Реорганизация / дефрагментация индекса СУБД MS SQL Server. Перестроение индексов ms sql
Оптимизируем базу на MSSQL: определяем фрагментацию индексов
Оптимизируем базу на MSSQL: определяем фрагментацию индексов
Ничто так не "убивает" базу, как "плохое" индексирование (С)
Создать правильные индексы - это только половина дела. Нужно еще и правильно ими управлять.
В процессе работы с базой, особенно, если данные в ней довольно часто модифицируются/добавляются/удаляются, со временем индексы приходят в некоторую "негодность". Увеличивается их "фрагментарность", ухудшается их влияние на скорость исполнения запросов к БД.Оптимальным считается, когда уровень фрагментации индекса не превышает 10%, но для поддержания такого показателя необходимо проводить периодическую их дефрагментацию и реорганизацию.(подробнее про реорганизацию и дефрагментацию)
Основным инструментом в процессе управления фрагментацией индексов выступает функция sys.dm_db_index_physical_stats (подробнее)
SELECT IndStat.database_id, IndStat.object_id, QUOTENAME(s.name) + '.' + QUOTENAME(o.name) AS [object_name], IndStat.index_id, QUOTENAME(i.name) AS index_name, IndStat.avg_fragmentation_in_percent, IndStat.partition_number, (SELECT count (*) FROM sys.partitions p WHERE p.object_id = IndStat.object_id AND p.index_id = IndStat.index_id) AS partition_count FROM sys.dm_db_index_physical_stats (DB_ID(@db_name), OBJECT_ID(@table_name), NULL, NULL , 'LIMITED') AS IndStat INNER JOIN sys.objects AS o ON (IndStat.object_id = o.object_id) INNER JOIN sys.schemas AS s ON s.schema_id = o.schema_id INNER JOIN sys.indexes i ON (i.object_id = IndStat.object_id AND i.index_id = IndStat.index_id)WHERE IndStat.avg_fragmentation_in_percent > 10 AND IndStat.index_id > 0
Если указать @table_name = NULL, тогда мы получим данные по всем таблицам указанной базы. Если указать и @db_name = NULL - получим информацию по всем таблицам всех баз.- CONTROL на специфический объект БД.
- VIEW DATABASE STATE для получения информации обо всех объектах определенной БД (@object_id = NULL).
- VIEW SERVER STATE - для получения информации обо всех базах сервера (@database_id = NULL).
Так же перед использованием желательно обновить статистику БД.
Вышеприведенный запрос дает только справочную информацию. Но на основании функции sys.dm_db_index_physical_stats можно построить скрипт или хранимую процедуру, которая будет не только определять список индексов, нуждающихся в перестройке, но и будет сама проводить эту операцию.Один из вариантов такого скрипта приведен ниже (проводит реорганизацию или перестройку(оффлайн) индексов таблиц текущей базы в зависимости от степени фрагментации):
USE [DATABASE]; GOSET NOCOUNT ON;DECLARE @objectid int;DECLARE @indexid int;DECLARE @partitioncount bigint;DECLARE @schemaname nvarchar(130);DECLARE @objectname nvarchar(130);DECLARE @indexname nvarchar(130);DECLARE @partitionnum bigint;DECLARE @partitions bigint;DECLARE @frag float;DECLARE @command nvarchar(4000);DECLARE @dbid smallint;
-- Выбираем индексы с уровнем фрагментации выше 10%-- Определяем текущую БД
SET @dbid = DB_ID();SELECT [object_id] AS objectid, index_id AS indexid, partition_number AS partitionnum, avg_fragmentation_in_percent AS frag, page_countINTO #work_to_doFROM sys.dm_db_index_physical_stats (@dbid, NULL, NULL , NULL, N'LIMITED')WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0 -- игнорируем heapAND page_count > 25; -- игнорируем маленькие таблицы
-- объявляем курсор для списка обрабатываемых partitionDECLARE partitions CURSOR FOR SELECT objectid,indexid, partitionnum,frag FROM #work_to_do;
OPEN partitions;
-- цикл по partitionWHILE (1=1)BEGINFETCH NEXTFROM partitionsINTO @objectid, @indexid, @partitionnum, @frag;IF @@FETCH_STATUS 0 BREAK;SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name)FROM sys.objects AS oJOIN sys.schemas AS s ON s.schema_id = o.schema_idWHERE o.object_id = @objectid;
SELECT @indexname = QUOTENAME(name)FROM sys.indexesWHERE object_id = @objectid AND index_id = @indexid;SELECT @partitioncount = count (*)FROM sys.partitionsWHERE object_id = @objectid AND index_id = @indexid;
-- 30% считаем пределом для определения типа обновления индекса.IF @frag 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE';IF @frag >= 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD';IF @partitioncount > 1 SET @command = @command + N' PARTITION=' + CAST(@partitionnum AS nvarchar(10));
EXEC (@command);PRINT N'Выполнено: ' + @command;END;
CLOSE partitions;DEALLOCATE partitions;
-- удаляем временную таблицуDROP TABLE #work_to_do;GO
Еще посмотреть примеры скриптов/хранимок можно тут или вот тут.
Операцию по устранению дефрагментации индексов рекомендуется проводить регулярно (например, раз в неделю/месяц - в зависимости от величины операций модификации над хранимыми данными). Индексы, за состоянием которых не следят, могут очень существенно "просадить" производительность БД при исполнении запросов.
Обслуживание баз 1C в MS SQL Server. Часть 1. -, TEAM-IT.
Обслуживание баз 1C в MS SQL Server. Часть 1.
В данной статье рассмотрен процесс создания планов обслуживания баз. Оповещение оператора, а так же пример восстановления базы рассмотрим в следующих статьях.
В тестовой лаборатории у нас следующее:
- Сервер Windows Server 2008 Enterprise: SRV-1C-TEST.
- Microsoft SQL Server 2008: SRV-1C-TEST.
- Тестовая база BuhFirma.
Задача:Проводить обслуживание базы в период 00:30 — 01:00, при этом обслуживание не должно быть заметным (либо слабозаметным) для пользователей базы.
Начнём с важных моментов. MS SQL база данных может иметь один из трех типов модели восстановления:
- Простая.
- Полная.
- С неполным протоколированием.
