Curl парсер php: Парсинг PHP: Оттачиваем CURL | PROG-TIME
21 книга для самостоятельного изучения парсинга — Что почитать на vc.ru
Моя компания занимается парсингом сайтов в России уже более трёх лет, ежедневно мы парсим порядка 500 крупнейших интернет-магазинов в России. Направление парсинга перспективно, т.к. информации все больше и всегда есть задача ее структурировать для последующего анализа.
16 004
просмотров
Для тех, кто хочет научиться парсингу самостоятельно, предлагаем следующую подборку из 21 книги (на английском языке), опираясь на рейтинг BookAuthority, который выбирает лучшие книги в мире, основываясь на публикациях, рекомендациях, рейтингах и мнениях. Мы специально оставили и английские названия книг, чтобы вам было проще их найти.
1. Краткое руководство по веб-парсингу на R (R Web Scraping Quick Start Guide)
Парсинг веб-сайтов становится все более популярными, поскольку данные — нефть 21 века. Благодаря этой книге вы получите ключевые знания об использовании XPath, regEX и веб-библиотек для R, таких как Rvest и RSelenium.
2. Наука о данных и R: конкретные примеры для вычислительных объяснений и решения проблем (Data Science in R)
Книга на реальных примерах рассказывает о задачах, связанных с решением вычислительных проблем, возникающих при анализе данных. Она раскрывает динамический и итеративный процесс, в помощью которого аналитики данных решают задачи, и рассказывает о различных способах поиска решений.
3. Изучаем Scrapy (Learning Scrapy)
В этой книге рассказывается о Scrapy v 1.0, который дает вам возможность без особых усилий извлекать (т.е. парсить) полезные данные практически из любого источника. Книга начинается с объяснения основ Scrapy Framework, после чего следует подробное описание того, как используя Python и сторонние API можно извлечь данные из любого источника, очистить их и сохранить в соответствии с вашими требованиями. Вы ознакомитесь с хранением информации в базах данных, с основами поисковых систем и работы с ними через Spark Streaming, платформу аналитики в реальном времени. К концу этой книги разработчики легко смогут получать любые данные для своих задач.
К концу этой книги разработчики легко смогут получать любые данные для своих задач.
4. Веб-парсинг в Excel (Web Scraping with Excel)
Парсинг с Microsoft Excel может быть пугающим для непрограммистов и новичков. Эта книга, однако, демонстрирует, что с правильными знаниями и практикой этот навык может быть быстро и эффективно освоен каждым. Начинающие пользователи, начинающие разработчики VBA и опытные программисты найдут ценные уроки, советы и хитрости в этом простом, но в то же время лаконичном руководстве, которое поможет освоить этот ценный навык, который по-прежнему востребован.
5. Визуализация данных с Python и JavaScript (Data Visualization with Python and JavaScript)
Python и Javascript являются идеальным дополнением для превращения данных в многофункциональные интерактивные графики, которые затмят любые статичные изображения. Разработчики должны знать, как превратить необработанные данные, часто «грязные» или искаженные, в динамические интерактивные визуализации. Автор, используя интересные примеры и подчеркивая лучшие практики, учит, как использовать для этого возможности лучших в своем классе библиотек Python и Javascript.
Автор, используя интересные примеры и подчеркивая лучшие практики, учит, как использовать для этого возможности лучших в своем классе библиотек Python и Javascript.
6. Автоматизация маркетинга с помощью ботов (Automated Marketing with Webbots)
Что если ключ к эффективному маркетингу спрятан в ботах? Эта книга может стать окончательным ответом на вопросы, которые вас беспокоят. Побочными эффектами от чтения этой книги может стать внезапный подъем самооценки, беспрецедентная решительность при принятии маркетинговых решений, а также пожизненное пристрастие к автоматизации и парсингу данных.
7. Веб-парсинг на Python (Web Scraping with Python)
Книга рассказывает о том, как правильно получать данные с любых сайтов при помощи Python. Она предназначена для разработчиков, которые хотят использовать парсинг в законных целях. Предыдущий опыт программирования на Python полезен, но не обязателен. Любой человек, обладающий общими знаниями языков программирования, может прочесть книгу и понять основные принципы.
