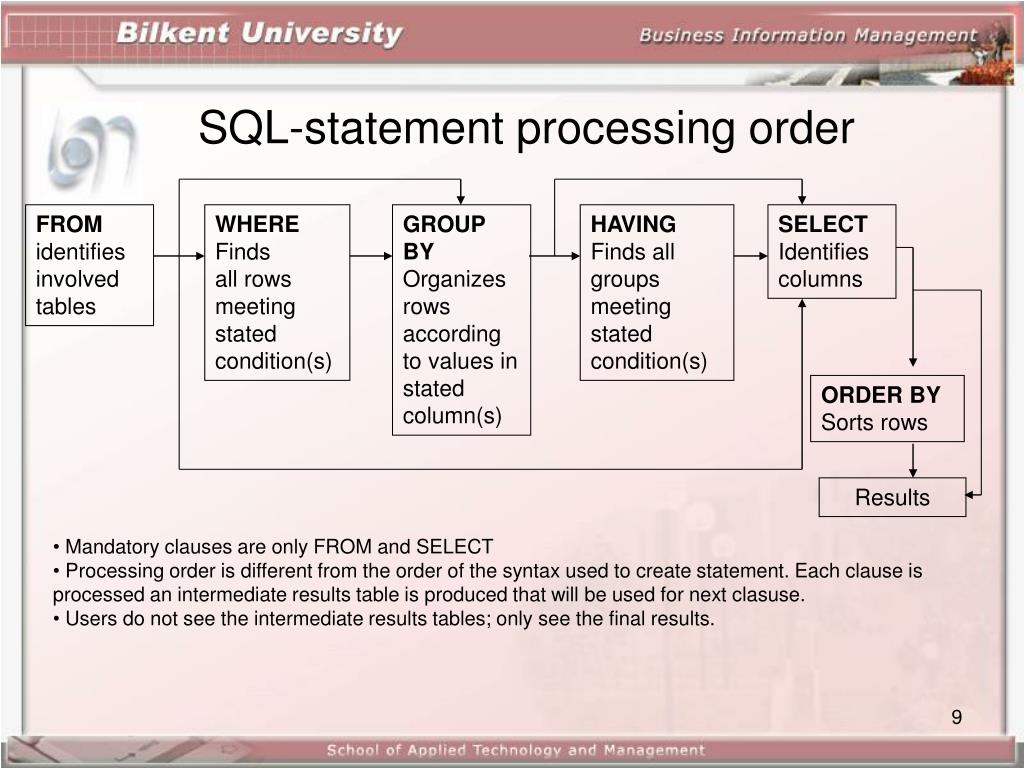
With ties sql: Использование фильтра TOP с параметром WITH TIES | Windows IT Pro/RE
Содержание
Подробнее о TOP / Хабр
В прошлой статье я писал об особом виде оператора TOP, известного как ROWCOUNT TOP. Теперь рассмотрим несколько других интересных сценариев появления в плане оператора TOP.
В общем случае, ТОР — довольно приземленный оператор. Он просто подсчитывает и возвращает заданное количество строк. SQL Server 2005 включает в себя два усовершенствования этого оператора, которых не было в SQL Server 2000.
Во-первых, в SQL Server 2000 можно указать только константу в виде целого числа возвращаемых строк. В SQL Server 2005 мы можем указать произвольное выражение, включая выражение, содержащее переменные или параметры T-SQL.
Во-вторых, SQL Server 2000 допускает только TOP в операторе SELECT (хотя он поддерживает ROWCOUNT TOP в операторах INSERT, UPDATE и DELETE). SQL Server 2005 допускает TOP с операторами SELECT, INSERT, UPDATE и DELETE.
