Средство импорта и экспорта данных в Microsoft SQL Server 2008. Ms sql экспорт в sql
Средство импорта и экспорта данных в Microsoft SQL Server 2008 | Info-Comp.ru
В СУБД Microsoft SQL Server 2008 существует отличный функционал по импорту и экспорту данных, причем в разные форматы и разные базы данных. Его можно также использовать для простого переноса данных из одной базы в другую или с одного сервера на другой. Сегодня мы рассмотрим примеры использования данного средства, и, как мне кажется, это очень удобно.
Мы с Вами уже не раз затрагивали тему импорта и экспорта данных в MS SQL Server 2008, например, в статьях:
Но так или иначе, это было связанно с клиентским приложением, т.е. Access, другими словами, мы это делали для пользователей, чтобы они могли выгружать или загружать данные в базу. А теперь пришло время поговорить о том, чем может, и, наверное, должен пользоваться системный администратор или программист для подобного рода задач.
Примечание! Далее подразумевается, что у Вас уже установлена СУБД Microsoft SQL Server 2008 и средство импорта и экспорта данных, так как оно идет в комплекте, и на примере Windows 7 Вы можете наблюдать в меню «Пуск-> Все программы-> Microsoft SQL Server 2008 R2-> Импорт и экспорт данных (32-разрядная версия)». У меня это выглядит следующим образом:
И для того чтобы рассмотреть функционал по импорту и экспорту данных, давайте разберем два примера, первый по импорту данных, а второй по экспорту данных.
Импорт данных из Excel документа в MSSql 2008
Создаем тестовые данные в документе Excel
Мы будем использовать старый, но проверенный Excel 2003 и формат файла у нас будет xls.
Данные будут вот такие, файл я назвал test_file.xls:
Сразу скажу, что в данном примере мы будем импортировать данные в новую таблицу, поэтому на название полей мы не обращаем внимания. Но если бы мы импортировали уже в существующую таблицу, то нам в процессе импорта пришлось бы задавать соответствие этих полей или изначально в файле создать столько полей с тем же названием и в той же последовательности, как и в таблице. А если этого не сделать, то те поля, которые отсутствуют в таблице в базе, будут со значением null. Как задать соответствие этих полей и как импортировать данные в уже существующую таблицу я покажу в процессе импорта.
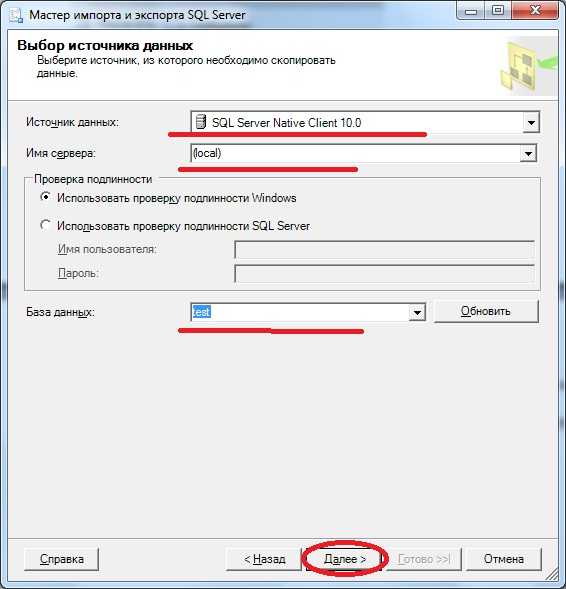
Примечание! Сервер располагается локально, база данных называется test.
Шаг 1
Итак, приступим, у нас есть файл, теперь запускаем средство импорта, и у нас открывается следующее окно:

Шаг 2
Нажимаем далее, где нам предлагают выбрать источник данных, в нашем случае это Excel, мы выбираем файл, версию excel и ставим галочку, что первая строка - это заголовок:

Шаг 3
Жмем далее, нам предлагают выбрать назначение, куда копировать эти данные, мы выбираем SQL Server, указываем имя сервера, т.е. его адрес, в нашем случае, как я уже сказал, он расположен локально. Также не забудьте про проверку подлинности, выбирайте тот метод, который у Вас настроен на сервере, и, конечно же, про базу данных, в которую копировать:
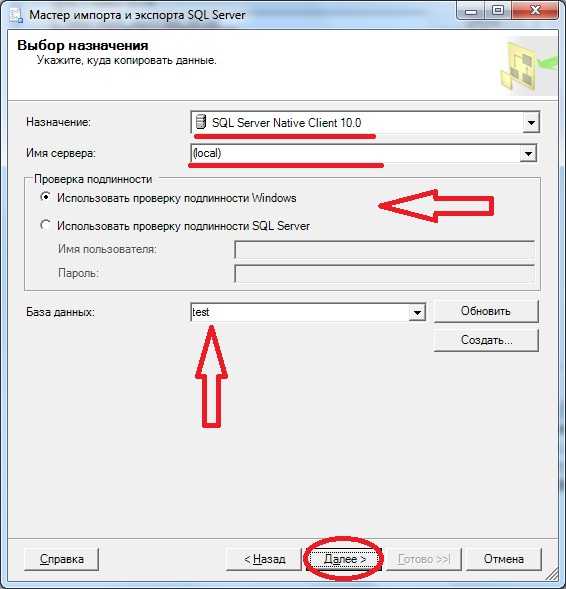
Шаг 4
Снова жмем далее, где мы укажем все ли данные копировать, в нашем случае мы говорим что все:
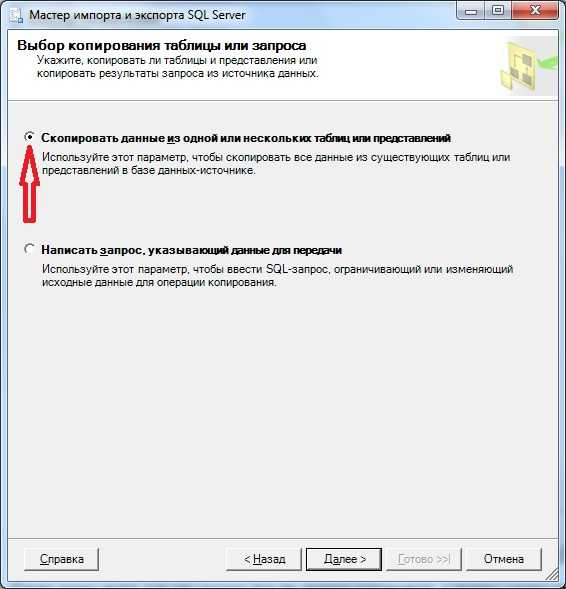
Шаг 5
Жмем далее, и попадаем на окно выбора листа с данными и задания названия таблицы в нашей базе, я выбрал лист 1 и назвал таблицу test_table:
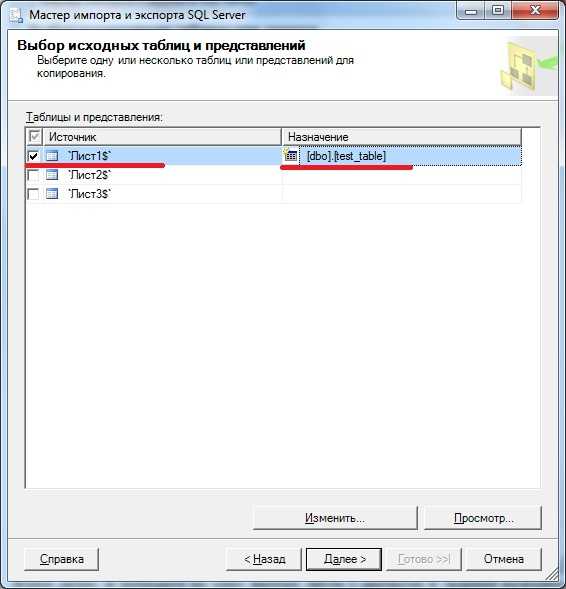
И, кстати, вот на этом этапе можно задать соответствие полей. В случае если Вы импортируете данные в существующую таблицу, для соответствия полей Вам необходимо выбрать таблицу из выпадающего списка и нажать изменить, где Вы также можете задать такие параметры как назначение, тип данных и другие, для примера вот это окно:

Шаг 6
Это было небольшое отступление, а в нашем примере мы жмем далее, и попадаем в окно, в котором можно сохранить все наше действия в пакет, но мы этого делать не будем, а сразу же нажмем готово:

Шаг 7
После появится окно, где мы все проверяем и жмем готово:
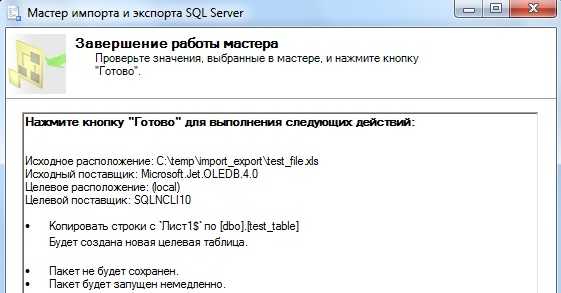
Шаг 8
И в заключение у нас появится еще одно окно, так сказать результат наших действий, жмем закрыть:
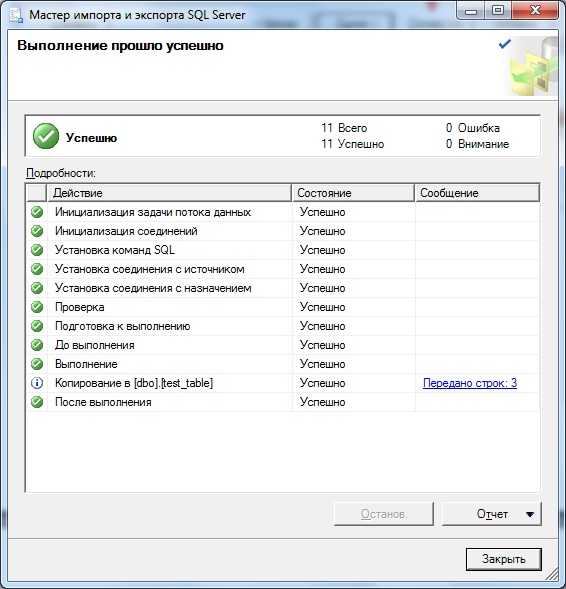
Как видно, передано 3 строки, т.е. импортировано - это означает, что все наши данные, которые были в файле, импортировались.
И для того, чтобы проверить какие данные у нас импортировались, выполним в Management Studio простой запрос select.

И как видите все хорошо!
Экспорт данных из Microsoft SQL Server 2008 в файл Excel
А теперь давайте рассмотрим пример экспорта данных из нашей только что созданной таблицы в Excel документ.
Шаг 1
Для этого делаем практически то же самое, открываем средство экспорта, но уже здесь в качестве источника указываем нашу базу:
Шаг 2
Жмем далее, где нам предлагают указать назначение экспорта, мы соответственно выбираем Excel, и задаем путь и название выгружаемого файла:

Шаг 3
После того как Вы нажмете далее, Вы попадете в окно выбора данных, т.е. какие именно данные мы будем выгружать, и здесь давайте укажем - выгружать данные на основе запроса. Так как, когда мы импортировали данные, мы выбрали все, а теперь для примера выберем не все, а на основе запроса, можно также выбрать все и указать таблицу или представление VIEWS, в котором уже будут отфильтрованные данные, но мы напишем SQL запрос:

Шаг 4
И в следующем окне вставляем свой запрос, например, я написал вот такой:

Также в этом окне Вы можете выполнить анализ своего запроса, на предмет наличия ошибок или выбрать файл, который содержит текст запроса, и, если все хорошо, жмем далее.
Шаг 5
На следующем окне сразу же можем нажимать далее, если конечно Вы не хотите задать свои названия полей в выгружаемом файле.
Шаг 6
Затем на следующем окне все проверяем и жмем готово.
Шаг 7
Далее, как и в импорте, жмем последний раз готово. И все, после этого у Вас в той папке, которую Вы указали, появится документ Excel с Вашими данными.
После рассмотрения этих примеров, я думаю стало понятно, как можно осуществлять импорт и экспорт данных в MS SQL Server 2008. Использовать можно не только Excel, но и другие источники данных, ну я думаю, дальше Вы разберетесь сами, так как это не так сложно, но если у Вас все равно возникают вопросы, можете задавать их в комментариях.
Пока!
Похожие статьи:
info-comp.ru
экспорт запроса в формате .txt MS SQL Server
вы делаете это в SSMS-приложении, а не в SQL. На панели инструментов выберите
Query -> Results To -> Results to File
Другой путь – из командной строки, используя команду osql:
OSQL -S SERVERNAME -E -i thequeryfile.sql -o youroutputfile.txtЭто может быть использовано из файла BAT и синхронизировано пользователем Windows для аутентификации.
Вы можете использовать утилиту bcp .
Чтобы скопировать результирующий набор из инструкции Transact-SQL в файл данных, используйте параметр запроса. Следующий пример копирует результат запроса в файл данных Contacts.txt. В этом примере предполагается, что вы используете проверку подлинности Windows и имеете надежное соединение с экземпляром сервера, на котором выполняется команда bcp. В командной строке Windows введите:
bcp "<your query here>" queryout Contacts.txt -c -TВы можете использовать Windows Powershell для выполнения запроса и вывода его в текстовый файл
Invoke-Sqlcmd -Query «Выбрать * из базы данных» -ServerInstance «Имя сервера \ SQL2008» -Database «DbName»> c: \ Users \ outputFileName.txt
Утилиту BCP можно также использовать в виде .bat-файла, но будьте осторожны с escape-последовательностями (например, кавычки «" должны использоваться вместе с) и соответствующими тегами.
.bat Пример:
C: bcp "\"YOUR_SERVER\".dbo.Proc" queryout C:\FilePath.txt -T -c -q -- Add PAUSE here if you'd like to see the completed batch-q ДОЛЖНО использоваться при наличии котировок внутри самого запроса.
BCP также может запускать хранимые процедуры, если это необходимо. Опять же, будьте осторожны: временные таблицы должны быть созданы до выполнения, иначе вам следует рассмотреть использование переменных таблицы.
Это довольно просто сделать, и ответ доступен в других запросах. Для тех из вас, кто просматривает это:
select entries from my_entries where INTO OUTFILE 'bishwas.txt';Импорт/экспорт данных в sql Server
1. Экспорт данных в другую БД SQL Server (создание копии БД)