Так же при резервном копировании нам предоставляется на выбор три варианта копирования:
- Полное.
- Разностное.
- Копирование журнала транзакций (логов).
При полном варианте копирования происходит сохранение базы mdf и журнала транзакций. Разностное копирование (по-другому дифференциальное) производит копирование данных, изменившихся с момента создания последней полной резервной копии. Копирование журнала транзакций соответственно производит сохранение только самого журнала транзакций.
При выборе простой модели восстановить базу данных можно с момента создания последней разностной или полной резервной копии. При выборе полной модели восстановления мы можем восстанавливать базу до минуты, создав полную резервную копию, например, ночью, и в течение дня создавать копии журнала транзакции. Ниже мы увидим, где всплывает этот момент. Хотелось так же привести некоторые выдержки из MSDN: «Модель восстановления с неполным протоколированием предназначена исключительно как дополнение к модели полного восстановления. В общем случае модель восстановления с неполным протоколированием похожа на модель полного восстановления, за исключением того, что протоколирование большинства массовых операций в ней производится в минимальной степени».
Модель восстановления своей базы вы можете посмотреть, зайдя в свойства базы данных, например BuhFirma и перейдя на строку — Параметры.
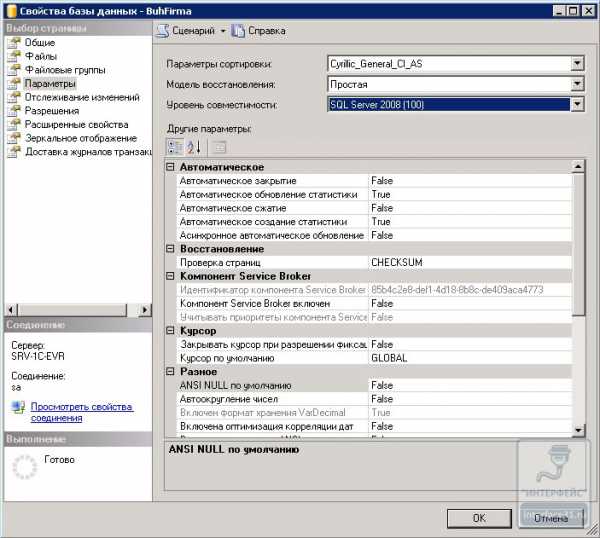
В MSSQL 2008 по умолчанию в созданных базах данных модель восстановления Полная.
Как выбрать модель восстановления? Надо лишь ответить на вопрос: смертельна ли потеря информации за время, прошедшее после полного резервного копирования? Если ответ да, тогда выбираем полную модель восстановления, если нет, простую. Модель с неполным протоколированием стоит применять только на время массовых операций в БД.
Таким образом, если вы выбрали простую модель, то восстановить данные вы сможете только на момент ночного полного или разностного копирования, а всю информацию после этого пользователи будут восстанавливать вручную. Выбирая Полную модель, вы обязательно должны делать резервное копирование журнала транзакций, иначе логи будут сильно расти. При любой модели восстановления вы всегда должны иметь полную резервную копию.
В начале создадим ночной план обслуживания базы, который будет включать в себя последовательность следующих действий:
- Проверка целостности базы
- Перестроение индекса
- Обновление статистики
- Очистка процедурного кэша СУБД
- Резервное копирование базы данных
- Очистка после обслуживания
- Очистка журнала
Для этого подключимся к MSSQL серверу с помощью среды Microsoft SQLServer Management Studio. Запустить среду можно перейдя в Пуск — Все программы — Microsoft SQL Server 2008.Подключимся с серверу SQL и перейдем в Управление — Планы Обслуживания. Кликнем правой кнопкой по Планы обслуживания и выберем Создать план обслуживания. Дадим ему имя: SRV1CTEST.
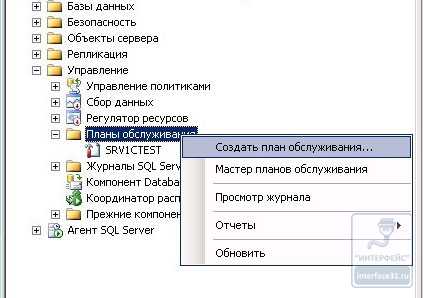
Перед нами окно SRV1CTEST, в котором мы и будем создавать последовательность действий, обозначенных раннее. Сразу видим появившейся Вложенный_План1. Справа от названия вложенного плана вы увидите иконку в виде таблички. Нажимаем на нее и попадаем в свойства расписания задания. Здесь можно менять название вложенного плана, выставить частоту повторения в Ежедневно и установить время. И так теперь осталось наполнить наш план заданиями. Для этого с Панели инструментов, которая находится справой стороны, перетаскиваем задания.
Начнем с Проверки целостности базы данных.
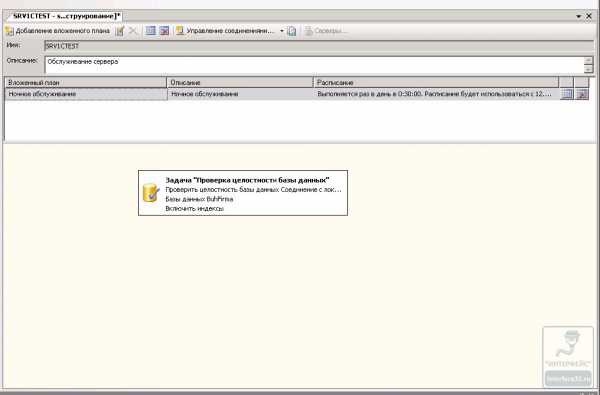
После того, как вы перетащили задание, щелкните по нему два раза. Откроется окно, в котором в строке Базы данных мы выбираем созданную нашу базу BuhFirma. Далее таким же образом добавляем задания Перестроение индекса и Обновление статистики, не забыв выбрать в них нужную базу данных.
Процедура Перестроение индекса пересоздает индекс с новым коэффициентом заполнения. За счет этого мы увеличиваем производительность работы в БД.
Задача Обновление статистики обновляет сведения о данных таблиц для MS SQL. Что тоже повышает производительность. Но после этой операции надо обязательно проводить очистку кэша.
