ABBYY. Файн ридер для чего нужен
Неочевидные возможности ABBYY FineReader / Блог компании ABBYY / Хабр
Каждая следующая версия ABBYY FineReader становится всё более интуитивно понятной. В частности, в последние версии включена система встроенных сценариев, которые дают возможность выполнить стандартные последовательности действий за несколько щелчков мышью. Так мы стараемся облегчить работу с программой для большинства наших пользователей. И, тем не менее, FineReader обладает рядом возможностей, которые не лежат на поверхности, но могут быть полезны пользователям «продвинутым». О нескольких таких возможностях мы расскажем в этом посте.
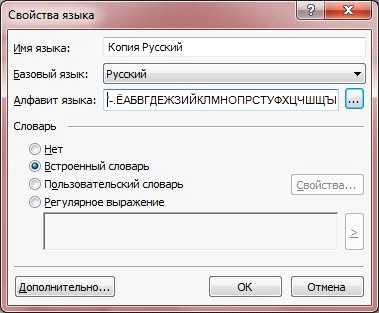
Начнем с функции создания языков в ABBYY FineReader 10 Professional Edition. Для чего и кому это нужно? В основном, для тех, кто занимается распознаванием текста, содержащего много специфических конструкций, например, артикулов, небуквенных символов, аббревиатур или цифр. На первый взгляд кажется, что такие случаи бывают редко, но мы довольно часто сталкиваемся с подобными вопросами от наших пользователей. Например, интересный случай был описан на форуме FineReader, где пользователю нужно было распознать книгу по покеру, в которой, разумеется, встречались символы-масти. Чтобы решить проблему с корректным отображением мастей, мы посоветовали создать в программе новый язык. Эта процедура облегчает работу с подобными документами и значительно сокращает время их обработки. Сам процесс создания не займет много времени и не требует специфических знаний, здесь просто нужно быть внимательным. Чтобы вам легче было разобраться, мы покажем, как это делается.
Основной диалог, в котором настраиваются параметры нового языка, вызывается из меню Сервис -> Редактор языков нажатием кнопки Новый…. Язык создается на основе одного из существующих, поэтому перед тем как редактировать свойства нового языка, выберите тот, который будет принят за основу. Если текст, который вы будете распознавать, на русском языке, его и стоит выбрать в качестве базового. Открываем окно Свойства языка.
 "
"
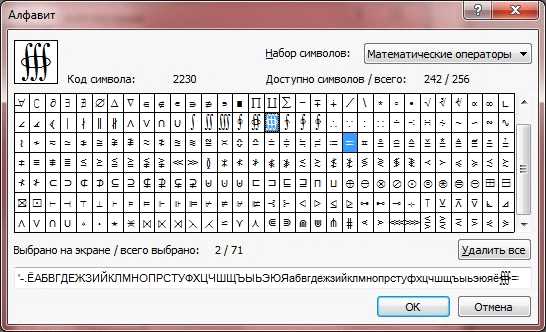
Нетрудно догадаться, что начинать данный процесс придется с создания алфавита. Нажимаем кнопку редактирования и попадаем в диалог с широкими возможностями для создания собственного алфавита: здесь можно добавить любые символы из более чем шестидесяти наборов – от привычной кириллицы до специальных математических и декоративных. Находим нужные символы, добавляем их в алфавит и закрываем окно редактирования.
Кроме возможности добавления символов в алфавит, существует обратная процедура – исключение ненужных символов. Например, если вы распознаете книгу 60-70 годов выпуска, то имеет смысл убрать из языка распознавания такие символы, как & # @. Так мы поможем программе исключить ненужные варианты при распознавании нечётко пропечатанных букв.
После того как работа с алфавитом завершена, нужно выбрать словарь, который будет использоваться системой при распознавании и проверке, и указать дополнительные свойства (например, символы, которые могут встречаться в начале и конце слова и т.д.). Теперь FineReader готов к распознаванию вашего текста.
