Основы XML — разметка и структура XML документов. Основы xml
Основы XML для Java программиста

Вступление
Здравствуйте, дорогие читатели моей статьи. Сразу хочу сказать, что это только первая статья в моём цикле из трёх статей. Основная цель всего цикла – посвятить каждого читателя в XML и дать, если не полное разъяснение и понимание, то, хотя бы, хороший такой толчок к нему, объяснив основные моменты и вещи. Весь цикл будет для одной номинации – «Внимание к деталям», а разделение на 3 статьи сделано для того, чтобы вмещаться в лимит символов в постах и разделить большое количество материала на более маленькие порции для большего понимания. Первая статья будет посвящена самому XML и что это такое, а так же одному из способов составления схемы для XML файлов – DTD. Для начала, хотелось бы высказать небольшое предисловие для тех, кто вообще еще не знаком с XML: не нужно пугаться. XML не очень сложный и с ним нужно разобраться любому программисту, так как это очень гибкий, эффективный и популярный формат файлов на сегодняшний день для хранения разнообразной информации, какой вы только захотите. XML используется в Ant, Maven, Spring. Любому программисту нужно знание XML. Теперь, когда вы собрались силами и мотивацией, давайте приступать к изучению. Весь материал я буду пытаться выложить максимально просто, собрав только самое важное и не вдаваться в дебри. XML Для более ясного объяснения, правильней будет визуализировать XML примером. <?xml version="1.0" encoding="UTF-8"?> <company> <name>IT-Heaven</name> <offices> <office floor="1" room="1"> <employees> <employee> <name>Maksim</name> <job>Middle Software Developer</job> </employee> <employee> <name>Ivan</name> <job>Junior Software Developer</job> </employee> <employee> <name>Franklin</name> <job>Junior Software Developer</job> </employee> </employees> </office> <office floor="1" room="2"> <employees> <employee> <name>Herald</name> <job>Middle Software Developer</job> </employee> <employee> <name>Adam</name> <job>Middle Software Developer</job> </employee> <employee> <name>Leroy</name> <job>Junior Software Developer</job> </employee> </employees> </office> </offices> </company> HTML и XML похожи синтаксисом, так как у них общий родитель – SGML. Однако, в HTML есть только фиксированные теги конкретного стандарта, в то время, как в XML вы можете создавать свои собственные теги, атрибуты и, в целом, делать все, что захотите, чтобы хранить данные так, как вам будет удобно. По сути, XML файлы может прочитать любой человек, знающий английский язык. Изобразить данный пример можно с помощью дерева.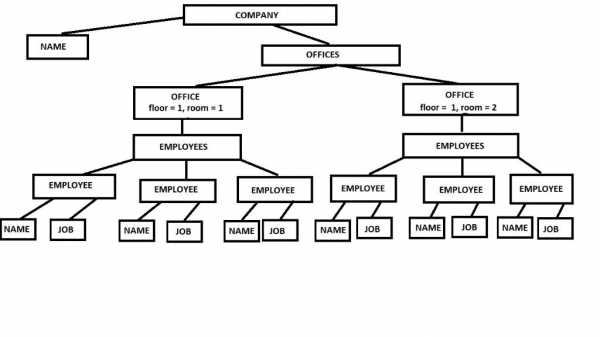
DTD
DTD создан для того, чтобы описывать типы документов. DTD уже устаревает и сейчас от него активно отказываются в XML, однако еще много XML файлов используют именно DTD и, в целом, его полезно понимать. DTD – это технология валидации XML-документов. DTD объявляет конкретные правила для типа документа: его элементы, какие элементы могут быть внутри элемента, атрибуты, обязательные они или нет, количество их повторений, а так же сущности (Entity). По аналогии с XML, для более ясного объяснения DTD можно визуализировать примером. <!-- Объявление возможных элементов --> <!ELEMENT employee EMPTY> <!ELEMENT employees (employee+)> <!ELEMENT office (employees)> <!ELEMENT offices (office+)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (name, offices)> <!-- Добавление атрибутов для элементов employee и office --> <!ATTLIST employee name CDATA #REQUIRED job CDATA #REQUIRED > <!ATTLIST office floor CDATA #REQUIRED room CDATA #REQUIRED > <!-- Добавление сущностей --> <!ENTITY M "Maksim"> <!ENTITY I "Ivan"> <!ENTITY F "Franklin"> Вот такой вот простой пример у нас есть. В данном примере, мы объявили всю нашу иерархию из XML примера: работник, работники, офис, офисы, имя, компания. Для создания DTD файлов служат 3 основные конструкции, чтобы описывать любые XML файлы: ELEMENT (для описания элементов), ATTLIST (для описания атрибутов для элементов) и ENTITY (для подстановки текста сокращенными формами). ELEMENT Служит для описания элемента. Элементы, которые можно использовать внутри описанного элемента, перечисляются в скобках в виде списка. Можно использовать квантификаторы для указания количества (они аналогичны с квантификаторами из регулярных выражений): + значит 1+ * значит 0+ ? значит 0 ИЛИ 1 Если квантификаторов не было добавлено, то считается, что должен быть только 1 элемент. Если бы нам нужен был один из группы элементов, можно было бы написать так: <!ELEMENT company ((name | offices))> Тогда выбирался бы один из элементов: name или offices, но если бы внутри company было сразу два их, то валидация бы не проходила. Так же можно заметить, что в employee есть слово EMPTY – это значит, что элемент должен быть пустым. Есть еще ANY – любые элементы. #PCDATA – текстовые данные. ATTLIST Служит для добавления атрибутов к элементам. После ATTLIST следует название нужного элемента, а после словарь вида «название атрибута – тип атрибута», а в конце можно добавить #IMPLIED (не обязателен) или #REQUIRED (обязателен). CDATA – текстовые данные. Есть и другие типы, однако все они строчные. ENTITY ENTITY служит для объявления сокращений и текста, который будет на них подстваляться. По сути, мы просто сможем использовать в XML вместо полного текста просто название сущности со знаком & перед и ; после. Например: чтобы отличать разметку в HTML и просто символы, левую угловую скобочку часто экранируют с помощью lt; , только нужно еще выставить & перед lt. Тогда мы будем использовать не разметку, а просто символ Есть два способа использовать их в XML: 1. Внедрение - написание DTD правил внутри самого XML файла, достаточно просто написать корневой элемент после ключевого слова DOCTYPE и заключить наш DTD файл внутри квадратных скобочек. <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE company [ <!-- Объявление возможных элементов --> <!ELEMENT employee EMPTY> <!ELEMENT employees (employee+)> <!ELEMENT office (employees)> <!ELEMENT offices (office+)> <!ELEMENT name (#PCDATA)> <!ELEMENT company (name, offices)> <!-- Добавление атрибутов для элементов employee и office --> <!ATTLIST employee name CDATA #REQUIRED job CDATA #REQUIRED > <!ATTLIST office floor CDATA #REQUIRED room CDATA #REQUIRED > <!-- Добавление сущностей --> <!ENTITY M "Maksim"> <!ENTITY I "Ivan"> <!ENTITY F "Franklin"> ]> <company> <name>IT-Heaven</name> <!-- Иван недавно уволился, только неделю отработать должен. Не забудьте потом удалить его из списка.--> <offices> <office floor="1" room="1"> <employees> <employee name="&M;" job="Middle Software Developer" /> <employee name="&I;" job="Junior Software Developer" /> <employee name="&F;" job="Junior Software Developer" /> </employees> </office> <office floor="1" room="2"> <employees> <employee name="Herald" job="Middle Software Developer" /> <employee name="Adam" job="Middle Software Developer" /> <employee name="Leroy" job="Junior Software Developer" /> </employees> </office> </offices> </company> 2. Импорт - мы записываем все наши правила в отдельный DTD файл, после чего в XML файле используем DOCTYPE-конструкцию из первого способа, только вместо квадратных скобочек нужно написать SYSTEM и указать абсолютный или относительный до текущего местоположения файла путь. <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE company SYSTEM "dtd_example1.dtd"> <company> <name>IT-Heaven</name> <!-- Иван недавно уволился, только неделю отработать должен. Не забудьте потом удалить его из списка.--> <offices> <office floor="1" room="1"> <employees> <employee name="&M;" job="Middle Software Developer" /> <employee name="&I;" job="Junior Software Developer" /> <employee name="&F;" job="Junior Software Developer" /> </employees> </office> <office floor="1" room="2"> <employees> <employee name="Herald" job="Middle Software Developer" /> <employee name="Adam" job="Middle Software Developer" /> <employee name="Leroy" job="Junior Software Developer" /> </employees> </office> </offices> </company> Так же можно использовать ключевое слово PUBLIC вместо SYSTEM, однако оно вряд ли вам пригодится. Если интересно, то почитать про него (и про SYSTEM тоже) можно подробно тут: ссылочка. Теперь мы не можем использовать другие элементы без их объявления в DTD, а весь XML подчиняется нашим правилам. Можете попробовать записать данный код в IntelliJ IDEA в отдельный файл с расширением .xml и попробовать добавить какие-то новые элементы или удалить элемент из нашего DTD и заметите, как IDE будет указывать вам на ошибку. Однако, у DTD есть свои минусы: - У него свой собственный синтаксис, отличный от синтаксиса xml.
