Cast sql функция: SQL Server функция CAST — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Содержание
Поддерживаемые функции стандарта SQL — Портал документации Picodata
Приведенный ниже перечень функциональности планировщика отражает соответствие SQL Broadcaster в Picodata требованиями стандарта SQL:2016, а именно ISO/IEC 9075 «Database Language SQL» (Язык баз данных SQL).
E011. Числовые типы данных
E011-01. Типы данных INTEGER и SMALLINT (включая все варианты написания).
Подпункт 5.3, Установка знака для беззнакового целого
E011-02. Типы данных REAL, DOUBLE PRECISION и FLOAT
Подпункт 5.3, Установка знака для приблизительного числового литерала
Подпункт 6.1, Округление числового типа
E011-03. Типы данных DECIMAL и NUMERIC
Подпункт 5.3, Литералы точных чисел
E011-05. Числовые сравнения
Подпункт 8.2, Поддержка числовых типов данных, без учета табличного подзапроса и без поддержки Feature F131, «Групповые операции»
E011-06. Неявное приведение числовых типов данных
Подпункт 8.2, Значения любых числовых типов данных можно сравнивать друг с другом; такие значения сравниваются по отношению к их алгебраическим значениям
Подпункт 9. 1, «Назначение получения» и Подпункт 9.2, «Назначение хранения»: Значение одного числового типа можно назначать другому типу с возможным округлением, отсечением и учётом условий вне диапазона.
1, «Назначение получения» и Подпункт 9.2, «Назначение хранения»: Значение одного числового типа можно назначать другому типу с возможным округлением, отсечением и учётом условий вне диапазона.
E021. Типы символьных строк
E021-01. Символьный тип данных (включая все варианты написания)
Подпункт 6.1, Соответствие типа CHARACTER лишь одному символьному типу
Подпункт 13.5, Использование символьного типа CHARACTER для всех поддерживаемых языков
E021-03. Символьные литералы
Подпункт 5.3
E021-07. Конкатенация символов
Подпункт 6.29, Выражение конкатенации
E021-12. Сравнение символов
Подпункт 8.2, Поддержка типов CHARACTER и CHARACTER VARYING, не включая поддержку табличных подзапросов и без поддержки Feature F131, «Групповые операции»
E031. Идентификаторы
E031-02. Идентификаторы в нижнем регистре
Подпункт 5.2, Алфавитный символ в обычном идентификаторе может быть как строчным, так и прописным (т.е. идентификаторы без разделителей не обязательно должны содержать только буквы верхнего регистра)
идентификаторы без разделителей не обязательно должны содержать только буквы верхнего регистра)
E031-03. Символ нижнего подчеркивания в конце
Подпункт 5.2, Последний символ в обычном идентификаторе может быть символом подчеркивания.
E051. Спецификация базовых запросов
E051-05. Элементы в списке выборки можно переименовывать
Подпункт 7.12, «Спецификация запросов»: как в заголовке пункта
E051-07. Допускается использование * в квалификаторе для списка выборки
Подпункт 7.12, «Спецификация запросов»: символ умножения
E051-08. Корреляционные имена в предложении FROM
Подпункт 7.6, «Ссылка на таблицу»: [ AS ] в качестве корреляционного имени
E061. Базовые предикаты и условия поиска
E061-01. Предикат сравнения
Подпункт 8.2, «Предикат сравнения»: Для поддерживаемых типов данных, без поддержки табличных подзапросов
E061-02. Предикат BETWEEN
Подпункт 8.3, «Предикат BETWEEN»
E061-03.