В этой статье мы сосредоточимся на нескольких простых примерах с оператором SELECT. Для начала создадим небольшую таблицу:
CREATE TABLE T (A INT, B INT)
CREATE CLUSTERED INDEX TA ON T(A)
SET NOCOUNT ON
DECLARE @i INT
SET @i = 0
WHILE @i < 100
BEGIN
INSERT T VALUES (@i, @i)
SET @i = @i + 1
END
SET NOCOUNT OFFПлан простейшего запроса с TOP не нуждается в пояснениях:
SELECT TOP 5 * FROM T
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5))) 5 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
 [dbo].[T].[TA]))
[dbo].[T].[TA]))TOP часто используется в сочетании с ORDER BY. Сочетание TOP с ORDER BY способствует детерминированности выборки. Без ORDER BY выборка зависит от плана запроса и даже может меняться от выполнения к выполнению. Если у нас есть подходящий индекс для поддержки выбранного порядка строк, план запроса останется простым (обратите внимание на ключевые слова ORDERED FORWARD):
SELECT TOP 5 * FROM T ORDER BY A
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5))) 5 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]), ORDERED FORWARD)
Если подходящего индекса нет, SQL Server вынужден будет добавить в план сортировку:
SELECT TOP 5 * FROM T ORDER BY B
Rows Executes 5 1 |--Sort(TOP 5, ORDER BY:([tempdb].[dbo].[T].[B] ASC)) 100 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
Обратите внимание что, если нет подходящего индекса для выборки первых 5 строк SQL Server должен просмотреть все 100 строк таблицы. Также обратите внимание, что сортировка в этом сценарии будет «TOP sort». Такая сортировка обычно использует меньше памяти, чем обычная сортировка, поскольку ей нужно прокрутить через алгоритм сортировки только несколько топовых строк, а не всю таблицу.
Также обратите внимание, что сортировка в этом сценарии будет «TOP sort». Такая сортировка обычно использует меньше памяти, чем обычная сортировка, поскольку ей нужно прокрутить через алгоритм сортировки только несколько топовых строк, а не всю таблицу.
Теперь давайте рассмотрим, что произойдет, если мы запросим TOP 5% строк. Чтобы это определить. Для получения результата SQL Server должен подсчитать все строки и вычислить 5%. Это делает запросы, использующие TOP PERCENT, менее эффективными, чем запросы, использующие TOP с абсолютным числом строк.
SELECT TOP 5 PERCENT * FROM T
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5.000000000000000e+000)) PERCENT) 5 1 |--Table Spool 100 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
Как и в предыдущем примере, SQL Server будет просматривать все 100 строк таблицы. Тут SQL Server использует «жадную» очередь (Eager Spool), которая буферизует и подсчитывает все входные строки, прежде чем что-либо возвращать. Затем TOP запрашивает число строк в очереди, вычисляет 5% и продолжает работу, как любой другой TOP.
Затем TOP запрашивает число строк в очереди, вычисляет 5% и продолжает работу, как любой другой TOP.
Если SQL Server в плане запроса должен выполнять сортировку, этим он также может обеспечить подсчёт затронутых строк. Однако только обычная сортировка умеет подсчитывать их количество. Сортировка «TOP sort» должна знать какое число строк необходимо вернуть с самого начала.
SELECT TOP 5 PERCENT * FROM T ORDER BY B
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5.000000000000000e+000)) PERCENT) 5 1 |--Sort(ORDER BY:([tempdb].[dbo].[T].[B] ASC)) 100 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
TOP WITH TIES также несовместим с «TOP sort». TOP WITH TIES не позволяет узнать наверняка, сколько строк будет получено, пока не будет вычитаны все «привязки». В нашем примере давайте сделаем «привязку» для пятой строки:
INSERT T VALUES (4, 4) SELECT TOP 5 WITH TIES * FROM T ORDER BY B
Rows Executes 6 1 |--Top(TOP EXPRESSION:((5))) 7 1 |--Sort(ORDER BY:([tempdb].
 [dbo].[T].[B] ASC))
101 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
[dbo].[T].[B] ASC))
101 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
В этом представлении плана нет TOP WITH TIES, но при SHOWPLAN_ALL или STATISTICS PROFILE можно увидеть следующее: «TIE COLUMNS:([T].[B])». Это также доступно в графическом и XML-планах запроса для SQL Server 2005. Обратите внимание, что TOP теперь возвращает на одну строку больше. Когда TOP N WITH TIES достигает N-й строки, он хранит копию для привязки значения столбца этой строки (в примере B==4) и сравнивает каждую следующую в выборке строку с этим значением. Если есть подходящие строки, он их все вернёт в результате запроса. Поскольку TOP вынужден сравнивать значения всех оставшихся строк, пока не выберет все совпадения для первых N строк, в нашем примере TOP извлечёт из сортировки на одну строку больше, чем было до него.
