Организация работы в Fine Reader. Как работать с программой файн ридер
Работа с документом FineReader – видео урок TeachVideo
Работа с документом FineReader
При работе с документом ABBYY® FineReader® доступны следующие операции:
Создать документ.
- В меню Файл выберите пункт Новый документ FineReader®, или
- На главной панели инструментов нажмите кнопку Новый документ FineReader® .
- Удалить страницу из документа.
- В меню Страница выберите пункт Удалить страницу из документа, или
- В контекстном меню выделенной страницы в окне Страницы выберите Удалить страницу из документа.
Чтобы удалить несколько страниц, выделите несколько страниц в окне Страницы.
Открыть документ.
При запуске ABBYY® FineReader® по умолчанию открывает новый документ FineReader®.
Если вы хотите, чтобы при запуске программа открывала последний документ, с которым вы работали, отметьте опцию Открывать последний документ при запуске ABBYY® FineReader® на закладке Дополнительные диалога Опции (меню Сервис>Опции…).
Как открыть документ: 1. В меню Файл выберите пункт Открыть документ FineReader®… 2. В открывшемся диалоге Открыть документ FineReader® выберите нужный документ.
Документ ABBYY® FineReader® также можно открыть непосредственно из Проводника Windows (такие документы обозначаются значком ), выбрав в контекстном меню документа пункт Открыть в ABBYY® FineReader®.
Добавить изображение в документ.
- В меню Файл выберите пункт Открыть PDF/изображение…
- В диалоге Открыть изображение выберите одно или несколько изображений и нажмите кнопку Открыть. Изображение будет добавлено в открытый документ, и его копия будет сохранена в папке документа.
Вы можете добавить изображение из Проводника Windows:
- Выделите в Проводнике Windows один или несколько файлов с изображениями, затем в контекстном меню выберите пункт Открыть в ABBYY® FineReader®.
Если на вашем компьютере уже открыт ABBYY® FineReader®, выделенные файлы будут добавлены в текущий документ, в противном случае ABBYY® FineReader® запустится автоматически, и файлы будут добавлены в новый документ.
www.teachvideo.ru
Как работает ABBYY FineReader | Энциклопедия Windows
В соответствии с базовыми положениями IPA, разбираемый программой ABBYY FineReader отдельный фрагмент изображения, согласно главного принципа целостности, будет интерпретирован как некий объект (символ), лишь если на нем присутствуют все структурные элементы с соответствующими взаимосвязями.
При этом система выдвигает ряд гипотез, касающихся того, на что именно похож обнаруженный объект, потом они целенаправленным образом проверяются с использованием отдельного принципа адаптивности, который подразумевает наличие ранее накопленных сведений о вероятных начертаниях в распознаваемом документе символа.
На подготовительном этапе обработки и анализа полученных графических данных фактически перед каждой OCR-системой стоят две фундаментальные задачи: подготовка картинки к определенным процедурам распознавания, а также выявление логической структуры этого документа — с тем, чтобы иметь возможность в дальнейшем воссоздать ее в электронном виде.

