В чем разница между таблицей temp и табличной переменной в SQL Server? Ms sql табличная переменная
Сравнение временных таблиц, табличных переменных и обобщенных табличных выражений (CTE)

Последнее время стали часто обсуждать временные таблицы, табличные переменные и cte. По этой причине было принято решение вынести это обсуждение в отбельную статью.
Временные таблицы. Производительность (temporal tables)
Существует несколько основных моментов, на которые стоит обратить внимание:
- Перемещение данных во временную таблицу может вызвать большую нагрузку на дисковую подсистему, где она лежит tempdb.
- SQL Server очень плотно работает с tempdb и бывает сложно гарантировать время выполнения запросов, которые активно её используют, так как может быть существенная конкуренция за эту БД
Большим преимуществом временных таблиц является то, что на них можно создавать индексы и статистику. Это может существенно ускорить выполнение запросов.
Табличные переменные. Производительность
Самое большие заблуждение, связанное с табличными переменными это то, что многие полагают, что они всегда располагаются в памяти, но это не так. Табличные переменные, как и временные таблицы в последних версиях SQL Server, располагаются в памяти до того момента, пока размер выборки не станет слишком большим, после чего он непременно будет сброшен в tempdb. Если памяти недостаточно или SQL Server испытывает давление на память, то сброс в tempdb происходит чаще.
На что стоит обратить внимание:
- Табличные переменные не позволяют выполнять DDL операции, поэтому вы не можете создать индексы, для улучшения выполнения запросов. Создание UNIQUE constraint позволяет обойти это ограничение.
- Если вопросы с индексами решить как-то возможно, то отсутствие статистики на табличных переменных никак не побороть. На средних и больших выборка это приведёт к проблемам с производительностью.
Создавайте табличные переменные только на малом объёме данных, где нет необходимости в индексах и статистике. Никогда не пользуйтесь табличными переменными, если выборка может содержать более 1000 строк. Я рекомендую не пользоваться табличными переменными уже начиная с 50-100 строк.
Обобщённое табличное выражение. Производительность (CTE)
CTE — это на самом деле только синтаксический способ разбить запрос, который работает в рамках одного запроса. Внутри SQL Server это похоже на создание VIEW «на лету», к которому можно обратиться несколько раз в рамках одного запроса. Вот когда Microsoft рекомендует использовать CTE:
- Создания рекурсивных запросов. Дополнительные сведения см. в разделе Рекурсивные запросы, использующие обобщенные табличные выражения.
- Замены представлений в тех случаях, когда использование представления не оправдано, то есть тогда, когда нет необходимости сохранять в метаданных базы его определение.
- Группирования по столбцу, производного от скалярного подзапроса выборки или функции, которая недетерминирована или имеет внешний доступ.
- Многократных ссылок на результирующую таблицу из одной и той же инструкции.
