Запрос select sql: SQL SELECT и запросы на выборку данных
Содержание
Сложные SQL-запросы
Сложные SQL-запросы
Пожалуйста, включите JavaScript в браузере!
Сложные SQL-запросы
С помощью строки поиска вы можете вручную создавать SQL-запросы любой сложности для фильтрации событий.
Чтобы сформировать SQL-запрос вручную:
- Перейдите в раздел События веб-интерфейса KUMA.
Откроется форма с полем ввода.
- Введите SQL-запрос в поле ввода.
- Нажмите на кнопку .
Отобразится таблица событий, соответствующих условиям вашего запроса. При необходимости вы можете отфильтровать события по периоду.
Поддерживаемые функции и операторы
SELECT– поля событий, которые следует возвращать.Для
SELECTв программе поддержаны следующие функции и операторы:- Функции агрегации:
count, avg, max, min, sum. - Арифметические операторы:
+, -, *, /, <, >, =, !=, >=, <=.Вы можете комбинировать эти функции и операторы.

Если вы используете в запросе функции агрегации, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
- Функции агрегации:
FROM– источник данных.При создании запроса в качестве источника данных вам нужно указать значение events.
WHERE– условия фильтрации событий.AND, OR, NOT, =, !=, >, >=, <, <=INBETWEENLIKEILIKEinSubnetmatch(в запросах используется синтаксис регулярных выражений re2)
GROUP BY– поля событий или псевдонимы, по которым следует группировать возвращаемые данные.Если вы используете в запросе группировку данных, настройка отображения таблицы событий, сортировка событий по возрастанию и убыванию, получение статистики, а также ретроспективная проверка недоступны.
ORDER BY– столбцы, по которым следует сортировать возвращаемые данные.Возможные значения:
DESC– по убыванию.ASC– по возрастанию.
OFFSET– пропуск указанного количества строк перед выводом результатов запроса.LIMIT– количество отображаемых в таблице строк.Значение по умолчанию – 250.
Если при фильтрации событий по пользовательскому периоду количество строк в результатах поиска превышает заданное значение, вы можете отобразить в таблице дополнительные строки, нажав на кнопку Показать больше записей. Кнопка не отображается при фильтрации событий по стандартному периоду.
Примеры запросов:
SELECT * FROM `events` WHERE Type IN ('Base', 'Audit') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events с типом Base и Audit, отсортированные по столбцу Timestamp в порядке убывания.
Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE BytesIn BETWEEN 1000 AND 2000 ORDER BY Timestamp ASC LIMIT 250Все события таблицы events, для которых в поле BytesIn значение полученного трафика находится в диапазоне от 1000 до 2000 байт, отсортированные по столбцу Timestamp в порядке возрастания. Количество отображаемых в таблице строк – 250.
SELECT * FROM `events` WHERE Message LIKE '%ssh:%' ORDER BY Timestamp DESC LIMIT 250Все события таблицы events, которые в поле Message содержат данные, соответствующие заданному шаблону
%ssh:%в нижнем регистре, и отсортированы по столбцу Timestamp в порядке убывания. Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE inSubnet(DeviceAddress, '10.0.0.1/24') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events для хостов, которые входят в подсеть 10.0.0.1/24, отсортированные по столбцу Timestamp в порядке убывания.
Количество отображаемых в таблице строк – 250.SELECT * FROM `events` WHERE match(Message, 'ssh.*') ORDER BY Timestamp DESC LIMIT 250Все события таблицы events, которые в поле Message содержат текст, соответствующий шаблону
ssh.*, и отсортированы по столбцу Timestamp в порядке убывания. Количество отображаемых в таблице строк – 250.SELECT max(BytesOut) / 1024 FROM `events`Максимальный размер исходящего трафика (КБ) за выбранный период времени.
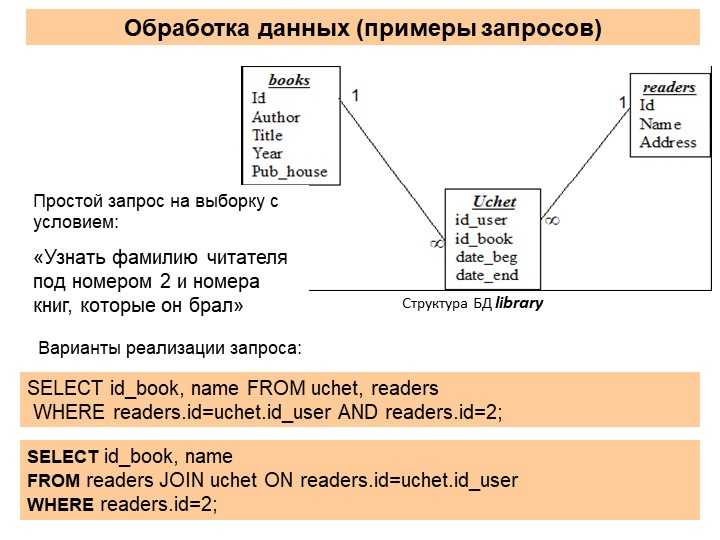
SELECT count(ID) AS "Count", SourcePort AS "Port" FROM `events` GROUP BY SourcePort ORDER BY Port ASC LIMIT 250Количество событий и номер порта. События сгруппированы по номеру порта и отсортированы по столбцу Port в порядке возрастания. Количество отображаемых в таблице строк – 250.