8. Автоматизированный сбор данных с помощью R: практическое руководство по парсингу веб-страниц и интеллектуальному анализу текста (Automated Data Collection With R)
Практическое руководство по поиску в сети и интеллектуальному анализу текста, как для начинающих, так и для опытных пользователей R. Книга представляет фундаментальные концепции архитектуры Сети и баз данных, рассказывает про HTTP, HTML, XML, JSON, SQL. Предоставляет основные методы для получения веб-документов и наборов данных (XPath и регулярные выражения). Представляет большой набор упражнений, которые помогут читателю понять каждую технику. В книге изучается как обучаемые, так и и необучаемые методы, очистка данных и управление текстом, приводятся тематические исследования, а также примеры для каждого из представленных методов.
8. «Поваренная книга» парсинга на Python (Python Web Scraping Cookbook)
Эта книга, ориентированная на практические решения, научит вас методам разработки высокопроизводительных парсеров и поможет понять, как работают краулеры, карты сайтов, автоматизация форм, сайты на основе Ajax и кэш. В ней изучается ряд реальных сценариев, в которых полностью рассматриваются все части циклов разработки и жизненных циклов продуктов. Вы не только разовьете навыки проектирования и разработки надежных парсеров, но и развернете свою кодовую базу в AWS. Если вы занимаетесь разработкой программного обеспечения, разработкой продуктов или интеллектуальным анализом данных (или заинтересованы в создании продуктов на основе данных), то точно найдете эту книгу полезной, поскольку каждый рецепт в ней имеет четкую цель и задачу.
В ней изучается ряд реальных сценариев, в которых полностью рассматриваются все части циклов разработки и жизненных циклов продуктов. Вы не только разовьете навыки проектирования и разработки надежных парсеров, но и развернете свою кодовую базу в AWS. Если вы занимаетесь разработкой программного обеспечения, разработкой продуктов или интеллектуальным анализом данных (или заинтересованы в создании продуктов на основе данных), то точно найдете эту книгу полезной, поскольку каждый рецепт в ней имеет четкую цель и задачу.
10. Краткое руководство по парсингу на Go (Go Web Scraping Quick Start Guide)
Парсинг — это процесс извлечения информации с использованием различных инструментов, которые получают и очищают данные. Go становится популярным языком для этого. Книга быстро объяснит вам, как собирать данные с различных веб-сайтов, используя библиотеки Go, такие как Colly и Goquery.
11. Цифровые социальные исследования (Digital Social Research)
Чтобы проанализировать социальные и поведенческие явления в нашем цифровом мире, необходимо понять основные исследовательские возможности и проблемы, специфичные для интернета и цифровых данных. Эта книга представляет собой обзор многих методов, которые являются частью инструментария цифрового социолога. Используя онлайн-методы в устоявшихся шаблонах социальных исследований, Джузеппе Вельтри обсуждает принципы и фреймворки, лежащие в основе каждого метода цифровых исследований. Это практическое руководство охватывает методологические вопросы, такие как работа с различными типами цифровых данных, вопросы их проверки, репрезентативности и выборки для больших данных. В нем рассматриваются различные неявные подходы к сбору данных (такие как парсинг веб-страниц и майнинг социальных сетей), а также явные методы (включая качественные методы, веб-опросы и эксперименты). Особое внимание уделяется вычислительным подходам к статистическому анализу, анализу текста и сетевому анализу. Книга будет отличным ресурсом для студентов и исследователей в области социальных и гуманитарных наук, проводящих цифровые исследования (или заинтересованных в них в будущем).