Для правильного решения первой задачи в программе ABBYY FineReader задействован отдельный механизм по бинаризации, то есть скорого преобразования как цветного, так и полутонового образа в образ монохромный (1 бит глубина цвета). Бинаризация значительно ускоряет весь процесс анализа ряда графических элементов.
Без дальнейшей обработки процедурой адаптивной бинаризации данный документ может быть скорее всего распознан с ошибками. Вторая задача, поставленная в ABBYY FineReader, решается с использованием целого ряда алгоритмов многоуровневого анализа некоторых документов, осуществляющих конкретный разбор последних постепенно, сверху вниз, благодаря делению страниц на различные объекты низших уровней вплотную до каких-то отдельных символов.
Главную роль в ходе предварительного анализа отдельного изображения и дальнейшей сборки обработанных данных в одно единое целое играет в основном адаптивная технология по распознаванию ADRT документов.
Алгоритмы, которые лежат в ее основе, как бы «смотрят» на контекст самого документа, находят определенные структурные общие элементы, выявляют между ними связи и сохраняют все полученные сведения для дальнейшего использования на завершающих этапах синтеза или же экспорта данных в формат, выбранный пользователем.
Для распознавания отдельных символов в FineReader используются какие-то специальные механизмы, которые называются классификаторами и порождают список гипотез, которые потом целенаправленно проверяются. Для классификаторов входными данными может служить список гипотез в процессе распознавания.
Данная программа очень популярна для оцифровки разнообразных документов. Например, когда банку нужно выселить через суд должника, который не собирается выплачивать кредит, то оцифровка всех необходимых документов позволяет адвокатам успешно завершить данное дело, ведь все данные будут под рукой. Во многих делах число бумажной документации просто ошеломляет.
windata.ru
Как преобразовать отсканированный текст в текстовый файл
Как преобразовать отсканированный текст в текстовый файл | FineReader 11 Pro
Как работать в FineReader 11
— Открываете программу FineReader, щёлкнув два раза по ярлыку на рабочем столе.— Перед вами откроется программа FineReader, нажмите на надпись «PDF изображение в Microsoft Word». Смотри фото.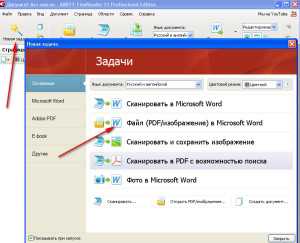
— Выберите на компьютере отснятое цифровое фото или отсканированное изображение с текстом, который вам нужно преобразовать в текст.— Откройте его и текст автоматически отобразится в документе Microsoft Word.— Сохраните его и дайте ему название.Теперь с этим текстом можете делать всё, что вам нужно.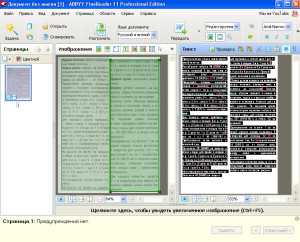
Если вам надо перенести текст в другое место, то в правом окне просто выделите его или нужную фразу (текст выделяется чёрным цветом), нажмите на выделенный текст правой кнопкой мыши, выберите «копировать» и переносите в другое место.Если у вас не появилось окно «Задачи», то нажмите в меню «Задача» (смотри фото выше). С другими функциями Вы без труда разберётесь сами.Желаю Вам удачи. Спасибо за внимание. Автор Юрий Москвин.
Не откажите в любезности, не забудьте про рек-му. С уважением, Юрий Москвин. При использовании материалов сайта ссылка на aidasteh.ru обязательна! Ссылка на данный материал здесь.
Перейди на главную и почитай советы по теме WordPress, кулинарные рецепты, стихи, поздравления в стихах и другие полезные советы.
Читай очень полезные советы:
Как работать в Nature Illusion Studio Ретушь фото. Как работать в Beauty Pilot v.2.3.0«Красные глаза» на фото Pet Eye Fix Guide 2.1Вывод денег с Google Adsense на WebMoneyВывод денег с Google Adsense чекомЗаработок на YouTubeРеклама за показы PEOPLE GROUPЛучшая программа для создания скриншотов FSCapture_RUS.exe Лучшая программа для очистки реестра и дисков от мусора Auslogics BoostSpeed
Статья была полезна? Ретвитим, добавляем в соц. закладки. Спасибо!Главная
aidasteh.ru
Организация работы в Fine Reader
Поиск ЛекцийОсновой работы Fine Reader, является так называемый пакет, содержащий всю информацию о распознаваемом документе. Пакет представляет собой набор страниц документа и может содержать около тысячи страниц. В один пакет для удобства работы рекомендуется объединять изображения, логически связанные между собой, например страницы одной книги. Пользователь импортирует в пакет изображение страниц со сканера или непосредственно из файлов графических форматов.
В окне Пакетвиден список страниц, входящих в открытый пакет. Для просмотра страницы нужно щелкнуть мышью по ее изображению или номеру, при этом откроются файлы, которыми данная страница представлена в пакете. Страницы в окне Пакет могут быть представлены пиктограммами или уменьшенным изображением страницы.
