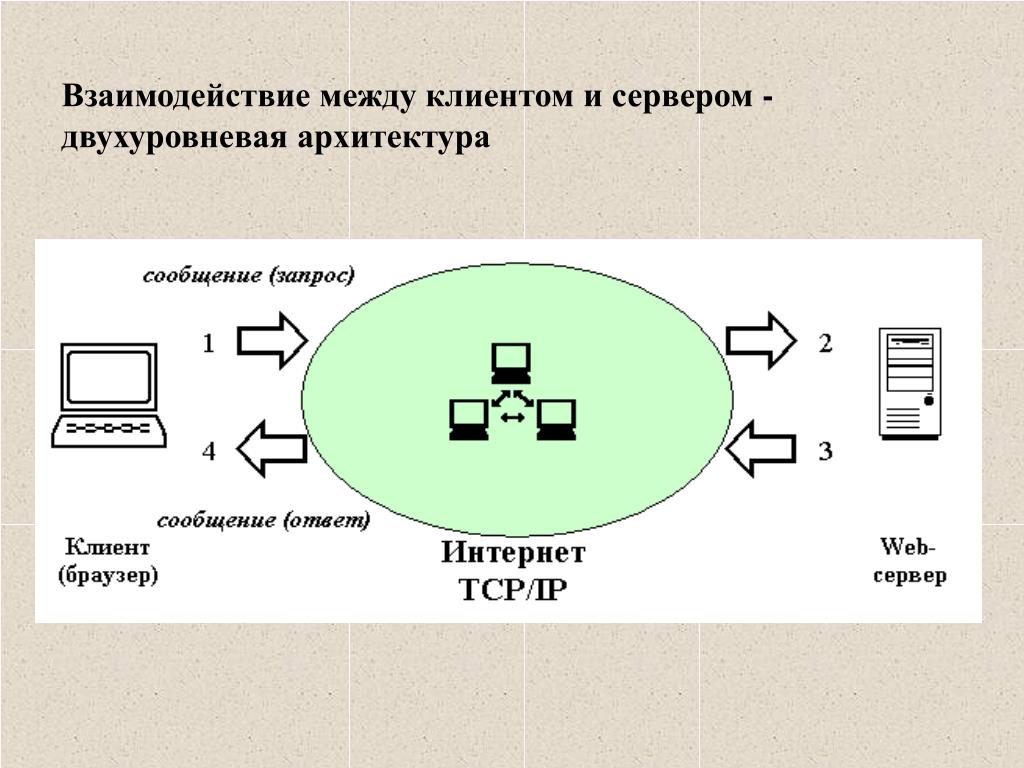 jsonObject(with: data, options: .mutableContainers) else {
jsonObject(with: data, options: .mutableContainers) else {
Завершение (ноль)
Возврат
}
. })
Task.Resume ()
}
}
Важные концепции для запоминания:
- Как REST RESI SELY на HOLS и HOLS. Архитектура REST для веб-служб использует URL-адреса для указания ресурсов и параметров и HTTP-команды для определения действий.
- Ответы используют код состояния HTTP для выражения результата и тела для возврата запрошенных данных, часто в формате JSON.
- как выполнять сетевые запросы в приложениях iOS с помощью URLSession.
- Класс URLSession представляет сеанс HTTP, URLRequest представляет один запрос в сеансе, а URLSessionTask фактически выполняет асинхронную передачу данных.
