Ms sql покрывающий индекс: Для чего нужен покрывающий индекс? — Хабр Q&A
Содержание
sql server — Важен ли порядок при создании покрывающего индекса в Microsoft SQL?
Для начала предлагаю разобраться что такое покрывающий индекс, приведу выдержку из статьи на Хабре:
Зачем использовать покрывающий индекс взамен составного индекса?
Во-первых, давайте убедимся, что мы понимаем различие между ними.
Составной индекс это просто обычный индекс, в который включено больше одного столбца. Несколько ключевых столбцов может
использоваться для обеспечения уникальности каждой строки таблицы,
также возможен вариант, когда первичный ключ состоит из нескольких
столбцов, обеспечивающих его уникальность, или вы пытаетесь
оптимизировать выполнение часто вызываемых запросов к нескольким
столбцам. В общем, однако, чем больше ключевых столбцов содержит
индекс, тем менее эффективна работа этого индекса, а значит составные
индексы стоит использовать разумно.Как было сказано, запрос может извлечь огромную выгоду, если все необходимые данные сразу расположены на листьях индекса, как и сам
индекс.Это не проблема для кластеризованного индекса, т.к. все данные
уже там (вот почему так важно хорошенько подумать когда вы создаете
кластеризованный индекс). Но некластеризованный индекс на листьях
содержит только ключевые столбцы. Для доступа ко всем остальным данным
оптимизатору запросов необходимы дополнительные шаги, что может
вызвать значительные дополнительные накладные расходы для выполнения
ваших запросов.Вот где покрывающий индекс спешит на помощь.
Когда вы определяете некластеризованный индекс, то можете указать
дополнительные столбцы к вашим ключевым.
 Это не проблема для кластеризованного индекса, т.к. все данные
Это не проблема для кластеризованного индекса, т.к. все данныеТаким образом покрывающий индекс не должен содержать все выбираемые столбцы запроса в структуре дерева индекса, а только те, которые будут использованы для фильтрации или группировки данных в запросе, остальные столбцы из секции SELECT должны быть помещены в INCLUDE раздел индекса.
Возможно вам будет полезен ответ из другого вопроса на StackOverflow
В приведенном примере использован составной индекс из 3 полей, а не покрывающий индекс, код для создания покрывающего индекса будет выглядеть следующим образом:
CREATE NONCLUSTERED INDEX [ix_Customer_Email] ON [dbo].
 [Customers] (
[Last_Name] ASC
)
INCLUDE ([First_Name], [Email_Address])
WITH (PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON
)
ON [PRIMARY]
[Customers] (
[Last_Name] ASC
)
INCLUDE ([First_Name], [Email_Address])
WITH (PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON
)
ON [PRIMARY]
для покрывающего индекса порядок столбцов в секции INCLUDE не важен, но важен порядок столбцов для составного индекса, т.к. данные колонок помещаются в дерево индекса по порядку перечисления столбцов и оптимизатор запроса не сможет использовать индекс из 2 колонок для поиска значений только 2 колонки. Наглядный пример того, как будет выглядеть структура индекса из 2 колонок (EMPLOYEE_ID, SUBSIDIARY_ID) вы можете увидеть на рисунке:
Рисунок заимствован из англоязычной статьи про составные индексы за авторством Markus Winand
sql — Должен ли покрывающий индекс включать в себя primary key?
База данных Postgresql (хотя мне кажется, это не должно влиять).

Это критично важная вещь для любых вопросов производительности.
Индексы в postgresql хранят ссылки на физический адрес строки в датафайлах — TID. Поэтому значения первичного ключа не имеют значения и включение полей первичного ключа в индекс без необходимости в этом даже сделают хуже — индекс будет больше занимать места, а значит больше данных будет читаться и писаться на диски, больше памяти занимать в shared_buffers и page cache системы.
