Что такое запрос sql: Что такое SQL? – Описание структурированного языка запросов (SQL) – AWS
Содержание
Нормализация данных через запрос в SQL
Главный принцип анализа данных GIGO (от англ. garbage in — garbage out, дословный перевод «мусор на входе — мусор на выходе») говорит нам о том, что ошибки во входных данных всегда приводят к неверным результатам анализа. От того, насколько хорошо подготовлены данные, зависят результаты всей вашей работы.
Например, перед нами стоит задача подготовить выборку для использования в алгоритме машинного обучения (модели k-NN, k-means, логической регрессии и др). Признаки в исходном наборе данных могут быть в разном масштабе, как, например, возраст и рост человека. Это может привести к некорректной работе алгоритма. Такого рода данные нужно предварительно масштабировать.
В данном материале мы рассмотрим способы масштабирования данных через запрос в SQL: масштабирование методом min-max, min-max для произвольного диапазона и z-score нормализация. Для каждого из методов мы подготовили по два примера написания запроса — один с помощью подзапроса SELECT, а второй используя оконную функцию OVER().
Для работы возьмем таблицу students с данными о росте учащихся.
| name | height |
| Иван | 174 |
| Петр | 181 |
| Денис | 199 |
| Ксения | 158 |
| Сергей | 179 |
| Ольга | 165 |
| Юлия | 152 |
| Кирилл | 188 |
| Антон | 177 |
| Софья | 165 |
Min-Max масштабирование
Подход min-max масштабирования заключается в том, что данные масштабируются до фиксированного диапазона, который обычно составляет от 0 до 1. В данном случае мы получим все данные в одном масштабе, что исключит влияние выбросов на выводы.
Выполним масштабирование по формуле:
Умножаем числитель на 1.0, чтобы в результате получилось число с плавающей точкой.
SQL-запрос с подзапросом:
SELECT height,
1. 0 * (height-t1.min_height)/(t1.max_height - t1.min_height) AS scaled_minmax
FROM students,
(SELECT min(height) as min_height,
max(height) as max_height
FROM students
) as t1;
0 * (height-t1.min_height)/(t1.max_height - t1.min_height) AS scaled_minmax
FROM students,
(SELECT min(height) as min_height,
max(height) as max_height
FROM students
) as t1; 0 * (height-t1.min_height)/(t1.max_height - t1.min_height) AS scaled_minmax
FROM students,
(SELECT min(height) as min_height,
max(height) as max_height
FROM students
) as t1;
0 * (height-t1.min_height)/(t1.max_height - t1.min_height) AS scaled_minmax
FROM students,
(SELECT min(height) as min_height,
max(height) as max_height
FROM students
) as t1;SQL-запрос с оконной функцией:
SELECT height,
(height - MIN(height) OVER ()) * 1.0 / (MAX(height) OVER () - MIN(height) OVER ()) AS scaled_minmax
FROM students;В результате мы получим переменные в диапазоне [0…1], где за 0 принят рост самого невысокого учащегося, а 1 рост самого высокого.
| name | height | scaled_minmax |
| Иван | 174 | 0.46809 |
| Петр | 181 | 0.61702 |
| Денис | 199 | 1 |
| Ксения | 158 | 0.12766 |
| Сергей | 179 | 0.57447 |
| Ольга | 165 | 0.2766 |
| Юлия | 152 | 0 |
| Кирилл | 188 | 0. 76596 76596 |
| Антон | 177 | 0.53191 |
| Софья | 165 | 0.2766 |
Масштабирование для заданного диапазона
Вариант min-max нормализации для произвольных значений. Не всегда, когда речь идет о масштабировании данных, диапазон значений находится в промежутке между 0 и 1.
Формула для вычисления в этом случае такая:
Это даст нам возможность масштабировать данные к произвольной шкале. В нашем примере пусть а=10.0, а b=20.0.