Наконец, есть пара вырожденных случаев, когда оптимизатор знает, что TOP 0 и TOP 0 PERCENT никогда ничего не возвращают, и заменяет любой такой план запроса на сканирование константы:
SELECT TOP 0 * FROM T
|--Constant Scan
Оптимизатор также знает, что TOP 100 PERCENT всегда возвращает все строки и удаляет оператор TOP из плана запроса:
SELECT TOP 100 PERCENT * FROM T
|--Clustered Index Scan(OBJECT:([tempdb].
 [dbo].[T].[TA]))
[dbo].[T].[TA]))Для этих случаев требуется, чтобы количество строк было постоянным. Например, использование выражения, включающего переменную или параметр T-SQL, приведёт к тому, что план запроса будет такой же, как в общем случае. Оба описанных упрощения плана также работают и с операторами INSERT, UPDATE и DELETE.
Обратите внимание, что не рекомендуется использовать TOP для обхода ограничений языка SQL на использование ORDER BY в подзапросах или представлениях или для принудительного определенных порядка использования операторов в плане запроса.
LIMIT и FETCH в SQL
Занимательный факт: В SQL-стандарте не предусмотрен limit.
Все используют limit:
select * from employees order by salary desc limit 5;
┌────┬──────────┬────────────┬────────┐ │ id │ name │ department │ salary │ ├────┼──────────┼────────────┼────────┤ │ 25 │ Иван │ it │ 120 │ │ 23 │ Леонид │ it │ 104 │ │ 24 │ Марина │ it │ 104 │ │ 33 │ Анна │ sales │ 100 │ │ 31 │ Вероника │ sales │ 96 │ └────┴──────────┴────────────┴────────┘
А согласно стандарту, следует использовать fetch:
select * from employees order by salary desc fetch first 5 rows only;
fetch first N rows only делает то же, что и limit N. Но вообще
Но вообще fetch может больше.
Лимит с одинаковыми значениями
Допустим, мы хотим выбрать топ-5 сотрудников по зарплате, и заодно всех, у кого такая же зарплата, как у последнего из этой пятерки. Используем для этого with ties:
select * from employees order by salary desc fetch first 5 rows with ties;
┌────┬──────────┬────────────┬────────┐ │ id │ name │ department │ salary │ ├────┼──────────┼────────────┼────────┤ │ 25 │ Иван │ it │ 120 │ │ 23 │ Леонид │ it │ 104 │ │ 24 │ Марина │ it │ 104 │ │ 33 │ Анна │ sales │ 100 │ │ 31 │ Вероника │ sales │ 96 │ │ 32 │ Григорий │ sales │ 96 │ └────┴──────────┴────────────┴────────┘
Относительный лимит
Допустим, мы хотим выбрать верхние 10% сотрудников по зарплате. Поможет percent:
select * from employees order by salary desc fetch first 10 percent rows only;
┌────┬──────────┬────────────┬────────┐ │ id │ name │ department │ salary │ ├────┼──────────┼────────────┼────────┤ │ 25 │ Иван │ it │ 120 │ │ 23 │ Леонид │ it │ 104 │ └────┴──────────┴────────────┴────────┘
(всего 20 сотрудников, так что 10% — это 2 записи)
Лимит со смещением
Допустим, мы хотим пропустить 3 первых сотрудников и выбрать 5 следующих. Без проблем:
Без проблем: fetch сочетается с offset точно так же, как limit:
select * from employees order by salary desc offset 3 rows fetch next 5 rows only;
┌────┬──────────┬────────────┬────────┐ │ id │ name │ department │ salary │ ├────┼──────────┼────────────┼────────┤ │ 33 │ Анна │ sales │ 100 │ │ 31 │ Вероника │ sales │ 96 │ │ 32 │ Григорий │ sales │ 96 │ │ 22 │ Ксения │ it │ 90 │ │ 21 │ Елена │ it │ 84 │ └────┴──────────┴────────────┴────────┘
next здесь — просто синтаксический сахар, синоним для first, который использовался в предыдущих примерах. Можно заменить next на first с точно таким же результатом:
select * from employees order by salary desc offset 3 rows fetch first 5 rows only;
Кстати, row и rows тоже синонимы.
