Информация в интернете. Откуда берется информация в интернете
Как работает Яндекс.Вебмастер? Откуда берутся данные?
В этой статье будет рассказано о том, как Яндекс.Вебмастер устроен изнутри, откуда он берет данные и как с ними работает.
Зачем нужен Яндекс.Вебмастер
Зачем нужен Яндекс.Вебмастер? Для того чтобы ответить на этот вопрос, нужно осознать, что в работе поиска принимают участие три стороны:
- пользователи, которые приходят в Яндекс за ответами на свои вопросы;
- владельцы сайтов, которые предоставляют контент и хотят получить трафик;
- Яндекс, который предоставляет поисковую технологию.
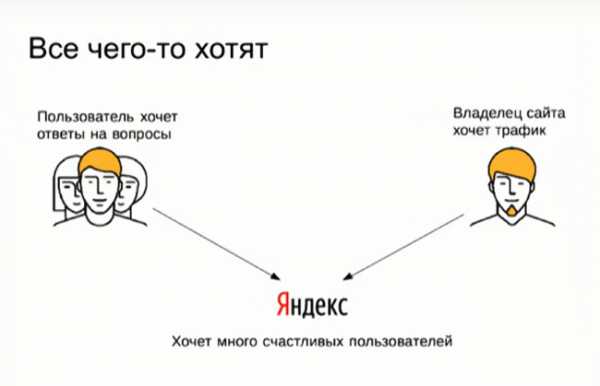
Яндекс.Вебмастер – это один из инструментов, который позволяет удовлетворить потребность всех трех этих сторон. Владельцы сайтов могут заходить в Яндекс.Вебмастер и получить информацию о том, что происходит с их сайтом. Яндекс показывает им существующие проблемы и пути их решения. Вебмастера исправляют проблемы и улучшают контент, у Яндекса улучшается выдача, пользователи тоже довольны. Triple win!
Сервис Яндекс.Вебмастер умеет делать хорошо ровно две вещи – собирать данные и показывать их. Тому, как этот сервис собирает данные, где он их берет и как обрабатывает, и будет посвящена сегодняшняя статья. Надеемся, эта информация поможет Вам более эффективно использовать Яндекс.Вебмастер для решения своих задач. Также она может быть весьма полезной аналитикам и другим людям, занимающимся обработкой данных.
Nota bene: у Google есть свой сервис для контроля и поддержки трафика – Google Search Console.
Раздел «Поисковые запросы»
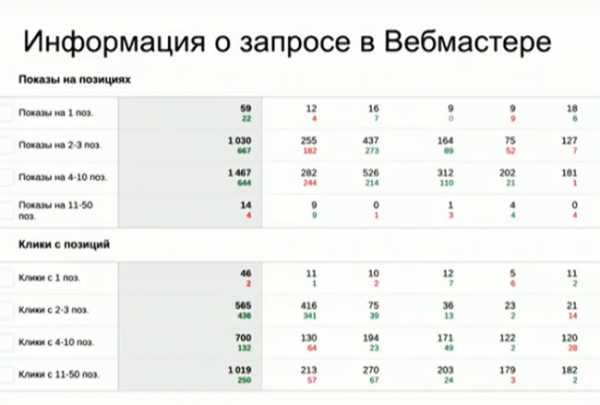
На данном скриншоте показана информация о каком-то запросе в сервисе Яндекс.Вебмастер. О запросе предоставляются максимально подробные данные: количество показов, количество кликов, ctr и т.д. Причем эти данные показываются для различных позиций. Это информация является самой точной, потому что предоставляет ее непосредственно Яндекс.
Разумеется, можно пользоваться другими инструментами – счетчиками, Яндекс.Метрикой и т.д. Но для того чтобы получить наиболее полные данные, вам нужны именно поисковые логи. А Яндекс.Вебмастер – это инструмент, который берет данные именно из этого источника. Каждый раз, когда пользователь совершает поисковый запрос, этот запрос уходит в поисковую программу, которая не только формирует выдачу, но и записывает в лог подробную информацию о нем (сам запрос, регион, список URL-адресов в выдаче и т.д.)
