Pl sql pivot: PIVOT оператор — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Содержание
Оператор PIVOT / Хабр
По материалам статьи Craig Freedman: The PIVOT Operator
Несколько статей будут посвящены тому как в SQL Server реализован оператор PIVOT и UNPIVOT. Начнем с оператора PIVOT. Оператор PIVOT берет нормализованную таблицу и преобразует ее в другой вид, в котором столбцы результирующей таблицы получаются из значений исходной таблицы. Например, предположим, что мы хотим хранить данные о суммарной выручке от продаж за год по каждому из сотрудников. Для этих целей можно создать следующую таблицу:
CREATE TABLE Sales (EmpId INT, Yr INT, Sales MONEY) INSERT Sales VALUES(1, 2005, 12000) INSERT Sales VALUES(1, 2006, 18000) INSERT Sales VALUES(1, 2007, 25000) INSERT Sales VALUES(2, 2005, 15000) INSERT Sales VALUES(2, 2006, 6000) INSERT Sales VALUES(3, 2006, 20000) INSERT Sales VALUES(3, 2007, 24000)
Обратите внимание, что в этой таблице на одного сотрудника приходится одна строка на каждый год. Кроме того, сотрудники 2 и 3 имеют данные о продажах только за два года из трех. Теперь предположим, что мы хотим показать эти данные в табличном виде с одной строкой на каждого сотрудника и данными о продажах за все три года в этой строке. Мы можем очень легко добиться этого, используя оператор преобразования PIVOT:
Теперь предположим, что мы хотим показать эти данные в табличном виде с одной строкой на каждого сотрудника и данными о продажах за все три года в этой строке. Мы можем очень легко добиться этого, используя оператор преобразования PIVOT:
SELECT EmpId, [2005], [2006], [2007] FROM (SELECT EmpId, Yr, Sales FROM Sales) AS s PIVOT (SUM(Sales) FOR Yr IN ([2005], [2006], [2007])) AS p
Я не буду углубляться в синтаксис PIVOT, который хорошо описан в электронной документации. Достаточно сказать, что использование этого оператора позволяет суммировать продажи по каждому сотруднику за каждый год, перечисленный в списке, и представить результат в виде одной строки для каждого сотрудника. Ниже представлена результирующая выборка:
EmpId 2005 2006 2007 ----------- --------------------- --------------------- --------------------- 1 12000.00 18000.00 25000.00 2 15000.00 6000.00 NULL 3 NULL 20000.00 24000.00
 00 NULL
3 NULL 20000.00 24000.00
00 NULL
3 NULL 20000.00 24000.00Обратите внимание, что SQL Server выводит NULL для отсутствующих данных о продажах сотрудников 2 и 3.
Ключевое слово SUM (или либо другой агрегат) является обязательным. Если таблица «Sales» содержит для сотрудника за какой-то год несколько строк, PIVOT в результате объединяет их (в данном случае путем суммирования) в одну строку данных. Разумеется, поскольку в этом примере запись в каждой «ячейке» выборки является результатом суммирования одной строки, мы также легко могли бы использовать и другой агрегат, например, MIN или MAX. Я использовал SUM, поскольку он более интуитивно понятен.
Этот пример с PIVOT является обратимым. Информацию из выборки можно использовать для восстановления исходной таблицы с помощью оператора UNPIVOT (о котором я расскажу в следующей статье). Однако не все операции с PIVOT являются обратимыми. Чтобы быть обратимой, операция с PIVOT должна соответствовать следующим критериям:
Все входные данные должны подпадать под преобразование.
Если будет использоваться какой-либо фильтр, в том числе предложение IN, некоторые данные могут быть исключены из результата PIVOT. Например, если бы мы в приведенном выше примере выбирали данные о продажах только за 2006 и 2007 годы, очевидно, что мы не смогли бы восстановить из выборки данные о продажах за 2005 год.Каждая ячейка результирующей таблицы должна быть получена из одной строки таблицы на входе. Если в одну ячейку будут объединены несколько строк таблицы на входе, восстановить исходные входные строки будет невозможно.
Агрегатная функция должна быть реверсивной (при использовании одной строки на входе). SUM, MIN, MAX и AVG возвращают одно, полученное из таблицы на входе значение без изменений и, таким образом, могут быть реверсированы. COUNT не возвращает свое входное значение без изменений и, следовательно, не может быть обратимо.
 Если будет использоваться какой-либо фильтр, в том числе предложение IN, некоторые данные могут быть исключены из результата PIVOT. Например, если бы мы в приведенном выше примере выбирали данные о продажах только за 2006 и 2007 годы, очевидно, что мы не смогли бы восстановить из выборки данные о продажах за 2005 год.