 Предикат IN со списком значений
Предикат IN со списком значений
Подпункт 8.4, «Предикат in»: Без поддержки табличных подзапросов
E061-06. Предикат NULL
Подпункт 8.8, «Предикат null»: Не включая Feature F481, «Расширенный предикат NULL»
E061-09. Подзапросы в предикате сравнения
Подпункт 8.2, «Предикат сравнениe»: Включая поддержку табличных подзапросов
E061-11. Подзапросы в предикате IN
Подпункт 8.4, «Предикат in»: Включая поддержку табличных подзапросов
E061-14. Условие поиска
Подпункт 8.21, «Условие поиска»
E071. Базовые выражения с запросами
E071-02. Табличный оператор UNION ALL
Подпункт 7.13, «Выражение с запросом»: Включая поддержку UNION [ ALL ]
E071-03. Табличный оператор EXCEPT DISTINCT
Подпункт 7.13, «Выражение с запросом»: Включая поддержку EXCEPT [ DISTINCT ]
E071-05. Столбцы, совмещенные с помощью табличных операторов, необязательно должны иметь идентичный тип данных
Подпункт 7. 13, «Выражение с запросом»: Столбцы, совмещенные с помощью UNION и EXCEPT, необязательно должны иметь идентичный тип данных
13, «Выражение с запросом»: Столбцы, совмещенные с помощью UNION и EXCEPT, необязательно должны иметь идентичный тип данных
E071-06. Табличные операторы в подзапросах
Подпункт 7.13, «Выражение с запросом»: В табличных подзапросах можно указывать UNION и EXCEPT
E101. Базовая обработка данных
E101-01. Инструкция INSERT
Подпункт 14.11, «Инструкция INSERT»: Когда конструктор контекстно типизированного табличного значения может состоять не более чем из одного контекстно типизированного выражения значения строки
E111. Инструкция SELECT, возвращающая одну строку
Подпункт 14.7, «Инструкция select: одна строка»: Не включая поддержку Feature F131, «Групповые операции»
E131. Поддержка значения NULL (NULL вместо значений)
Подпункт 4.13, «Столбцы, поля и атрибуты»: Способность обнуления
Подпункт 6.5, «Спецификация контекстно типизированного значения»: Спецификация нулевого значения
F041. Базовое объединение таблиц
F041-01.
 Операция inner join, но необязательно с ключевым словом INNER
Операция inner join, но необязательно с ключевым словом INNER
Подпункт 7.6, «Ссылка на таблицу»: Раздел про объединения таблиц, но не включая поддержки подфункций с ### F041-02 по ### F041-08
F041-02. Ключевое слово INNER
Подпункт 7.7, «Объединенная таблица»: тип объединения INNER
F041-05. Вложенные outer join
Подпункт 7.7, «Объединенная таблица»: Подфункция ### F041-01 расширена таким образом, что ссылка на таблицу в объединенной таблице сама может быть объединенной таблицей:
F041-08. Все операторы сравнения поддерживаются (помимо обычного =.
Подпункт 7.7, «Объединенная таблица»: Подфункция ### F041-01 расширена таким образом, что условие соединения не ограничивается предикатом сравнения с оператором сравнения
F201. Функция CAST
Подпункт 6.13, «Спецификация CAST» для всех типов данных