Здесь я попытался объяснить основные принципы связи между клиентом и сервером. Однако я попытаюсь включить концепцию сетевой архитектуры для ваших приложений и то, как подход MVC к сети в iOS может решить многие проблемы.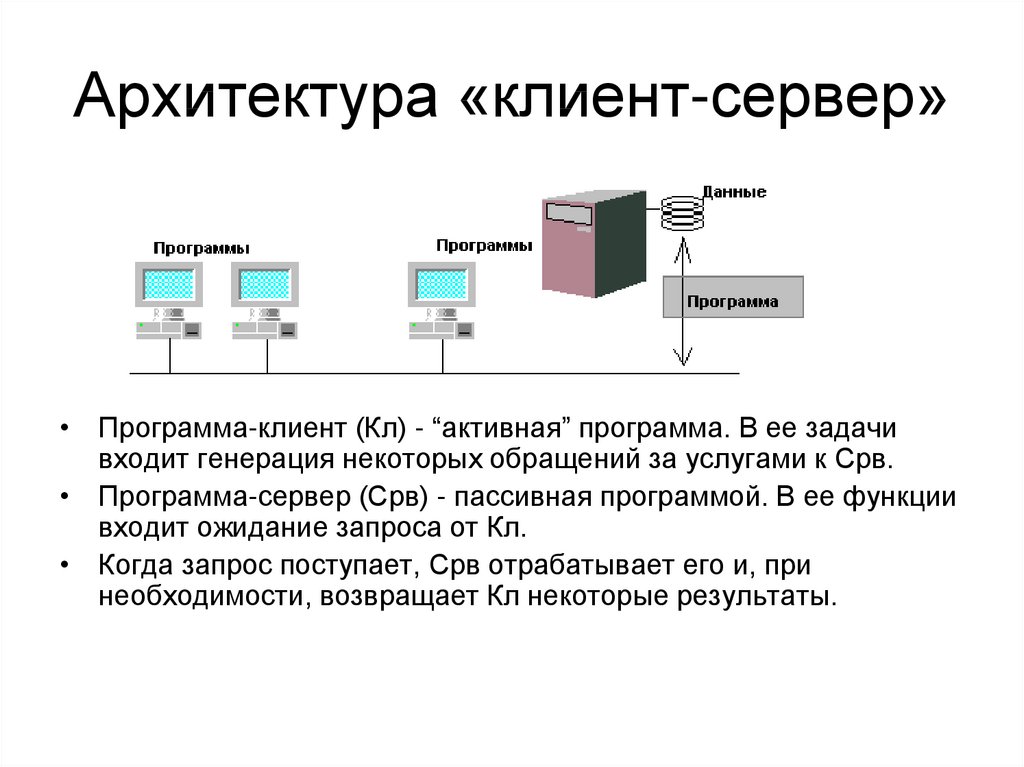 Пожалуйста, не стесняйтесь оставлять отзывы, а также дайте мне знать, если я пропустил какие-либо концепции здесь.
Пожалуйста, не стесняйтесь оставлять отзывы, а также дайте мне знать, если я пропустил какие-либо концепции здесь.
С уважением и благодарностью
Взаимодействие сервер-клиент — проектирование системы
Нередко мы хотим, чтобы наш клиент заранее получал последние данные с сервера, или сервер отправлял последние данные клиенту.
Несколько способов реализовать их:
Короткий/длинный опрос (притяжение клиента)
WebSockets (Server Push)
Серверные события (Server Push)
периодически запрашивать сервер.
Плюсы: Простота реализации
Минусы: Бесполезная трата ресурсов системы, так как многие из этих запросов получат пустой ответ.
Вместо того, чтобы сразу возвращать клиентский запрос с пустым ответом, сервер держит клиентское соединение открытым как можно дольше.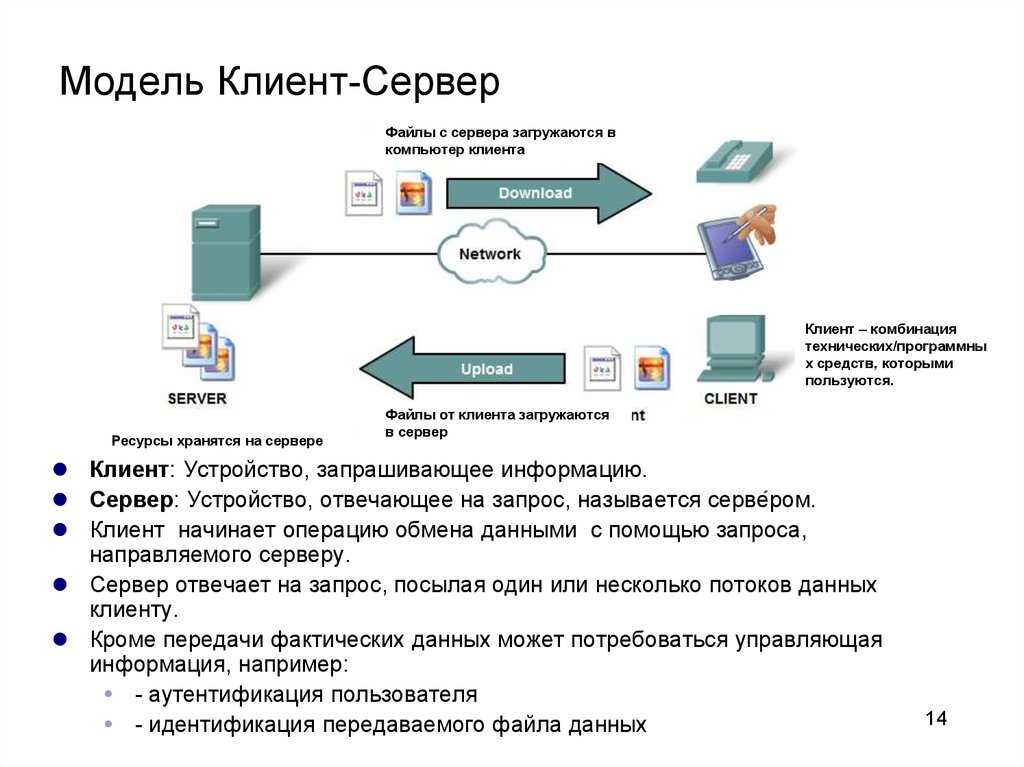 Он отправляет ответ только после того, как данные станут доступны или будет достигнут порог тайм-аута.