Когда вы создавали новый язык, наверняка заметили вторую опцию, доступную в диалоге Редактор языков – «Создать новую группу языков». Пригодится она тем, кому приходится распознавать документы, тексты которых составлены одновременно на нескольких нетрадиционных языках одновременно. Например, вам внезапно понадобилось распознать научную диссертацию, составленную на языках аймара, конго и зулу…
Сразу напомню, что в программе есть и предопределённые группы языков. Они используются для распознания документов, составленных на двух-трех распространенных языках, например, на русском и английском, или на английском, немецком и французском и т.д. Для таких документов создавать новую группу каждый раз совсем не обязательно. А если вам вдруг понадобится сочетание китайского упрощенного и простых химических формул, или английского и того, который вы ранее создали сами, то вам сюда. Смело устанавливайте флажок на опцию «Создать новую группу языков» и из предложенного списка выбирайте и добавляйте нужные вам языки. Не забудьте придумать оригинальное название для вновь созданной группы – тогда вы сможете использовать ее в следующий раз.
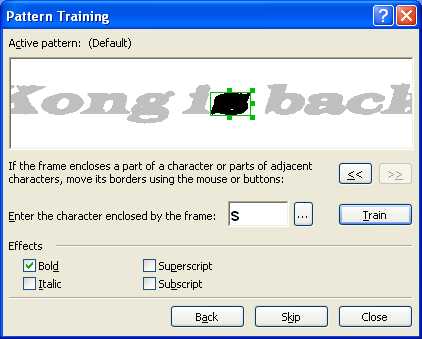
Следующая возможность – «Распознавание с обучением» – пригодится, когда нужно распознать текст, напечатанный декоративным шрифтом. В таких случаях составить алфавит из имеющихся символов просто физически невозможно, но зато вы сможете создать свой эталон букв, которые будут использованы в тексте, и с их помощью распознать декоративный шрифт. Еще эту возможность удобно использовать при распознавании текста с большим количеством сложных математических формул и для больших объемов текста плохого качества.
Если вы все же решились на создание эталона, отправляйтесь в меню Сервис -> Опции на вкладку Распознать. Здесь в группе Обучение нужно установить флажок в положение Распознать с обучением и нажать кнопку Эталоны, которая вызывает диалог создания нового эталона. Введите название для нового эталона, закройте все открытые диалоги и начинайте процесс распознавания. Как только встретится незнакомый символ, откроется диалог Ручное обучение эталона с изображением этого символа.
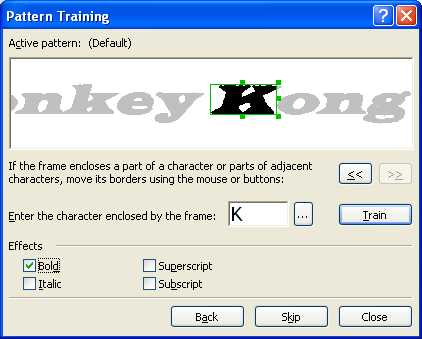
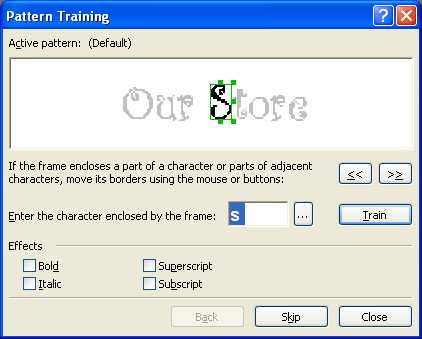
В результате распознавания вы получите именно те значения незнакомых символов, которым научили FineReader сами. Вот таким нехитрым способом происходит обучение FineReader. Кстати, созданные эталоны можно сохранять – тогда вы сможете их использовать их несколько раз, а также редактировать при необходимости.
Сегодня мы рассказали вам о двух возможностях FineReader, о которых вы, возможно, еще не знали и которые, быть может, окажутся вам полезными. Эти и другие интересные функции FineReader описаны в справке, поэтому рекомендуем вам иногда туда заглядывать.
Алиса Рахманова, Департамент продуктов для распознавания текстов
habr.com
Распознавание FineReader
Автор:
Тип лицензии:
Крякнутая
Языки:
Мульти
ОС:
Windows 8, 8 64-bit, 7, 7 64-bit, Vista, Vista 64-bit, XP, XP 64-bit
Просмотров:
5016
Скачано:
2006
Предлагаю на рассмотрение восьмую версию ресурса, ведь я сама его использую.
Распознание
Воспользуйтесь функцией «Сканировать», то есть открыть в определенном источнике, для начала сканирования. Появляется окошко ресурса сканирования. В основном приемлемым разрешением является 300pi, процесс сканирования более оптимально установить, если следить за различными элементами в документе: это может быть «голый» текст, текст и графики, а также текст с картинками.