- В DTD нет проверки типов данных, а содержать он может только строки.
- В DTD нет пространства имён.
javarush.ru
Основы XML - пространства имен
Это очередной урок по основам XML и в нем мы рассмотрим такую тему как пространства имен. Если выражаться простыми словами, то в XML пространства имен используются грубо говоря для придания уникальности каждому отдельному элементу XML. Как вы помните из предыдущих статей, каждый разработчик, работая с XML, как бы сам изобретает свой язык. В связи с этим чтобы все элементы документа были уникальны и несли свой смысл, используются так называемые пространства имен, речь о которых и пойдет в данной статье.
Чтобы лучше понять всю суть вышесказанного, давайте рассмотрим небольшой пример. Допустим у нас есть документ в котором используются несколько логических схем, которые имеют одинаковые элементы, используемые в разных смыслах. Если бы схема была одной, то особых проблем не возникало бы, но поскольку их несколько, то становится невозможным определить, какой элемент относится к какой схеме или какие схемы используются в документе вообще.
В связи с этим были разработаны пространства имен XML. Чтобы различать схемы документов, для каждой из них ставится в соответствие специальный уникальный идентификатор ресурса или URI. В результате схемы будут считаться тождественными только в том случае, если уникальные идентификаторы будут совпадать. В связи с этим в качестве идентификатора чаще всего используется адрес своего ресурса.
Стоит заметить, что не обязательно, чтобы по этому адресу что-то находилось. Обработчик не будет переходить по ссылке и проверять наличие какой-либо информации. Она используется чисто как уникальный идентификатор, а поскольку это еще и URL своего ресурса, то вряд ли кто-то будет использовать его в качестве идентификатора для своей схемы.
Итак, с теорией мы разобрались. Теперь давайте перейдем непосредственно к рассмотрению префиксов пространств имен и примеров правильного их использования.
Префиксы пространств имен XML. Примеры использования пространств имен в XML и XSLT
Как уже говорилось чуть выше, пространства имен задаются при помощи уникальных идентификаторов URI. Чтобы упростить работу с ними, были разработаны специальные префиксы пространств имен, которые позволяют с легкостью определить, какой схеме принадлежит тот или иной элемент документа. Чтобы это продемонстрировать, рассмотрим небольшой пример.
<префикс:элемент xmlns:префикс="URI"> ... </префикс:элемент>Как видно с примера, префиксы пространств имен задаются как атрибуты с именами, которые начинаются последовательностью xmlns. Если говорить об XSLT, то там чаще всего используется префикс xsl. На практике все это выглядит следующим образом.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> ... </xsl:stylesheet>В качестве префикса пространств имен может использоваться и любое другое название, например, ddd. В этом случае код будет выглядеть следующим образом.
<ddd:stylesheet xmlns:ddd="http://www.w3.org/1999/XSL/Transform" version="1.0"> ... </ddd:stylesheet>Вышеприведенные два примера абсолютно идентичны между собой и ничем не будут отличаться. Стоит сразу заметить, что созданный префикс пространств имен может использоваться только в собственном имени и во вложенных элементах, но никак не за пределами элемента в котором он был создан. Для наглядности рассмотрим следующий пример.
<!-- Еще нельзя использовать префикс yyy --> <yyy:element xmlns:yyy="http://yyy.com/xml"> <!-- Здесь можно использовать префикс yyy --> <yyy:anyelement>any content</yyy:anyelement> ... </yyy:element> <!-- Уже нельзя использовать префикс yyy -->Еще один момент, на который стоит обратить внимание, это то, что сами префиксы не определяют элемент к той или иной схеме. Это делают уникальные идентификаторы, которые поставлены в соответствие этим префиксам. Таким образом, два элемента с разными префиксами которым заданы одинаковые идентификаторы будут считаться принадлежащими к одной схеме. Чтобы продемонстрировать это, рассмотрим следующий пример.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xslt:text xmlns:xslt="http://www.w3.org/1999/XSL/Transform">Any text</xslt:text> ... </xsl:stylesheet>Несмотря на то, что элементы stylesheet и text имеют разные префиксы, они принадлежат одной схеме, так как их префиксам проставлены в соответствие одинаковые идентификаторы. Таким образом, в документе может использоваться любое количество префиксов пространств имен. Зачастую все они определяются в корневом элементе, а потом просто используются в нужном месте документа. И опять еще один пример для демонстрации.
<xsl:element xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xslt="http://xslt.com/xslt" xmlns:xlt="http://xlt.com/xlt"> <xsl:anyelement /> <xslt:anyelement /> <xlt:anyelement /> ... </xsl:element>Существует еще один способ, который позволяет не проставлять префиксы в элементах. Для этого достаточно задать пространство имен по умолчанию. В этом случае все вложенные элементы будут принадлежать пространству имен родительского элемента. При этом не теряется возможность использовать другие пространства имен для дочерних элементов. Для этого достаточно вручную прописать нужное пространство имен, используя атрибут xmlns.
<xsl:element xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <firstelement>Any content</firstelement> <xslt:secondelement xmlns:xslt="http://xslt.com/xslt">Any content</xslt:secondelement> <xlt:thirdelement xmlns:xlt="http://xlt.com/xlt"> <one>Any content</one> <two>Any content</two> </xlt:thirdelement> ... </xsl:element>Здесь стоит обратить внимание, что элементы one и two будут принадлежать пространству имен элемента thirdelement, так как он является для них родительским. Как видим, здесь прослеживается так называемое наследование. Если для элемента не указано пространство имен, то ему автоматически присваивается пространство имен ближайшего родительского элемента.
Обычно вышеприведенный способ не очень популярный и чаще всего используются префиксы пространств имен. Но в некоторых случаях их можно опустить и использовать способ с заданием пространства имен по умолчанию. Чтобы не оставалось никаких вопросов рассмотрим аналогичный способ представления последнего примера.
<xsl:element xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xslt="http://xslt.com/xslt" xmlns:xlt="http://xlt.com/xlt"> <xsl:firstelement>Any content</xsl:firstelement> <xslt:secondelement>Any content</xslt:secondelement> <xlt:thirdelement> <xlt:one>Any content</xlt:one> <xlt:two>Any content</xlt:two> </xlt:thirdelement> ... </xsl:element>На этом мы заканчиваем рассмотрение пространств имен и в следующей статье поговорим об основных моментах описания структуры XML-документов при помощи DTD. Если вы не хотите пропустить выпуска новых статей, рекомендую подписаться на новостную рассылку, воспользовавшись формой подписки ниже.
На этом все. Удачи вам и успехов в изучении XML.