Импортированные изображения подвергаются графической обработке. Если исходное изображение представляет собой негатив, оно может быть инвертировано, далее производится очистка от лишних деталей - мелких дефектов изображения. Если не нужна цветность, то цветные изображения сводятся к черно-белым, что экономит место на диске и ускоряет процесс распознавания.
Следующий шаг - анализ макета страниц пакета, т. е. выделение областей, подлежащих распознаванию. На этом этапе Fine Reader анализирует ориентацию страницы и переворачивает изображение, если это необходимо, а также выделяет блоки - области, которые при дальнейшем анализе будут интерпретироваться как текст, таблицы или рисунки.
После анализа макета страниц, входящих в пакет, проводится собственно распознавание текста и таблиц. Именно технология распознавания является основой Fine Reader и обеспечивает ее Уникальность, однако этот процесс совершенно незаметен пользователю - он видит только бегущее по тексту выделение и типовую строку состояния, указывающую, сколько информации обработано, а сколько осталось.
Далее производится проверка правописания, после чего пользователь проверяет слова, которых нет в словаре системы, а также символы, в точности распознавания которых программа не уверена, при этом такие слова и буквы выделяются цветом.
Завершающий этап работы программы - сохранение и экспорт результатов распознавания. На самом деле, в сохранении результатов нет нужды, поскольку вся информация, включая распознанный текст и его форматирование, автоматически сохраняются в пакете вместе с исходным изображением и сведениями о макете страниц. Пользователь может просто закрыть Fine Reader , не опасаясь потери данных, однако отдельно сохраненный текст можно импортировать в различные форматы для дальнейшей работы с ним в других приложениях.
Каждый из описанных шагов - импорт изображений, анализ документа и распознавание, проверка орфографии и сохранение результатов представлены кнопками в панели инструментов программы, что значительно упрощает работу.
Главное окно программы Fine Reader. Программа относительно проста в использовании (особенно если учесть сложность выполняемой ею задачи). Отключаемые панели инструментов снабжены всплывающими подсказками, информативная строка состояния поясняет назначение всех элементов управления, имеется мощная справочная система.
После запуска программы Fine Reader (Пуск/Программы/АВВУУ Fine Reader) открывается Главное окно (рисунок 3.1) программы.
Рисунок 3.1 - Главное Окно Fine Reader
В верхней части Главного окна находится меню системы, под ним - панели инструментов. В программе их четыре: Стандартная, Форматирование, Изображение и Scan&Read. Спрятать или показать инструментальные панели можно через меню Вид/Панели инструментов или через локальное меню, которое открывается щелчком правой кнопки мыши на одной из инструментальных панелей. Панели, которые видны на экране, будут отмечены.
Внизу окна расположена информационная панель или строка состояния. Она отражает информацию о состоянии программы и производимых ею операциях, а также краткую справку о выбираемых пунктах меню и кнопках.
Остальное пространство Главного окна занимают по мере своего появления рабочие окна программы: Пакет, Изображение, Крупный план и Текст. Окна с изображением текущей страницы взаимосвязаны: два показывают общий и крупный планы картинки, третье содержит распознанный текст. Если поместить курсор на символ в текстовом окне, программа автоматически выделяет соответствующую деталь на крупном плане. При возникновении проблем с распознаванием Fine Reader выдает достаточно осмысленные сообщения, предлагая изменить параметры сканирования или точнее указать язык документа. Текстовое окно позволяет форматировать и редактировать документ.
В окне Крупный план по умолчанию показывается черно-белое изображение независимо от того, какое именно изображение имеет оригинал - цветное, серое или черно-белое. Если изображение цветное и необходимо, чтобы показываемое в окне Крупный план изображение также было цветным, следует Изменить настройки. Для этого в окне Опции (меню Сервис/Опции) на вкладке Вид надо снять отметку с пункта Черно-белая палитра в окне Крупный план (рисунок 3.2).
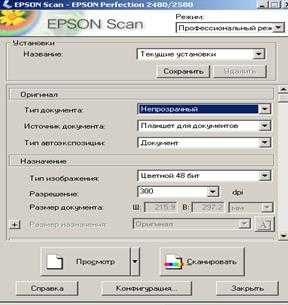
Рисунок 3.2 - Окно настройки параметров Fine Reader
Взаимное расположение окон на экране можно изменять. Процесс ввода документа в компьютер складывается из этапов сканирования и распознавания изображения, после чего производятся проверка и сохранение полученного электронного документа.
Сканирование изображения. После запуска программы Fine Reader, открывается окно программы. Вставить в сканер страницу, которую необходимо распознать, нажать на стрелку справа от кнопки Scan&Read.в открывшемся меню выбрать пункт Мастер Scan&Read (рисунок 3.3).