Столбцу ID в таблице событий присвоено имя Count, столбцу SourcePort присвоено имя Port.

 Количество отображаемых в таблице строк – 250.
Количество отображаемых в таблице строк – 250. Количество отображаемых в таблице строк – 250.
Количество отображаемых в таблице строк – 250.Если вы хотите указать в запросе специальный символ, вам требуется экранировать его, поместив перед ним обратную косую черту (\).
Пример:
Все события таблицы events, которые в поле Message содержат текст, соответствующий шаблону
|
При переключении на конструктор параметры запроса, введенного вручную в строке поиска, не переносятся в конструктор: вам требуется создать запрос заново. При этом запрос, созданный в конструкторе, не перезаписывает запрос, введенный в строке поиска, пока вы не нажмете на кнопку Применить в окне конструктора.
После обновления KUMA до версии 1.6 при фильтрации событий с помощью SQL-запроса, содержащего условие inSubnet, может возвращаться ошибка Code: 441. DB::Exception: Invalid IPv4 value. В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config.d/users.xml в разделе profiles → default добавить директиву
В таких случаях необходимо на серверах хранилища (на каждой машине кластера ClickHouse) в файле /opt/kaspersky/kuma/clickhouse/cfg/config.d/users.xml в разделе profiles → default добавить директиву <cast_ipv4_ipv6_default_on_conversion_error>true</cast_ipv4_ipv6_default_on_conversion_error>.
Подробнее об SQL см. в справке ClickHouse.
В начало
SQL Query for SQL Server
EMS SQL Query for SQL Server — это программа для быстрого и простого построения SQL запросов к базам данных SQL Server. В программе существует возможность как визуального создания запросов к SQL Server, так и использования многофункционального редактора SQL кода для написания текста запроса вручную.
Простой и удобный графический интерфейс позволяет подключаться к базам данных SQL Server, выбирать таблицы и поля для запроса к серверу SQL Server, устанавливать критерии отбора и многое другое.
Программа позволяет работать с несколькими запросами одновременно, редактировать текст запроса во многофункциональном редакторе SQL, просматривать результаты выполнения в различных режимах, визуально создавать запросы SQL Server с объединениями и подзапросами, строить основанные на запросах диаграммы, просматривать план выполнения запросов SQL Server и выполнять другие операции необходимые для работы с запросами к базам данных SQL Server.
Ключевые особенности
- Современный графический интерфейс пользователя
- Поддержка новейших версий SQL Server
- Визуальный выбор таблиц и полей для запроса путем их перетаскивания
- Работа с несколькими запросами в отдельных окнах
- Возможность регистрации баз данных для работы только с выбранными базами
- Соединение с несколькими базами данных одновременно
- История недавно написанных запросов
- Подсветка синтаксиса, возможность «быстрого кода» и клавиатурные шаблоны для ускоренного редактирования текста запросов
- Инструменты для группировки и фильтрования данных
- Возможность визуально создавать запросы с объединениями и подзапросами
- Возможность создания диаграмм на основе запросов
- Возможность представления планов запросов
- Поддержка UNICODE данных
- Асинхронное выполнение запросов
- Мощный редактор BLOB–полей с несколькими видами представления BLOB-данных
- Гибкая система настройки интерфейса пользователя
- Многоязыковая поддержка пользовательского интерфейса
При покупке Вы получите также:
- БЕСПЛАТНАЯ подписка на 1 год Сопровождения!
- БЕСПЛАТНЫЕ Минорные и Мажорные обновления в период действия Обслуживания!
- БЕСПЛАТНАЯ неограниченная техническая поддержка в период действия Сопровождения!
- Разумные расценки на продление Сопровождения – всего от 35% в год!
- Скидки при покупке двух и более лицензий одного продукта
- Скидки на покупку сопутствующих продуктов
- Гарантия возврата денег в течение 30 дней
Скриншоты продукта
Визуальный конструктор запросов — установка критериев запроса
Визуальный конструктор запросов — сортировка исходных полей
Фильтрование данных
Группировка данных
Просмотр истории запросов
Работа с избранными запросами
SQL Query for SQL Server
Начните работу с SQL Query for SQL Server
Скачайте полнофункциональную 30-дневную бесплатную пробную версию и уже сегодня начните экономить время при управлении базами данных.
Скачать бесплатную пробную версию
Есть вопросы?
Если вам требуется какая-либо помощь, если у вас есть вопросы по нашим продуктам или по вариантам приобретения, просто свяжитесь с нами.
- Система Support Ticket
- [email protected]
- Общие вопросы
Сопутствующие продукты
Data Generator for SQL Server
Генерируйте тестовые данные в базы данных SQL Server для проверки ее работоспособности
Скачать
Подробнее
SQL Manager for SQL server
Упростите и автоматизируйте процесс разработки баз данных SQL Server
Скачать
Подробнее
SQL Management Studio for SQL Server
Комплексное решение для администрирования и разработки баз данных SQL Server
Скачать
Подробнее
Анатомия оператора Select
Реляционные базы данных важны не только из-за информации, которую они хранят, но, что более важно, из-за данных, которые мы извлекаем из них. Оператор select позволяет нам задать базе данных вопрос. Это то, как мы извлекаем информацию из системы баз данных.