Эта книга представляет собой обзор многих методов, которые являются частью инструментария цифрового социолога. Используя онлайн-методы в устоявшихся шаблонах социальных исследований, Джузеппе Вельтри обсуждает принципы и фреймворки, лежащие в основе каждого метода цифровых исследований. Это практическое руководство охватывает методологические вопросы, такие как работа с различными типами цифровых данных, вопросы их проверки, репрезентативности и выборки для больших данных. В нем рассматриваются различные неявные подходы к сбору данных (такие как парсинг веб-страниц и майнинг социальных сетей), а также явные методы (включая качественные методы, веб-опросы и эксперименты). Особое внимание уделяется вычислительным подходам к статистическому анализу, анализу текста и сетевому анализу. Книга будет отличным ресурсом для студентов и исследователей в области социальных и гуманитарных наук, проводящих цифровые исследования (или заинтересованных в них в будущем).
12. Веб-боты, пауки и экранные парсеры (Webbots, Spiders, and Screen Scrapers)
В Интернете имеется огромное количество данных, но их сортировка и ручной сбор могут быть утомительными и занимать много времени. Вместо того, чтобы бесконечно разглядывать одну страницу за другой, почему бы не позволить ботам сделать эту работу за вас? «Веб-боты, пауки и парсеры» покажет вам, как создавать простые программы на PHP/CURL для извлечения, анализа и архивирования данных, которые помогут принимать обоснованные решения.
Вместо того, чтобы бесконечно разглядывать одну страницу за другой, почему бы не позволить ботам сделать эту работу за вас? «Веб-боты, пауки и парсеры» покажет вам, как создавать простые программы на PHP/CURL для извлечения, анализа и архивирования данных, которые помогут принимать обоснованные решения.
13. Веб-парсинг на Python: собираем больше данных из интернета (Web Scraping with Python)
Если программирование — это волшебство, то парсинг, безусловно, является формой волшебства. Написав простую программу для автоматизации, вы сможете опрашивать веб-серверы, запрашивать данные и анализировать их для получения необходимой информации. Расширенное издание этой практической книги не только познакомит вас с поиском в интернете, но и послужит исчерпывающим руководством по сбору практически всех типов данных из современной Сети.
14. Парсинг для науки о данных на Python (Web Scraping for Data Science with Python)
В этой книге авторы стремятся предоставить краткое и современное руководство по парсингу сайтов, используя Python в качестве языка программирования. Эта книга написана для аудитории, специализирующейся на данных, и не скрывает никаких подробностей или лучших практик. Авторы сами являются учеными в области данных и считают, что веб-скрапинг является мощным инструментом в арсенале любого дата сайентиста, поскольку многие проекты в области данных начинаются с получения соответствующего набора данных. Так почему бы не использовать для этого сокровищницу информация — интернет?
Эта книга написана для аудитории, специализирующейся на данных, и не скрывает никаких подробностей или лучших практик. Авторы сами являются учеными в области данных и считают, что веб-скрапинг является мощным инструментом в арсенале любого дата сайентиста, поскольку многие проекты в области данных начинаются с получения соответствующего набора данных. Так почему бы не использовать для этого сокровищницу информация — интернет?
15. «Поваренная книга» автоматизации на Python (Python Automation Cookbook)
Вы когда-нибудь делали одну и ту же монотонную офисную работу снова и снова? Или пытались найти простой способ сделать вашу жизнь лучше, автоматизируя некоторые из ваших повторяющихся задач? Используя рабочий проверенный подход, вы поймете, как автоматизировать все скучные вещи с помощью Python. «Поваренная книга» поможет вам получить четкое представление о том, как автоматизировать ваши бизнес-процессы с помощью Python, как искать новые возможности для роста с помощью парсинга веб-страниц, как анализировать информацию и создавать автоматические отчеты в виде электронных таблиц с графиками и автоматически генерировать электронные письма.
16. Практический парсинг веб-страниц с помощью Python (Hands-On Web Scraping with Python)
Парсинг веб-страниц — это важный метод, используемый во многих компаниях для сбора ценных данных. Эта книга позволит вам глубоко вникнуть в техники и методики парсинга. Вы узнаете, как эффективно извлекать данные, используя различные методы Python и других популярных инструментов.