Рисунок 3.3 Мастер Scan&Read
На первом этапе сканер играет роль «глаза» компьютера, при этом полученное изображение является ни чем иным, как набором черных, белых или цветных точек, картинкой, которую невозможно отредактировать ни в одном текстовом редакторе.
Fine Reader взаимодействует со сканером через стандартные драйверы, что обеспечивает ему совместимость практически со всеми современными сканерами.
Для сканирования изображения документ кладут на стекло сканера страницу с текстом или книгу и нажимают кнопку. Сканировать (Scan) или в меню Файл выбирают пункт Сканировать. В результате в Главном окне программы Fine Reader появится окно Изображение с «фотографией» вставленной в сканер страницы.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании, что достигается установкой основных параметров сканирования - типа изображения, разрешения и яркости.
Сканирование в сером типе изображения (256 градаций) является оптимальным режимом для системы распознавания, и подбор яркости осуществляется автоматически. Черно-белый тип изображения обеспечивает более высокую скорость сканирования, но при этом теряется часть информации о буквах, что может привести к ухудшению качества распознавания на документах среднего и низкого качества печати.
Если необходимо, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используется серый тип изображения.
Для обычных текстов (с размером шрифта 10 и более пунктов) устанавливают разрешение не менее 300 точек на дюйм, а текстов с мелким шрифтом (9 и менее пунктов) - 400... 600 точек на дюйм. В большинстве случаев при сканировании подходит среднее значение яркости - 50 %, и только на некоторых документах при сканировании в черно-белом режиме может понадобиться дополнительная настройка яркости.
Для удобства сканирования большого числа страниц в программе предусмотрен специальный режим Сканировать несколько страниц. Он позволяет отсканировать несколько страниц в цикле, затем их распознать в один прием и сохранить в выбранном формате.
Распознаваемое изображение может содержать много лишних точек, возникших в результате сканирования документа среднего или плохого качества. Чтобы уменьшить количество лишних точек, можно воспользоваться опцией Очистить от мусора в меню Изображение.
Ряд настроек можно сделать еще перед началом сканирования в настройках можно указать программе инвертирование изображения, очистку его от «мусора», автоматическое определение ориентации текста на изображении, для чего в меню Сервис/Опции закладке Сканирование/Открытие следует отметить соответствующие позиции.
При распознавании изображение должно иметь стандартную ориентацию, т. е. текст должен читаться сверху вниз и строки должны быть горизонтальными. По умолчанию программа при распознавании определяет и корректирует ориентацию изображения автоматически, но имеется возможность повернуть изображение вручную.
После завершения сканирования изображение окажется включенным в конец пакета, если не активна опция Запрашивать номер страницы перед добавлением в пакет, а его пиктограмма отобразится на панели пакета (вертикальная панель слева на экране). Если щелкнуть мышью по этой пиктограмме, можно увидеть все окна Fine Reader , при этом основное место на экране будет занимать окно изображения и текста, в левой части которого расположено изображение страницы, а в правой будет находиться распознанный текст. Каждая из этих двух частей главного окна программы снабжена стандартными инструментами управления масштабом, а слева от окна изображения имеется еще и небольшая панель инструментов работы с изображением.
На изображении страницы можно увидеть небольшую пунктирную рамку с лупой. Та часть изображения, которая попадет в эту рамку, отображается в окне крупного плана. Щелчок мыши по определенной части изображения переместит центр увеличиваемой области в указанное место.
Анализ макета страниц.Передраспознаванием текста, необходимо указать, какие именно области подлежат распознаванию, как расположены строки.
Определение ориентации текста при установке соответствующей опции производится автоматически, хотя можно сделать это и вручную путем поворота исходного изображения. Выделение областей распознавания текста решает еще две задачи: во-первых, отдельными блоками выделяются таблицы и рисунки, которые не подлежат распознаванию; во-вторых, четкое выделение блоков позволяет максимально корректно сохранить макет исходной страницы при передаче распознанного документа во внешние приложения (МS Word и Adobe Acrobat).
Далее нажать кнопку Распознать, при этом различные части изображения, содержащие текст, таблицы или рисунки, окажутся обведенными рамками разных цветов и обозначены цифрами в углу каждой рамки. Цвет служит для обозначения типа блока - в стандартных настройках зеленый цвет для текста, красный для рисунков и синий для таблиц. Цветовое кодирование можно при желании изменить (рисунок 3.4).
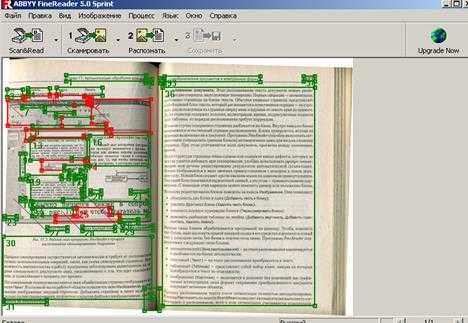
Рисунок 3.4 - Окно анализа макета страниц
Блоки - это заключенные в рамки участки изображения. Блоки выделяют для того, чтобы указать программе, какие участки отсканированной страницы надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы.
При обработке изображений выделяются блоки следующих типов: зона распознавания, текст, таблица, картинка и штрих-код (только в версии Office).
Изменять размеры или форму существующих блоков можно, потянув мышью за их границы. Изменить тип блока позволяет «всплывающее» меню, появляющееся после щелчка мышью по пиктограмме в углу блока, обозначающего его тип.
Для более сложного редактирования макета используются панели инструментов, расположенные слева от окна изображения. Они позволяют нарисовать новые блоки заданного типа, добавить или удалить часть блока, хотя удалить блок можно также с клавиатуры нажатием на клавишу [Dе1] после его выделения.
При автоматическом анализе макета страниц оригинальные изображения достаточно корректно разбиваются на блоки. Неточности, которые программа все-таки допускает, можно легко отредактировать с помощью панели инструментов.
Распознавание текста.После создания макета и его редактирования можно приступить к распознаванию. Задача распознавания состоит в том, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. Fine Reader поддерживает более сотни языков. Язык, на котором будет проводиться распознавание, выбирается на основной панели инструментов. Если исходный текст документа многоязычный, то можно указать несколько языков одновременно, однако следует принять во внимание, что увеличение числа включенных языков замедляет процесс распознавания. Помимо языка оригинала, модуль распознавания учитывает и тип печати, который по умолчанию определяется автоматически, но при необходимости может быть установлен и вручную.
При распознавании текстов, напечатанных на матричном принтере в черновом режиме или на пишущей машинке, можно добиться более высокого качества распознавания, установив правильный тип печати. Выделяются два специфических типа печати: Матричный принтер и пишущая машинка (Сервис/Опции/Тип печати).
Проверка правописания и сохранение результатов работы.Модуль распознавания анализирует не только отдельные символы, но и целые слова, используя при этом встроенный словарь. Кроме того, этот модуль особым образом помечает «неуверенно распознанные» символы.
Работа со словами, неизвестными системе, и с неуверенно распознанными символами осуществляется в модуле проверки правописания. Он вызывается кнопкой Проверить правописание. На рисунок 3.5 изображен спеллер Fine Reader, который предлагает варианты слов, один из которых надо выбрать и нажать кнопку Заменить. Можно поправить ошибку прямо в окне спеллера, а можно оставить слово, как оно есть, если это правильное, но не известное спеллеру слово, тогда используется кнопка Пропустить.