Обнаружили ошибку? Выделите ее и нажмите Ctrl+Enter
archive.dmitriydenisov.com
IT Notes: Основы XML
Для начала проведем краткий обзор, в котором попытаемся охватить основные идеи XML, увидеть концепцию в целом, не путаясь в деталях. Для этого рассмотрим основные положения:
1. XML — это способ записи структурированных данных
Под "структурированными данными" обычно подразумевают такие вещи, как электронные таблицы, адресные книги, конфигурационные параметры, финансовые транзакции, технические чертежи и так далее
2. XML немного похож на HTML
Также как и в HTML, в XML используются тэги (слова, заключенные в '<' и '>') и атрибуты (вида имя="значение"). Но если в HTML фиксируется смысловое значение каждого тэга и атрибута и часто то, как текст между ними будет выглядеть в браузере, в XML тэги используются только для логической разметки данных, и их интерпретация оставляется на усмотрение обрабатывающей программы
3. XML — это текст, но он не предназначен для чтения
Программы, которые работают с электронными таблицами, адресными книгами или другими структурированными данными, часто сохраняют эти данные на диск, используя либо двоичный, либо текстовый формат.
4. XML умышленно многословен
Так как XML — текстовый формат и использует тэги для разметки данных, XML-файлы почти всегда больше по размеру, чем аналогичные в двоичном формате. Это было сознательным решением разработчиков XML.
5. XML — это семейство технологий
Существует спецификация XML 1.0, в которой определяется, что такое "тэги" и "атрибуты". Но за XML 1.0 следует "семейство XML" — все более растущее множество модулей, предоставляющих полезные сервисы для решения важных и часто возникающих задач.
6. XML - модульная технология
XML позволяет вам определять новые форматы документов, комбинируя и повторно используя уже созданные. Поскольку два формата, разработанные независимо, могут иметь элементы или атрибуты с одинаковыми именами, при их комбинировании следует соблюдать осторожность (что должно отличать "<p>", обозначающий "paragraph" в одном формате, от "person" в другом?). Для устранения возможной путаницы при одновременном использовании разных форматов XML предоставляет механизм пространств имен. XSL и RDF являются хорошими примерами основанных на XML форматов, использующих пространства имен. XML Schema разработан для отражения подобной поддержки модульности на уровне определения структур XML-документа, облегчая процесс построения новой схемы на основе существующих.
7. Технология XML свободна от лицензирования, платформо-независима и хорошо поддерживаема
Выбирая XML в качестве основы для своего проекта, вы имеете доступ к большому и все более растущему семейству инструментов (один из которых уже, может, делает то, что вам нужно!) и опыту специалистов, работающих с этой технологией. Выбор XML немного похож на выбор SQL для баз данных: вы все еще должны строить свою базу данных и писать свои программы и процедуры для работы с ней, однако есть много инструментальных средств и людей, способных помочь вам. А так как XML свободен от лицензирования, вы можете строить свое программное обеспечение, не заплатив кому-либо ни копейки. Большая и все более растущая поддержка определяет то, что вы не привязаны к какому-либо конкретному производителю программ. XML — не всегда лучшее решение, но всегда стоит принимать его во внимание.
Что такое XML?
XML (eXtensible Markup Language) - это расширяемый язык разметки, предназначенный для описания в текстовой форме структурированных данных. Этот текстовый (text-based) формат, во многом схожий с HTML, разработан специально для хранения и передачи данных.
XML (eXtensible Markup Language) — это упрощенный диалект языка SGML, предназначенный для описания иерархических структур данных в World Wide Web. Он разрабатывается рабочей группой W3C с 1996 г.; в настоящее время принятой рекомендацией является вторая редакция языка XML 1.0 (октябрь 2000 г.).
XML, несомненно, входит в обойму наиболее перспективных технологий WWW, чем объясняется интерес, который уделяется ему и корпорациями-разработчиками, и широкой публикой. Прежде чем перейти к его описанию, представляется уместным обсудить причины его появления и последующего бурного развития. Попытаемся для этого взглянуть на те проблемы WWW, которые должны быть решены средствами нового поколения Веб-технологий.
HTML не выражает смысла документов.
Язык HTML был создан для описания структуры документов (название, заголовки, списки, абзацы и т. п.) и, в некоторой степени, правил их отображения (полужирный шрифт, курсивный шрифт и т. п.). Он ни в коей мере не предназначен для описания смысла написанных на нем документов, а во многих случаях именно данные составляют существо документа, будь-то биржевая сводка или научная публикация. Поэтому появилась необходимость в языке описания данных, причем данных, организованных в иерархические структуры.
HTML громоздок и негибок.
За последние годы HTML превратился в нагромождение тегов, которые часто дублируют друг друга и отнюдь не вносят ясности в текст документа. Если добавить сюда еще и нестандартные расширения HTML, которыми грешат все разработчики обозревателей, то создание мало-мальски сложных HTML-документов становится серьезной задачей. С другой стороны, раз и навсегда зафиксированный набор тегов часто оказывается недостаточно гибким для выражения нужного нам содержания.
Концепция Веб-обозревателя слишком ограничена.
С появлением Java-аплетов, сценарных языков и элементов ActiveX Веб-обозреватели перестали быть простыми "отображателями" HTML-документов; сегодня скорее они выглядят как программы, запускающие конкретные приложения. Тем не менее, сама концепция обозревателя накладывает излишние ограничения на пользователя; во многих случаях нам нужны Веб-ориентированные приложения, т. е. программы, способные читать специализированную информацию с Веб-узлов и выдавать нам ее в привычном виде, например, в виде электронных таблиц.
Поиск документов возвращает слишком много ссылок.
Все мы постоянно пользуемся поисковыми системами и постоянно клянем их за неудобство работы. Допустим, что мне нужны все тексты книг Сергея Довлатова, имеющиеся в Сети. Попытка поиска по имени автора приведет к тому, что я получу список всех ссылок с этим именем, включая воспоминания о Довлатове, рецензии на его книги и т. д. Намного удобнее было бы воспользоваться специальным тегом <AUTHOR>, чтобы указать, что именно я ищу.
Невозможно найти взаимосвязанные ресурсы.
Допустим теперь, что я все же нашел несколько рассказов Довлатова, которые явно составляют единый сборник. Хорошо, если они содержат ссылку на оглавление, но часто это не так. Поэтому необходим способ указания того, что данная группа страниц составляет единый ресурс и должна обрабатываться соответственно. Для этого необходима стандартизованная и развитая система метаописателей Веб-страниц.
XML — это попытка решить перечисленные проблемы путем создания простого языка разметки, описывающего произвольные структурированные данные. Точнее говоря, это метаязык, на котором пишутся специализированные языки, описывающие данные определенной структуры. Такие языки называются XML-словарями. В отличие от HTML, XML не содержит никаких указаний на то, как описанные в XML-документе данные должны отображаться. Способ отображения данных для различных устройств задается языком описания стилей XSL, который играет для XML примерно ту же роль, что CSS дл HTML. Другое принципиальное его отличие от HTML состоит в том, что XML может содержать любые теги, которые сочтут нужным использовать создатели XML-словаря. Приведем список лишь нескольких специализированных языков на базе XML, которые сегодня находятся в разных стадиях разработки рабочими группами W3C:
- MathML — язык математических формул;
- SMIL — язык интеграции и синхронизации мультимедийных средств;
- SVG — язык двумерной векторной графики;
- RDF — язык метаописаний ресурсов;
- XHTML — переформулировка HTML в терминах XML.
Процесс обработки XML-документа состоит в следующем. Его текст анализируется специальной программой, которая называется XML-процессором. XML-процессор ничего не знает о семантике данных в документе; он только производит синтаксический разбор (parsing) текста документа и проверяет его правильность с точки зрени правил XML. Если документ правильно оформлен (well-formed), то результаты разбора текста передаются XML-процессором прикладной программе, которая выполняет их содержательную обработку; если же документ оформлен неверно, т. е. содержит синтаксические ошибки, то XML-процессор должен сообщить о них пользователю.
Итого: XML позволяет описывать и передавать такие структурированные данные, как:
- отдельные документы
- метаданные, описывающие содержимое какого-либо узла Internet
- объекты, содержащие данные и методы работы с ними (например, элементы управления ActiveX или объекты Java)
- отдельные записи (например, результаты выполнения запросов к базам данных)
- всевозможные Web-ссылки на информационные и людские ресурсы Internet (адреса электронной почты, гипертекстовые ссылки и пр.)