17. Мгновенный веб-парсинг на PHP (Instant PHP Web Scraping)
Интернет подарил нам огромные объемы данных, свободно доступных для общего пользования. Однако сбор и обработка этих данных может занять много времени, если выполняется всё вручную. Тем не менее, парсинг может предоставить инструменты и фреймворки для получения данных за одно нажатие кнопки. ”Мгновенный веб-парсинг на PHP” предоставляет практические примеры и пошаговые инструкции, которые помогут вам разобраться с основными приемами, необходимыми для получения данных со страниц с помощью PHP. Книга даст вам знания и основу для создания веб-приложений для извлечения данных в самых разных целях — мониторинга, исследований, интеграции и т. п.
п.
18. Веб-парсинг на PHP, вторая редакция (Web Scraping with PHP, 2nd Edition)
Узнайте, как автоматизировать веб с помощью PHP. Хотите получать данные с другого сайта, но API недоступен? Или API просто не предоставляет то, что нужно? Парсинг — проверенный временем метод сбора необходимой информации с веб-страницы. В этой книге вы познакомитесь с различными инструментами и библиотеками для получения, анализа и извлечения данных из HTML. За последние десять лет Интернет прошел большой путь. «Веб-парсинг на PHP» во второй редакции учитывает использование современных библиотек на основе PHP 7, написанных для более легкого взаимодействия с данными. Используете ли вы обычный PHP с cURL или популярный фреймворк, такой как Zend Framework или Symfony, эта книга полна примеров, показывающих, как использовать доступные классы и функции.
19. Начинаем работать с Beautiful Soup (Getting Started with Beautiful Soup)
Эта книга отлично подходит для всех, кто интересуется поиском и извлечением информации с сайтов. Однако для лучшего ее понимания требуются базовые знания Python, HTM и CSS. Beautiful Soup — это пакет Python для анализа документов HTML и XML. Он создает дерево синтаксического анализа для проанализированных страниц, которое можно использовать для извлечения данных из HTML, что полезно для очистки данных. При этом для написания приложения с использованием Beautiful Soup не требуется много кода.
Однако для лучшего ее понимания требуются базовые знания Python, HTM и CSS. Beautiful Soup — это пакет Python для анализа документов HTML и XML. Он создает дерево синтаксического анализа для проанализированных страниц, которое можно использовать для извлечения данных из HTML, что полезно для очистки данных. При этом для написания приложения с использованием Beautiful Soup не требуется много кода.
20. Практический веб-парсинг для науки о данных (Practical Web Scraping for Data Science)
Эта книга представляет собой полное и современное руководство по парсингу веба с использованием Python в качестве языка программирования. Написанная для аудитории, специализирующейся на науке о данных, книга рассказывает как о веб-технологиях, с которыми она работает, так и о, собственно, извлечении информации. Авторы рекомендуют парсинг как мощный инструмент для любого ученого, поскольку многие проекты в Data Science начинают как раз с получения соответствующего набора данных.
21. Парсинг динамических страниц с PhantomJS (Scraping the Dynamic Web with PhantomJS)
Поиск информации в Интернете всегда был сложной задачей. Веб-браузеры используют статический HTML для генерации DOM, при этом HTML не всегда является полным или правильным. К счастью, браузеры совершают невероятную работу по отрисовке страниц из плохо написанного или даже неработающего HTML. Существует несколько библиотек для различных платформ, которые пытаются упростить извлечение информации из статического HTML-кода. К сожалению, эти решения не являются надежными или простыми в использовании для среднего веб-разработчика. Чтобы еще больше усложнить ситуацию, сеть превращается в динамичную среду. Вместо изучения новых моделей извлечения информации с веб-страниц, почему бы не использовать jQuery для надежного извлечения информации из полностью визуализированного DOM в автоматическом режиме?