Рисунок 3.5 - Диалоговое окно проверки правописания
Весь распознанный текст виден в окне текста главного окна программы. Оно представляет собой несложный текстовый редактор, позволяющий свободно изменять и гарнитуру шрифта, и его начертание. К тому же в этом окне цветом будут отмечены неуверенно распознанные символы.
После окончания проверки правописания следует определить, в каком формате сохранять полученные результаты (кнопка Сохранить), например RTF, DОС, PDF, НТМL, DBF, ХLS.
Как видно из приведенного списка, Fine Reader позволяет передавать результаты распознавания практически во все широко используемые приложения, такие как MS Word, Мs Ехсе1, а также использовать автоматический ввод для публикации в Wеb и для заполнения баз данных.
3.2 Системы машинного перевода
poisk-ru.ru
Fine Reader | АРТконсервация
- Работа в ABBYY Fine Reader 7.0
- Если программа не установился автоматически на сканер, то …
- Запускаете сканирование
- Распознать все листы
- Проверка последовательности и типа блоков (важный раздел)
- Вид «Черновой режим»
- Если тип блока неверный
- Неправильное наложение блоков
- Блоки сливаются один
- Блоки не распознаются
- Если последовательность блоков неверная
- Произвести «Проверку»
- Мастер сохранения результатов
Запускаете ABBYY Fine Reader 7.0
Если программа не установился автоматически на сканер, то …
Откройте меню сканирования документов.