Если вам необходимо отсканировать одновременно несколько страниц, выберите стрелку справа от клавиши «Скан», а затем команду опции, в появившимся окне опции требуется нажать «Скан несколько страниц». В случае большого количества страниц, как в PDF- и TIFF-документах, необходимо активировать только часть страниц, необходимых вам. Чтобы это сделать, нужно написать номер страниц через запятую, к примеру: 3,5,7-11.
Затем сканированное фото нужно распознать. Это можно сделать с текущим фото, и с набором фото, которые введены в границах этой сессии в ресурс со сканера.
Также нужно учитывать, что языки, предназначенные для распознания и написания документа должны совпадать. Есть также функция указания нескольких языков для распознания (для многоязычных док). Но лучше не использовать больше трех языков.
Клиенты, у которых есть желание использовать лишь сегменты документа, которые им необходимы, могут использовать функцию «Анализа макета страницы».
Проверить можно собственноручно используя встроенный WYSIWYG-редактор, он обеспечить наиболее точный процесс распознания всех элементов файла: разметки текста, таблички, фото, они появляются в окне редактирования тем же действием, если они были размещены в исходном изображении.
Вы можете использовать функцию для диалога «Проверка», где вы увидите слово с допущенной ошибкой, его скрин в исходном файле и способы замены. В этих действиях следует просчитать, что распознаются и показываются в диалоге «Проверка» исключительно слова, где присутствуют некорректно замеченные символы, или те, которым придана оценка в самой лучшей из гипотез в плане уверенности программы, менее определенной ошибки указанного уровня. И совсем не обязательно, что ошибки, указанные неуверенно действительно ошибки.
В случае необходимости в сохранении результата распознаваний в документ, требуется кликнуть по функции справа от клавиши «Сохранить», а затем использовать функцию «Сохранить страницы». Проверенный текст следует сохранять в таких форматах, как: RTF, DOC, Word XML, XLS, PDF, HTML,PPT, TXT, DBF, CSV, LIT. Есть также функция переформирования проверенного файла в исходное приложение для того, чтобы можно было завершить работу с файлом, но уже в привычном для вас виде.
Каждый формат имеет функцию настройки сохранения. Вы можете их отыскать в определенной вкладке диалога «форматы», для настаивания в формате PDF есть в вкладке PDF, к примеру, и так с каждым форматом. Чтобы активировать диалог «Форматы», требуется кликнуть клавишу справа от функции «Сохранить», а затем, использовать функцию опции. В появившимся диалоге кликните по клавише «Форматы».
Все, что было указано выше, скорее всего не является новой информацией, но все равно мне следует остановиться на двух моментах.
1. В ABBYY FineReader вы можете, обладая фото в формате pdf, переформатировать в документ word, чтобы в последующем плане иметь возможность редактировать его. Представим ситуацию: вы нашли в интернете файл в pdf, но вам необходим текст из изображения, чтобы вытащить его, требуется воспользоваться FineReader, затем выбрать документ, сохранить его в word, после чего вы уже можете отредактировать файл как вам угодно.
2. Мало кто знает, что в FineReader (правда не в версии демо) существует функция Screenshot Reader. Эта функция для того, чтобы вычитывать тексты с изображений прямо с экрана монитора. Используется она очень просто: нужно нажать (на клавиатуре) клавишу PrintScreen, затем FineReader берет это фото из буфера обмена и начинает вычитывать текст. Вы можете это совершить и собственноручно, ноScreenshot Reader дает возможность это сделать быстрее. О необходимости данного ресурса можно долго рассуждать, в любом случае, она приносит пользу. В первую очередь, она вычитывает текст быстрее, чем это можете сделать вы))), также, это великолепный вариант взять текст из защищенных текстовых документов.
Запуск происходит очень закономерно: Запускаете программу ABBYY FineReader, и функцию ABBYYScreenshot Reader.
Обличие программы неимоверно просто.
После кликанья клавши «Снимок», вы увидите сетку захвата, и сможете выбрать место на экране для последующего копирования на свой ПК но уже в виде файла.