Применения XML
Возникает вопрос: а какой смысл в использовании "пустого языка", лишенного собственного содержания? Дело в том, что, несмотря на внешнюю простоту, XML обладает достаточно изощренными механизмами контроля правильности данных, позволяет производить проверку иерархических отношений внутри документа, и, самое главное, устанавливает единый стандарт для документов, хранящих данные, какова бы ни была природа этих данных. Остановимся подробнее на некоторых сферах применения языка XML.
Традиционная обработка данных
Перечисленные выше возможности позволяют рассматривать XML как платформо-независимый стандарт хранения и представления информации, который в сочетании с другими современными технологиями (в частности, с технологиями Java) способен стать основой для создания любых машинно-независимых приложений, в т. ч. для обмена данными между сервером и клиентом. Кроме того, активно разрабатываемые сегодня языки запросов на базе XML могут составить серьезную конкуренцию языку SQL.
Программирование, управляемое документом
XML-документы могут служить контейнерами для построения приложений из существующих интерфейсов и компонентов. В этом случае документ состоит из ссылок на компоненты пользовательского интерфейса и модули обработки данных, которые связываются в процессе отображения страницы на экране.
Архивирование компонентов
Современное программирование базируется на использовании компонентов, которые в идеале должны легко собираться в единое целое с помощью несложного дополнительного кодирования. Основой для этого служит архивирование компонентов, которое, в свою очередь, требует единообразного подхода к их хранению и последующему использованию. Есть все основания полагать, что в ближайшем будущем XML-документы окажутся альтернативой распространенному сегодня хранению компонентов в виде двоичных модулей.
Внедрение данных
После того, как мы определили структуру данных XML, принципиально несложно написать генератор кода, обрабатывающего эти данные. По мере развития подобных программных средств вся рутинная обработка данных (включая проверку их правильности, представление в нужном формате и т. п.) может быть автоматизирована, позволяя разработчикам сосредоточиться на нестандартных частях создаваемого продукта.
kavayii.blogspot.com
Основы XML - разметка и структура XML документов
В данной статье мы начинаем изучение языка XML и подробно рассмотрим такие моменты, как разметка и структура XML-документа. Данная информация есть базовой в изучении XML, поэтому рекомендую тщательно проработать этот материал, чтобы не оставалось никаких вопросов. От этого зависит ваш успех в будущем и скорость изучения как самого XML, так и XSLT, который мы будем изучать сразу после освоения XML.
Итак, XML (eXtensible Markup Language) – это язык для текстового выражения информации в стандартном виде. Сам по себе он не имеет операторов и не выполняет никаких вычислений. Таким образом, XML – это метаязык, главной задачей которого есть описание новых языков документа.
Чтобы лучше понять суть вышесказанного, давайте перейдем непосредственно к примерам и первым делом рассмотрим разметку XML-документов.
Разметка XML документов
Разметка XML-документа практически ничем не отличается от разметки обычного HTML-документа (Как создать HTML страницу. HTML теги и атрибуты. Работа с текстом, списками и изображениями в HTML). Одним из преимуществ XML являет то, что он позволяет создавать неограниченное количество тегов. Таким образом, каждый тег имеет свою семантику, то есть несет определенный смысл. Для наглядности давайте рассмотрим XML-документ со списком книг.
<books> <book> <author>Автор 1</author> <name>Название 1</name> <price>Цена 1</price> </book> <book> <author>Автор 2</author> <name>Название 2</name> <price>Цена 2</price> </book> <book> <author>Автор 3</author> <name>Название 3</name> <price>Цена 3</price> </book> </books>Как видно с примера выше, все очень банально и просто. При этом XML-документ несет куда более подробную информацию по сравнению с обычным HTML-документом. В нашем примере очень просто понять, что тег <author> отвечает за автора книги, тег <name> — за название, тег <price> — за цену и т.д. Таким образом, каждый тег имеет свой смысл.
Одной из самых важных особенностей XML-документов является то, что их можно легко обрабатывать программно. Например, обработав пример вышеприведенного текста, можно с легкостью получить нужную информацию по книгам, вывести цены на книги по их названиям и т.д. При этом полностью сохраняется возможность визуального представления документа. Для этого достаточно лишь определить, как будет выглядеть тот или иной элемент.
Таким образом, XML позволяет отделять данные от их представления и создавать в текстовом виде документы со структурой, указанной явным образом. Если быть точным, то только лишь за счет расширения количества тегов мы сделали следующее:
- Явным образом выделили в XML-документе структуру, что в свою очередь сделало возможным дальнейшую программную обработку документа, например, при помощи технологии XSLT, которую мы будем изучать чуть позже. При этом одной из главных особенностей является то, что данный документ по прежнему остается понятным обычному человеку.
- Отделили данные в XML-документе от того, каким образом они должны быть представлены визуально. Это в свою очередь дало широкие возможности для публикации данных на разных носителях, например, на бумаге или в сети интернет.
Подводя итог вышесказанному, можно сделать вывод, что синтаксически в XML практически нет ничего нового по сравнению с HTML. XML является таким же текстом, размеченным тегами. Единственная разница лишь в том, что XML позволяет создавать любую разметку, которая может понадобиться для описания документа, при том как в HTML существует лишь ограниченный набор тегов, которые можно использовать.
Одним словом, XML является очень простым языком с небольшим набором основных конструкций, но в то же время он предоставляет неограниченные возможности для описания данных. Таким образом, каждый разработчик как бы сам изобретает свой собственный язык, который ограничивается лишь фантазией самого разработчика.
Структура XML документов
Для того чтобы представить структуру XML документов давайте рассмотрим самый простой пример документа XML.
<?xml version="1.0" encoding="utf-8"?> <pricelist> <book> <title>Книга 1</title> <author>Автор 1</author> <price>Цена 1</price> </book> <book> <title>Книга 2</title> <author>Автор 2</author> <price>Цена 2</price> </book> <book> <title>Книга 3</title> <author>Автор 3</author> <price>Цена 3</price> </book> </pricelist>Итак, мы видим, что данный пример практически ничем не отличается от предыдущего за исключением немного изменившихся тегов и нескольких атрибутов. Главное отличие здесь заключается в первой строчке, которая определяет файл как XML документ, построенный в соответствии с первой версией языка. Более подробно об этом мы поговорим в следующих статьях рубрики «Уроки XML и XSLT».
На данный момент нам важнее всего понять, что это очень простой язык, который очень похож на обычный HTML. В примере выше мы видим, что XML тоже имеет теги, которые могут быть вложенными, то есть содержать внутри себя другие теги. При этом теги в XML не просто ограничивают часть текста, а формируют отдельный элемент. Исходя из этого, то, что выделено тегами, в XML принято называть элементами.
Стоит также заметить, что в XML есть также атрибуты, комментарии и множество других элементов и конструкций. К сожалению одной статьи недостаточно для того чтобы обо всем подробно написать, поэтому будут написаны отдельные статьи по каждой теме. Если вы не хотите их пропустить, то рекомендую подписаться на новостную рассылку любым удобным для вас способом в пункте «Подписка» либо воспользоваться формой ниже.
На этом все. Удачи вам и успехов в изучении основ XML.