Если будет использоваться какой-либо фильтр, в том числе предложение IN, некоторые данные могут быть исключены из результата PIVOT. Например, если бы мы в приведенном выше примере выбирали данные о продажах только за 2006 и 2007 годы, очевидно, что мы не смогли бы восстановить из выборки данные о продажах за 2005 год.Ниже представлен пример необратимой операции PIVOT. В нём рассчитывается общий объем продаж для всех сотрудников за все три года, но результат не детализируется по сотруднику.
SELECT [2005], [2006], [2007] FROM (SELECT Yr, Sales FROM Sales) AS s PIVOT (SUM(Sales) FOR Yr IN ([2005], [2006], [2007])) AS p
Результат исполнения запроса показан ниже. Каждая ячейка представляет собой сумму двух или трех строк таблицы на входе.
2005 2006 2007 --------------------- --------------------- --------------------- 27000.00 44000.00 49000.00
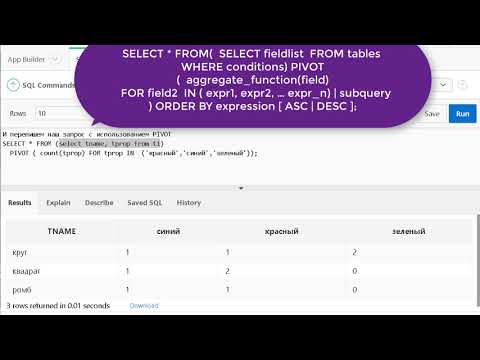
sql — Как задать столбцы для функции PIVOT динамически подзапросом?
В этом вопросе стояла задача: развернуть строки в столбцы за 12 месяцев, другими словами кол-во и имена столбцов были заранее известны.
А что если желаемые столбцы в результате заранее неизвестны?
Функция PIVOT допускает использовать подзапрос (или даже ключевое слово ANY) (см. pivot_in_clause), но только в сочетании с ключевым словом XML для вывода в XML формате:
The optional XML keyword generates XML output for the query. The XML keyword permits the pivot_in_clause to contain either a subquery or the wildcard keyword ANY.
 Subqueries and ANY wildcards are useful when the pivot_in_clause values are not known in advance.
Subqueries and ANY wildcards are useful when the pivot_in_clause values are not known in advance.Например, запрос и его результат за весь период будут выглядеть так:
select * from (
select name, qty, to_char (dt, 'mon') mon
from tstdata)
pivot xml (sum (qty) for mon in (select distinct to_char (dt, 'monyy') mon from tstdata))
/
NAME MON_XML
-------- --------------------------------------------------------------------------------
Петя <PivotSet><item><column name = "MON">apr19</column><column name = "SUM(QTY)"></c
Саша <PivotSet><item><column name = "MON">apr19</column><column name = "SUM(QTY)"></c
А как получить результат сразу в табличном виде и с чем связано это ограничение?
Можно конечно распарсить XML, например, написав PL/SQL табличную функцию, но это ведь не так просто.
Генерация тестовых данных db<>fiddle (см. историю правок, если ссылка недоступна).
историю правок, если ссылка недоступна).
- sql
- oracle
- plsql
- pivot
4
Столбцы в функции PIVOT, их кол-во и тип данных, на момент парсинга (hard-parse) должны быть известены. XML результат, это один столбец и тип его известен, отсюда и ограничение.
Самый простое решение, сделать два запроса, первым получить желаемые столбцы, а вторым получить результат для этих столбцов. Как-то так:
set autoprint on
var rc refcursor
begin
for r in (
select listagg (''''||mon||''' '||mon, ',') within group (order by mm) cols
from (
select distinct to_char (dt, 'monyy') mon, to_char (dt, 'yyyymm') mm from tstdata)
) loop
open :rc for '
select * from (
select name, qty, to_char (dt, ''monyy'') mon
from tstdata)
pivot (sum (qty) for mon in ('||r. cols||'))';
end loop;
if not :rc%isopen then open :rc for select 'no data found' msg from dual; end if;
end;
/
 cols||'))';
end loop;
if not :rc%isopen then open :rc for select 'no data found' msg from dual; end if;
end;
/
cols||'))';
end loop;
if not :rc%isopen then open :rc for select 'no data found' msg from dual; end if;
end;
/
Результат (укорочен для наглядности):
NAME JAN19 FEB19 MAR19 APR19 [...] NOV20 DEC20 -------- ---------- ---------- ---------- ---------- ---------- ---------- Петя 32 28 30 30 [...] 30 30 Саша 15 14 16 15 [...] 15 15
Существуют также другие решения без функции PIVOT, которые пытаются определить столбцы в сете результата динамическии. Как в частности:
- Т.н. Antons pivoting любезно предоставленный участником @MaxU
- Dynamic Pivot PFT пример реализации опубликованный участником @Chris Saxon
Они конечно дают некоторый комфорт по сравнению с решением с двумя запросами.
