Merge delete oracle: BASE — MERGE Statement Enhancements in Oracle Database 10g
4 способа повысить производительность оператора SQL MERGE | от лми | Data Science with Mingyang LI
Опубликовано в
·
Чтение: 3 мин. единая транзакция, что делает ее более читаемой и более эффективнее, чем наличие 3 отдельных операторов. Однако с удобством приходит сложность. Оптимизация операторов MERGE может быть сложной задачей.
Фото Сандера Мутукумарана на Unsplash
Предположим, что оператор MERGE имеет форму:
MERGE target AS TARGET
USING source AS SOURCE
ON условие
WHEN MATCHED THEN UPDATE
WHEN MATCHED THEN TURGET THEN INSERT
WHEN MATCHED THES SOURCE THE УДАЛИТЬ;
Вам абсолютно необходимо MERGE? Вы можете подвергнуть сомнению мой выбор формы, аргументируя это тем, что «но мне не нужно обновлять/вставлять/удалять [выберите два] любую запись; Я просто хочу вставить/удалить/обновить [выберите один]». Если это так, рассмотрите возможность использования инструкции языка манипулирования данными (DML) нижнего уровня (а именно, INSERT/DELETE/UPDATE). При неправильном использовании операторы MERGE могут ухудшить производительность, а не улучшить ее. Используйте с осторожностью.
При неправильном использовании операторы MERGE могут ухудшить производительность, а не улучшить ее. Используйте с осторожностью.
Есть несколько возможностей для улучшения:
Создание индексов . Убедитесь, что столбцы, указанные в условии , правильно проиндексированы. Как и все индексы, по возможности делайте их уникальными, чтобы упростить сравнение.
Следует ли группировать индексы? Хотя для таблицы SOURCE нет особых предпочтений, индекс в таблице TARGET предпочтительно должен быть кластеризован. (Этот трюк явно рекомендуется в документации Transact-SQL и SQL Server 2008 R2.)
Кластерный индекс физически сортирует записи, упрощая вставку/обновление/удаление таблицы. Вот хорошая аналогия: словарь — это таблица, записи которой имеют кластеризованный индекс, потому что он отсортирован в алфавитном порядке по словам. С другой стороны, некластеризованный указатель подобен обычному указателю в конце книги, который оставляет содержание книги нетронутым.
Под словарем можно понимать базу данных с кластеризованным индексом ее записей. Фото Ромена Виньеса на Unsplash
Отдельная фильтрация от сопоставления . Убедитесь, что условие сравнивает только столбцы в двух таблицах (например, target.user_id=source.u_id ), а не столбец с константой (например, source.account_status='ACTIVE' ) . Для сравнения между столбцами и константами используйте предложение WHEN .
Использовать подсказки запроса . Для некоторых механизмов SQL могут помочь указания подсказок запроса. Например, когда мы уверены, что какой-то индекс idx1 будет иметь меньше совпадений по сравнению с каким-то другим индексом, мы можем намекнуть движку на IGNORE INDEX (idx1) .
Прочитать план запроса . Мы можем узнать больше о способах повышения производительности, прочитав план запроса.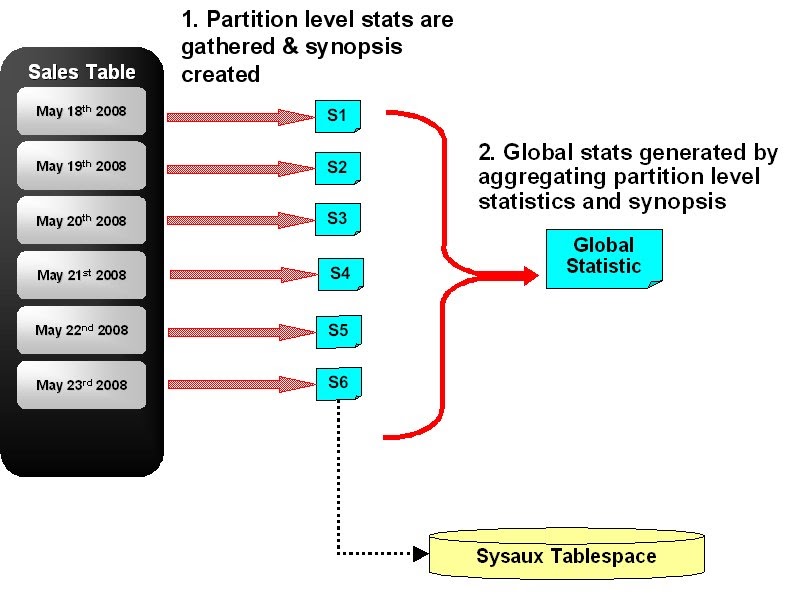 Вы можете обнаружить, что порядок соединения таблиц или тип цикла могут быть не идеальными для вашего варианта использования. Например, избегая правильных внешних соединений, инженеры Vertica сократили
Вы можете обнаружить, что порядок соединения таблиц или тип цикла могут быть не идеальными для вашего варианта использования. Например, избегая правильных внешних соединений, инженеры Vertica сократили MERGE с 30 секунд до 2. Они также предоставили сценарий для оптимизации данных 9 секунд.0032 MERGE заявление.