Обнаружили ошибку? Выделите ее и нажмите Ctrl+Enter
archive.dmitriydenisov.com
Основы XML для Java программиста
Вступление
Здравствуйте, дорогие читатели моей статьи. Это уже вторая статья из цикла про XML, и в данной статье будет рассказывать про XML Namespace и XML Schema. Буквально недавно, мне самому ничего про это известно не было, однако я осилил немало материала и буду пытаться объяснить простыми словами эти две важные темы. Сразу хочу сказать, что схемы – очень продвинутый механизм валидации XML документов и значительно более функциональный, чем DTD, потому полного его изучения от и до тут не будет. Давайте приступать :)
Буквально недавно, мне самому ничего про это известно не было, однако я осилил немало материала и буду пытаться объяснить простыми словами эти две важные темы. Сразу хочу сказать, что схемы – очень продвинутый механизм валидации XML документов и значительно более функциональный, чем DTD, потому полного его изучения от и до тут не будет. Давайте приступать :) XML Namespace
Namespace значит «пространство имён», однако в этой статье я буду часто подменивать русское выражение на просто namespace, ибо это короче и комфортнее для понимания. XML Namespace – это технология, основная цель которой - сделать так, чтобы все элементы были уникальными в XML файле и не было путаницы. И так, как это Java курсы, то такая же технология есть и в Java – пакеты. Если бы можно было поместить два класса с одинаковым именем рядом и использовать их, то как мы бы определили, какой класс нам нужен? Эта проблема решена пакетами – мы можем просто разместить классы в разные пакеты и импортировать их оттуда, точно указав имя нужного пакета и путь к нему, или просто указав полный путь к нужному классу. Теперь, мы можем сделать так: public class ExampleInvocation { public static void main(String[] args) { example_package_1.Example example1 = new example_package_1.Example(); example_package_2.Example example2 = new example_package_2.Example(); example_package_3.Example example3 = new example_package_3.Example(); } } В XML Namespace все примерно так же, только немного по-другому. Суть такая же: если элементы одинаковые (как классы), то мы просто должны использовать их в разных namespace’ах (указывать пакеты), тогда даже если имена элементов (классов) станут совпадать, мы все равно будем обращаться к конкретному элементу из пространства (пакета). Для примера: у нас в XML есть два элемента – предсказание (oracle) и БД Oracle. <?xml version="1.0" encoding="UTF-8"?> <root> <oracle> <connection value="jdbc:oracle:thin:@10.220.140.48:1521:test1" /> <user value="root" /> <password value="111" /> </oracle> <oracle> Сегодня вы будете заняты весь день. </oracle> </root> И когда мы будем обрабатывать данный XML файл, мы будем серьезно запутаны, если вместо базы данных нам придет предсказание, и обратно тоже. Для того, чтобы разрешить коллизию элементов, мы можем каждому из них выделить своё собственное пространство, чтобы различать их. Для этого есть специальный атрибут – xmlns:префикс= «уникальное значение для namespace”. После чего, мы можем использовать префикс перед элементами, чтобы указывать, что он является частью этого namespace (по сути, мы должны создать путь к пакету - namespace, а потом перед каждым элементом указывать префиксом, к какому пакету он принадлежит). <?xml version="1.0" encoding="UTF-8"?> <root> <database:oracle xmlns:database="Unique ID #1"> <connection value="jdbc:oracle:thin:@10.220.140.48:1521:test1" /> <user value="root" /> <password value="111" /> </database:oracle> <oracle:oracle xmlns:oracle="Unique ID #2"> Сегодня вы будете заняты весь день. </oracle:oracle> </root> В данном примере мы объявили два пространства имён: database и oracle. Теперь перед элементами можно использовать префиксы namespace’ов. Не нужно пугаться, если сейчас что-то неясно. На самом деле – это очень просто. Сначала, я хотел написать эту часть статьи более быстро, однако после среды я решил, что нужно уделить больше внимания данной теме, так как тут легко запутаться или в чем-то не разобраться. Сейчас будет очень много внимания уделено атрибуту xmlns. И так, еще пример: <?xml version="1.0" encoding="UTF-8"?> <root xmlns="https://www.standart-namespace.com/" xmlns:gun="https://www.gun-shop.com/" xmlns:fish="https://www.fish-shop.com/"> <gun:shop> <gun:guns> <gun:gun name="Revolver" price="1250$" max_ammo="7" /> <gun:gun name="M4A1" price="3250$" max_ammo="30" /> <gun:gun name="9mm Pistol" price="450$" max_ammo="12" /> </gun:guns> </gun:shop> <fish:shop> <fish:fishes> <fish:fish name="Shark" price="1000$" /> <fish:fish name="Tuna" price="5$" /> <fish:fish name="Capelin" price="1$" /> </fish:fishes> </fish:shop> </root> Вы можете видеть обычный XML, где используются пространства gun для уникальных элементов оружейного магазина и fish для уникальных элементов рыболовного магазина. Можно увидеть, что создав пространства, мы использовали один элемент shop сразу к двум разным вещам – магазину оружия и магазину рыбы, и нам точно известно, что это за магазин, благодаря тому, что объявили пространства. Самое интересно начнется в схемах, когда мы сможем таким образом еще валидировать разные структуры с одними элементами. xmlns – атрибут для объявления namespace’а, указывать его можно в любом элементе. Пример объявления namespace’а: xmlns:shop= «https://barber-shop.com/» После двоеточия находится префикс – это ссылка на пространство, которая потом может использоваться перед элементами, чтобы указывать, что они родом из этого пространства. Значение xmlns должно быть УНИКАЛЬНОЙ СТРОКОЙ. Это крайне важно понимать: очень часто используются ссылки на сайты или URI, чтобы объявить namespace. Это правило является стандартом, так как URI или URL ссылки являются уникальными, НО именно данный момент очень запутывает. Просто запомните: значением может быть ЛЮБАЯ строка, какая вы захотите, но для точной уникальности и стандарта нужно использовать URL или URI адреса. То, что можно использовать любые строки, показано в примере в oracle: xmlns:oracle="Unique ID #2" xmlns:database="Unique ID #1" Когда вы объявляете namespace, вы можете его использовать в самом элементе и во всех элементах внутри него, потому объявленные в root элементе namespace’ы можно использовать во всех элементах. Это можно видеть в последнем примере, и вот более конкретный пример: <?xml version="1.0" encoding="UTF-8"?> <root> <el1:element1 xmlns:el1="Element#1 Unique String"> <el1:innerElement> </el1:innerElement> </el1:element1> <el2:element2 xmlns:el2="Element#2 Unique String"> <el2:innerElement> </el2:innerElement> </el2:element2> <el3:element3 xmlns:el3="Element#3 Unique String"> <el3:innerElement> <el1:innerInnerElement> <!-- Так нельзя, потому что пространство el1 объявлено только в первом элементе, потому может использовать только внутри первого элемента и его внутренних элементов. --> </el1:innerInnerElement> </el3:innerElement> </el3:element3> </root> Тут важная деталь: существует так же стандартный namespace в root элементе. Если вы объявили другие namespace’ы, вы стираете стандартное и не можете его использовать. Тогда перед root элементом нужно поставить какой-то префикс пространства, любой, который вы объявили ранее. Однако, это можно так же обхитрить: вы можете объявить стандартное пространство явно. Достаточно просто не использовать префикс после xmlns, а сразу записать какое-то значение, и все ваши элементы без префикса станут принадлежать именно этому namespace’у. В последнем примере это было использовано: <root xmlns="https://www.standart-namespace.com/" xmlns:gun="https://www.gun-shop.com/" xmlns:fish="https://www.fish-shop.com/"> Мы объявили стандартное пространство явно, чтобы избежать необходимости использовать gun или fish, так как рут элемент не является сущностью ни рыболовного магазина, ни оружейного, потому использование любого пространства было бы уже логически неправильным. Далее: если вы создали xmlns:a и xmlns:b, но у них одно значение, то это одинаковое пространство и они не уникальные. Потому и нужно использовать всегда уникальные значения, ведь нарушение этого правила может создать большое количество ошибок. Например, если бы у нас было так объявлены пространства: xmlns="https://www.standart-namespace.com/" xmlns:gun="https://www.gun-shop.com/" xmlns:fish="https://www.gun-shop.com/" То наш рыболовный магазин стал бы оружейным, а префикс был бы все еще рыбного магазинчика. Это все основные моменты пространств. Я довольно много времени потратил на то, чтобы собрать их все и сократить, а потом ясно выразить, так как информация по пространствам в Интернете очень огромная и часто одна вода, потому большая часть всего, что тут есть – я узнал это сам пробами и ошибками. Если у вас остались вопросы, то можете попробовать ознакомиться с материалами по ссылкам в конце статьи.XML Schema