Будет ли он помогать, в случаях, если использоваться будут запросы: select count() from A where a = :a и select count() from A where b = :b
Зависит от типа индекса. Ответ на первый вопрос — да, возможен быть абстрактным для актуальных версий базы. Ответ на этот второй вопрос придётся рассматривать в отдельности для разных типов индексов.
btree— то, что обычно подразумевают и тип используемый по-умолчанию вcreate index. Это дерево, вы не сможете нормально произвести поиск по дереву, если вы не можете начинать от его корня. Поэтому btree(a,b)может ускорить запрос с условием по a, но для условия только по b будет неэффективен — вам придётся просмотреть весь индекс полностью вместо его части.brin— этому типу индекса не важен порядок участвующих полей.brin(a,b)может использоваться и дляa = ?и дляb = ?hash— ну, с этим проще, он просто не умеет многоколоночные индексы.gin/gistнемного не о том, и не поддерживают простые типы сами по себе. С расширениямиbtree_gin/btree_gistуже возможно построить, но в целом gist и gin это хорошая тема под отдельное сочинение.
 Поэтому
Поэтому Немаловажные ещё есть два момента:
- только
btreeможет быть сейчас покрывающим индексом - даже покрывающий
btreeне гарантирует, что таблица читаться не будет. Наоборот, он может гарантировать только то, что, возможно, некоторые блоки этой таблицы читать не придётся.

Такая на первый взгляд странная картина объясняется реализацией механизма MVCC. Индекс хранит только данные и ссылку на строку, но не хранит данные о транзакционной видимости этой строки. Поэтому каждую строку результата поиска по индексу необходимо проверить, а видна ли эта строка текущей транзакции. Суть index only scan в реализации postgresql — это возможность пропустить проверку видимости транзакции (и не читать блок данных с таблицы), если для этого блока проставлен бит видимости для всех транзакций в visibility map. Эту битовую карту обновляет autovacuum либо ручной vacuum и потому это ещё одна причина, почему для хорошей работы postgresql необходимо настраивать autovacuum на более интенсивную работу. Конфиг из коробки — не для работы, а чтобы запуститься где угодно и никому не мешать.
Если visibility map не говорит, что блок виден всем — то базе необходимо прочитать эту часть таблицы и проверить нужные строки. Для активно обновляемых и сильно скоррелированных данных может не быть смысла в покрывающем индексе вовсе.
Для активно обновляемых и сильно скоррелированных данных может не быть смысла в покрывающем индексе вовсе.
count же для MVCC базы вообще жутко неудобная вещь. Для вас это простая циферка, для базы — проверить каждую версию строки в отдельности, видна ли она вам.
Использование покрывающих индексов для повышения производительности запросов
Разработчики систем баз данных часто предполагают, что использование кластеризованного индекса всегда является лучшим подходом. Однако некластеризованный покрывающий индекс обычно обеспечивает оптимальную производительность запроса.
Введение
Существует множество способов измерения производительности базы данных. Мы можем посмотреть на его общую доступность; то есть: могут ли наши пользователи получать нужную им информацию, когда они в ней нуждаются? Мы можем рассмотреть его параллелизм; сколько пользователей могут запрашивать базу данных одновременно? Мы даже можем наблюдать за количеством транзакций, которые происходят в секунду, чтобы оценить уровень активности.
Однако часто для наших пользователей все сводится к одному очень простому, но несколько туманному измерению — воспринимаемой отзывчивости. Или, другими словами, когда пользователь выдает запрос, получает ли он свои результаты, не дожидаясь слишком долго?
Конечно, на это влияет множество факторов. Есть само оборудование и то, как оно настроено. Имеется физическая реализация базы данных; логическая структура базы данных; и даже как пишутся сами запросы.
Однако в этой статье я сосредоточусь на одном конкретном методе, который можно использовать для повышения производительности — создании покрывающих индексов.
Напоминание об индексировании
Прежде чем приступить к изучению индексов, давайте уделим немного времени краткому, но очень актуальному обзору типов индексов и терминологии.
Индексы позволяют SQL Server быстро находить строки в таблице на основе значений ключей, подобно индексу книги, позволяющему нам легко находить страницы, содержащие нужную нам информацию. В SQL Server существует два типа индексов: кластеризованные и некластеризованные индексы.
В SQL Server существует два типа индексов: кластеризованные и некластеризованные индексы.
Кластеризованные индексы
Кластеризованный индекс — это индекс, конечные узлы которого, то есть самый низкий уровень индекса, содержат фактические страницы данных базовой таблицы. Следовательно, указатель и сама таблица для всех практических целей являются одним и тем же. Каждая таблица может иметь только один кластеризованный индекс. Дополнительные сведения о кластерных индексах см. в электронной документации в разделе «Структуры кластеризованных индексов» (http://msdn.microsoft.com/en-us/library/ms177443.aspx).