Пока остановимся и поговорим о настройке связей между заданиями. Связи отражают последовательность выполнения. Что бы провести связь между заданиями надо нажать один раз на задание и увидите появившуюся стрелку. Её надо перетащить на следующее задание. У связи может быть 3 цвета: синий, зеленый и красный, каждый из которых означает три типа срабатывания перехода: при простом завершении предыдущего задания — Завершение, в случае успешного завершения — Успех, а в случае возникновения ошибки при выполнение предыдущего задания — Ошибка. Все эти параметры вы можете увидеть, нажав правой кнопкой мыши на проведенную между заданиями стрелку. Таким образом, если нам надо, чтобы Перестроение индекса срабатывало только после успешного завершения задания Проверка целостности базы данных, мы должны связать их стрелкой. Нажав правой кнопкой мыши на стрелку, сменим ее режим на Успешно, как видим, ее цвет изменился на зеленый.
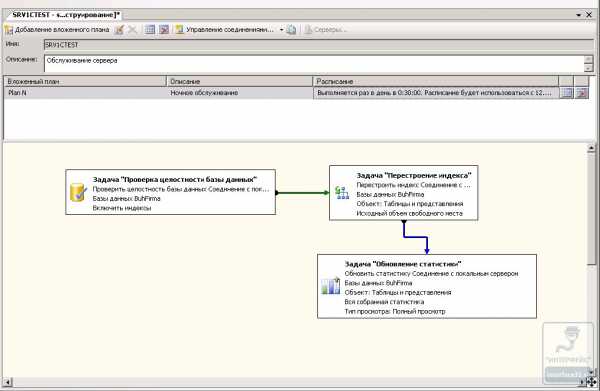
На данный момент мы имеем 3 созданных задания в нашем вложенном плане. Как вы могли заметить, задания Очистка процедурного кэша СУБД в панели элементов нету. Мы воспользуемся задачей Выполнение инструкции T-SQL. Перетащим ее в план, и щелкнем на ней два раза. Мы видим окно, в которое впишем следующее:
DBCC FREEPROCCACHEНажмем ОК. Далее стоит добавить задание задачу Резервное копирование базы данных. Так же щелкнув на добавленном задании, увидим опции настройки задания.
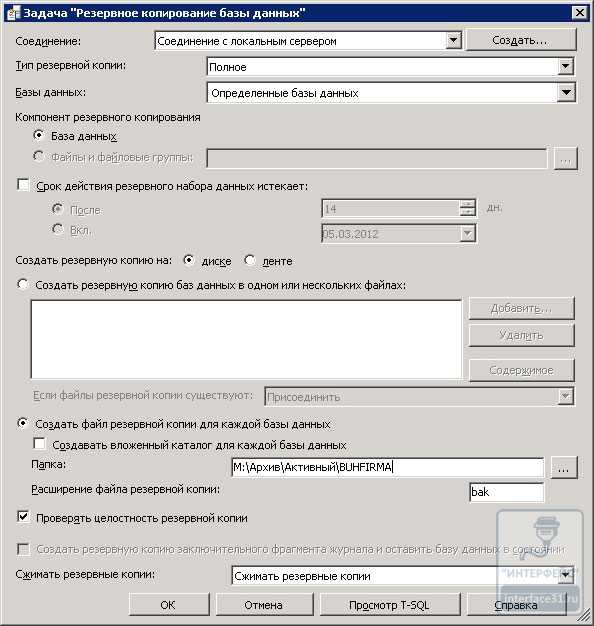
Здесь, исходя из поставленной задачи, выбираем полное резервное копирование, место, куда будем помещать архивы, а так же не забудем установить параметр Сжимать резервные копии.
Задача Очистка после обслуживания позволяет удалять устаревшие архивы. В нем мы можем установить место расположения архивов, а так же время, по истечению которого они будут удаляться.Задача Очистка журнала производит удаление данных журнала, связанных с процессами резервного копирования, восстановления, планами обслуживания баз, а также с деятельностью агента SQLServer.
Таким образов в конце мы получим список последовательно выполняемых задач.
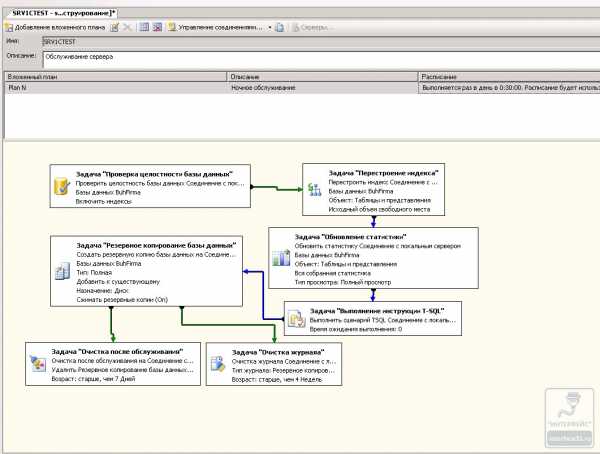
Сохранив план обслуживания, надо удостовериться в том, что на нашем сервер запущен Агент SQL Server. Для этого перейдем в Пуск — Все программы — Microsoft SQL Server 2008 — Средства настройки — Диспетчер конфигурации SQL Server. Перейдя на строчку Службы SQLServer, проверим, что служба Агент SQLServer находится в состоянии Работает и режим запуска выставлен в Авто.
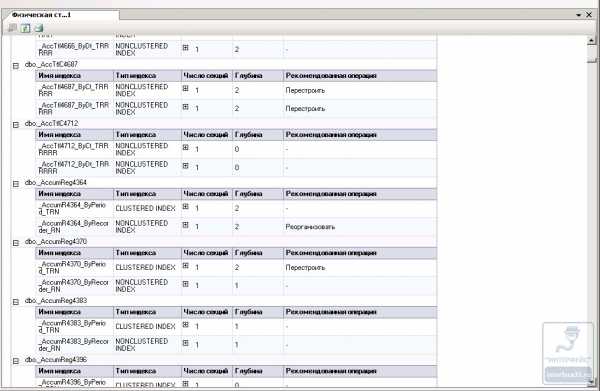
В конце хотелось бы сказать о том, что использование задачи Перестроение индекса можно заменить или совместить с задачей Реорганизация индекса. Реорганизация индекса представляет собой инструмент для дефрагментации индексов. Для того что бы просмотреть какие операции требуются индексу, необходимо просмотреть физическую статистику индекса. Для этого правой кнопкой мыши нажмите на базу данных, перейдите в Отчеты — Стандартные отчеты — Физическая статистика индекса.