Сразу хочу сказать, что в данной статье будет только верхушка айсберга, так как тема очень обширная. Если вы захотите ознакомиться более подробно со схемами и научиться писать их самому любой сложности, то в конце статьи будет ссылка, где будет все про разные типы, ограничения, расширения и так далее. Начать хочу с теории. Схемы обладают форматом .xsd (xml scheme definition) и являются более продвинутой и популярной альтернативой DTD: они способны так же создавать элементы, описывать их и так далее. Однако, добавлено очень много бонусов: проверка типов, поддержка нэймспэйсов и более широкий функционал. Помните, когда мы говорили про DTD, там был минус, что он не поддерживает пространства? Теперь, когда мы это изучили, объясняю: если бы можно было импортировать две и более схемы с DTD, где были бы одинаковые элементы, у нас были бы коллизии (совпадения) и нельзя было бы их использовать вообще, ведь неясно, какой элемент нам нужен. В XSD данная проблема решена, ведь вы можете импортировать схемы в одно конкретное пространство и использовать его. По сути, у каждой XSD схемы есть целевое пространство, которое означает, в какое пространство должна быть записана схема в XML файле. Таким образом, в самом XML файле нам нужно просто создать эти заранее определенные в схемах пространства и назначить префиксы для них, а потом подключить в каждое из них нужные схемы, после чего мы можем спокойно использовать элементы из схемы, подставляя префиксы из того пространства, куда мы импортировали схемы. И так, у нас есть пример: <?xml version="1.0" encoding="UTF-8"?> <house> <address>ул. Есенина, дом №5</address> <owner name="Ivan"> <telephone>+38-094-521-77-35</telephone> </owner> </house> Мы хотим валидировать его с помощью схемы. Для начала, нам нужна схема: <?xml version="1.0"?> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="https://www.nedvigimost.com/"> <element name="house"> <complexType> <sequence> <element name="address" type="string" maxOccurs="unbounded" minOccurs="0" /> <element name="owner" maxOccurs="unbounded" minOccurs="0" > <complexType> <sequence> <element name="telephone" type="string" /> </sequence> <attribute name="name" type="string" use="required"/> </complexType> </element> </sequence> </complexType> </element> </schema> Как вы видите, схемы – это тоже XML файлы. Вы прямо на XML языке расписываете то, что вам нужно. Данная схема способна валидировать XML файл из примера выше. Например: если у овнера не будет имени, то схема это увидит. Так же, благодаря элементу sequence, всегда должен идти сначала адрес, а потом владелец дома. Есть элементы обычные и комплексные. Обычные элементы – это элементы, которые хранят в себя только какой-то тип данных. Пример: <element name="telephone" type="string" /> Так мы объявляем элемент, который хранит в себе строку. Других элементов быть внутри этого элемента не должно. Так же есть комплексные элементы. Комплексные элементы способны хранить внутри себя другие элементы, атрибуты. Тогда тип указывать не нужно, а достаточно внутри элемента начать писать комплексный тип. <complexType> <sequence> <element name="address" type="string" maxOccurs="unbounded" minOccurs="0" /> <element name="owner" maxOccurs="unbounded" minOccurs="0" > <complexType> <sequence> <element name="telephone" type="string" /> </sequence> <attribute name="name" type="string" use="required"/> </complexType> </element> </sequence> </complexType> Так же можно было поступить по-другому: можно было создать комплексный тип отдельно, а потом подставлять его в type. Только во время написания этого примера, почему-то нужно было объявить пространство под каким-то префиксом, а не использовать стандартное. В общем, получилось вот так вот: <?xml version="1.0"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="https://www.nedvigimost.com/"> <xs:element name="house" type="content" /> <xs:complexType name="content"> <xs:sequence> <xs:element name="address" type="xs:string" maxOccurs="unbounded" minOccurs="0" /> <xs:element name="owner" maxOccurs="unbounded" minOccurs="0" > <xs:complexType> <xs:sequence> <xs:element name="telephone" type="xs:string" /> </xs:sequence> <xs:attribute name="name" type="xs:string" use="required"/> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:schema> Таким образом, мы можем создавать наши собственные типы отдельно, а потом подставлять их куда-либо в атрибут type. Это очень удобно, так как позволяет использовать один тип в разных местах. Хотелось бы еще поговорить про подключение схем и закончить на этом. Есть два способа подключить схему: в конкретное пространство и просто подключить.Первый способ подключения схемы
Первый способ подразумевает, что у схемы есть конкретное целевое пространство. Оно указывается с помощью атрибута targetNamespace у элемента scheme. Тогда достаточно создать ЭТО САМОЕ пространство в XML файле, после чего «загрузить» туда схему: <?xml version="1.0" encoding="UTF-8"?> <nedvig:house xmlns:nedvig="https://www.nedvigimost.com/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://www.nedvigimost.com/ example_schema1.xsd"> <address>ул. Есенина, дом №5</address> <owner name="Ivan"> <telephone>+38-094-521-77-35</telephone> </owner> </nedvig:house> Важно понимать две строчки: xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemeLocation="https://www.nedvigimost.com/ example_schema1.xsd" Первая строчка – просто запомните её. Считайте, что это объект, который помогает загружать схемы туда, куда надо. Вторая строчка – уже конкретная загрузка. schemaLocation принимает список значений вида «значение – значение», разделенные пробелом. Первый аргумент – пространство имён, которое должно соответствовать целевому пространству имён в схеме (значению targetNamespace). Второй аргумент – относительно или абсолютный путь к схеме. И так, как это СПИСОК значение, то вы можете после схемы в примере поставить пробел, и снова ввести целевое пространство и имя другой схемы, и так сколько захотите. Важно: чтобы схема потом валидировала что-либо, вам нужно объявить это пространство и с префиксом использовать. Посмотрите внимательно последний пример: <?xml version="1.0" encoding="UTF-8"?> <nedvig:house xmlns:nedvig="https://www.nedvigimost.com/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://www.nedvigimost.com/ example_schema1.xsd"> <address>ул. Есенина, дом №5</address> <owner name="Ivan"> <telephone>+38-094-521-77-35</telephone> </owner> </nedvig:house> Мы создали это целевое пространство на префиксе nedvig, а потом использовали его. Таким образом, наши элементы начали валидироваться, так как мы начали использовать пространство, куда ссылается целевое пространство схемы.Второй способ подключения схемы
Второй способ подключения схемы подразумевает, что у схемы нет конкретного целевого пространства. Тогда вы можете просто подключить её к XML файлу и она будет валидировать его. Делается почти так же, только вы можете не объявлять пространства вообще в XML файле, а просто подключить схему. <?xml version="1.0" encoding="UTF-8"?> <house xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="example_schema1.xsd"> <address>ул. Есенина, дом №5</address> <owner name="Ivan"> <telephone>+38-094-521-77-35</telephone> </owner> </house> Как вы видите, делается это с помощью noNamespaceSchemaLocation и указанием пути к схеме. Даже если у схемы нет целевого пространства, документ будет валидироваться. И последний штрих: мы можем импортировать в схемы другие схемы, после чего использовать элементы из одной схемы в другой. Таким образом, мы можем использовать в одних схемах элементы, которые есть уже в других. Пример:Схема, где объявляется тип owner:
<?xml version="1.0" encoding="UTF-8" ?> <schema targetNamespace="bonus" xmlns="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> <complexType name="owner"> <all> <element name="telephone" type="string" /> </all> <attribute name="name" type="string" /> </complexType> </schema>Вторая схема, где используется тип owner из первой схемы:
<?xml version="1.0" encoding="UTF-8"?> <schema targetNamespace="main" xmlns="http://www.w3.org/2001/XMLSchema" xmlns:bonus="bonus" elementFormDefault="qualified"> <import namespace="bonus" schemaLocation="xsd2.xsd" /> <element name="house"> <complexType> <all> <element name="address" type="string" /> <element name="owner" type="bonus:owner" /> </all> </complexType> </element> </schema> Во второй схеме используется конструкция: <import namespace="bonus" schemaLocation="xsd2.xsd" /> С помощью неё мы импортировали типы и элементы из одной схемы в другую в пространство bonus. Таким образом, мы получили доступ к типу bonus:owner. А в следующей строчке мы его использовали: <element name="owner" type="bonus:owner" /> Так же небольшое внимание следующей строчке: elementFormDefault="qualified" Этот атрибут объявляется в schema и означает, что в XML файлах каждый элемент должен объявляться с явным префиксом перед ним. Если его нет, то нам достаточно объявить внешний элемент с префиксом, а так нужно выставлять префиксы и во всех элементах внутри, явно указывая, что мы используем именно элементы этой схемы. И вот, собственно, пример XML файла, валидируемого схемой, которая импортировала другую схему: <?xml version="1.0" encoding="UTF-8"?> <nedvig:house xmlns:nedvig="main" xmlns:bonus="bonus" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="main xsd.xsd"> <nedvig:address>ул. Есенина, дом №5</nedvig:address> <nedvig:owner name="Ivan"> <bonus:telephone>+38-094-521-77-35</bonus:telephone> </nedvig:owner> </nedvig:house> В строчке: <bonus:telephone>+38-094-521-77-35</bonus:telephone> Нам нужно явно объявлять пространство имён bonus, указывающее на целевое пространство первой схемы, так как elementFormDefault у нас в qualified (проверять), потому все элементы должны явно указывать свое пространство.Конец статьи
Следующая статья будет последней в цикле и там уже будет про обработку XML файлов средствами Java. Мы будем обучаться доставать информацию разными способами и так далее. Надеюсь, что эта статья была полезной и, даже если тут есть где-то ошибки, научит вас чему-то полезному и новому, а может просто даст возможность лучше понимать XML файлы. Для тех, кто хотел бы изучить это более подробно, я решил собрать небольшой набор ссылок:- XSD Simple Elements - начиная с этой статьи начинайте читать и идите вперед, там собрана вся информация по схемам и рассказывается более-менее понятно, только на английском. Можете использовать переводчик.