Когда кластерный индекс используется для разрешения запроса, SQL Server начинает с корневого узла для индекса и проходит через промежуточные узлы, пока не найдет страницу данных, содержащую искомую строку.
Во многих проектах баз данных активно используются кластеризованные индексы. На самом деле, обычно считается лучшей практикой включать кластеризованный индекс в каждую таблицу; конечно, это рисование очень широкой кистью, и наверняка будут исключения.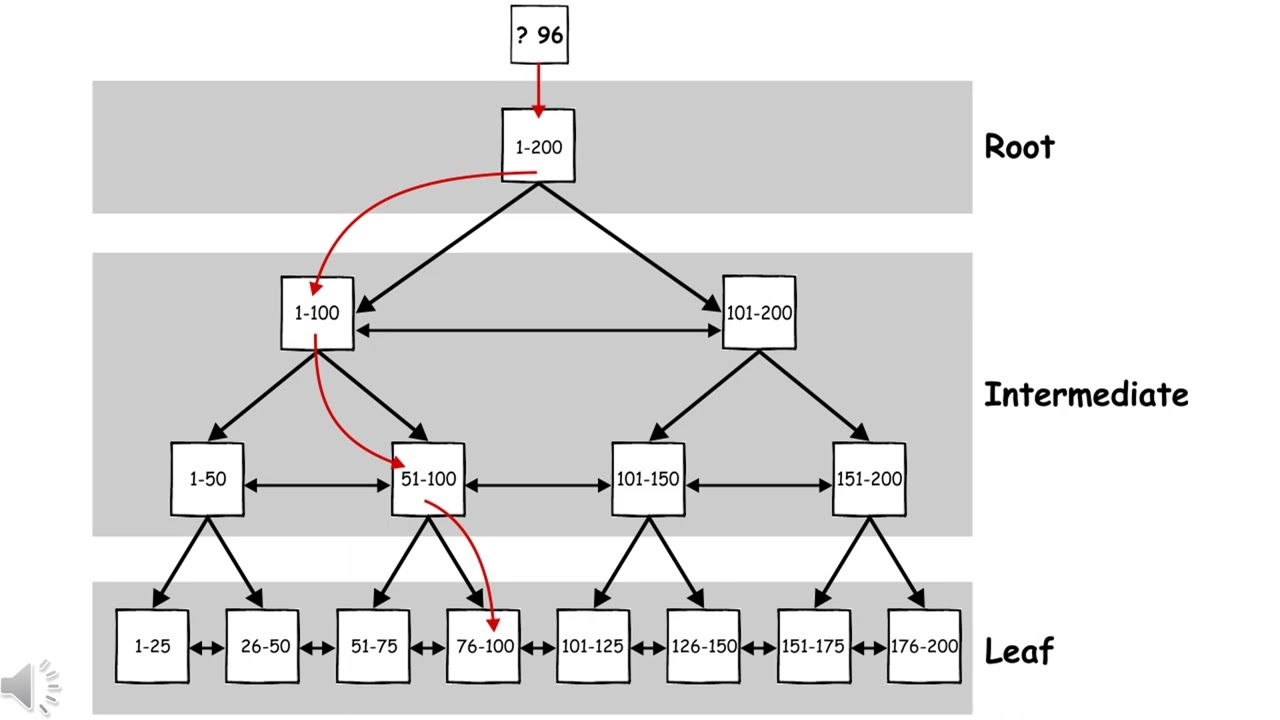 Дополнительные сведения о преимуществах кластерных индексов см. в статье с рекомендациями по использованию SQL Server, озаглавленной «Сравнение таблиц, организованных с помощью кластеризованных индексов и кучи» на сайте TechNet.
Дополнительные сведения о преимуществах кластерных индексов см. в статье с рекомендациями по использованию SQL Server, озаглавленной «Сравнение таблиц, организованных с помощью кластеризованных индексов и кучи» на сайте TechNet.
Рассмотрим пример. На рисунке 1 таблица Customers имеет кластеризованный индекс, определенный для столбца Customer_ID. Когда выполняется запрос, выполняющий поиск по столбцу Customer_ID, SQL Server перемещается по кластеризованному индексу, чтобы найти нужную строку, и возвращает данные. Это можно увидеть в операции Clustered Index Seek в плане выполнения запроса.
