Заменить символ в строке sql: REPLACE | SQL | SQL-tutorial.ru
Содержание
Функции поиска и замены в строках
replaceOne(haystack, pattern, replacement)
Замена первого вхождения, если такое есть, подстроки pattern в haystack на подстроку replacement.
Здесь и далее, pattern и replacement должны быть константами.
replaceAll(haystack, pattern, replacement)
Замена всех вхождений подстроки pattern в haystack на подстроку replacement.
replaceRegexpOne(haystack, pattern, replacement)
Замена по регулярному выражению pattern. Регулярное выражение re2.
Заменяется только первое вхождение, если есть.
В качестве replacement может быть указан шаблон для замен. Этот шаблон может включать в себя подстановки \0-\9.
Подстановка \0 — вхождение регулярного выражения целиком. Подстановки \1-\9 — соответствующие по номеру subpattern-ы.
Для указания символа \ в шаблоне, он должен быть экранирован с помощью символа \.
Также помните о том, что строковый литерал требует ещё одно экранирование.
Пример 1. Переведём дату в американский формат:
SELECT DISTINCT
EventDate,
replaceRegexpOne(toString(EventDate), '(\\d{4})-(\\d{2})-(\\d{2})', '\\2/\\3/\\1') AS res
FROM test.hits
LIMIT 7
FORMAT TabSeparated
2014-03-17 03/17/2014
2014-03-18 03/18/2014
2014-03-19 03/19/2014
2014-03-20 03/20/2014
2014-03-21 03/21/2014
2014-03-22 03/22/2014
2014-03-23 03/23/2014
Пример 2. Размножить строку десять раз:
SELECT replaceRegexpOne('Hello, World!', '.*', '\\0\\0\\0\\0\\0\\0\\0\\0\\0\\0') AS res
┌─res────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Hello, World!Hello, World!Hello, World!Hello, World!Hello, World!Hello, World!Hello, World!Hello, World!Hello, World!Hello, World! │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
replaceRegexpAll(haystack, pattern, replacement)
То же самое, но делается замена всех вхождений.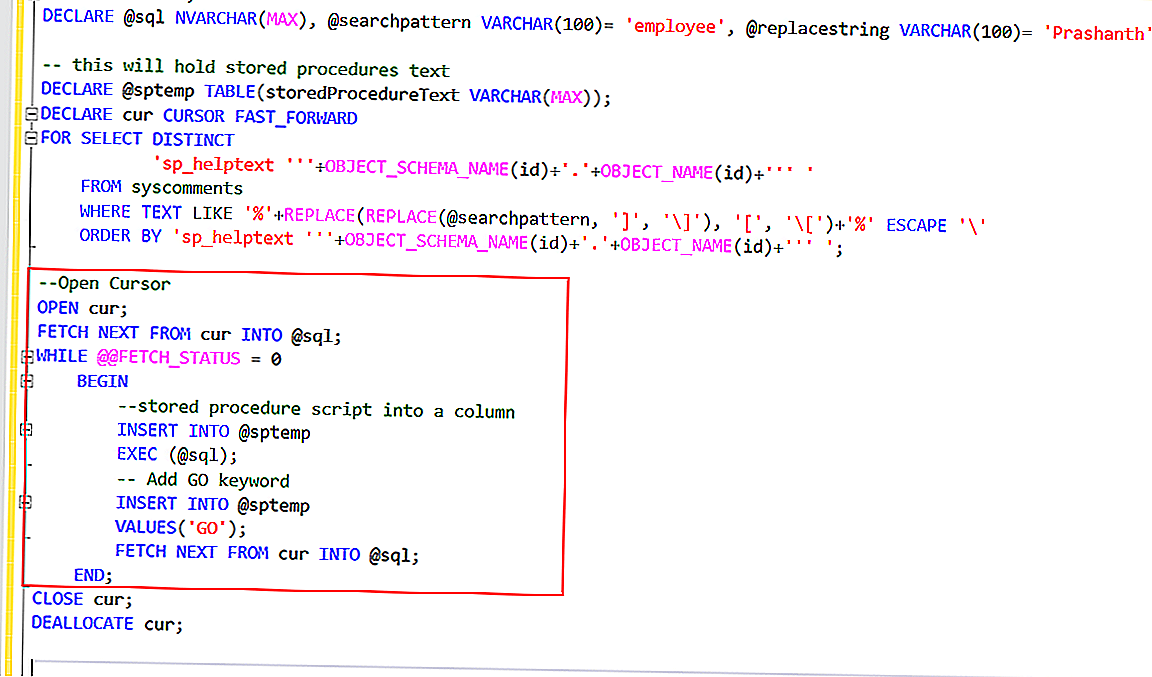 ‘, ‘here: ‘) AS res
‘, ‘here: ‘) AS res
┌─res─────────────────┐
│ here: Hello, World! │
└─────────────────────┘
translate(s, from, to)
Данная функция заменяет символы в строке ‘s’ в соответствии с поэлементным отображением определяемым строками ‘from’ и ‘to’. ‘from’ и ‘to’ должны быть корректными константными ASCII строками одного размера. Не ASCII символы в оригинальной строке не изменяются.
