
|
|
|
|
 Far Far |
| WinNavigator |
| Frigate |
| Norton
Commander |
| WinNC |
| Dos
Navigator |
| Servant
Salamander |
| Turbo
Browser |
|
|
| Winamp,
Skins, Plugins |
| Необходимые
Утилиты |
| Текстовые
редакторы |
| Юмор |
|
|

|
File managers and best utilites |
Web Scraping с помощью python. Python эмуляция браузера
Web Scraping с помощью python / Хабрахабр
Введение
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков? Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье. В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
Задача будет состоять в том, чтобы выгрузить данные о просмотренных фильмах на КиноПоиске: название фильма (русское, английское), дату и время просмотра, оценку пользователя. На самом деле, можно разбить работу на 2 этапа:- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
Для отправки http-запросов есть немало python-библиотек, наиболее известные urllib/urllib2 и Requests. На мой вкус Requests удобнее и лаконичнее, так что, буду использовать ее. Также необходимо выбрать библиотеку для парсинга html, небольшой research дает следующие варианты:- re Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним.
- BeatifulSoup, lxml Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html.
- scrapy Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.import requests user_id = 12345 url = 'http://www.kinopoisk.ru/user/%d/votes/list/ord/date/page/2/#list' % (user_id) # url для второй страницы r = requests.get(url) with open('test.html', 'w') as output_file: output_file.write(r.text.encode('cp1251')) Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.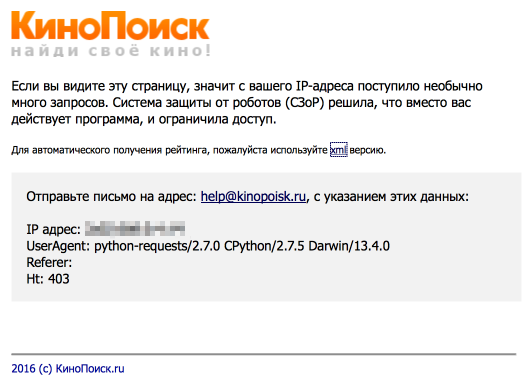
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью "Сеть" в "Инструментах разработчика" в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.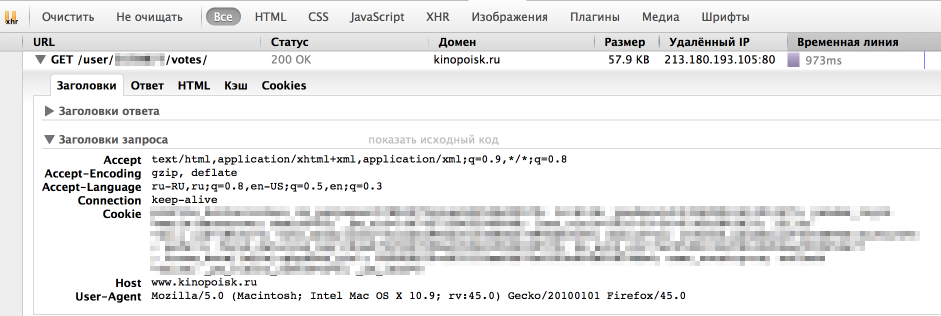
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0' } r = requests.get(url, headers = headers) На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.Скачаем все оценки
Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPathfrom lxml import html test = ''' <html> <body> <div> <h3 align='center'>one</h3> <h3 align='left'>two</h3> </div> <h3>another tag</h3> </body> </html> ''' tree = html.fromstring(test) tree.xpath('//h3') # все h3 теги tree.xpath('//h3[@align]') # h3 теги с атрибутом align tree.xpath('//h3[@align="center"]') # h3 теги с атрибутом align равным "center" div_node = tree.xpath('//div')[0] # div тег div_node.xpath('.//h3') # все h3 теги, которые являются дочерними div ноде Подробнее про синтаксис XPath также можно почитать на W3Schools.Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию "Инспектировать элемент" в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге <div class = "profileFilmsList">. Выделим эту ноду:from bs4 import BeautifulSoup from lxml import html # Beautiful Soup soup = BeautifulSoup(text) film_list = soup.find('div', {'class': 'profileFilmsList'}) # lxml tree = html.fromstring(text) film_list_lxml = tree.xpath('//div[@class = "profileFilmsList"]')[0] Каждый фильм представлен как <div class = "item"> или <div class = "item even">. Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).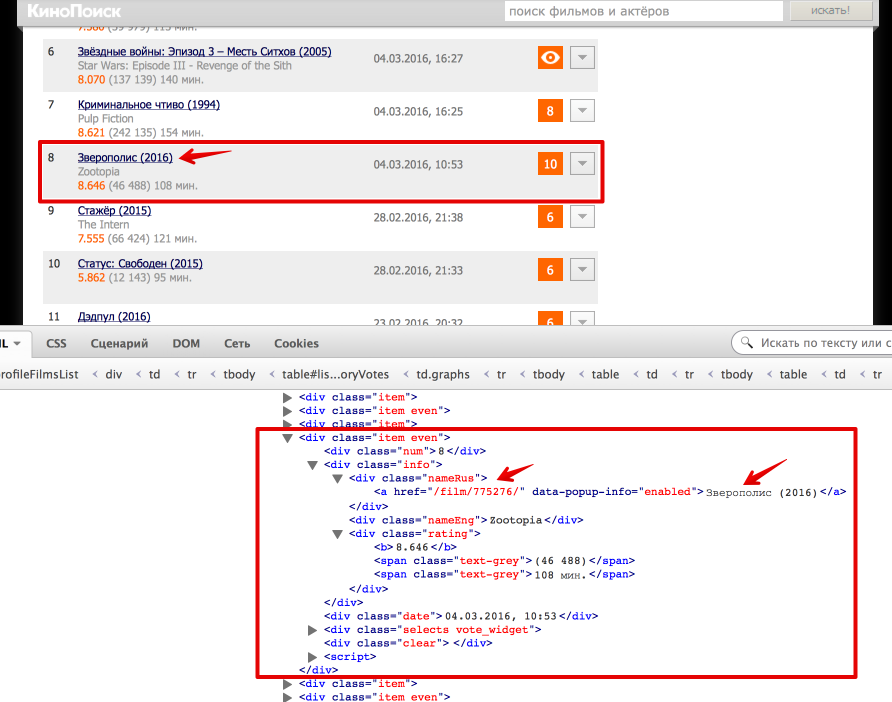
Резюме
В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске. 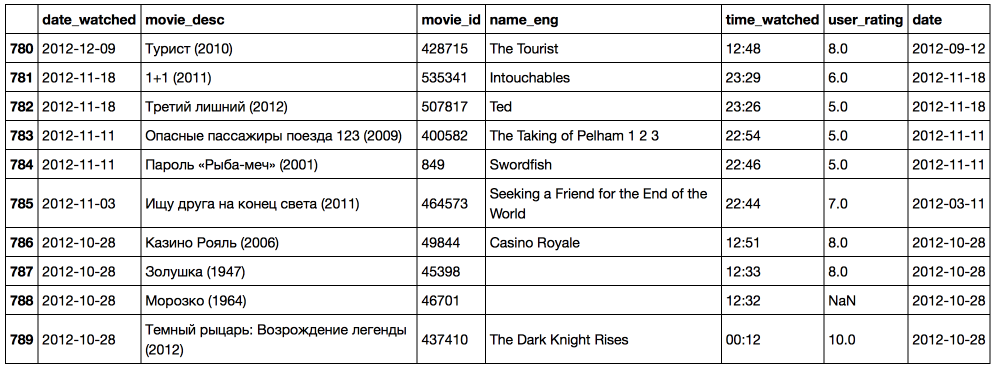 Полный код проекта можно найти на github'e.
Полный код проекта можно найти на github'e.UPD
Как отметили в комментариях, в контексте Web Scrapping'a могут оказаться полезны следующие темы:- Аутентификация: зачастую для того, чтобы получить данные с сайта нужно пройти аутентификацию, в простейшем случае это просто HTTP Basic Auth: логин и пароль. Тут нам снова поможет библиотека Requests. Кроме того, широко распространена oauth3: как использовать oauth3 в python можно почитать на stackoverflow. Также в комментариях есть пример от Terras того, как пройти аутентификацию в web-форме.
- Контролы: На сайте также могут быть дополнительные web-формы (выпадающие списки, check box'ы итд). Алгоритм работы с ними примерно тот же: смотрим, что посылает браузер и отправляем эти же параметры как data в POST-запрос (Requests, stackoverflow). Также могу порекомендовать посмотреть 2й урок курса "Data Wrangling" на Udacity, где подробно рассмотрен пример scrapping сайта US Department of Transportation и посылка данных web-форм.
habrahabr.ru
Selenium - эмуляция действий в браузере
Selenium - эмуляция действий в браузере

В предыдущих статьях я писал о том, как парсить различные сайты с помощью библиотек requests и beautiful soup. Но иногда нам нужно не просто спарсить сайт, а эмулировать действия пользователя на нём - нажимать на какие-то ссылки, проходить авторизацию, заполнять формы. В этом случае нам пригодится модуль Selenium. Сперва установим сам модуль: pip install selenium Кроме того, нам понадобится заранее установленный браузер Mozilla Firefox и специальная программа-драйвер для Firefox. Этот драйвер доступен как для Windows, так и для Linux. Драйвер нужно скачать и кинуть в папку с вашим скриптом, в котором вы собираетесь использовать Selenium. Скачать драйвер можно здесь После того как вы установили Selenium, и скачали драйвер в папку, где будет ваш скрипт, можно начинать писать программу. Сперва давайте просто откроем какой-либо сайт в Firefox через драйвер Selenium

pythono.ru
python - Эмулировать браузер для загрузки файла?