Рис. 1. План выполнения кластеризованного индекса
Следующая инструкция Transact-SQL использовалась для создания кластеризованного индекса для столбца Customer_ID.
СОЗДАТЬ КЛАСТЕРНЫЙ ИНДЕКС [ix_Customer_ID] ON [dbo].[Customers] ( [Customer_ID] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_ NORECOMPUTE = ВЫКЛ, SORT_IN_TEMPDB = ВЫКЛ, IGNORE_DUP_KEY = ВЫКЛ, DROP_EXISTING = ВЫКЛ, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] |
Некластеризованные индексы
Некластеризованные индексы используют аналогичную методологию для хранения индексированных данных для таблиц в SQL Server.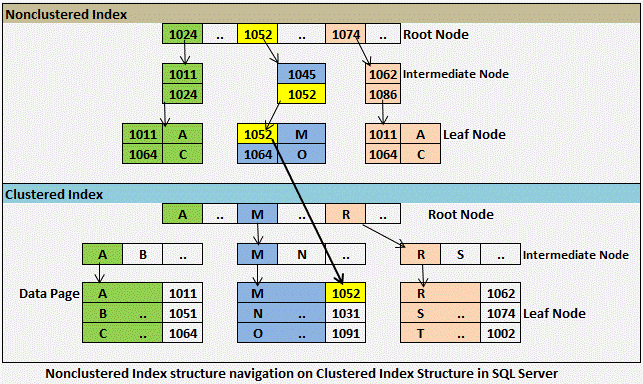 Однако в некластеризованном индексе самый низкий уровень индекса не содержит страницы данных таблицы. Вместо этого он содержит информацию, которая позволяет SQL Server переходить к нужным страницам данных. Для таблиц с кластеризованным индексом конечный узел некластеризованного индекса содержит ключи кластеризованного индекса. В предыдущем примере конечный узел некластеризованного индекса таблицы Customers будет содержать ключ Customer_ID.
Однако в некластеризованном индексе самый низкий уровень индекса не содержит страницы данных таблицы. Вместо этого он содержит информацию, которая позволяет SQL Server переходить к нужным страницам данных. Для таблиц с кластеризованным индексом конечный узел некластеризованного индекса содержит ключи кластеризованного индекса. В предыдущем примере конечный узел некластеризованного индекса таблицы Customers будет содержать ключ Customer_ID.
Если базовая таблица не имеет кластеризованного индекса (эта структура данных называется кучей), конечный узел некластеризованного индекса содержит локатор строк для страниц данных кучи.
В следующем примере для таблицы Customers создан некластеризованный составной индекс, как описано в следующем коде Transact-SQL.
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС [ix_Customer_Name] ON [dbo].[Customers] ( [Last_Name] ASC, [First_Name] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) НА [ПЕРВИЧНЫЙ] |
В этом случае, когда выполнялся запрос с поиском по фамилии клиента, оптимизатор запросов SQL Server решил использовать индекс ix_Customer_Name для разрешения запроса. Это можно увидеть в плане выполнения на следующем рисунке.
Это можно увидеть в плане выполнения на следующем рисунке.
Рисунок 2 . План выполнения некластеризованного индекса
Дополнительные сведения о кластеризованных индексах см. в электронной документации в разделе «Структуры некластеризованных индексов».
Использование некластеризованных индексов
Как показано в предыдущем примере, некластеризованные индексы могут использоваться для обеспечения SQL Server эффективным способом извлечения строк данных. Однако при некоторых обстоятельствах накладные расходы, связанные с некластеризованными индексами, могут быть сочтены оптимизатором запросов слишком большими, и SQL Server прибегает к сканированию таблицы для разрешения запроса. Чтобы понять, как это может произойти, давайте более подробно рассмотрим предыдущий пример.
Key Lookups
Взглянув еще раз на графический план выполнения запроса, изображенный на рис. 2, обратите внимание, что план включает не только операцию Index Seek, которая использует некластеризованный индекс ix_Customer_Name , но и операцию Key Lookup.
SQL Server использует поиск по ключу для извлечения неключевых данных со страницы данных, когда для разрешения запроса используется некластеризованный индекс. То есть после того, как SQL Server использовал некластеризованный индекс для идентификации каждой строки, соответствующей критериям запроса, он должен извлечь информацию о столбцах для этих строк со страниц данных таблицы.
