
|
|
|
|
 Far Far |
| WinNavigator |
| Frigate |
| Norton
Commander |
| WinNC |
| Dos
Navigator |
| Servant
Salamander |
| Turbo
Browser |
|
|
| Winamp,
Skins, Plugins |
| Необходимые
Утилиты |
| Текстовые
редакторы |
| Юмор |
|
|

|
File managers and best utilites |
Как мы контролируем качество кода в Браузере для Android. Лекция Яндекса. Браузер яндекс хабрахабр
Как мы контролируем качество кода в Браузере для Android. Лекция Яндекса
Сегодня я расскажу, как мы в браузере обеспечиваем хороший код. Браузер для Android — довольно громоздкая штука. В принципе, ядро в браузере — ядро Chromium, вокруг которого стоит core сервисов Яндекса, все это написано в основном на С++, и вокруг этих двух ядер, вложенных друг в друга, написаны платформенные приложения. Яндекс.Браузер есть на Windows, Mac, Linux, Android и на iOS. В основном я буду рассказывать про код для Android, а конкретно про Java и Kotlin.
 В Яндексе 200 мобильных разработчиков, но в одном Браузере — с десктопом и всем остальным — тоже 200 человек. Около 30 человек из них пишет под Android. Народу много, и мы написали большое количество кода. По количеству строк мы самые большие в Яндексе. И естественным образом, как и в любом живом организме, в нашем проекте код рождается, живет, стареет, за ним нужно следить и обеспечивать его хорошее самочувствие.
В Яндексе 200 мобильных разработчиков, но в одном Браузере — с десктопом и всем остальным — тоже 200 человек. Около 30 человек из них пишет под Android. Народу много, и мы написали большое количество кода. По количеству строк мы самые большие в Яндексе. И естественным образом, как и в любом живом организме, в нашем проекте код рождается, живет, стареет, за ним нужно следить и обеспечивать его хорошее самочувствие.
Расскажу последовательно о том, какие мы применили процессы, чтобы обеспечить качество кода, и какие мы используем инструменты. У любого бага, который возникает, есть несколько моментов, когда его можно решить. Можно баг просто не сделать. Можно баг решить, когда он в открытом окошке редактора у разработчика. Можно найти его на юнит-тестах. Можно найти его позже в тестировании или в продакшене.
 Мы постарались выстроить свои процессы так, чтобы на всех этих этапах максимальное количество багов отлавливалось или не возникало вовсе. В первую очередь, мы в браузере записали наш codestyle. В большом проекте реально очень важно, чтобы был писаный codestyle, который актуален, поддерживается, и мы его разместили как codestyle MD в нашем репозитории. Чтобы его отредактировать, нужно сделать pull request, чтобы как обычный код его поревьювили, полайкали, команда согласилась, и после этого все соглашаются с этими правилами. Либо мы обсуждаем и вносим новые изменения.
Мы постарались выстроить свои процессы так, чтобы на всех этих этапах максимальное количество багов отлавливалось или не возникало вовсе. В первую очередь, мы в браузере записали наш codestyle. В большом проекте реально очень важно, чтобы был писаный codestyle, который актуален, поддерживается, и мы его разместили как codestyle MD в нашем репозитории. Чтобы его отредактировать, нужно сделать pull request, чтобы как обычный код его поревьювили, полайкали, команда согласилась, и после этого все соглашаются с этими правилами. Либо мы обсуждаем и вносим новые изменения.
Codestyle кроме того, что фиксирует общее для всей команды правило, еще и носит образовательную функцию. У нас большая команда, мы очень много людей новеньких к себе приглашаем. Новички в первую очередь читают Вики, у нас очень много описаний, мы любим Вики. И читают codestyle. Там есть примеры того, как нужно делать и как не нужно. После того, как разработчик в соответствии с codestyle написал новую фичу, он ее должен закоммитить. Мы сделали precommit hooks, которые не дадут закоммитить код с отклонениями от принятых правил. Это может быть и codestyle, и какие-то вещи, которые статический анализ легко вылавливает. То есть просто не дать проникнуть коду в коммит, git отказывается принимать такой код.
После этого у нас в обязательном порядке проходит кодревью. Мы пользуемся Bitbucket, у нас есть правило, что любой код может попасть в репозиторий только после апрува от двух коллег. Два живых человека должны прийти, посмотреть на код, полайкать его. И обязательно этот pull request должен собраться и пройти все 100% наших юнит-тестов. А тестов у нас много. И ревьюверы смотрят, и все precommit hooks. У некоторых из вас может возникнуть вопрос, сколько времени это вообще занимает? Большой проект ведь. Я с гордостью могу сказать, что у нас минимальное время от создания pull request до попадания кода в репозиторий сейчас составляет около 30 минут. Это минимальное время, за которое код попадет в наш мастер. Мы к этому шли долго. И у нас обычный Chromium-based браузер. У всех, кто такие браузеры пишет, есть очень большие проблемы со временем сборки. Миллион строк кода, их нужно скомпилировать, они компилируются долго. И 400 тыс. строк Java кода нужно скомпилировать и выполнить тесты. Это результат работы всей команды. Мы все работаем над тем, чтобы наши процессы позволяли нам больше думать о результате, а не о том, как дождаться билдов, локально или на TeamCity.
Что важно, 30 минут — это время на TeamCity, а у локального разработчика билд занимает 30 секунд. Он не прогоняет все юнит-тесты, он не собирает все сборки под все платформы, все комбинации. А на TeamCity мы это собираем. Плюс на TeamCity прогоняются тесты. У нас сейчас от этих 30 минут юнит-тесты занимают около 20. Кроме того, чтобы обеспечить качественный код, мы ввели техническую квоту. 30% времени команды мы тратим на отдачу от того технического долга, который успели накопить, и который пытаемся делать снова и снова. Каждый спринт 30% команды занимаются рефакторингами, улучшением существующего кода, написанием юнит-тестов, которых не было, либо улучшением инструментов.
Вообще, чтобы улучшить любую вещь, есть очень важное правило — прежде чем что-то улучшать, тебе нужно это измерить. Прошу вашей помощи. Прошу предложить, какие вещи вы предложили бы измерять, чтобы понять, насколько у вас качественный код и качественный продукт, чтобы улучшать этот продукт. Для примера назову очевидную вещь: какое у вас тестовое покрытие в процентах. Еще какие варианты понять, качественный у вас код или нет? Количество строк в методе. Количество классов. Скорость исполнения, как долго ваше приложение запускается, как быстро скроллятся списки. Количество интерфейсов — в принципе, та же самая метрика. Энергопотребление годится? Время билда — тоже.
Для всего, что вы назвали, у нас есть инструменты. Мы умеем измерять, что у нас в проекте сейчас, как было год назад и что происходит сейчас. Мы в первую очередь меряем самочувствие приложения в продакшене, мы используем AppMetrica, это общедоступный сервис, который позволяет следить за событиями, за крешами, за самочувствием приложения. Мы с помощью AppMetrica собираем много всего, технические показатели.
Затем при помощи ClickHouse и наших собственных самописных инструментов делаем отчеты из этих данных. У нас их чуть больше, чем у обычного пользователя AppMetrica, только за счет того, что мы вложились в доступ к этой базе и делаем специальные запросы. AppMetrica позволяет собрать факт события. Произошло событие — столько-то штук. Но AppMetrica не позволяет посмотреть на численные данные. Например, нам нужно измерить энергопотребление в каких-то попугаях. И нужно понять, как в текущей версии у разных пользователей сколько этих попугаев получилось. Как выглядит распределение пользователей по энергопотреблению. Как выглядит распределение пользователей по времени старта. Как выглядит распределение пользователей по скорости скроллла в FPS или во времени между кадрами. И для сбора таких численных данных, чтобы их анализировать, мы использовали гистограммы.
Про них очень хорошо рассказал мой коллега, находятся в Яндексе по слову «гистограммы», первое же видео — рассказ коллеги из моей команды про то, как мы собираем численные показатели и их анализируем. Тот же Илья Богин сможет подробно рассказать, как эти численные показатели собирать. И затем у нас есть очевидный показатель — открытые баги. Есть продукт, есть тестирование, есть пользователи. Они репортят баги. Чем больше багов, тем хуже продукт. Чем больше блокер-багов, тем хуже продукт. Блокер-баги сравнить с минорами… У нас отдельная метрика показывает качество продукта в багах, zero bug policy, условно.
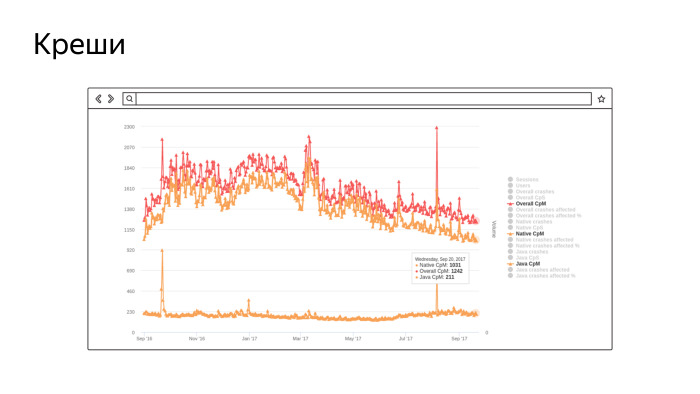 Это скриншот из реального нашего инструмента, в котором собирается количество крешей на миллион сессий. Не очень хорошо видно, но нижний график — это количество крешей в Java, около 200 на миллион сессий. А верхние два… Сначала креши в нативе, их довольно много, потому что у нас Chromium-ядро и там очень много «плюсов». Самый верхний — сумма. В целом, мы контролируем этот показатель и работаем над его улучшением. Чем меньше график, тем лучше. Это за последний год, мы работаем и улучшаем.
Это скриншот из реального нашего инструмента, в котором собирается количество крешей на миллион сессий. Не очень хорошо видно, но нижний график — это количество крешей в Java, около 200 на миллион сессий. А верхние два… Сначала креши в нативе, их довольно много, потому что у нас Chromium-ядро и там очень много «плюсов». Самый верхний — сумма. В целом, мы контролируем этот показатель и работаем над его улучшением. Чем меньше график, тем лучше. Это за последний год, мы работаем и улучшаем.
То же самое, такие же графики у нас есть для энергопотребления, для скорости скроллла и всего остального.
 Кроме того, мы внедрили и очень активно используем такую штуку, SonarQube, ее советую всем. Ее вы можете поставить себе, будь вы инди-разработчиком или в составе команды. Это платформа, на которую можно наворачивать любые статические анализаторы кода. Он опенсорсный, бесплатный и умеет анализировать почти все языки программирования, которые бывают. Мы его внедрили, и сейчас постоянно с его помощью следим за какими-то показателями здоровья нашего проекта. Коротко пройдусь по тому, что на этом слайде есть. Это очень важно, об этом в документации как бы написано, но не очень очевидно.
Кроме того, мы внедрили и очень активно используем такую штуку, SonarQube, ее советую всем. Ее вы можете поставить себе, будь вы инди-разработчиком или в составе команды. Это платформа, на которую можно наворачивать любые статические анализаторы кода. Он опенсорсный, бесплатный и умеет анализировать почти все языки программирования, которые бывают. Мы его внедрили, и сейчас постоянно с его помощью следим за какими-то показателями здоровья нашего проекта. Коротко пройдусь по тому, что на этом слайде есть. Это очень важно, об этом в документации как бы написано, но не очень очевидно.
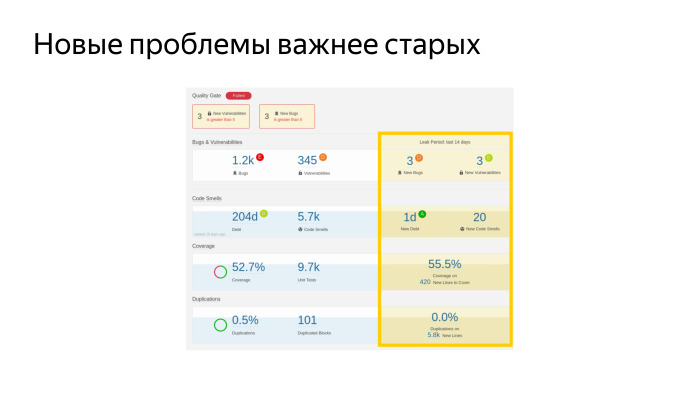
Это реальный дашборд, скриншот. У нас такое количество багов, больше тысячи. Есть какое-то количество уязвимостей с точки зрения безопасности. Вот такое тестовое покрытие — 52,7%. И такое количество юнит-тестов. Это круто, кажется. У нас сейчас самое большое покрытие из мобильных приложений Яндекса. Еще мы меряем долю дублированного кода. Что интересно, мы настроили эту штуку для всех мобильных приложений Яндекса и можем смотреть дубли между проектами, тоже очень круто, помогает нам выделять те части кода, которые стоит вынести в библиотечку, чтобы больше не дублировать.
Самая главная метрика, которая это все собирает, это и еще кучу всего, и в какой-то одной понятной цифре говорит, какой у вас проект, хороший или плохой. Это технический долг — у нас он 204 дня, условных рабочих дня условного разработчика в вакууме, который должен поработать, чтобы все эти проблемы были устранены. Как вы думаете, это большой долг или маленький? У нас команда большая, 30 человек. Если мы возьмемся, мы этот долг за ограниченное время отдадим. У нас были эпизоды, когда мы брались и начинали — давайте все блокеры в SonarQube пофиксим. И начинали их фиксить.
Но тут есть одна особенность. Это серебряная пуля. Неважно, сколько у вас всего багов нашел статический анализ в проекте. Важно, чтобы вы новых багов не делали. И фикс бага, который хороший и давно там лежит, точно когда-нибудь случится. Но он не случился, его в тестировании не нашли, его юнит-тесты не нашли. Скорее всего, он не стрельнет. И фикс старого бага может привести к тому, что у вас возникнет новый, настоящий, который приведет к реальному крешу.
Главное — не фиксить старые баги, а следить за тем, чтобы не было новых. Наш дашборде отдельный показатель — у нас нового долга за последние 14 дней накопилось 1 день. Да, мы его делаем, но очень умеренно. У нас показатель technical debt ratio, доля долга к объему всего кода, неуклонно падает. И это лучший показатель того, что мы все делаем правильно.