Выберете драйвер вашего сканера.

И нажмите «ОК»

Запускаете сканирование

Откроется окно сканирования (окно может выглядеть в виде редактора фирмы сканера)

Делаете разрешение 300 пикс.
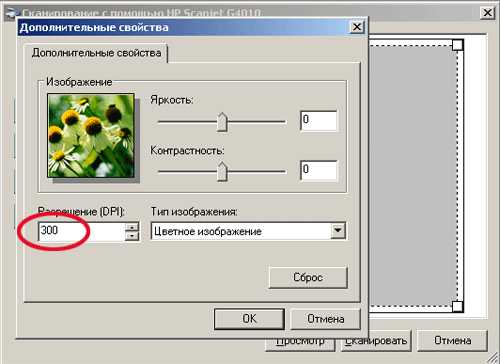
Сканируете лист или несколько листов, удаляя выделением ненужный текст (№ страниц, и т.п.).

Страницы можно развернуть в Fine Reader.
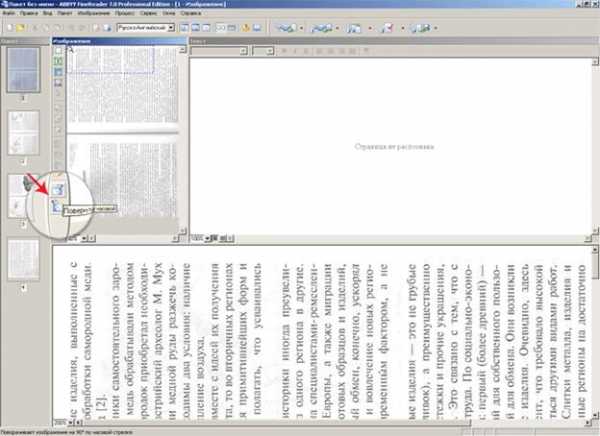
Проверить последовательность отсканированных листов.
Распознать все листы.

Появится окно распознавания страниц.

Проверка последовательности и типа блоков (важный раздел)
Вид «Черновой режим»
В окне «Текст», чтобы четко видеть расположение блоков - в левом нижнем углу этого окна нажмите на значок «Черновой режим» и увидите расположение текста в одну колонку разделенного пунктиром по блокам. Это удобно при редактировании материала.
Если тип блока неверный.
Если тип блока неверный - наводим курсор на блок, нажимаем контекстное меню (правая кнопка мыши). В выпадающем меню выбираем пункт «тип блока» и меняем на нужный тип блока.

Результат будет такой. Если это картинка распознавать блок не нужно, если текст или таблица распознать блок необходимо. Иначе блок будет пустой. Функция «Распознать блок» расположена в контекстном меню.

Неправильное наложение блоков.
Бывает, что блоки накладываются неправильно, тогда мы удаляем ненужные блоки (нажимаем на блок, после на кнопку «delete»), и редактируем нужный блок.

Если редактируется картинка, распознавать его не нужно, если текст или таблица - распознать обязательно. Функция «Распознать блок» расположена в контекстном меню.
Блоки сливаются один.
Бывает, что блоки не распознаются отдельно и сливаются в один текст.

Тогда мы (мы - это Вы и наша инструкция) редактируем границы блока, вызываем контекстное меню и распознаем блок.
Основной текст распознается без ненужного текста. Не забывайте просматривать текст в окне «Текст». Это уменьшит количество ошибок и опечаток.

Если блоки не распознаются.
Теперь выделяем второй текст, вызываем контекстное меню и анализируем его. Иногда можно действовать сразу на распознавание блока без его анализа.
И распознаем этот текст. Не забывайте просматривать текст в окне «Текст». Это уменьшит количество ошибок и опечаток.

Если последовательность блоков неверная.
Если последовательность блоков неверная - наводим курсор на блок.