Таблицы сравнения
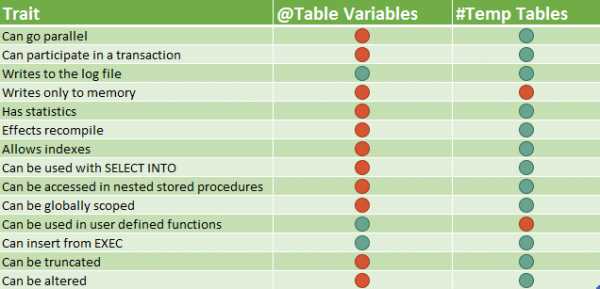
| Temp Table | Global Temp Table | Table Variable | |
| CREATE TABLE #t (ID INT) | CREATE TABLE ##t (ID INT) | DECLARE @t TABLE (ID INT) | ;WITH CTE_T AS (SELECT ID FROM table) |
| Создаётся в tempdb | Создаётся в tempdb | Создаётся в tempdb, но ведёт себя как переменная | Создаётся в памяти, при недостаткте которой, данные помещаются в tempdb |
| Доступна только в текущей сессии | Доступна всем сессиям | Доступна только в текущем батче текущей сессии | Доступна только в текущем запросе текущей сесcии |
| Доступна пока работает активная сессия | Доступна всем сессиям пока активна сессия, создавшая таблицу | Автоматические уничтожается когда сессия отключается/переходит на другой батч | Автоматически уничтожается, после перехода на другой запрос |
| Могут быть созданы: Primary key, индексы, статистика, ограничения | Могут быть созданы: Primary key, индексы, статистика, ограничения | Кластерные и некластерные индексы могут быть созданы с помощью первичного ключа | Не поддерживается |
| Может быть изменена после создания | Может быть изменена после создания | Не может быть изменена после создания | Не может быть изменена после создания |
| Не может использоваться во VIEW | Не может использоваться во VIEW | Не может использоваться во VIEW | Может использоваться во VIEW |
| Используйте для больших объёмов данных | Используйте для больших объёмов данных, но будьте аккуратны с именами, так как невозможно создать 2 одинаковых названия | Используйте для малого набора данных | Используйте для малого набора данных или когда необходима рекурсия |
Вконтакте
Google+
Запись опубликована в рубрике Полезно и интересно с метками compare. Добавьте в закладки постоянную ссылку.sqlcom.ru
В чем разница между таблицей temp и табличной переменной в SQL Server? MS SQL Server
В SQL Server 2005 мы можем создавать временные таблицы одним из двух способов:
Каковы различия между этими двумя? Я прочитал противоречивые мнения о том, продолжает ли @tmp использовать tempdb, или если все происходит в памяти.
В каких сценариях выполняется одно из другого?
Существует несколько различий между временными таблицами (#tmp) и табличными переменными (@tmp), хотя использование tempdb не является одним из них, как указано в ссылке MSDN ниже.
Как правило, для небольших и средних объемов данных и простых сценариев использования вы должны использовать переменные таблицы. (Это чрезмерно широкое руководство, конечно же, множество исключений – см. Ниже и следующие статьи.)
Некоторые моменты, которые следует учитывать при выборе между ними:
-
Временные таблицы являются реальными таблицами, поэтому вы можете делать такие вещи, как CREATE INDEXes и т. Д. Если у вас большие объемы данных, для которых доступ по индексу будет быстрее, тогда временные таблицы являются хорошим вариантом.
-
Табличные переменные могут иметь индексы с использованием ограничений PRIMARY KEY или UNIQUE. (Если вы хотите, чтобы не уникальный идентификатор просто включал столбец первичного ключа в качестве последнего столбца в уникальном ограничении. Если у вас нет уникального столбца, вы можете использовать столбец идентификатора.) SQL 2014 также имеет уникальные индексы ,
-
Переменные таблицы не участвуют в транзакциях, а SELECT s неявно с NOLOCK . Поведение транзакции может быть очень полезно, например, если вы хотите ROLLBACK на полпути через процедуру, тогда переменные таблицы, заполненные во время этой транзакции, будут по-прежнему заполняться!
-
Таблицы Temp могут привести к повторной компиляции хранимых процедур, возможно, часто. Переменные таблицы не будут.
-
Вы можете создать временную таблицу с помощью SELECT INTO, которая может быть быстрее написана (подходит для специальных запросов) и может позволить вам иметь дело с изменением типов данных с течением времени, поскольку вам не нужно заранее определять структуру вашей временной таблицы.
-
Вы можете передавать табличные переменные обратно из функций, позволяя значительно упростить инкапсуляцию и повторное использование логики (например, сделать функцию, чтобы разбить строку на таблицу значений на каком-либо произвольном разделителе).
-
Использование табличных переменных в пользовательских функциях позволяет использовать эти функции более широко (подробнее см. Документацию CREATE FUNCTION). Если вы пишете функцию, вы должны использовать переменные таблицы по сравнению с таблицами temp, если в противном случае нет необходимости.