Следить за состоянием выполняемых операций вы можете из Управление — Планы обслуживания. Для этого в свойствах плана SRV1CTEST выберите Просмотр журнала. Так же можно просмотреть журнал, который ведет Агент MS SQL по этому заданию. Для этого перейдите на строку Агент MS SQL и в свойствах задания SRV1CTEST выберите Просмотр журнала.
team-it.ru
Обслуживание индексов и статистик MS SQL Server
Обслуживание индексов и статистик MS SQL Server
Эта статья написана для администраторов, обслуживающих сервера СУБД MS SQL Server, которые используются вместе с 1С:Предприятием. Статья скорее практическая, чем разъяснительная, но я постарался хотя бы кратко обосновать те или иные решения, хотя большая часть информации дана несколько упрощенно и поверхностно.
Индексы и статистики в MS SQL Server — основа эффективного выполнения запросов. Без них сервер не сможет выполнять запросы за разумное время.
Статистика — небольшая таблица, до 200 строк, в которой хранится обобщенная информация о том, какие значения и как часто встречаются в таблице. На основании статистики сервер принимает решение, какой индекс использовать при выполнении запроса.
Индекс — особым образом структурированные данные (хранящиеся в базе данных), которые позволяют быстро найти нужные записи. Устроен он примерно так, как оглавление в книге или предметный указатель. Большинство баз данных 1С по объёму более чем наполовину состоят из индексов. Для каждого индекса обязательно хранится его статистика.
За подробностями внутреннего устройства, как обычно отсылаю в BOL:
В целом MS SQL Server сам справляется с поддержкой целостности и эффективности статистик и индексов, но если никак ему не помогать, то постепенно накапливаются следующие проблемы:
- Статистика становится существенно неточной, причем это выясняется сервером именно в тот момент, когда она нужна.
- Индексы становятся сильно фрагментированными и перемешанными.
- Часть данных на строк, когда-то участвовавших в индексе уже удалена, и из-за этого индекс занимает на диске больше места и требует при выполнении запросов больше операций ввода-вывода.
Для того, чтобы эти накопленные эффекты не влияли на производительность, рекомендуется выполнять регламентное обслуживание статистик и индексов. Так затратив ресурсы на обновление и упорядочивание данных в незагруженное время мы скорее всего не столкнёмся с проблемами во время интенсивной эксплуатации.
Стоит учесть, что 1C для облегчения переносимости архитектуры между разными видами СУБД использует лишь небольшую часть современных возможностей индексирования MS SQL Server. За счет этого обслуживание индексов и статистик несколько упрощается.
Итак, что такое это “обслуживание”? Всё просто.
- Статистика просто пересчитывается. Читается вся таблица или часть случайно выбранных страниц и полностью пересчитывается статистика.
- Индексы могут быть дефрагментированы двумя способами:
- Перестроение — полное построение индекса. При этом обычно станицы становятся максимально плотно забиты данными, а статистика обязательно обновляется (всё равно все данные читать). Обычно данные индексированные данные полностью недоступны при перестроении индекса.
- Реорганизация — серия небольших локальных перемещений страниц так, чтобы индекс не был фрагментирован. При этом статистика не пересчитывается, данные всё время выполнения доступны (точнее, недоступна лишь совсем небольшая часть в каждый момент времени). Но при большой степени фрагментации эта процедура значительно дольше.
Для обслуживания есть специальные “кирпичики” в планах обслуживания (maitenance plan), которые так и называются:
- Update Statistics Task
- Rebuild Index Task
- Reorganize Index Task
Казалось бы всё просто: накидал кирпичиков, соединил стрелочкой и поехали. Такое решение возможно, но оно очень неэффективно:
- Индексы перестраиваются/реорганизуются только все сразу в данной базе. То есть даже если таблица никогда не меняется, её индексы будут перестраиваться. Это очень расточительно, а при полной модели восстановления еще и приводит к огромному росту журналов транзакций.
- Статистики тоже перестраиваются вне зависимости от актуальности, причем даже если они были только что обновлены при перестроении индексов.
- Нет никаких гарантий, что операция обслуживания завершится за то время, которое вы ей выделили.
Решение очень простое: пишется свой скрипт обслуживания, который убирает эти ограничения. Такой скрипт можно запускать из задания (job) MS SQL Server Agent или из “кирпичика” Execute T-SQL Statement Task в планах обслуживания (кому как удобнее). В интернете можно найти много подобных скриптов (в простейшем виде они даже в документации есть), но мне ни один не подошёл, и поэтому я пользуюсь своим “велосипедом”. Этот скрипт и приведён ниже. Он подходит без изменений для большинства баз данных 1С до примерно 0,5-0,7 ТБ (дальше его уже лучше немного доработать, если кому-то интересно/актуально могу пояснить в комментариях).
Особенности скрипта:
- Как и в большинстве подобных скриптов, анализируется динамическое представление sys.dm_db_index_physical_stats, по которому выясняется степень фрагментации и заполненности страниц индекса.
- Можно задать для обработки лишь часть баз данных, можно, наоборот, исключить некоторые БД из обслуживания.
- Контролируется время выполнения скрипта.
- Очень грубо, но оценивается размер записи в журналы транзакций.
- Есть возможность исключить из обработки совсем небольшие таблицы.
- У скрипта есть режим “эмуляции” работы, чтобы оценить то, как он будет работать.
- Сначала обрабатываются самые большие таблицы (так как обычно их обслуживание важнее).
- Скрипт работает на SQL Server 2008 и более поздних (на 2005 тоже должен работать, но мне уже негде проверить)
- Результат вывода в режиме эмуляции сам является корректным TSQL скриптом.
- Ну и конечно, при регулярном выполнении этот скрипт на порядок легче, чем стандартные операции плана обслуживания.
С чем нужно быть осторожным при запуске скрипта:
- Нежелательно пересечение работы скрипта с интенсивной работой пользователей или с полным резервным копированием.