Надеюсь, это поможет! Дайте мне знать в комментариях, если у вас есть другие идеи, как ускорить выполнение операторов MERGE — очень ценно!
(Первоначально опубликовано на моей личной вики.)
sql server — Могу ли я упростить этот оператор MERGE относительно КОГДА СОВПАДАЮТ условия?
Я использую SQL Server (SQL Server 2016 и Azure SQL), и у меня есть этот оператор MERGE , который использует довольно грубое условие WHEN MATCHED для обновления только тех строк, где значения на самом деле разные.
Это делается по двум причинам:
- В таблице есть столбец
rowversion, который изменится при выполнении операцииUPDATE, даже если все значения одинаковы. Значения
Значения rowversionполезны для уменьшения клиентской активности (приложение используетrowversionдля оптимистичного параллелизма). - Эта таблица также является временной таблицей, и реализация временных таблиц в SQL Server будет добавлять копии оперативных данных в таблицу истории всякий раз, когда
ОБНОВЛЕНИЕвыполняется, даже если фактически никакие значения не изменились.
 Значения
Значения СОЗДАТЬ ПРОЦЕДУРУ UpsertItems
@групповой идентификатор,
@items dbo.ItemsList ТОЛЬКО ДЛЯ ЧТЕНИЯ -- Это параметр с табличным значением. Тип таблицы UDT имеет тот же дизайн, что и таблица `dbo.Items`.
С существующими AS -- использование CTE в качестве цели MERGE, чтобы разрешить *безопасное* использование `WHEN NOT MATCHED BY SOURCE THEN DELETE` и, по-видимому, это хорошо для производительности.
(
ВЫБИРАТЬ
идентификатор группы,
идентификатор товара,
а,
б,
в,
д,
е,
ф,
-- и т. д
ОТ
dbo.Items
ГДЕ
идентификатор группы = @ID_группы
)
ОБЪЕДИНИТЬСЯ С существующим WITH (HOLDLOCK) AS tgt
С ИСПОЛЬЗОВАНИЕМ
@items AS src ON tgt.itemId = src.itemId
КОГДА СООТВЕТСТВУЮТ И
(
-- Эта часть болезненна, но, к сожалению, все эти столбцы могут принимать значение NULL, поэтому им требуется полное сравнение `x IS DISTINCT FROM y`:
( ( tgt.a <> src.a ИЛИ tgt.a IS NULL ИЛИ src.a IS NULL ) И НЕ ( tgt.a IS NULL AND src.a IS NULL)) )
ИЛИ
(( tgt.b <> src.b ИЛИ tgt.b IS NULL ИЛИ src.b IS NULL ) И НЕ (tgt.b IS NULL AND src.b IS NULL))
ИЛИ
(( tgt.c <> src.c ИЛИ tgt.c IS NULL ИЛИ src.c IS NULL ) И НЕ (tgt.c IS NULL AND src.c IS NULL))
ИЛИ
(( tgt.d <> src.d ИЛИ tgt.d IS NULL ИЛИ src.d IS NULL ) И НЕ (tgt.d IS NULL AND src.d IS NULL))
ИЛИ
( ( tgt.e <> src.e ИЛИ tgt.e IS NULL ИЛИ src.e IS NULL ) AND NOT ( tgt.e IS NULL AND src.e IS NULL))
ИЛИ
(( tgt.f <> src.f ИЛИ tgt.f IS NULL ИЛИ src.f IS NULL ) И НЕ (tgt.f IS NULL AND src. f IS NULL))
-- и т. д
)
ЗАТЕМ ОБНОВИТЬ НАБОР
tgt.a = ист.a,
tgt.б = ист.б,
tgt.c = источник.c,
tgt.d = ист.d,
tgt.e = источник.e,
tgt.f = src.f,
-- и т. д
ЕСЛИ НЕ СООТВЕТСТВУЕТ ЦЕЛИ, ТО ВСТАВИТЬ (
идентификатор группы,
идентификатор товара,
а,
б,
в,
д,
е,
ф,
-- и т. д
)
ЦЕННОСТИ (
src.groupId,
src.itemId,
источник,
источник б,
src.c,
src.d,
источник,
src.f,
-- и т. д
)
ЕСЛИ НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ, УДАЛИТЬ
ВЫХОД
$действие КАК [Действие],
вставленный.groupId КАК Ins_groupId,
удален .groupId AS Del_groupId,
вставленный.itemId КАК Ins_itemId,