SQL-запрос с подзапросом:
SELECT height,
((height - min_height) * (20.0 - 10.0) / (max_height - min_height)) + 10 AS scaled_ab
FROM students,
(SELECT MAX(height) as max_height,
MIN(height) as min_height
FROM students
) t1;SQL-запрос с оконной функцией:
SELECT height,
((height - MIN(height) OVER() ) * (20.0 - 10.0) / (MAX(height) OVER() - MIN(height) OVER())) + 10.0 AS scaled_ab
FROM students;Получаем аналогичные результаты, что и в предыдущем методе, но данные распределены в диапазоне от 10 до 20.
| name | height | scaled_ab |
| Иван | 174 | 14.68085 |
| Петр | 181 | 16.17021 |
| Денис | 199 | 20 |
| Ксения | 158 | 11.2766 |
| Сергей | 179 | 15.74468 |
| Ольга | 165 | 12.76596 |
| Юлия | 152 | 10 |
| Кирилл | 188 | 17.65957 |
| Антон | 177 | 15.31915 |
| Софья | 165 | 12.76596 |
Нормализация с помощью z-score
В результате z-score нормализации данные будут масштабированы таким образом, чтобы они имели свойства стандартного нормального распределения — среднее (μ) равно 0, а стандартное отклонение (σ) равно 1.
Вычисляется z-score по формуле:
SQL-запрос с подзапросом:
SELECT height,
(height - t1. mean) * 1.0 / t1.sigma AS zscore
FROM students,
(SELECT AVG(height) AS mean,
STDDEV(height) AS sigma
FROM students
) t1; mean) * 1.0 / t1.sigma AS zscore
FROM students,
(SELECT AVG(height) AS mean,
STDDEV(height) AS sigma
FROM students
) t1;
mean) * 1.0 / t1.sigma AS zscore
FROM students,
(SELECT AVG(height) AS mean,
STDDEV(height) AS sigma
FROM students
) t1;SQL-запрос с оконной функцией:
SELECT height,
(height - AVG(height) OVER()) * 1.0 / STDDEV(height) OVER() AS z-score
FROM students;В результате мы сразу заметим выбросы, которые выходят за пределы стандартного отклонения.
| name | height | zscore |
| Иван | 174 | 0.01488 |
| Петр | 181 | 0.53582 |
| Денис | 199 | 1.87538 |
| Ксения | 158 | -1.17583 |
| Сергей | 179 | 0.38698 |
| Ольга | 165 | -0.65489 |
| Юлия | 152 | -1.62235 |
| Кирилл | 188 | 1.05676 |
| Антон | 177 | 0. 23814 23814 |
| Софья | 165 | -0.65489 |
Межбазовый запрос на Transact-SQL | Info-Comp.ru
Речь сегодня пойдет об очень полезной возможности в SQL это межбазовый запрос. Данный вид запроса просто незаменим, если у Вас существует несколько баз данных на одном сервере или даже на разных серверах, а так как иногда требуется получить данные сразу отовсюду, например, для отчета, то межбазовый запрос лучшее решение этой задачи.
Примечание! Сразу хочу сказать, что все примеры будем пробовать на Transact-SQL MS Sql Server 2008 в Management Studio, так как в других СУБД синтаксис будет отличаться. Также хочу заметить, что все примеры ниже требуют начальных знаний SQL, поэтому советую для начала ознакомиться с материалами: Язык запросов SQL – Оператор SELECT, Добавляем в таблицу новую колонку на SQL, Сочетание строковых функций на Transact-SQL, Transact-sql – Табличные функции и временные таблицы эти статьи помогут Вам приобрести начальные знания в SQL.
И так приступим, сначала как обычно немного теории, для того чтобы понять, что такое межбазовый запрос и для чего он служит, а потом как обычно рассмотрим несколько практических примеров.
Межбазовый запрос
Межбазовый запрос – это запрос, который в процессе своего выполнения подключается к разным базам данных, а также в некоторых случаях к разным серверам баз данных.
А теперь давайте определимся, для каких целей могут служить межбазовые запросы, допустим, у Вас есть 3 базы данных, 2 из них расположены на одном MSSQL сервере, а одна на другом. Все они служат для какой-то определенной задачи, может быть у них даже схожая структура, но это не важно и Вам как программисту иногда требуется выгружать данные из всех баз, например, для того чтобы предоставить эти данные начальству, и Вы скорей всего запускаете запросы из каждой базы или переключаетесь из менеджера запросов на работу с той ли иной базой, но гораздо удобней было бы запустить один запрос и получить сразу все данные. Именно для этого я пользуюсь данного вида запросами, но Вы, наверное, можете найти применение и для других задач. Если Вы сталкивались с такого рода задачами, то Вам просто необходимо узнать что такое межбазовый запрос.