- Чтение из sys.dm_db_index_physical_stats в режиме DETAILED достаточно интенсивно читает с дисков.
- Скрипт предназначен для баз 1С или подобных. Не стоит экспериментировать с ним на совсем специфичных базах данных с нестандартными индексами.
- Если у вас есть таблицы 100-200 ГБ и больше, то при распараллеливании построения индекса, после перестроения он формально снова может оказаться фрагментированным.
- Статистики пересчитываются без полного сканирования. Это заметно быстрее. Если вам нужно полное сканирование каких-то таблиц, то пишите отдельный скрипт.
Рекомендации по запуску:
- Никаких регулярных “шринков” на рабочих базах быть не должно. Еще раз: шринкам не место в регулярном обслуживании!
- При полной модели восстановления я бы поставил полное резервное копирование после обслуживания индексов. Иначе при необходимости восстановления придётся донакатывать достаточно тяжёлый кусок журналов транзакций после восстановления основного образа. Простую модель восстановления на промышленно используемых БД я считаю либо редким исключением, либо частым недоразумением.
- Первый запуск лучше выполнить вручную в SSMS чтобы оценить время работы.
Остальное можно прочитать в коде и в комментариях.
PS: Движок сайта некорректно отобажает текст со знаками больше-меньше, поэтому скрипт приложен файлом, а в статье оставлено только начало скрипта.
-- Параметры скрипта declare @database_names as nvarchar(max) = N''; -- имена баз задавать через запятую, если не заданы, то все несистемные базы -- пока парсер примитивный - строка просто делится по запятым и обрезаются крайние пробелы -- (если в имени базы будет запятая или в начале или конце имени пробел, то система не работает) -- если указано "-ИмяБазы", то база будет исключена, declare @index_size_threshhold as int = 1024; -- минимальный размер в КБ для перестраиваемого индекса. Нет смысла перестраивать индексы на десяток страниц declare @index_rebuild_threshhold as numeric(5,2) = 25; -- показатель фрагментации, начиная с которого происходит перестроение индекса declare @index_defrag_threshhold as numeric(5,2) = 12; -- показатель фрагментации, начиная с которого происходит дефрагментация индекса declare @index_rebuild_space_used_threshhold as numeric(5,2) = 50; -- процент заполненности страниц меньше которого требуется перестроение индекса declare @timeout as int = 7200; -- максимальное время работы скрипта declare @max_size as bigint = 536870912; -- максимальный суммарный обрабатываемый размер в КБ (чтобы не нагенерировать логов на терабайты) -- 512*1024*1024 КБ = 0,5 ТБ declare @is_emulate as bit = 1; -- 0 - выполнять, 1 - только вывести команды
1c-e.ru
Реорганизация / дефрагментация индекса СУБД MS SQL Server — AUsevich
В данной статье рассматривается создание нового (ежедневного) субплана плана обслуживания базы данных на СУБД MS SQL Server, а также настройка выполнения задания реорганизации/дефрагментации индекса. Статья является продолжением статьи «Перечень необходимых задач регламентного обслуживания MS SQL Server».
Предисловие
Индексы таблиц базы данных являются важной составляющей для производительной работы системы. Во время работы с базой данных, при добавлении/изменении/удалении информации из таблиц базы данных, происходит автоматическое обновление индексов, что, в свою очередь, приводит к постепенной фрагментации последних. Фрагментированные индексы могут значительно снизить производительность системы, для их дефрагментации необходимо выполнять соответствующие регламентные операции. Настройку одного из таких мы сейчас и рассмотрим на примере создания ежедневного субплана плана обслуживания.
Настройка задания
В ранее созданный нами план обслуживания (статья «Резервное копирование транзакционного лога») добавим еще один субплан «EveryDayActivity» и назначим расписание его выполнения. Поскольку данный план обслуживания должен выполняться ежедневно (а точнее 6 раз в неделю, т.к. в один из дней недели мы будем выполнять другой, «Еженедельный» план), установим выполнение, например, с понедельника по субботу, в период времени когда пользовательская активность минимальна или ее нет (в моем случае 5:00 утра).
 Свойства субплана «EveryDayActivity»
Свойства субплана «EveryDayActivity» Свойства расписания субплана «EveryDayActivity»
Свойства расписания субплана «EveryDayActivity»Далее, из панели инструментов Планов обслуживания перенесем задание «Реорганизация индекса» (Reorganize Index Task) в рабочую область субплана (т.е. добавим задание в наш субплан).
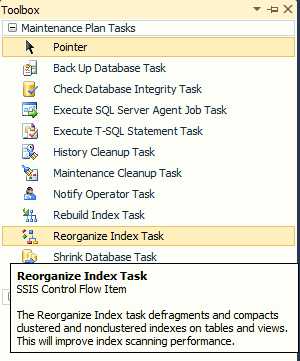 Задача «Реорганизация индекса» в панели инструментов плана обслуживания
Задача «Реорганизация индекса» в панели инструментов плана обслуживанияИ, сразу после этого, двойным щелчком по заданию, откроем его свойства.
Данная задача имеет лишь небольшое количество настроек, тем не менее, рассмотрим их:
- «Базы данных» (Databases): в данном свойстве можно выбрать одну/несколько/все базы данных. Здесь выбор зависит от вашего желания, если план обслуживания создается общий для нескольких баз, можно выбрать все необходимые.
- «Объект» (Object): ограничивает набор данных в поле «Выбор» для отображения таблиц, представлений или обоих элементов. Для наших целей подходит значение «Таблица» (Table)
- «Выбор» (Selection): в данном поле можно выбрать конкретные таблицы, индексы которых, необходимо реорганизовать. Такая возможность может быть полезной, например, если есть таблицы с редко изменяемыми данными, а значит и индексы у них фрагментируются медленно, тогда в целях экономии времени на выполнение задания, можно исключить такие таблицы из ежедневного задания, но включить в еженедельное, например.
- «Сжатие больших объектов» (Compact large objects): сжимает большие объекты (LOB), по умолчанию установлено. Смысла отключать не имеет, разве что для сокращения времени выполнения задания.