Поскольку конечный узел некластеризованного индекса содержит информацию о значении ключа для строки, SQL Server должен перемещаться по кластеризованному индексу, чтобы получить информацию о столбцах для каждой строки результирующего набора. В этом примере SQL Server выбрал для этого тип соединения с вложенным циклом.
Этот запрос дал результат в 1000 строк, и почти 100 % затрат на запрос были непосредственно связаны с операцией поиска ключа. Углубившись в операцию Key Lookup, мы можем понять, почему.
Рисунок 3. Свойства операции поиска ключа
Эта операция поиска ключа была выполнена 1000 раз, по одному разу для каждой строки набора результатов.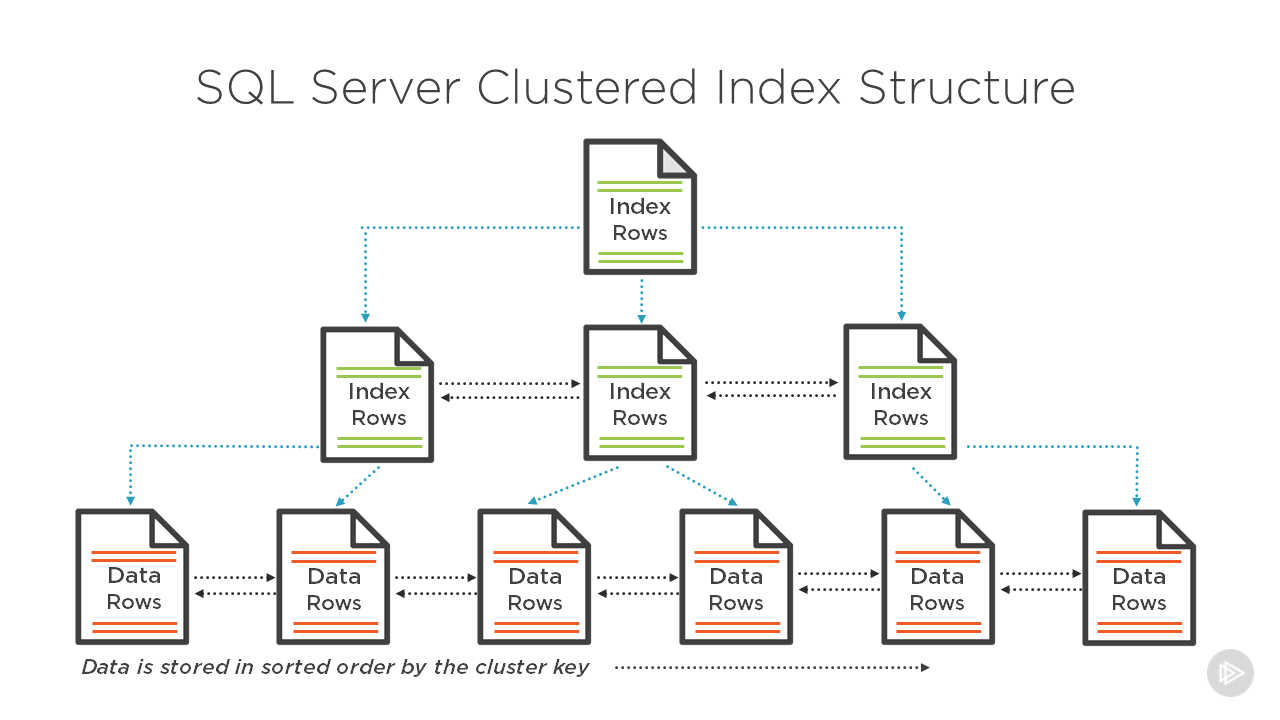
Использование сканирования таблиц
По мере увеличения количества строк в результирующем наборе увеличивается и количество поисковых запросов по ключу. В какой-то момент затраты, связанные с поиском ключа, перевесят любые преимущества, обеспечиваемые некластеризованным индексом.
Чтобы проиллюстрировать это, давайте изменим запрос, чтобы он извлекал больше строк. Рисунок 4. изображает новый запрос вместе с фактическим планом выполнения, используемым для разрешения запроса.
Рисунок 4. Использование сканирования таблицы
Новый запрос ищет диапазон клиентов, чья фамилия находится между «Roland» и «Smith». В нашей базе их 69 000. Из фактического плана выполнения мы видим, что оптимизатор запросов определил, что накладные расходы на выполнение поиска по ключу для каждой из 69 000 строк превышают простой обход всей таблицы посредством сканирования таблицы. Следовательно, наш индекс ix_Customer_Name вообще не использовался во время запроса.