Рисунок 6.1

Рисунок 6.2

Рисунок 6.3

Рисунок 6.4

Рисунок 6.5

Рисунок 6.6

Рисунок 6.7
2. Экспорт данных в другую СУБД
Экспорт выполняется аналогично только на шаге, показанном на рисунке 6.3, только в разделе Destination указать в качестве приемника нужную СУБД.
Лабораторная работа №3 «Обеспечение безопасности SQL Server. Создание Логинов. Реализация шифрования»
Цель:
Вид работы: индивидуальный.
Время выполнения: 4 часа.
Теоретические сведения:
Microsoft SQL Server 2000 – это законченное предложение в области баз данных и анализа данных для быстрого создания масштабируемых решений электронной коммерции, бизнес-приложений и хранилищ данных. Оно позволяет значительно сократить время выхода этих решений на рынок, одновременно обеспечивая масштабируемость, отвечающую самым высоким требованиям. В сервер SQL Server 2000 включена поддержка языка XML и протокола HTTP, средства повышения быстродействия и доступности, позволяющие распределить нагрузку и обеспечить бесперебойную работу, функции для улучшения управления и настройки, снижающие совокупную стоимость владения. Кроме того, SQL Server 2000 полностью использует все возможности операционной системы Windows 2000, включая поддержку до 32 процессоров и 64 ГБ ОЗУ.
Общие правила разграничения доступа
Если ваша база данных предназначена для использования более чем одним человеком, необходимо позаботиться о разграничении прав доступа. В процессе планирования системы безопасности следует определить, какие данные могут просматривать те или иные пользователи и какие действия в базе данных им разрешено при этом предпринимать.
После проектирования логической структуры базы данных, связей между таблицами, ограничений целостности и других структур необходимо определить круг пользователей, которые будут иметь доступ к базе данных. Чтобы разрешить этим пользователям обращаться к серверу, создайте для них учетные записи в MS SQL Server 2000 либо предоставьте им доступ посредством учетных записей в домене, если вы используете систему безопасности Windows NT. Разрешение доступа к серверу не дает автоматически доступа к базе данных и ее объектам.
Второй этап планирования системы безопасности заключается в определении действий, которые может выполнять в базе данных конкретный пользователь. Пол ный доступ к базе данных и всем ее объектам имеет администратор, который является своего рода хозяином базы данных — ему позволено все. Второй человек после администратора — это владелец объекта. При создании любого объекта в базе данных ему назначается владелец, который может устанавливать права доступа к этому объекту, модифицировать его и удалять. Третья категория пользователей имеет права доступа, выданные им администратором или владельцем объекта.
Тщательно планируйте права, выдаваемые пользователям в соответствии с занимаемой должностью и необходимостью выполнения конкретных действий. Так вовсе необязательно назначать права на изменение данных в таблице, содержа щей сведения о зарплате сотрудников, директору компании. И, конечно же, нельзя предоставлять подобные права рядовому сотруднику. Вы можете выдать права только на ввод новых данных, например информации о новых клиентах. Непра вильный ввод такой информации не нанесет серьезного ущерба компании, но если добавить к правам ввода еще и возможность исправления или удаления уже существующих данных, то злоумышленник, завладевший паролем, может нанес ти существенные финансовые потери. Кроме этого, следует учесть ущерб от рабо ты пользователей, не сильно задумывающихся о последствиях своих действий.
Правильно спроектированная система безопасности не должна позволять пользователю выполнять действия, выходящие за рамки его полномочий. Не, лишним также будет предусмотреть дополнительные средства защиты, например, не разрешать удалять данные, если срок их хранения не истек, то есть они не потеряли актуальность. Можно также предоставлять служащим, которые недавно устроились на работу, минимальный доступ или доступ только в режиме чтения. Позже им можно будет разрешить и изменение данных.
Следует внимательно относиться к движению сотрудников внутри компании, их переходам из одного отдела в другой. Изменения занимаемой должности должны незамедлительно отражаться на правах доступа. Своевременно удаляйте пользователей, которые больше не работают в компании. Если вы оставите человеку, занимавшему руководящую должность и ушедшему в конкурирующую фирму, доступ к данным, он может воспользоваться ими и нанести ущерб вашей компании. Если человек уходит в отпуск или уезжает в длительную командировку, нужно временно заблокировать его. учетную запись.
При создании паролей следуйте стандартным рекомендациям. Желательно, чтобы пароль включал в себя не только символы, но и цифры. Следите, чтобы пользователи не применяли в качестве пароля год рождения, номер паспорта, машины или другие часто используемые данные. Установите ограниченный срок действия пароля, по истечении которого система потребует у пользователя сменить пароль. Для достижения максимальной степени безопасности используйте аутентификацию пользователей средствами Windows NT поскольку операционные системы этого семейства предоставляют множество очень полезных средств защиты.
studfiles.net
sql - Как переносить или экспортировать данные SQL Server 2005 в Excel
Смотрите это
Это, безусловно, лучший пост для экспорта в excel из SQL:
http://www.sqlteam.com/forums/topic.asp?TOPIC_ID=49926
Процитировать от пользователя madhivanan,
Помимо использования мастера DTS и экспорта, мы также можем использовать этот запрос для экспорта данных из SQL Server2000 в Excel
Создайте файл Excel с именем testing с заголовками, аналогичными заголовкам столбцов таблицы, и используйте эти запросы
1 Экспорт данных в существующий файл EXCEL из таблицы SQL Server
insert into OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=D:\testing.xls;', 'SELECT * FROM [SheetName$]') select * from SQLServerTable2 Экспорт данных из Excel в новую таблицу SQL Server
select * into SQLServerTable FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=D:\testing.xls;HDR=YES', 'SELECT * FROM [Sheet1$]')3 Экспорт данных из Excel в существующую таблицу SQL Server
Insert into SQLServerTable Select * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=D:\testing.xls;HDR=YES', 'SELECT * FROM [SheetName$]')4 Если вы не хотите заранее создавать файл EXCEL и хотите экспортировать данные на него, используйте