php | kocherov.net
Частая проблема — tmp папка web сервера вдруг содержит n миллионов файлов.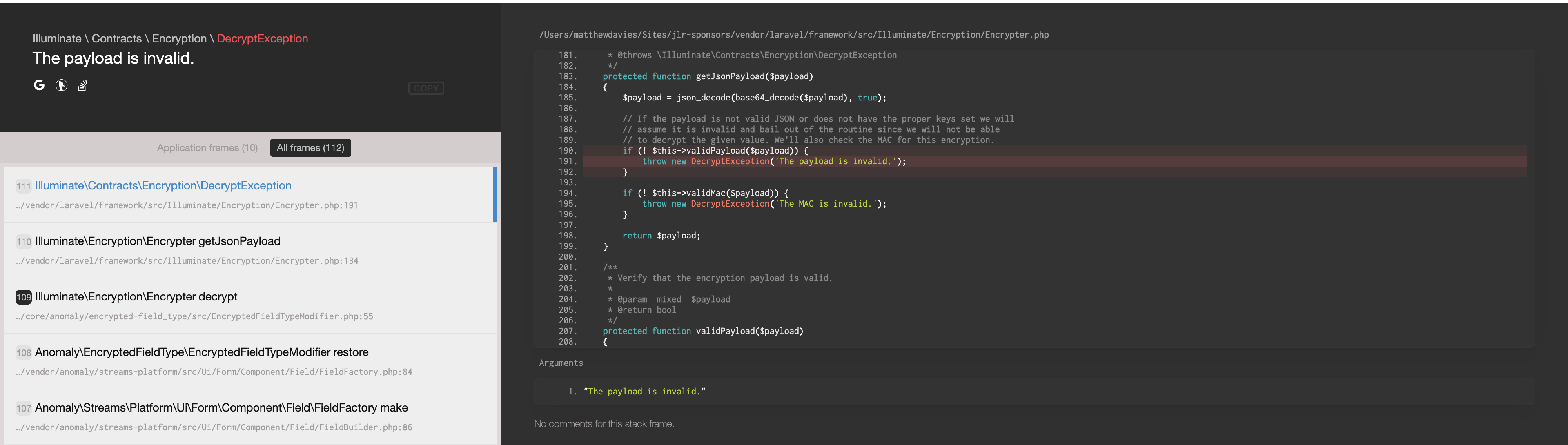 Скорее всего это файлы сессий. И образовались они там не вдруг, а за пару месяцев/лет.
Скорее всего это файлы сессий. И образовались они там не вдруг, а за пару месяцев/лет.
Диагностируем
Во первых, затруднительно посмотреть, что находится в папке, т.к. ни FAR, ни виндовый проводник (серверы с проблемой были на windows) не хотят такую папку открывать (FAR вылетал забрав 1гб оперативной памяти, где-то на чтении трехмиллионного файла). Как зайти в папку, содержащую много файлов? Переходим в папку в консоле через cd (переходит махом не зависимо от количества файлов) и пишем:
dir /p
Это постраничный вывод содержимого каталога. Несколько раз жмем пробел, убеждаясь что все забито файлами сессий.
Исправляем
Что же произошло и почему garbage collector (далее GC) PHP забил на вашу tmp папку и сто лет ее не чистил?
1) Возможно, не правильно заданы параметры php.ini session.gc_probability и session.gc_divisor. Вероятность запуска GC при каждом запуске скрипта — session.gc_probability / session.gc_divisor. По умолчанию — 1/100. Соответственно, если задать session.gc_probability = 0 GC не запустится никогда. Соответсвующие параметры нужно проверить и в коде приложения.
По умолчанию — 1/100. Соответственно, если задать session.gc_probability = 0 GC не запустится никогда. Соответсвующие параметры нужно проверить и в коде приложения.
2) Возможно, вы изменили session.save_path в своем приложении, и теперь она отличается от той, которая в php.ini. В этом случае GC чистить в вашей кастомной папке ничего не будет и вам нужно заботиться об этом самим, т.к. он чистит только папку, которая указана в ini. Цитата из конфигурационного файла:
; NOTE: If you are using the subdirectory option for storing session files
; (see session.save_path above), then garbage collection does *not*
; happen automatically. You will need to do your own garbage
; collection through a shell script, cron entry, or some other method.
; For example, the following script would is the equivalent of
; setting session.gc_maxlifetime to 1440 (1440 seconds = 24 minutes):
; cd /path/to/sessions; find -cmin +24 | xargs rm
3) Последнее, самое непонятное. Возможно, вы стали жертвой бага — https://bugs.php.net/bug.php?id=55333 Не знаю, правда это или нет, и баг ли это php или криворукость админов, но у меня на двух серверах, где не была изменена папка сессий по умолчанию, и все сохранялось в «C:/Windows/Temp», GC не работал. И это при абсолютной идентичности других настроек с серверами, где папка была изменена и все было ок. Решил проблему просто — сменил папку с дефолтной на свою, чего и вам желаю.