Example:
SELECT translate('Hello, World!', 'delor', 'DELOR') AS res
┌─res───────────┐
│ HELLO, WORLD! │
└───────────────┘
translateUTF8(string, from, to)
Аналогично предыдущей функции, но работает со строками, состоящими из UTF-8 символов. ‘from’ и ‘to’ должны быть корректными константными UTF-8 строками одного размера.
Example:
SELECT translateUTF8('Hélló, Wórld¡', 'óé¡', 'oe!') AS res
┌─res───────────┐
│ Hello, World! │
└───────────────┘
Как заменить значения в столбце на заданные в PySpark
При работе со строками иногда приходится заменять одни строки столбца DataFrame на другие. Apache PySpark предлагает массу возможностей это сделать. В этой статье поговорим о том, как заменить строковые значения столбца с помощью регулярных выражений, как заменить определенные символы через функцию
Apache PySpark предлагает массу возможностей это сделать. В этой статье поговорим о том, как заменить строковые значения столбца с помощью регулярных выражений, как заменить определенные символы через функцию translate, а также как заменить значения одного столбца на значения другого через функцию overlay.
В качестве исходной таблице будет использовать DataFrame ниже. Также мы заранее импортировали функции PySpark SQL.
import pyspark.sql.functions as F
df = spark.createDataFrame([
('py', 'Anton'),
('c', 'Valentina'),
('py', 'Andry23'),
('cpp', 'Alex189'), ],
['lang', 'name']
)
Как заменить строковые значения в одном столбце в PySpark
Возможно вам понадобилось заменить или подправить некоторые строковые значения столбца. Тогда вы можете воспользоваться SQL-функцией regexp_replace, которая на основании регулярного выражения будет заменять соответствующие символы. Первым параметром функция
Первым параметром функция regexp_replace принимает имя столбца, вторым — регулярное выражение, третьим — на что заменяем.
Графовые алгоритмы в Apache Spark
Допустим требуется заменить все имена начинающиеся с An на On. Тогда код на Python для замены строки на основе регулярного выражения выглядит так:
df.withColumn('name', F.regexp_replace('name', 'An', 'Or'))
"""
+----+---------+
|lang| name|
+----+---------+
| py| Orton|
| c|Valentina|
| py| Ordry23|
| cpp| Alex189|
+----+---------+
"""
Или, например, нужно убрать цифры из имён. В нашем DataFrame две таких записи с цифрами, от которых мы хотим избавиться. Это сделать можно через диапазоны [0-9], вот так:
# Либо просто один столбец вернуть:
# df.select(F.regexp_replace('name', 'An', 'Or').alias('name'))
df. withColumn('name', F.regexp_replace('name', '[0-9]', ''))
"""
+----+---------+------+------+---+
|lang| name| city|salary|age|
+----+---------+------+------+---+
| py| Anton|Moscow| 23| 19|
| c|Valentina| Omsk| 27| 25|
| py| Andry|Moscow| 24| 22|
| cpp| Alex| Omsk| 32| 25|
+----+---------+------+------+---+
"""
withColumn('name', F.regexp_replace('name', '[0-9]', ''))
"""
+----+---------+------+------+---+
|lang| name| city|salary|age|
+----+---------+------+------+---+
| py| Anton|Moscow| 23| 19|
| c|Valentina| Omsk| 27| 25|
| py| Andry|Moscow| 24| 22|
| cpp| Alex| Omsk| 32| 25|
+----+---------+------+------+---+
"""
 withColumn('name', F.regexp_replace('name', '[0-9]', ''))
"""
+----+---------+------+------+---+
|lang| name| city|salary|age|