Прежде всего, если вы пытаетесь выполнить какие-либо выскабливания (да, это считается соскабливанием, даже если вы не обязательно разбираете HTML), у вас есть определенное предварительное исследование.
Если у вас еще нет Firefox и Firebug, получите их. Тогда, если у вас еще нет Chrome, получите его.
Запустите Firefox/Firebug и Chrome, очистите все ваши файлы cookie/etc. Затем откройте Firebug, а в Chrome запустите View- > Developer- > Developer Tools.
Затем загрузите основную страницу видео, которое вы пытаетесь захватить. Обратите внимание на любые файлы cookie/заголовки/POST-переменные/строковые переменные запроса, которые устанавливаются при загрузке страницы. Возможно, вы захотите сохранить эту информацию.
Затем попробуйте загрузить видео еще раз, обратите внимание на любые файлы cookie/headers/post variables/query string, которые устанавливаются при загрузке видео. Весьма вероятно, что при первоначальной загрузке страницы была указана переменная cookie или POST, которая требуется для фактического вытягивания видеофайла.
Когда вы пишете свой питон, вам нужно будет как можно ближе подражать этому взаимодействию. Используйте python-requests. Вероятно, это самая простая библиотека URL-адресов, и если вы не столкнетесь с ней как-то с ней (что-то, чего она не может сделать), я бы никогда больше ничего не использовал. Во-вторых, я начал использовать python-requests, весь код для извлечения URL уменьшился в 5 раз.
Теперь, возможно, вы не будете работать в первый раз, когда вы их попробуете. Soooo, вам нужно будет загрузить основную страницу с помощью python. Распечатайте все ваши файлы cookie/заголовки/переменные POST/переменные строки запроса и сравните их с тем, что было у Chrome/Firebug. Затем попробуйте загрузить свое видео, еще раз, сравните все эти значения (это означает, что вы отправили сервер, и то, что SERVER также отправил вам обратно). Вам нужно будет выяснить, что между ними (не волнуйтесь, мы ВСЕ узнали об этом в детском саду... "одна из этих вещей не похожа на другую" ) и проанализируйте, как эта разница разрушает материал.
Если по окончанию всего этого вы все равно не сможете понять, тогда вам, вероятно, нужно будет взглянуть на HTML-страницу, содержащую ссылку на фильм. Посмотрите на любой javascript на странице. Затем используйте Firebug/Chrome Developer Tools, чтобы проверить javascript и посмотреть, выполняет ли он какое-то управление вашей пользовательской сессией. Если он каким-то образом генерирует токены (файлы cookie или POST/GET), связанные с доступом к видео, вам нужно будет эмулировать его метод токенизации в python.
Надеюсь, все это поможет, и не выглядит слишком страшно. Ключ в том, что вам нужно быть ученым. Выясните, что вы знаете, что вы не делаете, что хотите, и начинайте экспериментировать и записывать свои результаты. В конце концов появится шаблон.
Изменить: Уточнить шаги
- Изучите, как поддерживается состояние.
- Вытащить исходную страницу с помощью python, захватить любую информацию о состоянии, которая вам нужна от нее.
- Выполнить любой токенинг, который может потребоваться с этой информацией о состоянии
- Потяните видео, используя маркеры из шагов 2 и 3
- Если материал взрывается, выведите заголовки запроса/ответа, файлы cookie, vars запросов, post vars и сравните их с Chrome/Firebug.
- Вернитесь к шагу 1. пока не найдете решение
Edit: Вы также можете перенаправляться по одному из этих запросов (страница html или загрузка файла). Скорее всего, вы пропустите запрос/ответ в Firebug/Chrome, если это произойдет. Решением было бы использовать сниффер, например LiveHTTPHeaders, или, как было предложено другими респондентами, WireShark или Fiddler. Обратите внимание, что Fiddler не принесет вам пользы, если вы находитесь в Linux или OSX. Это только Windows и определенно ориентирована на .NET-разработку... (ugh). Wireshark очень полезен, но перегружен для большинства проблем, и в зависимости от того, на какой машине вы работаете, у вас могут возникнуть проблемы с его работой. Поэтому я бы предложил сначала LiveHTTPHeaders.
Мне нравится эта проблема
qaru.site

|
|
..:::Счетчики:::.. |
|
|
|
|
|
|
|
|