Оператор select позволяет нам задать базе данных вопрос. Это то, как мы извлекаем информацию из системы баз данных.
Существует два стандарта, регулирующих SQL (язык структурированных запросов) — ANSI (Американский национальный институт стандартов) и ISO (Международная организация по стандартизации). Microsoft SQL Server поддерживает оба эти стандарта. Как и другие продукты баз данных, Microsoft SQL Server имеет собственный диалект SQL. Этот диалект для SQL Server называется T-SQL или Transact-SQL.
Основы оператора select одинаковы для разных баз данных. Однако некоторые параметры заявления варьируются от продукта к продукту. Мы специально рассмотрим оператор select SQL Server, хотя он практически идентичен другим операторам select.
SQL Server — одна из многих систем реляционных баз данных. Реляционные базы данных хранят информацию в наборе таблиц (строк и столбцов), которые «связаны» друг с другом.
Допустим, у нас есть база данных клиентов. Эта база данных имеет несколько различных подтем — или объектов, таких как клиент, заказ, поставщик, продукт и сотрудник.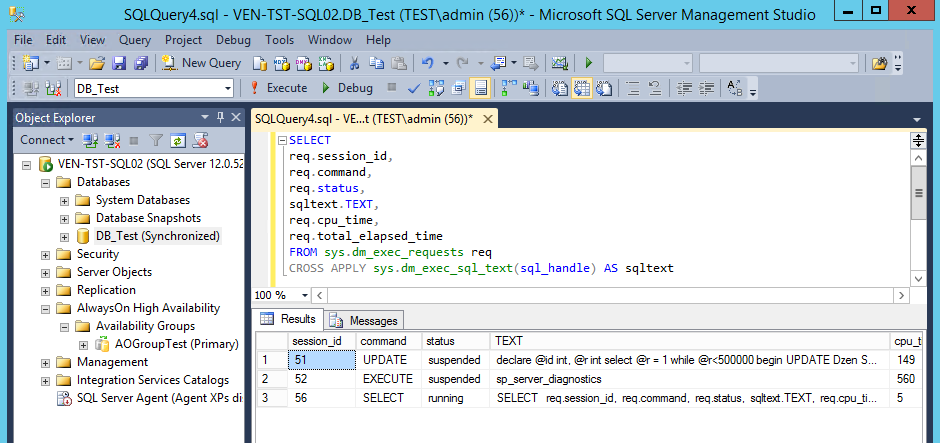 Сущности могут быть переведены в тему таблицы. Мы будем работать только с одной таблицей, чтобы наши примеры были очень простыми.
Сущности могут быть переведены в тему таблицы. Мы будем работать только с одной таблицей, чтобы наши примеры были очень простыми.
Our table has the following structure and records (rows):
CUSTOMER
| CustomerID | LastName | FirstName | Address | Город | Штат | Почтовый индекс | |||||
100026 | Susan | 101 Main Street | Cary | NC | 27513 | ||||||
| 1001 | Johnson | JoAnne | 5402 Loop 1 | Austin | TX | 78752 | |||||
| 1002 | Smith | RON | 2201 THOMAS DR | 2201 THOMAS DR | 2201 THOMAS DR | 2201 THOMAS DR | 2201 DR | 2201 DR | 0023 Panama City | FL | 32401 |
| 1003 | Baker | Pete | 2408 NW 119th | Oklahoma City | OK | 73120 | |||||
| 1004 | Smith | Билл | 4407 12th Avenue | Austin | TX | 787469969 | TX | 787469696996969946 | TX | 78746 0026 |
Начнем с обсуждения частей оператора select. Тогда мы будем выбирать информацию только из одной таблицы.
Тогда мы будем выбирать информацию только из одной таблицы.
Оператор select состоит из нескольких предложений. Это:
SELECT
FROM
WHERE
GROUP BY
ORDER BY
HAVING
Каждое из этих предложений содержит информацию, которая следует за ним. Это:
SELECT столбцы
FROM таблица/представление
WHERE условие/выражение
GROUP BY столбец (столбцы)
ORDER BY столбец (столбцы)
HAVING агрегатная функция и условие/выражение
В операторе выбора требуются только два предложения: SELECT и FROM.
Предложение SELECT указывает, какие столбцы мы хотим получить, а предложение FROM определяет имя используемой таблицы. У нас может быть что-то вроде этого:
Выберите фамилию, имя
от клиента
Это дает нам вывод:
| LastName | FirstName |
| Adams | Susan |
| Johnson | JoAnne |
| Smith | Рон |
| Бейкер | Пит |
| Смит | Билл0026 |
Обратите внимание, что заголовки над данными столбца не являются заглавными, как в таблице. Это потому, что в моем запросе они были указаны в нижнем регистре. Наш оператор select указывает именно то, что мы хотим видеть на выходе.
Это потому, что в моем запросе они были указаны в нижнем регистре. Наш оператор select указывает именно то, что мы хотим видеть на выходе.
Теперь рассмотрим необязательные пункты.