EXEC sp_makewebtask @outputfile = 'd:\testing.xls', @query = 'Select * from Database_name..SQLServerTable', @colheaders =1, @FixedFont=0,@lastupdated=0,@resultstitle='Testing details'(Теперь вы можете найти файл с данными в табличном формате)
5 Чтобы экспортировать данные в новый файл EXCEL с заголовком (имена столбцов), создайте следующую процедуру
create procedure proc_generate_excel_with_columns ( @db_name varchar(100), @table_name varchar(100), @file_name varchar(100) ) as --Generate column names as a recordset declare @columns varchar(8000), @sql varchar(8000), @data_file varchar(100) select @columns=coalesce(@columns+',','')+column_name+' as '+column_name from information_schema.columns where table_name=@table_name select @columns=''''''+replace(replace(@columns,' as ',''''' as '),',',',''''') --Create a dummy file to have actual data select @data_file=substring(@file_name,1,len(@file_name)-charindex('\',reverse(@file_name)))+'\data_file.xls' --Generate column names in the passed EXCEL file set @sql='exec master..xp_cmdshell ''bcp " select * from (select '+@columns+') as t" queryout "'+@file_name+'" -c''' exec(@sql) --Generate data in the dummy file set @sql='exec master..xp_cmdshell ''bcp "select * from '+@db_name+'..'+@table_name+'" queryout "'+@data_file+'" -c''' exec(@sql) --Copy dummy file to passed EXCEL file set @sql= 'exec master..xp_cmdshell ''type '+@data_file+' >> "'+@file_name+'"''' exec(@sql) --Delete dummy file set @sql= 'exec master..xp_cmdshell ''del '+@data_file+'''' exec(@sql)После создания процедуры выполните ее, указав имя базы данных, имя таблицы и путь к файлу:
EXEC proc_generate_excel_with_columns 'your dbname', 'your table name','your file path'Его объявление 29 страниц, но это потому, что другие показывают разные способы, а также люди, задающие вопросы точно так же, как это делать.
Следуйте этой теме полностью и посмотрите на различные вопросы, которые задавали люди и как они решаются. Я получил довольно много знаний, просто просматривая его и использовал его части для получения ожидаемых результатов.
Обновление отдельных ячеек
Член также там Питер Ларсон сообщает следующее: Я думаю, здесь одна вещь отсутствует. Замечательно иметь возможность экспортировать и импортировать файлы Excel, но как насчет обновления отдельных ячеек? Или диапазон ячеек?
Это принцип того, как вы справляетесь с этим
update OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=c:\test.xls;hdr=no', 'SELECT * FROM [Sheet1$b7:b7]') set f1 = -99Вы также можете добавить формулы в Excel, используя это:
update OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=c:\test.xls;hdr=no', 'SELECT * FROM [Sheet1$b7:b7]') set f1 = '=a7+c7'Экспорт с именами столбцов с использованием T-SQL
У члена Mladen Prajdic также есть запись в блоге о том, как это сделать здесь
Ссылки: www.sqlteam.com (кстати, это отличный блог/форум для тех, кто хочет получить больше от SQL Server).
qaru.site
sql - Экспорт схемы базы данных в файл SQL
Я написал это sp, чтобы автоматически создать схему со всеми вещами, pk, fk, разделами, ограничениями...
ВАЖНО!! перед exec
create type TestTableType as table (ObjectID int)здесь SP:
create PROCEDURE [dbo].[util_ScriptTable] @DBName SYSNAME ,@schema sysname ,@TableName SYSNAME ,@IncludeConstraints BIT = 1 ,@IncludeIndexes BIT = 1 ,@NewTableSchema sysname ,@NewTableName SYSNAME = NULL ,@UseSystemDataTypes BIT = 0 ,@script varchar(max) output AS BEGIN try if not exists (select * from sys.types where name = 'TableType') create type TableType as table (ObjectID int)--drop type TableType declare @sql nvarchar(max) DECLARE @MainDefinition TABLE (FieldValue VARCHAR(200)) --DECLARE @DBName SYSNAME DECLARE @ClusteredPK BIT DECLARE @TableSchema NVARCHAR(255) --SET @DBName = DB_NAME(DB_ID()) SELECT @TableName = name FROM sysobjects WHERE id = OBJECT_ID(@TableName) DECLARE @ShowFields TABLE (FieldID INT IDENTITY(1,1) ,DatabaseName VARCHAR(100) ,TableOwner VARCHAR(100) ,TableName VARCHAR(100) ,FieldName VARCHAR(100) ,ColumnPosition INT ,ColumnDefaultValue VARCHAR(100) ,ColumnDefaultName VARCHAR(100) ,IsNullable BIT ,DataType VARCHAR(100) ,MaxLength varchar(10) ,NumericPrecision INT ,NumericScale INT ,DomainName VARCHAR(100) ,FieldListingName VARCHAR(110) ,FieldDefinition CHAR(1) ,IdentityColumn BIT ,IdentitySeed INT ,IdentityIncrement INT ,IsCharColumn BIT ,IsComputed varchar(255)) DECLARE @HoldingArea TABLE(FldID SMALLINT IDENTITY(1,1) ,Flds VARCHAR(4000) ,FldValue CHAR(1) DEFAULT(0)) DECLARE @PKObjectID TABLE(ObjectID INT) DECLARE @Uniques TABLE(ObjectID INT) DECLARE @HoldingAreaValues TABLE(FldID SMALLINT IDENTITY(1,1) ,Flds VARCHAR(4000) ,FldValue CHAR(1) DEFAULT(0)) DECLARE @Definition TABLE(DefinitionID SMALLINT IDENTITY(1,1) ,FieldValue VARCHAR(200)) set @sql= ' use '+@DBName+' SELECT distinct DB_NAME() ,inf.TABLE_SCHEMA ,inf.TABLE_NAME ,''[''+inf.COLUMN_NAME+'']'' as COLUMN_NAME ,CAST(inf.ORDINAL_POSITION AS INT) ,inf.COLUMN_DEFAULT ,dobj.name AS ColumnDefaultName ,CASE WHEN inf.IS_NULLABLE = ''YES'' THEN 1 ELSE 0 END ,inf.DATA_TYPE ,case inf.CHARACTER_MAXIMUM_LENGTH when -1 then ''max'' else CAST(inf.CHARACTER_MAXIMUM_LENGTH AS varchar) end--CAST(CHARACTER_MAXIMUM_LENGTH AS INT) ,CAST(inf.NUMERIC_PRECISION AS INT) ,CAST(inf.NUMERIC_SCALE AS INT) ,inf.DOMAIN_NAME ,inf.COLUMN_NAME + '','' ,'''' AS FieldDefinition --caso di viste, dà come campo identity ma nn dà i valori, quindi lo ignoro ,CASE WHEN ic.object_id IS not NULL and ic.seed_value is not null THEN 1 ELSE 0 END AS IdentityColumn--CASE WHEN ic.object_id IS NULL THEN 0 ELSE 1 END AS IdentityColumn ,CAST(ISNULL(ic.seed_value,0) AS INT) AS IdentitySeed ,CAST(ISNULL(ic.increment_value,0) AS INT) AS IdentityIncrement ,CASE WHEN c.collation_name IS NOT NULL THEN 1 ELSE 0 END AS IsCharColumn ,cc.definition from (select schema_id,object_id,name from sys.views union all select schema_id,object_id,name from sys.tables)t --sys.tables t join sys.schemas s on t.schema_id=s.schema_id JOIN sys.columns c ON t.object_id=c.object_id --AND s.schema_id=c.schema_id LEFT JOIN sys.identity_columns ic ON t.object_id=ic.object_id AND c.column_id=ic.column_id left JOIN sys.types st ON st.system_type_id=c.system_type_id and st.principal_id=t.object_id--COALESCE(c.DOMAIN_NAME,c.DATA_TYPE) = st.name