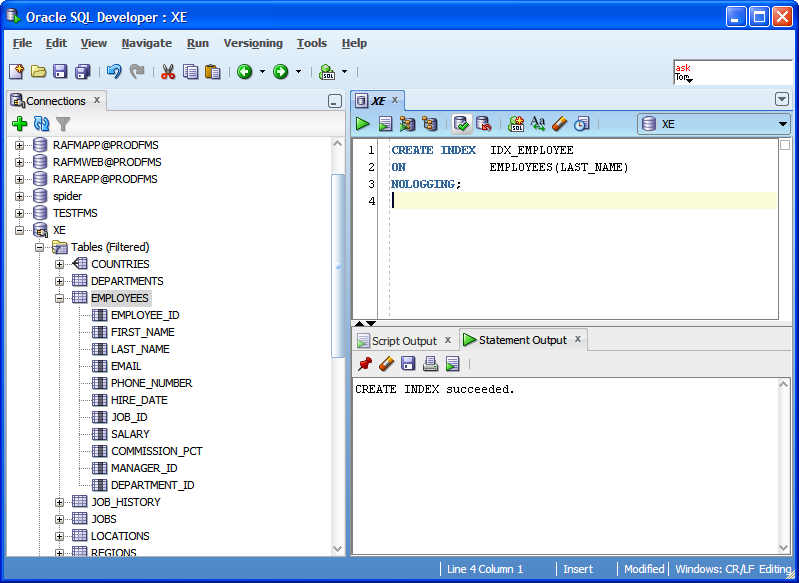
Create index mssql: CREATE INDEX (Transact-SQL) — SQL Server
Содержание
Использование SQL CREATE INDEX для создания кластеризованных и некластеризованных индексов
Оператор SQL CREATE INDEX используется для создания как кластеризованных, так и некластеризованных индексов в SQL Server. Индекс в базе данных очень похож на индекс в книге. Книжный указатель может иметь список тем, обсуждаемых в книге, в алфавитном порядке. Поэтому, если вы хотите найти какую-либо конкретную тему, вы просто заходите в индекс, находите номер страницы темы и переходите к этому конкретному номеру страницы. Индексы базы данных похожи и удобны.
В частности, если у вас в базе данных огромное количество записей, индексы могут ускорить процесс выполнения запроса. В SQL Server существует два основных типа индексов: кластеризованные индексы и некластеризованные индексы.
В этой статье вы увидите, что такое кластеризованные и некластеризованные индексы, в чем разница между этими двумя типами и как их можно создать с помощью инструкции SQL CREATE INDEX. Итак, начнем без дальнейших церемоний.
Итак, начнем без дальнейших церемоний.
Создание фиктивных данных
Следующий сценарий создает фиктивную базу данных с именем BookStore с одной таблицей, т. е. Books. Книги
таблица имеет четыре столбца: id , имя , категория и
цена :
1 2 3 4 5 6 7 8 10 3 9 3 | СОЗДАТЬ базу данных BookStore; GO ИСПОЛЬЗОВАНИЕ Книжный магазин; CREATE TABLE Books ( id INT PRIMARY KEY NOT NULL, name VARCHAR(50) NOT NULL, категория VARCHAR(50) NOT NULL, цена INT NOT NULL ) |
Теперь добавим несколько фиктивных записей в таблицу Books:
1 2 3 4 5 6 7 8 10 110003 12 13 14 9000. | ИСПОЛЬЗОВАТЬ BookStore
ВСТАВИТЬ В Книги
ЗНАЧЕНИЯ (1, ‘Книга1’, ‘Категория 1’, 1800), (2, ‘Книга2’, ‘Категория 2’, 1500), (3, ‘Книга3’, ‘Категория 3 2000) , (7, ‘Книга7’, ‘Категория 7’, 8000), (8, ‘Книга8’, ‘Категория 8’, 5000), (9, ‘Книга9’, ‘Категория 9’, 5400), (10, «Книга 10», «Категория 10», 3200) |
 15
15Приведенный выше скрипт добавляет 10 фиктивных записей в таблицу Books.
Кластерные индексы
Кластерные индексы определяют способ физической сортировки записей в таблице базы данных. Кластерный указатель очень похож на оглавление книги. В оглавлении вы можете увидеть, как физически отсортирована книга. Либо темы отсортированы по главам в соответствии с их актуальностью, либо они могут быть отсортированы по алфавиту.