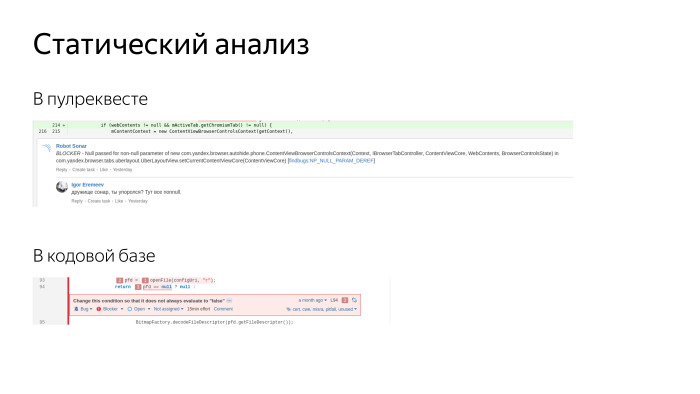 Вырезки из реальных скриншотов на экране. Этот же самый Sonar позволяет добавлять комментарии в pull requests. У нас приходят два ревьюера и оставляют комментарии, плюс еще приходит робот, третий ревьюер. Он оставляет комментарии по очевидным вопросам, по codestyle, оформлению кода, находит уязвимости с точки зрения безопасности. Люди его любят. Не дает добавить новый долг.
Вырезки из реальных скриншотов на экране. Этот же самый Sonar позволяет добавлять комментарии в pull requests. У нас приходят два ревьюера и оставляют комментарии, плюс еще приходит робот, третий ревьюер. Он оставляет комментарии по очевидным вопросам, по codestyle, оформлению кода, находит уязвимости с точки зрения безопасности. Люди его любят. Не дает добавить новый долг.
Кроме того, в Sonar мы можем посмотреть существующие баги. Там очень удобный просмотрщик, где мы видим всю кодовую базу, и для каждой строчки можем посмотреть, какой есть там issue, когда он был добавлен и что с ним делали. Можно прийти к автору и сказать: дружок, за последние две недели ты добавил пять блокеров — как так? Разобраться с причинами и устранить. Мы всегда стараемся любую проблему решить в корне, устранить возможность появления такой проблемы. Как правило, мы готовим какие-то инструменты или делаем так, чтобы баги невозможно было допускать.
Мы очень активно пишем тесты. Мы любим тесты. За последнее время очень сильно продвинулись в их написании.
 У нас вот такое количество тестов сейчас выполняется при помощи JUnit, это тесты, которые гоняются на хост-машинах, просто Java и Robolectric. И Android Instrumentation Tests. Такое количество у нас сейчас.
У нас вот такое количество тестов сейчас выполняется при помощи JUnit, это тесты, которые гоняются на хост-машинах, просто Java и Robolectric. И Android Instrumentation Tests. Такое количество у нас сейчас.
Пока мы писали это количество тестов, мы прошли несколько этапов. Тесты нужно писать, все их пишут, мы хотим качественный продукт — давайте тоже писать. Мы реально огребли кучу проблем. Мы пишем новые тесты, а старые все время ломаются, требуют много времени на поддержку и багов никаких не находят. Любое изменение кода вызывает поломку десятков сотен тестов, и мы ходим и фиксим тесты. К счастью, сейчас мы этот кризис миновали, сейчас наши тесты действительно обеспечивают и документирование кода, и обеспечивают разработчику уверенность в том, что код написан правильно. Сейчас вся команда тесты писать научилась и пишет их очень активно. На предыдущем слайде видно, что покрытие на новом коде — 55%. Это больше, чем на старом, мы движемся в правильном направлении. Лучше бы еще выше, но пока так.
Мы активно используем Robolectric, мы им довольны, он позволяет нам мокать, заменять собой настоящий Android, но при этом выполнять тесты гораздо быстрее. 9000 тестов — это много. Из них на эмуляторах выполняется около 600, остальные тесты выполняются на хост-машине. Билд-агент у нас быстрый, 16 ядер, на них все быстро и просто. Эмулятор если поднимаем, на нем начинают долго и мучительно выполняться Instrumentation Tests. Этого мы стараемся избежать. Robolectric очень хорош.
Еще мы активно используем интерфейсы. Мы сторонники чистого кода, активно используем inversion of control, dependency injection и при помощи интерфейсов отделяем платформу от того кода, который мы пишем. Есть люди, которые отрицают Robolectric, говорят, что нужны только интерфейсы, и Robolectric — зло. Мы сторонники разумного подхода. Мы активно используем Mockito и намеренно выпилили Powermock, поскольку он провоцировал плохой стиль тестов. Это зло, он позволяет мокать статики, файналы, вообще ломает все вокруг и провоцирует плохую архитектуру.
Главное резюме этого слайда, что мы все документируем — так же, как и любые вещи. Мы записываем в стиле «не делай так». У нас есть test smells, отдельная страничка, где фиксируются типичные проблемы, которые возникают при написании тестов в режиме «так плохо, а так было бы хорошо». И новые разработчики, когда приходят, обычно говорят, что очень помогает эта вещь, потому что там есть не просто примеры, как не нужно делать, и многие смотрят просто на правую часть, как делать нужно. Там есть многие приемы и инструменты, про которые невозможно догадаться, нужно их понять с опытом или узнать с опытом. А тут мы им на блюдечке с голубой каемочкой это все рассказываем.
 Этот график говорит сам за себя. Это данные с июня прошлого года до текущего момента. Мы работали над тестовым покрытием, писали тесты. Но важнее, что мы не стояли на месте, мы росли.
Этот график говорит сам за себя. Это данные с июня прошлого года до текущего момента. Мы работали над тестовым покрытием, писали тесты. Но важнее, что мы не стояли на месте, мы росли.
Кроме юнит-тестов мы используем автотесты. Кто не знает и не использует, это условное название для тестов, которые тестируют приложение как черный ящик. Запускают его на девайсе или эмуляторе, и условный робот своим резиновым пальцем скроллит списки, тыкает кнопки, пытается сломать ваше приложение по стандартным сценариям. Автотестами мы заменяем ручных тестировщиков, живых людей, которым лучше заниматься чем-то более осмысленным, чем повторять снова и снова сценарии. Мы ускоряем свою регрессию, проверку того, что новый релиз хорош и может ехать в продакшен. Сейчас мы раз в три недели релизимся и немалая часть этой заслуги в том, что мы перевели ручные тесты на автотесты. У нас больше 60% тестов автоматизированы.
 Автотесты у нас написаны на Appium, это довольно стандартный для Яндекса инструмент, он к нам пришел из тестирования веба вместе с людьми, которые тестировали веб. Сейчас мы на Appium написали около 3000 тестов, развернули инфраструктуру, которая позволяет каждый раз запускать 25 эмуляторов, они поднимаются, новые и чистые, на них в параллель запускаются и гоняются тесты. Но все равно все получается очень медленно. У нас запуск регрессии занимает сейчас несколько часов, и мы не можем это делать постоянно, на каждый билд. У нас не хватит ресурсов и железа, чтобы это все выполнять. И как раз эти инструменты мы очень активно контрибьютим в open source, на GitHub в Yandex QA Tools есть много инструментов, есть активное комьюнити, где мы все это выкладываем.
Автотесты у нас написаны на Appium, это довольно стандартный для Яндекса инструмент, он к нам пришел из тестирования веба вместе с людьми, которые тестировали веб. Сейчас мы на Appium написали около 3000 тестов, развернули инфраструктуру, которая позволяет каждый раз запускать 25 эмуляторов, они поднимаются, новые и чистые, на них в параллель запускаются и гоняются тесты. Но все равно все получается очень медленно. У нас запуск регрессии занимает сейчас несколько часов, и мы не можем это делать постоянно, на каждый билд. У нас не хватит ресурсов и железа, чтобы это все выполнять. И как раз эти инструменты мы очень активно контрибьютим в open source, на GitHub в Yandex QA Tools есть много инструментов, есть активное комьюнити, где мы все это выкладываем.
Вот еще одна вещь, которую мы, можно сказать, выстрадали. Изначально автотесты писали отдельные люди, не совсем разработчики. Есть ручники, их нужно автоматизировать. Первая реакция — давайте ручника заменим роботом, пускай он пишет, и отдельно от браузера поднимается репозиторий, куда пишут код. Вроде ребята пишут код на Java, тот же JUnit, вроде тестировщики. Но мы в итоге объединили команды, слились воедино, и сейчас у нас автотесты может писать любой разработчик. Мы специально ротируем людей, чтобы все знали, как автотесты пишутся, чтобы знали, как чинить автотесты, когда мы их внезапно поломали. В автотестах главная боль, что они все время отваливаются и ломаются, что они все время красные.
 Покажу один из способов решения этой проблемы. Это телевизор из моего кабинета, один из них. У нас вообще любят телевизоры с графиками. Но это телевизор про автотесты. Зеленые — успешно пройденные, желтые — зафейленные по известной нам причине, красные — по неизвестной. Мы все время за этим смотрим. Выделили отдельного дежурного, который все время меняется, который следит за тем, что с тестами происходит. Это очень важно — следить, чтобы тесты, которые отваливаются, не отгнивали. Если сразу не взяться за тест и не найти причину, то в итоге этот тест умрет и усилия, потраченные на его разработку, вы выкинете. Поэтому мы постоянно следим и знаем, почему зафейлился каждый тест. Указанные тесты у нас реально находят регрессии, проблемы, которые возникают в продакшен-коде. Мы не даем коду докатиться до продакшена, находим все на автотестах, не даем ручникам это посмотреть.
Покажу один из способов решения этой проблемы. Это телевизор из моего кабинета, один из них. У нас вообще любят телевизоры с графиками. Но это телевизор про автотесты. Зеленые — успешно пройденные, желтые — зафейленные по известной нам причине, красные — по неизвестной. Мы все время за этим смотрим. Выделили отдельного дежурного, который все время меняется, который следит за тем, что с тестами происходит. Это очень важно — следить, чтобы тесты, которые отваливаются, не отгнивали. Если сразу не взяться за тест и не найти причину, то в итоге этот тест умрет и усилия, потраченные на его разработку, вы выкинете. Поэтому мы постоянно следим и знаем, почему зафейлился каждый тест. Указанные тесты у нас реально находят регрессии, проблемы, которые возникают в продакшен-коде. Мы не даем коду докатиться до продакшена, находим все на автотестах, не даем ручникам это посмотреть.
 Еще мы активно используем Espresso. И сейчас мы считаем, что тесты на Espresso гораздо важнее, чем тесты на Appium, потому что на Espresso писать тесты быстрее. Они быстрее в поддержке и быстрее выполняются, но им тоже нужно много быстрых эмуляторов. Инфраструктура — главная проблема. Тесты на Espresso мы гоняем на эмуляторах. Раньше мы гоняли их на железных девайсах, но это действительно проблема. У нас до сих пор стоят шкафы, где десятки телефонов лежат и моргают экранами. Все время с ними что-то происходит. Поэтому во всех тестах мы ушли от девайсов на эмуляторы и очень этому рады. Если будете поднимать такую инфраструктуру, советую сразу смотреть только на эмуляторы.
Еще мы активно используем Espresso. И сейчас мы считаем, что тесты на Espresso гораздо важнее, чем тесты на Appium, потому что на Espresso писать тесты быстрее. Они быстрее в поддержке и быстрее выполняются, но им тоже нужно много быстрых эмуляторов. Инфраструктура — главная проблема. Тесты на Espresso мы гоняем на эмуляторах. Раньше мы гоняли их на железных девайсах, но это действительно проблема. У нас до сих пор стоят шкафы, где десятки телефонов лежат и моргают экранами. Все время с ними что-то происходит. Поэтому во всех тестах мы ушли от девайсов на эмуляторы и очень этому рады. Если будете поднимать такую инфраструктуру, советую сразу смотреть только на эмуляторы.
В тестах, именно в Espresso, мы начали активно использовать Kotlin, на котором написали очень удобный DSL, описывающий нашу систему, наш браузер, и позволяющий очень быстро реализовывать новые тесты. Потому что все шаги готовы, и ты словно из кубиков все собираешь и делаешь новый тест.
Качество — не разовое мероприятие. Нельзя взять и сделать качественно. Качество — это процесс.
 Чтобы добиться качества, мы модифицировали процессы. Добавили роботов, которые проверяют все, что делают люди. Людей мы просим делать все одинаково. Мы контролируем то, что у нас происходит с продуктом, с нашим кодом, пишем много тестов и постоянно их все запускаем. Все юнит-тесты запускаются всегда. И мы пишем много автотестов, которые позволяют разгрузить ручных тестировщиков и раньше находить баги.
Чтобы добиться качества, мы модифицировали процессы. Добавили роботов, которые проверяют все, что делают люди. Людей мы просим делать все одинаково. Мы контролируем то, что у нас происходит с продуктом, с нашим кодом, пишем много тестов и постоянно их все запускаем. Все юнит-тесты запускаются всегда. И мы пишем много автотестов, которые позволяют разгрузить ручных тестировщиков и раньше находить баги. Но все-таки главное — люди. Вся команда должна понимать, что мы делаем продукт, нам с этим продуктом жить и создавать баги не нужно, а нужно писать хороший, чистый и клевый код. Думал, я сам придумал эту фразу. Оказалось, нет.
Но все-таки главное — люди. Вся команда должна понимать, что мы делаем продукт, нам с этим продуктом жить и создавать баги не нужно, а нужно писать хороший, чистый и клевый код. Думал, я сам придумал эту фразу. Оказалось, нет.
habrahabr.ru
От черного прямоугольника в Яндекс.Браузере к ускорению всего Chromium
Сегодня мы расскажем вам историю об одном интересном баге в Яндекс.Браузере, исправление которого привело к значительному ускорению отрисовки во всем проекте Chromium. И помогут мне в этом Кирилл drBasic Плешивцев и Вадим Lof Петров, специалисты из нашей команды, которым и посчастливилось разбираться с проблемой. Передаю им слово.
Один не совсем обычный баг
Меня зовут Кирилл, я работаю в группе внутренних компонентов Яндекс.Браузера в Новосибирске. В один не совсем прекрасный день коллеги из тестирования Яндекс.Браузера воспроизвели проблему с проигрыванием видео через Flash Player. И поскольку именно наша группа отвечает за эту часть браузера (медиа, кодеки, вот это все), задача досталась мне. Баг, скажем так, не претендовал на оригинальность. Клик по кнопке Play приводил к черному прямоугольнику вместо корректного воспроизведения видео. Этот симптом я встречал и раньше, поэтому рассчитывал на достаточно быструю локализацию проблемы. Но я ошибался. Буквально в первые же минуты удалось выяснить, что черный прямоугольник возникает не всегда, а только для flash-элементов с типом transparent, т.е. полупрозрачных. Отлично, уже есть за что зацепиться при отладке. Собираю debug-версию браузера, запускаю, бага нет. А это уже тревожный звонок. Расхождения в работе debug и release версий — это всегда очень весело. Поэтому решаюсь собрать еще и релизную версию. Собрал, запускаю, бага нет.