Именно для этого я пользуюсь данного вида запросами, но Вы, наверное, можете найти применение и для других задач. Если Вы сталкивались с такого рода задачами, то Вам просто необходимо узнать что такое межбазовый запрос.
Примеры межбазовых запросов
И первый пример он достаточно простой, требуется тогда когда необходимо получить данные из нескольких баз расположенных на одном сервере. Для объединения этих данных будем использовать конструкцию union all, которую мы рассматривали в статье – union и union all на Transact-SQL .
И для начала, допустим, у нас есть две базы данных (test и test2), схемы dbo в которых мы создали вот такие таблицы:
Таблица в базе test
CREATE TABLE [dbo].[test_table_base_1](
[id] [bigint] NOT NULL,
[text] [varchar](50) NULL,
CONSTRAINT [PK_test_table] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Таблица в базе test2
CREATE TABLE [dbo].
 [test_table_base_2](
[id] [bigint] NOT NULL,
[text] [varchar](50) NULL,
CONSTRAINT [PK_test_table] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
[test_table_base_2](
[id] [bigint] NOT NULL,
[text] [varchar](50) NULL,
CONSTRAINT [PK_test_table] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Я их заполнил тестовыми данными, сейчас увидите какими, и для того чтобы получить данные из этих таблиц напишем вот такой запрос:
Код:
select * from test.dbo.test_table_base_1 – Первая база select * from test2.dbo.test_table_base_2 –Вторая база
Как видите синтаксис очень простой:
Select * from [база].[схема].[таблица]
Но результата в вышеуказанном запросе будет два, и для того чтобы объединить эти запросы, используем конструкцию union all.
Код:
select * from test.dbo.test_table_base_1 – Первая база union all select * from test2.
 dbo.test_table_base_2 –Вторая база
dbo.test_table_base_2 –Вторая база
И результат будет уже один. И с помощью данного межбазового запроса Вы легко можете объединить данные, а еще для удобства, чтобы каждый раз не писать текст запроса можете создать представление views, для того чтобы обращаться напрямую к этому представлению.
Теперь давайте рассмотрим пример посложней, когда требуется получить данные из базы, которая располагается на другом сервере.
Для этого мы будем использовать конструкцию opendatasource.
Сразу скажу, что opendatasource работает, только если на сервере выставлен параметр Ad Hoc Distributed Queries со значением 1. Для того чтобы посмотреть этот параметр выполните процедуру sp_configure и посмотрите значение данного параметра:
Где,
- config_value — это значение которое внеслось но еще не сохранилось, т.е. сервер еще не переконфигурировался;
- run_value – текущее значение данного параметра, т. е. с которым работает сервер в данный момент.
 е. с которым работает сервер в данный момент.
е. с которым работает сервер в данный момент.Кстати данная процедура возвращает очень много конфигурационных параметров, которые Вы можете посмотреть.
И для того чтобы изменить данный параметр, используем туже самую процедуру, синтаксис:
exec sp_configure [Название параметра],[Значение]
А для того чтобы сконфигурировать сервер с новым значением, запустим процедуру reconfigure, и весь запрос будет выглядеть вот так:
exec sp_configure 'Ad Hoc Distributed Queries',1 reconfigure exec sp_configure
Ну а теперь можем приступать непосредственно к запросу, который подключится к серверу и получит необходимые данные. Для примера я буду подключаться сам к себе к тем же таблицам.
Код:
select * from
opendatasource ('sqlncli','Data Source=myserver;Integrated Security=SSPI')
.test.dbo.test_table_base_1
union all
select * from
opendatasource ('sqlncli','Data Source=myserver;Integrated Security=SSPI')
. test2.dbo.test_table_base_2
 test2.dbo.test_table_base_2
test2.dbo.test_table_base_2
Как видите результат тот же самый.