+----+---------+------+------+---+
| py| Anton|Moscow| 23| 19|
| c|Valentina| Omsk| 27| 25|
| py| Andry|Moscow| 24| 22|
| cpp| Alex| Omsk| 32| 25|
+----+---------+------+------+---+
"""
withColumn('name', F.regexp_replace('name', '[0-9]', ''))
"""
+----+---------+------+------+---+
|lang| name| city|salary|age|
+----+---------+------+------+---+
| py| Anton|Moscow| 23| 19|
| c|Valentina| Omsk| 27| 25|
| py| Andry|Moscow| 24| 22|
| cpp| Alex| Omsk| 32| 25|
+----+---------+------+------+---+
"""
Регулярные выражения — это очень полезный инструмент, о котором можно говорить долго. У нас даже есть небольшая статья, где вы можете ознакомиться с ними.
Как заменить один символ за другой в PySpark
Если вам нужно заменить только некоторые символы, то используйте функцию translate, которая должна работать быстрее, чем regexp_replace. Первый параметр — имя столбца, второй — последовательность символом для замены, третий — символы, на которые заменяем.
Например, следующий код в PySpark:
df.select(F.translate('name', 'Aer', '$!'). alias('name'))
 alias('name'))
alias('name'))
— заменит символ A на $, e на ! и r на пустой символ (т.е. просто удалит его).
""" +---------+ | name| +---------+ | $nton| |Val!ntina| | $ndy23| | $l!x189| +---------+ """
Как заменить значения одного столбца на значения другого
В PySpark 3.0 появилась функция overlay, которая заменяет строку одного столбца на заданные символы строки другого столбца. Первым параметром src задает столбец, куда происходит замена, второй replace — откуда (из какого столбца), третий pos — от какого индекса заменяемой строки производить замену, четвертый len — сколько символов нужно заменить.
Четвертый параметр по умолчанию равен -1, что значит заменить столько символов, сколько имеется во втором столбце, т.е. все. Рассмотрим примеры.
Выставим pos = 0:
df.withColumn('res', F.overlay('name', 'lang', 0))
"""
+----+---------+----------+
|lang| name| res|
+----+---------+----------+
| py| Anton| pynton|
| c|Valentina|cValentina|
| py| Andry23| pyndry23|
| cpp| Alex189| cppex189|
+----+---------+----------+
"""
Как видим, первый символ, т.е. символ с индексом 0, был заменен на строку из lang.
А вот при значении pos превышающем количество символов в src результат будет просто добавлен в конец:
df.withColumn('res', F.overlay('name', 'lang', 100).alias('res'))
"""
+----+---------+----------+
|lang| name| res|
+----+---------+----------+
| py| Anton| Antonpy|
| c|Valentina|Valentinac|
| py| Andry23| Andry23py|
| cpp| Alex189|Alex189cpp|
+----+---------+----------+
"""
Значение len определяет сколько символов нужно заменить. Например, следующий код на Python:
Например, следующий код на Python:
df.withColumn('res', F.overlay('name', 'lang', 3, 5).alias('res'))
"""
+----+---------+-----+
|lang| name| res|
+----+---------+-----+
| py| Anton| Anpy|
| c|Valentina|Vacna|
| py| Andry23| Anpy|
| cpp| Alex189|Alcpp|
+----+---------+-----+
"""
Заменяет строку, начиная с 3-го символа, на 5 символов из столбца replace. Если в столбце replace нет столько символов, то в заменяемой строке будут удалены столько, сколько не хватает. Например, в строке Valentina 5 символов, начиная с 3-ей, следующие: lenti — эти символы будут заменены на c.