Подпункт 6.26, «Выражение значения» для спецификации CAST
F471. Скалярные значения подзапросов
Подпункт 6.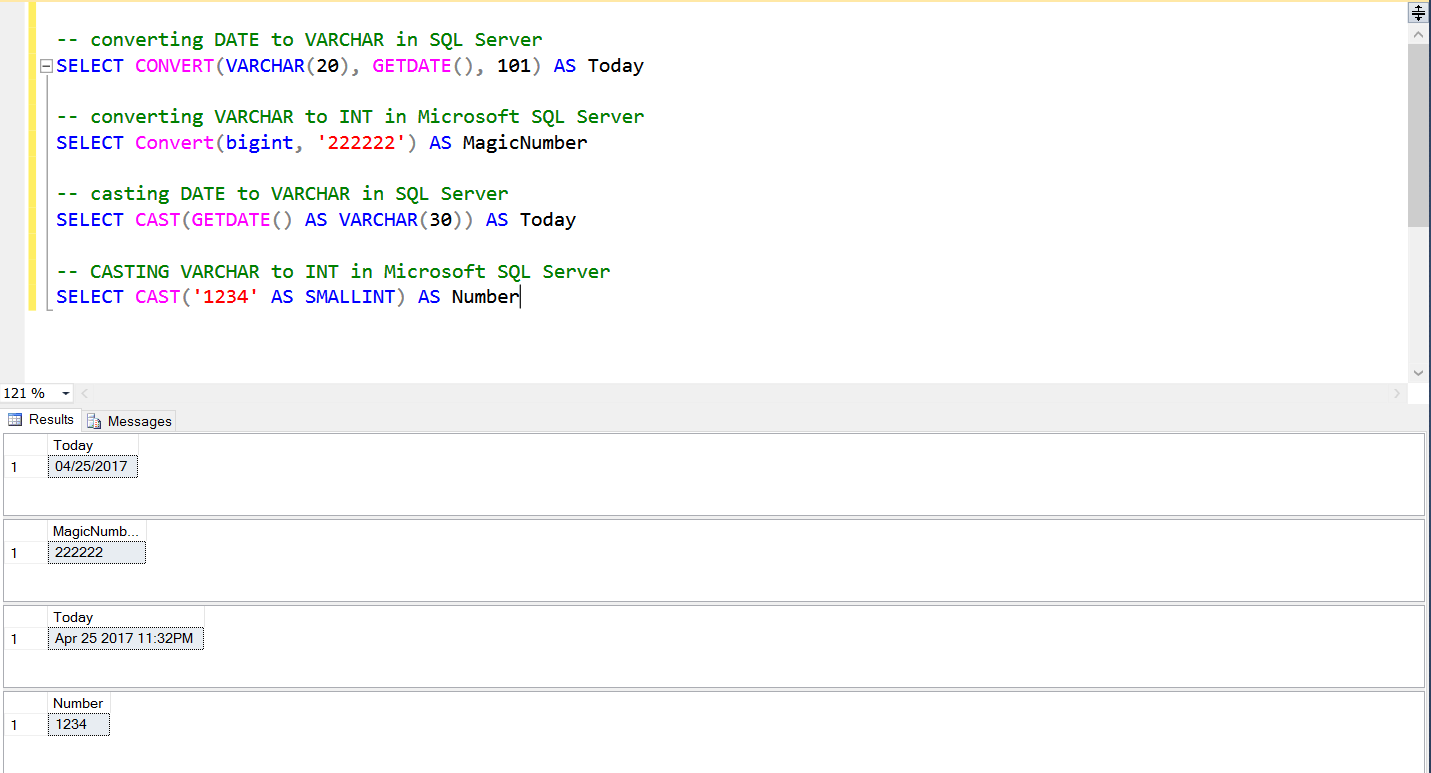 26, «Выражение значения»: Первичное выражение значения может быть скалярным подзапросом.
26, «Выражение значения»: Первичное выражение значения может быть скалярным подзапросом.
T631. Предикат IN с одним элементом списка
Подпункт 8.4, «Предикат in»: Список значений ‘in’ содержит ровно одно выражение значения строки.
E101-03. Инструкция UPDATE с поиском
E101-04. Инструкция DELETE с поиском
E011-04. Арифметические операторы
E071-01. Табличный оператор UNION DISTINCT
E071-03. Табличный оператор EXCEPT DISTINCT
F041-03. LEFT OUTER JOIN.
Подробнее о внутренней архитектуре кластера Picodata см. в разделе Общая схема инициализации кластера. Параметры запуска из командной строки описаны в разделе Описание параметров запуска.
Использование CONTEXT_INFO | Олонцев Сергей
SQL Server обладает широким набором интересных функций. Одной из них является возможность реализовать передачу определенной информации в пределах одной сессии. Когда это может быть нужно? Например, с одной таблицей в базе данных работает несколько приложений и каждое вводит или изменяет данные с помощью своей хранимой процедуры, а триггер в таблице на изменение данных должен это учитывать и вести себя по-разному для всех приложений. В этом случае как раз можно использовать следующий сценарий: хранимая процедура сохраняет определенное значение в переменной сессии, а триггер считывает это значение и выполняет нужной действие в зависимости от контекста. Также эту технику можно применять при использовании вложенных триггеров (nested triggers).
В этом случае как раз можно использовать следующий сценарий: хранимая процедура сохраняет определенное значение в переменной сессии, а триггер считывает это значение и выполняет нужной действие в зависимости от контекста. Также эту технику можно применять при использовании вложенных триггеров (nested triggers).
Переменная сессии CONTEXT_INFO позволяет сохранять данные переменной длины размером до 128 байт. Это немного, но для большинства задач должно хватить. Чтобы установить значение переменной сессии нужно воспользоваться командой SET CONTEXT_INFO, а чтобы получить текущее значение – функцией CONTEXT_INFO(). Ну и сразу приведу небольшой пример.
DECLARE @context_info varbinary(128)
SET @context_info = CAST('MyApplicationID1' AS varbinary(128))
SET CONTEXT_INFO @context_info
GO
SELECT CONTEXT_INFO()
SELECT CAST(CONTEXT_INFO() AS varchar(128))
GO |
Между присваиванием значения и его получением я специально поставил разделитель GO, чтобы показать, что параметр сохраняет свое значение даже между разными блоками команд.
Также переменную сессии можно посмотреть в следующих системных представлениях в столбце context_info.