Существует только один способ физической сортировки записей на диске. Например, записи могут быть
отсортированы по их идентификаторам, или они могут быть отсортированы по алфавитному порядку какого-либо строкового столбца или любым другим критериям.
Однако у вас не может быть записей, физически отсортированных по идентификаторам, а также по именам. Следовательно, кластер может быть только один.
индекс для таблицы базы данных. Таблица базы данных по умолчанию имеет один кластеризованный индекс в столбце первичного ключа. Чтобы увидеть
индекс по умолчанию, вы можете использовать sp_helpindex хранимая процедура, как показано ниже:
USE BookStore EXECUTE sp_helpindex Книги |
Вот результат:
Вы можете увидеть имя кластеризованного индекса и столбец, для которого кластеризованный индекс был создан по умолчанию.
Чтобы просмотреть записи, упорядоченные по кластеризованному индексу по умолчанию, просто выполните оператор SELECT, чтобы выбрать все
записи из таблицы books:
ВЫБЕРИТЕ * ИЗ Книг |
Вы можете видеть, что записи были отсортированы по кластерному индексу по умолчанию для столбца первичного ключа, т. е. id.
е. id.
Чтобы создать кластеризованный индекс в SQL Server, вы можете изменить SQL CREATE INDEX. Вот синтаксис:
СОЗДАТЬ КЛАСТЕРНЫЙ ИНДЕКС <имя_индекса> ON <имя_таблицы>(<имя_столбца> ASC/DESC) |
Давайте теперь создадим пользовательский кластеризованный индекс, который физически сортирует записи в таблице Books в порядке возрастания.
цены. Поскольку может быть только один кластеризованный индекс, нам сначала нужно удалить кластеризованный индекс по умолчанию.
созданный с помощью ограничения первичного ключа. Чтобы удалить кластеризованный индекс по умолчанию, вам просто нужно удалить основной
ключевое ограничение из таблицы, содержащей кластеризованный индекс по умолчанию. Посмотрите на следующий скрипт:
USE BookStore ALTER TABLE Books DROP CONSTRAINT PK__Books__3213E83F7DFA309B GO |
Теперь мы можем создать новый кластеризованный индекс с помощью оператора SQL CREATE INDEX, как показано ниже:
использовать BookStore CREATE CLUSTERED INDEX IX_tblBook_Price ON Books (цена ASC) |
В приведенном выше сценарии мы создаем кластеризованный индекс с именем IX_tblBook_Price . Этот кластеризованный индекс физически сортирует все записи в таблице Books по возрастанию цены.
Этот кластеризованный индекс физически сортирует все записи в таблице Books по возрастанию цены.
Давайте теперь выберем все записи из таблицы «Книги», чтобы увидеть, были ли они отсортированы в порядке возрастания
их цены:
ВЫБЕРИТЕ * ИЗ Книг |
Вот результат:
Из вывода видно, что записи фактически отсортированы по возрастанию цены.
Некластеризованные индексы
Некластеризованный индекс — это индекс, который физически не сортирует записи базы данных. Вместо этого некластеризованный индекс хранится отдельно от фактической таблицы базы данных. Это некластеризованный указатель, который фактически похож на указатель книги. Индекс книги хранится в отдельном месте, а фактическое содержание книги находится отдельно.
Запрос SQL CREATE INDEX можно изменить следующим образом, чтобы создать некластеризованный индекс:
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС <имя_индекса> ON <имя_таблицы>(<имя_столбца> ASC/DESC) |
Давайте создадим простой некластеризованный индекс, который сортирует записи в таблице Books по имени. Вы можете изменить SQL
Вы можете изменить SQL
CREATE INDEX запрос следующим образом:
использовать BookStore СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС IX_tblBook_Name ON Books (имя ASC) |
Как я сказал ранее, некластеризованный индекс хранится в месте, отличном от местоположения
фактической таблицы, созданный нами некластеризованный индекс будет выглядеть так:
Имя | Адрес записи |
Книга1 | Записать адрес |
Книга2 | Записать адрес |
Книга3 | Записать адрес |
Книга4 | Записать адрес |
Книга5 | Записать адрес |
Книга6 | Записать адрес |
Книга7 | Записать адрес |
Книга8 | Записать адрес |
Книга9 | Записать адрес |
Книга10 | Записать адрес |
Теперь, если пользователь ищет имя, идентификатор и цену конкретной книги, база данных сначала будет искать название книги в некластеризованном индексе. После поиска имени книги выполняется поиск идентификатора и цены книги в фактической таблице с использованием адреса записи записи в фактической таблице.