видео по пространствам имён, всегда полезно послушать другую точку зрения на что-либо, если первая не ясна.
- XML пространства имен - хороший пример использования пространств имён и довольно укомплектованная информация.
- Основы XML — пространства имен - еще одна небольшая статья по пространствам имён.
- Основы использования XML Schema для определения элементов - тоже крайне полезная ссылка по схемам, только читать нужно медленно и внимательно, вникая в материал.
javarush.ru
Тема Основы xml лекция Создание и отображение xml-документа
Тема 2. Основы XMLЛекция 3. Создание и отображение XML-документаПлан 1. Определение и структура XML-документа 2. Создание XML-документа 3. Способы отображения XML-документа. 4. Правила создания корректного XML-документа 1. Определение и структура XML-документаЛюбой документ можно представить в виде некого набора символов, разделенных на две группы: первая группа определяет содержимое документа, вторая – специальные наборы символов (теги), служащие для специфического выделения или пометки некоторых частей первой группы. В XML-документах первая группа носит название "текст" или "контент", а вторая, представляющая собой систему обозначений, которые поддаются интерпретации, называется разметкой. В языке HTML, к примеру, к разметке относятся все теги, без исключения.Разметка XML-документа представляет собой несколько более сложное понятие, чем в языке HTML. Это связано с тремя следующими обстоятельствами: 1. XML-документ может содержать инструкции обработки самого себя. Это означает, что обработчик XML-документа (процессор) является посредником между этим документом и некоторым приложением или приложениями. Такими приложениями могут быть базы данных, сервер каталога, язык программирования, работающий на стороне сервера, и т. п. 2. Синтаксис языка XML определен весьма жестко и не допускает многозначного толкования своих правил. Причем любое отклонение от этих правил влечет за собой отказ процессора обрабатывать весь документ. Поэтому в языке XML количество ограничений на синтаксис документа, о которых необходимо помнить разработчику, гораздо больше, чем в языке HTML. 3. В отличие от языка HTML, разработчик XML-документов сам определяет названия тегов и, может быть, правила их интерпретации. Если такие правила присутствуют, то они отделены от непосредственно XML-кода и образуют так называемый сценарий XSLT (XSL Transformation). Иными словами, если XML-файл служит не только для хранения каких-либо данных, но и для их представления, (например, в браузере), то способы представления этих данных вынесены в отдельный XSL-файл (XSL – расширяемый язык стилей). Структура информации, содержащейся в XML-файле, представляет собой иерархическую модель данных (как и HTML-документа), то есть, вся символьная информация: разметка или контент представляет собой совокупность узлов некоторого дерева. По правилам XML в корректном документе должен присутствовать единственный корневой элемент. Все остальные элементы являются его непосредственными потомками или потомками других его потомков. Процесс обработки такого документа начинается с первого или корневого элемента, затем обрабатываются узлы дерева второго уровня, затем — третьего и т. д. Подавляющее большинство ошибок возникает в результате того, что наборы символов размечены не однозначно, т. е. процессор не может определить, к какому именно узлу следует отнести данный набор. 2. Создание XML-документаXML-документ представляет собой обычный текстовый файл, в котором при помощи специальных тегов создаются элементы данных, последовательность и вложенность которых определяет структуру документа и его содержание.2.1. Структура XML-документаКак и HTML-документ, XML-документ состоит из двух частей: Заголовка (пролога) (как тег HEAD в HTML) и элемента Документ (его также называют корневым элементом).Рассмотрим еще один пример XML-документа. Важная деловая встреча Надо встретиться с Иваном Ивановичем, предварительно позвонив ему по телефону 123-12-12 ... Позвонить домой 124-13-13 Вопрос. Как называется в этом примере корневой элемент? Заголовок XML-документа Заголовок (пролог) согласно спецификации языка XML, подчиняется следующим правилам синтаксиса: 1) заголовок должен начинаться с символов ; 2) перед начальными символами заголовка не должно быть других символов; 3) заголовок должен заканчиваться символами ?> ; 4) после начальных символов должно стоять слово xml; 5) указание версии с помощью конструкции version =" . . . " обязательно; 6) номер версии на данный момент — 1.0; 7) номер версии должен быть заключен в кавычки. Помимо номера версии заголовок XML- документа может включать в объявление кодировки документа, которая определяется с помощью конструкции encoding =". . . ". Например: , или Элемент Документ Второй основной частью XML-документа является единый элемент Документ, или корневой элемент, который в свою очередь содержит дополнительные элементы. Примечание. Элемент Документ в XML-документе похож на элемент BODY на HTML-странице, за исключением того, что вы можете присвоить ему любое допустимое имя. Важно! 1. Язык XML является чувствительным к регистру символов, поэтому как открывающий, так и закрывающий теги должны быть записаны символами в одном регистре. Неверно Верно content content content tag и Tag – это разные теги в отличие от HTML! 2. Не допускается один или несколько пробелов перед открывающей скобкой тега, хотя в любом другом месте пробелы допустимы, То же касается и символов концов строк. Таким образом, будут верными, например, такие два варианта кода: ... и attl="l" att2="2" > …………….. 3. Применение закрывающего тега всегда обязательно! Mark Twain mass market paperback 298 $5.49 Herman Melville trade paperback 605 $4.95 Nathaniel Hawthorne trade paperback 253 $4.25 Имена элементов в XML-документе (такие как INVENTORY, BOOK и TITLE в приведенном выше примере) не являются определениями языка XML. Вы всего лишь назначаете эти имена при создании определенного документа. Для ваших элементов вы можете выбирать любые корректно заданные имена (LIST вместо INVENTORY, либо ITEM вместо BOOK). Примечание. Хотя нет спец. запрещений, лучше имена элементов писать латиницей. В предыдущем примере XML-документ имеет иерархическую структуру в виде дерева с элементами, вложенными в другие элементы, и с одним элементом верхнего уровня (в нашем примере – INVENTORY) – он носит название элемент Документ или корневой элемент, – который содержит все другие элементы. Структуру описанного в примере документа можно представить, как показано на рисунке. Таким образом, с помощью XML вы можете описать иерархическую структуру документа, такого как книга, содержащего части, главы и разделы. 3. Способы отображения XML-документа Есть три основных способа сообщить браузеру как обрабатывать и отображать каждый из созданных XML-элементов.