 Свойства задачи «Реорганизация индекса»
Свойства задачи «Реорганизация индекса»Таким образом, сейчас у нас должно быть одно задание в новом субплане:
 Субплан «EveryDayActivity»
Субплан «EveryDayActivity»В следующих статьях будет рассмотрено добавление оставшихся заданий в ежедневный субплан плана обслуживания.
ausevich.ru
Есть ли способ имитировать перестроение онлайн-индексов в SQL Server без обновления до Enterprise?
В настоящее время у нас есть SQL Agent Job, который работает один раз в неделю, чтобы идентифицировать индексы с высоким фрагментом и перестроить их. Для некоторых больших индексов на больших таблицах это приводит к тому, что система отключается, так как индекс недоступен во время перестройки.
Мы определили стратегию, которая должна значительно сократить фрагментацию, которая происходит, но которая не будет реализована в течение некоторого времени, и она не охватывает все.
Мы проверили обновление до версии Enterprise, что позволяет перестраивать онлайн-индексы. Тем не менее, стоимость на данный момент является непомерно высокой для нас.
Индексы действительно не так сильно меняются, поэтому мы можем предположить, что они статичны, по крайней мере, по большей части.
Я предвидел способ, которым мы могли бы, возможно, смоделировать перестроение онлайн-индекса. Он мог бы работать следующим образом
Для каждого из идентифицированных больших индексов запустите сценарий, чтобы:
- Проверьте фрагментацию и продолжайте, если она превышает определенный порог.
- Создайте новый индекс под названием CurrentIndex_TEMP.
- Инициировать перестройку индекса.
- Удалите временный индекс.
Похоже, что после создания временного индекса можно было бы перестроить другой индекс без каких-либо простоев, поскольку SQL Server будет иметь еще один индекс, который затем будет доступен для использования в запросах, которые в противном случае использовали бы другой запрос.
Итерация через это для каждого индекса, мы надеемся, позволит свести к минимуму увеличение общего размера индекса, поскольку каждый временный индекс будет удален до того, как будут созданы какие-либо другие временные индексы.
Эта стратегия также сохранит исторические данные об индексах. Первоначально я рассмотрел стратегию первого переименования текущего индекса, затем снова создав его с исходным именем, а затем удалив индекс, который был переименован. Это, однако, приведет к потере истории.
Итак, мой вопрос …
Это приемлемая стратегия? Есть ли серьезные проблемы, с которыми я могу столкнуться? Я понимаю, что время от времени потребуется некоторое ручное наблюдение, но я готов принять это на данном этапе.
Спасибо за помощь.
Solutions Collecting From Web of "Есть ли способ имитировать перестроение онлайн-индексов в SQL Server без обновления до Enterprise?"
Любой автономный индекс перестроит с блокировкой таблицы, чтобы вы ничего не выиграли, создав дублированный индекс.
С большим усилием вы можете имитировать онлайн-перестроения индексов. Вы должны сразу перестроить все индексы в таблице.
- Создайте копию таблицы T с одинаковой схемой (« T_new »)
- Переименуйте T в T_old
- Создайте представление T определенное как select * from T_old и настройте триггеры INSTEAD OF DML, которые выполняют все DML как на T_old и на T_new
- В фоновом задании копировать пакеты из T_old в T_new с помощью оператора T_new
- Наконец, после завершения копирования выполните некоторое переименование и удаление, чтобы сделать T_new новым T
Это требует безумно высоких усилий и хорошего тестирования. Но вы можете реализовать практически любые изменения схемы в этом онлайн-режиме.
sqlserver.bilee.com
Работа с индексами в MS SQL Server Management Studio
Поиск ЛекцийТеоретический материал
Индексы позволяют максимально эффективно находить информацию в огромных базах данных.
SQL Server 2008 поддерживает два базовых типа индексов: кластеризованные и некластеризованные. Индексы обоих типов реализуются как сбалансированное дерево (B-дерево), в котором уровень листьев находится на нижнем уровне структуры. Разница между индексами двух типов состоит в том, что кластеризованный индекс обеспечивает физическое упорядочивание данных на диске. Кластерный индекс является разреженным – указатели в листьях B-дерева ссылаются на страницу данных.
Некластеризованный индекс является плотным и содержит только столбцы, включенные в ключ индекса. В плотных индексах указатели в листьях B-дерева ссылаются на строки реальных данных. Если для таблицы не определен кластеризованный индекс, она называется кучей (heap) или неотсортированной таблицей. В последнем случае таблица физически организуется (отсортирована) в порядке добавления новых записей в отличии от таблиц с кластеризованными индексами, которые упорядочиваются по значениям ключа сортировки. Можно сказать, что таблица может быть представлена в одной из двух форм, в виде кучи или в виде кластеризованного индекса [1].
Кластеризованные индексы
Кластеризованные индексы можно создавать на основе одного или нескольких столбцов таблицы – такой индекс называется индексным ключом и у него есть ряд ограничений:
- индекс не может охватывать не более 16 столбцов;
- максимальный размер индексного ключа – 900 байт.
Столбцы кластеризованного индекса называются ключом кластеризации (clustering key). Кластеризованный индекс оказывает особое влияние на SQL Server, так как заставляет его упорядочивать данные в таблице согласно ключу кластеризации. Поскольку таблица может упорядочиваться лишь одним способом, в ней можно задать лишь один кластеризованный индекс.
Кластеризованные индексы задают порядок сортировки данных в таблице. Однако кластеризованные индексы не обеспечивают порядок физической сортировки. Кластеризованный индекс не приводит к физическому упорядочиванию данных на диске, потому что это привело бы к большому числу операций дискового ввода-вывода при разбиении страниц. Он лишь гарантирует, что индексированная цепочка страниц упорядочена логически, что позволяет SQL Server при поиске данных переходить прямо по цепочке страниц. В процессе движения сервера SQL Server по индексированной цепочке страниц строки данных считываются в порядке ключа кластеризации [2].
Некластеризованный индекс
Некластеризованный индекс не накладывает никаких ограничений на упорядочивание записей в таблице, поэтому в одной таблице можно создать много некластеризованных индексов, но у этих индексов такие же ограничения, как и у кластеризованных индексов:
- индекс не может охватывать не более 16 столбцов;
- максимальный размер индексного ключа – 900 байт.