WHERE
Предложение WHERE является фильтром для результатов запроса и использует условие или выражение. Мы используем предложение WHERE, чтобы указать наш запрос только для определенных строк.
Если я хочу получить только тех людей с фамилией Смит, я могу добавить предложение WHERE.
Select lastname, firstname
from customer
where lastname = ‘Smith’
This gives us the output:
| CustomerID | LastName | FirstName | Адрес | Город | State | Zip | |
| 1002 | Smith | Ron | 2201 Thomas Dr | Panama City | FL | 32401 | |
| 1004 | Smith | Билл | 4407 12th Avenue | Austin | TX | TX | 78746 |
GROUP BY
Целью предложения GROUP BY является группировка или кластеризация записей на основе столбца или списка столбцов. В нашем примере я также использую агрегатную функцию, которая подсчитывает количество строк, определяющих наши критерии. Я также создал псевдоним для заголовка столбца с функцией.
В нашем примере я также использую агрегатную функцию, которая подсчитывает количество строк, определяющих наши критерии. Я также создал псевдоним для заголовка столбца с функцией.
Выберите штат, количество (штат) как «Количество клиентов по штатам»
из группы клиентов
по штатам
This gives us the output:
| State | Count of Customers by State |
| FL | 1 |
| NC | 1 |
| OK | 1 |
| TX | 2 |
HAVING
Предложение HAVING работает в сочетании с предложением GROUP BY. Это очень похоже на предложение WHERE, поскольку работает как фильтр. Однако он работает как фильтр в группе агрегатов.
Однако он работает как фильтр в группе агрегатов.
Выберите состояние, подсчитайте (состояние) как «Количество клиентов больше 1»
от клиента
группируйте по состоянию
имея количество (состояние)> 1
Это дает нам вывод:
| Count of Customers Greater Than 1 | |
| TX | 2 |
ORDER BY
The ORDER BY clause indicates the sort order for the query results .
Если я хочу расположить результаты в алфавитном порядке по фамилии, я могу добавить предложение ORDER BY.
Выбрать фамилию, имя
от клиента
заказать по фамилии
This gives us the output:
| LastName | FirstName |
| Adams | Susan |
| Baker | Pete |
| Джонсон | Джоанн |
| Смит | |
| Смит | Билл |
Обратите внимание, что Рон Смит стоит перед Биллом Смитом в нашем примере, хотя «Билл» стоит перед «Роном» в алфавитном порядке. Это потому, что я не заказывала по имени, только по фамилии. Чтобы исправить это, я могу сделать следующее.
Это потому, что я не заказывала по имени, только по фамилии. Чтобы исправить это, я могу сделать следующее.
Выбрать фамилию, имя
от клиента
заказать по фамилии, имени
Это дает нам вывод:
| LastName | FirstName |
| Adams | Susan |
| Baker | Pete |
| Johnson | JoAnne |
| Смит | Билл |
| Смит | Рон |
Мы увидели основы выбора данных из одной таблицы. Ищите часть II, где мы рассмотрим запросы из нескольких таблиц.
Связанные курсы
Запись запросов с использованием Microsoft SQL Server 2008 Transact-SQL
SQL Server 2008 R2 для администрирования
Проектирование и реализация SQL Server 2008 R2. Язык SQL используется на многих платформах реляционных баз данных. Грег Ларсен объясняет основы инструкции SELECT для SQL Server.
Язык SQL используется на многих платформах реляционных баз данных. Грег Ларсен объясняет основы инструкции SELECT для SQL Server.
Оператор SELECT является наиболее часто используемым оператором языка T-SQL. Он выполняется для извлечения столбцов данных из одной или нескольких таблиц. Оператор SELECT может ограничивать возвращаемые данные с помощью предложений WHERE или HAVING , а также сортировать или группировать результаты с помощью предложений ORDER BY и GROUP BY соответственно. Оператор SELECT также может состоять из множества различных операторов SELECT 9.0708 операторов, обычно называемых подзапросами.
Существует множество различных аспектов оператора SELECT , что делает его очень сложным оператором T-SQL. Эта статья является первой в серии статей, посвященных различным нюансам инструкции SELECT . В этой статье я расскажу только об основах оператора SELECT .
Оператор SELECT
Оператор SELECT состоит из множества различных частей, что делает его многогранным. Основные положения, поддерживаемые 9Оператор 0707 SELECT , найденный в документации Microsoft, показан на рисунке 1.
Рисунок 1: Основные предложения оператора SELECT
Оператор SELECT поддерживает множество различных параметров. Для обсуждения каждого из этих различных вариантов потребовалась бы очень длинная статья. Для целей этой статьи я сосредоточусь только на нескольких предложениях, которые я представляю как базовый синтаксис оператора SELECT , показанный на рис. 2.
Рисунок 2. Базовый оператор SELECT
Базовый оператор SELECT состоит из трех частей: списка выбора, предложения FROM и предложения WHERE .