Если XML-документ не содержит связи с таблицей стилей, Internet Explorer помечает различные составные части документа различным цветом, чтобы облегчить их распознавание, а также представляет элемент Документ в виде иерархического дерева с возможностью свертывания и развертывания структуры и просмотра с меньшей или большей степенью детализации. Если же XML-документ имеет связь с таблицей стилей, Internet Explorer отобразит только символьные данные из элементов документа, отформатировав их в соответствии с правилами, установленными в таблице стилей. 4. Правила создания корректного XML-документа4.1. Определение корректного документаКорректно сформированным (правильно оформленным, well-formed) называется документ, отвечающий минимальному набору критериев соответствия для ХМL-документа. Когда вы создаете корректно сформированный XML-докуменг, вы можете добавлять элементы и вводить данные непосредственно в ваш документ, как вы это делаете при создании HTML-документов.Имена, которые вы присваиваете элементу (тегу), называются типом элемента. Правила создания корректного документа:
Вопрос. Найти ошибку в приведенной выше строке. 4.2. Составные части корректно сформированного ХМL-документаКак мы уже знаем, XML-документ состоит из двух основных частей: пролога и элемента Документ (корневого элемента). Помимо этого, корректно сформированный XML-документ может содержать комментарии, инструкции по обработке, пробелы. На следующем рисунке приведен пример корректно сформированного XML-документа, отражающий различные части документа и включения, которые вы можете добавлять в каждую из частей.Примечание. XML-объявление в этом примере также включает в себя объявление документа автономным (standalone='yes'). Это объявление может использоваться в некоторых XML-документах с целью упростить обработку документа. В рассматриваемом примере имеется комментарий в прологе, а также другой комментарий, следующий за элементом Документ. 4.3. Наименьший XML-документПролог рассматриваемого XML-документа содержит примеры каждого из разрешенных внутри пролога включений. Заметим, однако, что все эти включения не являются обязательными (хотя в спецификации XML заявлено, что вам «следует» включать XML-объявление). Следовательно, и сам пролог является необязательным, что подтверждается следующим минимальным документом, который содержит только элемент Документ, в соответствии с XML-стандартом для корректно сформированного документа.A minimalist document. 4.4. Добавление элементов в документПонятие элемента (element) является главнейшим в языке XML. Элемент представляет собой логические скобки, в которые помещается информация, выделенная из общего контента документа. Эти логические скобки являются открывающим и закрывающим тегами, либо, в том случае, когда у элемента отсутствует содержимое, это будет тег пустого элемента. Синтаксис записи тегов почти ничем не отличается от их аналога в языке HTML.В XML-документе элементы определяют его логическую структуру и несут в себе информацию, содержащуюся в документе. Типовой элемент состоит из начального тега, содержимого элемента и конечного тега. Содержимым элемента могут быть символьные данные, другие (вложенные) элементы, либо сочетание данных и вложенных элементов. Каждый элемент содержит ряд вложенных элементов, как показано на следующем рисунке. Примечание. Имя, которое содержится в начальном и конечном теге, есть тип элемента. Каждый из элементов, вложенных в элемент BOOK, например, элемент TITLE, содержит только символьные данные, как показано на следующем рисунке. Элементы организованы в иерархическую древовидную структуру, в которой одни элементы вложены в другие. Документ должен иметь один и только один элемент верхнего уровня - элемент Документ, или корневой элемент — а все другие элементы вложены в него. При добавлении элемента в XML-документ вы можете выбрать любое имя типа, руководствуясь при этом следующими правилами:
Следующие имена использовать недопустимо: 1stPlace В Section B/Section :Chapter A:Section 4.5. Типы содержимого элементаСодержимым элемента считается текст, расположенный между начальным и конечным тегами. Вы можете использовать в качестве содержимого элемента следующие типы сообщений:
При добавлении в элемент символьных данных вы можете использовать любые символы, за исключением левой угловой скобки (.
Пустые элементы Вы также можете помещать пустой элемент — т.е. элемент, не имеющий содержимого — в ваш документ. Пустой элемент создается путем размещения конечного тега сразу же после начального тега. Например: Либо вы можете использовать специальный тег пустого элемента: Эти нотации являются эквивалентными. Практическое занятие № 1. Создание простого XML-документа Методические указания к выполнению практического занятия
Mark Twain mass market paperback 298 $5.49 Walt Whitman hardcover 462 $7.75 Washington Irving mass market paperback 98 $2.95 Nathaniel Hawthorne trade paperback 473 $10.95 Herman Melville hardcover 724 $9.95 Henry James mass market paperback 256 $4.95
В текстовом редакторе откройте документ .xml, созданный в предыдущем упражнении. Измените первый элемент TITLE с на |
zavantag.com
Основы xml
XML – это средство для описания грамматики представления и контроля правильности составления документов.
Инструкции языка, заключенные в угловые скобки, называются тэгами и служат для разметки основного текста документа.
Если XML-документ не нарушает правила синтаксиса XML, он называется формально-правильным или хорошо оформленным документом, и разборщики XML-документов будут работать с ним корректно.
Хорошо оформленные XML-документы, удовлетворяющие также требованиям DTD или XML-схем, определяющих их структуру и содержание, называются состоятельными.
Правильные, хорошо оформленные XML-документы должны удовлетворять следующим требованиям (Слайд 13.5):
1). В XML все элементы должны иметь закрывающий тэг, т.е. в отличие от HTML, XML не разрешается опускать конечные тэги элементов
2). В тэгах XML учитывается регистр. Например, <Book> отличается от <book>. Таким образом, начальные и конечные тэги должны быть записаны в одном регистре.
3). Элементы XML должны быть правильно вложены друг в друга, например:
<b><i>Этот текст пишется полужирным курсивом</i></b>
Перекрывание элементов возникает тогда, когда закрывающий тэг внешнего элемента располагается перед закрывающим тэгом внутреннего элемента.
4). XML-документы должны иметь единственный корневой элемент. Все остальные элементы должны быть вложены в корневой элемент.
5) Значения атрибутов всегда должны быть заключены в кавычки.
6) Все пробелы являются значимыми, т.е. при отображении пробелы в XML-документе не будут устраняться.
7) В XML есть несколько зарезервированных символов, которые используются только как элементы синтаксиса XML. Такими зарезервированными символами являются пять следующих знаков: <, >, &, “, ‘.
XML-документы имеют два раздела: пролог и тело документа (Слайд 13.6)
Пролог, предваряющий любой XML-документ, включает объявление XML и объявление типа документа. Объявление XML заключается между парами символов <? и ?> и может включать указание программе-анализатору текущего стандарта, объявление кодировки и самостоятельности, а объявлению типа документа предшествует ключевое слово DOCTYPE, например, объявление XML-документа с внешним DTD-определением в файле sample.dtd:
<?xml version=”1.1” encoding=”UTF-8” standalone=”yes”?>
<!DOCTYPE sampledoc SYSTEM “sample.dtd”>
К телу документа относится все кроме пролога.
Тело XML-документа состоит из элементов разметки и непосредственно содержимого документа – данных и представляет собой набор элементов и атрибутов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных.
Помимо элементов и атрибутов, обеспечивающих структурированное представление текстовой информации, языки разметки могут оперировать и двоичными данными (специальные символы, графика и т.д.) - сущностями, которые представляют собой поименованные фрагменты данных.
Элементы данных - это структурные единицы XML-документа, например (Слайд 13.7):
<flower> rose </flower>
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
В общем случае в качестве содержимого элементов могут выступать как текст, так и другие, вложенные, элементы документа, заключенные между начальным и конечным тэгами.
Элементы могут иметь подэлементы (дочерние элементы). Подэлементы должны быть правильно вложены внутри родительского элемента (в примере - <root>, <child>).
Элементы XML в свою очередь могут иметь собственные характеристики, задаваемые атрибутами.
Атрибуты определяют собственные характеристики элемента и задаются парой название = «значение» при определении элемента, например:
<color RGB="true">#ff08ff</color>
<color RGB="false">white</color>
studfiles.net
- Pc сокращение

- Зарядное устройство подключено но не заряжается

- Почему зависает и тормозит компьютер

- Что делать если администратор заблокировал выполнение этого приложения
- Windows 10 обновилась

- Код друга
- Список sql таблиц
- Пропала панель языка windows 10
- Операторы сравнения sql
- Сайт бесплатного обучения на компьютере

- Трекер торрент это