Экспериментируйте с программой, я уверена, это принесет Вам массу удовольствия.
finereader2015.ru
На пути к профессиональному использованию современных OCR. Understanding FineReader / Блог компании ABBYY / Хабр
 Я занимаюсь разработкой технологий, используемых в продуктах распознавания текста компании ABBYY. Самым известным продуктом (а точнее – семейством продуктов), использующим эти технологии, является FineReader.Что я понимаю под «технологиями»
Я занимаюсь разработкой технологий, используемых в продуктах распознавания текста компании ABBYY. Самым известным продуктом (а точнее – семейством продуктов), использующим эти технологии, является FineReader.Что я понимаю под «технологиями»Чем занимается программа FineReader?
Сейчас любой из настольных вариантов FineReader может проделать все самостоятельно от получения изображения со сканера, камеры или из готового файла до выдачи результата обработки в файл или в указанное приложение, так, что человек остается «за кадром». Программа сама «распознаёт» всё что нужно (в кавычках, так как при этом программа определяет места расположения текста, таблиц, картинок, OCRит обнаруженные участки с изображённым текстом, формирует документ, который сохраняет в желаемом формате с указанными настройками)Пара скриншотов
А чем занимается пользователь?
 Обычно почти ничем — сперва заказывает работу, а потом её принимает. Иногда пользователя что-то не устраивает в результате автоматической обработки, но в таких случаях типичный пользователь смиренно думает «Не повезло...»
Обычно почти ничем — сперва заказывает работу, а потом её принимает. Иногда пользователя что-то не устраивает в результате автоматической обработки, но в таких случаях типичный пользователь смиренно думает «Не повезло...» К сожалению, далеко не все знают, что помимо окна «Задача», которое показывается и при запуске, есть другие способы управлять работой программы. Они помогают с помощью человеческого интеллекта преодолеть недостатки и ограничения (иногда принципиальные) искусственного интеллекта программы.
Как научиться это делать? Есть несколько способов, при необходимости сочетаемых:
- почитать «Краткое руководство», «Полное руководство пользователя», online-Справку к программе – там конечно же много букв, но почти все они написаны по делу.
- прочитать до конца эту статью. В ней гораздо меньше букв, к тому же, автор обещает избавить читателя от страха перед программой и пробудить у него интерес к экспериментам,
- экспериментировать с программой (единственный пункт, без которого не обойтись) – даже демо-версия позволяет попробовать всё, что нужно при реальной эксплуатации.
С чего начать?
Начать нужно с привычки сохранять результат работы не только в виде документа в целевом формате, но и как документ FineReader, содержащий результаты проделанной работы. Это позволяет работать с большим документом не несколько часов подряд в один подход, а когда удобно и сколько угодно раз, возвращаться к распознанному и вычитанному документу для экспериментов с настройками сохранения и так далее. Все действия с документом FineReader собраны в Меню «Файл».Картинки
Нет ничего практичнее хорошей теории, или из чего состоит «распознавание»
 Глядя на лаконичные названия задач, например, «Сканировать в PDF», трудно вообразить, сколько всего происходит в промежутке между «Сканировать» и «PDF» (то есть на месте одной буквы «в»). Давайте посмотрим, сколько. Задача «преобразования документов из растрового представления в редактируемое» (не просто «распознавания») включает следующие основные этапы:
Глядя на лаконичные названия задач, например, «Сканировать в PDF», трудно вообразить, сколько всего происходит в промежутке между «Сканировать» и «PDF» (то есть на месте одной буквы «в»). Давайте посмотрим, сколько. Задача «преобразования документов из растрового представления в редактируемое» (не просто «распознавания») включает следующие основные этапы:- Получение исходного одно- или многостраничного изображения (со сканера, фотоаппарата или в виде файла), преобразование его в специальное внутреннее представление (для упрощения и ускорения дальнейших операций). В любом случае используется подсистема обработки изображений, понимающая множество внешних форматов как на чтение, так и на запись.
- Подготовка изображения (исправление искажений разных типов, разделение книжных разворотов на отдельные страницы – всё это включаемо/отключаемо в настройках) – выполняет также подсистема обработки изображений. Узнать про некоторые элементы этого процесса чуть больше можно в этом посте.
- Сегментация, или «анализ макета страниц», когда решается, где и что нужно и не нужно распознавать, выполняется подсистемой Анализ.