LEFT OUTER JOIN sys.objects dobj ON dobj.object_id = c.default_object_id AND dobj.type = ''D'' left join sys.computed_columns cc on t.object_id=cc.object_id and c.column_id=cc.column_id join INFORMATION_SCHEMA.COLUMNS inf on t.name=inf.TABLE_NAME and s.name=inf.TABLE_SCHEMA and c.name=inf.COLUMN_NAME WHERE inf.TABLE_NAME = @TableName and inf.TABLE_SCHEMA=@schema ORDER BY inf.ORDINAL_POSITION ' print @sql INSERT INTO @ShowFields( DatabaseName ,TableOwner ,TableName ,FieldName ,ColumnPosition ,ColumnDefaultValue ,ColumnDefaultName ,IsNullable ,DataType ,MaxLength ,NumericPrecision ,NumericScale ,DomainName ,FieldListingName ,FieldDefinition ,IdentityColumn ,IdentitySeed ,IdentityIncrement ,IsCharColumn ,IsComputed) exec sp_executesql @sql, N'@TableName varchar(50),@schema varchar(50)', @TableName=@TableName,@schema=@schema /* SELECT @DBName--DB_NAME() ,TABLE_SCHEMA ,TABLE_NAME ,COLUMN_NAME ,CAST(ORDINAL_POSITION AS INT) ,COLUMN_DEFAULT ,dobj.name AS ColumnDefaultName ,CASE WHEN c.IS_NULLABLE = 'YES' THEN 1 ELSE 0 END ,DATA_TYPE ,CAST(CHARACTER_MAXIMUM_LENGTH AS INT) ,CAST(NUMERIC_PRECISION AS INT) ,CAST(NUMERIC_SCALE AS INT) ,DOMAIN_NAME ,COLUMN_NAME + ',' ,'' AS FieldDefinition ,CASE WHEN ic.object_id IS NULL THEN 0 ELSE 1 END AS IdentityColumn ,CAST(ISNULL(ic.seed_value,0) AS INT) AS IdentitySeed ,CAST(ISNULL(ic.increment_value,0) AS INT) AS IdentityIncrement ,CASE WHEN st.collation_name IS NOT NULL THEN 1 ELSE 0 END AS IsCharColumn FROM INFORMATION_SCHEMA.COLUMNS c JOIN sys.columns sc ON c.TABLE_NAME = OBJECT_NAME(sc.object_id) AND c.COLUMN_NAME = sc.Name LEFT JOIN sys.identity_columns ic ON c.TABLE_NAME = OBJECT_NAME(ic.object_id) AND c.COLUMN_NAME = ic.Name JOIN sys.types st ON COALESCE(c.DOMAIN_NAME,c.DATA_TYPE) = st.name LEFT OUTER JOIN sys.objects dobj ON dobj.object_id = sc.default_object_id AND dobj.type = 'D' WHERE c.TABLE_NAME = @TableName ORDER BY c.TABLE_NAME, c.ORDINAL_POSITION */ SELECT TOP 1 @TableSchema = TableOwner FROM @ShowFields INSERT INTO @HoldingArea (Flds) VALUES('(') INSERT INTO @Definition(FieldValue)VALUES('CREATE TABLE ' + CASE WHEN @NewTableName IS NOT NULL THEN @DBName + '.' + @NewTableSchema + '.' + @NewTableName ELSE @DBName + '.' + @TableSchema + '.' + @TableName END) INSERT INTO @Definition(FieldValue)VALUES('(') INSERT INTO @Definition(FieldValue) SELECT CHAR(10) + FieldName + ' ' + --CASE WHEN DomainName IS NOT NULL AND @UseSystemDataTypes = 0 THEN DomainName + CASE WHEN IsNullable = 1 THEN ' NULL ' ELSE ' NOT NULL ' END ELSE UPPER(DataType) +CASE WHEN IsCharColumn = 1 THEN '(' + CAST(MaxLength AS VARCHAR(10)) + ')' ELSE '' END +CASE WHEN IdentityColumn = 1 THEN ' IDENTITY(' + CAST(IdentitySeed AS VARCHAR(5))+ ',' + CAST(IdentityIncrement AS VARCHAR(5)) + ')' ELSE '' END +CASE WHEN IsNullable = 1 THEN ' NULL ' ELSE ' NOT NULL ' END +CASE WHEN ColumnDefaultName IS NOT NULL AND @IncludeConstraints = 1 THEN 'CONSTRAINT [' + ColumnDefaultName + '] DEFAULT' + UPPER(ColumnDefaultValue) ELSE '' END END + CASE WHEN FieldID = (SELECT MAX(FieldID) FROM @ShowFields) THEN '' ELSE ',' END CASE WHEN DomainName IS NOT NULL AND @UseSystemDataTypes = 0 THEN DomainName + CASe WHEN IsNullable = 1 THEN ' NULL ' ELSE ' NOT NULL ' END ELSE case when IsComputed is null then UPPER(DataType) + CASE WHEN IsCharColumn = 1 THEN '(' + CAST(MaxLength AS VARCHAR(10)) + ')' ELSE CASE WHEN DataType = 'numeric' THEN '(' + CAST(NumericPrecision AS VARCHAR(10))+','+ CAST(NumericScale AS VARCHAR(10)) + ')' ELSE CASE WHEN DataType = 'decimal' THEN '(' + CAST(NumericPrecision AS VARCHAR(10))+','+ CAST(NumericScale AS VARCHAR(10)) + ')' ELSE '' end end END + CASE WHEN IdentityColumn = 1 THEN ' IDENTITY(' + CAST(IdentitySeed AS VARCHAR(5))+ ',' + CAST(IdentityIncrement AS VARCHAR(5)) + ')' ELSE '' END + CASE WHEN IsNullable = 1 THEN ' NULL ' ELSE ' NOT NULL ' END + CASE WHEN ColumnDefaultName IS NOT NULL AND @IncludeConstraints = 1 THEN 'CONSTRAINT [' + replace(ColumnDefaultName,@TableName,@NewTableName) + '] DEFAULT' + UPPER(ColumnDefaultValue) ELSE '' END else ' as '+IsComputed+' ' end END + CASE WHEN FieldID = (SELECT MAX(FieldID) FROM @ShowFields) THEN '' ELSE ',' END FROM @ShowFields IF @IncludeConstraints = 1 BEGIN set @sql= ' use '+@DBName+' SELECT distinct '',CONSTRAINT ['' + @NewTableName+''_''+replace(name,@TableName,'''') + ''] FOREIGN KEY ('' + ParentColumns + '') REFERENCES ['' + ReferencedObject + '']('' + ReferencedColumns + '')'' FROM ( SELECT ReferencedObject = OBJECT_NAME(fk.referenced_object_id), ParentObject = OBJECT_NAME(parent_object_id),fk.name , REVERSE(SUBSTRING(REVERSE(( SELECT cp.name + '','' FROM sys.foreign_key_columns fkc JOIN sys.columns cp ON fkc.parent_object_id = cp.object_id AND fkc.parent_column_id = cp.column_id WHERE fkc.constraint_object_id = fk.object_id FOR XML PATH('''') )), 2, 8000)) ParentColumns, REVERSE(SUBSTRING(REVERSE(( SELECT cr.name + '','' FROM sys.foreign_key_columns fkc JOIN sys.columns cr ON fkc.referenced_object_id = cr.object_id AND fkc.referenced_column_id = cr.column_id WHERE fkc.constraint_object_id = fk.object_id FOR XML PATH('''') )), 2, 8000)) ReferencedColumns FROM sys.foreign_keys fk inner join sys.schemas s on fk.schema_id=s.schema_id and s.name=@schema) a WHERE ParentObject = @TableName ' print @sql INSERT INTO @Definition(FieldValue) exec sp_executesql @sql, N'@TableName varchar(50),@NewTableName varchar(50),@schema varchar(50)', @TableName=@TableName,@NewTableName=@NewTableName,@schema=@schema /* SELECT ',CONSTRAINT [' + name + '] FOREIGN KEY (' + ParentColumns + ') REFERENCES [' + ReferencedObject + '](' + ReferencedColumns + ')' FROM ( SELECT ReferencedObject = OBJECT_NAME(fk.referenced_object_id), ParentObject = OBJECT_NAME(parent_object_id),fk.name , REVERSE(SUBSTRING(REVERSE(( SELECT cp.name + ',' FROM sys.foreign_key_columns fkc JOIN sys.columns cp ON fkc.parent_object_id = cp.object_id AND fkc.parent_column_id = cp.column_id WHERE fkc.constraint_object_id = fk.object_id FOR XML PATH('') )), 2, 8000)) ParentColumns, REVERSE(SUBSTRING(REVERSE(( SELECT cr.name + ',' FROM sys.foreign_key_columns fkc JOIN sys.columns cr ON fkc.referenced_object_id = cr.object_id AND fkc.referenced_column_id = cr.column_id WHERE fkc.constraint_object_id = fk.object_id FOR XML PATH('') )), 2, 8000)) ReferencedColumns