Возможно, вы стали жертвой бага — https://bugs.php.net/bug.php?id=55333 Не знаю, правда это или нет, и баг ли это php или криворукость админов, но у меня на двух серверах, где не была изменена папка сессий по умолчанию, и все сохранялось в «C:/Windows/Temp», GC не работал. И это при абсолютной идентичности других настроек с серверами, где папка была изменена и все было ок. Решил проблему просто — сменил папку с дефолтной на свою, чего и вам желаю.
Удаляем
В tmp папке на момент решения проблемы было 4 миллиона файлов. Удалил их просто:
del sess_*
Процесс удаления не слишком нагружает сервер, и было решено просто запустить операцию на сутки. Тихо мирно все старые файлы сессий были выкошены. Обязательно перед удалением меняйте tmp папку сессий, т.к. иначе пользователи вашего ресурса будут все сутки без конца разлогиниваться (в лучщем случае), а в худшем будут толстые дата лосы из-за вашей невнимательности. Сначала смените путь в php. ini, потом удаляйте.
ini, потом удаляйте.
Для Linux серверов есть хорошая статья на хабре: http://habrahabr.ru/post/152193/
cURL 7 в пользовательском агенте Linux
Mozilla/5.0 (X11; Linux x86_64) python-requests/3.6 CPython/3.6 curl/7.65.0 libcurl/7.65.0 Wget/1.21.0 PHP/5.0.0
90 002
cURL 7 в Linux
PHP 5.0.0
Вот некоторая подробная информация о том, что мы можем проанализировать и рассказать вам об этом пользовательском агенте.
Упрощенное считывание
Четкие, удобочитаемые описания программного обеспечения и платформы
Строка простого программного обеспечения
cURL 7 в Linux
Простое подописание
—
Простая операционная платформа
PHP 5.
 0.0
0.0
 0.0
0.0Дополнительное программное обеспечение
Дополнительные вещи, о которых объявляет этот пользовательский агент.
Программное обеспечение
Информация о веб-программном обеспечении
Программное обеспечение
CURL 7
Имя программного обеспечения
CURL
Код имени программного обеспечения
завиток
Версия программного обеспечения
7
Версия программного обеспечения (полная)
7.
65.0Имя двигателя макета
—
Версия механизма компоновки
—
Тип ПО
приложение
Тип оборудования
сервер
Операционная система
Информация об операционной системе
Операционная система
Линукс
Название операционной системы
Линукс
Код имени операционной системы
линукс
Вариант операционной системы
—
Версия операционной системы
—
Версия операционной системы (полная)
—
Платформы операционных систем
—
Разное
Разная информация
Операционная платформа
PHP 5.
0.0Код операционной платформы
5.0.0
Кодовое название операционной платформы
—
Название поставщика операционной платформы
—
 0.0
0.0Ищете пользовательские агенты, похожие на этот?
Просмотреть все пользовательские агенты cURL
Просмотреть все пользовательские агенты Linux
Просмотреть все пользовательские агенты PHP 5. 0.0
0.0
Просмотреть все пользовательские агенты приложения
Просмотреть все пользовательские агенты сервера
Разобрать другой пользовательский агент?
Вы хотите легко загрузить все 219,4 миллиона пользовательских агентов? Это быстро и легко сделать. Узнайте больше о нашей базе данных User Agent.
Легко найти миллионы пользовательских агентов, которые у нас есть с помощью API. Воспользуйтесь нашим интерфейсом поиска.
Не выполнять очистку этих списков
Существует защита, предотвращающая очистку этих списков пользовательского агента. Нам пришлось это сделать, потому что в противном случае мы будем постоянно перегружены невнимательными или неисправными ботами, которые перегружают систему. Таким образом, мы вынуждены блокировать трафик от популярных веб-хостинговых компаний, VPN и прокси-серверов, мы также ограничиваем запросы на скорость и проводим некоторые другие проверки. Удаление этих списков приведет к блокировке вашего IP.