- Распознавание (наконец-то) – выполняет подсистема Распознаватель (сюрприз!), она порождает строки, состоящие из фрагментов (будущих слов), состоящие из символов без форматирования (пока нет даже деления на параграфы, есть только строки). Некоторое количество информации о деталях работы распознавателя уже было написано на Хабре моим коллегой. А если вам действительно интересны технические подробности, то не лишним будет и упоминание, что распознаватель в своей работе использует кроме прочего и подсистему морфологии. В этом посте можно поучиться правильно использовать упомянутую подсистему морфологии и механизм Распознавание с обучением, позволяющий лучше распознавать декоративные шрифты или символы, о которых FineReader ничего не знает (бывает и такое).
- Синтез документа (он имеет два этапа – страничный, вызываемый сразу по завершении распознавания отдельной страницы и документный, работающий по окончании обработки всех страниц) — именно здесь определяется структура и все характеристики распознанного текста, кроме кодов символов, порождая целостный документ – выполняет подсистема Синтез. В этом посте можно попытаться осознать тяжёлую судьбу тех, кто пишет те сотни сотен эвристик, которые позволяют делать распознанный документ максимально похожим на оригинал.
- Просмотр и редактирование изображений страниц, структуры областей, результатов распознавания – выполняет Оболочка программы и подсистема Редактор в её составе (исполняемый файл FineReader.exe – это есть оболочка). В оболочке можно увидеть и отредактировать значительную часть порождаемой при обработке информации (начиная со структуры блоков). Конечно же, для пользовательского редактирования доступна не вся информация, которой оперируют разные подсистемы – в первую очередь потому, что показ всех находимых автоматикой сущностей, их свойств и взаимосвязей вызвал бы безумное усложнение пользовательского интерфейса.
- Сохранение готового документа в многочисленные внешние форматы – выполняется подсистемой Экспорт (разработкой которой занимаюсь как раз я с коллегами). Подсистемы, работающие до экспорта, не знают выходного формата/варианта сохранения. Поэтому при синтезе документа создаются сразу несколько его представлений, которые могут потребоваться всем форматам/вариантам экспорта, а оболочка умеет их показывать аналогично тому, как результаты экспорта будут отображены в целевых приложениях. Это порождает немало трудностей при разработке, потому что слишком тесная взаимосвязь обозначенных подсистем приводит к усложнению разделения ответственности на «пограничных территориях», когда бага/фича лежит где-то между подсистемами. Но мы пока справляемся :)
Зачем так много модулей (подсистем)?
Для начала необходимо заметить, что перечислены только основные, а не все. Подсистема сканирования, например, не день и не два писалась, а многие месяцы и даже, возможно, годы. Впрочем, вернёмся к вопросу, обозначенному выше.Во-первых, проект «Технологии распознавания» и много сложных продуктов на его основе разрабатываются уже не первое десятилетие большими коллективами людей — их работу просто необходимо делить организационно и технологически на части, чтобы разрабатывать каждую более-менее независимо — конечно же, детально описав интерфейсы и правила взаимодействия модулей, чтобы выход предыдущего модуля в цепочке стыковался со входом следующего.
Во-вторых, некоторые продукты могут использовать не все из перечисленных стадий обработки (и реализующих их подсистем), а только некоторые. Например, модуль «Распознаватель» имеет собственные подмодули для обработки печатного и рукописного текста, а его «печатный» под-модуль – ещё и свои под-под-модули для обработки языков со сложной письменностью. Похожая ситуация с модулем разпознавания штрихкодов и кодеками некоторых форматов изображений – некоторые продукты обходятся без них.
Какой результат и зачем нужен пользователю?
 Не озадачившись вовремя этим вопросом, можно остаться недовольным даже полностью правильным результатом OCR в узком смысле – когда вроде все буквы найдены и правильно распознаны, но в целом что-то в результате печалит. Перечислю некоторые из популярных сценариев использования FineReader с особенностями каждого сценария.
Не озадачившись вовремя этим вопросом, можно остаться недовольным даже полностью правильным результатом OCR в узком смысле – когда вроде все буквы найдены и правильно распознаны, но в целом что-то в результате печалит. Перечислю некоторые из популярных сценариев использования FineReader с особенностями каждого сценария.Преобразование архива документов-изображений в электронный вид, с максимальным сохранением внешнего вида страниц, но добавлением возможности поиска и копирования небольших фрагментов текста.
