Create index mssql: CREATE INDEX (Transact-SQL) — SQL Server
Содержание
Использование SQL CREATE INDEX для создания кластеризованных и некластеризованных индексов
Оператор SQL CREATE INDEX используется для создания как кластеризованных, так и некластеризованных индексов в SQL Server. Индекс в базе данных очень похож на индекс в книге. Книжный указатель может иметь список тем, обсуждаемых в книге, в алфавитном порядке. Поэтому, если вы хотите найти какую-либо конкретную тему, вы просто заходите в индекс, находите номер страницы темы и переходите к этому конкретному номеру страницы. Индексы базы данных похожи и удобны.
В частности, если у вас в базе данных огромное количество записей, индексы могут ускорить процесс выполнения запроса. В SQL Server существует два основных типа индексов: кластеризованные индексы и некластеризованные индексы.
В этой статье вы увидите, что такое кластеризованные и некластеризованные индексы, в чем разница между этими двумя типами и как их можно создать с помощью инструкции SQL CREATE INDEX. Итак, начнем без дальнейших церемоний.
Итак, начнем без дальнейших церемоний.
Создание фиктивных данных
Следующий сценарий создает фиктивную базу данных с именем BookStore с одной таблицей, т. е. Books. Книги
таблица имеет четыре столбца: id , имя , категория и
цена :
1 2 3 4 5 6 7 8 10 3 9 3 | СОЗДАТЬ базу данных BookStore; GO ИСПОЛЬЗОВАНИЕ Книжный магазин; CREATE TABLE Books ( id INT PRIMARY KEY NOT NULL, name VARCHAR(50) NOT NULL, категория VARCHAR(50) NOT NULL, цена INT NOT NULL ) |
Теперь добавим несколько фиктивных записей в таблицу Books:
1 2 3 4 5 6 7 8 10 110003 12 13 14 9000 15 | ИСПОЛЬЗОВАТЬ BookStore
ВСТАВИТЬ В Книги
ЗНАЧЕНИЯ (1, ‘Книга1’, ‘Каталог 1’, 1800), (2, ‘Книга2’, ‘Категория 2’, 1500), (3, ‘Книга3’, ‘Категория 3 2000) , (7, ‘Книга7’, ‘Категория 7’, 8000), (8, ‘Книга8’, ‘Категория 8’, 5000), (9, ‘Книга9’, ‘Категория 9’, 5400), (10, «Книга 10», «Категория 10», 3200) |
Приведенный выше скрипт добавляет 10 фиктивных записей в таблицу Books.
Кластерные индексы
Кластерные индексы определяют способ физической сортировки записей в таблице базы данных. Кластерный указатель очень похож на оглавление книги. В оглавлении вы можете увидеть, как физически отсортирована книга. Либо темы отсортированы по главам в соответствии с их актуальностью, либо они могут быть отсортированы по алфавиту.
Существует только один способ физической сортировки записей на диске. Например, записи могут быть
отсортированы по их идентификаторам, или они могут быть отсортированы по алфавитному порядку какого-либо строкового столбца или любым другим критериям.
Однако у вас не может быть записей, физически отсортированных по идентификаторам, а также по именам. Следовательно, кластер может быть только один.
индекс для таблицы базы данных. Таблица базы данных по умолчанию имеет один кластеризованный индекс в столбце первичного ключа. Увидеть
индекс по умолчанию, вы можете использовать sp_helpindex хранимая процедура, как показано ниже:
USE BookStore EXECUTE sp_helpindex Книги |
Вот результат:
Вы можете увидеть имя кластеризованного индекса и столбец, для которого кластеризованный индекс был создан по умолчанию.
Чтобы просмотреть записи, упорядоченные по кластеризованному индексу по умолчанию, просто выполните оператор SELECT, чтобы выбрать все
записи из таблицы books:
ВЫБЕРИТЕ * ИЗ Книг |
Вы можете видеть, что записи были отсортированы по кластерному индексу по умолчанию для столбца первичного ключа, т.е. id.
Чтобы создать кластеризованный индекс в SQL Server, вы можете изменить SQL CREATE INDEX. Вот синтаксис:
СОЗДАТЬ КЛАСТЕРНЫЙ ИНДЕКС <имя_индекса> ON <имя_таблицы>(<имя_столбца> ASC/DESC) |
Давайте теперь создадим пользовательский кластеризованный индекс, который физически сортирует записи в таблице Books в порядке возрастания.