Список SELECT
Компонент select_list определяет данные, которые будут возвращены при выполнении оператора SELECT . Это единственная часть, которая требуется в каждом операторе
Это единственная часть, которая требуется в каждом операторе SELECT . Все остальные атрибуты 9Оператор 0707 SELECT является опцией.
select_list определяет один или несколько элементов данных, которые будут возвращены при выполнении инструкции SELECT . Если в списке указано несколько элементов, каждый элемент отделяется запятой. Аргументы списка выбора могут принимать различные формы, такие как имя столбца, вычисление, вызов функции или литеральная константа, и это лишь некоторые из них.
Формат select_list , найденный в документации по предложению SELECT, показан на рис. 3.
Рисунок 3: Спецификации Select_list
В листинге 1 приведен пример оператора SELECT , который содержит только список выбора. В списке есть два разных столбца данных, которые будут возвращены.
Листинг 1. Возврат вычисляемого поля и литерального значения
ИСПОЛЬЗОВАТЬ базу данных tempdb; GO SELECT 1024*1024, ‘Основной оператор выбора’; |
В отчете 1 показаны значения двух столбцов, возвращенные при выполнении листинга 1.
Отчет 1: столбцы, возвращенные при выполнении листинга 1
Первый возвращенный столбец является результатом вычисления, умножающего 1024 на 1024. Второй отображаемый столбец — это просто литеральная строка The Basic Select Statement . Возвращенным столбцам не были присвоены имена столбцов, поэтому имена столбцов говорят (нет имени столбца).
Отсутствие имени столбца для некоторых столбцов в результирующем наборе на самом деле не является проблемой, если только вам не нужно ссылаться на возвращаемые данные по имени. Чтобы присвоить имена этим двум столбцам, можно использовать псевдоним столбца.
Назначение псевдонимов столбцов
Псевдоним столбца полезен, когда вы хотите присвоить определенное имя столбцу данных, возвращаемому оператором SELECT . Если вы обратитесь к спецификациям select_list , приведенным на рис. 3, есть два способа определить псевдоним столбца. Один из способов — использовать Ключевое слово AS , за которым следует имя псевдонима столбца.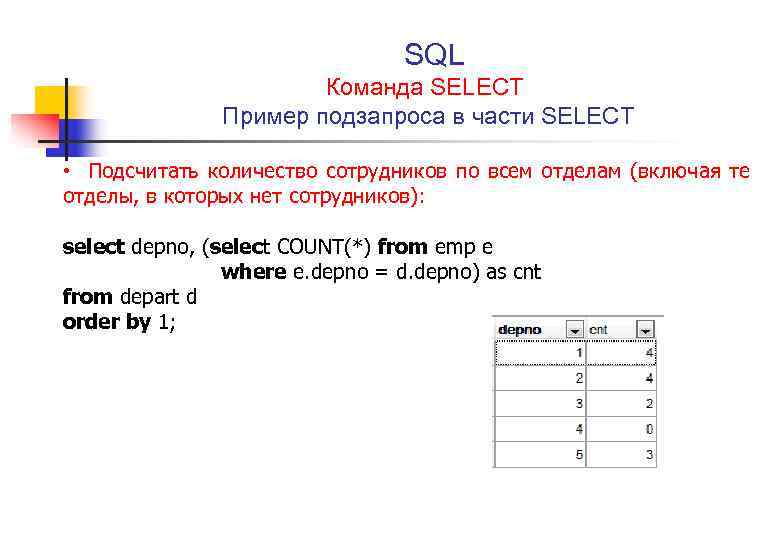 Ключевое слово
Ключевое слово AS является необязательным. Другой способ — использовать оператор равенства ( = ), где псевдоним определяется слева от знака = . Оператор SELECT в листинге 2 возвращает те же данные, что и в листинге 1, но каждому элементу, идентифицированному в списке выбора, теперь присвоен псевдоним столбца.
Листинг 2: Определение псевдонимов столбцов
ИСПОЛЬЗОВАТЬ базу данных tempdb; GO SELECT 1024*1024 AS NumOfBytesInMB, ‘Основной оператор выбора’ BasicSelectStatement; |
При выполнении листинга 2 каждому возвращаемому столбцу будет назначен псевдоним столбца, как показано в отчете 2.