Этот сценарий обычно использует сохранение обработанного документа в PDF с видимым изображением страницы (не всегда в полностью оригинальном виде, но по возможности максимально похожим на него) и добавлением «невидимого» распознанного текста, который в PDF-просмотрщиках можно искать, выделять и копировать. На нашем жаргоне этот режим сохранения в PDF называется «Текст под изображением», он наиболее популярен, но это лишь один из 4 режимов сохранения в PDF (на остальных остановлюсь подробнее в статье про сохранение). Ценители формата DjVu также могут использовать аналогичный режим сохранения.Важное достоинство режима «Текст под изображением» в том, что он требует минимальных знаний о структуре сохраняемого текста, привязывая символы к нужным местам результирующей страницы просто по координатам на исходном изображении. Поэтому неважно, если таблицы не были правильно автоматически детектированы в оригинале (развалившись на кучу текстовых областей), или текст немного нелогично выделился в текстовые области – в результирующем PDF найдётся всё или почти всё, лишь бы символы правильно распознались и собрались в слова.
Создание документа в формате любого из популярных текстовых редакторов (Microsoft Word или OpenOffice/LibreOffice Writer), более-менее похожего на оригинал — для последующего редактирования и/или переиспользования значительных фрагментов в новых документах.
При сохранении в форматы RTF и DOCX (для Word) и ODT (для Writer) поддержаны 4 режима сохранения, отличающихся балансом «точное сохранение вида простота редактирования и копирования содержимого». Я ещё напишу подробнее об их различиях, но общим требованием для разумного вида результата обработки является разумность разметки всех элементов документа в FR — областей и их свойств.Создание электронной книги на базе сканированной бумажной книги.
Во многом похож на предыдущий, но в силу упрощённой модели документа в форматах электронных книг, ограничений средств их редактирования и показа после FineReader, иногда требует больше внимания к некоторым мелочам.И зачем я это теперь знаю?
Как вы, наверняка, уже догадались, понимание этих логичных, но всё-таки не очевидных моментов позволило бы пользователям доводить результат деятельности FineReader до идеального (с точки зрения пользователя) состояния с минимальными трудозатратами. В следующей части поста я дам конкретные рекомендации по решению типичных пользовательских проблем, а пока давайте вернёмся к работе.habr.com
Обучаем эталон и редактируем эталон
Для начала процесса обучения эталона требуется проверить, дабы на закладке Распознавание переключатель находился в положении Распознавание с обучением. После этого нажимаем на кнопочку Распознать. Файн ридер начнет выполнять распознавание и, как только, найдется символ, которому программу надо обучить выполнится открытие диалогового окна обучение эталона с пиктограммой символа. программа finereader скачать бесплатноФайн ридер: обучение символуВ описывающем прямоугольнике, который находится в верхней части диалогового окна должен быть один символ. Ежели там находится более одного символа, либо только часть символа, то посредством мышки, либо же соответствующих кнопок прямоугольник требуется передвинуть таким образом, дабы он окружал одну букву. Далее вводим требуемый символ и кликаем Обучить. Только учтите, что обучение может производиться только символом, которые имеются в алфавите языка. Ежели обучение подразумевает под собой символы, которые нельзя вводить с клавиатуры, то для их обозначения нужно применять комбинацию нескольких символов.Файн ридер: советы во время обучения эталонаЕжели в тексте для обучения находятся слова, которые набраны полужирным или курсивом, и Вам нужно не потерять гарнитуру, то во время обучения таким символам требуется выбрать пункты Полужирный или Курсив. Во время обучения старайтесь следить за тем, чтобы изображения строчных букв отвечали строчным буквам, а заглавных - заглавным. При ошибке можно вернуться. Для этого требуется кликнуть на Вернуться, и прямоугольник возвратится к предыдущей позиции. При этом последняя пара будет удалена из эталона. Данная кнопка действует лишь в границах одного слова.Файн ридер: обучение эталона лигатурамЛигатурами являются сочетания символов (обычно 2-3), которые сложно во время обучения разделить. Эти комбинации обучаются как комбинации буквально. В остальном процесс обучения ничем не отличается от обучение символам.