- Поиск Яндекса – большая программа;
- хорошие программы ведут лог;
- в логе поиска есть все что нужно.
Встает вопрос о том, как эту информацию можно обрабатывать, потому что поисковый лог Яндекса – это очень масштабный источник данных. Каждый день Яндекс отвечает на огромное количество запросов, и для того, чтобы предоставлять точную статистику, Яндекс.Вебмастер должен видеть их все.
Map Reduce
Map Reduce – это модель вычислений, которой активно пользуются разные команды Яндекса. Это довольно известная модель, для нее есть разные реализации и платформы, самой популярной из которых является Apache Hadoop.
В чем заключается идея Map Reduce? Возьмем классическую схему работы сервиса с данными. В такой схеме у сервиса есть кластер с базами данных и вычислительный кластер, где работают бэкенды, отправляющие и обрабатывающие запросы к этим базам. Нетрудно заметить, что в такой схеме всегда есть машины, у которых простаивают процессоры, потому что их основной задачей является хранение данных, и машины у которых простаивают жесткие диски, на которых ничего не хранится. Map Reduce – это концепция, которая призвана решить, в числе прочего, эту проблему. Согласно ей данные хранятся и обрабатывается в едином кластере, что позволяет снизить простой мощностей и минимизировать сетевой трафик. Яндекс.Вебмастер использует именно эту модель вычислений.
Поисковый лог
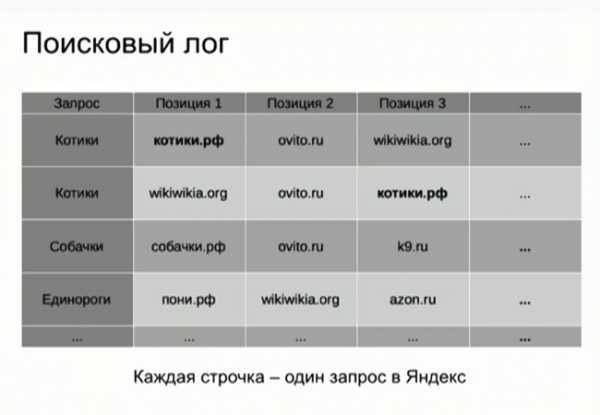
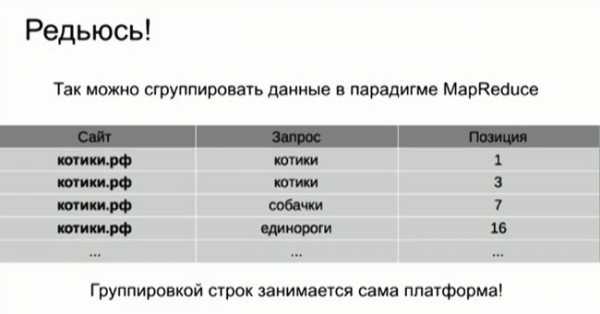
Каждый поисковый лог представляет собой строчку таблицы, в которой указан сам запрос и далее пункты выдачи, в соответствии с их позицией. Легко заметить, что в этой таблице записаны некие факты. Например, по запросу «котики» сайт котики.рф оказался на первой позиции – это факт. Map Reduce позволяет обработать эту огромную таблицу с помощью специальной программы и собрать факты в другую таблицу.
Теперь в каждой строчке находится не отдельный запрос, а отдельный факт. Например, говорящий о том, что по определенному запросу определенный сайт оказался на определенной позиции. Эта таблица существенно больше и уже немного ближе к тому, что показывает в интерфейсе Яндекс.Вебмастер.
Далее встает задача агрегировать полученные данные по хостам. Для этого выполняется операция Reduce, которая группирует все строчки с одинаковым ключом.
Nota bene: Если Вы занимаетесь обработкой больших данных, и Вам не хватает мощностей, Вы также можете использовать модель вычислений Map Reduce. Это отличный способ сократить расходы на «железо» для вычислений.