цены. Поскольку может быть только один кластеризованный индекс, нам сначала нужно удалить кластеризованный индекс по умолчанию.
созданный с помощью ограничения первичного ключа. Чтобы удалить кластеризованный индекс по умолчанию, вам просто нужно удалить основной
ключевое ограничение из таблицы, содержащей кластеризованный индекс по умолчанию. Посмотрите на следующий скрипт:
USE BookStore ALTER TABLE Books DROP CONSTRAINT PK__Books__3213E83F7DFA309B GO |
Теперь мы можем создать новый кластеризованный индекс с помощью оператора SQL CREATE INDEX, как показано ниже:
использовать BookStore CREATE CLUSTERED INDEX IX_tblBook_Price ON Books (цена ASC) |
В приведенном выше сценарии мы создаем кластеризованный индекс с именем IX_tblBook_Price . Этот кластеризованный индекс физически сортирует все записи в таблице Books по возрастанию цены.
Давайте теперь выберем все записи из таблицы «Книги», чтобы увидеть, были ли они отсортированы в порядке возрастания
их цены:
ВЫБЕРИТЕ * ИЗ Книг |
Вот результат:
Из вывода видно, что записи фактически отсортированы по возрастанию цены.
Некластеризованные индексы
Некластеризованный индекс — это индекс, который физически не сортирует записи базы данных. Вместо этого некластеризованный индекс хранится отдельно от фактической таблицы базы данных. Это некластеризованный указатель, который фактически похож на указатель книги. Индекс книги хранится в отдельном месте, а фактическое содержание книги находится отдельно.
Запрос SQL CREATE INDEX можно изменить следующим образом, чтобы создать некластеризованный индекс:
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС <имя_индекса> ON <имя_таблицы>(<имя_столбца> ASC/DESC) |
Давайте создадим простой некластеризованный индекс, который сортирует записи в таблице Books по имени. Вы можете изменить SQL
CREATE INDEX запрос следующим образом:
использовать BookStore СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС IX_tblBook_Name ON Books (имя ASC) |
Как я сказал ранее, некластеризованный индекс хранится в месте, отличном от местоположения
фактической таблицы, созданный нами некластеризованный индекс будет выглядеть так:
Имя | Адрес записи |
Книга1 | Записать адрес |
Книга2 | Записать адрес |
Книга3 | Записать адрес |
Книга4 | Записать адрес |
Книга5 | Записать адрес |
Книга6 | Записать адрес |
Книга7 | Записать адрес |
Книга8 | Записать адрес |
Книга9 | Записать адрес |
Книга10 | Записать адрес |
Теперь, если пользователь ищет имя, идентификатор и цену конкретной книги, база данных сначала будет искать название книги в некластеризованном индексе. После поиска имени книги выполняется поиск идентификатора и цены книги в фактической таблице с использованием адреса записи записи в фактической таблице.
После поиска имени книги выполняется поиск идентификатора и цены книги в фактической таблице с использованием адреса записи записи в фактической таблице.
Заключение
В статье рассказывается, как использовать оператор SQL CREATE INDEX для создания как кластеризованного, так и некластеризованного индекса. В статье также на примерах показаны основные различия между двумя типами кластерных индексов.
- Автор
- Последние сообщения
Бен Ричардсон
Бен Ричардсон управляет Acuity Training, ведущим поставщиком обучения SQL в Великобритании. Он предлагает полный спектр обучения SQL от вводных курсов до продвинутого обучения администрированию и работе с хранилищами данных — см. здесь для получения более подробной информации. Acuity имеет офисы в Лондоне и Гилфорде, графство Суррей. Он также иногда пишет в блоге Acuity 9.0003
Просмотреть все сообщения Бена Ричардсона
Последние сообщения Бена Ричардсона (посмотреть все)
SQL Server Helper
Сообщения об ошибках SQL Server — сообщение 1940 Сообщение об ошибке Сервер: Сообщение 1940, Уровень 16, Состояние 1, Строка 1 Не удается создать индекс для представления «<Имя представления>». Причины Представление — это виртуальная таблица, содержимое которой определяется запросом. Как и настоящая таблица, представление состоит из набора именованных столбцов и строк данных. Однако представление не существует в виде сохраненного набора значений данных в базе данных. Строки и столбцы данных поступают из одной или нескольких таблиц, на которые ссылается запрос, определяющий представление, и создаются динамически при обращении к представлению. |
 У него нет уникального кластеризованного индекса.