На рис. 5 показаны некоторые дополнительные свойства сканирования таблицы.
Рисунок 5. Свойства операции сканирования таблицы
Может возникнуть соблазн заставить SQL Server разрешить запрос с использованием некластеризованного индекса, предоставив табличную подсказку, как показано на следующем рисунке.
Рисунок 6. Использование табличной подсказки для разрешения запроса
Это почти всегда плохая идея, поскольку оптимизатор обычно хорошо справляется с выбором подходящего плана выполнения. Кроме того, оптимизатор основывает свои решения на статистике столбца; они, вероятно, изменятся со временем. Табличная подсказка, которая хорошо работает сегодня, может не работать в будущем, когда изменится селективность ключевых столбцов.
На рис. 7 показаны свойства поиска ключа, когда мы заставили SQL Server использовать некластеризованный индекс ix_Customer_Name. Расчетная стоимость оператора для поиска ключа составляет 57,02 по сравнению с 12,17 для сканирования кластеризованного индекса, показанного на рис.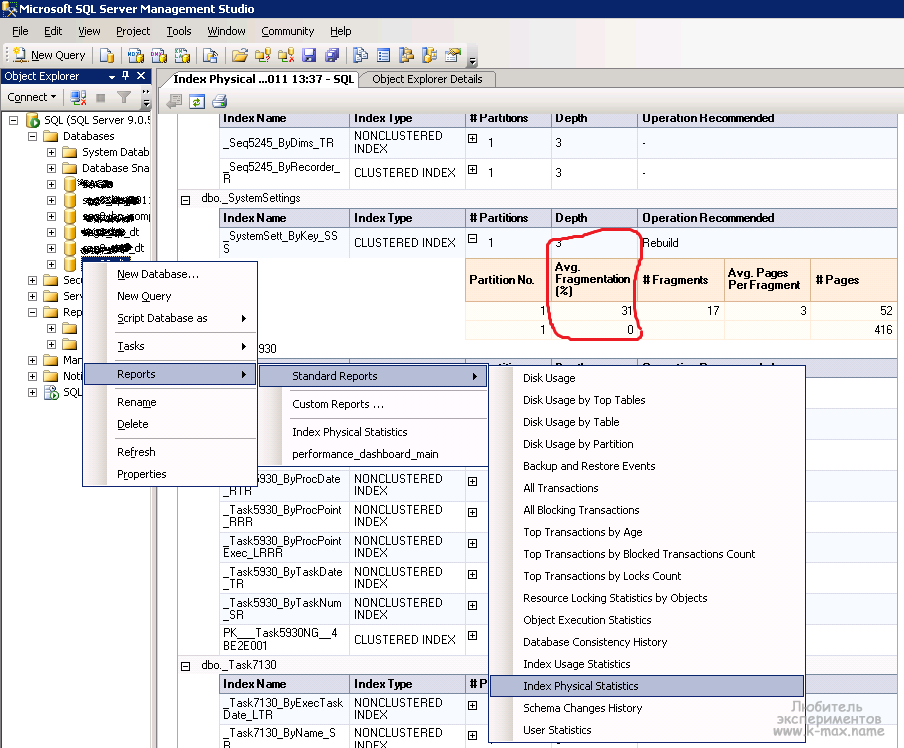 5. Принудительное использование индекса SQL Server значительно повлияло на производительность, и не в лучшую сторону!
5. Принудительное использование индекса SQL Server значительно повлияло на производительность, и не в лучшую сторону!
Рисунок 7 . Свойства поиска по ключу для таблицы hint
Покрывающие индексы
Итак, если поиск по ключу может отрицательно сказаться на производительности при разрешении запросов для больших наборов результатов, возникает естественный вопрос: как мы можем их избежать? Чтобы ответить на этот вопрос, давайте рассмотрим запрос, не требующий поиска ключа.
Давайте начнем с изменения нашего запроса, чтобы он больше не выбирал столбец Email_Address . На рис. 8 показан этот обновленный запрос вместе с его фактическим планом выполнения.