Здесь мы указали в первом параметре провайдер источника данных, т.е. SQL server (‘sqlncli’) и задали строку подключения:
Где,
- Data Source – это адрес сервера баз данных;
- Integrated Security=SSPI – при подключении использовать проверку подлинности Windows, т.е. аутентификация и авторизация пользователя будет проходить по учетным данным Windows, отлично подходит, если в сети развернута AD(Active Directory).
А если Вы хотите использовать проверку подлинности на уровне SQL сервера, то придется писать имя пользователя и пароль (которые должны быть созданы на SQL сервере) в строке подключения, например, абсолютно такой же результат, как и выше, получится, если мы напишем вот такой запрос:
select * from
opendatasource ('sqlncli','Data Source= myserver;user id = username; pwd=password')
.test.dbo.test_table_base_1
union all
select * from
opendatasource ('sqlncli','Data Source= myserver;user id = username; pwd=password')
. test2.dbo.test_table_base_2
 test2.dbo.test_table_base_2
test2.dbo.test_table_base_2
Т.е. вместо параметра Integrated Security мы укажем параметры:
- user id — логин на SQL сервере;
- pwd – соответственно пароль.
Примечание! Opendatasource может подключаться и другим отличным от SQL сервера источникам для этого в параметрах указываете нужный Вам провайдер, например, для подключения к Excel документу можете использовать вот такой запрос (Синтаксис):
SELECT * FROM OPENDATASOURCE('Microsoft.Jet.OLEDB.4.0',
'Data Source=C:\TestExcel.xls; Extended Properties=EXCEL 5.0')...[Sheet1$] ;
По межбазовым запросам все, надеюсь, данный материал был Вам интересен, и пригодится Вам на практике.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Что такое SQL и для чего он используется?
SQL — один из самых важных языков программирования, которые необходимо знать, если вы работаете с данными. Мы изучаем, что это такое, для чего он используется и какую работу вы могли бы получить, если бы изучили SQL.
Мы изучаем, что это такое, для чего он используется и какую работу вы могли бы получить, если бы изучили SQL.
Поделиться этой публикацией
Данные есть везде, от цен на товары в вашем местном супермаркете до личных данных, собранных из ваших привычек просмотра. Наш мир построен на данных, а SQL — это язык программирования, который значительно упрощает навигацию по этим данным.
Помимо изучения SQL и его использования, мы рассмотрим, как вы можете выучить язык и какие виды работ вы могли бы получить, если вы изучите SQL. Например, если вы заинтересованы в работе в индустрии данных, изучение SQL очень важно.
Что такое SQL?
Как мы обсуждали в нашей статье о том, для чего используются различные языки программирования, язык структурированных запросов, или сокращенно SQL, — это язык программирования, который взаимодействует с базами данных. Назначение SQL (часто произносимое как продолжение) состоит в том, чтобы хранить, извлекать, управлять и манипулировать данными в системе управления базами данных.
SQL был разработан IBM в начале 1970-х годов и стал коммерчески доступным в 1979 году. Он принят во всем мире в качестве стандартной системы управления реляционными базами данных (RDBMS).
Он использует наборы ключевых слов для извлечения данных из баз данных, и эти ключевые слова называются операторами. Позже мы рассмотрим некоторые операторы, доступные в SQL.
Фонд малины Пи
Введение в базы данных и SQL
БудущееУзнать
SQL для анализа данных
Что такое база данных?
Базы данных окружают нас повсюду, и почти каждой компании и бизнесу необходимо хранить информацию в цифровом виде. База данных — это набор организованных данных, которые можно легко хранить, сортировать, извлекать и искать.
База данных — это набор организованных данных, которые можно легко хранить, сортировать, извлекать и искать.
Существует множество типов баз данных, и выбор типа зависит от типа данных, которые вы хотите хранить. Давайте рассмотрим несколько популярных типов баз данных:
- Реляционные базы данных — эти базы данных расположены в строках и столбцах, хранят и предоставляют данные в нескольких таблицах и позволяют вам идентифицировать и получать доступ к данным по отношению друг к другу. Все реляционные базы данных используют SQL. Microsoft SQL Server является примером системы управления реляционными базами данных.