-
Обе таблицы и временные таблицы хранятся в tempdb. Но переменные таблицы (с 2005 года) по умолчанию сопоставляют текущую базу данных по сравнению с временными таблицами, которые принимают стандартную настройку tempdb ( ref ). Это означает, что вы должны знать о проблемах с сортировкой, если использование временных таблиц и сопоставление db отличаются от tempdb, что вызывает проблемы, если вы хотите сравнить данные в таблице temp с данными в вашей базе данных.
-
Глобальные таблицы темпов (## tmp) – это еще один тип таблицы temp, доступный для всех сеансов и пользователей.
Дальнейшее чтение:
Просто глядя на утверждение в принятом ответе, что переменные таблицы не участвуют в регистрации.
Как правило, неверно, что существует какая-либо разница в количестве ведения журнала (по крайней мере, для операций insert / update / delete в самой таблице, хотя я обнаружил, что в этом отношении существует небольшая разница для кэшированных временных объектов в хранимых процедурах из-за обновление дополнительных системных таблиц).
Я рассмотрел поведение ведения журнала как для @table_variable и для таблицы #temp для следующих операций.
- Успешная вставка
- Multi Row Вставьте, где инструкция откат из-за нарушения ограничения.
- Обновить
- Удалить
- Освобождает
Записи транзакций практически идентичны для всех операций.
В версии переменной таблицы фактически есть несколько дополнительных записей журнала, потому что она получает запись, добавленную к (и позже удаленной) из базовой таблицы sys.syssingleobjrefs но в целом было несколько меньше байтов, записанных чисто, поскольку внутреннее имя для переменных таблицы потребляет 236 байт чем для # #temp таблиц (на 118 меньше символов nvarchar ).
Полный скрипт для воспроизведения (лучший запуск в экземпляре запускался в однопользовательском режиме и с использованием режима sqlcmd )
:setvar tablename "@T" :setvar tablescript "DECLARE @T TABLE" /* --Uncomment this section to test a #temp table :setvar tablename "#T" :setvar tablescript "CREATE TABLE #T" */ USE tempdb GO CHECKPOINT DECLARE @LSN NVARCHAR(25) SELECT @LSN = MAX([Current LSN]) FROM fn_dblog(null, null) EXEC(N'BEGIN TRAN StartBatch SAVE TRAN StartBatch COMMIT $(tablescript) ( [4CA996AC-C7E1-48B5-B48A-E721E7A435F0] INT PRIMARY KEY DEFAULT 0, InRowFiller char(7000) DEFAULT ''A'', OffRowFiller varchar(8000) DEFAULT REPLICATE(''B'',8000), LOBFiller varchar(max) DEFAULT REPLICATE(cast(''C'' as varchar(max)),10000) ) BEGIN TRAN InsertFirstRow SAVE TRAN InsertFirstRow COMMIT INSERT INTO $(tablename) DEFAULT VALUES BEGIN TRAN Insert9Rows SAVE TRAN Insert9Rows COMMIT INSERT INTO $(tablename) ([4CA996AC-C7E1-48B5-B48A-E721E7A435F0]) SELECT TOP 9 ROW_NUMBER() OVER (ORDER BY (SELECT 0)) FROM sys.all_columns BEGIN TRAN InsertFailure SAVE TRAN InsertFailure COMMIT /*Try and Insert 10 rows, the 10th one will cause a constraint violation*/ BEGIN TRY INSERT INTO $(tablename) ([4CA996AC-C7E1-48B5-B48A-E721E7A435F0]) SELECT TOP (10) (10 + ROW_NUMBER() OVER (ORDER BY (SELECT 0))) % 20 FROM sys.all_columns END TRY BEGIN CATCH PRINT ERROR_MESSAGE() END CATCH BEGIN TRAN Update10Rows SAVE TRAN Update10Rows COMMIT UPDATE $(tablename) SET InRowFiller = LOWER(InRowFiller), OffRowFiller =LOWER(OffRowFiller), LOBFiller =LOWER(LOBFiller) BEGIN TRAN Delete10Rows SAVE TRAN Delete10Rows COMMIT DELETE FROM $(tablename) BEGIN TRAN AfterDelete SAVE TRAN AfterDelete