FROM sys.foreign_keys fk ) a WHERE ParentObject = @TableName */ set @sql= ' use '+@DBName+' SELECT distinct '',CONSTRAINT ['' + @NewTableName+''_''+replace(c.name,@TableName,'''') + ''] CHECK '' + definition FROM sys.check_constraints c join sys.schemas s on c.schema_id=s.schema_id and s.name=@schema WHERE OBJECT_NAME(parent_object_id) = @TableName ' print @sql INSERT INTO @Definition(FieldValue) exec sp_executesql @sql, N'@TableName varchar(50),@NewTableName varchar(50),@schema varchar(50)', @TableName=@TableName,@NewTableName=@NewTableName,@schema=@schema /* SELECT ',CONSTRAINT [' + name + '] CHECK ' + definition FROM sys.check_constraints WHERE OBJECT_NAME(parent_object_id) = @TableName */ set @sql= ' use '+@DBName+' SELECT DISTINCT PKObject = cco.object_id FROM sys.key_constraints cco JOIN sys.index_columns cc ON cco.parent_object_id = cc.object_id AND cco.unique_index_id = cc.index_id JOIN sys.indexes i ON cc.object_id = i.object_id AND cc.index_id = i.index_id join sys.schemas s on cco.schema_id=s.schema_id and s.name=@schema WHERE OBJECT_NAME(parent_object_id) = @TableName AND i.type = 1 AND is_primary_key = 1 ' print @sql INSERT INTO @PKObjectID(ObjectID) exec sp_executesql @sql, N'@TableName varchar(50),@schema varchar(50)', @TableName=@TableName,@schema=@schema /* SELECT DISTINCT PKObject = cco.object_id FROM sys.key_constraints cco JOIN sys.index_columns cc ON cco.parent_object_id = cc.object_id AND cco.unique_index_id = cc.index_id JOIN sys.indexes i ON cc.object_id = i.object_id AND cc.index_id = i.index_id WHERE OBJECT_NAME(parent_object_id) = @TableName AND i.type = 1 AND is_primary_key = 1 */ set @sql= ' use '+@DBName+' SELECT DISTINCT PKObject = cco.object_id FROM sys.key_constraints cco JOIN sys.index_columns cc ON cco.parent_object_id = cc.object_id AND cco.unique_index_id = cc.index_id JOIN sys.indexes i ON cc.object_id = i.object_id AND cc.index_id = i.index_id join sys.schemas s on cco.schema_id=s.schema_id and s.name=@schema WHERE OBJECT_NAME(parent_object_id) = @TableName AND i.type = 2 AND is_primary_key = 0 AND is_unique_constraint = 1 ' print @sql INSERT INTO @Uniques(ObjectID) exec sp_executesql @sql, N'@TableName varchar(50),@schema varchar(50)', @TableName=@TableName,@schema=@schema /* SELECT DISTINCT PKObject = cco.object_id FROM sys.key_constraints cco JOIN sys.index_columns cc ON cco.parent_object_id = cc.object_id AND cco.unique_index_id = cc.index_id JOIN sys.indexes i ON cc.object_id = i.object_id AND cc.index_id = i.index_id WHERE OBJECT_NAME(parent_object_id) = @TableName AND i.type = 2 AND is_primary_key = 0 AND is_unique_constraint = 1 */ SET @ClusteredPK = CASE WHEN @@ROWCOUNT > 0 THEN 1 ELSE 0 END declare @t TableType insert @t select * from @PKObjectID declare @u TableType insert @u select * from @Uniques set @sql= ' use '+@DBName+' SELECT distinct '',CONSTRAINT '' + @NewTableName+''_''+replace(cco.name,@TableName,'''') + CASE type WHEN ''PK'' THEN '' PRIMARY KEY '' + CASE WHEN pk.ObjectID IS NULL THEN '' NONCLUSTERED '' ELSE '' CLUSTERED '' END WHEN ''UQ'' THEN '' UNIQUE '' END + CASE WHEN u.ObjectID IS NOT NULL THEN '' NONCLUSTERED '' ELSE '''' END + ''(''+REVERSE(SUBSTRING(REVERSE(( SELECT c.name + + CASE WHEN cc.is_descending_key = 1 THEN '' DESC'' ELSE '' ASC'' END + '','' FROM sys.key_constraints ccok LEFT JOIN sys.index_columns cc ON ccok.parent_object_id = cc.object_id AND cco.unique_index_id = cc.index_id LEFT JOIN sys.columns c ON cc.object_id = c.object_id AND cc.column_id = c.column_id LEFT JOIN sys.indexes i ON cc.object_id = i.object_id AND cc.index_id = i.index_id WHERE i.object_id = ccok.parent_object_id AND ccok.object_id = cco.object_id order by key_ordinal FOR XML PATH(''''))), 2, 8000)) + '')'' FROM sys.key_constraints cco inner join sys.schemas s on cco.schema_id=s.schema_id and s.name=@schema LEFT JOIN @U u ON cco.object_id = u.objectID LEFT JOIN @t pk ON cco.object_id = pk.ObjectID WHERE OBJECT_NAME(cco.parent_object_id) = @TableName ' print @sql INSERT INTO @Definition(FieldValue) exec sp_executesql @sql, N'@TableName varchar(50),@NewTableName varchar(50),@schema varchar(50),@t TableType readonly,@u TableType readonly', @TableName=@TableName,@NewTableName=@NewTableName,@schema=@schema,@t=@t,@u=@u /* SELECT ',CONSTRAINT ' + name + CASE type WHEN 'PK' THEN ' PRIMARY KEY ' + CASE WHEN pk.ObjectID IS NULL THEN ' NONCLUSTERED ' ELSE ' CLUSTERED ' END WHEN 'UQ' THEN ' UNIQUE ' END + CASE WHEN u.ObjectID IS NOT NULL THEN ' NONCLUSTERED ' ELSE '' END + '(' +REVERSE(SUBSTRING(REVERSE(( SELECT c.name + + CASE WHEN cc.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END + ',' FROM sys.key_constraints ccok LEFT JOIN sys.index_columns cc ON ccok.parent_object_id = cc.object_id AND cco.unique_index_id = cc.index_id LEFT JOIN sys.columns c ON cc.object_id = c.object_id AND cc.column_id = c.column_id LEFT JOIN sys.indexes i ON cc.object_id = i.object_id AND cc.index_id = i.index_id WHERE i.object_id = ccok.parent_object_id AND ccok.object_id = cco.object_id FOR XML PATH(''))), 2, 8000)) + ')' FROM sys.key_constraints cco LEFT JOIN @PKObjectID pk ON cco.object_id = pk.ObjectID LEFT JOIN @Uniques u ON cco.object_id = u.objectID WHERE OBJECT_NAME(cco.parent_object_id) = @TableName */ END INSERT INTO @Definition(FieldValue) VALUES(')') set @sql= ' use '+@DBName+' select '' on '' + d.name + ''([''+c.name+''])'' from sys.tables t join sys.indexes i on(i.object_id = t.object_id and i.index_id < 2) join sys.index_columns ic on(ic.partition_ordinal > 0 and ic.index_id = i.index_id and ic.object_id = t.object_id) join sys.columns c on(c.object_id = ic.object_id and c.column_id = ic.column_id) join sys.schemas s on t.schema_id=s.schema_id join sys.data_spaces d on i.data_space_id=d.data_space_id where t.name=@TableName and s.name=@schema order by key_ordinal ' print 'x' print @sql INSERT INTO @Definition(FieldValue) exec sp_executesql @sql, N'@TableName varchar(50),@schema varchar(50)', @TableName=@TableName,@schema=@schema IF @IncludeIndexes = 1 BEGIN set @sql= ' use '+@DBName+' SELECT distinct '' CREATE '' + i.type_desc + '' INDEX ['' + replace(i.name COLLATE SQL_Latin1_General_CP1_CI_AS,@TableName,@NewTableName) + ''] ON '+@DBName+'.'+@NewTableSchema+'.'