- Базы данных NoSQL — сюда входят любые базы данных, не использующие SQL в качестве основного языка. Эти базы данных лучше подходят для тех, кто не хочет, чтобы их данные были структурированы. Мы поговорим об этих базах данных позже. CouchDB — пример базы данных NoSQL.
- Облачные базы данных — это любая база данных, которая работает в облаке, доступ к этим базам данных предоставляется как услуга. Они требуют минимального обслуживания и обеспечивают гибкость. Oracle Autonomous Database — это пример облачной базы данных.
- Базы данных временных рядов — это базы данных, оптимизированные для данных с отметками времени, что обеспечивает более точное понимание. Druid является примером базы данных временных рядов.
 Они требуют минимального обслуживания и обеспечивают гибкость. Oracle Autonomous Database — это пример облачной базы данных.
Они требуют минимального обслуживания и обеспечивают гибкость. Oracle Autonomous Database — это пример облачной базы данных.Для чего используется SQL?
Итак, теперь, когда вы знаете, что такое SQL, вам может быть интересно, для чего он используется. Как мы упоминали ранее, это язык программирования, используемый для связи с реляционными базами данных. Но давайте рассмотрим это немного дальше.
SQL позволяет выполнять запросы к базе данных различными способами, используя операторы, похожие на английские. Он используется на веб-сайтах для внутреннего хранения данных и решений для обработки данных (например, Facebook использует SQL).
Помимо Facebook, вы можете ожидать, что SQL будет использоваться в музыкальных приложениях, таких как Spotify, банковских приложениях, таких как Revolut, и других платформах социальных сетей, таких как Twitter и Instagram. SQL является наиболее часто используемым языком баз данных, поэтому его можно использовать практически в любой компании, которой необходимо хранить реляционные данные.
SQL является наиболее часто используемым языком баз данных, поэтому его можно использовать практически в любой компании, которой необходимо хранить реляционные данные.
Запросы в SQL используются для извлечения данных из базы данных, но эффективность запросов различается. Это связано с тем, что многие базы данных имеют собственные системные дополнительные проприетарные расширения.
По сути, SQL обеспечивает функциональность CRUD для баз данных. Что означает CRUD?
- Создать
- Читать
- Обновление
- Удалить.
CloudSwyft Global Systems, Inc.
Microsoft Future Ready: запрос данных с Transact-SQL (T-SQL)
БудущееУзнать
Основы разработки программного обеспечения: языки программирования и HTML
Операторы SQL
Если бы вы перемещались по большой базе данных без SQL, поиск необходимых данных занял бы значительно больше времени.
Используя оператор SELECT, вы можете выбирать данные по типам таблиц и столбцов. Таким образом, вы можете мгновенно определить наборы данных, отвечающие всем требованиям вашего поиска, вместо того, чтобы тратить много времени на поиск вручную.
Оператор INSERT позволяет добавлять в таблицы новую информацию. Как и в случае с оператором SELECT, вы можете выбрать несколько столбцов для ввода данных.
Оператор DELETE делает именно то, на что он похож: он позволяет вам удалять существующие записи в таблице. Запрос DELETE также позволяет указать строки, которые должны быть удалены и которые соответствуют определенным условиям.
Оператор CREATE DATABASE — это первый шаг к настройке вашей базы данных, он используется для создания совершенно новой базы данных в вашей системе управления базами данных. Точно так же CREATE TABLE используется для создания новой таблицы после создания базы данных.
Оператор UPDATE используется для обновления одной или нескольких записей в базе данных. Вы можете либо обновить все строки сразу, либо использовать условие, чтобы изменить только подмножество.
Вы можете либо обновить все строки сразу, либо использовать условие, чтобы изменить только подмножество.
Типы команд SQL
Язык можно разделить на четыре типа команд SQL — DDL, DML, DQL и DCL. Рассмотрим каждый из этих разделов.
- DDL (язык определения данных) — используется для создания и изменения объектов базы данных, таких как таблицы, пользователи и индексы.
- DML (язык обработки данных) — используется для удаления, добавления и изменения данных в базах данных.
- DCL (язык управления данными) — используется для управления доступом к любым данным в базе данных.