COMMIT BEGIN TRAN EndBatch SAVE TRAN EndBatch COMMIT') DECLARE @LSN_HEX NVARCHAR(25) = CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 1, 8),2) AS INT) AS VARCHAR) + ':' + CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 10, 8),2) AS INT) AS VARCHAR) + ':' + CAST(CAST(CONVERT(varbinary,SUBSTRING(@LSN, 19, 4),2) AS INT) AS VARCHAR) SELECT [Operation], [Context], [AllocUnitName], [Transaction Name], [Description] FROM fn_dblog(@LSN_HEX, null) AS D WHERE [Current LSN] > @LSN SELECT CASE WHEN GROUPING(Operation) = 1 THEN 'Total' ELSE Operation END AS Operation, Context, AllocUnitName, COALESCE(SUM([Log Record Length]), 0) AS [Size in Bytes], COUNT(*) AS Cnt FROM fn_dblog(@LSN_HEX, null) AS D WHERE [Current LSN] > @LSN GROUP BY GROUPING SETS((Operation, Context, AllocUnitName),())Для меньших таблиц (менее 1000 строк) используйте временную переменную, иначе используйте временную таблицу.
@wcm – на самом деле, чтобы забрать таблицу, переменная таблицы не только Рам – ее можно частично сохранить на диске.
Временная таблица может иметь индексы, тогда как переменная таблицы может иметь только первичный индекс. Если скорость является проблемой, переменные таблицы могут быть более быстрыми, но, очевидно, если есть много записей или необходимость поиска в таблице temp кластерного индекса, то таблица Temp будет лучше.
Хорошая статья фона
-
Таблица Temp: таблицу Temp легко создавать и создавать резервные копии данных.
Переменная таблицы: Но переменная таблицы связана с усилием, когда мы обычно создаем обычные таблицы.
-
Таблица Temp: Результат таблицы Temp может использоваться несколькими пользователями.
Переменная таблицы: Но переменная таблицы может использоваться только текущим пользователем.
-
Таблица Temp: таблица temp будет храниться в tempdb. Это сделает сетевой трафик. Когда у нас есть большие данные в таблице temp, он должен работать через базу данных. Будет проблема с производительностью.
Таблица: переменная таблицы хранится в физической памяти для некоторых данных, а затем, когда размер увеличивается, он будет перемещен в tempdb.
-
Таблица Temp: таблица Temp может выполнять все операции DDL. Он позволяет создавать индексы, отбрасывать, изменять и т. Д.
Переменная таблицы: в то время как переменная таблицы не позволяет выполнять операции DDL. Но переменная таблицы позволяет нам создавать только кластерный индекс.
-
Таблица Temp: таблица Temp может использоваться для текущего сеанса или глобальной. Чтобы сеанс нескольких пользователей мог использовать результаты в таблице.
Переменная таблицы: Но переменную таблицы можно использовать до этой программы. (Хранимая процедура)
-
Таблица Temp: переменная Temp не может использовать транзакции. Когда мы выполняем операции DML с временной таблицей, это может быть откат или совершение транзакций.
Переменная таблицы: Но мы не можем это сделать для переменной таблицы.
-
Таблица Temp: функции не могут использовать временную переменную. Более того, мы не можем выполнять операцию DML в функциях.
Переменная таблицы: Но функция позволяет использовать переменную таблицы. Но используя переменную таблицы, мы можем это сделать.
-
Таблица Temp: хранимая процедура выполняет перекомпиляцию (не может использовать тот же план выполнения), когда мы используем временную переменную для каждого последующего вызова.
Переменная таблицы: в то время как переменная таблицы не будет работать так.