MapReduce в Яндексе
Яндекс использует собственную реализацию парадигмы MapReduce, которая называется YT (Ыть). Эта реализация развернута на кластере в несколько тысяч машин. При этом у сервиса Яндекс.Вебмастер есть гарантия доступности нескольких тысяч процессорных ядер, на которых в любой момент времени можно производить вычисления. И это действительно происходит – каждую минуту Яндекс.Вебмастер обрабатывает несколько гигабайт данных. В последнее время команда Яндекс.Вебмастер идет к тому, чтобы использовать MapReduce для всех типов данных, потому что это очень удобно.
Раздел «Страницы в поиске»
В раздел Яндекс.Вебмастера «Страницы в поиске» недавно были внесены два важных изменения:
- Добавлена возможность мгновенной доставки данных.
- Добавлена история изменений позиций сайта в выдаче.
Данные для этого раздела берутся из поисковой базы – реально существующего набора таблиц, данных и т.д. Все, что остается Яндекс.Вебмастеру, – это забрать эти таблицы и произвести нужные вычисления.
- Поиск берет страницы из поисковой базы.
- Поисковая база — это тоже данные.
- Любые данные можно обработать.
Как получить информацию об изменениях в поисковой базе? Для этого нужно просто сравнить две базы – старую и новую – и проверить в них наличие того или иного URL-адреса. Кроме того, в поисковой базе имеется дополнительная информация о причинах появления в ней или удаления из нее URL-адреса.
MapReduce – это технология, которая идеально подходит именно для таких задач по сравнению данных. Команде Яндекс.Вебмастер оставалось только написать соответствующую функцию сравнения.
Что касается мгновенной доставки данных, понятно, что это некоторое преувеличения – они доставляются не за одну секунду. На больших базах данных расчет может длиться часами. Тем не менее в течение 5–6 минут после переключения базы на поиске данные уже есть в сервисе.
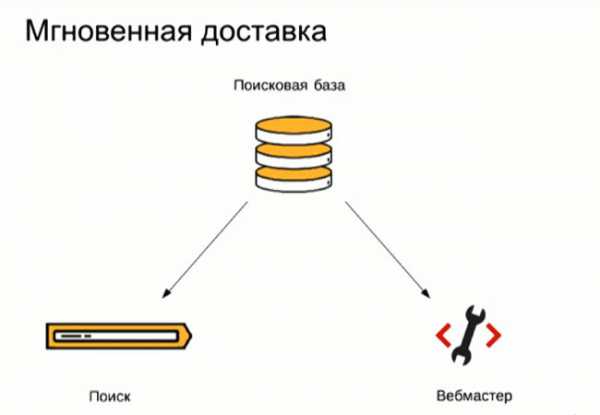
Как у Яндекса получилось добиться такого результата? Дело в том, что поисковая база формируется не на самих поисковых машинах. Поэтому, после того как она сформировалась, ей нужно еще некоторое время, чтобы доехать до поиска – данные в ней проходят проверку, оценку и т.д. Этот процесс занимает несколько часов. А Яндекс.Вебмастер забирает поисковую базу еще до того, как она появилась на поиске. Далее над данными из этой базы проводятся все необходимые вычисления, и в тот момент, когда она появляется на поиске, Яндекс.Вебмастер включает ее и у себя.