Вызываем контекстное меню (правая кнопка мыши). В выпадающем меню выбираем пункт «Свойства».

Появляется окно с вкладками. На вкладке «Блок» меняем на нужный № блока.

Блоки автоматически меняют свой номер. Проверяем последовательность блоков в окнах «Изображение» и «Текст». Не забывайте просматривать текст в окне «Текст». Это уменьшит количество ошибок и опечаток.
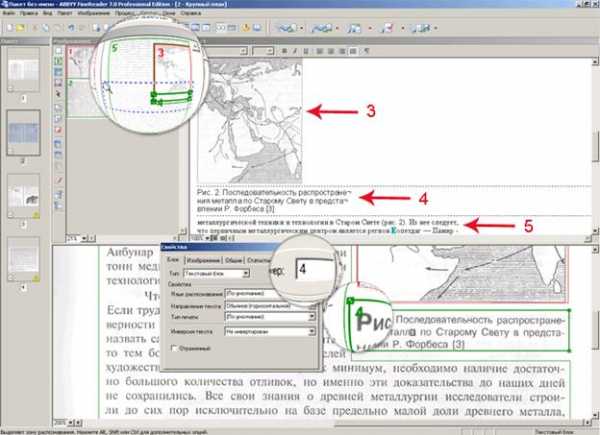
Произвести «Проверку».
Нажмите на кнопку «Начать проверку».

Появится окно «Проверка».
Желательно удалять переносы в виде тире (-) соединяя слова. Знаки в виде переноса (¬) удалять необязательно.
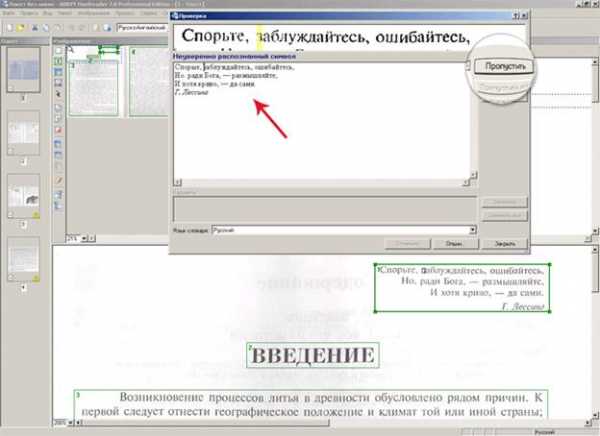
Нераспознанные сложные символы типа α, β, φ, выделяете жирным шрифтом, чтобы найти и исправить в Word. Там это можно сделать, используя редактор «Вставка->Символ».
Проверка завершена - ОК

Мастер сохранения результатов.
Нажимаете на первую страницу в «Пакете». Переходите в «Мастер сохранения результатов»

Выбираете приложение «Microsoft Word», нажимаете на кнопку «Сохранение начертание и размер шрифта», ставите галочку «Сохранять картинки», нажимаете на кнопку «Все страницы» и нажимаете «ОК». Иногда надо запустить Word перед сохранением текста в «Мастере сохранения результатов».