Но сновной принцип остаётся прежним: столбцы в сете результата должны быть известны парсеру SQL; после компиляции запроса, нет никакой возможности изменить столбцы в сете результата.
Посмотрим на примере Dynamic Pivot with PFT, т.к. код на Live SQL проще воспроизвести:
with rep as (
select name, to_char (dt, 'yyyy') year
from tstdata where name='Саша'
)
select *
from dynamic_pivot_ptf (
rep, columns (year),
'select distinct to_char (dt, ''yyyy'') from tstdata')
/
NAME 2019 2020
-------- ---------- ----------
Саша 182 183
delete from tstdata where name='Саша' and dt<date'2020-01-01';
182 rows deleted.
После удаления вроде ожидается, что и столбец 2019 теперь тоже «динамически» исчезнет.
Нет, это не так. Повторите запрос выше. Он не изменился, его скомпилированный байт-код будет вызван из Library Cache, соответственно и столбцы в сете результата останутся неизменными:
NAME 2019 2020 -------- ---------- ---------- Саша null 183
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Сводка и развертка Oracle Database 11g
Сожалеем.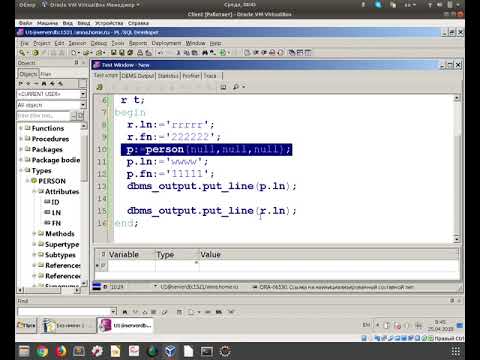 Мы не смогли найти совпадение по вашему запросу.
Мы не смогли найти совпадение по вашему запросу.
Мы предлагаем вам попробовать следующее, чтобы найти то, что вы ищете:
- Проверьте правильность написания вашего ключевого слова.
- Используйте синонимы для введенного вами ключевого слова, например, попробуйте «приложение» вместо «программное обеспечение».
- Начать новый поиск.
Связаться с отделом продаж
Меню
Меню
Лучшие функции для администраторов баз данных и разработчиков
Аруп Нанда, директор Oracle ACE
Pivot и Unpivot
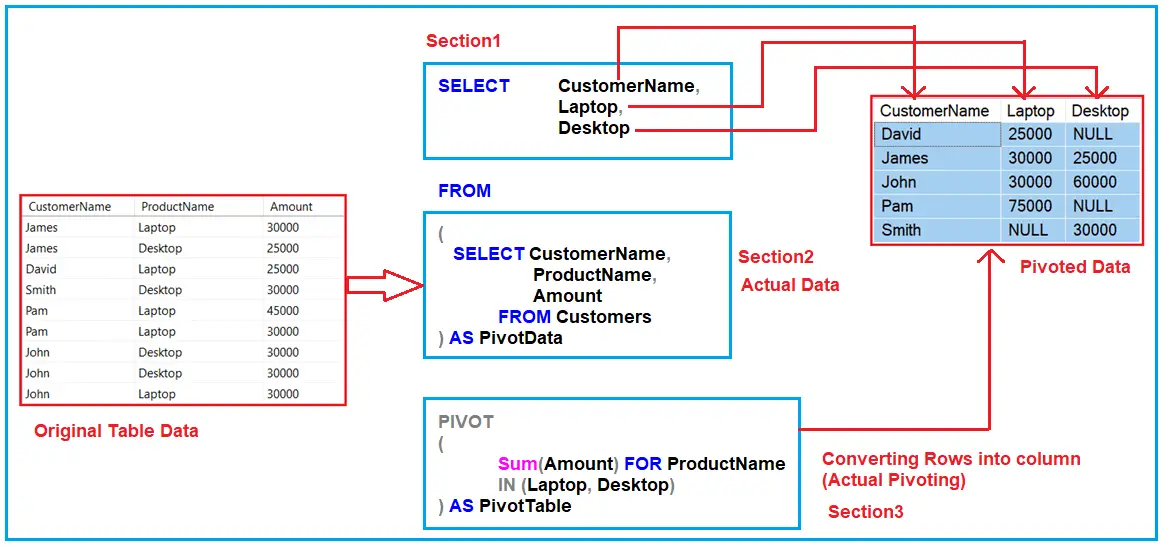
Представление информации в отчете кросс-таблицы типа электронной таблицы из любой реляционной таблицы с использованием простого SQL и сохранение любых данных из таблицы кросс-таблицы в реляционную таблицу.