отчет 2: результаты выполнения листинга 2 не содержат пробелов в имени. Если вы хотите включить пробелы в псевдоним, то имя должно быть заключено в кавычки. Кавычки могут быть как набором квадратных скобок, так и одинарными или двойными кавычками.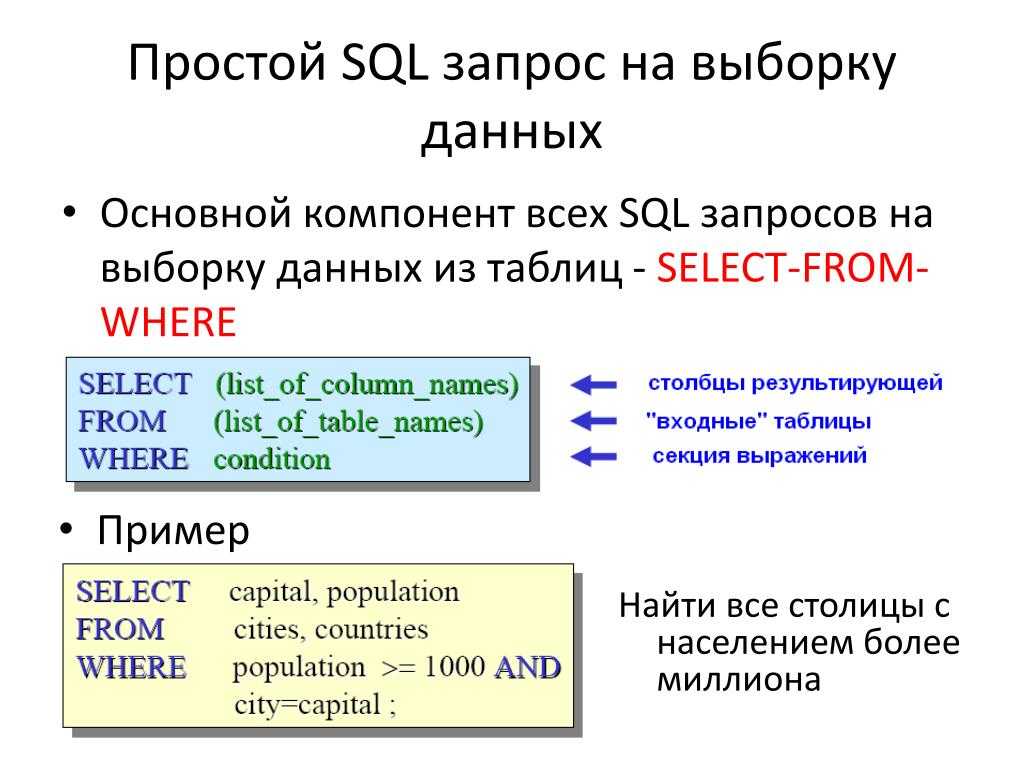 В листинге 3 показано, как использовать различные варианты цитирования.
В листинге 3 показано, как использовать различные варианты цитирования.
Листинг 3. Создание псевдонимов с пробелами
1 2 3 4 5 6 | ИСПОЛЬЗОВАТЬ базу данных tempdb; GO SET QUOTED_IDENTIFIER ON SELECT 1024*1024 AS [Число байтов в МБ], «Использование двойных кавычек» = ‘Основной оператор выбора’, String ABC’ AS’ ‘ABC |
Вывод в отчете 3 создается при выполнении листинга 3.
Отчет 3: Псевдонимы с пробелами в имени
Предложение FROM
Предложение FROM в SQL Server используется для идентификации таблицы или таблиц, в которых необходимо получить данные. В этой базовой статье SELECT я буду обсуждать только получение данных из одной таблицы SQL Server. В следующих статьях речь пойдет об извлечении данных из нескольких таблиц.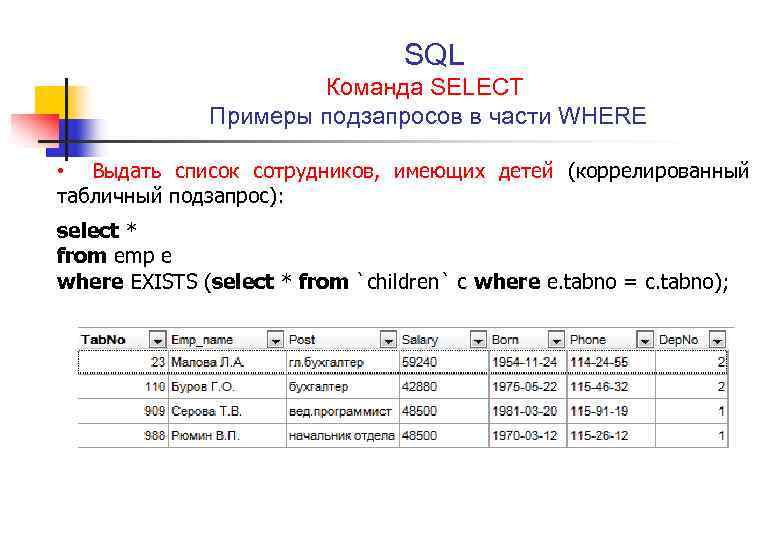
Таблица в SQL Server хранится в базе данных. У данного экземпляра SQL Server может быть много баз данных, и в базе данных может быть много таблиц. Таблицы в базе данных сгруппированы и организованы по схеме. Иерархия баз данных, схем и таблиц означает, что в экземпляре SQL Server может быть несколько таблиц с одинаковыми именами. Поскольку заданное имя таблицы может находиться в различных схемах, базах данных или даже экземплярах, используемое имя таблицы должно быть однозначно идентифицировано в ОТ ст. Чтобы уникально идентифицировать таблицу в предложении FROM , ее можно назвать, используя имя из одной, двух, трех или четырех частей, где каждая часть отделяется точкой ( . ).