art-con.ru
Персональный сайт - Работа с программой для распознавания текстов "ABBYY Fine Reader v. 10.0 "
? Вы можете временно скрыть неиспользуемыеокна.Чтобы скрыть/отобразить окна воспользуйтесь командами меню
Вид или горячими клавишами:
? F5 —для окна Страницы
 ? F6 — для окнаИзображение
? F6 — для окнаИзображение
? F7 —для оконИзображение и Текст
? F8 —для окна Текст
? Ctrl+F5 —для окнаКрупный план
? Вы можете менять размер окон, перемещаямышью разделители окон.
? Вы можете менять расположениеокон СтраницыиКрупный план.Для этого воспользуйтесь командами меню Видили контекстного меню окна.? Вы можете настроитьпросмотр предупреждений исообщений об ошибках,возникающих в процессе работы программы. По умолчаниюпанельпредупреждений всплывает при выделении страницы в окне Страницы.Чтобы прикрепить панель к нижней части главногоокна, нажмите кнопку .Команда Показыватьпредупреждения в менюВид отвечает заотображение панели предупреждений.? Чтобы открыть/скрыть панель Свойства вокне Изображениеили Текст,воспользуйтесь пунктом Свойствавконтекстном меню окна, или в нижнейчасти окна нажмите кнопку / соответственно.? Некоторые настройки оконзадаются в диалоге Опцииназакладке Вид.
Язык интерфейса
Язык интерфейса программы выбирается при установке ABBYY FineReader.На этом языкебудут написаны всесообщения, названия диалогов, кнопок и пунктов меню программы. Вы можетепереключать язык интерфейса непосредственно изпрограммы.Для этого:1. Откройте диалог Опциина закладке Дополнительные(меню Сервис>Опции…).2. В выпадающем списке Языкинтерфейса выберите нужный язык.3. Нажмите кнопку Закрыть.4. Перезапустите ABBYY FineReader.
ДиалогОпции
Диалог Опциисодержит настройки, позволяющие регулировать опцииоткрытия, сканирования, распознавания,сохранения документов в различные форматы, вид окон программы, выбирать язык итип печати входного документа,язык интерфейса программы и др.
Внимание! Данный диалог доступен из меню Сервис>Опции…,а также из панели инструментов,диалоговсохранения в различные форматы, диалогов открытия изображений иконтекстного меню панели инструментов.
Диалог имеет 6 закладок, на каждой из которых находятсяопции, касающиесятой или иной части функциональностипрограммы:
? Документ
Здесь можно настраивать:
? Языки документа (языки, на которых написанвходной документ)
? Тип печати документа
? Свойства документа (название, автор,ключевые слова)
? Сканировать/Открыть
Здесь определяются общие опции автоматической обработкидокумента, а такжеопции предобработки изображенийпри сканировании и открытии документов, такие как:
? Производить или нет автоматическийанализстраниц документа (автоматически определятьобласти и их типы)
? Выполнять ли автоматическоеконвертированиеизображений страниц
? Выполнять ли автоматическую предобработкуизображений
? Следует ли автоматически определятьориентациюстраниц
? Разбивать ли сдвоенные страницы
Также здесь можно выбрать драйвер для сканера и интерфейссканирования.
? Распознать
Здесь содержатся настройки распознавания:
? Следует применять быстрое или детальноераспознавание
? Следует ли обучить или использовать прираспознавании пользовательский эталон
? Сохранить
Содержит опции сохранения выходного документа в различныеформаты:
? RTF/DOC/DOCX
Подробнее см. в статье «Формат RTF/DOC/DOCX».
? XLS/XLSX
Подробнее см. в статье «Формат XLS/XLSX».
Подробнее см. в статье «Формат PDF».
? PDF/A
Подробнее см. в статье «Формат PDF/A».
? HTML
Подробнее см. в статье «Формат HTML».
? PPTX
Подробнее см. в статье «Формат PPTX».
? TXT
Подробнее см. в статье «Формат TXT».
? CSV
Подробнее см. в статье «Формат CSV».
? Вид
Содержит:? Настройки для видастраниц в окне Страницы(ПиктограммыилиТаблица)? Опции для окна Текст — выделятьли цветом(и каким) неуверенно распознанные символы ислова, отображать ли непечатаемыесимволы (например,перевод строки), какой шрифт использовать для отображенияпростоготекста (Plain text)
? Параметры задания цвета и толщины рамок,используемых для выделенияразличных типов областей в окне
Изображение
? Дополнительные
Содержит:
? Выбор шрифтов, используемых в выходномдокументе
? Настройки проверки орфографии в распознанномтексте
? Путь к папке, в которой будут сохранятьсяпользовательские языки
? Опцию открытия при старте приложенияпоследнегоиспользованного документа
? Выбор языка интерфейса программы
? Кнопку для сохранения в файл текущегополного набора опций
? Кнопку для загрузки из файла полного набораопций, сохраненногоранее
? Кнопкусброса полного набора опций в значения по умолчанию
tiflosoft.narod.ru
- Программа скорость интернета в реальном времени

- После нанесения термопасты когда можно включать компьютер

- Какие бывают сети локальные

- От чего зависит скорость передачи данных в интернете

- Установка windows 7 iis 7

- Sql запрос в excel

- Почему моргают

- Установить мозилла
- Скорость интернета сколько должна быть

- Компьютерные сети видео

- Биос в ноутбуке это что