- sys.dm_exec_requests
- sys.dm_exec_sessions
- sys.sysprocesses
Также можно использовать технику, когда в CONTEXT_INFO мы будем хранить не одно, а несколько значений, но в разных местах. Например, мы договариваемся, что в позиции с 1 по 20 мы храним идентификатор процесса, а 21 по 28 – дату и время. Тогда процесс формирования нашей строки будет выглядеть примерно следующим образом.
DECLARE @process_id char(20) = 'MyProcessID2' DECLARE @date_time datetime = GETDATE() DECLARE @context_info varbinary(128) SET @context_info = CAST(@process_id AS binary(20)) + CAST(@date_time AS binary(8)) SET CONTEXT_INFO @context_info SELECT CAST(SUBSTRING(CONTEXT_INFO(), 1, 20) AS char(20)) AS process_id, CAST(SUBSTRING(CONTEXT_INFO(), 21, 8) AS datetime) AS date_time |
И еще одна небольшая деталь, о которой необходимо помнить: если вы используете CONTEXT_INFO внутри транзакции, то при откате значение не возвращается к исходному. Пример:
Пример:
DECLARE @context_info varbinary(128)
SET @context_info = CAST('Value before transaction' AS varbinary(128))
SET CONTEXT_INFO @context_info
SELECT CAST(CONTEXT_INFO() AS varchar(128)) AS [Value before transaction]
BEGIN TRAN
SET @context_info = CAST('Value inside transaction' AS varbinary(128))
SET CONTEXT_INFO @context_info
SELECT CAST(CONTEXT_INFO() AS varchar(128)) AS [Value inside transaction]
ROLLBACK
SELECT CAST(CONTEXT_INFO() AS varchar(128)) AS [Value after transaction]Финальным результатом вернется значение, которое мы установили внутри транзакции, несмотря на то, что транзакцию мы откатили. Это нужно учитывать или можно использовать.
Функция SQL CAST | Синтаксис и примеры BigQuery
Ресурсы SQL/BigQuery/CAST
Определение
Функция CAST позволяет выполнять преобразование между различными типами данных в BigQuery.
Синтаксис
CAST (выражение AS typename)Где typename является любым из:
- INT64, NUMERIC, BIGNUMERIC, FLOAT64, BOOL, STRING, БАЙТЫ, ДАТА, ДАТАВРЕМЯ, ВРЕМЯ, TIMESTAMP, МАССИВ, СТРУКТУРА
Подробнее о каждом типе можно прочитать здесь.
ВЫБЕРИТЕ стр_номер, CAST(TRIM(str_number) AS INT64) Номер AS ОТ ( ВЫБИРАТЬ '3' AS номер_строки СОЮЗ ВСЕХ ( ВЫБИРАТЬ '8' AS номер_строки) СОЮЗ ВСЕХ ( ВЫБИРАТЬ '23' AS номер_строки) ) AS table_3str_number
number
Практическая информация
Преобразование STRING в DATE
При преобразовании STRING в DATE STRING должен быть в формате : ГГГГ-ММ-ДД
ВЫБЕРИТЕ safe_CAST(дата1 КАК ДАТА) КАК дата1, safe_CAST(дата2 КАК ДАТА) КАК дата2, FORMAT_DATE('%b %d,%Y', safe_CAST(date2 AS DATE)) AS formatted_date2 ОТ ( ВЫБИРАТЬ '01.02.20' AS date1, '2020-02-01' Дата по AS2 ) КАК таблица_1date2
01.02.2020
formatted_date2
01 февраля 2020 г.
Здесь мы использовали SAFE_CAST, чтобы в случае сбоя CAST на сегодняшний день весь запрос не завершился сбоем.
В приведенном выше примере date1 возвращает значение NULL, поскольку оно имеет неверный формат.
Аналогичные правила применяются для преобразования STRING в DATETIME, TIMESTAMP и TIME:
При преобразовании STRING -> DATETIME строка должна иметь формат ГГГГ:ММ:ДД ЧЧ:ММ:СС
ВЫБЕРИТЕ CAST('2020-12-25 03:22:01' AS DATETIME) AS str_to_datetimestr_to_datetime
2020-12-25T03:22:01
При преобразовании STRING -> TIMESTAMP строка должна быть в формате Y ГГГ :MM:DD HH:MM:SS [отметка времени] (где отметка времени по умолчанию равна UTC, если она не указана).