Имя таблицы, состоящее из одной части, — это имя таблицы, которое не содержит точки, например Заказы или Клиенты. Если в предложении FROM используется однокомпонентное имя, ядро базы данных должно определить, какой схеме принадлежит таблица.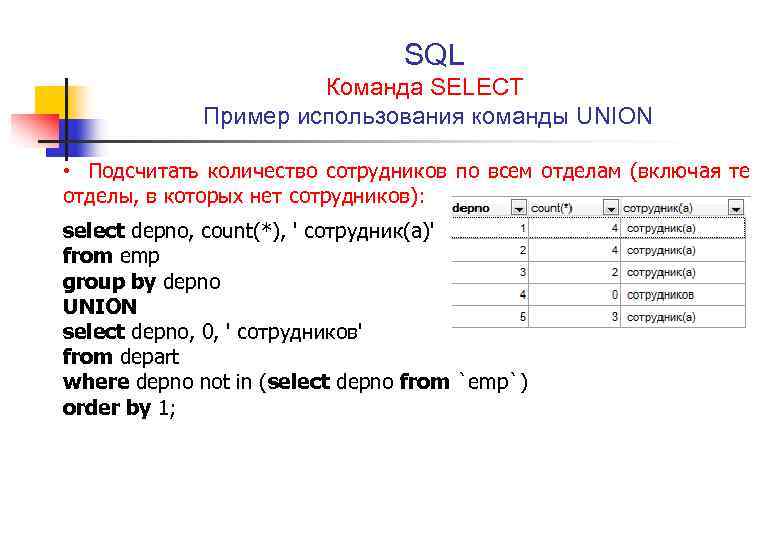 Чтобы определить схему, которой принадлежит однокомпонентное имя таблицы, SQL Server использует двухэтапный процесс. Первый шаг — посмотреть, находится ли таблица в схеме по умолчанию, связанной с пользователем, отправившим
Чтобы определить схему, которой принадлежит однокомпонентное имя таблицы, SQL Server использует двухэтапный процесс. Первый шаг — посмотреть, находится ли таблица в схеме по умолчанию, связанной с пользователем, отправившим Оператор SELECT . Если таблица находится в схеме по умолчанию для пользователя, то используется эта таблица, и механизму базы данных не нужно выполнять второй шаг. Если таблица не найдена в схеме пользователя по умолчанию, то выполняется второй шаг идентификации таблицы. Второй шаг просматривает схему dbo , чтобы попытаться найти таблицу. Когда база данных содержит только одну схему с именем dbo, имеет смысл использовать имена, состоящие из одной части. Однако при наличии нескольких схем в базе данных лучше всего использовать несколько имен таблиц частей, чтобы уточнить, какая таблица используется. Это упрощает объем работы, которую SQL Server должен выполнить для идентификации таблицы.
Имя, состоящее из двух частей, состоит из имени таблицы и схемы, содержащей таблицу с точкой ( . ) между ними, например Sales.Orders, или Sales.Customer. При написании инструкций 
SELECT , которые запрашивают данные только из таблиц в одной базе данных с несколькими схемами, рекомендуется использовать имена таблиц, состоящие из двух частей.
В большинстве случаев, когда оператор SELECT использует таблицы в одной базе данных, используются одно- и двухкомпонентные имена таблиц. Имена таблиц, состоящие из трех частей, необходимы, когда код запускается в контексте одной базы данных и ему необходимо получить данные из другой базы данных или вы объединяете данные из нескольких таблиц, находящихся в разных базах данных. Третья часть имени предшествует имени таблицы, состоящему из двух частей, и идентифицирует базу данных, в которой находится таблица, например 9.0794 AdventureWorks2019.Продажи.Заказы.
Последний способ однозначно идентифицировать таблицу в предложении FROM — включить имя экземпляра в качестве четвертой части.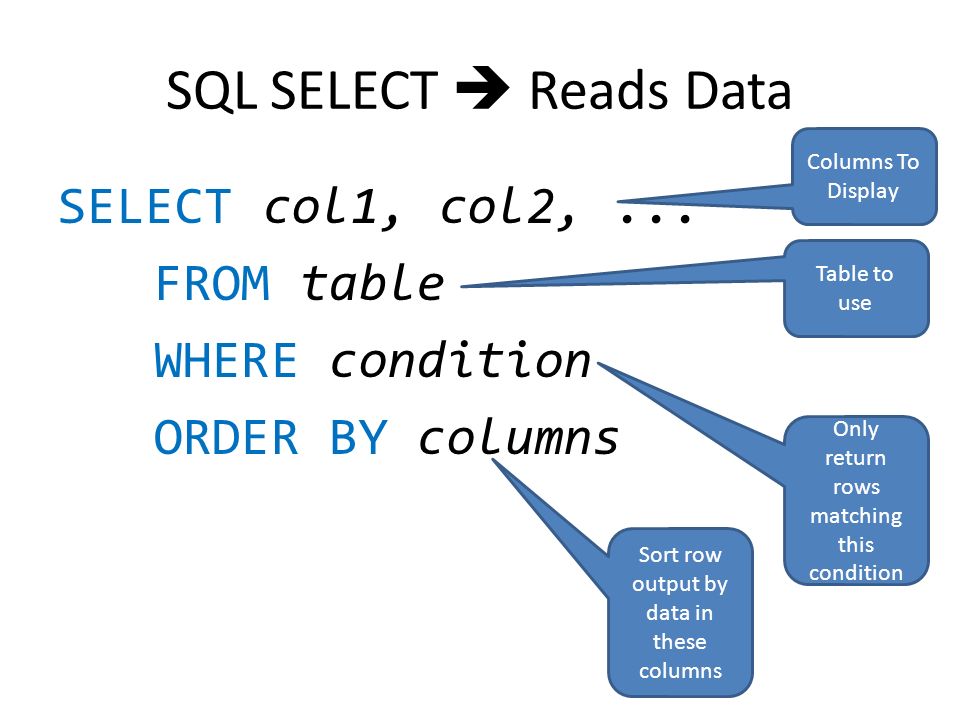 Имя экземпляра помещается перед полным именем таблицы, состоящим из трех частей. Имена из четырех частей используются для запросов между экземплярами с использованием связанного сервера. Обсуждение связанных серверов — это совершенно отдельная тема, которую я оставлю для будущей статьи.