Раздел «Нарушения и безопасность»
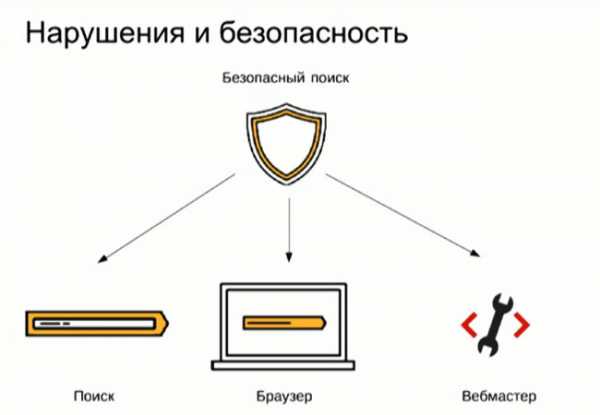
В этом разделе отображается информация о найденных на сайте вирусах. Т.к. Яндекс заботится о своих пользователях и не хочет, чтобы их устройства заражались вирусами или троянами, на борьбу с этой проблемой в нем тратится много ресурсов. Для этого в составе Яндекса есть отдельное подразделение, занимающееся обнаружением вирусов на сайтах. Информация о вирусах доставляется до пользователей двумя способами:
- непосредственно в выдаче – рядом с URL-адресом зараженного сайта;
- через Яндекс.Браузер.
Однако в такой схеме страдают владельцы сайтов, потому что, когда Яндекс помечает сайт как зараженный, у них происходит падение трафика. Поэтому одной из задач сервиса Яндекс.Вебмастер является доведение до вебмастеров информации о взломе или заражении сайта. Данные о зараженных страницах берутся Яндекс.Вебмастером непосредственно из первоисточника – оттуда же, откуда их забирает поиск и Яндекс.Браузер.
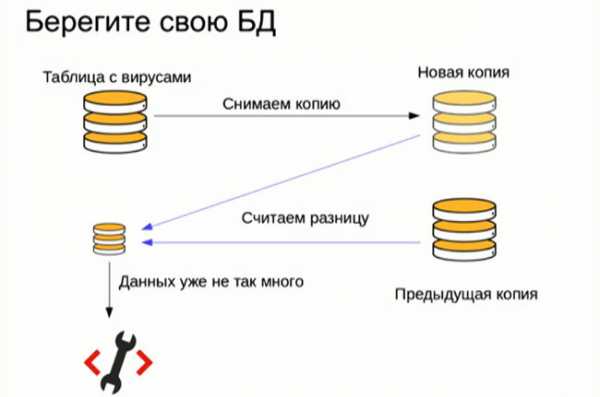
Хранятся они в простой таблице, где указаны адреса сайтов и обнаруженные проблемы. Размер этой таблицы относительно невелик, однако изменения в нее все равно вносятся частями. Она не переписывается целиком каждые 10 минут, поэтому в ней все время находятся примерно одинаковые данные.
Для того чтобы минимизировать время доставки информации об обнаружении вируса до вебмастера, Яндекс.Вебмастер раз в 10 минут снимает полную копию таблицы с вирусами и сравнивает ее с предыдущей версией. Благодаря технологии MapReduce, это занимает совсем немного времени. Получается небольшая таблица с изменениями, и именно она и загружается в Яндекс.Вебмастер. Благодаря этому время доведения до вебмастера информации о заражении сократилось до 10 минут.
Кстати о базах данных
MapReduce – это офлайновая технология. В большинстве случаев она нужна для того, чтобы что-то посчитать в офлайне в течение нескольких часов. С ее помощью нельзя быстро показывать данные пользователю в интерфейсе. Поэтому команде Яндекс.Вебмастера все равно были нужны классические базы данных.
Интересно, что команда Яндекс.Вебмастера и разработчики аналогичных аналитических инструментов сталкиваются с диаметрально противоположными проблемами. Обычно основной проблемой разработчиков является нехватка данных для анализа. В Яндекс.Вебмастере обратная ситуация – у разработчиков очень много данных, которые нужно уменьшить, чтобы была возможна их обработка.
Clickhouse
Для уменьшения объема данных команда Яндекс.Вебмастера также использовала технологию MapReduce, однако даже после обработки объем был слишком велик. Тогда они обратились за помощью к команде Яндекс.Метрики, которые для похожих целей разработали собственную базу данных Clickhouse.
- Clickhouse – это колоночная база данных, разработанная командой Яндекс.Метрики$
- поддерживает SQL-синтаксис;
- эффективно хранит данные.