Рисунок 8 . Сокращен запрос для исключения поиска ключа
Новый план выполнения был упрощен и использует только некластеризованный индекс ix_Customer_Name . Глядя на свойства провайдеров операций, можно увидеть еще одно свидетельство улучшения. Свойства показаны на рисунке 9. .
.
Рис. 9. Уменьшенный запрос для устранения свойств поиска ключа
Расчетная стоимость оператора резко снизилась: с 12,17 на рис. 5 до 0,22 на рис. 9. STATISTICS IO включен, однако для этой демонстрации достаточно просмотреть затраты оператора для каждой операции.
Наблюдаемое улучшение связано с тем, что некластеризованный индекс содержал всю необходимую информацию для разрешения запроса. Поиск ключей не требовался. Индекс, который содержит всю информацию, необходимую для разрешения запроса, известен как «покрывающий индекс»; он полностью покрывает запрос.
Использование кластеризованного ключевого столбца
Напомним, что если таблица имеет кластеризованный индекс, эти ключевые столбцы автоматически становятся частью некластеризованного индекса. Таким образом, следующий запрос является покрывающим запросом по умолчанию.
Рисунок 10 . Покрытие индекса с использованием ключей кластеризованного индекса
Однако, если ваш кластеризованный индекс не содержит обязательных столбцов, чего нет в нашем примере, его будет недостаточно для покрытия нашего запроса.
Добавление ключевых столбцов в индекс
Чтобы повысить вероятность того, что некластеризованный индекс является покрывающим индексом, возникает соблазн начать добавлять дополнительные столбцы в ключ индекса. Например, если мы регулярно запрашиваем отчество и номер телефона клиента, мы можем добавить эти столбцы в индекс ix_Customer_Name. Или, чтобы продолжить наш предыдущий пример, мы могли бы добавить столбец Email_Address в индекс, как показано в следующем коде Transact-SQL.
1 2 3 4 5 6 | CREATE NONCLUSTERED INDEX [ix_Customer_Email] ON [dbo].[Customers] ( [Last_Name] ASC, [First _Name] ASC, [Email_Address] ASC )С (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] |
Прежде чем сделать это, важно помнить, что индексы должны поддерживаться SQL Server во время операций по обработке данных.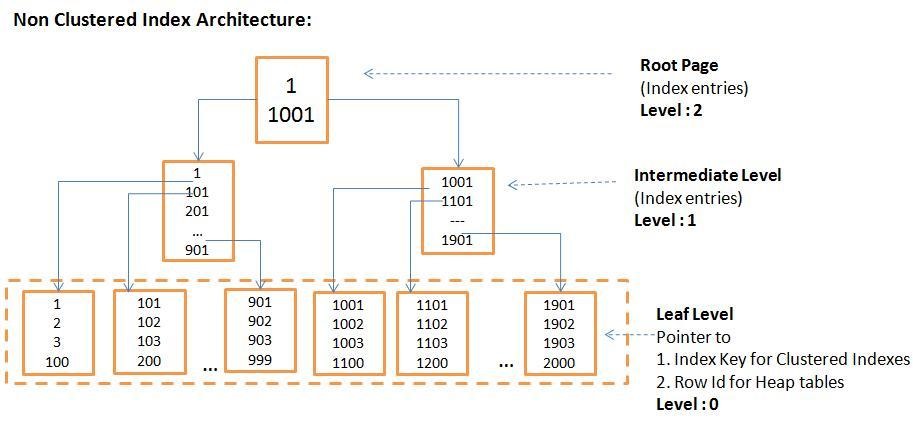 Слишком большое количество индексов снижает производительность во время операций записи. Кроме того, чем шире индекс, то есть чем больше байтов составляют ключи индекса, тем больше страниц данных потребуется для хранения индекса.
Слишком большое количество индексов снижает производительность во время операций записи. Кроме того, чем шире индекс, то есть чем больше байтов составляют ключи индекса, тем больше страниц данных потребуется для хранения индекса.
Кроме того, существуют некоторые встроенные ограничения для индексов. В частности, индексы ограничены 16 ключевыми столбцами или 900 байт, в зависимости от того, что наступит раньше, как в SQL Server 2005, так и в SQL Server 2008. Некоторые типы данных нельзя использовать в качестве ключей индекса, например, varchar(max) .