- DQL (язык запросов данных) — используется для выполнения запросов к данным и поиска информации и состоит только из операторов COMMAND.
Существуют инструменты, которые помогут вам писать SQL, некоторые из этих инструментов включают Microsoft SQL Server Management Studio, DataGrip, Oracle SQL Developer, SQL Workbench и Toad.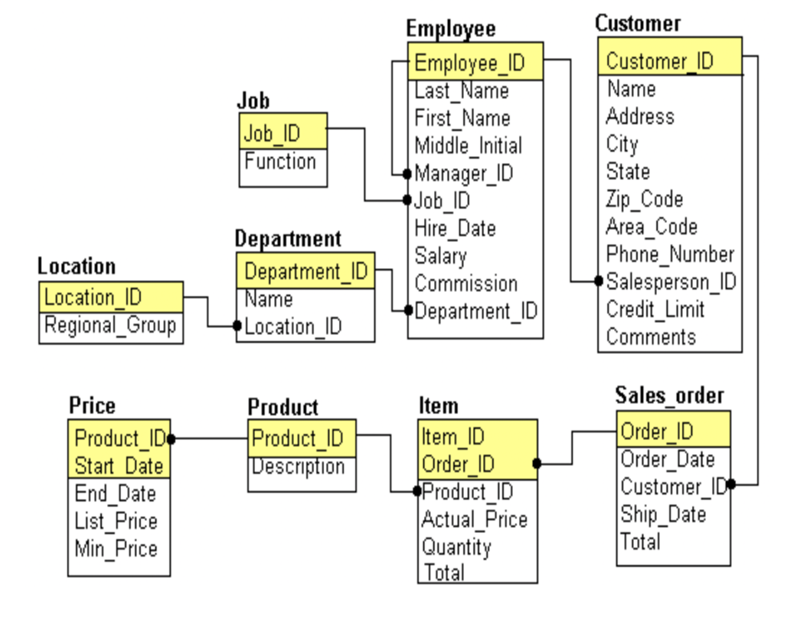
SQL против NoSQL
Базы данных NoSQL получили известность в конце 2000-х годов для размещения данных с меньшей потребностью в предварительной структуре. Эти типы баз данных, как правило, проще для разработчиков, поскольку они иногда имеют более быстрые запросы и более гибкие модели данных.
Для сравнения, базы данных на основе SQL используются специально для реляционных данных. Они позволяют гибко использовать запросы, хорошо структурированы и занимают меньше места для хранения данных. Базы данных SQL гораздо более распространены, чем NoSQL, но часто они используются вместе.
Между ними есть некоторые существенные различия, в том числе:
- Масштабируемость . Базы данных NoSQL, как правило, масштабируются горизонтально, тогда как базы данных SQL чаще масштабируются вертикально. Это означает, что базы данных NoSQL часто могут обрабатывать большие объемы трафика.
- Структура — Базы данных SQL имеют табличную структуру, но базы данных NoSQL могут быть хранилищами на основе графиков, документов или широких столбцов. Базы данных SQL лучше подходят для многострочных транзакций.
- Знания и сообщество . Существует огромное количество информации и сообществ, доступных для SQL, поскольку он более распространен и существует дольше. NoSQL не использует такое количество форумов и ресурсов, поэтому при необходимости может быть сложнее обратиться за помощью.
 Базы данных SQL лучше подходят для многострочных транзакций.
Базы данных SQL лучше подходят для многострочных транзакций.
CloudSwyft Global Systems, Inc.
Запрос данных с Transact-SQL с Python
Боксплей
Руководство для начинающих по анализу данных
Типы вакансий SQL
Изучение SQL откроет возможности для различных профессий. Давайте рассмотрим некоторые из доступных вариантов.
Давайте рассмотрим некоторые из доступных вариантов.
Специалист по данным
Специалист по данным — это специалист по анализу данных. Он извлекает, анализирует и интерпретирует большие данные из различных источников для решения проблем. SQL имеет решающее значение для специалистов по данным, поскольку базы данных лежат в основе их работы из-за анализа данных, который они должны выполнять.