Первым делом разработчики Яндекс.Вебмастера попытались поместить в эту базу данных раздел «Поисковые запросы». Оказалось, что Clickhouse очень эффективно хранит информацию – объем данных на входе и выходе оказался не сопоставимым. В результате на проект Clickhouse была выделена отдельная команда, и теперь эта база данных является opensource продуктом. Документация по продукту выложена на clickhouse.yandex. Так что, если у вас тормозит PostgreSQL, теперь есть хорошая альтернатива.
Тем не менее у Clickhouse есть и обратная сторона медали. Ради эффективности пришлось пожертвовать функционалом – в этой базе данных нельзя обновлять и удалять данные. Можно только делать insert и удалять таблицу целиком. По этой причине для некоторых разделов в Яндекс.Вебмастере используется еще одна база данных – Apache Cassandra.
Apache Cassandra
Apache Cassandra – это также опенсорсная база данных.
- Apache Cassandra – это распределенная база данных;
- более простой язык запросов;
- каждым данным выделяется своя база;
- умеет удалять данные.
Пирамида юзабилити
Можно заметить, что любые сложные системы растут предсказуемым образом – иерархически. Например, если в компании появляется больше людей, в ней появляются слои управления и т.д. То же самое происходило с интернетом, в который люди выходили, каждый раз забивая адрес нужного сайта в браузер. Потом появился поиск – производный инструмент, который привнес новый сценарий пользования интернетом. В свою очередь, поиск Яндекса также рос, и владельцам сайтов становилось все сложнее понимать его механизм. Для того чтобы дать обратную связь владельцам сайтов, появился Яндес.Вебмастер. Потом сам Яндекс.Вебмастер разросся до внушительных размеров, и у него появился свой производный инструмент – раздел диагностики сайта.
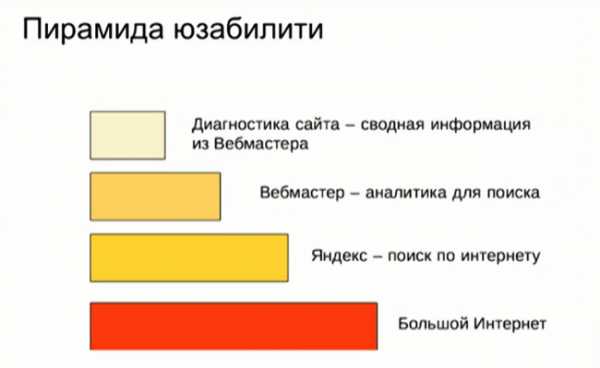
Раздел диагностики сайта
Раздел диагностики сайта – это страница, на которой перечислен список проблем и рекомендаций, о которых Яндекс хочет сообщить вебмастеру. Начиная от критических проблем, вроде вируса на сайте, и заканчивая отсутствием сайта в справочнике организаций Яндекса. Это полезная страница, которую можно посещать каждый день, чтобы следить за состоянием Вашего сайта.
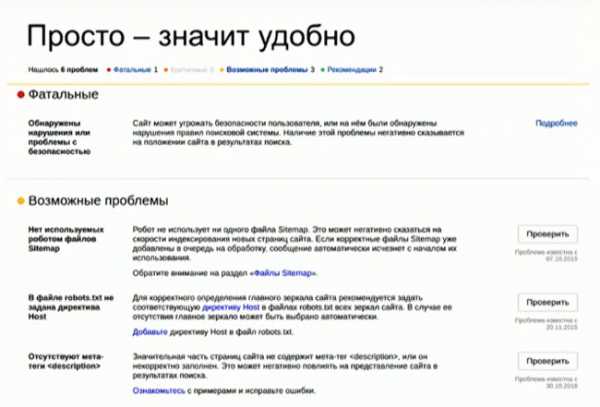
Чтобы вебмастер точно ничего не пропустил, разработчики создали еще одну функцию. Теперь, если с Вашим сайтом что-то не так, в списке сайтов на странице диагностики рядом с ним появится красный треугольник с восклицательным знаком.