Конечный уровень некластеризованного индекса содержит указатель на нужные данные. Если в таблице есть кластеризованный индекс, конечный уровень некластеризованного индекса указывает на ключ кластеризации. Если же кластеризованного индекса нет, страницы конечного уровня указывают на строки данных в таблице [2].
Общий синтаксис создания реляционного индекса таков:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED] INDEX имя_индекса
ON <объект> (column [ASC | DESC] [, … n])
[INCLUDE (имя_столбца [, … n] )]
[WHERE <предикат_фильтра> ]
[WITH (<параметры_реляционного_индекса> [, … n] )]
[ON {имя_схемы_секции ( имя_столбца ) | имя_файловой_группы | default }]
[FILESTREAM_ON { имя_файловой_группы_filestream | имя_схемы_секции | «NULL»}][ ; ] [3]
Составной индекс
Составной индекс может быть создан на основании нескольких полей. В этом случае справедливы ограничения описанные ранее. Если индекс построен по полям с фиксированным размером, сумма длин этих полей должна не превышать эти 900 байт, если индекс построен по полям с переменной длинной, сумма максимальных размеров полей может превышать 900 байт, но само значение сумм по каждой записи не может быть больше 900 байт. Например, в таблице есть два поля переменной длины по 500 байт. SQL Server позволяет создать составной ключ на базе этих двух полей, если нет записей, сумма длин по обоим полям которых превышает 900 байт. Стоит обратить внимание на тот момент, что составной индекс для (Column1, Column2) является отличным от (Column2, Column1), а так же от индексов, созданных по двум этим полям в отдельности.
Фрагментация индексов
Файлы операционной системы обычно со временем фрагментируются из-за многократных операций записи. Индексы тоже могу становится фрагментированными, но фрагментация индексов отличается от фрагментации файлов.
При создании индекса все значения ключа индекса записываются в упорядоченном виде на страницах индекса. При удалении строки из таблицы SQL Server должен удалить соответствующею запись в индексе, что создает "дыры" на странице индекса. SQL Server не возвращает освобожденное пространство из-за слишком высокой стоимости операции обнаружения и повторного использования "дыр" в индексе. Если значение в базовой таблице изменяется, SQL Server перемещает запись с указателем в другое место, что создает еще одну "дыру". При переполнении страниц индексов и потребности разбиения страниц снова происходит фрагментация индекса. Со временем индексы таблицы, в которых происходит изменение данных, становятся фрагментированными [2].
Для управления степенью фрагментации индекса обычно используют параметр, который называется коэффициентом заполнения (fill factor). Для устранения фрагментации можно так же задействовать инструкцию ALTER INDEX. Параметр fill factor - это параметр индекса, который определяет долю свободного пространства, которое резервируется на каждой странице конечного уровня при создании или перестроении индекса. Зарезервированное пространство позволяет в дальнейшем размещать дополнительные значения, снижая таким образом число разбиений страниц Коэффициент заполнения измеряется в целых процентах, например значение 75 означает, что каждая создаваемая страница конечного уровня должно содержать 25% свободного пространства для размещения будущих значений [1].
Дефрагментация индексов
Поскольку SQL Server не возвращает пространство в систему, надо периодически освобождать пустое пространство в индексе, чтобы сохранить тот выигрыш в производительности, из-за которого индекс изначально создавался. Для дефрагментации индексов используют инструкцию ALTER INDEX [2].
ALTER INDEX { index_name | ALL }
ON <object>
{ REBUILD
[ [PARTITION = ALL]
[ WITH ( <rebuild_index_option> [ ,...n ] ) ]
| [ PARTITION =partition_number
[ WITH ( <single_partition_rebuild_index_option>
[ ,...n ] )
]
]
]
| DISABLE
| REORGANIZE
[ PARTITION =partition_number ]
[ WITH ( LOB_COMPACTION = { ON | OFF } ) ]
| SET ( <set_index_option> [ ,...n ] )
}
[ ; ] [3]
При дефрагментации индексов можно выбрать параметры REBUILD или REORGANIZE.
Первый параметр перестраивает все уровни индекса и заполняет страницы в соответствии с параметром fill factor. При перестроении кластеризованного индекса перестраивается только он, однако если задать параметр ALL, будет перестроен как кластеризованный, так и все некластеризованные индексы таблицы. Перестроение индекса обновляет всю структуру сбалансированного дерева, поэтому, если не задан параметр ONLINE, таблица блокируется до завершения перестроения [2]. Например, для того, чтобы перестроить индекс IX_BillID, таблицы BillItem, необходимо выполнить следующий запрос:
ALTER INDEX IX_BillID
ON BillItem
REBUILD
Параметр REORGANIZE устраняет дефрагментацию только на конечном уровне. Страницы промежуточного уровня и корневая страница не дефрагментируются. Операция REORGANIZE всегда выполняется в оперативном режиме, поэтому не вызывает долгосрочной блокировки таблицы. [2] Например, чтобы реорганизовать индекс IX_BillID, таблицы BillItem, необходимо выполнить следующий запрос:
ALTER INDEX IX_BillID
ON BillItem
REORGANIZE
Работа с индексами в MS SQL Server Management Studio
Для того что бы посмотреть какие индексы созданы нужно, открыть вкладку Index таблицы Bill на панели Object Explorer. Полный путь до вкладки: Databases ® EducationDatabase ® Tables ® [имя таблицы] ® Indexes показан на рисунке 1.1. Согласно рисунку для данной таблицы создан один кластеризованный индекс PK_Bill.
Проверьте наличие кластеризованных индексов во всех таблицах базы данных самостоятельно.

Рисунок 1.1 – Object Explorer, раскрытая вкладка Indexes
Создадим дополнительный индекс по полю внешнего ключа BillID таблицы BillItem. Создать индекс можно двумя способами:
Выполнение запроса CREATE INDEX. Создадим запрос в новой вкладке, нажав кнопку New Query стандартной панели инструментов. Панель инструментов показана на рисунке 1.2.
Рисунок 1.2 – Панель инструментов
После открытия новой вкладки, выполним запрос, показанный на рисунке 1.3. Для того что бы выполнить запрос, необходимо нажать кнопку Execute на панели инструментов (рисунок 1.2), или нажать клавишу F5 на клавиатуре.