После поиска имени книги выполняется поиск идентификатора и цены книги в фактической таблице с использованием адреса записи записи в фактической таблице.
Заключение
В статье рассказывается, как использовать оператор SQL CREATE INDEX для создания как кластеризованного, так и некластеризованного индекса. В статье также на примерах показаны основные различия между двумя типами кластерных индексов.
- Автор
- Последние сообщения
Бен Ричардсон
Бен Ричардсон управляет Acuity Training, ведущим поставщиком обучения SQL в Великобритании. Он предлагает полный спектр обучения SQL от вводных курсов до продвинутого обучения администрированию и работе с хранилищами данных — см. здесь для получения более подробной информации. Acuity имеет офисы в Лондоне и Гилфорде, графство Суррей. Он также иногда пишет в блоге Acuity 9.0003
Просмотреть все сообщения Бена Ричардсона
Последние сообщения Бена Ричардсона (посмотреть все)
Индексы в SQL Server
Введение
Индекс SQL Server используется в таблице базы данных для более быстрого доступа к данным. В этой статье вы узнаете, что такое индексы SQL Server, зачем они нам нужны и как их реализовать в SQL Server.
В этой статье вы узнаете, что такое индексы SQL Server, зачем они нам нужны и как их реализовать в SQL Server.
Индексы в SQL Server
Индексы SQL используются в реляционных базах данных для быстрого извлечения данных. Они похожи на указатели в конце книг, цель которых — быстро найти тему. SQL предоставляет команды Create Index, Alter Index и Drop Index, используемые для создания нового индекса, обновления существующего и удаления индекса в SQL Server.
- Данные хранятся внутри базы данных SQL Server в виде «страниц», где размер каждой страницы составляет 8 КБ.
- Непрерывные восемь страниц называются «Ex. «nt».
- При создании таблицы один экстент будет выделен для двух таблиц; когда он вычисляется, он заполняется данными. Затем будет дано другое время, и эта протяженность может быть или не быть непрерывной до первой степени.
Сканирование таблицы
В SQL Server системная таблица с именем sysindexes содержит информацию об индексах, доступных для таблиц в базе данных. Если у таблицы нет индекса, в таблице sysindexes будет одна строка, связанная с этой таблицей, указывающая на отсутствие индекса в таблице, когда вы пишете оператор выбора с условием, где предложение, первый SQL Server будет ссылаться на «индид» ( идентификатор индекса).
Если у таблицы нет индекса, в таблице sysindexes будет одна строка, связанная с этой таблицей, указывающая на отсутствие индекса в таблице, когда вы пишете оператор выбора с условием, где предложение, первый SQL Server будет ссылаться на «индид» ( идентификатор индекса).
Столбцы таблицы «Sysindex» определяют, имеет ли столбец, в котором вы записываете условия, индекс. Когда это столбцы indid, чтобы получить адрес первого экстента таблицы, а затем ищет каждую строку таблицы для данного значения. Этот процесс проверяет заданное условие для каждой строки таблицы, что называется сканированием таблицы. Недостатком сканирования таблицы является то, что если количество строк в таблице не увеличивается, время, необходимое для извлечения данных, увеличивается, что влияет на производительность.
Тип индексов
SQL Server поддерживает два типа индексов:
- Кластеризованный индекс
- Некластерный индекс.
Кластерный индекс в SQL Server
Кластерный индекс B-Tree (вычисляемый) — это индекс, который физически упорядочивает строки в памяти в отсортированном порядке.
Преимущество кластеризованного индекса заключается в том, что поиск диапазона значений будет быстрым. Кластеризованный индекс внутренне поддерживается с использованием конечного узла структуры данных B-дерева btree кластеризованного индекса, который будет содержать данные таблицы; вы можете создать только один кластеризованный индекс для таблицы.
Как получить данные с помощью кластеризованного индекса?
При написании оператора select с условием в предложении where первый SQL Server будет ссылаться на столбцы indid таблицы Sysindexes, когда этот столбец содержит значение «1».
Затем он индексирует таблицу с помощью кластеризованного индекса. В этом случае это относится к столбцам. «Корневой» узел B-дерева кластеризованного индекса ищет в B-дереве конечный узел, содержащий первую строку, удовлетворяющую заданным условиям, и извлекает все строки, которые удовлетворить заданную ситуацию, которая будет в последовательности.
