abbyy finereader что это. Abbyy finereader это
Abbyy finereader что это — для чего нужен Abbyy FineReader? — 22 ответа
Abbyy finereader это
В разделе Компьютеры, Связь на вопрос для чего нужен Abbyy FineReader? заданный автором Bacha лучший ответ это Если не нужен - стирай смело, к работе сканера он отношения не имеет.Он нужен для того, что бы картинку ( включая pdf) перевести в текст.
Ответ от 22 ответа[гуру]Привет! Вот подборка тем с ответами на Ваш вопрос: для чего нужен Abbyy FineReader?
Ответ от Squall[гуру]для распознпния текстов
Ответ от Миха'ил Zoom'ов[новичек]Проще говоря чтобы текст на изображении перевести в текст для редактирования....Актуально для тех у кого есть сканер...
Ответ от Николай Доля[гуру]Программа для работы со сканером. Если к компу не подключен сканер, можешь стереть. Без сканера она тебе не нужна.
Ответ от Ёергей Куделькин[гуру]Если у тебя нет сканера то она тебе не нужна
Ответ от БОРО-ДА[гуру]FineReader - одна из лучших, признанных во всём мире программа распознавания текстов. Берёте статью, напечатанную в журнале или текст, отпечатанный на принтере, запихиваете это в сканер, пропускаете через Файнридер и на выходе получаете текстовый документ в формате от *.txt до *.doc или *.rtf. Далее поступаете с ним по собственному усмотрению. Можете просто хранить в одном из этих форматов, а не как графический файл, который занимает много места, а можете - отредактировать в том же Word-е.Есть аналог Файнридера - OmnyPage от не помню какого зарубежного изготовителя. Но, аналог более слабый.
Ответ от Mary Fine[гуру]Если не сканируешь тексты - сотри. Даже не заметишь...
Ответ от Yaroslav Panych[гуру]Abbyy FineReader - приложание которое реализует систему оптического распознания текстов (OCR). если проще, то эта програмка позволяет отсканированый(или сфотканый) документ, книгу газету(да все что угодно) сохранить в формате, пригодном для редактирования текста, т.е. не рисунком, а например Вордовским документом. Делает он это просто: у него есть грубо говоря табличка: буква(цифра, знак)<=> ее графический образ. Прога проходит по всему рисунку и сравнивает елементарные кусочки с образами. Тот образ, который самый похожий оно записует в документ уже как букву. При это прога запоминает размеры букв, положение на странеце, подчеркнутость, зачеркнутоть и т.д. т.е. прога работае почти также как это делает человеческий мозг, только вомного раз медленее. К сожалению рукописи таким образом не распознаются, так как нету возможности хранить все рукописные образа(места очень много занимают) Также распознает структурирувану запись(таблицы списки). Есть возможность вручную указать какие области рисунка как фоспринивать(рисунком, таблицей, текст)
Привет! Вот еще темы с нужными ответами:
ABBYY FineReader на ВикипедииПосмотрите статью на википедии про ABBYY FineReader
Ответить на вопрос:
22oa.ru
Как мы сделали ABBYY FineReader, или история, произошедшая 20 лет назад / Блог компании ABBYY / Хабр
 ABBYY FineReader – программа для распознавания текстов, которая в России известна многим ещё со студенческих времён. В этом году FineReader исполняется 22 года, он немного моложе нашего словаря Lingvo. Как так вышло, что вместе со словарём молодые программисты из BIT Software (в то время ABBYY называлась именно так) занялись распознаванием текстов? И что помогло Файну стать одной из самых узнаваемых на рынке программ?
ABBYY FineReader – программа для распознавания текстов, которая в России известна многим ещё со студенческих времён. В этом году FineReader исполняется 22 года, он немного моложе нашего словаря Lingvo. Как так вышло, что вместе со словарём молодые программисты из BIT Software (в то время ABBYY называлась именно так) занялись распознаванием текстов? И что помогло Файну стать одной из самых узнаваемых на рынке программ?В Lingvo Systems были объединены четыре программы: от сторонних компаний — распознавалка символов, корректор, переводчик, а также наш словарь Lingvo. И самым слабым звеном было как раз распознавание: программу нужно было долго обучать каждому шрифту, но даже после этого качество оставляло желать лучшего. Программа должна была встретить по крайней мере несколько экземпляров одной буквы и каждый раз нуждалась в подсказке. Понемногу она «прозревала» и начинала понимать все больше символов. Так проходил процесс обучения. Но как только менялся шрифт или хотя бы его размер, все приходилось повторять сначала.
Стоит сказать, что тогда, в начале 90-х, в организациях, отпочковавшихся от различных НИИ, уже начали разрабатывать свои OCR-системы (оптическое распознавание символов). Это была довольно востребованная технология – качественное распознавание было нужно не только нам для нашей Lingvo Systems, но и рынку. И у нас был выбор – ждать, пока кто-то другой сделает крутую программу, или разработать свою собственную.