Рисунок 1.3 – Запрос CREATE INDEX
С помощью графического интерфейса Microsoft SQL Server Management Studio. В контекстном меню, вкладки Indexes выбираем пункт New Index, как показано на рисунке 1.4.
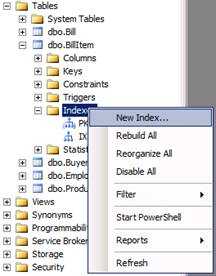
Рисунок 1.4 – Контекстное меню вкладки Indexes
В открывшемся окне необходимо указать имя индекса, атрибуты сортировки и тип индекса (кластерный, некластерный или первичный индекс XML). Если в таблице уже существует кластеный индекс, то при попытке создать новый кластерный индекс система выдаст предупреждение о возможности удаления существующего индекса и создания нового. При создании кластерного индекса происходит перестроение всех некластерных индексов.
Кроме того, в окне создания индекса можно указать признак поддержки уникальности значений в индексируемых полях. Наличие такого индекса будет препятствовать добавлению дублированных значений в индексированные поля.
Содержание работы
1. Проверьте наличие индексов по ключевым полям таблицы. При необходимости создайте кластеризованные индексы. Для создания нового индекса воспользуйтесь командой CREATE INDEX, или в среде Microsoft SQL Management Studio в разделе Tables/имя_таблицы/Indexes используйте команду New Index…
2. Создайте некластеризованные индексы по полям внешних ключей таблиц базы данных. Объясните, для чего нужны такие индексы?
3. Создайте некластеризованные индексы по информационным полям: Name и Date во всех таблицах базы данных. Объясните, для чего нужны такие индексы?
4. Для кластерного индекса и индекса по полю Date таблицы записей в чеке получите сведения о расширенных свойствах индексов. Объяснить значение информации, представленной в разделе «Fragmentation» на странице «Properties». Объясните, как вычислена глубина дерева индекса, число листьев, коэффициент фрагментации.
5. Перестройте кластеризованный индекс таблицы BillItem, используя команду ALTER INDEX или с помощью команды Rebuild в контекстном меню индекса.
6. Подготовьте материал для включения в отчетную презентацию по курсу Базы данных: специальный курс.
poisk-ru.ru
Повреждение данных в SQL Server 2012 и 2014 при перестроении индексов в режиме online
Всегда, когда заходит речь о причинах повреждения данных в SQL Server, я называю программные ошибки в операционной системе и самом продукте. К счастью, это крайне редкий случай, но всем людям свойственно ошибаться, а SQL Server тоже пишут люди. Один их таких случаев произошел совсем недавно и затрагивает новые версии продуктов: SQL Server 2012 и 2014. Если кратко, то при онлайн перестроении индексов в вышеуказанных продуктов может возникнуть повреждение индексов или потеря данных, если при этом параллельно выполняются запросы на изменение большого количества строк и в определенном порядке возникает ошибка взаимоблокировки и фатальная ошибка, такая как «lock timeout». Проблема довольно серьезная, поэтому стоит обратить на нее очень пристальное внимание и установить вышедшие обновления. Дополнительно описание и ссылку на скачивание исправлений можно получить по нижеуказанной ссылке. Исправление доступно только для SQL Server 2012 SP1 и SP2, а также SQL Server 2014. Для SQL Server 2012 RTM его нет и не предвидится. FIX: Data corruption occurs in clustered index when you run online index rebuild in SQL Server 2012 or SQL Server 2014 Стоит обратить особое внимание на то, что недавно вышедший SP2 для SQL Server 2012 не содержит указанного исправления. Поэтому, если вы придерживаетесь политики ставить только сервис паки и игнорируете кумулятивные обновления или установку отдельных исправлений, то у вас могут возникнуть большие проблемы. На мой взгляд, ситуация, когда организации переходят на новые версии продукта тогда, когда становится доступен только первый или второй сервис пак не оправдана. Да, я согласен с тем, что не стоит бросаться сломя голову и обновлять ваш сервер, как только вышла новая версия продукта, но и ждать так долго тоже не имеет смысла. Сейчас мир меняется очень быстро, и релиз циклы начинают уменьшаться, что мы все отчетливо можем наблюдать эту тенденцию на примере версий 2012 и 2014. Второй сервис пак для SQL Server 2012 вышел уже после официального выхода SQL Server 2014, а третий, я боюсь, уже не будет выпущен. Но немного вернемся к основной проблеме. Как проверить, что на ваш SQL Server установлены все необходимые исправления? Для этого выполните команду select @@version на вашем сервере и результат сверьте с нижеприведенной таблицей:
| SQL Server 2012 RTM | Для указанной версии обновлений недоступно. Рекомендуется установить первый или второй сервис пак, а потом исправление KB #2969896. |
| SQL Server 2012 SP1 | В случае, если версия ниже 11.0.3437, то установите исправление KB #2969896. |
| SQL Server 2012 SP2 | В случае, если версия ниже 11.0.5522, то установите исправление KB #2969896. |
| SQL Server 2014 RTM | В случае, если версия ниже 12.0.2370, то установите исправление KB #2969896или второй накопительный пакет исправлений KB # 2967546. |
В случае, если вы по каким-то причинам сейчас не можете установить обновления, например, вам необходимо провести полный цикл его тестирования внутри компании, то можно временно использовать следующие обходные пути:
- Вы можете временно отключить перестроение индексов совсем.
- Вы можете установить опцию max degree of parallelism на уровне сервера в значение 1, но учтите, что это может негативно сказаться на производительности остальных запросов.
- Вы можете добавить опцию WITH (MAXDOP = 1) ко всем командам перестроения индексов. В случае, если вы используете стандартные Maintenance Plans, то в них нет возможности указать, что перестроение индексов необходимо делать в однопоточном режиме. Если вы используете какие-либо еще утилиты для перестроения индексов, то уточняйте возможность перестроения в однопоточном режиме в их документации.
olontsev.ru
- Что не рекомендуется указывать в пароле

- Не включается плеер

- Windows 7 как узнать сервис пак
- Ошибка 0x0000009c
- Пропал вай фай на ноуте что делать

- Откуда пришло слово компьютер

- Тотал коммандер для чего нужен

- Sql insert несколько строк
- Рабочий стол пропал на виндовс 8
- Скриптование что это

- Загрузка и восстановление в windows 10