Для всех вас, кто верит в миф о том, что временные переменные находятся в памяти только
Во-первых, переменная таблицы НЕ обязательно является резидентной. Под давлением памяти страницы, принадлежащие переменной таблицы, могут быть вытолкнуты на tempdb.
Читайте статью здесь: TempDB :: Таблица переменной vs локальная временная таблица
Другое главное отличие состоит в том, что переменные таблицы не имеют статистики столбцов, где это делают таблицы temp. Это означает, что оптимизатор запросов не знает, сколько строк находится в переменной таблицы (оно угадывает 1), что может привести к созданию очень неоптимальных планов, если переменная таблицы фактически имеет большое количество строк.
Цитата взята из; Профессиональный внутренний SQL Server 2012 и устранение неполадок
Статистика . Основное различие между временными таблицами и табличными переменными состоит в том, что статистические данные не создаются в переменных таблицы. Это имеет два основных последствия, первый из которых заключается в том, что оптимизатор запросов использует фиксированную оценку количества строк в переменной таблицы независимо от содержащихся в ней данных. Более того, добавление или удаление данных не изменяет оценку.
Индексы Вы не можете создавать индексы в переменных таблицы, хотя вы можете создавать ограничения. Это означает, что, создавая первичные ключи или уникальные ограничения, вы можете иметь индексы (поскольку они созданы для поддержки ограничений) для переменных таблицы. Даже если у вас есть ограничения и, следовательно, индексы, которые будут иметь статистику, индексы не будут использоваться, когда запрос скомпилирован, потому что они не будут существовать во время компиляции и не будут вызывать перекомпиляции.
Модификации схемы Модификации схемы возможны во временных таблицах, но не в переменных таблицы. Хотя модификации схемы возможны во временных таблицах, избегайте их использования, поскольку они вызывают перекомпиляцию операторов, которые используют таблицы.
ТАБЛИЧНЫЕ ПЕРЕМЕННЫЕ НЕ СОЗДАНЫ В ПАМЯТИ
Существует распространенное заблуждение, что переменные таблицы являются структурами в памяти и как таковые будут выполняться быстрее, чем временные таблицы . Благодаря DMV называется sys. dm _ db _ session _ space _ use, которое показывает использование tempdb сеансом, вы можете доказать, что это не так . После перезапуска SQL Server, чтобы очистить DMV, запустите следующий скрипт, чтобы подтвердить, что ваш идентификатор сеанса _ возвращает 0 для объектов _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
SELECT session_id, database_id, user_objects_alloc_page_count FROM sys.dm_db_session_space_usage WHERE session_id > 50 ;Теперь вы можете проверить, сколько пространства использует временная таблица, запустив следующий скрипт, чтобы создать временную таблицу с одним столбцом и заполнить ее одной строкой:
CREATE TABLE #TempTable ( ID INT ) ; INSERT INTO #TempTable ( ID ) VALUES ( 1 ) ; GO SELECT session_id, database_id, user_objects_alloc_page_count FROM sys.dm_db_session_space_usage WHERE session_id > 50 ;Результаты на моем сервере показывают, что таблице была выделена одна страница в tempdb. Теперь запустите тот же скрипт, но на этот раз используйте переменную таблицы:
DECLARE @TempTable TABLE ( ID INT ) ; INSERT INTO @TempTable ( ID ) VALUES ( 1 ) ; GO SELECT session_id, database_id, user_objects_alloc_page_count FROM sys.dm_db_session_space_usage WHERE session_id > 50 ;Какой из них использовать?
Независимо от того, используете ли вы временные таблицы или переменные таблицы, следует решить путем тщательного тестирования, но лучше всего ориентироваться на временные таблицы по умолчанию, потому что гораздо меньше ошибок, которые могут пойти не так .