Он отправляет ответ только после того, как данные станут доступны или будет достигнут порог тайм-аута.
Поток для длинного опроса будет выглядеть следующим образом
1
.
Клиент инициирует запрос XHR/AJAX, запрашивая некоторые данные с сервера.
2
.
Сервер не сразу отвечает запросом информации, а ждет, пока не появится новая информация.
3
.
Когда доступна новая информация, сервер отвечает новой информацией.
4
.
Клиент получает новую информацию и немедленно отправляет другой запрос на сервер, перезапуская процесс.

Pro: более эффективен, чем короткий опрос.
Против: при одном рукопожатии HTTP сервер может отправить ответ только один раз.
WebSocket — это протокол компьютерной связи , который обеспечивает полнодуплексных каналов связи по одному TCP-соединению.
Отличается от HTTP, но совместим с HTTP.
Расположен на уровне 7 в модели OSI и зависит от TCP на уровне 4.
Работает через порты 80 и 443 (в случае шифрования TLS) и поддерживает HTTP-прокси и посредников.
Для обеспечения совместимости рукопожатие WebSocket использует заголовок Upgrade для обновления протокола до протокола WebSocket.
Протокол WebSocket обеспечивает взаимодействие между клиентом и веб-сервером с меньшими затратами, обеспечивая передачу данных с сервера и на сервер в реальном времени. WebSockets поддерживает соединение открытым, позволяя передавать сообщения туда и обратно между клиентом и сервером. Таким образом, между клиентом и сервером может иметь место двусторонний непрерывный диалог.
Поток подключения WebSocket будет выглядеть примерно так.
1
.
Клиент инициирует процесс рукопожатия WebSocket, отправив запрос, который также содержит заголовок Upgrade для переключения на протокол WebSocket вместе с другой информацией.
2
.
Сервер получает запрос квитирования WebSocket и обрабатывает его.
1
.
Если сервер может установить соединение и соглашается с условиями клиента, то отправляет ответ клиенту, подтверждая запрос установления связи WebSocket с другой информацией.
2
.
Если сервер не может установить соединение, он отправляет ответ, подтверждающий, что он не может установить соединение WebSocket.
3
.
После того, как клиент получит успешный запрос подтверждения соединения WebSocket, соединение WebSocket будет открыто. Теперь клиент и серверы могут начать отправлять данные в обоих направлениях, обеспечивая связь в режиме реального времени.
4
.
Соединение будет закрыто, как только сервер или клиент решит закрыть соединение.
Полный дуплекс
С помощью одного рукопожатия HTTP между клиентом и сервером может быть отправлено несколько сообщений.
Поскольку WebSocket на самом деле не является HTTP, некоторые элементы ИТ-инфраструктуры могут не работать с WebSocket, например балансировщик нагрузки, брандмауэр и т.
д.что-то, что вам нужно реализовать самостоятельно, и это одна из причин, по которой существует множество клиентских библиотек.
 д.
д.WebSocket — лучшее решение для приложений реального времени, таких как чат.
В отличие от WebSockets, события, отправленные сервером, представляют собой односторонний канал связи , где события передаются только с сервера на клиент . Server-Sent Events позволяет клиентам браузера получать поток событий с сервера через HTTP-соединение без опроса.