Задумался. В чем отличия моей релизной сборки от той, что собирает сервер? Сходу вспомнил про компоновку библиотек. Разработчики собирают браузер в режиме shared_library. Это увеличивает количество dll, но зато сильно экономит время компоновки. Распространяется же браузер, собранный в режиме static_library, при котором собирается лишь несколько больших dll. Выставляю флаг static_library, делаю полную сборку. Наблюдаю, как link.exe медленно съедает всю оперативную память, но нет, 16 ГБ RAM хватит всем, компоновка завершается без допинга в виде файла подкачки. Запускаю. Бага нет.
Серьезно задумался. Вспомнил, что сборочный сервер собирает релизный Яндекс.Браузер с флагом official, который немного меняет поведение (подробнее расскажем чуть позже). Собираю с этим флагом. Дрожащей рукой запускаю браузер. Вы уже угадали? Бага нет.
Тут я не на шутку встревожился и начал думать изо всех сил. Через некоторое время обратил внимание на то, что сервер собирает Яндекс.Браузер с помощью Visual Studio 2013. А я же использовал 2015 версию. Собираю в 2013 версии. Запускаю. Баг есть! Кто бы мог подумать, что я так буду радоваться ошибке.
Если вы сейчас подумали, что вся проблема заключалась только в версии VS, то ошибаетесь. Баг действительно не воспроизводился в debug-версии браузера. Опытным путем удалось установить, что для появления ошибки с черным прямоугольником браузер должен быть собран не только с помощью VS 2013, но и в статичной компоновке с флагом official. О причинах такого странного поведения вы узнаете чуть позже.
Следующие два дня были не менее интересными. В ходе отладки мне удалось понять, что сам плагин Flash Player отрабатывает свою задачу корректно: видео воспроизводится. Его интеграция с браузером вопросов также не вызывала. Результат его работы передавался для отрисовки, но по каким-то причинам на экране мы видели совсем другое. А это значит, что баг нужно было искать в той части браузера, которая отвечает за рендеринг. И здесь я передаю слово Вадиму.
Оптимизируй это
Как вы уже поняли, теперь на связи Вадим. Работаю я в группе разработки рендеринг-движка Яндекс.Браузера в Москве. Несколько слов о том, как вообще происходит отрисовка в Яндекс.Браузере или Chromium. Все, что вы видите в окне браузера, есть результат совмещения различных слоев (веб-страница, интерфейс), почти как в Photoshop. За работу с этими слоями отвечает компонент Compositor (или Chrome's Compositor == CC). А вот для отрисовки уже каждого слоя СС вызывает специальную опенсорсную библиотеку Skia.
Вместе с Кириллом мы поняли, что следы бага уходят в Skia. Оставалось понять, куда именно. К счастью, у меня была ценная подсказка. Почти в самом начале Кирилл её упомянул. Речь о том, что проблема возникает только в случае flash-элементов с прозрачностью. Чтобы отрисовать на экране такой элементы, браузеру необходимо совместить картинку видео с фоном. И для этого в Skia есть специальная функция SrcATop, отвечающая за блендинг. Несколько минут поиска, и вот я уже нашел багрепорт со схожей проблемой в Chrome, который окончательно развеял все сомнения.
Ура. Мы локализовали источник проблемы вплоть до конкретной функции. А теперь, внимание. Этот участок кода не содержал никаких ошибок. Совсем никаких. И работал он идеально для любых сборок кроме самой финальной, которая и отправляется пользователям. Причем только для Visual Studio 2013. И вот в этот момент я понял, почему Кирилл называл этот баг «веселым».
Начинаю разбираться в прочих отличиях, которые влияют на воспроизводимость ошибки. Пришло время вновь вспомнить про флаг official, который используются только в самом конце. Помимо всего прочего, этот флаг влияет на оптимизацию, а точнее на параметр /LTCG. Когда он указан, компилятор производит достаточно серьезную оптимизацию всей программы. На это уходит очень много времени, поэтому такие сборки просто так не собирают. Но как оптимизация может привести к ошибке? Чтобы понять это, нам понадобится небольшой флешбек.

В 2011 году проект Chromium стал настолько большим и сложным, что компоновщик Visual Studio 2010 однажды не смог слинковать его со всеми оптимизациями из-за нехватки ресурсов. Чтобы обойти проблему, разработчики решили по умолчанию оптимизировать все подпроекты (а их больше тысячи) не по скорости работы (/O2), а по размеру кода (/O1). И лишь для избранных и наиболее критичных, или для тех, чьи владельцы не проспали эту ситуацию, включили обратно /O2. Например, это сделали для CC и Skia. Вот только в 2013 году при рефакторинге в Skia оптимизацию случайно потеряли. И никто бы ничего не заметил, если бы еще через два года не случился еще один рефакторинг в Chromium, в результате которого часть кода сделали шаблонным и перенесли в header. И вот тут-то все и началось.
А началось вот что. Когда происходит сборка релизного браузера с флагом official, библиотеки, имеющие разные цели для оптимизации (по скорости, по размеру), оказываются в одной dll. Само по себе это не признак чего-то плохого. Например, в Visual Studio 2015 никаких проблем это не вызывает. Студия пыхтит час над оптимизацией и выдает вполне рабочий код. Но стоит нам заменить её 2013-й версией, и все ломается. Почему?
Функция SrcATop, которая отвечает за блендинг в Skia, принимает два параметра через регистры xmm0 и xmm1. И почти всегда она работает корректно. Но как мне удалось выяснить в ходе отладки, стоит добавить сюда VS 2013 и непростую оптимизацию, и функция вырождается до такой степени, что начинает возвращать в ответ содержимое первого регистра. Отсюда и появлялся неизменный черный фон вместо видео. Всему виной была неправильная кодогенерация в VS 2013.
Ускоряем веб-сёрфинг
При большом желании баг можно было «исправить» локально, немного подкрутив SrcATop. Но мне показалось неправильным, что у такого важного для отрисовки компонента, как Skia, отсутствует оптимизация по скорости. Поэтому я собрал новую сборку, в которой выставил для Skia оптимизацию по скорости. Баг, конечно же, пропал. Казалось бы, можно закрывать задачу и идти пить чай, но нет. Мне нужно было сделать еще кое-что.
Команда Яндекс.Браузера участвует в разработке Chromium уже не первый год. И это касается не только исправления ошибок. В свое время коллеги помогли с реализацией server push для HTTP/2 и со сборочной системой проекта для Windows. Поэтому и в этот раз я предложил решение проблемы и отправил на рассмотрение готовый коммит, который после небольшого обсуждения был принят.
Разработчикам из Chromium, так же как и мне, было интересно взглянуть на изменения в плане производительности браузера. Поэтому они прогнали целый комплекс performance-тестов. Практически все показатели для Windows подросли. Часть низкоуровневых тестов и вовсе показала улучшения в 2-3 раза. Интегральный FPS-тест для ключевых сайтов (иными словами, повседневный веб-сёрфинг) вырос на 6,5%. Отзывчивость на ввод улучшилась на 20-30%. В проекте Chromium далеко не каждый день случается оптимизация подобного уровня.
Учитывая, что VS 2010 уже давно не используется, я предложил попробовать включить оптимизацию по скорости для всего проекта. Тем более что обычная release-сборка (без флага official) всегда оптимизировалась по скорости целиком, и с тестированием никогда проблем не было. Но это уже совсем другая история.
P.S. Эта отдельно взятая проблема затронула лишь два офиса. На самом деле разработка Яндекс.Браузера ведется не только в Москве и Новосибирске. У нас есть команды еще и в Санкт-Петербурге, Екатеринбурге, Нижнем Новгороде, Минске и Киеве. И если вам было бы интересно к ним присоединиться, то заглядывайте на yandex.ru/jobs.
habrahabr.ru
Борьба с перехватом HTTPS-трафика. Опыт Яндекс.Браузера
Согласно исследованию сотрудников Mozilla, Google, Cloudflare и ряда университетов, от 4 до 11% защищенных соединений «прослушиваются» в результате установки сомнительных корневых сертификатов на компьютерах пользователей, которые даже и не догадываются о риске. Сегодня я расскажу о том, как наша команда привлекает внимание к этой проблеме с помощью Яндекс.Браузера.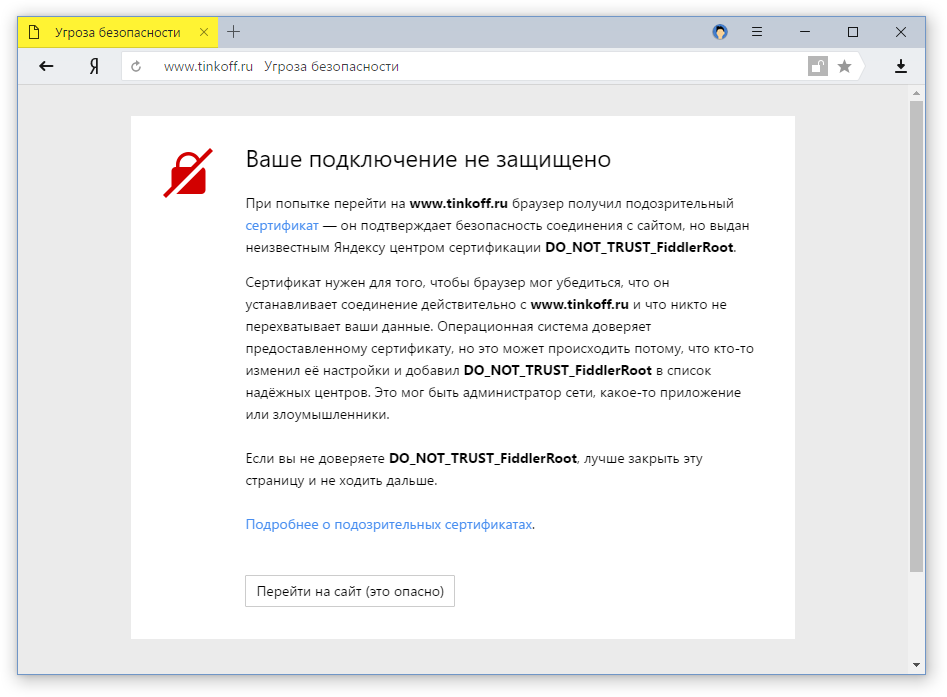
Вряд ли на Хабре стоит подробно рассказывать об SSL-сертификатах и тех задачах, которые они решают, но на всякий случай коротко напомним о главном (вы можете просто пропустить пару абзацев, если хорошо представляете принципы работы). Получить закрытый замочек в адресной строке браузера сейчас легко и быстро может любой сайт, поэтому сертификат это ни в коей мере не признак «надежности» сайта, несмотря на соответствующую маркировку в Chromium. Тем не менее он выполняет важную функцию защиты наших с вами данных от перехвата. Администратору сети или злоумышленнику, получившему доступ к трафику, нужно еще придумать способ для расшифровки потока, что обычно сделать затруднительно при стойкой криптографии и отсутствии ключа.
Если нельзя расшифровать поток, то можно его перенаправить через себя, заставив браузер устанавливать соединение не с сайтом, а со своим сервером (атака типа man-in-the-middle). Например, можно взломать маршрутизатор пользователя и с помощью подмены DNS-ответов перенаправлять его на фишинг-сайт для воровства паролей. Опытный пользователь вряд ли с таким столкнется, а своим близким можно настроить альтернативный DNS-сервер с поддержкой DNSCrypt прямо в браузере. Но если злоумышленник захочет пойти дальше и начнет выступать посредником между пользователем и HTTPS-сайтом, то тут нас спасет другая задача сертификата – аутентификация.
Когда браузер получает сертификат от сайта, он должен убедиться, что его прислал именно сайт, а не «человек посередине». Подтвердить это можно с помощью корневых сертификатов, которые находятся в хранилище операционной системы. Если для сертификата, который якобы прислал сайт, не удается найти подтверждающий корневой, то любой современный браузер выдаст что-то такое:
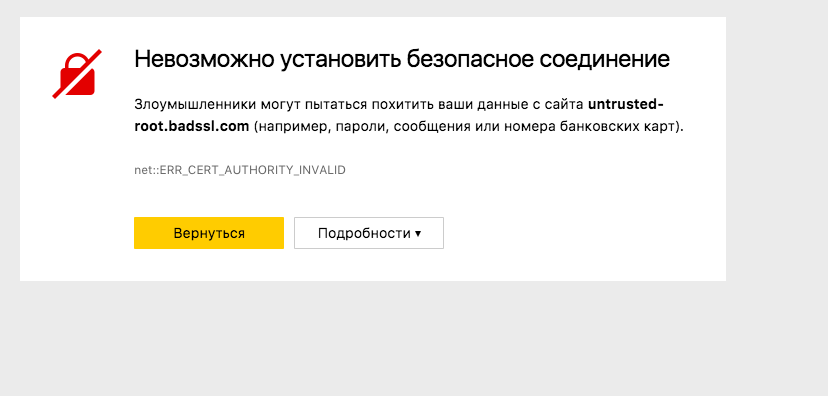
Чтобы обойти такую защиту и скрыть от пользователя факт своего вмешательства в трафик, остается только одно – поместить в системное хранилище свой корневой сертификат, который легализует в глазах браузера подписанные им сертификаты злоумышленника. Причем сделать это может любое приложение. А с правами администратора еще и без предупреждений и вопросов пользователю. Человек устанавливает с сомнительного сайта программу, а в довесок получает прослушку трафика. И ни один современный браузер никак на это не отреагирует. Вы увидите все ту же надпись «Надежный» и зеленые замочки. Разве что в случае с Firefox злоумышленникам понадобится добавить свой корневой сертификат еще и в хранилище этого браузера, потому что системное он не использует (но сделать это ничуть не сложнее).
Если исключить случаи относительно легального использования этой возможности со стороны программ (антивирусы, блокировщики рекламы, Fiddler) и контроль сотрудников в организациях, то обычно подобная практика приводит к появлению шокирующей и опасной рекламы на посещаемых страницах. Пользователи в большинстве случаев не догадываются о причинах, винят владельцев сайтов или даже разработчиков Яндекс.Браузера. Можете себе представить, как порой сложно нашей службе поддержки добраться до причины и помочь человеку. Но так проблему хотя бы заметно. А ведь в некоторых случаях никаких внешних проявлений не происходит, а данные просто воруются.