Я видел, как клиенты разрабатывают код с использованием переменных таблицы, поскольку они имеют дело с небольшим количеством строк, и это было быстрее, чем временная таблица, но через несколько лет в таблице были сотни тысяч строк, а производительность была ужасной , поэтому постарайтесь и планируйте планирование мощности, когда принимаете решение!
Другое отличие:
Таблицу var можно получить только из операторов внутри процедуры, которая ее создает, а не из других процедур, вызываемых этой процедурой, или вложенного динамического SQL (через exec или sp_executesql).
С другой стороны, область temp table включает код в вызываемых процедурах и вложенный динамический SQL.
Если таблица, созданная вашей процедурой, должна быть доступна из других процедур или динамического SQL, вы должны использовать временную таблицу. Это может быть очень удобно в сложных ситуациях.
Подумайте также, что вы часто можете заменить обе производные таблицы, которые также могут быть быстрее. Однако, как и при любой настройке производительности, только фактические тесты против ваших фактических данных могут рассказать вам лучший подход для вашего конкретного запроса.
Временная таблица
Временная таблица ведет себя как реальные таблицы, но создается во время выполнения. Его работа похожа на реальную таблицу. Мы можем делать почти все операции, которые возможны в реальных таблицах. Мы можем использовать DDL-выражения, такие как ALTER, CREATE, DROP на временных таблицах.
Любые изменения в структуре Временной таблицы возможны после создания. Временная таблица хранится в базе данных системных баз данных «tempdb».
Временная таблица участвует в транзакциях, протоколировании или блокировке. По этой причине он медленнее, чем Table Variable.
Переменная таблицы
Это переменная, но работает как таблица. Он также создается в базе данных Tempdb не в памяти. Переменная таблицы доступна только в пакетной или хранимой процедуре. Вам не нужно отбрасывать переменную таблицы, она автоматически отбрасывается при завершении процесса пакетной обработки и хранения
Поддержка переменной таблицы первичный ключ, идентификатор во время создания. Но он не поддерживает некластеризованный индекс. После первичного ключа объявления, идентификатор, который вы не можете изменить.
Переменные таблицы не участвуют в транзакциях, протоколировании или блокировке. Транзакции, протоколирование и блокировка не влияют на переменные таблицы.
Прочтите эту статью для получения дополнительной информации – http://goo.gl/GXtXqz
sqlserver.bilee.com
Как передать табличную переменную в хранимую процедуру
Вопрос: Табличная переменная VS вложенный запрос
Добрый день!Отлаживая запрос, наткнулся на неожиданную ситуацию.Работа с табличной переменной в mssql 2016 происходит на порядки дольше.Был подготовлен тестовый скрипт:
DECLARE @CurrentDate DATE = '2017-02-15' -- Определение границ прошлого месяца DECLARE @LeftDateTimeMargin DATETIME = DATEADD(MONTH, DATEDIFF( MONTH, 0, @CurrentDate )-1, 0) DECLARE @RightDateTimeMargin DATETIME = DATEADD(MONTH, DATEDIFF( MONTH, 0, @CurrentDate ), 0) -- debug -- SELECT @CurrentDate as CurrentDate, @LeftDateTimeMargin as LeftDateTimeMargin, @RightDateTimeMargin as RightDateTimeMargin -- Создание табличной переменной для сохранения выборки данных за целевой период DECLARE @SourceData TABLE ( [id] [uniqueidentifier] NOT NULL PRIMARY KEY, [event_datetime] [datetime] NOT NULL, [base_id] [uniqueidentifier] NOT NULL, [event_id] [uniqueidentifier] NOT NULL, [user_id] [uniqueidentifier] NULL, [metaname] [nvarchar](300) NOT NULL, [duration] [int] NULL, [product_id] [uniqueidentifier] NOT NULL, [server_event_datetime] [datetime] NOT NULL, [aeh_id] [uniqueidentifier] NULL ) -- Заполнение табличной перемнной данными с отбором (число строк = 6 599 436) INSERT INTO @SourceData ( [id], [event_datetime], [base_id], [event_id], [user_id], [metaname], [duration], [product_id], [server_event_datetime], [aeh_id] ) SELECT [id], [event_datetime], [base_id], [event_id], [user_id], [metaname], [duration], [product_id], [server_event_datetime], [aeh_id] FROM [StatSoftwareUsageData] WHERE server_event_datetime >= @LeftDateTimeMargin AND server_event_datetime < @RightDateTimeMargin -- ОЧЕНЬ ДОЛГО РАБОТАЕТ, БОЛЕЕ 20+ МИНУТ - в качестве источника, заранее подготовленная выборка -- При исполнении запроса, sqlservr грузит 1 ядро на 100% SELECT DISTINCT [@SourceData].[metaname] FROM @SourceData LEFT JOIN [StatMetanames] ON [StatMetanames].[metaname] = [@SourceData].[metaname] WHERE [StatMetanames].[id] IS NULL -- РАБОТАЕТ НОРМАЛЬНО (20 сек) - в качестве источника, обычная таблица -- При исполнении запроса, sqlservr грузит все ядра --SELECT -- DISTINCT [StatSoftwareUsageData].[metaname] --FROM [StatSoftwareUsageData] --LEFT JOIN [StatMetanames] ON [StatMetanames].[metaname] = [StatSoftwareUsageData].[metaname] --WHERE -- [StatMetanames].[id] IS NULL AND -- server_event_datetime >= @LeftDateTimeMargin AND -- server_event_datetime < @RightDateTimeMargin Понятно, что по строке соединяться - не самая лучшая затея. Но вопрос не в этом.Вопрос - почему такая существенная разница, при работе с одинаковым числом записей?Табличная переменная на порядки медленнее чем запрос к исходной таблице.Есть ли возможность как-то использовать табличные переменные, не теряя производительность? Почему грузится 1 ядро при работе с табличной переменной?Казалось бы, табличная переменная целиком в памяти, вместо того, чтобы 10 раз прицеплять вложенный запрос к исходной таблице,должно быть лучше создать 1 раз нужную выборку и везде её использовать...
Ответ: Нектотам,Нектотам| 2. Какая структура у StatSoftwareUsageData и какие индексы? |
| 3. В случае с табличной переменной вы читаете из StatSoftwareUsageData и пишите в @SourceData 10 колонок, а в простом запросе - 2. |
| 4. Табличная переменная живет в tempdb. Это вполне может привести к большим IO. |
| 5. В случае с табличной переменной сначала надо выгрести все записи, а потом уже делать join. |
| 6. В случае с табличной переменной оптимизатор часто промахивается, особенно без option(recompile), т.к. статистики по табличной переменной нет. |
TaPaKСпасибо.
aleks2Никогда не понимал таких людей. Ты поди эксперт во всём, раз допускаешь такие комментарии.Опимизация тестового примера не дает ответ на вопрос.