Удаление этих списков приведет к блокировке вашего IP.
Если вам нужно получить доступ к спискам пользовательских агентов, вы можете получить их либо через простую в использовании загрузку базы данных, либо через API. Спасибо за понимание.
Использование cURL для парсинга веб-страниц
В этом сообщении блога вы узнаете:
- Что такое cURL?
- Как использовать cURL?
- Почему cURL так популярен?
- Использование cURL с прокси
- Как изменить User-Agent
- Веб-скрапинг с помощью cURL
Что такое CURL?
cURL — это инструмент командной строки, который можно использовать для передачи данных по сетевым протоколам. Имя cURL означает «URL-адрес клиента» и также пишется как «curl». Эта популярная команда использует синтаксис URL для передачи данных на серверы и с них. Curl использует libcurl, бесплатную и простую в использовании библиотеку для передачи URL-адресов на стороне клиента.
Почему использование curl выгодно?
Универсальность этой команды означает, что вы можете использовать curl для различных вариантов использования, в том числе:
- Аутентификация пользователя
- сообщений HTTP
- SSL-соединения
- Поддержка прокси
- загрузок по FTP
Простейшим вариантом использования curl будет загрузка и загрузка целых веб-сайтов с использованием одного из поддерживаемых протоколов.
Протоколы Curl
Хотя curl имеет длинный список поддерживаемых протоколов, по умолчанию он будет использовать HTTP, если вы не укажете конкретный протокол. Вот список поддерживаемых протоколов:
Установка curl
Команда curl устанавливается по умолчанию в дистрибутивах Linux.
Как проверить, установлен ли уже curl?
1. Откройте консоль Linux
2. Введите curl и нажмите Enter.
3. Если у вас уже установлен curl, вы увидите следующее сообщение:
4. Если у вас еще не установлен curl, вы увидите следующее сообщение: «команда не найдена». Затем вы можете обратиться к своему дистрибутиву и установить его (подробнее ниже).
Как использовать cURL
Синтаксис Curl довольно прост:
Например, если вы хотите загрузить веб-страницу: webpage.com, просто введите:
Команда выдаст вам исходный код страницы в окно вашего терминала. Имейте в виду, что если вы не укажете протокол, по умолчанию curl будет использовать HTTP. Ниже вы можете найти пример того, как определить определенные протоколы:
Если вы забудете добавить ://, curl угадает протокол, который вы хотите использовать.
Мы кратко рассказали об основном использовании команды, но вы можете найти список опций на сайте документации curl. Параметры — это возможные действия, которые вы можете выполнять с URL-адресом. Когда вы выбираете вариант, он сообщает curl, какое действие следует предпринять для указанного вами URL-адреса. URL-адрес сообщает cURL , где ему необходимо выполнить это действие. Затем cURL позволяет перечислить один или несколько URL-адресов.
URL-адрес сообщает cURL , где ему необходимо выполнить это действие. Затем cURL позволяет перечислить один или несколько URL-адресов.
Чтобы загрузить несколько URL-адресов, добавьте к каждому URL-адресу префикс -0, за которым следует пробел. Вы можете сделать это в одной строке или написать отдельную строку для каждого URL-адреса. Вы также можете загрузить часть URL-адреса, перечислив страницы. Например:
Сохранение загрузки
Вы можете сохранить содержимое URL-адреса в файл с помощью curl двумя разными способами:
1. Метод -o: позволяет добавить имя файла, в котором будет сохранен URL-адрес. . Эта опция имеет следующую структуру:
2. Метод -O: Здесь вам не нужно добавлять имя файла, так как эта опция позволяет сохранить файл под именем URL. Чтобы использовать эту опцию, вам просто нужно добавить к URL-адресу префикс -O.
Возобновление загрузки
Может случиться так, что ваша загрузка остановится посередине. В этом случае перепишите команду, добавив в начале параметр -C:
В этом случае перепишите команду, добавив в начале параметр -C:
Почему curl так популярен?