У него нет уникального кластеризованного индекса. Создание индексов для представлений разрешено, если первый индекс, созданный для представления, должен быть уникальным кластеризованным индексом. После создания уникального кластеризованного индекса можно создавать дополнительные некластеризованные индексы. Создание уникального кластеризованного индекса для представления повышает производительность запросов, поскольку представление хранится в базе данных точно так же, как хранится таблица с кластеризованным индексом.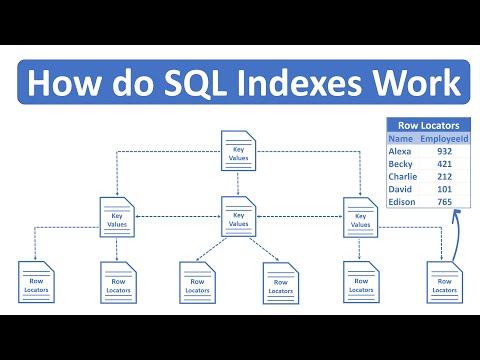 Если первый индекс, созданный для представления, не предназначен для уникального кластерного индекса, это сообщение об ошибке будет вызвано SQL Server.
Если первый индекс, созданный для представления, не предназначен для уникального кластерного индекса, это сообщение об ошибке будет вызвано SQL Server.
Чтобы проиллюстрировать это, вот скрипт, который покажет, как можно встретить это сообщение об ошибке:
CREATE TABLE [dbo].[Клиент] (
[CustomerID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Имя] VARCHAR(50) НЕ NULL,
[Фамилия] VARCHAR(50) НЕ NULL,
[Адрес] VARCHAR(100) НЕ NULL,
[Город] VARCHAR(50) НЕ NULL,
[Состояние] CHAR(2) НЕ NULL,
[ZIP] VARCHAR(10) НЕ NULL
)
ИДТИ
CREATE VIEW [dbo].[Customer_NY]
С ПРИВЯЗКОЙ СХЕМ
В КАЧЕСТВЕ
ВЫБЕРИТЕ [CustomerID], [Имя], [Фамилия], [Адрес], [Город], [Штат], [ZIP]
ОТ [dbo].[Клиент]
ГДЕ [Штат] = 'Нью-Йорк'
ИДТИ
CREATE INDEX [IX_Customer_NY_Name] ON [dbo].[Customer_NY] ([LastName], [FirstName])
ВПЕРЕД Сообщение 1940, уровень 16, состояние 1, строка 2 Невозможно создать индекс для представления «dbo.Customer_NY».У него нет уникального кластеризованного индекса.
 У него нет уникального кластеризованного индекса.
У него нет уникального кластеризованного индекса. Поскольку представление [dbo].[Customer_NY] не имеет предыдущих индексов, а первый индекс, создаваемый для представления, является простым индексом, SQL Server выдает это сообщение об ошибке.
Решение/Временное решение:
Как упоминалось ранее, первый индекс, созданный для представления, должен быть уникальным кластеризованным индексом. Если можно гарантировать уникальность значений столбца в создаваемом индексе, то все, что нужно сделать, — это сделать индекс уникальным и сгруппированным следующим образом:0003
CREATE UNIQUE CLUSTERED INDEX [IX_Customer_NY_Name] ON [dbo].[Customer_NY] ( [LastName], [FirstName] )
Однако, если невозможно гарантировать уникальность значений столбца, так как в Нью-Йорке может быть много людей с одинаковым именем и фамилией, то уникальный кластеризованный индекс необходимо создать для другого столбца. В данном определении таблицы [CustomerID] можно использовать для создания уникального кластеризованного индекса в представлении следующим образом:
СОЗДАТЬ УНИКАЛЬНЫЙ КЛАСТЕРНЫЙ ИНДЕКС [IX_Customer_NY] ON [dbo].