Мы решили не ждать. Конечно, задача казалась нетривиальной: проблемой распознавания символов занимались целые научные институты, а у нас такого опыта не было. Но мы были молоды и амбициозны, считали, что любые задачи нам по плечу, поэтому с энтузиазмом взялись за разработку качественной программы.
Начали создавать программу мы в ноябре 1992 года, а закончить планировали к маю 1993. Отсутствие качественной программы распознавания существенно мешало продажам, конкуренты не дремали, поэтому нам надо было спешить. Понимая, что разработать всю технологию с нуля в такой срок невозможно, приобрели некоторые наработки у молодого учёного, который в свободное время дома работал над похожей программой – без особой цели, просто из личного интереса к предмету.
Его технология была в состоянии, далёком от коммерческого применения, и мы приложили массу усилий, чтобы программа научилась выдавать полезный результат. Одно дело – экспериментальная разработка, другое – работающий продукт. Исходно код программы был разработан под MS DOS, а нам нужно было перенести все под Windows. Кроме того, технология поддерживала лишь один простейший формат изображений (несжатый BMP), а от коммерческого продукта требовалась поддержка всех основных на тот момент форматов – хотя бы формата TIFF. Но в те времена это был очень неустоявшийся формат, каждый его писал, как хотел: то с выравниванием, причем разным, то без, то в прямом варианте, то в негативе. В общем, пришлось повозиться, и все равно еще долго находились файлы TIFF, которые вызывали проблемы с чтением.
Ну и самое главное: в системе практически не было готовых описаний символов, а инструменты для создания этих описаний отсутствовали вовсе. В качестве такого инструмента использовался набор больших текстовых файлов, в которых в псевдографическом виде были прочерчены обобщенные контуры символов. Их полагалось править и улучшать прямо в этом файле в обычном текстовом редакторе. В какой-то момент Давид Ян лично сел за подготовку данных для системы – до этого несколько девушек, нанятых на эту работу, отказались от неё, очень тяжело было. Инструмент был очень неудобный, а работа была большая, сложная и очень нудная. Надо было часами листать огромные текстовые файлы, что-то там высматривать и править, изучая результаты тестовых прогонов. Работа казалась вечной, прогресс происходил мелкими шажками. Нужна была крепкая психика, чтобы справляться с этим. И Давид два месяца без выходных каждый день по 12-14 часов доводил до ума базу распознавания.
Параллельно с этим мы начали вникать в предметную область. Общались со специалистами, познакомились с Александром Львовичем Шамисом – выдающимся учёным, который занимался практическими и теоретическими проблемами искусственного интеллекта, разрабатывал прикладные технологии в области машинного восприятия (Александр Львович до сих пор работает научным консультантом в ABBYY). И к моменту выпуска FineReader 1.0 мы уже знали, какой должна быть следующая версия. Вы спросите, почему всё то хорошее, что мы придумали, не вошло в первую версию – мы ответим, что первую версию нужно было делать быстро. Компании нужны были деньги – без первой версии у нас бы не хватило денег на разработку следующей. Следующая версия была существенно лучше первой – даже не на голову, а на много голов. Она делала значительно меньше ошибок, намного лучше справлялась со сложными проблемами, существенно лучше сохраняла форматирование и по тем временам имела просто рекордную точность работы.
Конечно, мы подошли к разработке с умом, представили себе, как должна выглядеть идеальная программа. И у нас сразу сложилось два преимущества – независимость от шрифта и многоязычность.
С многоязычностью всё просто: очевидно, что многие технические тексты, даже написанные на русском, содержат довольно много слов и терминов на латинице, чаще всего на английском. Но в то время об этом почему-то никто не задумывался, и первые системы распознавания понимали только один язык. А мы специально включили в программу поддержку русского и английского языков, чтобы такие тексты можно было качественно обработать. Здесь нам помогло наличие в команде Владимира Селегея, который имел значительный опыт в разработке средств проверки правописания для различных языков. Вообще, с тех пор и поныне словарная поддержка является сильной стороной нашей технологии распознавания.
Независимость от шрифта (омнифонтовость) означает, что программу не нужно было настраивать для распознавания каждого нового шрифта, то есть она распознаёт символы практически любых размеров и начертаний. Наш FineReader был первой омнифонтовой программой, поддерживающей кириллицу. Сейчас-то мы уже привыкли, что, если программа не распознала шрифт, значит, он какой-то очень сложный или причудливый, а тогда даже для обычных книжных шрифтов приходилось проводить обучение. Шаг влево, шаг вправо – и программа не может воспринять даже тот шрифт, который вообще-то знает. Например, если он другого размера или качество изображения хуже.
Так выглядела коробка первого FineReader:


Сразу же после выпуска программы к ней возник огромный интерес. Спрос был большой, и существовавшие до появления FineReader программы его не удовлетворяли. Нам повезло — мы оказались в правильном месте и в правильное время.
Первая версия FineReader’а вышла тиражом 500 экземпляров. В первый месяц мы продали больше сотни копий – для тех времён это было эпохальное число! Даже продажи Lingvo, уже очень популярного в то время и стоившего в несколько раз дешевле, редко доходили до 100 экземпляров в месяц.
Конечно, нам предстояла еще большая работа, чтобы довести программу до высочайшего уровня. И, кстати, помогла нам в этом конкурентная борьба с одной из российских компаний. В результате в пылу жаркой конкуренции мы создали продукт, оказавшийся лучше многих иностранных аналогов.
Выпуск второй версии FineReader сопровождался ещё одной интересной историей. FineReader 2.0 был 32-битным приложением. Мы запланировали его выпуск на весну 1995 года, и собирались подгадать прямо под выпуск Windows 95 (ранее Microsoft объявляла, что новая версия Windows выйдет именно в апреле). Новая Windows выгодно отличалась от старой, мы понимали, что люди станут сразу делать апргейд и наши продажи пойдут в гору. Но при этом мы имели «запасной аэродром» в виде компоненты Win32s – дополнения к 16-битной Windows 3.1x, которая позволяла запускать под нее специально адаптированные 32-битные приложения. Но тут возникло одновременно две проблемы: Microsoft перенесла выпуск Windows 95 на август, а в Win32s версии 1.2 обнаружилась ошибка с поддержкой Unicode, из-за которой русские буквы в интерфейсе не отображались. Пришлось срочно связываться с Microsoft, что в то время было делом практически невозможным, – это был крупнейший монополист на рынке ПО, от которого зависело почти все в индустрии, и ожидать от него реакции на нужды небольшой компании в далекой России с мизерным для Microsoft рынком сбыта было бы безумием.
Но случилось чудо: та же проблема оказалась у компании Autodesk, которая была стратегическим партнером Microsoft. В результате нас с Autodesk объединили в один кейз и выделили специального менеджера, который вступил с нами в переписку. В результате удалось договориться, чтобы в версии 1.3, которая, правда, вышла одновременно с Windows 95, эту ошибку исправили. А до того мы нашли обходной вариант – полученная версия не работала корректно под Windows 95, зато работала до поры до времени в Windows 3.1x.
Так выглядел FineReader 1.3:


Вообще, наша рисковая затея с выпуском 32-битного коробочного продукта испортила нам много крови. 16-битная Windows была еще широко распространена, а Win32s не отличалась стабильностью. Помню, как почти неделю мы ловили какую-то жуткую ошибку в недрах самой Win32s с помощью отладчика ядра (kernel debugger) через com-порт в командно-строчном режиме. Нашли проблему – что-то неправильно работало в системном аллокаторе памяти, и смогли придумать обход. Зато новый FineReader блистал на Windows 95, будучи родным для него приложением, а 32-битный режим был очень важен для программы OCR, так как позволял значительно оптимизировать работу с большими данными в памяти, что типично для задач распознавания. Это дало нам фору на много лет вперед перед конкурентами и во многом предопределило наш успех на рынке лицензирования технологии распознавания.
А вот FineReader 2.0:


Программа загружалась с четырёх дискет:

Руководство пользователя:

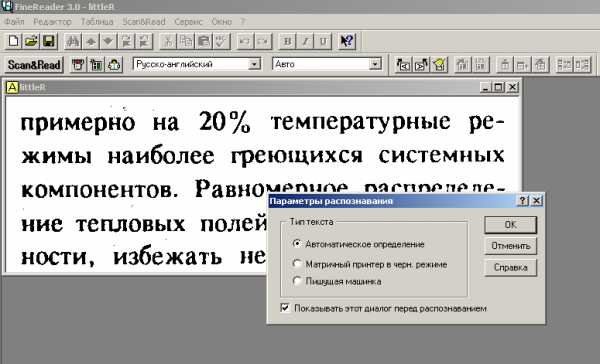
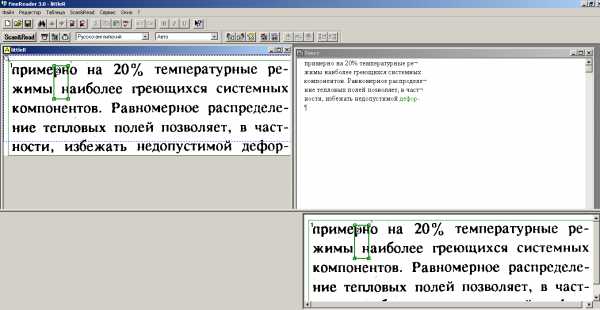
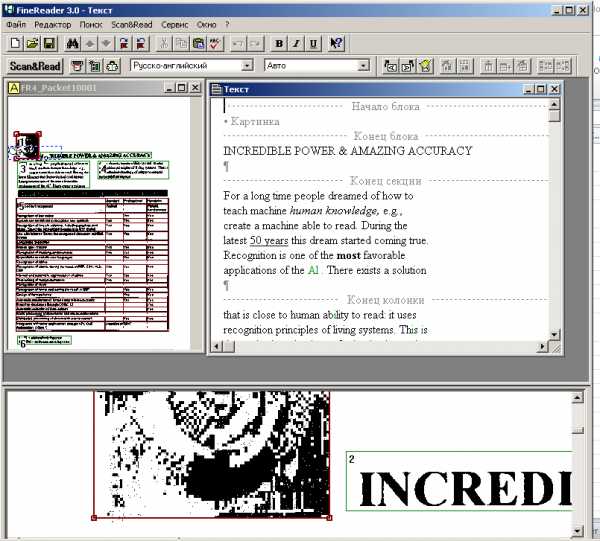
Конечно, вы ждёте скриншотов. Вот как выглядел интерфейс FineReader 3.0:
FineReader стал знаковой программой для нас. Именно с ним мы вышли на международный рынок. Сегодня эту программу используют более 20 миллионов людей в мире. А технологию распознавания текстов, лежащую в основе FineReader, лицензируют крупнейшие мировые компании – Microsoft, Samsung, Fujitsu, Panasonic и многие другие.
Тогда, 22 года назад, мы и предположить не могли, куда все зайдет. А сегодня понимаем, что добиться такого впечатляющего результата смогли благодаря:
• Большой и упорной работе. Да-да, из последних сил, но с колоссальным драйвом (помните про 12-14 часов в день без выходных ). • Умению найти и создать конкурентные преимущества – те самые многоязычность и независимость от шрифта. • И смелости. Теперь-то мы понимаем, как важно не бояться преград на пути.
habr.com
ABBYY — Википедия
Материал из Википедии — свободной энциклопедии
(перенаправлено с «Abbyy») Перейти к навигации Перейти к поиску Компания ABBYYТип Основание Расположение Ключевые фигуры Отрасль Продукция Число сотрудников Сайт| общество с ограниченной ответственностью[d] | |
| 1989 | |
| Россия | |
| Давид Ян (основатель) Ульф Перссон (ген. директор ABBYY) Дмитрий Шушкин (ген. директор ABBYY Россия)[1] | |
| программное обеспечение | |
| технологии оптического распознавания символов, технологии интеллектуальной обработки информации, системы потокового ввода документов и данных, электронные словари | |
ru.wikipedia.org
ABBYY FineReader 12
ABBYY- Contacts
- Store
-
Select Region
Global Global Web Site English North America Canada English Mexico Español United States English South America Brazil Português South America Español
Europe
France Français Germany Deutsch Italy Italiano United Kingdom English Spain Español Western Europe English Central and Eastern Europe English Croatia Hrvatski Czech Republic Čeština Hungary Magyar Poland Polski Romania Română Russia Русский Slovakia Slovenčina Ukraine Українська Africa and Asia China 中文 India and SEA Countries English Israel עברית Japan 日本語 Middle East English South Korea 한국어 Turkey Türkçe Australia Australia English
www.abbyy.com
Программа распознавания текста при сканировании
Abbyy FineReader – это широко известная программа распознавания текста при сканировании. На сегодняшний день она является наиболее популярной благодаря понятному и удобному интерфейсу, большому набору всевозможных функций, связанный со сканированием и работой с готовым документом, а также удобством в использовании.
При помощи Abbyy FineReader можно:
- Переводить изображения, сканы, PDF-файлы, фотографии в другие форматы, например, конвертировать их в таблицы и тексты без необходимости набирать текст заново. При этом распознаются многие форматы изображений, а форматирование текста часто остаётся не тронутым.
- Работать со множеством самых разных языков. В последней версии Abbyy FineReader их было уже 42.
- Конвертировать разнообразные форматы изображений, PDF-файлы и другие документы в электронные книги.
- Осуществлять машинный перевод с 30 языков мира.
- Направить копию в один из выбранных редакторов. Среди них популярные PowerPoint, OpenOffice, WordPerfekt, Org Writer, Adobe Acrobat, MS Excel и
- Экспортировать файлы в облачные хранилища по вашему выбору.