Причем вред от злоумышленников не только прямой (в виде перехвата данных и рекламы), но и косвенный. В обычной ситуации мы можем кликнуть на замочек и узнать, какой именно удостоверяющий центр выдал сертификат, оценить его надежность (в Яндекс.Браузере; в других браузерах эту информацию уже часто скрывают). При подмене эти данные скрыты от нас. И не только эти, но и любые другие проблемы с соединением. Если на сайте используется некорректный сертификат, который неизбежно бы привел к полноценной предупреждающей заглушке в любом браузере, то подмена сертификата маскирует эту проблему от пользователя – в адресной строке отображается обычный закрытый замочек. Все это приводит к общему падению уровня безопасности.
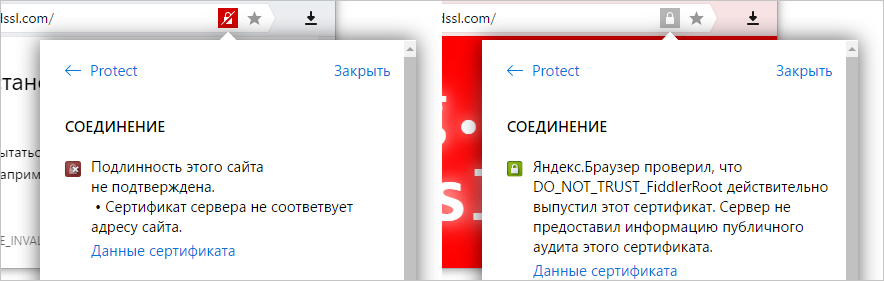
По предварительным подсчетам, уже порядка 400 тыс. пользователей из недельной аудитории Яндекс.Браузера живут с перехватом трафика. И это за вычетом антивирусов! Именно поэтому мы всерьез взялись за проблему и начали экспериментировать с выявлением факта установки сомнительного корневого сертификата в систему. Работает это следующим образом. Теперь Яндекс.Браузер не слепо доверяет корневому сертификату из системного хранилища, а проверяет его по списку известных авторитетных центров сертификации. И если корневой сертификат браузеру не знаком, то мы размыкаем замочек и честно сообщаем о потенциальном риске.
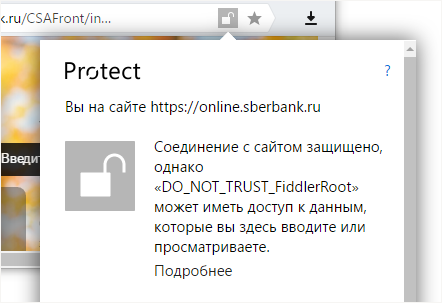
Решение с открытым замочком относительно мягкое – наблюдали за реакцией пользователей. Но несколько дней назад мы перешли к следующему этапу. Теперь при загрузке важных сайтов, к которым относятся банки, платежные и поисковые системы, популярные социальные сети, появляется полноценное предупреждение, рассказывающее об угрозе.
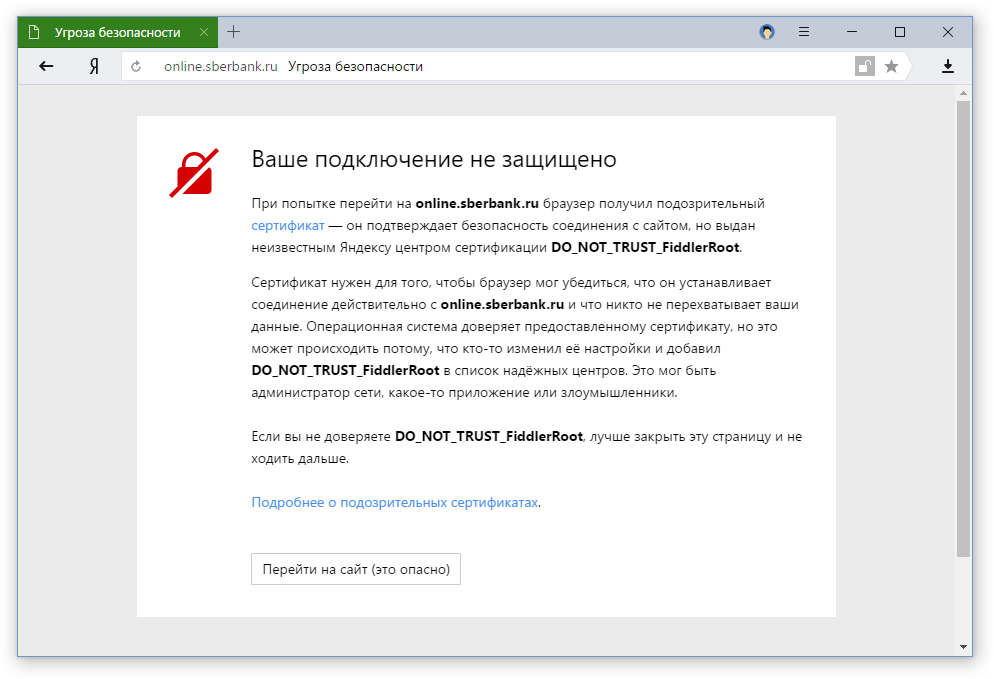
Предупреждения в Яндекс.Браузере нельзя назвать панацеей, потому что они никак не влияют на основной источник проблемы – программу, устанавливающую свой корневой сертификат. Но мы надеемся, что информирование пользователей привлечет их внимание к риску потери данных или как минимум упростит диагностику. Ведь даже сам факт перехвата трафика до этого момента был скрыт от людей.
habrahabr.ru
Будущее браузеров и искусственный интеллект. Дзен в Яндекс.Браузере
В будущем, как нам кажется, все популярные браузеры выйдут за рамки программ для открытия веб-страниц и научатся лучше понимать людей, которые ими пользуются. Сегодня я расскажу вам, каким мы видим это будущее на примере персональной ленты Дзен в Яндекс.Браузере, которая теперь доступна пользователям Windows, Android и iOS.
Несмотря на кажущуюся простоту, в основе Дзена лежат довольно сложные технологии. Я расскажу немного о том, как это реализовано у нас, где и почему мы использовали традиционное машинное обучение, а где — нейронные сети и искусственный интеллект, и буду благодарен за ваше мнение об этом подходе.
Рекомендации хорошо знакомы всем, кто активно пользуется сетью. Интернет-магазины предлагают схожие товары. Онлайн-кинотеатры советуют фильмы. Музыка, книги, игры, приложения — в любой нише можно найти примеры подобных решений. В современном мире, где количество информации растет в геометрической прогрессии, рекомендации помогают людям найти что-то новое и интересное.
Яндекс всегда специализировался на поиске. В широком смысле этого слова. Поиск ответов на свои вопросы. Поиск оптимального маршрута. И даже поиск свободного такси рядом с вами. Примерно два года назад у нас появилась еще одна идея. Научить машину искать в сети тот контент, который был бы интересен конкретному человеку. Персонализированный поиск, где в качестве запроса выступают не слова, а интересы. Из этой идеи и родилась лента рекомендованного контента Дзен.
Дзен
Дзен – это бесконечная лента контента, которая формируется исходя из интересов конкретного человека. Мы хотим помочь пользователям найти интересный контент, а издателям – целевой трафик (клик по рекомендациям открывает материал на сайте-первоисточнике). Обычно рассказы о новых продуктах начинают с описания идеологии и продуктовой стратегии, и здесь я рекомендую вам прочитать пост Романа kukutz Иванова в блоге Яндекса, а мы с вами сразу перейдем к самому важному для Хабра, к технологиям. Тем более, что именно они отличают Дзен в Яндекс.Браузере от любых других браузерных (и не только) аналогов.
Кстати, внимательный читатель может вспомнить, что первые эксперименты с Дзеном проводились в 2015 году на странице zen.yandex.ru. Почему теперь лента рекомендаций стала частью Браузера? На этот раз вопрос я обязательно отвечу чуть позже.
В основе Дзена лежит рекомендательная технология Диско, разработанная в Яндексе и уже нашедшая применение в Яндекс.Музыке и Яндекс.Маркете. Слово «диско» созвучно английскому слову discovery, которое означает «открытие нового» и хорошо описывает суть технологии.
Упрощенная логическая схема работы Диско в случае с Дзеном выглядит так:
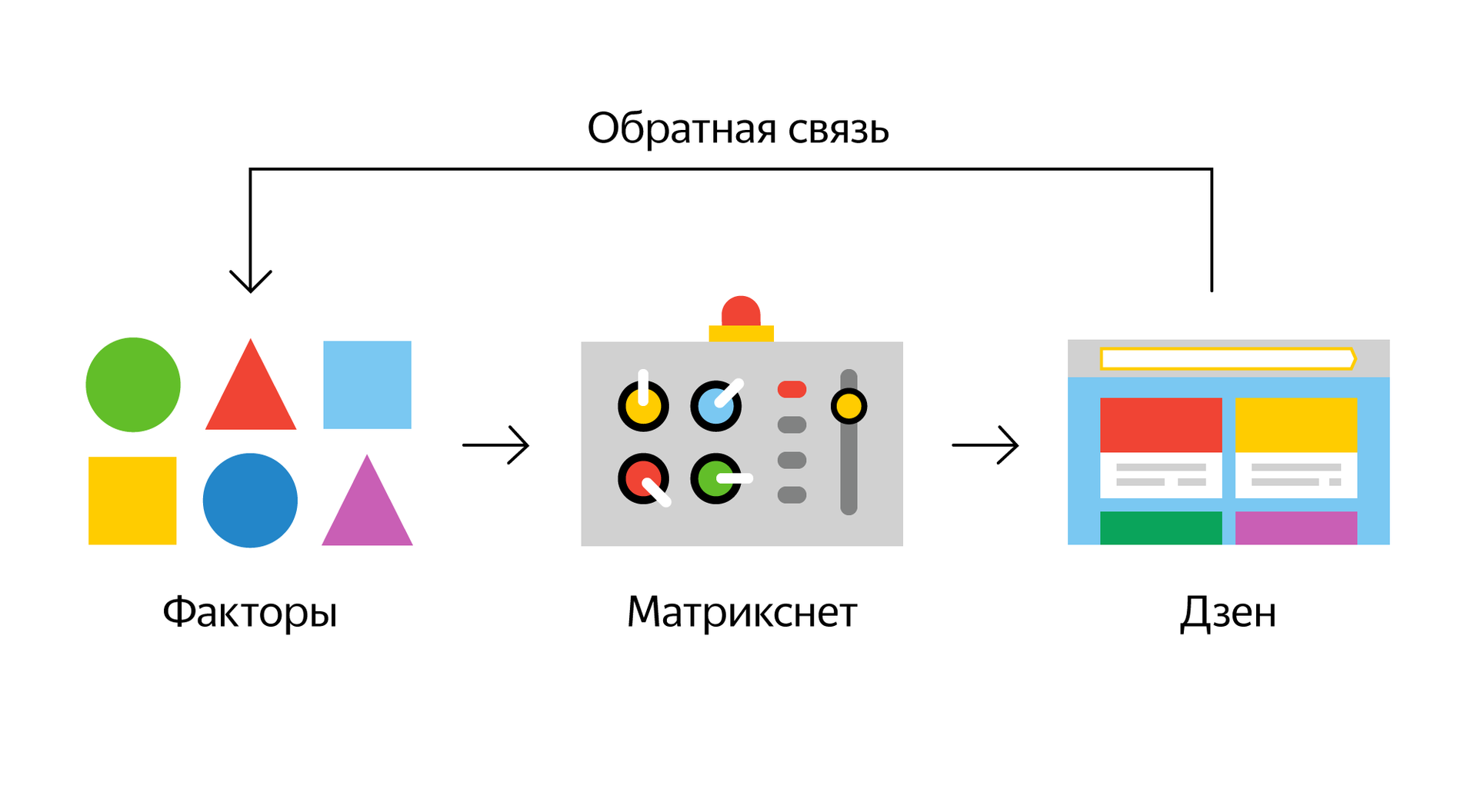
Начнем с самого начала, с исходных данных, которым еще только предстоит как-то превратиться в факторы.
С чего начинаются рекомендации
Прежде чем что-либо советовать человеку, нужно понять его интересы и предпочтения. Дзен для этого использует знания Яндекса о посещаемых людьми сайтах. Благодаря этим знаниям многие новые пользователи Дзена смогут сразу увидеть ленту персональных рекомендаций без необходимости что-то настраивать. Но иногда их недостаточно. Можно было бы попробовать решить эту проблему с помощью ленты, ориентированной на среднестатистического человека. Но мы же знаем, что такого человека в реальности не существует (что хорошо было показано на примере американских военно-воздушных сил). Поэтому пошли другим путем и предложили людям самостоятельно ограничить круг своих интересов. У этих настроек нет своего названия, но внутри мы называем их «Онбордингом».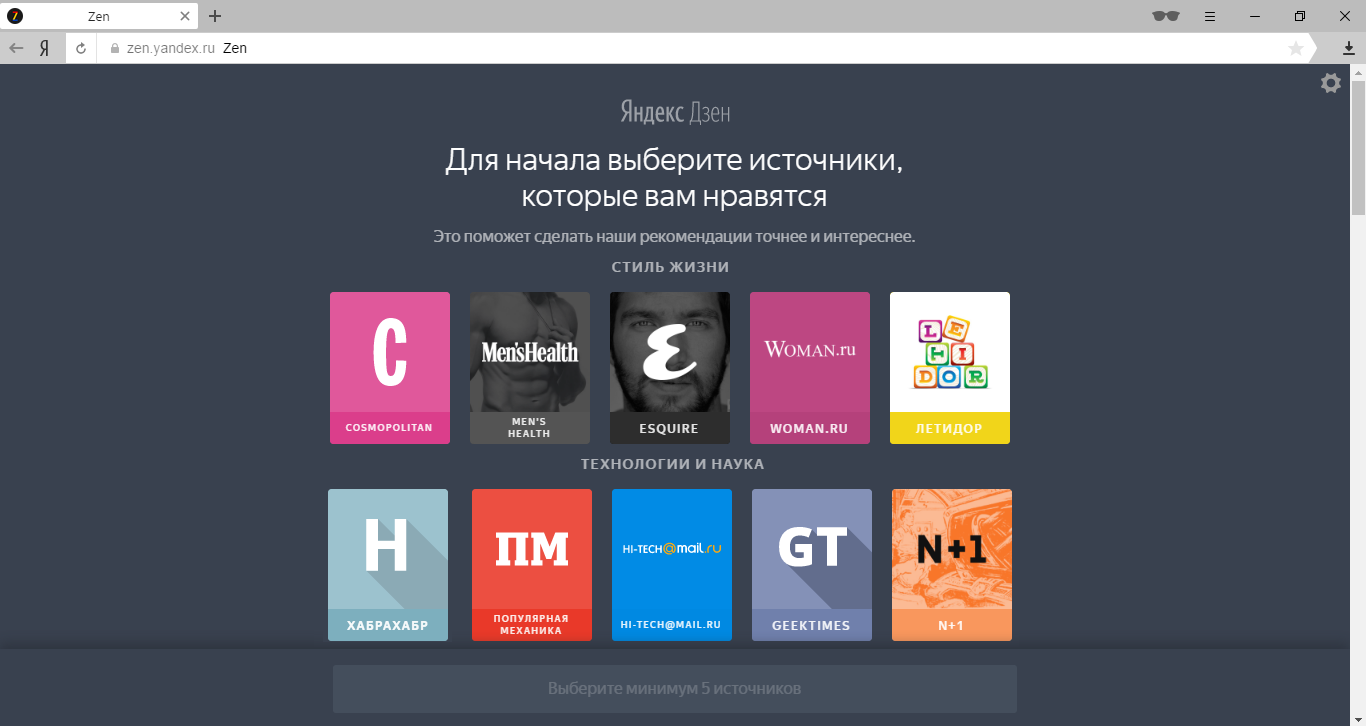
Важно понимать, что Онбординг – это не обязательный этап начальных настроек, а лишь резервный вариант для тех, кому точно нечего предложить. Лента рекомендаций сразу после прохождения Онбординга может достаточно сильно отличаться от подборок, формируемых через несколько недель активного использования Дзена. Эти настройки уже доступны пользователям Яндекс.Браузера для Android и iPhone. Для Windows станут доступны в ближайшее время (а пока можно воспользоваться временным решением).