Ознакомьтесь с этим углубленным курсом по науке о данных, если вы хотите узнать больше об этом варианте карьеры.
SEO-аналитик
SEO-аналитик анализирует данные и оптимизирует контент сайта для увеличения органического поискового трафика. SQL выгоден для этой роли, поскольку он работает с большим количеством больших данных, а базы данных намного надежнее, чем часто используемые документы Excel.
Если вас интересует идея роли SEO, почему бы не попробовать наш учебный курс SEO и WordPress, чтобы начать?
Инженер-программист
Инженер-программист разрабатывает и создает программное обеспечение компьютерных систем и прикладное программное обеспечение. Для разработки программного обеспечения требуется знание языков программирования, а большинству программистов требуется некоторое знание SQL.
Для разработки программного обеспечения требуется знание языков программирования, а большинству программистов требуется некоторое знание SQL.
Если вы хотите стать инженером-программистом, наш ExpertTrack по основам разработки программного обеспечения проведет вас по некоторым основным вопросам.
Бизнес-аналитик
Бизнес-аналитик анализирует данные и документирует рыночную среду, чтобы принимать бизнес-решения. Эта роль тесно связана с SQL, так как он очень объемный, и вы почти наверняка будете работать с реляционными базами данных.
Чтобы узнать больше о данных для бизнеса, ознакомьтесь с этим замечательным курсом по бизнес-аналитике.
Помимо того, что SQL может помочь вам занять одну из этих ролей, он также может быть полезен тем, у кого есть собственный бизнес или кто планирует его открыть. Реляционные базы данных могут помочь вам хранить, сортировать и изменять огромные объемы данных.
Как выучить SQL
Поначалу первый шаг к изучению языка программирования может показаться сложным, но при наличии терпения и усердия вы сможете полностью раскрыть свой потенциал.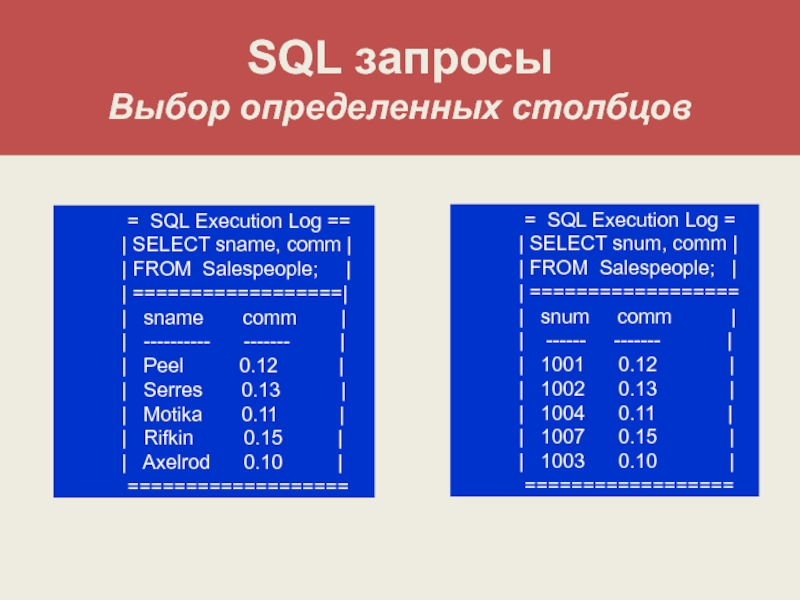 Начните с основ и постепенно переходите к более сложным командам, когда будете готовы.
Начните с основ и постепенно переходите к более сложным командам, когда будете готовы.
К счастью, существует множество онлайн-курсов и ресурсов, которые помогут вам выучить этот полезный язык. Попробовать курс, такой как наше введение в базы данных и SQL, — отличное место для начала.
Помимо онлайн-курсов, еще одним отличным способом обучения является просмотр видеоуроков и ознакомление с используемыми методами и программным обеспечением.
Один из лучших способов сохранить любую изучаемую информацию и запомнить команды SQL — это попрактиковаться. Вы можете скачать бесплатную систему управления базами данных SQL, например MySQL, и проверить свои знания, играя с функциями и исследуя базу данных.