ВЫБЕРИТЕ CAST('2020-12-25 03:22:01-5:00' AS TIMESTAMP) AS str_to_timestampstr_to_timestamp
2020-12-25T08:22:01.000Z
При кастинге STRING ->TIME строка должна быть в формате ЧЧ:ММ:СС
выберите приведение ('15:03:11' как TIME) as str_to_timestr_to_time
15:03:11
Преобразование в BOOL
Когда преобразование в BOOL (логические значения, True/False) из других Есть несколько правил, о которых следует помнить:
INT64 -> BOOL: возвращает FALSE для 0, TRUE в противном случае.
ВЫБЕРИТЕ CAST(0 AS BOOL) AS zero_to_bool, CAST(5 AS BOOL) AS Five_to_boolzero_to_bool
Five_to_bool
STRING -> BOOL: Возвращает TRUE для «true», FALSE для «false», NULL в противном случае.
ВЫБЕРИТЕ SAFE_CAST('true' AS BOOL) КАК true_to_bool, SAFE_CAST('false' AS BOOL) AS false_to_bool, SAFE_CAST('apples' AS BOOL) AS apples_to_booltrue_to_bool
false_to_bool
apples_to_bool
Общие вопросы
9003 6 Как преобразовать STRING в DATE?
Допустим, у вас есть строковая дата, не отформатированная в стандартном формате ГГГГ-ММ-ДД. Как преобразовать ее в дату?
Есть 2 варианта:
Используйте PARSE_DATE, где вы можете указать точный синтаксис вашей строки:
SELECT PARSE_DATE('%m/%d/%Y', '03.01.2020')f0_
2020-01-03
Воспользуйтесь манипуляцией STRING, чтобы преобразовать строку и CAST в правильный формат:
ВЫБЕРИТЕ CAST(CONCAT(REGEXP_EXTRACT(str_date, r'\/([0-9]{4})'), "-", REGEXP_EXTRACT(str_date, r'([0-9]{1,2})\/' ), "-", REGEXP_EXTRACT(str_date, r'\/([0-9]{1,2})\/')) AS DATE) AS date_from_str ОТ ( ВЫБИРАТЬ '03.12.2020' AS str_date ) КАК таблица_1
date_from_str
2020-12-03
Как преобразовать EPOCH в TIMESTAMP?
Эпохи, или время Unix, представляют собой секунды с 01:00:00 UTC 01-01-1970. Чтобы их можно было использовать для анализа, вам нужно преобразовать их в DATETIME или TIMESTAMP.
Для этого вы снова можете использовать PARSE_DATETIME или PARSE_TIMESTAMP, если ваша эпоха STRING.
SELECT parse_timestamp('%s', '1611592773')f0_
2021-01-25T16:39:33.000Z
Или, если ваша эпоха — INT64, используйте следующие функции: TIMESTAMP_SECONDS, TIMESTAMP_MILLIS, TIMESTAMP_MICROS, UNIX_SECONDS, UNIX_MILLIS, UNIX_MICROS.
ВЫБЕРИТЕ TIMESTAMP_SECONDS(1611592773) AS formatted_timestampformatted_timestamp
2021-01-25T16:39:33.000Z
Как преобразовать экспоненциальное представление в десятичный формат?
CAST to NUMERIC, чтобы преобразовать столбец научной нотации в десятичный:
Выберите sci, cast(sci as NUMERIC) sci_numeric FROM ( ВЫБИРАТЬ (15000000.sci
32000000.01
sci_numeric
32000000.0100000 02
Устранение распространенных ошибок
Не удалось преобразовать литерал в тип DATE
Проверьте формат строки при преобразовании в DATE . Помните, что это должно быть в YYYY-MM-DD . Но также попробуйте PARSE_DATE, если вы ищете что-то для чтения в определенном формате.
Связанные страницы

 12.2020' AS str_date
) КАК таблица_1
12.2020' AS str_date
) КАК таблица_1  0 + 17000000.01) AS sci)
0 + 17000000.01) AS sci) - Даты и время в стандартном SQL
Функции DATE/TIME в SQL. Учебное пособие по использованию CAST, EXTRACT… | by Jason
Руководство по использованию CAST, EXTRACT и DATE_TRUNC
Опубликовано в
·
Чтение: 7 мин.
·
29 марта 2020 г.
Photo Лукас Блазек на Unsplash
Работа с датами и временем обычная практика при работе с SQL. Используя даты, мы можем рассчитать изменения во времени, тенденции в данных, выполнить интервальную арифметику. Чтобы лучше понять последствия основной бизнес-проблемы.