Отметим также, что все эти функции могут быть использованы с методами фильтрации, о котором говорили тут. А еще больше подробностей о способах обработки строк в PySpark вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и IT-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
Записаться на курс
Смотреть раcписание
Источники
- regexp_replace
- translate
- overlay
Как заменить n-й символ в sql server
спросил
Изменено
сегодня
Просмотрено
72к раз
Я пытаюсь заменить n-й символ в SQL Server. Я пробовал использовать
Я пробовал использовать replace() :
SELECT REPLACE(ABC,0,1) FROM XXX
В приведенном выше коде все нули будут заменены единицами, но я хочу изменить их только в определенной позиции, и иногда эта позиция может меняться.
- sql
- sql-server
- sql-server-2008
использовать материал
Функция STUFF вставляет строку в другую строку. Он удаляет указанную длину символов в первой строке в начальной позиции, а затем вставляет вторую строку в первую строку в начальной позиции.
выберите МАТЕРИАЛ(ABC, start_index, 1, 'X') из XXX
«Здесь ваша позиция int для замены» — это позиция, которую нельзя просто заменить на любой int no, и эта позиция будет заменена
Примечание: (спасибо pcnate за предложение)
start_index — это ваша внутренняя позиция для замены.
1
Вы ищете МАТЕРИАЛ :
выберите МАТЕРИАЛ(ABC, @n, 1, 'X') из XXX
Это заменит @n -й символ на X .
Технически он ищет исходную строку в столбце ABC , начиная с позиции @n , удаляет 1 символ, затем вставляет строку 'X' в эту позицию.
Вы используете STUFF для этого:
SELECT STUFF(ABC, 5, 1, '1') ОТ ХХХ
Это заменит 5-й символ на 1.
Используйте stuff() :
select stuff(abc, 0, 1, 'a')
Документировано здесь.
1
Использовать вещи.
STUFF(Имя_столбца,начальный_индекс, lenth_ofthestring_to_replace_from_starting_index, character_to_replce)
Example_
DECLARE @str varchar(100) = '123456789' выберите @ул ВЫБЕРИТЕ МАТЕРИАЛ(@str,2,1, 'привет') -- хотите заменить 1 чартер, начиная со 2-й позиции, строкой «привет»
Проверьте это.
ВЫБЕРИТЕ МАТЕРИАЛ(@str,2,25, 'привет'),len(@str)
У меня была таблица со столбцом PartDesc , как показано ниже, где мне нужно удалить символы, начиная с индекса 1 до символа - .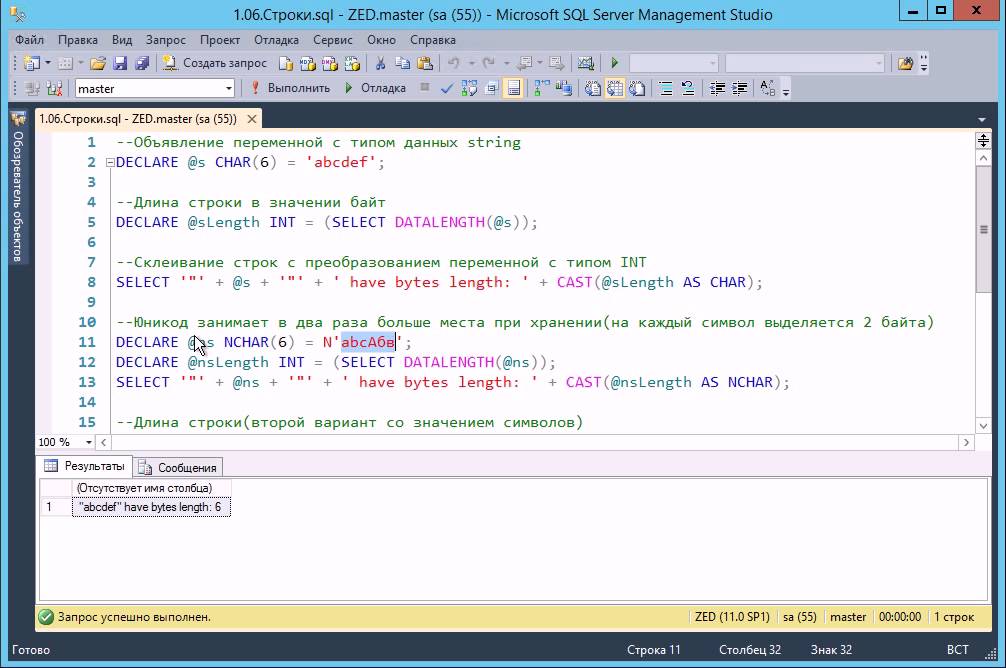
| PartDesc |
|---|
| OPERA_BLUE-ALTROZ DCA XZ 1.2 RTN BS6 |
| ATLAS_BLACK-NEXON XZ+ DK 1.2 RTN BS6 |
| DAYTONA_GREY-PUNCH ADV 1.2P BS6 MT RT |
| ARCADE_GREY-ALTROZ XZ+ 1.2 RTN BS6 |
| CALGARY_WHTE-NEXON XM(S) 1.2 RTN BS6 |
Здесь, после использования приведенного ниже запроса, я получил желаемый результат:
Выберите PATINDEX('%-%',PartDesc),Stuff(PartDesc,1,PATINDEX('%-%',PartDesc),' ' ),* из #temp
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Функции поиска и замены в строках
примечание
Функции поиска и других манипуляций со строками описаны отдельно.