Совместимость
fetch поддерживают эти СУБД:
- PostgreSQL 8. 4+
- Oracle 12c+
- MS SQL 2012+
- DB2 9+
 4+
4+Но только Oracle поддерживает относительные лимиты (percent).
А MySQL и SQLite не поддерживают fetch вовсе.
P.S. Хотите узнать больше о продвинутых возможностях SQL? Обратите внимание на Оконные функции SQL
Подписывайтесь на твитер, чтобы не пропустить новые заметки 🚀
SQL | Пункт With Ties
Этот пост является продолжением пункта SQL Offset-Fetch
Теперь мы понимаем, как использовать пункт Fetch в базе данных Oracle вместе с указанным смещением, и мы также понимаем, что пункт Fetch является недавно добавленным пунктом в базе данных Oracle 12c или это новая функция, добавленная в базу данных Oracle 12c.
Теперь рассмотрим приведенный ниже пример:
Предположим, у нас есть таблица с именем myTable со следующими данными:
ID ИМЯ ЗАРПЛАТА ----------------------------- 1 Компьютерщики 10000 4 Финч 10000 2 6000 руб.
 3 Дони 16000
5 Картик 7000
6 Watson 10000
3 Дони 16000
5 Картик 7000
6 Watson 10000 Теперь предположим, что мы хотим, чтобы первые три строки были упорядочены по зарплате в порядке убывания, тогда необходимо выполнить следующий запрос:
Запрос: ВЫБЕРИТЕ * из моей таблицы сортировать по разряду зарплаты получить только первые 3 строки; Вывод: Мы получили только первые 3 строки в порядке убывания по зарплате ID ИМЯ ЗАРПЛАТА -------------------------- 3 Дони 16000 1 Компьютерщики 10000 4 Финч 10000
Примечание : В приведенном выше результате мы получили первые 3 строки, упорядоченные по зарплате в порядке убывания, но у нас есть еще одна строка с той же зарплатой, то есть строка с именем Watson и зарплатой 10000 , но это не так. не подошло, потому что мы ограничили наш вывод только первыми тремя строками. Но это не оптимально, потому что большую часть времени в живых приложениях нам потребуется также отображать связанные строки.
Пример из реальной жизни . Предположим, у нас есть 10 гонщиков, и у нас есть только 3 приза, то есть первый, второй, третий, но предположим, что гонщики 3 и 4 закончили гонку вместе в одно и то же время, поэтому в этом случае мы имеем ничья между 3 и 4, поэтому оба занимают позицию 3.
With Ties
Таким образом, чтобы преодолеть вышеупомянутую проблему, Oracle вводит пункт, известный как пункт With Ties . Теперь давайте посмотрим на наш предыдущий пример с использованием предложения With Ties.
Запрос: ВЫБЕРИТЕ * из моей таблицы сортировать по разряду зарплаты выборка первых 3 строк Со связями ; Выход : Смотрите, мы получаем только первые 3 строки, упорядоченные по зарплате в порядке убывания, а также Tied Row . ID ИМЯ ЗАРПЛАТА -------------------------- 3 Дони 16000 1 Компьютерщики 10000 6 Watson 10000 // Мы также получаем Tied Row 4 Финч 10000
Теперь смотри, мы получили связал также строку , которую мы раньше не получали.
Примечание : мы получаем связанную строку в нашем выводе, только когда мы используем предложение order by в нашем операторе Select. Предположим, что если мы не будем использовать предложение order by, и все же мы используем с предложением ties , то мы не получим связанную строку в нашем выводе, и запрос будет вести себя так же, как если бы мы использовали предложение ТОЛЬКО . вместо пункта With Ties.
Пример — Предположим, мы выполняем следующий запрос (без использования предложения order by):
Запрос : ВЫБЕРИТЕ * из моей таблицы выборка первых 3 строк Со связями ; Выход : Смотрите, мы не получим связанную строку, потому что мы не использовали предложение order by ID ИМЯ ЗАРПЛАТА -------------------------- 1 Компьютерщики 10000 4 Финч 10000 2 6000 руб.