удален .itemId AS Del_itemId,
вставленный.a AS Ins_a,
удален .а AS Del_a,
вставленный.b КАК Ins_b,
удален .b AS Del_b,
вставленный.с КАК Ins_c,
удален .c AS Del_c,
вставленный.d КАК Ins_d,
удален .d AS Del_d,
вставленный.e КАК Ins_e,
удалил .e AS Del_e,
вставлено.f КАК Ins_f,
удален . f AS Del_f,
-- и т. д
;
 д
ОТ
dbo.Items
ГДЕ
идентификатор группы = @ID_группы
)
ОБЪЕДИНИТЬСЯ С существующим WITH (HOLDLOCK) AS tgt
С ИСПОЛЬЗОВАНИЕМ
@items AS src ON tgt.itemId = src.itemId
КОГДА СООТВЕТСТВУЮТ И
(
-- Эта часть болезненна, но, к сожалению, все эти столбцы могут принимать значение NULL, поэтому им требуется полное сравнение `x IS DISTINCT FROM y`:
( ( tgt.a <> src.a ИЛИ tgt.a IS NULL ИЛИ src.a IS NULL ) И НЕ ( tgt.a IS NULL AND src.a IS NULL)) )
ИЛИ
(( tgt.b <> src.b ИЛИ tgt.b IS NULL ИЛИ src.b IS NULL ) И НЕ (tgt.b IS NULL AND src.b IS NULL))
ИЛИ
(( tgt.c <> src.c ИЛИ tgt.c IS NULL ИЛИ src.c IS NULL ) И НЕ (tgt.c IS NULL AND src.c IS NULL))
ИЛИ
(( tgt.d <> src.d ИЛИ tgt.d IS NULL ИЛИ src.d IS NULL ) И НЕ (tgt.d IS NULL AND src.d IS NULL))
ИЛИ
( ( tgt.e <> src.e ИЛИ tgt.e IS NULL ИЛИ src.e IS NULL ) AND NOT ( tgt.e IS NULL AND src.e IS NULL))
ИЛИ
(( tgt.f <> src.f ИЛИ tgt.f IS NULL ИЛИ src.f IS NULL ) И НЕ (tgt.f IS NULL AND src.
д
ОТ
dbo.Items
ГДЕ
идентификатор группы = @ID_группы
)
ОБЪЕДИНИТЬСЯ С существующим WITH (HOLDLOCK) AS tgt
С ИСПОЛЬЗОВАНИЕМ
@items AS src ON tgt.itemId = src.itemId
КОГДА СООТВЕТСТВУЮТ И
(
-- Эта часть болезненна, но, к сожалению, все эти столбцы могут принимать значение NULL, поэтому им требуется полное сравнение `x IS DISTINCT FROM y`:
( ( tgt.a <> src.a ИЛИ tgt.a IS NULL ИЛИ src.a IS NULL ) И НЕ ( tgt.a IS NULL AND src.a IS NULL)) )
ИЛИ
(( tgt.b <> src.b ИЛИ tgt.b IS NULL ИЛИ src.b IS NULL ) И НЕ (tgt.b IS NULL AND src.b IS NULL))
ИЛИ
(( tgt.c <> src.c ИЛИ tgt.c IS NULL ИЛИ src.c IS NULL ) И НЕ (tgt.c IS NULL AND src.c IS NULL))
ИЛИ
(( tgt.d <> src.d ИЛИ tgt.d IS NULL ИЛИ src.d IS NULL ) И НЕ (tgt.d IS NULL AND src.d IS NULL))
ИЛИ
( ( tgt.e <> src.e ИЛИ tgt.e IS NULL ИЛИ src.e IS NULL ) AND NOT ( tgt.e IS NULL AND src.e IS NULL))
ИЛИ
(( tgt.f <> src.f ИЛИ tgt.f IS NULL ИЛИ src.f IS NULL ) И НЕ (tgt.f IS NULL AND src. f IS NULL))
-- и т. д
)
ЗАТЕМ ОБНОВИТЬ НАБОР
tgt.a = ист.a,
tgt.б = ист.б,
tgt.c = источник.c,
tgt.d = ист.d,
tgt.e = источник.e,
tgt.f = src.f,
-- и т. д
ЕСЛИ НЕ СООТВЕТСТВУЕТ ЦЕЛИ, ТО ВСТАВИТЬ (
идентификатор группы,
идентификатор товара,
а,
б,
в,
д,
е,
ф,
-- и т. д
)
ЦЕННОСТИ (
src.groupId,
src.itemId,
источник,
источник б,
src.c,
src.d,
источник,
src.f,
-- и т. д
)
ЕСЛИ НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ, УДАЛИТЬ
ВЫХОД
$действие КАК [Действие],
вставленный.groupId КАК Ins_groupId,
удален .groupId AS Del_groupId,
вставленный.itemId КАК Ins_itemId,
удален .itemId AS Del_itemId,
вставленный.a AS Ins_a,
удален .а AS Del_a,
вставленный.b КАК Ins_b,
удален .b AS Del_b,
вставленный.с КАК Ins_c,
удален .c AS Del_c,
вставленный.d КАК Ins_d,
удален .d AS Del_d,
вставленный.e КАК Ins_e,
удалил .e AS Del_e,
вставлено.f КАК Ins_f,
удален .