+@NewTableName+' ('' + REVERSE(SUBSTRING(REVERSE(( SELECT name + CASE WHEN sc.is_descending_key = 1 THEN '' DESC'' ELSE '' ASC'' END + '','' FROM sys.index_columns sc JOIN sys.columns c ON sc.object_id = c.object_id AND sc.column_id = c.column_id WHERE t.name=@TableName AND sc.object_id = i.object_id AND sc.index_id = i.index_id and is_included_column=0 ORDER BY key_ordinal ASC FOR XML PATH('''') )), 2, 8000)) + '')''+ ISNULL( '' include (''+REVERSE(SUBSTRING(REVERSE(( SELECT name + '','' FROM sys.index_columns sc JOIN sys.columns c ON sc.object_id = c.object_id AND sc.column_id = c.column_id WHERE t.name=@TableName AND sc.object_id = i.object_id AND sc.index_id = i.index_id and is_included_column=1 ORDER BY key_ordinal ASC FOR XML PATH('''') )), 2, 8000))+'')'' ,'''')+'''' FROM sys.indexes i join sys.tables t on i.object_id=t.object_id join sys.schemas s on t.schema_id=s.schema_id AND CASE WHEN @ClusteredPK = 1 AND is_primary_key = 1 AND i.type = 1 THEN 0 ELSE 1 END = 1 AND is_unique_constraint = 0 AND is_primary_key = 0 where t.name=@TableName and s.name=@schema ' print @sql INSERT INTO @Definition(FieldValue) exec sp_executesql @sql, N'@TableName varchar(50),@NewTableName varchar(50),@schema varchar(50), @ClusteredPK bit', @TableName=@TableName,@NewTableName=@NewTableName,@schema=@schema,@ClusteredPK=@ClusteredPK END /* SELECT 'CREATE ' + type_desc + ' INDEX [' + [name] COLLATE SQL_Latin1_General_CP1_CI_AS + '] ON [' + OBJECT_NAME(object_id) + '] (' + REVERSE(SUBSTRING(REVERSE(( SELECT name + CASE WHEN sc.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END + ',' FROM sys.index_columns sc JOIN sys.columns c ON sc.object_id = c.object_id AND sc.column_id = c.column_id WHERE OBJECT_NAME(sc.object_id) = @TableName AND sc.object_id = i.object_id AND sc.index_id = i.index_id ORDER BY index_column_id ASC FOR XML PATH('') )), 2, 8000)) + ')' FROM sys.indexes i WHERE OBJECT_NAME(object_id) = @TableName AND CASE WHEN @ClusteredPK = 1 AND is_primary_key = 1 AND type = 1 THEN 0 ELSE 1 END = 1 AND is_unique_constraint = 0 AND is_primary_key = 0 */ INSERT INTO @MainDefinition(FieldValue) SELECT FieldValue FROM @Definition ORDER BY DefinitionID ASC ---------------------------------- --SELECT FieldValue+'' FROM @MainDefinition FOR XML PATH('') set @script='use '+@DBName+' '+(SELECT FieldValue+'' FROM @MainDefinition FOR XML PATH('')) --declare @q varchar(max) --set @q=(select replace((SELECT FieldValue FROM @MainDefinition FOR XML PATH('')),'</FieldValue>','')) --set @script=(select REPLACE(@q,'<FieldValue>','')) --drop type TableType END try -- ############################################################################################################################################################################## BEGIN CATCH BEGIN -- INIZIO Procedura in errore ========================================================================================================================================================= PRINT '***********************************************************************************************************************************************************' PRINT 'ErrorNumber : ' + CAST(ERROR_NUMBER() AS NVARCHAR(MAX)) PRINT 'ErrorSeverity : ' + CAST(ERROR_SEVERITY() AS NVARCHAR(MAX)) PRINT 'ErrorState : ' + CAST(ERROR_STATE() AS NVARCHAR(MAX)) PRINT 'ErrorLine : ' + CAST(ERROR_LINE() AS NVARCHAR(MAX)) PRINT 'ErrorMessage : ' + CAST(ERROR_MESSAGE() AS NVARCHAR(MAX)) PRINT '***********************************************************************************************************************************************************' -- FINE Procedura in errore ========================================================================================================================================================= END set @script='' return -1 END CATCH -- ##############################################################################################################################################################################выполнить его:
declare @s varchar(max) exec [util_ScriptTable] 'db','schema_source','table_source',1,1,'schema_dest','tab_dest',0,@s output select @sqaru.site
mysql - Как экспортировать базу данных SQL Server в MySQL?
Как уже упоминалось выше, если ваши данные содержат символы табуляции, запятые или новые строки в ваших данных, тогда будет очень сложно экспортировать и импортировать его с помощью CSV. Значения будут переполнены из полей, и вы получите ошибки. Эта проблема еще хуже, если любое из ваших длинных полей содержит многострочный текст с символами новой строки.
Мой метод в этих случаях - использовать служебную программу командной строки BCP для экспорта данных с SQL-сервера, а затем использовать команду LOAD DATA INFILE.. INTO TABLE в MySQL для чтения файла данных. BCP является одним из самые старые утилиты командной строки SQL Server (начиная с рождения SQL Server - v6.5), но он по-прежнему остается одним из самых простых и надежных способов получения данных.
Чтобы использовать этот метод, вам нужно создать каждую таблицу назначения с той же или эквивалентной схемой в MySQL. Я делаю это, щелкнув правой кнопкой мыши базу данных в SQL-менеджере предприятия, затем Tasks- > Generate Scripts... и создав SQL script для всех таблиц. Затем вы должны преобразовать script в MySQL совместимый SQL вручную (определенно, самую худшую часть задания) и, наконец, запустить команды CREATE TABLE в базе данных MySQL, чтобы у вас были сопоставленные таблицы с версиями SQL Server по столбцам, пустыми и готов к данным.
Затем экспортируйте данные со стороны MS-SQL следующим образом.
bcp DatabaseName..TableName out TableName.dat -q -c -T -S ServerName -r \0 -t !\t!(Если вы используете SQL Server Express, используйте значение -S так: -S "ComputerName\SQLExpress" )
Это создаст файл с именем TableName.dat с полями, разделенными на! [tab]! и строки, ограниченные символами \0 NUL.
Теперь скопируйте файлы .dat в /tmp на сервере MySQL и загрузите на стороне MySQL так:
LOAD DATA INFILE '/tmp/TableName.dat' INTO TABLE TableName FIELDS TERMINATED BY '!\t!' LINES TERMINATED BY '\0';Не забывайте, что таблицы (TableName в этом примере) должны быть созданы уже на стороне MySQL.
Эта процедура очень болезненно ручна, когда дело доходит до преобразования схемы SQL, но она работает даже для самых сложных данных, и поскольку она использует плоские файлы, вам никогда не нужно убеждать SQL Server говорить с MySQL или наоборот.