Включение неключевых столбцов
В SQL Server 2005 появилась новая функция для некластеризованных индексов — возможность включения дополнительных неключевых столбцов на конечный уровень некластеризованных индексов. Эти столбцы технически не являются частью индекса, однако они включены в конечный узел индекса. SQL Server 2005 и SQL Server 2008 позволяют включать до 1023 столбцов в конечный узел.
Чтобы создать некластеризованный индекс с включенными столбцами, используйте следующий синтаксис Transact-SQL.
1 2 3 4 5 6 | CREATE NONCLUSTERED INDEX [ix_Customer_Email] ON [dbo].[Customers] ( [Last_Name] ASC, [First _Name] ASC ) INCLUDE ([Email_Address]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] |
Повторное выполнение нашего запроса дает план выполнения, который использует наш новый индекс для быстрого возврата набора результатов. План выполнения показан на рис. 11.
. разрешить запрос без использования поиска ключа для каждой строки. С Индекс ix_CustomerEmail включает столбец Email_Address как часть своего определения, индекс «покрывает» запрос. Свойства оператора поиска по некластеризованному индексу подтверждают наши результаты, как показано на рисунке 12.
Рисунок 12. Свойства выполнения для покрывающего запроса с включенными столбцами
снизился с 12,17 на рис. 5 до 0,41. Включение дополнительного неключевого столбца значительно повысило производительность запроса.
Дополнительные сведения о включении неключевых столбцов в некластеризованный индекс см. в разделе «Индекс с включенными столбцами» в электронной документации.
Сводка
Включив часто запрашиваемые столбцы в некластеризованные индексы, мы можем значительно повысить производительность запросов за счет снижения затрат на ввод-вывод. Поскольку страницы данных для некластеризованного индекса часто легко доступны в памяти, покрывающие индексы обычно являются окончательным решением запросов.
sql server — как превратить некластеризованный индекс в покрывающий индекс
спросил
Изменено
4 года, 1 месяц назад
Просмотрено
295 раз
Я погуглил покрывающий индекс и нашел:
«Покрывающий индекс — это особый тип составного индекса, в котором присутствуют все столбцы индекса».
Я понимаю, что основная цель состоит в том, чтобы некластеризованный индекс не искал кластерный индекс, а для SQL Server мы можем использовать столбцы «INCLUDE» при создании индекса, поэтому SQL Server добавляет их на конечный уровень индекс. Таким образом, нет необходимости искать через cluster-index.
Но представьте себе, у нас есть таблица Customers (CustID, FirstName, City) с кластеризованным индексом для CustID.
, если мы создадим некластеризованный индекс (называемый IX_FIRSTNAME) для столбца FirstName и включим этот столбец в качестве полезной нагрузки в конечный узел индекса и запросим как:
выберите FirstName from Customers, где FirstName Like 'T*';
, так что в этом случае нет необходимости искать по кластеризованному индексу, поэтому можно ли считать IX_FIRSTNAME покрывающим индексом?
или он должен соответствовать требованиям для всех столбцов?
и нам нужно создать некластеризованный для всех трех столбцов индекс покрытия?
- sql-сервер
- база данных
- индексация
- некластеризованный индекс
2
Здесь есть две концепции:
- кластеризованные и некластеризованные индексы
- закрывающие индексы
Покрывающий индекс — это такой индекс, который может удовлетворить условие where в вашем запросе. Поскольку у вас, вероятно, будет более одного запроса к вашим данным, данный индекс может быть «покрывающим» для одного запроса, но не для другого.
Поскольку у вас, вероятно, будет более одного запроса к вашим данным, данный индекс может быть «покрывающим» для одного запроса, но не для другого.
В вашем примере IX_FIRSTNAME является покрывающим индексом для запроса
select FirstName from Customers where FirstName Like 'T*'; ,
, но не для запроса
выберите Имя из Клиентов, где Имя нравится «T*» и Город нравится «Лондон»; .
Большая часть оптимизации производительности сводится к «пониманию ваших запросов, особенно предложения where, и разработке индексов покрытия». Создание индексов для всех возможных комбинаций столбцов — плохая идея, поскольку индексы сами по себе влияют на производительность.
Вторая концепция — это «кластеризованные» и «некластеризованные» индексы. Это скорее физическая проблема — с кластеризованным индексом данные хранятся на диске в порядке индекса. Это отлично подходит для создания индекса по первичному ключу таблицы (если ваш первичный ключ является увеличивающимся целым числом).