Знания об интересах человека – это лишь половина необходимой информации. Для того чтобы что-то рекомендовать, нужно для начала это что-то найти. Обычно рекомендательные сервисы решают эту задачу примитивным способом – формируют ограниченный каталог RSS-лент по интересам. В случае с Дзеном таких ограничений нет. Поисковые роботы ищут любые материалы. Это могут быть как авторские публикации с популярных блогов, так и качественные истории с форумов или ролики с YouTube. Это то, что мы называем «диким вебом». Главное, чтобы сайт не был заброшен и на странице содержалось достаточное количество полезного контента.
Итак, с одной стороны у нас знания о любимых публикациях миллионов пользователей, с другой – вся мощь глобального поискового индекса Яндекса. Осталось самое «простое». Научить машину строить рекомендации.
Виды рекомендательных систем
В истории рекомендательных технологий хорошо известны два их основных вида: фильтрация по содержимому и коллаборативная фильтрация. Начнем с первого, который основан на сравнении содержимого рекомендуемых объектов. Для примера предлагаю рассмотреть фильмы. Если два фильма относятся к одному и тому же жанру, и пользователь уже высоко оценил один из них, то с определенной вероятностью можно посоветовать ему и второй. И здесь интересно вспомнить онлайн-кинотеатр Netflix, который увеличил количество жанров с нескольких сотен до десятков тысяч, среди которых можно найти даже «Культовые ужастики со злыми детьми». Большая часть из этих жанров скрыта от глаз зрителей и используется только для построения рекомендаций.
В нашем случае никаких жанров нет. Чтобы сделать вывод о соответствии веб-страницы интересам человека, нужно сравнить ее контент с известными образцами. Причем заниматься этим должен компьютер, которому нужно не просто прочитать материал, но и понять его смысл. И единственный способ решить эту задачу достаточно точно, это использовать опыт Яндекса в области искусственного интеллекта.
NLP + CV
Когда речь заходит об искусственном интеллекте, то многие пользователи представляют себе SkyNet, желающий поработить человечество. К счастью, будущее не предопределено и все в наших руках. Но а если серьезно, то наработки в области ИИ уже сейчас помогают нам решать сложные задачи. Способность машины читать, видеть и, что наиболее важно, понимать смысл открывает большие перспективы.Обработка естественного языка (Natural Language Processing, NLP) и компьютерное зрение (Computer Vision, CV) – два широко применяемых в Дзене направления из области искусственного интеллекта.
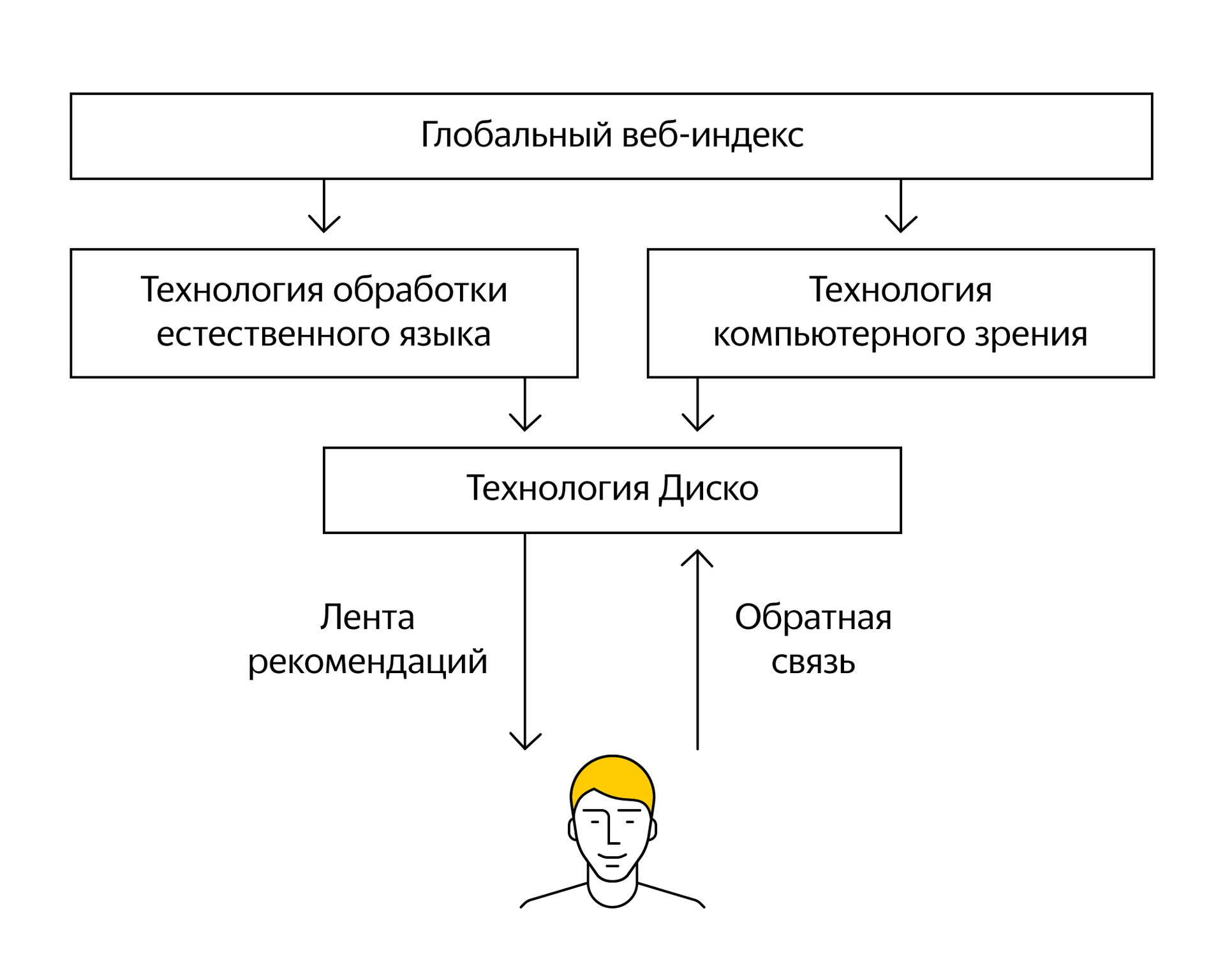
Когда мы говорим о рекомендациях, то подразумеваем себе материалы, которые были бы достаточно близки по своему смысловому наполнению к образцам пользователя. Иными словами, машина должна прочитать два текста и сделать вывод: близки ли они по смыслу или нет. Ровно это мы и учимся делать. Специально обученная нейронная сеть преобразует текст в вектор, в котором заключен смысл текста. Два текста могут быть написаны с использованием разных слов и даже на разных языках, но смысл у них будет один. Сравнивая эти векторы, мы можем с определенной вероятностью предсказать интерес человека к новому материалу. Кстати, если векторы почти совпадают, то это уже говорит о смысловом дубликате (рерайт текста или разные статьи об одном и том же событии), с которыми мы боремся в ленте.
Другой подход к NLP, над которым работает команда Дзена, это автоматическое присвоение меток для любого текста. Вспомните про пример с Netflix'ом и десятками тысяч жанров. Так и здесь. Классификация публикаций с помощью меток помогает повысить точность итоговых рекомендаций.
Работа с компьютерным зрением в целом похожа на NLP. Только вместо чтения текста машина учится «смотреть» и понимать смысл изображения. Помимо прямого применения в рекомендациях у компьютерного зрения есть и другие задачи в Дзене. Например, миниатюры картинок далеко не всегда удобно масштабируются, и их приходится обрезать, а компьютерное зрение помогает находить на картинках людей и спасает их от судьбы Нэда Старка из «Игры престолов».
Компьютерное зрение применяется и для нахождение текста на картинках. Некоторые сайты любят дублировать заголовок в виде изображения. В ленте это смотрится далеко не так красиво, поэтому подобные картинки выявляются и не используются в качестве миниатюр. Существует еще такое труднообъяснимое понятие, как «качество» картинки. Машина учится выбирать на сайте те изображения, которые больше нравятся людям, и использует их в качестве все тех же миниатюр.
SVD
Выше я рассказал вам о подходе к построению рекомендаций, который основан на фильтрации по содержимому объектов. Теперь пришло время вспомнить о коллаборативной фильтрации. В основе этого подхода лежит идея, что похожим людям нравятся похожие объекты. В этом случае вам не нужно знать свойства рекомендуемых объектов, достаточно собрать статистику о том, насколько они соответствуют интересам пользователей. На примере фильмов это может выглядеть так: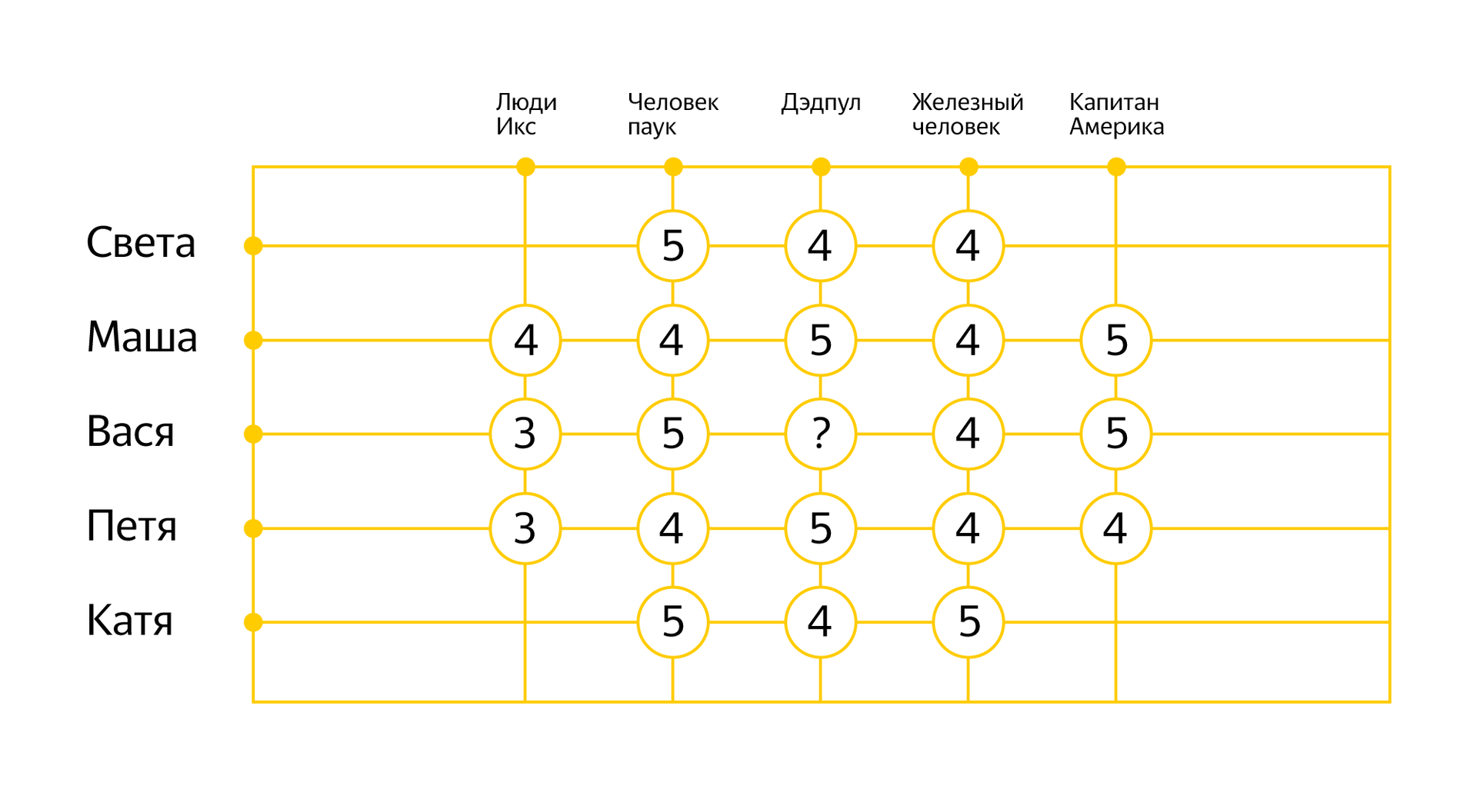
Опираясь на уже известные оценки, можно выявить закономерности в поведении разных людей и попробовать предсказать реакцию на новый фильм. На математическом уровне для применения коллаборативной фильтрации придуманы разные алгоритмы, о которых в свое время на Хабре хорошо рассказал мой коллега Михаил Ройзнер.