«данные временного ряда» как последовательность точек данных, измеряющих одно и то же во времени, хранящихся во временном порядке.
Некоторые распространенные способы использования временных рядов данных примет тебя иметь средний уровень владения SQL. Мы рассмотрим три функции и поработаем с синтаксисом PostgreSQL.
- CAST
- EXTRACT
- DATE_TRUNC
Каждая из этих функций может быть полезна при разбивке наборов данных с большим количеством данных. Мы увидим преимущества каждого из них, когда рассмотрим код с некоторыми примерами.
Функция CAST преобразует выбранный тип данных в другой. Довольно прямолинейно. Он изменяет один тип на ваш предпочтительный тип. Синтаксис ниже.
CAST(выражение AS тип данных )
Ниже приведен пример того, как его можно применить к дате и времени. 9В этом запросе ожидаем иметь 6 выходов. Если вы не знакомы с NOW() , CURRENT_DATE , CURRENT_TIME , это функции SQL, которые извлекают текущее время или дату. Ниже приведены все результаты запроса по порядку. (обратите внимание — вы получите разные числа, так как функции вызывают точное время или дату)
Ниже приведены все результаты запроса по порядку. (обратите внимание — вы получите разные числа, так как функции вызывают точное время или дату)
- 2020–03–28 23:18:20.261879+00:00
- 2020–03–28 23:18:20.261879
- 2020–03–28
- 2020–03–28
- 23:18:20.261879+00:00
900 19 23:18:20.261879
Глядя на первый результат NOW() , используемого отдельно, мы получаем полное значение метки времени, включая часовой пояс. Теперь, когда мы переходим ко второму выходу, мы использовали CAST только для получения TIMESTAMP, который не включает часовой пояс из NOW() . Теперь мы можем увидеть, как работает приведение. Мы передаем значение, которое хотим преобразовать, а затем указываем нужный тип.
Затем мы используем CAST() на NOW() , но передаем DATE в качестве желаемого типа. Теперь мы получаем метку времени, разделенную только на формат год/месяц/день.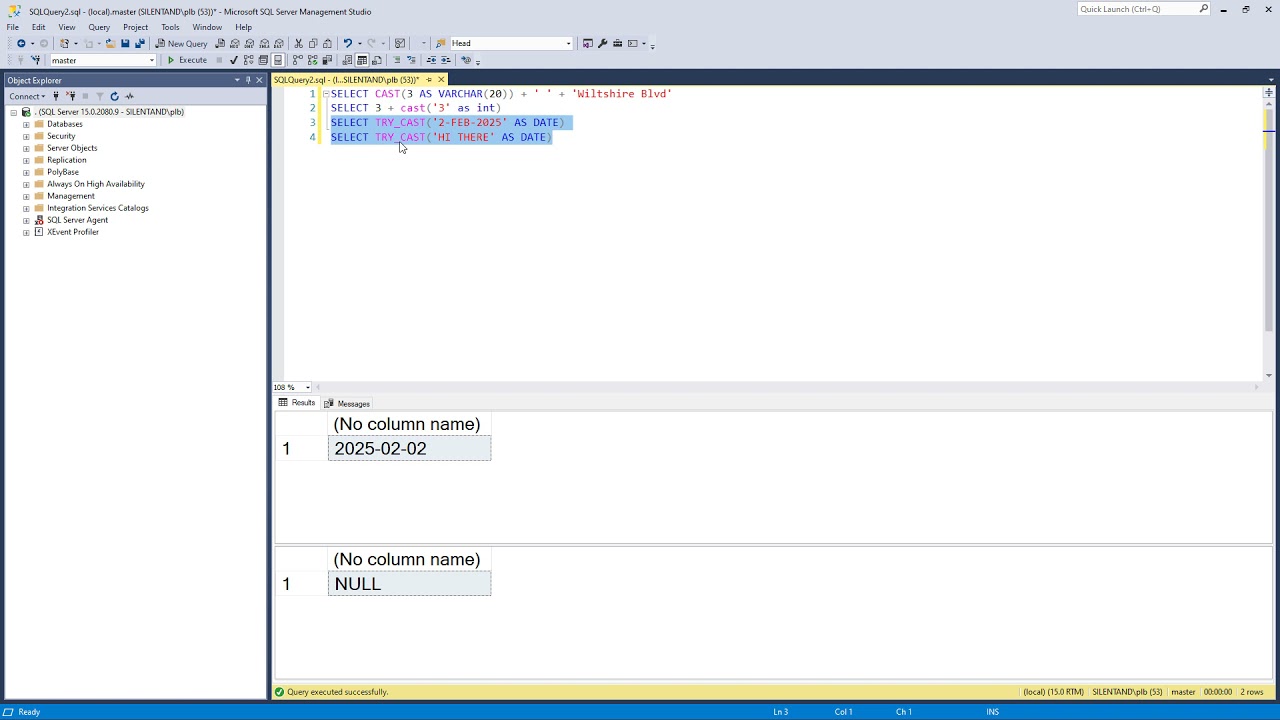 Точно так же посмотрите на функцию
Точно так же посмотрите на функцию CAST() с NOW() и только TIME , и мы получим только значение времени без даты.