В приведенном выше результате мы не получим связанную строку и получим только первые 3 строки. Так With Ties — это , связанный с предложением order by , т. е. мы получаем связанную строку в выводе тогда и только тогда, когда мы используем With Ties вместе с предложением Order by.
Так With Ties — это , связанный с предложением order by , т. е. мы получаем связанную строку в выводе тогда и только тогда, когда мы используем With Ties вместе с предложением Order by.
Примечание : убедитесь, что вы выполняете эти запросы в базе данных Oracle 12c, поскольку предложение Fetch является недавно добавленной функцией в Oracle 12c, а также с Ties, работает только в базе данных Oracle 12c, эти запросы не будут запустите версии 12c ниже, такие как 10g или 11g.
Ссылка s: О предложении Fetch, а также о предложении Ties, выполнение SQL-запросов онлайн
SQL Server SELECT TOP на практических примерах
Резюме : в этом руководстве вы узнаете, как использовать оператор SQL Server SELECT TOP чтобы ограничить количество строк, возвращаемых запросом.
Введение в SQL Server
SELECT TOP
Предложение SELECT TOP позволяет ограничить количество строк или процент строк, возвращаемых в наборе результатов запроса.
Поскольку порядок строк, хранящихся в таблице, не указан, оператор SELECT TOP всегда используется в сочетании с предложением ORDER BY . Поэтому результирующий набор ограничен первым N числом упорядоченных строк.
Ниже показан синтаксис предложения TOP с оператором SELECT :
SELECT TOP (выражение) [PERCENT]
[СО СВЯЗЬМИ]
ОТ
имя_таблицы
СОРТИРОВАТЬ ПО
имя_столбца;
Язык кода: SQL (язык структурированных запросов) (sql) В этом синтаксисе оператор SELECT может иметь другие предложения, такие как WHERE , JOIN , HAVING и 901 04 ГРУППА ПО .
выражение
После ключевого слова TOP следует выражение, указывающее количество возвращаемых строк. Выражение оценивается как значение с плавающей запятой, если используется 90 104 ПРОЦЕНТ 90 105, в противном случае оно преобразуется в число 9. 0104 БОЛЬШОЕ значение.
0104 БОЛЬШОЕ значение.
PERCENT
Ключевое слово PERCENT указывает, что запрос возвращает первые N процентов строк, где N — результат выражения .
WITH TIES
WITH TIES позволяет вернуть больше строк со значениями, которые соответствуют последней строке в ограниченном наборе результатов. Обратите внимание, что WITH TIES может привести к тому, что будет возвращено больше строк, чем указано в выражении.
Например, если вы хотите вернуть самые дорогие товары, вы можете использовать TOP 1 . Однако, если у двух или более товаров такие же цены, как и у самого дорогого товара, вы пропустите другие самые дорогие товары в результирующем наборе.
Во избежание этого можно использовать ВЕРХ 1 С СВЯЗЯМИ . В него войдет не только первый дорогой товар, но и второй, и так далее.
SQL Server
SELECT TOP примеров
Мы будем использовать 9Таблица 0104 production. products в образце базы данных для демонстрации.
products в образце базы данных для демонстрации.
1) Использование
TOP с постоянным значением
В следующем примере используется постоянное значение для возврата 10 самых дорогих товаров.
ВЫБЕРИТЕ ПЕРВЫЕ 10
наименование товара,
список цен
ОТ
производство.продукция
СОРТИРОВАТЬ ПО
list_price DESC;
Язык кода: SQL (язык структурированных запросов) (sql) Вот результат:
2) Использование
TOP для возврата процента строк
В следующем примере используется ПРОЦЕНТ для указания количества продуктов, возвращаемых в результирующем наборе. Таблица production.products содержит 321 строк, поэтому один процент от 321 является дробным значением ( 3.21 ), SQL Server округляет его до следующего целого числа, равного четырем ( 4 ) в Это дело.
ВЫБЕРИТЕ ВЕРХНИЙ 1 ПРОЦЕНТ
наименование товара,
список цен
ОТ
производство.