Клиент подписывается на «поток» с сервера, и сервер будет отправлять сообщения («поток событий») клиенту до тех пор, пока сервер или клиент не закроет поток. Сервер сам решает, когда и что отправлять клиенту, например, как только данные изменяются.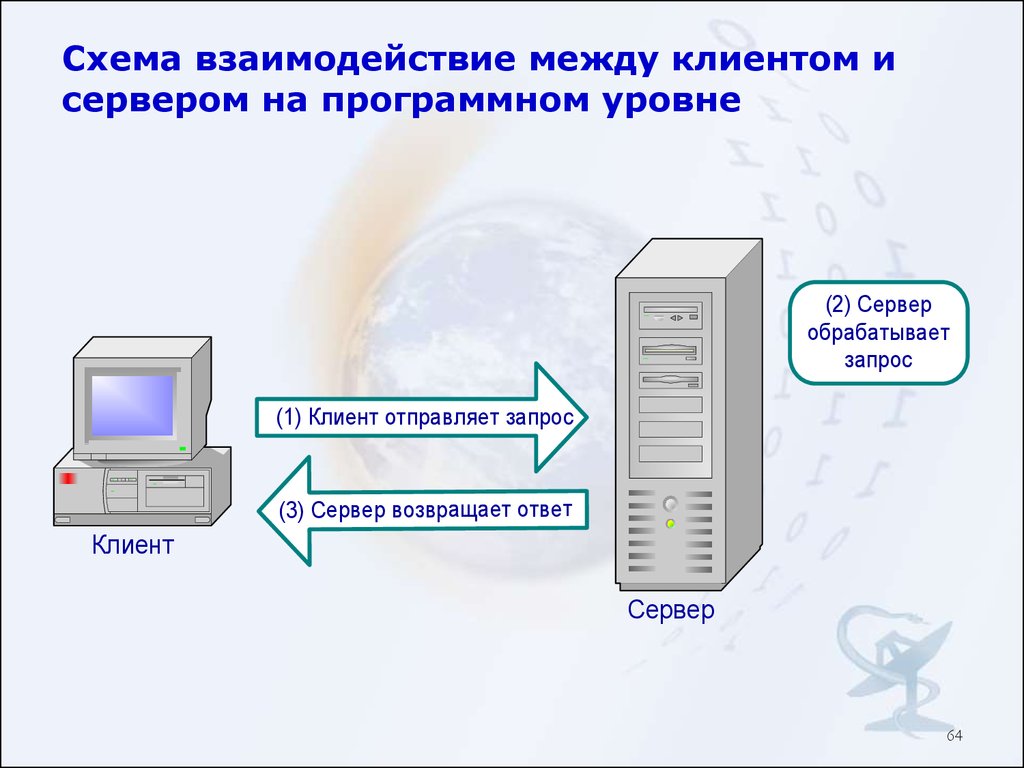
Поток событий отправки сервера будет следующим.
1
.
Клиент браузера создает соединение с помощью API EventSource с конечной точкой сервера, которая, как ожидается, со временем будет возвращать поток событий. По сути, это делает HTTP-запрос по заданному URL-адресу.
2
.
Сервер получает обычный HTTP-запрос от клиента, открывает соединение и поддерживает его открытым. Теперь сервер может отправлять данные о событии столько, сколько захочет, или закрыть соединение, если данных нет.
3
.
Клиент получает каждое событие от сервера и обрабатывает его.
Если он получает сигнал закрытия от сервера, он может закрыть соединение. Клиент также может инициировать запрос на закрытие соединения.
 Если он получает сигнал закрытия от сервера, он может закрыть соединение. Клиент также может инициировать запрос на закрытие соединения.
Если он получает сигнал закрытия от сервера, он может закрыть соединение. Клиент также может инициировать запрос на закрытие соединения.Поскольку SSE основан на HTTP, он более совместим с существующей ИТ-инфраструктурой, такой как (балансировщик нагрузки, брандмауэр и т. д.), в отличие от WebSockets, которые могут быть заблокированы некоторыми брандмауэрами.
События Server-Sent поддерживаются не всеми браузерами.
Варианты использования:
График цен акций в реальном времени
Новостное освещение важного события (публикация ссылок, твитов и изображений)
Монитор статистики сервера, такой как время безотказной работы, работоспособность и запущенные процессы.
8 A 9 Live Dashboard стена, питаемая потоковым API Twitter