Вставка и обновление с помощью кластеризованного индекса
- Поскольку кластеризованный индекс физически упорядочивает строки в памяти в отсортированном порядке, вставка и будет выполняться медленно, поскольку строка должна вставляться или обновляться в отсортированном порядке.

- Наконец, страница, на которую необходимо вставить или обновить строку, и если на странице нет свободного места, создайте свободное место, а затем выполните вставку, обновление и удаление.
- Чтобы решить эту проблему при создании индекса кластеризации, укажите коэффициент заполнения, и если вы укажете коэффициент заполнения равным 70, то на каждой странице этой таблицы 70 % будут заполнены данными, а оставшиеся 30 % останутся свободными. .
- Поскольку на каждой странице есть свободное место, вставка и обновление будут быстрыми.
Некластеризованный индекс в SQL Server
- Некластеризованный индекс — это индекс, который физически не упорядочивает строки в памяти в отсортированном порядке.
- Преимущество некластеризованного индекса заключается в том, что поиск значений в диапазоне будет быстрым.
- Вы можете создать максимум 999 некластеризованных индексов для таблицы, 254 до SQL Server 2005.
- Некластеризованный индекс также поддерживается в структуре данных B-Tree. Тем не менее, конечные узлы B-дерева некластеризованного индекса содержат указатели на страницы, которые содержат данные таблицы, а не непосредственно данные таблицы.
 Тем не менее, конечные узлы B-дерева некластеризованного индекса содержат указатели на страницы, которые содержат данные таблицы, а не непосредственно данные таблицы.
Тем не менее, конечные узлы B-дерева некластеризованного индекса содержат указатели на страницы, которые содержат данные таблицы, а не непосредственно данные таблицы.Как получить данные с помощью некластеризованного индекса?
- Когда вы пишете оператор select с условием в предложении where, SQL Server будет ссылаться на столбцы «indid» таблицы sysindexes, а когда этот столбец содержит значение в диапазоне от 2 до 1000, тогда он указывает, что таблица имеет некластеризованный индекс. В этом случае он будет ссылаться на корень столбцов таблицы sysindexes, чтобы получить два адреса.
Корневой узел B-дерева некластеризованного индекса, а затем выполните поиск в B-дереве, чтобы найти конечный узел, содержащий указатели на строки, содержащие искомое значение, и извлеките эти строки.
Вставка и обновление с помощью некластеризованного индекса
- Вставка и обновление с помощью некластеризованного индекса не будут иметь никакого эффекта, поскольку физически строка в памяти не будет располагаться в отсортированном порядке.
- При использовании некластеризованного индекса строки вставляются и обновляются в конце таблицы.

| Кластерный индекс | Некластеризованный индекс |
| Это упорядочит строки в памяти физически в отсортированном порядке | Физически строки в памяти не будут располагаться в отсортированном порядке. |
| Это ускорит поиск диапазона значений. | Это ускорит поиск значений, не входящих в диапазон. |
| Индекс для таблицы. | Для таблицы можно создать не более 999 некластеризованных индексов. |
| Конечный узел 3-х уровней кластеризованного индекса содержит табличные данные. | Конечные узлы b-дерева некластеризованного индекса содержат указатели для получения включенных указателей с двумя табличными данными, а не непосредственно с табличными данными. |
Как создавать индексы в SQL Server?
Используйте команду create index со следующей системой для создания индекса.
создать [уникальный] [кластеризованный/не кластеризованный] индекс:
<имя_индекса> на <имя объекта>(<список столбцов>) [включить(<столбец>)] [with fillfactor=]
По умолчанию индекс является некластеризованным.
Например, в следующих примерах создается некластеризованный индекс по номеру отдела таблицы emp.
создать индекс DNoINdex по Emp(DeptNo)
Простые и составные индексы
- В зависимости от количества столбцов, для которых создается индекс, индексы подразделяются на простые и составные.
- Когда индексы создаются для отдельных столбцов, они называются простыми индексами; в сочетании с несколькими столбцами он называется составным индексом.
Например, в следующем примере создается некластеризованный индекс в сочетании со столбцами номера отдела и задания таблицы emp.
create index dnotedxi on emp(deptno asc,job desc)
Уникальный индекс
- Когда индекс создается с использованием ключевого слова unique, он называется уникальным индексом; вы создаете уникальный индекс для столбцов, и будет создано уникальное ограничение индекса.