Имя экземпляра помещается перед полным именем таблицы, состоящим из трех частей. Имена из четырех частей используются для запросов между экземплярами с использованием связанного сервера. Обсуждение связанных серверов — это совершенно отдельная тема, которую я оставлю для будущей статьи.
Пример оператора SELECT в листинге 4 выполняется в контексте 9База данных 0794 AdventureWorks2019 , использующая имя таблицы, состоящее из двух частей, для возврата всех данных в таблице Territory , принадлежащей схеме Sales .
Листинг 4. Использование имени таблицы из двух частей
ИСПОЛЬЗОВАТЬ AdventureWorks2019; GO SELECT * FROM Sales.SalesTerritory; |
Оператор в листинге 5 использует имя таблицы, состоящее из трех частей, для возврата всех данных из Territory в схеме Sales в базе данных AdventureWorks2019 , но выполняется в контексте базы данных tempdb .
Листинг 5. Использование имени таблицы из трех частей
USE tempdb GO SELECT * FROM AdventureWorks2019.Sales.SalesTerritory; |
Строки, отображаемые в отчете 4, создаются при выполнении кода из листинга 4 или листинга 5.
Отчет 4: вывод при выполнении листинга 4 или 5
В листинге 4 и листинге 5 для параметра select_list использовался подстановочный знак * . Код * указывает SQL Server, что все столбцы из таблицы AdventureWorks2019.Sales.SalesTerritory должны быть возвращены в соответствии с их порядковыми позициями в таблице. Использование подстановочного знака * в списке выбора — это простой способ указать и выбрать все столбцы в таблице. Я бы не рекомендовал использовать подстановочные знаки для производственного кода, потому что, если столбцы добавляются или удаляются из запрашиваемой таблицы, количество возвращаемых столбцов будет основано на определении таблицы во время запроса. Лучше всего не использовать подстановочные знаки, а вместо этого специально указывать имена столбцов для данных, которые необходимо вернуть. Обратите внимание, что в некоторых ситуациях подстановочные знаки имеют смысл, и я расскажу о них в следующих статьях.
Лучше всего не использовать подстановочные знаки, а вместо этого специально указывать имена столбцов для данных, которые необходимо вернуть. Обратите внимание, что в некоторых ситуациях подстановочные знаки имеют смысл, и я расскажу о них в следующих статьях. Оператор SELECT в листинге 6 возвращает те же результаты, что и в листингах 4 и 5, но указывает фактические имена столбцов в кавычках вместо подстановочного знака * .
Листинг 6. Указание имен столбцов
1 2 3 4 5 6 7 8 10 11 0003 12 13 | ЕГЭ AdventureWorks2019; GO SELECT [TerritoryId], [имя], [CountryRegionCode], [группа], [Salesytd], [Saleslastyear], [CostyTD], ], [rowguid], [ModifiedDate] FROM Sales. |
 SalesTerritory;
SalesTerritory;Предложение WHERE
Показанные мной примеры операторов SELECT возвращают все строки в AdventurewWorks2019.Sales.SalesTerritory таблица. Могут быть случаи, когда вы не хотите возвращать все строки в таблице, а хотите вернуть только подмножество строк. В этом случае можно использовать предложение WHERE для ограничения возвращаемых строк.
При использовании предложения WHERE необходимо указать критерии поиска. Критерии поиска определяют одно или несколько выражений, известных как предикаты, которым должна соответствовать каждая строка, чтобы быть выбранной. Логические операторы И , ИЛИ и НЕ можно использовать для объединения нескольких выражений для точной настройки возвращаемых строк.
В листинге 7 есть оператор SELECT , который содержит одно выражение в предложении WHERE . В этом случае будут возвращены только те записи Sales. SalesTerritory , значение SalesLastYear которых превышает 3 000 000.
SalesTerritory , значение SalesLastYear которых превышает 3 000 000.
Листинг 7. Простое условие поиска в операторе WHERE
ИСПОЛЬЗОВАТЬ AdventureWorks2019; GO SELECT * FROM Sales.SalesTerritory ГДЕ SalesLastYear > 3000000; |
При выполнении кода в листинге 6 возвращаются строки в отчете 5.
Отчет 5: строки, возвращаемые при выполнении листинга 7
Иногда для получения определенного подмножества строк требуются более сложные условия поиска. Оператор SELECT в листинге 8 использует два разных условия в предложении WHERE , чтобы сузить возвращаемые строки. Два разных условия используют логический оператор И для создания сложного составного условия поиска.
Листинг 8. Использование двух выражений с оператором И
ИСПОЛЬЗОВАТЬ AdventureWorks2019; GO SELECT * FROM Sales. |