Помимо широкого функционала эта программа распознавания текста при сканировании выпускается более, чем на 170 языках мира, в том числе и на русском. Скорость и эффективность работы, особенно в самой новой версии Abbyy FineReader, удивительны. А улучшенный редактор изображений позволяет сделать предварительную обработку сканов и фотографий. Можно по своему желанию добавить или снизить яркость и контрастность, интенсивность теней и освещения, скорректировать погрешности, допущенные камерой. Это позволит как можно точнее распознать текст и области рисунков.
Удобный и понятный даже впервые столкнувшемуся с программой человеку интерфейс, делает её незаменимым помощником как на рабочем месте, так и дома. Открывайте для себя новые возможности вместе с Abbyy FineReader!
abbyyfinereader.ru
PDF Software with Text Recognition
ABBYY- Contacts
- Store
-
Select Region
Global Global Web Site English North America Canada English Mexico Español United States English South America Brazil Português South America Español
Europe
France Français Germany Deutsch Italy Italiano United Kingdom English Spain Español Western Europe English Central and Eastern Europe English Croatia Hrvatski Czech Republic Čeština Hungary Magyar Poland Polski Romania Română Russia Русский
www.abbyy.com
PDF Software with Text Recognition
ABBYY- Contacts
- Store
-
Select Region
Global Global Web Site English North America Canada English Mexico Español United States English South America Brazil Português South America Español
Europe
France Français Germany Deutsch Italy Italiano United Kingdom English Spain Español Western Europe English Central and Eastern Europe English Croatia Hrvatski Czech Republic Čeština Hungary Magyar Poland Polski Romania Română Russia Русский
www.abbyy.com
- Как сменить пароль на ноутбуке виндовс 10 при включении

- Сложные пароли на телефон

- Hosts что такое

- Powershell where несколько условий

- Что значит роуминг

- Вернуть ярлыки на рабочий стол
- Очистить кэш браузера опера

- Перевод wifi
- Как узнать все о человеке по ip

- Как называется шлюзовой компьютер который выполняет защитную роль
- Прога для удаленного доступа к чужому компьютеру