В случае с Дзеном мы используем коллаборативную фильтрацию (а точнее алгоритм SVD) для предсказания интереса человека к определенному сайту в целом. Эта информация дополняет рекомендации, построенные для отдельных материалов с помощью искусственного интеллекта (NLP+CV). Позволяет отсеять излишний шум и выявить нетривиальные закономерности (скажем, может выясниться, что люди, которые интересуются Хабром и историями с Пикабу, чаще других читают «N+1»).
Подытожим. Используя исходные данные о сайтах и пользователях, мы с помощью технологий обработки естественного языка, компьютерного зрения и алгоритма SVD формируем комплект различных факторов, которые характеризуют интересы человека к тем или иным сайтам/материалам.
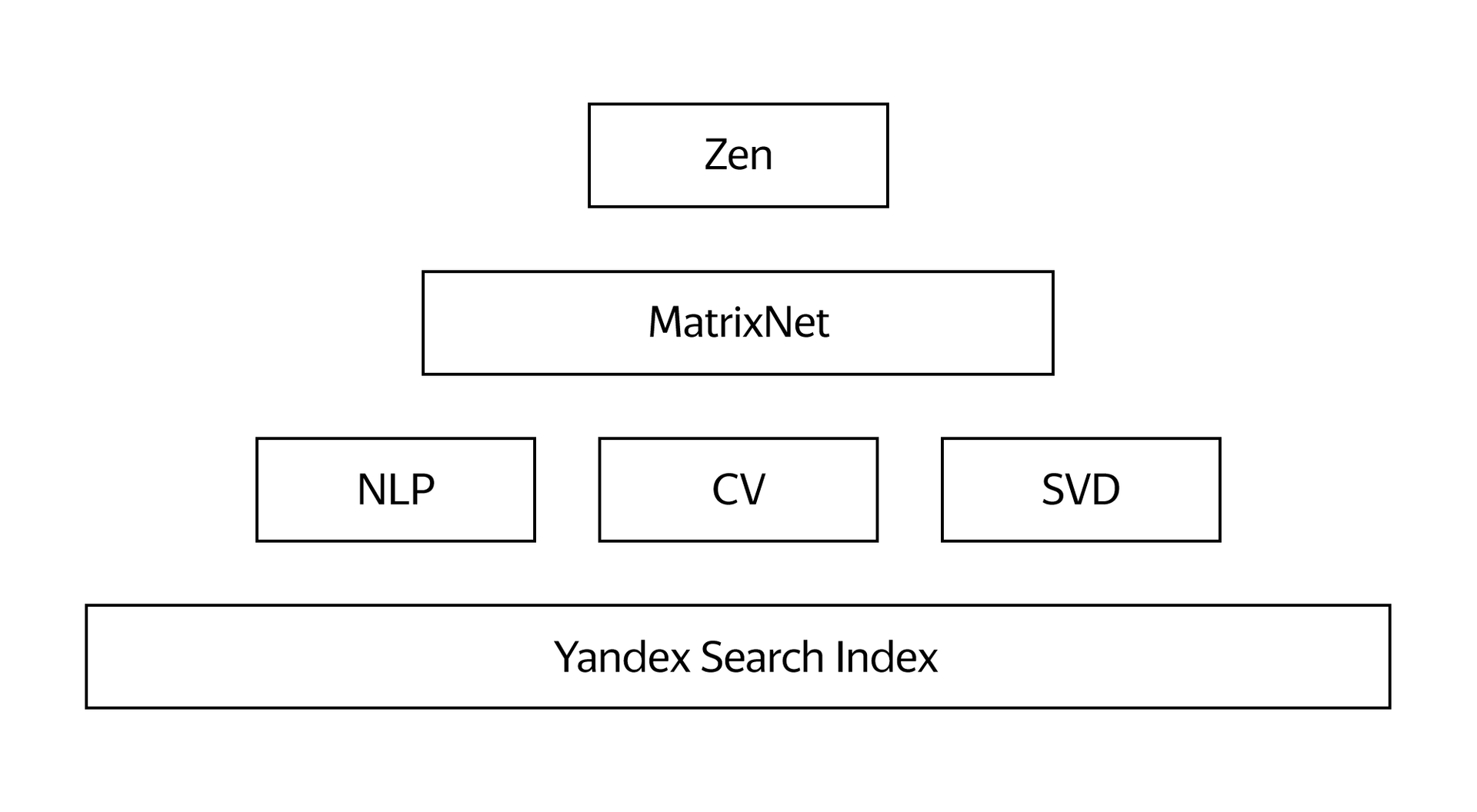
Точность итоговых рекомендаций напрямую зависит от количества и разнообразия исходных данных, поэтому в качестве факторов используются и многие другие наши знания. Например, знания Яндекса о конкретном сайте или странице, информация о том, как человек использует Дзен, его обратная связь в виде кликов, «больше такого» и «меньше такого», местоположение и даже время суток. Общее количество отдельных факторов, которые мы закладываем в систему рекомендаций, исчисляется тысячами. Сложность системы достигает такого уровня, что одних алгоритмов уже мало. Нужна технология, которая будет сама вычислять идеальную формулу для построения итоговой ленты. И здесь нам пригодился опыт Яндекса в области машинного обучения.
Матрикснет
Термин «машинное обучение» появился еще в 50-х годах. Он обозначает попытку научить компьютер решать задачи, которые легко даются человеку, но формализовать путь их решения сложно. В результате машинного обучения компьютер может демонстрировать поведение, которое в него не было явно заложено.Каждый день наша поисковая система отвечает на миллионы запросов, многие из которых — неповторяющиеся. Поэтому невозможно написать такую программу, в которой предусмотрен каждый запрос и для каждого запроса известен лучший ответ. Поисковая система должна уметь принимать решения самостоятельно, то есть сама выбирать из миллионов документов тот, который лучше всего отвечает пользователю. Для этого нужно научить ее обучаться.
С 2009 года поиск Яндекса использует собственный метод машинного обучения Матрикснет. С его помощью можно построить очень длинную и сложную формулу ранжирования, которая учитывает множество различных факторов и их комбинаций. Кроме того, Матрикснет сам определяет разную чувствительность для разных значений факторов ранжирования. Эта технология достаточно универсальна, поэтому впоследствии нашла применение не только в Яндексе, но и в Европейском Центре ядерных исследований.
Способность компьютера учитывать тысячи факторов и самостоятельно искать наилучшее решение – это то, без чего невозможно построить современную рекомендательную систему. Именно поэтому Матрикснет был взят за основу при создании собственной рекомендательной технологии.
Результат работы Матрикснета – это именно то, что пользователь и видит в ленте Дзен. Со стороны разработчиков не существует каких-либо правил вида «Если человек любит А, то рекомендуем ему Б». Все подобные закономерности рождаются и постоянно меняются внутри Матрикснета. И чем больше у него данных, тем точнее рекомендации. Именно поэтому Дзен – это часть Яндекс.Браузера, а не самостоятельный веб-сервис или приложение. Отдельному приложению сложнее понять интересы пользователя, который после двух-трех дней может просто перестать его запускать. Чтобы магия Дзена и машинного обучения вступила в полную силу, им нужно активно пользоваться или хотя бы регулярно проходить рядом. И браузер, как единая точка выхода в интернет, подходит для этого лучше всего. Само собой, любой пользователь может отказаться от использования Дзена в Браузере.
В этом посте я рассказал вам о том, как формируется лента персональных рекомендаций в Яндекс.Браузере, и почему Дзен – это не очередная «лента новостей», а результат работы серьезных технологий. Наработки из области искусственного интеллекта уже сейчас помогают машине понимать смысл контента и интересы человека. Но это лишь самое начало. Кто знает, может быть, однажды компьютеры будут понимать нас лучше, чем мы сами?
habrahabr.ru
От черного списка до машинного обучения. Антифишинг в Яндекс.Браузере
Злоумышленники, специализирующиеся на воровстве паролей, номеров банковских карт и прочей личной информации, появились еще в прошлом веке и с тех пор их число только растет. Согласно отчету Лаборатории Касперского, от 9% до 13% их пользователей в России сталкиваются с фишингом. Ежегодно в мире фишинг и другие формы кражи личных данных наносят ущерб в $5 млрд, согласно оценкам Microsoft. Это в целом соответствует нашим наблюдениям и объясняет, почему в любом более-менее популярном браузере есть защита от фишинга, основанная на «черных списках». В Яндекс.Браузере она тоже есть. Казалось бы, зачем изобретать что-то еще?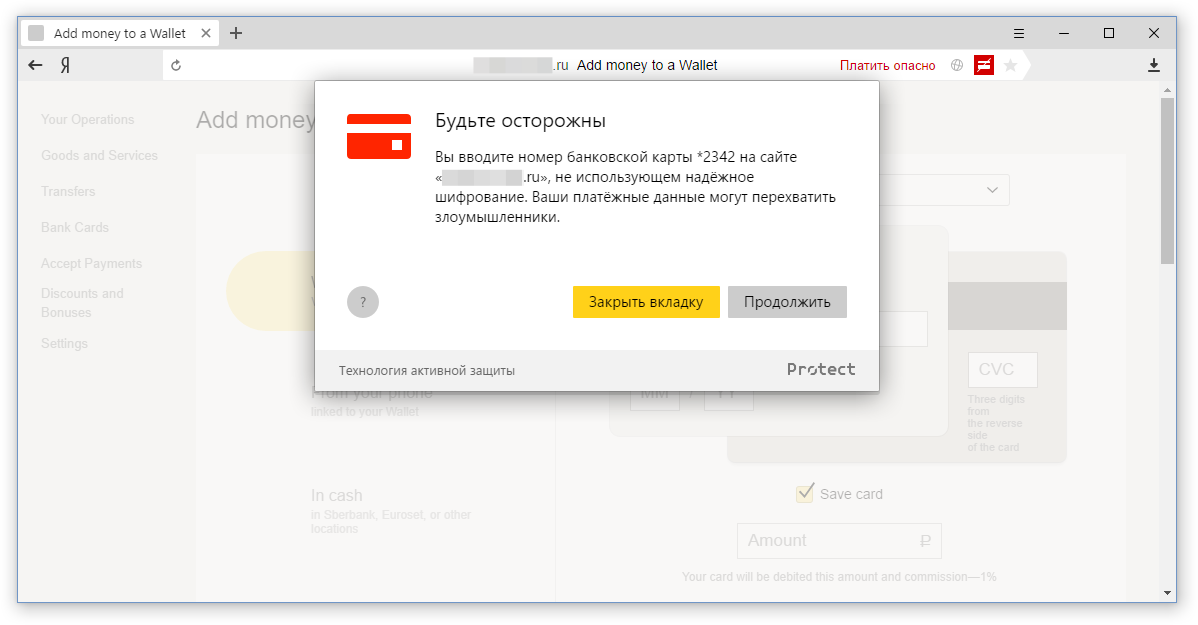
Safe Browsing
Самое очевидное решение для защиты пользователей – это использование готовой базы со списком фишинг-сайтов. Проверяем по «черному списку» посещаемые страницы и предупреждаем, если нашлось совпадение. На этой идее и основана защита с использованием технологии Safe Browsing, которая работает в Яндекс.Браузере с момента его появления. Немного о том, как это работает. В Браузере регулярно обновляется список плохих сайтов весом в несколько мегабайт. На самом деле опасных сайтов очень много, а степень сжатия ограничена, поэтому вместо явных адресов локально храним лишь префиксы (т.е. начальная часть) их хэшей. Посещаемые сайты проверяем по локальной базе. Если нашли совпадение, то префикс отправляем на сервер, в ответ получаем полные хэши, перепроверяем, если и здесь совпадение, то показываем предупреждение. Цепочка выглядит длинной, но работает за доли секунды, не плодит запросы и, что наиболее важно, защищает пользователя.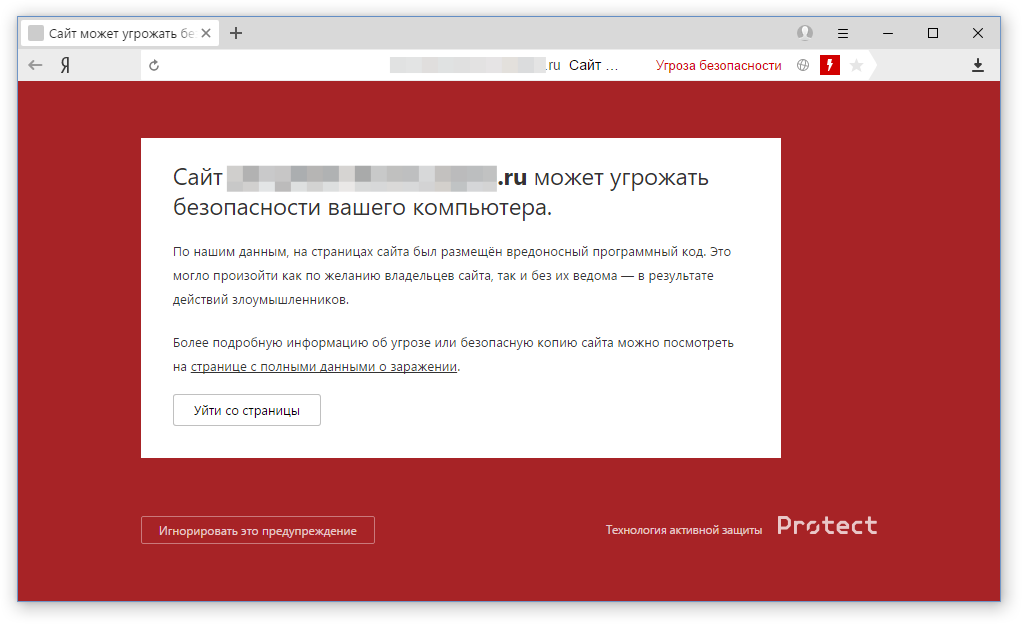 Списки Safe Browsing пополняются с помощью поисковых и антивирусных технологий Яндекса, детали которых раскрывать по понятным причинам не стоит. Однако сторонние разработчики тоже могут воспользоваться результатами в своих продуктах (в том числе в браузерах) с помощью нашего Safe Browsing API.