Мы можем видеть, как функция CAST работает со временем, и последние два вывода с использованием CURRENT_DATE и CURRENT_TIME просто для вас, чтобы увидеть сравнение результатов.
Другие примеры — без временных меток
SQL также позволяет использовать функции CAST() с типами без временных меток.
SELECT
CAST(1.34 AS INT),
CAST(1 AS BOOLEAN),
CAST(2.65 AS DEC(3,0))
Результаты этого запроса:
- 1 → Поскольку целое число может t есть десятичные числа, он будет округлен до ближайшего целого числа
- истина → 1, поскольку логическое значение истинно, а 0 ложно
- 3 → используя
DEC(), мы также можем сделать обратное нашему первому целочисленному CAST.
Интервалы
В SQL вы также можете использовать ИНТЕРВАЛ , чтобы добавить больше времени к любой имеющейся у вас метке времени. Для приведенных ниже примеров вам не нужно использовать функцию
Для приведенных ниже примеров вам не нужно использовать функцию CAST() , но я решил сделать это только для того, чтобы иметь дату.
ВЫБЕРИТЕ
ПЕРЕДАЧА (СЕЙЧАС () КАК ДАТА) КАК СЕГОДНЯ_ДАТА,
ПЕРЕДАЧА (( ИНТЕРВАЛ '3 ДНЯ' + СЕЙЧАС()) КАК ДАТА) КАК три_дня,
CAST(( ИНТЕРВАЛ '3 НЕДЕЛИ' + СЕЙЧАС()) КАК ДАТА) КАК three_weeks,
CAST(( ИНТЕРВАЛ '3 МЕСЯЦА' + NOW()) AS DATE) AS three_months,
CAST(( INTERVAL '3 YEARS' + NOW()) AS DATE) AS three_years
Output
Мы видим, что используя INTERVAL в дополнение к длине интервала в днях, неделях, месяцах или годах добавляет больше времени к любой имеющейся у вас дате — в этом примере текущая дата получается из СЕЙЧАС() .
Далее мы можем посмотреть на извлечение определенного формата из метки времени. Цель состоит в том, чтобы извлечь часть из метки времени. Например, если нам нужен только месяц с даты 10. 12.2018, мы получим декабрь (12).
12.2018, мы получим декабрь (12).
Давайте посмотрим на EXTRACT синтаксис
EXTRACT(часть из даты)
Мы указываем тип извлечения, который мы хотим, как часть , а затем источник, который нужно извлечь дата . EXTRACT — это инструмент импорта для анализа данных временных рядов. Это помогает вам изолировать группы в ваших временных метках для агрегирования данных на основе точного времени. Например, если магазин по аренде автомобилей хочет найти самый загруженный пункт проката ЧАС по ПОНЕДЕЛЬНИКАМ каждые МАЯ , вы можете сделать это с помощью ЭКСТРАКТ . Вы можете детализировать детали и увидеть более ценную информацию.
Предположим, мы запускаем NOW() и наша отметка времени 2020–03–29 00:27:51.677318+00:00 , мы можем использовать EXTRACT , чтобы получить следующее.