forundex.ru
Табличные переменные и OUTPUT
Вопрос: Табличная переменная VS вложенный запрос
Добрый день!Отлаживая запрос, наткнулся на неожиданную ситуацию.Работа с табличной переменной в mssql 2016 происходит на порядки дольше.Был подготовлен тестовый скрипт:
DECLARE @CurrentDate DATE = '2017-02-15' -- Определение границ прошлого месяца DECLARE @LeftDateTimeMargin DATETIME = DATEADD(MONTH, DATEDIFF( MONTH, 0, @CurrentDate )-1, 0) DECLARE @RightDateTimeMargin DATETIME = DATEADD(MONTH, DATEDIFF( MONTH, 0, @CurrentDate ), 0) -- debug -- SELECT @CurrentDate as CurrentDate, @LeftDateTimeMargin as LeftDateTimeMargin, @RightDateTimeMargin as RightDateTimeMargin -- Создание табличной переменной для сохранения выборки данных за целевой период DECLARE @SourceData TABLE ( [id] [uniqueidentifier] NOT NULL PRIMARY KEY, [event_datetime] [datetime] NOT NULL, [base_id] [uniqueidentifier] NOT NULL, [event_id] [uniqueidentifier] NOT NULL, [user_id] [uniqueidentifier] NULL, [metaname] [nvarchar](300) NOT NULL, [duration] [int] NULL, [product_id] [uniqueidentifier] NOT NULL, [server_event_datetime] [datetime] NOT NULL, [aeh_id] [uniqueidentifier] NULL ) -- Заполнение табличной перемнной данными с отбором (число строк = 6 599 436) INSERT INTO @SourceData ( [id], [event_datetime], [base_id], [event_id], [user_id], [metaname], [duration], [product_id], [server_event_datetime], [aeh_id] ) SELECT [id], [event_datetime], [base_id], [event_id], [user_id], [metaname], [duration], [product_id], [server_event_datetime], [aeh_id] FROM [StatSoftwareUsageData] WHERE server_event_datetime >= @LeftDateTimeMargin AND server_event_datetime < @RightDateTimeMargin -- ОЧЕНЬ ДОЛГО РАБОТАЕТ, БОЛЕЕ 20+ МИНУТ - в качестве источника, заранее подготовленная выборка -- При исполнении запроса, sqlservr грузит 1 ядро на 100% SELECT DISTINCT [@SourceData].[metaname] FROM @SourceData LEFT JOIN [StatMetanames] ON [StatMetanames].[metaname] = [@SourceData].[metaname] WHERE [StatMetanames].[id] IS NULL -- РАБОТАЕТ НОРМАЛЬНО (20 сек) - в качестве источника, обычная таблица -- При исполнении запроса, sqlservr грузит все ядра --SELECT -- DISTINCT [StatSoftwareUsageData].[metaname] --FROM [StatSoftwareUsageData] --LEFT JOIN [StatMetanames] ON [StatMetanames].[metaname] = [StatSoftwareUsageData].[metaname] --WHERE -- [StatMetanames].[id] IS NULL AND -- server_event_datetime >= @LeftDateTimeMargin AND -- server_event_datetime < @RightDateTimeMargin Понятно, что по строке соединяться - не самая лучшая затея. Но вопрос не в этом.Вопрос - почему такая существенная разница, при работе с одинаковым числом записей?Табличная переменная на порядки медленнее чем запрос к исходной таблице.Есть ли возможность как-то использовать табличные переменные, не теряя производительность? Почему грузится 1 ядро при работе с табличной переменной?Казалось бы, табличная переменная целиком в памяти, вместо того, чтобы 10 раз прицеплять вложенный запрос к исходной таблице,должно быть лучше создать 1 раз нужную выборку и везде её использовать...
Ответ: Нектотам,Нектотам| 2. Какая структура у StatSoftwareUsageData и какие индексы? |
| 3. В случае с табличной переменной вы читаете из StatSoftwareUsageData и пишите в @SourceData 10 колонок, а в простом запросе - 2. |
| 4. Табличная переменная живет в tempdb. Это вполне может привести к большим IO. |
| 5. В случае с табличной переменной сначала надо выгрести все записи, а потом уже делать join. |
| 6. В случае с табличной переменной оптимизатор часто промахивается, особенно без option(recompile), т.к. статистики по табличной переменной нет. |
TaPaKСпасибо.
aleks2Никогда не понимал таких людей. Ты поди эксперт во всём, раз допускаешь такие комментарии.Опимизация тестового примера не дает ответ на вопрос.
forundex.ru
- Во время работы компьютер зависает

- While sql цикл

- Как поставить браузер на пароль

- Как работать с acronis disk director 12

- Как проверить зарядку на ноутбуке

- Почему на электронную почту не доходят письма

- Windows 10 какая версия самая последняя

- Как почистить реестр компьютера

- Удалить маршрут
- Сделать установочную флешку

- Ubuntu как удалить phpmyadmin