С технической точки зрения, раздел диагностики сайта также имеет некоторые особенности. Во-первых, в отличие от других разделов, источником данных является сам Яндекс.Вебмастер. Во-вторых, эти данные должны быть на 100 % консистентны с другими разделами. Недопустима ситуация, когда в разделе диагностики сайта, к примеру, выложена одна информация о наличии вирусов на сайте, а в другом разделе – совершенно другая.
Источник (видео): Вебмастер: Рассказ о данных — Андрей Халлиулин (Яндекс).
o-es.ru
Информация в интернете — http://jkeks.ru
8.7.2013 - 1151 просмотр ;)Сегодняшний молодой человек сильно отличается от молодого человека 80-х годов прошлого века. Жизнь современной молодежи постепенно поглощает интернет. Это вполне объяснимо, ведь в интернете теперь можно не только общаться, но и читать, играть и даже работать. Интернет http://glok17.ru заменяет нам магнитофон, телевизор, радио, книги, газеты и т.д. Ежедневно мы читаем какие-то новости, заметки, обзоры. Но можно ли верить всей информации, которая распространяется в интернете? Ответ на этот интересный вопрос будет приведен в этой статье.
1. Можно ли верить новостям? Итак, рассмотрим, откуда же берутся новости в интернете. Авторитетные новостные агентства работают только с официальными пресс-службами и ссылаются только на официальные источники информации. Известные газеты, которые имеют свой сайт во всемирной сети, также публикуют только подтвержденные данные. Таким сайтам верить можно. Но есть сайты, которые публикуют новости с той целью, чтобы привлечь посетителей. А что больше всего привлекает пользователей? Конечно же, сенсации. И не важно, вымышленные они или нет. О подлинности информации вы узнаете позже, а веб-сайт http://glok17.ru уже получил своих заветных посетителей. Поэтому будьте осторожны, доверяя сомнительным новостным порталам.
2. Можно ли верить статьям, обзорам? Здесь определить подлинность будет гораздо сложнее. Опять-таки старайтесь читать статьи только на авторитетных проверенных ресурсах. Но в любом случае знайте, что 80% конента сегодня – это рерайтинг. То есть переписанные чужие статьи. А почему переписанные и измененные? Потому что статьи должны быть уникальными, иначе сайт не продвинется в поисковых системах. А когда статью подвергают рерайту по несколько раз, ее смысл может измениться. В результате вы как читатель проигрываете. Поэтому будьте внимательны. Особенно бдительным нужно быть на сайтах таких тематик, как «Красота и здоровье», «Строительство» и т.д. Вы можете начать делать ремонт квартиры, ориентируясь на статью человека, который никогда не занимался ремонтом. В результате все ваши обои через год отклеятся.
3. Можно ли верить блогерам? Блогеры – это люди, которые передают вам свои знания и рассказывают о своем опыте. Вы можете верить им или нет. Но в любом случае – это не рерайтинг чьих-то статей, а рассказы от первого лица. В них может содержаться много полезной информации. Бороздя просторы интернета, будьте бдительны и внимательны, только в этом случае вы будете читать лишь то, что действительно интересно и полезно.
Другие заметки на эту тему:
jkeks.ru
Откуда берутся деньги в интернете?
Для создания коммерческого интернет-проекта нужна идея. Нужна схема получения денег.
Откуда вообще берутся деньги в интернете? Как Вы думаете? Кто платит и за что?
Вот, к примеру, попробуйте решить следующую задачку.
Некая интернет-фирма предлагает лёгкую работу: просматривать рекламу и получать за переход по рекламному объявлению, скажем, по полцента.
Как Вы думаете, какой в этом смысл? За что платятся деньги?
Может, за просмотр рекламы? Или, за посещение сайта?
А какая выгода кому-то от того, что рекламу посмотрели, а сайт — посетили?
Быть может, деньги платятся, чтобы обеспечить сайту трафик? Прилив посетителей?
А какой толк от посетителей, которым нужно платить деньги? У владельца сайта что, денег девать некуда?
На самом деле всё довольно просто.