Списки Safe Browsing пополняются с помощью поисковых и антивирусных технологий Яндекса, детали которых раскрывать по понятным причинам не стоит. Однако сторонние разработчики тоже могут воспользоваться результатами в своих продуктах (в том числе в браузерах) с помощью нашего Safe Browsing API.Защита с помощью списков плохих сайтов (будь то Safe Browsing Яндекса, Гугла или другие аналоги) долгое время была единственным применяемым способом в браузерной индустрии. Проблема в том, что современные фишеры уже не такие медленные, как раньше. Создание сайтов-подделок, их публикация, рассылка спама через социальные сети – все это уже давно автоматизировано. Пока новая фишинг-страница дойдет до полной базы, а затем до легкой локальной она вполне может успеть кому-то навредить. Нам нужно было научиться бороться с проблемой в условиях отсутствия точных знаний.
Защита паролей
Злоумышленники с помощью фишинга активно воруют пароли от банков, платежных систем, социальных сетей и даже админок управления сервером. Как их защитить, если браузер еще не знает, хороший или плохой сайт открыт в нем? Предупреждать при каждом вводе пароля и просить убедиться, что это именно тот самый сайт? Это не просто навязчиво, но и бесполезно в перспективе. Если пользователь 100 раз подтвердит, что перед ним настоящий сайт Сбербанка, а не поддельный, то на 101 раз он просто не станет проверять сайт, который по закону подлости обязательно окажется мошенническим.К слову, есть распространенное заблуждение, что двухфакторная авторизация на банковских сайтах спасет от кражи денег, даже если человек попался на фишинг. Спасет, конечно, но далеко не всегда. В нашей практике мы сталкивались с примерами опасных сайтов, которые после ввода логина и пароля умели инициировать отправку СМС настоящим банком. Код из СМС пользователь вводил на уже открытой фишинг-странице, и злоумышленники использовали его, получая полный доступ к личному кабинету. Но мы отвлеклись.
Изначально идея была достаточно проста. Нужно присматривать за паролями, уже сохраненными в браузере. Если пользователь вводит пароль на сайте, который явно не совпадает с сайтом из менеджера паролей в браузере, то нужно его остановить и предупредить. Проблема в том, что встроенным менеджером паролей пользуются далеко не все. Даже простые пользователи, которые никогда не слышали о LastPass, KeePass или 1Password, не спешат сохранять свои пароли, нередко предпочитая вводить их по памяти или из блокнота (бумажного, а не из Windows). Причем именно эта категория пользователей наиболее уязвима перед фишингом, а значит, такое простое решение не подходило.
Использовать уже сохраненные пароли не было смысла, но вместо отказа от всей идеи мы научили Браузер самостоятельно запоминать хэши вводимых паролей. Почему хэши? Потому что их вполне достаточно для сравнения паролей, к тому же хранить хэши все же безопаснее. Конечно же, мы дали опцию отключить функцию для тех, кто и хэшам не доверяет. Итак, если пользователь хотя бы раз вошел, например, на настоящий Альфа-Банк, то Браузер предупреждал его при попытке ввода пароля на фишинговых копиях. Казалось бы, можно было идти пить шампанское, но не все так просто.
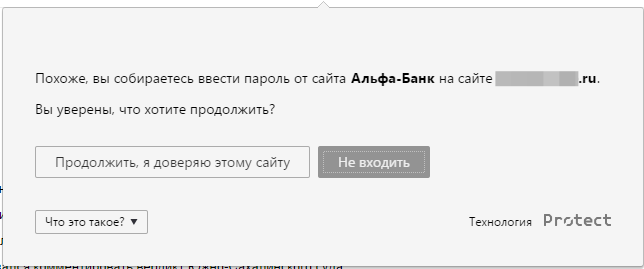 Память пользователей не подчиняется закону Мура, поэтому многие предпочитают придумать один пароль на все сайты. Это ужасно с точки зрения безопасности, но такова реальность. Если бы мы включили защиту паролей на всех пользователей для всех сайтов, то изобрели бы не только хорошую защиту от фишинга, но и отличный способ распугать аудиторию. Поэтому по умолчанию защита была включена только для наиболее популярных среди мошенников сайтов. Для любого другого ее можно включить вручную.
Память пользователей не подчиняется закону Мура, поэтому многие предпочитают придумать один пароль на все сайты. Это ужасно с точки зрения безопасности, но такова реальность. Если бы мы включили защиту паролей на всех пользователей для всех сайтов, то изобрели бы не только хорошую защиту от фишинга, но и отличный способ распугать аудиторию. Поэтому по умолчанию защита была включена только для наиболее популярных среди мошенников сайтов. Для любого другого ее можно включить вручную.Эта функция была внедрена примерно год назад, и все это время она не только защищает от фишинга, но и привлекает внимание людей к теме безопасности паролей. Вот только пароли – это не единственный вид конфиденциальных данных, которые любят воровать.
Защита карт
Чтобы украсть деньги, не обязательно воровать пароли от онлайн-банков и продумывать логику с обходом двухфакторной авторизации. Можно просто выкрасть данные банковской карты. Про необязательный 3-D Secure вспоминать тоже не стоит – пользователь и CVV-код не забудет ввести на фишинг-странице. После кражи данных карты остается только придумать, как забрать оттуда деньги. Способы бывают разные. Например, кто-то продает туристам билеты с 50% скидкой, по факту покупая их с украденной карты по полной стоимости. С переменным успехом подобные операции удается вовремя оспорить через свой банк, но лучше до этого не доводить и защищать данные своей банковской карты.В отличие от защиты паролей, где можно было однозначно контролировать пары «пароль-сайт», банковские карты могут использоваться где угодно. Мы можем контролировать крупные площадки, но длинный хвост онлайн-магазинов все равно не покроем. Да и что вообще значит «контролировать»? Не давать вводить номер карты? Если предупреждать, то о чем? Осознав, что вряд ли на уровне Браузера можно сделать однозначный вывод о плохих намерениях сайта, мы взглянули на ситуацию под другим углом – с точки зрения шифрования.
Наличие SSL-сертификата – обязательное условие для любого сайта, который работает с конфиденциальными данными пользователей, в особенности с банковскими данными. Если ресурс просит ввести номер карты, но не поддерживает защиту и работает по HTTP, то тут возможны сразу две разные проблемы. Во-первых, ваши данные кто-то может перехватить по пути из открытого трафика. Например, через незащищенную Wi-Fi точку в кафе. Во-вторых, владелец такого ресурса как минимум не заботится о безопасности своих посетителей, а, возможно, просто ворует данные. В любом случае, вводить номер карты на таком сайте не стоит. Если проблему с перехватом мы еще как-то решаем с помощью функции защиты Wi-Fi, то от мошенника шифрование канала никак не спасет. Точнее спасет данные от мошенников-перехватчиков и доставит их в целостности мошенникам-фишерам. И вот здесь нужно было что-то делать.
Итак, мы локализовали проблему. Если пользователь заходит на HTTP-сайт, который просит ввести номер банковской карты, то это повод предупредить. Но чтобы показать сообщение, нужно для начала распознать ввод карты. Специальный банковский тип тега input еще никто не придумал, а относительно свежий атрибут для браузерного автозаполнения autocomplete=cc-number мало кто использует. Команда Chromium, конечно, не бросает идею научить браузер самостоятельно подставлять номера карт и даже внедряет эвристику, которая угадывает по названиям полей и некоторым другим данным, но работает это не везде. В общем, анализ полей ввода – не вариант. Но зато мы можем ловить ввод цифр. Например, если пользователь ввел 16 цифр, то можно предположить, что это банковская карта. Проблема в том, что это не всегда так. К счастью, существует алгоритм Луна.
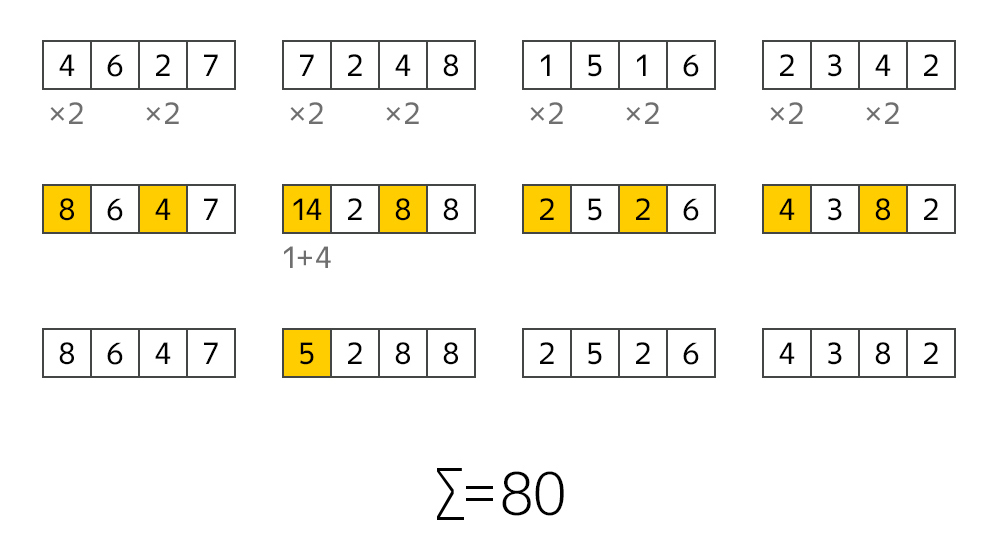
Думаю, многие знают, что последняя цифра в номере карты нужна для проверки корректности всего номера. А саму проверку можно легко провести с помощью алгоритма Луна. Он достаточно простой. В каждой паре цифр номера карты первое число умножаем на 2. Если после умножения число становится больше 9, то нужно сложить составные цифры. А затем все сложить. Если итоговая сумма кратна 10, то перед нами номер банковской карты. С вероятностью ошибки в 10%.
 Алгоритм Луна снижает вероятность ложного срабатывания в разы. Но существует дешевый способ снизить ошибку еще немного – контролировать первые цифры в номере. Именно в начале номера закодирована платежная система, поддерживающая карту. Если в начале стоит цифра 4, то это VISA. Что-то из диапазона 51-55 – это MasterCard. 34-37 – это American Express. Аналогично для некоторых других систем. Вероятность ошибки, конечно же, всегда остается, но уже на допустимом уровне.
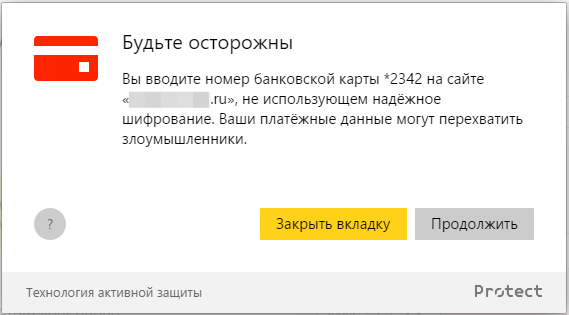
Алгоритм Луна снижает вероятность ложного срабатывания в разы. Но существует дешевый способ снизить ошибку еще немного – контролировать первые цифры в номере. Именно в начале номера закодирована платежная система, поддерживающая карту. Если в начале стоит цифра 4, то это VISA. Что-то из диапазона 51-55 – это MasterCard. 34-37 – это American Express. Аналогично для некоторых других систем. Вероятность ошибки, конечно же, всегда остается, но уже на допустимом уровне.Мы научили Браузер распознавать ввод определенного количества цифр (от 15 до 19), проверять их по алгоритму Луна и на соответствие кодам известных платежных систем. И все это работает полностью локально – номер карты Браузер никуда не отправляет и не хранит. Если все условия выполняются, то пользователь видит такое предупреждение:
 Подобное же сообщение мы показываем и для ряда других опасных ситуаций. Например, если сам сайт защищен HTTPS, но ввод номера происходит в HTTP-фрейме. Или если сертификат сайта не валиден.
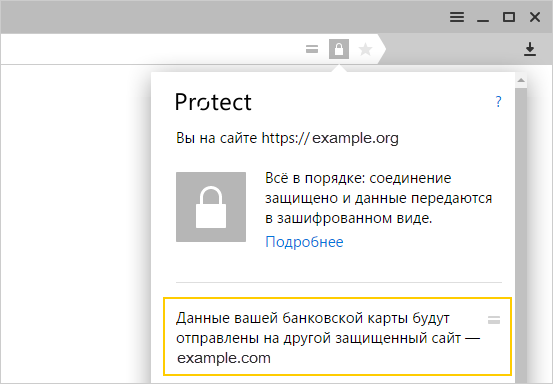
Подобное же сообщение мы показываем и для ряда других опасных ситуаций. Например, если сам сайт защищен HTTPS, но ввод номера происходит в HTTP-фрейме. Или если сертификат сайта не валиден.Существуют ситуации, для которых в силу широкой распространенности и относительной безопасности не стоит показывать предупреждение, но дать возможностям пользователям разобраться все же надо. Например, если форма ввода номера карты находится во фрейме на другом домене (и сайт, и фрейм при этом HTTPS). Это встречается сплошь и рядом, потому что онлайн-магазинов много, но далеко не все из них способны проработать собственный модуль оплаты, предпочитая встраивать фреймы популярных платежных систем. Или другой пример. Сайт не использует шифрование, но карту принимает через HTTPS-фрейм на своем же домене. Для таких ситуаций Браузер не показывает предупреждение, но добавляет в адресную строку значок карты. Если кликнуть по нему, то можно узнать, кому именно вы доверяете свои данные.
 Вся наша вышеописанная защита вертится вокруг наличия SSL-сертификата. Это обоснованно, потому что пользователи в массе своей еще не привыкли обращать внимание на замочек в адресной строке, и у фишеров нет мотивации использовать сертификаты. Но постепенно все меняется. Установить бесплатный сертификат от того же Let's Encrypt уже не проблема. А значит, рано или поздно мы вновь вернемся к ситуации, когда защищать как-то надо, но данных на клиенте недостаточно. И чтобы не проиграть фишинг-сайтам в будущем, готовиться мы начали уже сейчас.