qaru.site
Экспорт таблиц MS SQL Server 2000/2005/2008 в XML файл / Хабр
Здравствуйте, уважаемое хабрасообщество !
Поговорим о проблеме, ставшей заголовком этой темы.Постановка:
Необходимость вывода таблицы на сервере в XML файл нужной кодировки для дальнейших нужд (анализ, включение XML в другие компоненты и приложения и т.п.). Будем использовать bat-сценарий.Возникшие трудности
Отсутствие поддержки экспорта в различные кодировки средствами MS SQL.SQL Server не сохраняет кодировку XML, если XML-данные постоянно хранятся в базе данных. Поэтому оригинальная кодировка полей XML недоступна при экспорте XML-данных. Для экспорта данных SQL Server использует кодировку UTF-16. © Простота и скорость использования для различных таблиц и баз.Шаги реализации
Для начала, воспользуемся утилитой bcp, которая входит в комплект поставки MS SQL Server (Даже в Express версии). Подробрее. Из ее возможностей нам понадобится только вывод результата запроса в файл. Значения ключей на примере:bcp "SELECT * FROM DB.SCHEMA.TABLE FOR XML AUTO, ROOT('ROOT')" queryout temp.xml -w -S %SERVERNAME% -U %DBUSER% -P %DBPASS%Описание команды:
SELECT запрос для выборки всех данных из таблицы (указывается полное имя).XML AUTO отвечает за преобразование результата в XML дерево.ROOT назначает корневой элемент в этом дереве queryout задает выходной файл-w задает использование юникода для массового копирования-S имя экземпляра сервера-P пароль-U пользователь
Этой командой мы получим XML файл БЕЗ заголовка в кодировке UTF-16. Нужно присоединить заголовок и сделать xml нужной кодировки. Создадим шаблон заголовка xml_header.xml с содержимым:
<?xml version="1.0" encoding="Windows-1251"?>* This source code was highlighted with Source Code Highlighter.
Теперь достаточно будет выполнить команду copy xml_header.xml + bcp_out.xml result.xml и получить валидный XML документ.
Для преобразования кодировки же будем использовать iconv, любой реализации. Я выбрал самое компактное и портативное решение под Windows, написанное на Win32 API от Yukihiro Nakadaira.
Итак, файл сценария:
@echo offif "%1" == "" (rem Отсутстуют параметры echo Use with: db_name db_table [out_file]exit /b 1 )
if "%2" == "" ( echo Use with: db_name db_table [out_file]exit /b 1 )
rem Читаем настройки из файла settings.txt, который должен располагаться вrem том же каталоге, что и bat-файл. Если не удалось распарсить настройки -rem выходим с ненулевым кодом возврата.call :read_settings %~dp0settings.txt || exit /b 1
set DBNAME=%1set DBTABLE=%2set OUTFILE=%3
echo; echo ====== ECHO SETTINGS FROM CONFIG ====== echo; echo ServerName : %SERVERNAME% echo Schema : %SCHEMA% echo Out codepage: %OUTCP% echo User : %DBUSER% echo Pass : ******** echo Iconv path : %ICONVPATH% echo; echo ======================================= echo; echo ====== ECHO SETTINGS FROM CMD ========= echo; echo DB Name = %1 echo DB Table = %2 echo Output file = %3 echo; echo ======================================= echo; echo ====== CALL TO BCP UTIL =============== echo;call :bcp_call echo; echo ====== CALL TO ICONV ================== echo;call :iconv_call echo; echo ======================================= echo; echo See the log\log.txt for detailsexit /b 0
remrem Функция для чтения настроек из файла.rem Вход:rem %1 - Имя файла с настройками :read_settings
set SETTINGSFILE=%1
rem Проверка существования файлаif not exist %SETTINGSFILE% ( echo FAIL: No such file %SETTINGSFILE% exit /b 1 )
rem Обработка файла c настройками
for /f "eol=# delims== tokens=1,2" %%i in (%SETTINGSFILE%) do ( set %%i=%%j )
exit /b 0
rem rem Функция для обращения к БД :bcp_call
bcp "SELECT * FROM %DBNAME%.%SCHEMA%.%DBTABLE% FOR XML AUTO, ROOT('%DBTABLE%')" queryout temp.xml -w -r "" -S %SERVERNAME% -U %DBUSER% -P %DBPASS% > log\rawlog.txt
rem Кодируем лог в нормальную кодировку %ICONVPATH% -f cp866 -t cp1251 log\rawlog.txt > log\log.txt del log\rawlog.txt
copy lib\xml_header.xml + temp.xml temp2.xml > nul del temp.xml
echo Finished.
exit /b 0
rem rem Функция перекодировки :iconv_call
rem Дефолтное значение выходной кодировкиif "%OUTCP%" == "" ( set OUTCP=CP1251 )
rem Дефолтное значение выходного файлаif "%OUTFILE%" == "" ( set OUTFILE=out\%DBTABLE%.xml )
if not exist %ICONVPATH% ( echo FAIL: Check Iconv path ! exit /b /1 )
%ICONVPATH% -f UTF-16 -t %OUTCP% temp2.xml > %OUTFILE% del temp2.xml
echo Finished.
exit /b 0
* This source code was highlighted with Source Code Highlighter.
Через параметры командной строки передаем: имя_базы имя_таблицы [выходной файл] Остальную конфигурацию прописываем в settings.txt:
# Имя сервера SERVERNAME=WIND\SQLEXPRESS # Имя схемы SCHEMA=dbo # Имя выходной кодировки OUTCP=CP1251
# Имя пользователя DBUSER=dzhon # Пароль пользователя DBPASS=123
#Путь к iconv.exe ICONVPATH=lib\win_iconv.exe
Для логики, в XML файле создано 3 функции. Первая парсит конфигурацию, вторая вызывает bcp, третья — iconv для результирующего файла.
Заключение
Сразу замечу, что по-умолчанию используется CP1251 и лог работы bcp кодируется в нее же. Сделано это для удобства работы именно в Windows, а не каких-то иных религиозных предпочтений. Помню времена, когда Windows XP выдавала крокозябры при вызове простого route PRINT в описаниях интерфейсов… Поэтому я сам и предпочитаю всегда и везде UTF-8. Впрочем, скрипт достаточно гибок к замене кодировки выхода, правда придется задать в xml_header.xml другое значение.Скачать архив с рабочим вариантом решения можно здесь (13 Кб).
Для SQL Server 2000 придется внести некоторые изменения, в связи с тем, что понятие схемы (в смысле контейнера объектов) было введено только с 2005-го.
Вы можете также посмотреть материал по написанию bat файлов, из которого была утащена функция парсинга конфигурации.
Спасибо за внимание, надеюсь, кому-то поможет. Перенесу в тематический блог при наличии кармы, впрочем, решать вам.
habr.com
- Windows 10 контрольная точка восстановления

- Сбросить уровень чернил
- Как зарегистрироваться на электронную почту
- Как в виндовс 10 удалить папку windows old

- Как создать компьютерную программу

- Что значит выходное аудиоустройство не установлено

- Почему плагин адобе флеш плеер заблокирован

- Postgresql установка linux

- Как удалить сразу все письма в почте яндекс сразу

- Как бесплатно поставить касперского
- Компьютерная сеть включает в себя