Предположим, Вы написали хорошую электронную книгу и теперь хотите эту книгу продавать. Вы создаёте сайт, на котором подробно описывается, какая Ваша книга хорошая. Тут же, на сайте, Вы предусмотрели, чтобы заинтересованный посетитель смог сразу оплатить и скачать Вашу книгу.
Теперь Вам нужно, чтобы о Вашем сайте узнало как можно больше народа. Вам нужно, чтобы люди приходили на сайт, читали описание книги, и покупали.
Обратите внимание, Вам нужно, чтобы Вашу книгу покупали.
Как раскрутить сайт? Как привлечь посетителей? Самый простой способ — заплатить за рекламу.
Вы находите рекламную фирму, которая обещает быстро и дёшево привлечь на Ваш сайт несколько тысяч тематических посетителей. Всего по центу за посетителя.
Названная цена Вас вполне устраивает, ведь продажа одной копии книги отобьёт все затраты на такую рекламу, поэтому Вы платите и ждёте своих покупателей.
Сразу после того, как Вы заплатили рекламной фирме за услугу, Ваше рекламное объявление размещается на нескольких незначительных сайтах, а тысяча желающих заработать получает задание — кликнуть по Вашей рекламе. Хлоп, и за пару дней весь Ваш рекламный бюджет потрачен.
Все довольны. Рекламная фирма честно заработала половину Ваших денег. Кликальщикам начислено по полцента на счёт участника. А Вы получили своих посетителей.
Только вот, никто у Вас ничего не купил. Потому что у тех, кто согласен работать за доли цента, нет денег, чтобы заплатить за Вашу книгу. Их вообще не интересует Ваша книга, их интересует полцента, которые они получат за посещение Вашего сайта.
Почему у кликальщиков нет денег, ведь им начисляются деньги за выполненную работу?
Дело в том, что сразу получить свои заработанные полцента нельзя. По условиям системы заработка, минимальная сумма, которую можно вывести, это, скажем, 10 или 20 долларов. Посчитайте сами, сколько объявлений придётся просмотреть и сколько сайтов посетить.
У большинства участников попросту не хватит сил и терпения, чтобы наработать нужную сумму. А значит, невостребованные деньги зависают в системе, увеличивая доход хозяина фирмы.
Описанная мной схема заработка — мошенническая. Фирма с двумя лицами-сайтами. Один сайт для клиентов-рекламодателей, второй — для желающих заработать. Но обмануты будут, как первые, так и вторые.
Этот пример я привёл вовсе не для того, чтобы научить Вас обманывать людей. Вам нужно научиться понимать схемы движения денег и запомнить, что всегда деньги платит покупатель, который хочет получить свою выгоду.
Тренируйте в себе умение увидеть и понять выгоду покупателя в любой схеме — везде, где кто-то за что-то платит деньги.
Во-первых, такое умение поможет Вам избегать попадания в сети мошенников.
Во-вторых, умея понять выгоду, Вы сможете создавать и предлагать покупателям что-то действительно ценное.
Источник - http://basil.kz/
yvision.kz
Откуда берется интернет-зависимость - Интернет
Уровень интернет-зависимости обуславливается как проникновением интернета, так и уровнем жизни в стране, выяснили гонконгские ученые. Их исследование объясняет, почему в России так много пристрастившихся к интернету и социальным сетям.В России очень высок уровень интернет-зависимости: по данным опроса, проведенного ВЦИОМ в 2013 году, 22% россиян признались, что проводят в интернете слишком много времени. При этом 11% респондентов заявили, что тратят его на проверку электронной почты.
Больше интернет-зависимых в России среди молодежи. 53% россиян в возрасте от 18 до 24 лет признались, что подолгу сидят в интернете, а 44% из них поглотили социальные сети.
Россияне действительно крайне много времени проводят в соцсетях: согласно исследованию, проведенному консалтинговой компанией A.T. Kerney, пользователи из России, а также из Индии, Нигерии и Бразилии больше половины своего времени онлайн тратят на социальные сети. Начиная с 2011 года Россия является лидером по количеству времени, проводимого типичным пользователем интернета в соцсетях — около 13 часов в месяц.