f IS NULL))
-- и т. д
)
ЗАТЕМ ОБНОВИТЬ НАБОР
tgt.a = ист.a,
tgt.б = ист.б,
tgt.c = источник.c,
tgt.d = ист.d,
tgt.e = источник.e,
tgt.f = src.f,
-- и т. д
ЕСЛИ НЕ СООТВЕТСТВУЕТ ЦЕЛИ, ТО ВСТАВИТЬ (
идентификатор группы,
идентификатор товара,
а,
б,
в,
д,
е,
ф,
-- и т. д
)
ЦЕННОСТИ (
src.groupId,
src.itemId,
источник,
источник б,
src.c,
src.d,
источник,
src.f,
-- и т. д
)
ЕСЛИ НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ, УДАЛИТЬ
ВЫХОД
$действие КАК [Действие],
вставленный.groupId КАК Ins_groupId,
удален .groupId AS Del_groupId,
вставленный.itemId КАК Ins_itemId,
удален .itemId AS Del_itemId,
вставленный.a AS Ins_a,
удален .а AS Del_a,
вставленный.b КАК Ins_b,
удален .b AS Del_b,
вставленный.с КАК Ins_c,
удален .c AS Del_c,
вставленный.d КАК Ins_d,
удален .d AS Del_d,
вставленный.e КАК Ins_e,
удалил .e AS Del_e,
вставлено.f КАК Ins_f,
удален . f AS Del_f,
-- и т. д
;
f AS Del_f,
-- и т. д
;
Как видите, поддерживать это совсем несложно!
Я уже использую такие инструменты, как T4, для автоматизации создания повторяющихся частей этого запроса, но просто… масштаб и боль этого оператора MERGE заставляют меня чувствовать, что я делаю что-то очень неправильное (потому что программное обеспечение предназначена для того, чтобы освещать путь через Яму Успеха, поэтому, если кто-то сталкивается с трудностями, пытаясь поступать правильно , вы, вероятно, делаете это неправильно ), но я не могу придумать или увидеть лучшего способа сделать это ( BULK INSERT несмотря на это, но для целей данного вопроса это невозможно).
Я знаю, что это утверждение может быть упрощено в других СУБД, которые поддерживают x IS DISTINCT FROM y (который заменяет ужасные, но необходимые NULL -safe проверки в WHEN MATCHED AND , но SQL Server по-прежнему не поддерживает его
Еще одной проблемой является отсутствие DRY в SQL в целом и сложность реализации базы данных DRY в SQL Server (например, нет поддержки отложенных ограничений или наследования таблиц, поэтому вы не можете реализовать подкласс Table Pattern, что означает ненужное повторение дизайна данных в нескольких таблицах и более слабые ограничения) — но это другая тема. Я просто разочарован тем, как назад Сегодня программирование на SQL кажется сравнимым со многими функциями, позволяющими экономить время и нажатия клавиш в современных языках, таких как Kotlin и TypeScript.
Я просто разочарован тем, как назад Сегодня программирование на SQL кажется сравнимым со многими функциями, позволяющими экономить время и нажатия клавиш в современных языках, таких как Kotlin и TypeScript.
Я хотел бы иметь возможность сделать что-то подобное, и не иметь ничего общего (например, MERGE небезопасно по умолчанию без явного HOLDLOCK — это безумие!):
MERGE INTO
dbo.Items AS tgt
ГДЕ
tgt.groupId = @groupId
ОТ
@items AS источник
НА
tgt.itemId = src.itemId
КОГДА СООТВЕТСТВУЮТ И РАЗЛИЧНЫ, ТОГДА ОБНОВЛЯЙТЕ (automap)
КОГДА НЕ СООТВЕТСТВУЕТ ЦЕЛИ, ТО ВСТАВИТЬ (автокарта)
ЕСЛИ НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ, УДАЛИТЬ
ВЫВОД ВСЕ;
(Где автоматическое сопоставление было бы замечательной функцией в SQL Server, которая автоматически сопоставляет столбцы источника и назначения по имени и выдает ошибку времени компиляции, если она не может автоматически и безопасно сопоставлять столбцы друг с другом), и ВЫВОД ВСЕ выведет все $action , вставил и удалил значения с разными именами столбцов — используя те же имена столбцов, но с вставленными и удаленными значениями в соседних строках).