replaceOne(haystack, pattern, replace)
Заменяет первое вхождение подстроки «pattern» (если она существует) в «haystack» строкой «replacement».
replaceAll(стог сена, шаблон, замена), replace(стог сена, шаблон, замена)
Заменяет все вхождения подстроки «шаблон» в «стог сена» строкой «замена».
Псевдоним: заменить .
replaceRegexpOne(haystack, pattern, replace)
Заменяет первое вхождение подстроки, соответствующей регулярному выражению ‘pattern’ в ‘haystack’, строкой ‘replacement’.
«шаблон» должен быть регулярным выражением re2.
«замена» должна быть простой строкой или строкой, содержащей замены \0-\9 .
Замены \1-\9 соответствуют группе захвата с 1-й по 9-ю (субсовпадение), замена \0 соответствует всему совпадению.
Чтобы использовать дословный символ \ в строке «шаблон» или «замена», экранируйте его, используя \ .
Также имейте в виду, что строковые литералы требуют дополнительного экранирования.
Пример 1. Преобразование дат ISO в американский формат:
SELECT DISTINCT
EventDate,
replaceRegexpOne(toString(EventDate), '(\\d{4})-(\\d{2})-(\\d {2})', '\\2/\\3/\\1') AS res
FROM test.hits
LIMIT 7
FORMAT TabSeparated
17.03.2014 17.03.2014
18.03.2014 18.03.2014
19.03.2014 19.03.2014
20.03.2014 20.03.2014
2014-03-2014 21.03.2014
2014-03-22 22.03.2014
2014-03-23 23.03.2014
Пример 2. Копирование строки десять раз:
SELECT replaceRegexpOne('Hello, World!' , '.*', '\\0\\0\\0\\0\\0\\0\\0\\0\\0\\0') AS res
┌─res─── ─диимобилил ─диимобилил ─────────────────────────┐
│ Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! Привет, Мир! │
└ackindyacbultyacsdupendy │
└acмобильный ─диимобилил ─диимобили Аналогично replaceRegexpOne, но заменяет все вхождения шаблона. Пример:SELECT replaceRegexpAll('Hello, World!', '.$,.,[,],?,*,+,{,:,-. Эта реализация немного отличается от re2::RE2::QuoteMeta. Он экранирует нулевой байт как\0вместо\x00и экранирует только необходимые символы. Для получения дополнительной информации см. ссылку: RE2translate(s, from, to)
Функция заменяет символы в строке 's' в соответствии со взаимно однозначным отображением символов, определяемым 'от' и 'к ' струны. «от» и «до» должны быть постоянными строками ASCII одинакового размера. Символы, отличные от ASCII, в исходной строке не изменяются.
Пример:
SELECT translate('Hello, World!', 'delor', 'DELOR') AS res
┌─res───────────┐
, WORLD HELLO! │
└───────────────┘
translateUTF8(string, from, to)
Аналогична предыдущей функции, но работает с аргументами UTF-8.
 ', '\\0\\0') AS res 9,
', '\\0\\0') AS res 9, 