Файн ридер: ограничения во время обучения эталонаОдин эталон может содержать до одной тысячи новых комбинаций. Впрочем, не нужно создавать достаточно большое количество лигатур, поскольку это может негативно сказаться на уровне качества распознавания. Изображения определенных символов система не распознает, поэтому они сопоставляются с одним символом. К примеру, три разных вида апострофов воспринимаются файн ридер, как прямой апостроф. Для определенных изображений решение относительно того, какому символу в тексте назначить определенный символ принимается на основании анализа текста, который находится рядом. Если Вы желаете проводить распознавание с обучением, то нужно на закладке Распознавание, которое находится в диалоговом окне Опции, установить переключатель в позицию Распознавание с обучением. В строке состояние возникнет наименование эталона. Далее нажимаем кнопочку Распознать. скачать abbyy finereader 6.0 бесплатно Файн ридер: процесс обучение эталонаДля обучения эталона требуется распознавать около двух страниц в режиме распознавания с обучением. Данные символы добавляются в эталон, который создается системой. После окончания обучения эталон сохранится в каталоге хранения пакета. После этого, при необходимости, выполните редактирование эталона. Далее отменяем режим Распознавания с обучением и запускаем распознавание основного текста.Файн ридер: работа с несколькими эталонамиДля создания разного количества эталонов в одном пакете можно воспользоваться диалоговым окном Редактор эталонов. Здесь создаем новый эталон и выбираем его для работы. После этого нужно выполнить действия, которые описаны в процессе обучения эталона. В случае, когда во время обучения были созданы несколько эталонов, то выполняется подключение последнего эталона. Название эталона, который подключен прописывается в строке состояния. Если нужно выбрать другой эталон, то в списке эталонов требуется выбрать нужный и нажать Выбрать. В случае, когда на закладке Распознавание выбрана опция Использовать встроенные эталоны, то файн ридер в режиме Распознавание с обучением предложить опознать лишь символы, которые распознаны неуверенно. Ежели Вы программу обучаете нестандартным или декоративным шрифтам, то лучше убрать галочку с Использовать встроенные эталоны. Перед запуском распознавания с созданным эталоном настоятельно советуется выполнить просмотр эталон. В случае необходимости его нужно отредактировать. Этим можно свести ошибки распознавания на минимальный уровень. В эталоне должны находиться лишь целые лигатуры или символы. Символы, которые обрезаны с краев, а также символы, которые имеют неправильные подписи нужно удалить. finereader 6.0 скачать бесплатно с ключом Файн ридер: что нужно для редактирования эталонаДля начала выбираем пункт Редактор эталонов в меню Сервис. В открывшемся диалоге выбираем требуемый эталон и кликаем на Редактировать... После этого открывается диалог Символы пользовательского эталона. После выбора символа нажимаем кнопочку Свойства для редактирования подписи и указания правильного начертания: полужирный, курсив, нижний или верхний индексы, либо же нажимаем на кнопочку Удалить, дабы произвести удаление неправильно обученным символам.Файн ридер: пользовательские группы языков и языкиУ Вас имеется возможность применять не лишь предопределенные группы языков и языки, но и выполнить создание нового языка, либо же выполнить объединение существующих языков в новую группу и во время распознавания выполнить непосредственно их подключение.Файн ридер: Когда требуется создавать новый язык?Для того чтобы подключить пользовательский словарь. К примеру, для распознавания текста, который содержит аббревиатуры. Для того чтобы распознать документы специального вида. К примеру, на страничке находится список артикулов, которые состоят из нескольких букв и цифр. Для этого можно создать новый язык, который будет включать только необходимый перечень символов, и применять его для распознавания непосредственно такого типа документов. В документе присутствуют только строчные буква из английского языка. При этом рекомендуется использовать для распознавания только строчные буквы.Файн ридер: Когда требуется создавать новую группу языков?Главным образом при частом использовании какой-либо комбинации языков. |
legkyyzarabotok.ucoz.ru
- Что делать если взломали сайт

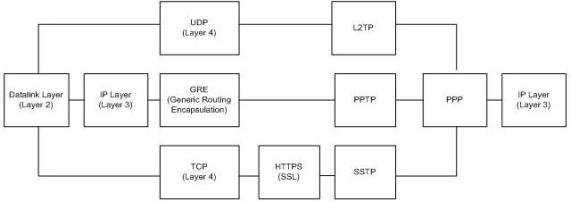
- Настройка windows server vpn
- Как отключить рекламу в браузерах
- Какой браузер у меня
- Видео не воспроизводится avi
- Ошибка при работе с ярлыком
- Как на ноутбуке отключить вай фай виндовс 7
- Acer сенсорная панель на ноутбуке не работает
- Возникла проблема с этим диском проверьте диск и исправьте ее
- Командные файлы windows
- Где находится корзина в компьютере