Вся наша вышеописанная защита вертится вокруг наличия SSL-сертификата. Это обоснованно, потому что пользователи в массе своей еще не привыкли обращать внимание на замочек в адресной строке, и у фишеров нет мотивации использовать сертификаты. Но постепенно все меняется. Установить бесплатный сертификат от того же Let's Encrypt уже не проблема. А значит, рано или поздно мы вновь вернемся к ситуации, когда защищать как-то надо, но данных на клиенте недостаточно. И чтобы не проиграть фишинг-сайтам в будущем, готовиться мы начали уже сейчас.Машинное обучение
Любой сайт в интернете обладает совокупностью характеристик, по которым его можно оценить. Например, размер аудитории, время жизни, наличие SSL-сертификата, его надежность или даже уникальность адреса (фишеры любят использовать максимально схожие адреса). И наше с вами доверие к тому или иному сайту во многом определяется именно ими. Опытный пользователь, глядя на неизвестный сайт, может для себя решить, вызывает ли эта площадка доверие. С компьютером все сложнее. Задача определения «подозрительности» сложно поддается формализации и не укладывается в простые алгоритмы. Понятно, что грубая ошибка в HTTPS — это сильный критерий, но я говорю о куда более неочевидных случаях. И здесь без машинного обучения уже не обойтись.Яндекс применяет машинное обучение не первый год. Наши технологии используются не только внутри компании (Поиск, Музыка, Маркет, Дзен), но и доступны для внешних заказчиков через Yandex Data Factory. Именно машинное обучение позволяет компьютеру демонстрировать поведение, которое в него не было явно заложено. И для нашей задачи – предупреждать пользователей при оплате на подозрительных сайтах – подходит идеально.
Чтобы обучить машину искать подозрительные сайты, мы должны показать ей примеры заведомо плохих сайтов. С этим у нас нет проблем – спасибо технологии Safe Browsing. С другой стороны, мы указываем ей уже упомянутые выше характеристики (факторы), на которые стоит обращать внимание. А уже дальше наш метод машинного обучения Матрикснет учится выводить закономерности и строить формулы, которым можно было бы скормить адрес сайта, а на выходе получить вердикт. Максимально упрощенно это выглядит так:
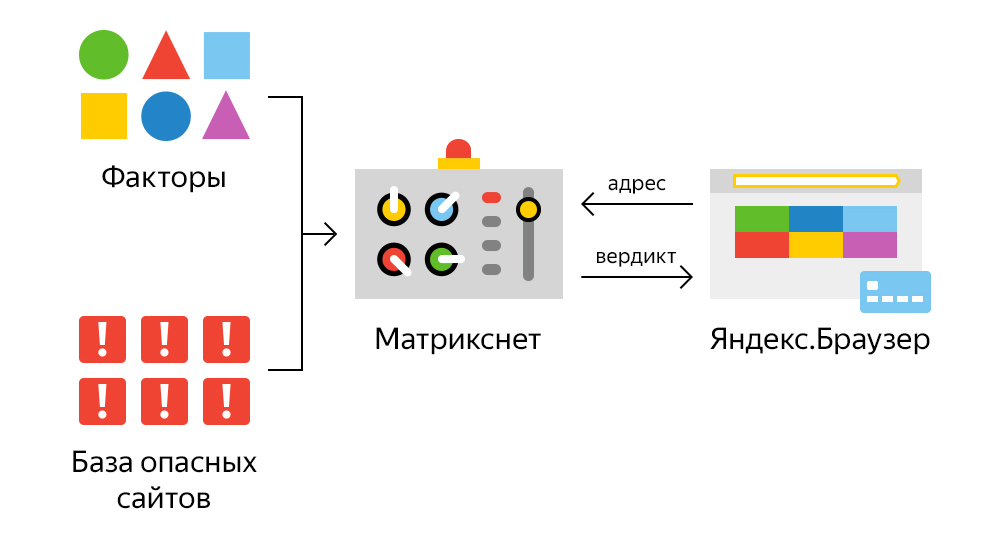 Среди всех факторов один хотелось бы выделить особенно. Обычные пользователи, которые чаще других становятся жертвами фишинга, ориентируются в первую очередь на внешний вид сайта и далеко не всегда смотрят на его адрес, замочек и прочие детали. Злоумышленники этим и пользуются. Отличительная черта большинства фишинг-сайтов – это копирование оформления популярных ресурсов. Поэтому с помощью технологии компьютерного зрения мы научили машину сравнивать внешний вид страниц с образцами популярных сайтов. Если она находит совпадение, то это сильный сигнал о возможной угрозе.
Среди всех факторов один хотелось бы выделить особенно. Обычные пользователи, которые чаще других становятся жертвами фишинга, ориентируются в первую очередь на внешний вид сайта и далеко не всегда смотрят на его адрес, замочек и прочие детали. Злоумышленники этим и пользуются. Отличительная черта большинства фишинг-сайтов – это копирование оформления популярных ресурсов. Поэтому с помощью технологии компьютерного зрения мы научили машину сравнивать внешний вид страниц с образцами популярных сайтов. Если она находит совпадение, то это сильный сигнал о возможной угрозе.Результаты работы машинного обучения и компьютерного зрения доступны пользователям Яндекс.Браузера, начиная с версии 16.9.1. Если пользователь вводит на сайте номер карты, то на сервер уходит запрос с указанием страницы. Если есть риск, то пользователь видит предупреждение.
 Может показаться странным, что мы показываем именно предупреждение и только в ответ на ввод карты, а не используем сразу при загрузке полноэкранную блокировку. Причина в том, что машина обучается выявлять сайты, на которых есть риск потери денег, и блокировать доступ ко всей информации было бы неправильно. К тому же вероятность ложноположительных вердиктов никогда не равна нулю.
Может показаться странным, что мы показываем именно предупреждение и только в ответ на ввод карты, а не используем сразу при загрузке полноэкранную блокировку. Причина в том, что машина обучается выявлять сайты, на которых есть риск потери денег, и блокировать доступ ко всей информации было бы неправильно. К тому же вероятность ложноположительных вердиктов никогда не равна нулю.Если вы дочитали до конца, то уже знаете, что с фишингом можно (и нужно) бороться с помощью совершенно разных технологий. К сожалению, далеко не все зависит только от них. Знания и опыт самих пользователей во многом определяют их уязвимость перед злоумышленниками. Но мы верим, что если привлекать внимание к проблеме, рассказывать об угрозах на уровне предупреждений, объяснять средствами Браузера, почему важно использовать разные пароли и не стоит вводить номера карт на сайтах без шифрования, то в конечном счете люди начнут с большей осторожностью относиться к своей работе в сети.
habrahabr.ru
Усмирение Яндекс.Браузера / Песочница / Хабрахабр
Я немножко консервативен по натуре. Когда мимо пробегает толпа с криками «как же это круто!» – самое время выпить чашечку чая и лениво отследить траекторию движения.Потому в свое время долго сидел на браузере Opera – том, что позже назвали Classic. Все еще живы теплые воспоминания про браузер времен медленного нестабильного интернета, когда Опера умела «показывать только кэшированную графику», а также позволяла легко отключать и включать Flash.
Прощание с Opera Classic началось тогда, когда в Яндекс.Браузере появились «оперные» жесты мышью. Это был Chrome, но Хром симпатичный, свой, родной, пушистый.
«И дальше жили они долго и счастливо».
Стоп.
Не всегда долго и счастливо. Скажем, идиотская затея по включению в состав браузера антивируса. «Железной рукой загоним человечество к счастью» и замечательный ответ техподдержки «вы же можете его отключить». Ну да, могу. Впрочем, кто старое помянет… И кто старое забудет…
С другой стороны, реализованы совершенно приятные вещи. Реализация вынесенного видео – как в Опере, но лучше. Возможность без лишних телодвижений устанавливать расширения из магазина Оперы. Жесты – да, жесты! Переводчик – не без странностей, но работает.
Вот только в последние месяцы начал замечать, что браузер мешает работать. Самое неприятное начиналось, если браузер закрыть – тогда он начинал мешаться по-настоящему, в тяжелых случаях терроризируя жесткий диск по несколько минут. Дисковый монитор навскидку показывал, что браузер усиленно пилит файл History. Поскольку это всегда происходит в самый ненужный момент – моего любопытства не хватило на дальнейшие наблюдения.
Через пару-тройку месяцев такого свинства я откровенно устал.
Все приложения, активно эксплуатирующие жесткий диск без моего позволения – вообще раздражают.
В свое время пришлось потратить время на выпиливание всевозможных задач Майкрософт из планировщика (регулярная отправка «телеметрии» в разгар рабочего дня), мало того, что software repository операционки регулярно обновляется с обширным пропилом жесткого диска, антивирус влезает со своим сканированием без спросу – так теперь еще и браузер своевольничает.
Народ говорит, что в Chromium-браузере можно отключить дисковый кэш ключом командой строки --disk-cache-dir=nul, но это не обнадежило — тем более, не могло решить проблему «попила» History.
Решил тряхнуть стариной и вспомнить времена УКНЦ – искать спасение в RAM-диске.
Воспользовался ImDisk'ом, настроил монтаж образа RAM-диска (объемом 1 Гб) при входе в систему и регулярное сохранение содержимого диска в образ (одного раза в два часа оказалось достаточно). Прописал в ярлыке запуска ключ командной строки browser.exe --user-data-dir=«RAMdrive:\User Data».
Все бы хорошо, но при открытии гиперссылок из внешних приложений браузер запускался с параметрами по умолчанию, обнаруживал отсутствие профиля – и радостно создавал профиль в каталоге пользователя.
Хорошо, пробежимся по реестру и пропишем ключ --user-data-dir. Прописать придется не в одном и не в трех местах – для Яндекс.Браузера таких мест однозначно больше. Больше, чем в Хроме. Устав перебирать, прописал везде, где нашел — в двадцати местах.
Но после очередного обновления Браузера – установщик затрет значения на дефолтные.
Оказалось проще создать символьную ссылку для каталога RAMdrive:\User Data, чтобы браузер видел содержимое RAM-диска там, где профиль размещается по умолчанию –%userprofile%\AppData\Local\Yandex\YandexBrowser\User Data.
Итак, что мы имеем общего для Яндекс.Браузера и Google Chrome:
1. Нельзя выбрать путь для установки. 2. Нельзя настроить расположение профиля пользователя в установках. 3. Нет документированной возможности отключения дискового кэша.
Это тянется год за годом — и, похоже, разработчики не собираются идти навстречу редким воплям. Кушайте, что дают.
Чем отличается в худшую сторону Яндекс.Браузер от Google Chrome в моем ограниченном опыте? Интенсивнее работает с жестким диском. Правда, Chrome я использую гораздо реже, на меньшем количестве сайтов. Но никогда не замечал за Хромом скрытых процессов, занимающихся чем-то после закрытия программы.
В результате манипуляций жить с Яндекс.Браузером стало лучше, веселее.
Но как же это грустно, что браузер для широких масс трудящихся, программа, которую может установить любой чайник, для гладкой работы на среднестатическом компьютере – требует магических пассов с RAM-диском и настройками.
Господа, это не народно.
И скажите, что же вы там делаете после закрытия Браузера, и почему именно этот момент запуска выбран самым подходящим?
habrahabr.ru
с технологией Турбо от Opera Software / Блог компании Яндекс / Хабрахабр
Сегодня мы выпускаем значительное обновление Яндекс.Браузера. На самом деле, с момента его релиза в начале октября было уже четыре апдейта. Они включали в себя критические багфиксы, в том числе и устранение существовавших уязвимостей. Главное, что появляется в Браузере 1.1 — технология Opera Turbo, о которой, в частности, на YaC 2012 рассказывал и CTO Opera Software Хакон Виум Ли.Режим Турбо позволяет в разы быстрее загружать страницы при низкой скорости интернет-соединения. Наш браузер стал первым после выпущенного самой Opera Software, в котором используется эта технология.

В прошлом смысл разработок, которые ускоряют доступ к вебу на медленных каналах, был очевиден всем: интернет-соединения были низкоскоростными и нестабильными. Многие до сих пор помнят, сколько нервов можно было потратить, дозваниваясь до своего провайдера и по несколько раз выслушивая писк модема, который пытался подключиться к сети на скорости в целых 56 килобит. А чаще — ниже.
Но в наши дни в Сети уже много тех, кто этого не застал. Средняя скорость соединения по стране превысила 10 мегабит, и быстрый интернет довольно резко стал нормой. Казалось, что такой проблемы, как низкая скорость, больше не будет.
Всё в жизни становилось быстрее и мобильнее. Это относится и к десктопам, которые в действительности давно стали лэптопами. Людям захотелось, чтобы доступ к сайтам у них был не только дома и в офисе, но и в метро, в парке под деревом, на вершине горы — везде.
С одной стороны, это очень удобно, но с другой — возвращает нас в тёмные времена медленного интернета. Когда мы говорим о мобильном соединении, то уже давно подразумеваем выход в Сеть не только для мобильных устройств, но и для ноутбуков. А его качество очень разное не только по стране, но и внутри Москвы. Иногда оно даже не уступает домашнему Wi-Fi, а иногда — сравнивается с публичными беспроводными сетями. Последние, к тому же, часто бывают не очень грамотно настроены, что тоже ведёт к снижению скорости соединения.
И в таких ситуациях Турбо поможет сэкономить немного времени и много нервов. Если Яндекс.Браузер заметит, что скорость соединения меньше 128 кбит/с, он автоматически включит этот режим, а когда она станет выше 512 Кбит/с — выключит.
Сам Турбо работает по следующей схеме: — весь текст html-страниц архивируется с помощью gzip; — изображения на странице анализируются и тяжёлые картинки переводятся из jpeg в WebP; — всё это отдаётся пользователям по быстрому протоколу SPDY.
Если говорить в двух словах, то эта технология отправляет часть трафика через прокси-сервер, который загружает страницу по быстрому каналу, сжимает и быстро отдаёт вам.
Благодаря тому, что всё идёт через прокси-сервера Турбо, мы можем поддерживать для соединения keepalive. Это особенно важно на медленных каналах: при низкой скорости затраты на то, чтобы каждый раз заново открывать соединение для загрузки чего-либо, могут быть очень ощутимыми.
Но даже при включённом Турбо, страницы, открывающиеся по HTTPS, будут делать это напрямую — без прокси-сервера. Это важно, например, для соединения с почтовыми сервисами и платёжными системами. То же самое и с интранетом — все данные из внутренних сетей будут отображаться в Браузере напрямую.
Как будет включаться режим, можно решать самому. Если в какой-то ситуации вы понимаете, что ваше соединение долгое время будет медленным, можно вручную включить Турбо и самому потом выключить. Браузер может переключаться в режим автоматически, но можно и запретить ему это делать.

В любом случае, когда Яндекс.Браузер поймёт, что скорость соединения не превышает 128 Кбит/с в течение достаточного времени, то предложит вам включить Турбо. Он удобен уже тем, что будет блокировать загрузку тяжёлого содержимого и экономить трафик, который на медленных каналах может влиять на стоимость подключения.
Постепенно Яндекс.Браузер сам обновится у всех пользователей до версии с Турбо. Но вы можете установить её самостоятельно, загрузив на browser.yandex.ru.
habrahabr.ru

|
|
..:::Счетчики:::.. |
|
|
|
|
|
|
|
|