Несмотря на то что зависимость от интернета не признана психическим расстройством официально, психологи и психиатры говорят о ней уже 20 лет. Впервые об интернет-зависимости (правда, в шуточной форме) рассказал американский врач Айвен Гольдберг еще в 1995 году. Позже на это явление обратили внимание и другие специалисты. Так, английский психолог Марк Гриффитс выделил шесть критериев, по которым можно определить интернет-зависимость, а психиатр Кимберли Янг разработала тест-опросник, направленный на выявление интернет-зависимости.
Больше всего внимания интернет-зависимости уделяют именно в Китае: в 2008 году она была объявлена угрозой здоровью нации, тогда же были созданы реабилитационные центры для лечения людей, слишком глубоко погрузившихся в сеть. В 2009 году подобные центры появились и в США.
Как выяснили психологи из Университета Гонконга, уровень интернет-зависимости людей зависит как от уровня удовлетворенности жизнью, так и, безусловно, от уровня проникновения интернета в регион.
Ученые проанализировали данные по 89 тыс. человек из 31 страны, с 1996 по 2012 год заполнивших «опросник Янг». Интернет-зависимыми признали по итогам около 6% людей, причем наибольшая их доля – 10,9% — обнаружена в странах Ближнего Востока (в Иране, Израиле, Ливане и Турции). В Северной и Западной Европе доля интернет-зависимых оказалась наименьшей — только 2,6%.
Согласно исследованию, уровень болезненного пристрастия к интернету находится в обратной зависимости от качества жизни в стране. Люди могут погружаться в виртуальный мир, чтобы избежать стресса офлайн — в реальной жизни.
По мере того, как границы между реальным и виртуальным мирами размываются, люди, которые часто сталкиваются с проблемами в офлайне, с большей вероятностью могут использовать интернет для бегства от реальности. Следовательно, закономерно предлагать обратную связь интернет-зависимости и удовлетворенности жизнью, считают ученые.
Качество жизни определяют, основываясь как на субъективных, так и на объективных индикаторах. Психологи определяют этот конструкт как субъективную оценку уровня жизни, поэтому рейтинги качества жизни зачастую основываются на опросах людей.
Россия – страна, в которой сочетаются оба описанных гонконгскими психологами фактора.
Согласно статистике Internet World Stats, уровень проникновения интернета в России составляет 62%. Это достаточно высокий показатель: так, например, уровень проникновения интернета в США (лидере мировой IT- и телеком-индустрии) — 78%. По данным ФОМ, месячная аудитория интернета в России — 71,7 млн пользователей.
При этом качество жизни в России достаточно низкое, особенно в сравнении с большинством других стран с настолько же высоким уровнем проникновения интернета. Индекс качества жизни (where-to-be-born index), разработанный компанией Economist Intelligence Unit, базируется на методологии, связывающей исследования по субъективной оценке жизни. Методика включает в себя исследования качества жизни по девяти параметрам: здоровье, семейная жизнь, общественная жизнь, материальное благополучие, политическая стабильность и безопасность, климат и география, гарантия работы, политическая свобода и гендерное равенство. Последний where-to-be-born index был подсчитан в 2013 году в 80 странах мира.
Согласно этому рейтингу, Россия занимает 72-е место из 80 исследованных стран, с индексом 5,31 (на первом месте Швейцария с 8,22). Ниже российского оказались индексы только восьми стран: Сирии, Казахстана, Пакистана, Анголы, Бангладеш, Украины, Кении и Нигерии.
ingvarr.net.ru
- Установка jdk 7 windows
- Хороший браузер какой

- Как перенести на флешку большой файл
- Как открывается

- Windows 10 как переустановить windows store
- Команды route
- Что такое вкладка и что такое закладка
- Команды linux ubuntu
- Программирование http для начинающих
- Radmin server настройка
- Аваст установка