Curl — настоящий «швейцарский нож» команд, созданный для сложных операций. Однако есть альтернативы, например, «wget» или «Kurly», которые хороши для более простых задач.
Curl является фаворитом среди разработчиков, потому что он доступен почти для каждой платформы. Иногда он даже установлен по умолчанию. Это означает, что какие бы программы/задания вы ни запускали, команды curl должны работать.
Кроме того, есть вероятность, что если вашей ОС меньше десяти лет, у вас будет установлен curl. Вы также можете прочитать документы в браузере и проверить документацию по curl. Если вы используете последнюю версию Windows, у вас, вероятно, уже установлен curl. Если нет, прочтите этот пост на Stack Overflow, чтобы узнать больше о том, как это сделать.
Использование cURL с прокси
Некоторые люди могут предпочесть использовать cURL в сочетании с прокси. Преимущества здесь включают в себя:
Преимущества здесь включают в себя:
- Повышение способности успешно управлять запросами данных из разных геолокаций.
- Экспоненциальное увеличение количества одновременных заданий с данными, которые можно выполнять одновременно.
Для этого вы можете использовать возможности «-x» и «(- – proxy)», уже встроенные в cURL. Вот пример командной строки, которую вы можете использовать для интеграции используемого прокси-сервера с cURL:
$ curl -x 026.930.77.2:6666 http://linux.com/
В приведенном выше фрагменте кода «6666» — это номер порта, а «026.930.77.2» — это IP-адрес.
Полезно знать: cUrl совместим с большинством распространенных типов прокси, используемых в настоящее время, включая HTTP, HTTPS и SOCKS.
Как изменить User-Agent
User-Agent — это характеристики, которые позволяют целевым сайтам идентифицировать устройство, запрашивающее информацию. Целевой сайт может потребовать, чтобы запрашивающие лица соответствовали определенным критериям, прежде чем возвращать желаемые целевые данные. Это может относиться к типу устройства, операционной системе или используемому браузеру. В этом сценарии организации, собирающие данные, захотят подражать идеальному «кандидату» своего целевого сайта.
Это может относиться к типу устройства, операционной системе или используемому браузеру. В этом сценарии организации, собирающие данные, захотят подражать идеальному «кандидату» своего целевого сайта.
В качестве аргумента предположим, что сайт, на который вы ориентируетесь, «предпочитает» просить стороны использовать Chrome в качестве браузера. Чтобы получить желаемый набор данных с помощью cURL, необходимо эмулировать эту «черту браузера» следующим образом:
curl -A «Goggle/9.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Chrome/103.0. 5060.71” https://getfedora.org/
Веб-скрейпинг с помощью cURL
Совет для профессионалов: Обязательно соблюдайте правила веб-сайта и в целом не пытайтесь получить доступ к защищенному паролем содержимому, которое является незаконным для большая часть или, по крайней мере, неодобрительно.
Вы можете использовать curl для автоматизации повторяющегося процесса при просмотре веб-страниц, что поможет вам избежать утомительных задач. Для этого вам нужно будет использовать PHP. Вот пример, который мы нашли на GitHub:
Для этого вам нужно будет использовать PHP. Вот пример, который мы нашли на GitHub:
Когда вы используете curl для очистки веб-страницы, есть три варианта, которые вы должны использовать:
- curl_init($url) -> Инициализирует сеанс
- curl_exec() -> Выполняет
- curl_close() -> Закрывает
Другие варианты, которые вы должны использовать, включают:
- Curlopt_url -> Устанавливает URL-адрес, который вы хотите очистить
- Curlopt_returntransfer -> Приказывает curl сохранить очищенную страницу как переменную. (Это позволит вам получить именно то, что вы хотели извлечь со страницы.)
Практический результат
Несмотря на то, что cURL является мощным инструментом веб-скрейпинга, он требует от компаний использования драгоценного времени разработчиков как для сбора данных, так и для очистки данных. Компания Bright Data выпустила полностью автоматизированный парсер веб-страниц, который не требует написания кода.