Существуют даже веб-сайты, имитирующие систему управления SQL, например SQLfiddle. На подобных сайтах вы можете экспериментировать с написанием заявлений без необходимости установки какого-либо программного обеспечения.
Как только вы освоитесь со своими знаниями SQL, вы можете начать работать над сертификацией SQL. Это будет отлично смотреться в вашем резюме и действительно повысит ваши шансы получить одну из упомянутых выше вакансий SQL.
Это будет отлично смотреться в вашем резюме и действительно повысит ваши шансы получить одну из упомянутых выше вакансий SQL.
Заключительные мысли
Если вы хотите повысить квалификацию в своей нынешней должности или вообще найти новую карьеру, SQL — очень мощный и полезный язык для изучения. Мы надеемся, что эта статья снабдила вас знаниями, которые помогут вам начать изучение языка самостоятельно.
Если вы готовы начать знакомство с SQL прямо сейчас, почему бы не ознакомиться с нашими курсами по SQL для анализа данных, запросов данных с помощью Transact-SQL, а также для сохранения и структурирования данных?
Боксплей
Введение в бизнес-аналитику и анализ данных
CloudSwyft Global Systems, Inc.
Успешный анализ данных для современных отраслей

Данные запроса в Snowflake | Документация Snowflake
Snowflake поддерживает стандартный SQL, включая подмножество ANSI SQL:1999 и аналитические расширения SQL:2003.
Snowflake также поддерживает общие варианты для ряда команд, где эти варианты не конфликтуют друг с другом.
- Работа с объединениями
Объединение объединяет строки из двух таблиц для создания новой объединенной строки, которую можно использовать в запросе.
Изучите концепции соединений, типы соединений и способы работы с соединениями.
- Устранение избыточных объединений
Объединение ключевого столбца может ссылаться на таблицы, которые не нужны для объединения. Такое соединение называется избыточным соединением .
Узнайте о избыточных соединениях и о том, как их устранить для повышения производительности запросов.
- Работа с подзапросами
Подзапрос — это запрос внутри другого запроса.
Узнайте о подзапросах и о том, как их использовать.
- Запрос иерархических данных
Реляционные базы данных часто хранят иерархические данные с помощью разных таблиц.
Узнайте о запросах иерархических данных с помощью объединений, общих табличных выражений (CTE) и CONNECT BY.
- Работа с CTE (общие табличные выражения)
CTE (общее табличное выражение) — это именованный подзапрос, определенный в предложении WITH, результатом которого фактически является таблица.
Узнайте, как писать выражения CTE и работать с ними.
- Использование оконных функций
Оконные функции работают с окнами, которые представляют собой группы строк, которые каким-то образом связаны.
Узнайте об окнах, оконных функциях и о том, как использовать оконные функции для проверки данных.
- Идентификация последовательностей строк, соответствующих шаблону
В некоторых случаях может потребоваться идентифицировать последовательности строк таблицы, соответствующие шаблону.
Узнайте о сопоставлении шаблонов и о том, как использовать MATCH_RECOGNIZE для работы со строками таблицы, соответствующими шаблонам.
- Использование последовательностей
Последовательности используются для создания уникальных номеров для сеансов и операторов, включая параллельные операторы.
Узнайте, что такое последовательности и как их использовать.
- Использование сохраненных результатов запроса
При выполнении запроса результат сохраняется в течение определенного периода времени.
Узнайте, как сохраняются результаты запроса, как долго доступны сохраненные результаты,
и как использовать сохраненные результаты запросов для повышения производительности.- Вычисление количества уникальных значений
Существуют различные методы определения количества уникальных элементов в столбце.
Изучите методы идентификации и сообщения об отдельных элементах данных.
- Оценка подобия двух или более наборов
Snowflake предоставляет механизмы для сравнения наборов данных на предмет сходства.
Узнайте, как Snowflake определяет сходство и как сравнивать несколько наборов данных на предмет сходства.
- Оценка часто встречающихся значений
Snowflake может анализировать данные, чтобы определить, насколько часто встречаются значения в данных.
Узнайте, как определяется частота и как запрашивать данные для определения частоты данных, используя семейство функций через APPROX_TOP_K.