ВЫБЕРИТЕ
ИЗВЛЕЧЬ(МИНУТА ОТ СЕЙЧАС()) КАК МИНУТА,
ИЗВЛЕЧЬ(ЧАС ОТ СЕЙЧАС()) КАК ЧАС,
ИЗВЛЕЧЬ(ДЕНЬ ОТ СЕЙЧАС()) КАК ДЕНЬ,
ВЫЧИСЛЕНИЕ(НЕДЕЛЯ С СЕГОДНЯ()) КАК НЕДЕЛЯ,
ВЫЧИСЛЕНИЕ(МЕСЯЦ С СЕГОДНЯ()) КАК МЕСЯЦ,
ВЫЧИСЛЕНИЕ(ГОД С СЕГОДНЯ()) КАК ГОД,
ВЫЧИСЛЕНИЕ(ДАУ ОТ СЕГОДНЯ()) КАК ДЕНЬ_НЕДЕЛИ,
ВЫЧИСЛЕНИЕ (DOY FROM NOW()) AS DAY_OF_YEAR,
EXTRACT(QUARTER FROM NOW()) AS QQUARTER,
EXTRACT(TIMEZONE FROM NOW()) AS TIMEZONE
Output
Мы видим, что можем вдаваться в мельчайшие детали того, как мы хотите извлечь информацию из наших временных меток. Примечание — DOW — день недели с воскресенья (0) по субботу (6).
Примечание — DOW — день недели с воскресенья (0) по субботу (6).
Мы можем использовать приведенный выше пример с арендованным автомобилем и посмотреть, как это будет работать.
ВЫБЕРИТЕ
ВЫЧИСЛЕНИЕ (ЧАС ОТ ДАТЫ АРЕНДЫ) КАК ЧАС,
СЧЕТЧИК (*) как АРЕНДА
ИЗ АРЕНДА
ГДЕ
ВЫЧИСЛЕНИЕ (ДОУ ОТ ДАТЫ АРЕНДЫ) = 1 И
ВЫДВИЖЕНИЕ (МЕСЯЦ ОТ ДАТЫ АРЕНДЫ) = 5
СГРУППИРОВАТЬ ПО 1
ПОРЯДОК BY RENTALS DESC
Помните, что нам нужна самая загруженная аренда ЧАС по ПОНЕДЕЛЬНИКАМ каждые МАЯ . Во-первых, мы используем EXTRCT в SELECT , чтобы указать, нам нужны только HOUR и общее количество COUNT . Затем мы передаем две функции EXTRACT для предложения WHERE , чтобы отфильтровать только MONDAYS и MAY . Глядя на таблицу ниже, 11:00 — самое популярное время аренды каждый понедельник в мае, всего 11 аренд.
Выходные данные
Усечение — сокращение или как бы отсечение
Целью усечения даты в SQL является получение интервала с абсолютной точностью. Значения точности — это подмножество идентификаторов полей, которые можно использовать с ЭКСТРАКТ . DATE_TRUNC вернет интервал или метку времени, а не число.
Синтаксис для DATE_TRUNC , time_column — это столбец базы данных, который содержит метку времени, которую вы хотите округлить, а ‘[интервал]’ диктует желаемый уровень точности.
DATE_TRUNC(‘[interval]’, time_column)
Предположим, что наш NOW() возвращает то же самое 2020–03–29 00:27:51.677318+00:00 , мы можем использовать date_part , чтобы получить следующее.
ВЫБРАТЬ
CAST(DATE_TRUNC('DAY', NOW()) AS DATE) AS DAY,
CAST(DATE_TRUNC('WEEK', NOW()) AS DATE) AS WEEK,
CAST(DATE_TRUNC('MONTH', NOW()) AS DATE) AS MONTH,
CAST(DATE_TRUNC('YEAR', NOW()) AS DATE) AS YEAR
Output
Думайте об использовании DATE_TRUNC как о получении интервала текущего положения, и каждый уровень интервала — это то, как обрезается дата. Примечание — нам не нужно было использовать
Примечание — нам не нужно было использовать CAST 9.0245 в этом примере. Я использовал его, чтобы убедиться, что формат чист для анализа.
Мы можем использовать DATE_TRUNC в предыдущем сценарии аренды автомобиля и попытаться определить, какой день в году, независимо от времени, более популярен для аренды.
ВЫБЕРИТЕ
CAST(DATE_TRUNC('DAY', RENTAL_DATE) AS DATE) AS RENTAL_DAY,
COUNT(*) AS RENTALS
FROM RENTAL
GROUP BY
RENTAL_DAY
ORDER BY RENTALS DE SC Выход
Теперь, когда мы видели как использовать CAST , EXTRACT и DATE_TRUNC мы можем объединить некоторые из изученных методов в один практический пример.
В этом примере мы добавим новую функцию времени с именем ВОЗРАСТ , которая принимает 2 даты в качестве аргумента и выводит «ВОЗРАСТ» или время в годах и месяцах между датами.
Давайте завершим этот урок, извлекая список клиентов, у которых была самая большая продолжительность аренды ( AGE ) из 2019 года.