См. оглавление серии
Сводная таблица
Как вы знаете, реляционные таблицы являются табличными, то есть они представлены в виде пары столбец-значение. Рассмотрим случай с таблицей CUSTOMERS.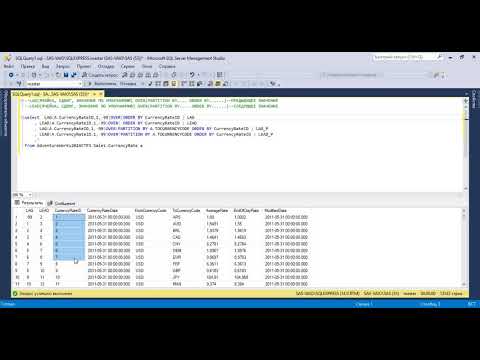
SQL> desc клиенты Имя Нуль? Тип ----------------------------------------- -------- - -------------------------- CUST_ID НОМЕР(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)
При выборе этой таблицы:
выберите cust_id, state_code, times_purchased от клиентов заказ по cust_id;
Вывод:
CUST_ID STATE_CODE TIMES_PURCHASED
------- ---------- ---------------
1 КТ 1
2 НЙ 10
3 Нью-Джерси 2
4 Нью-Йорк 4
...
и так далее ...
Обратите внимание на то, как данные представлены в виде строк значений: для каждого покупателя запись показывает домашний штат покупателя и количество покупок, которые он совершал в магазине. По мере того, как покупатель покупает больше товаров в магазине, столбец times_purchased обновляется.
Теперь рассмотрим случай, когда вы хотите получить отчет о частоте покупок в каждом штате, т. е.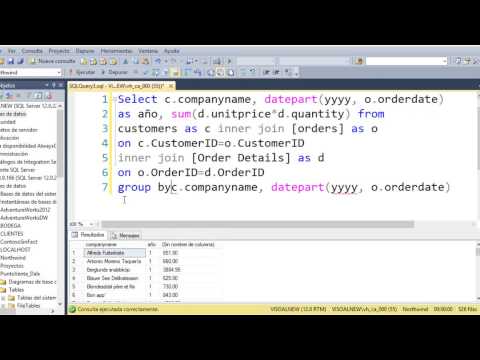 сколько клиентов купили что-то только один раз, дважды, трижды и так далее в каждом штате. В обычном SQL вы можете ввести следующий оператор:
сколько клиентов купили что-то только один раз, дважды, трижды и так далее в каждом штате. В обычном SQL вы можете ввести следующий оператор:
выберите state_code, times_purchased, count(1) cnt от клиентов группировать по state_code, times_purchased;
Вот результат:
ST TIMES_PURCHASED CNT
-- -------------- ----------
КТ 0 90
КТ 1 165
КТ 2 179
КТ 3 173
КТ 4 173
КТ 5 152
...
и так далее ...
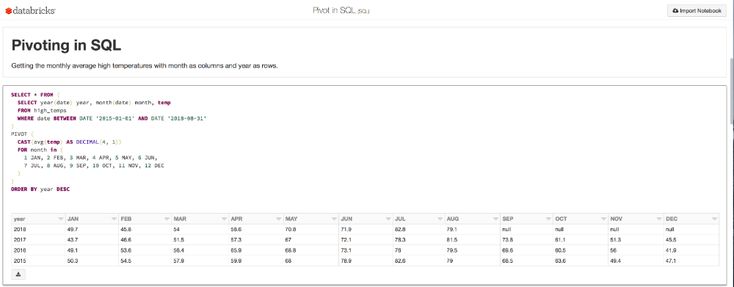
Это нужная вам информация, но ее трудно прочитать. Лучшим способом представления одних и тех же данных может быть использование отчетов в виде перекрестных таблиц, в которых вы можете организовать данные по вертикали, а состояния по горизонтали, как в электронной таблице:
Times_purchased
CT NY NJ ...
и так далее ...
1 0 1 0 ...
2 23 119 37 ...
3 17 45 1 ...
...
и так далее . ..
 ..
..
До Oracle Database 11 g это можно было сделать с помощью некоторой функции декодирования для каждого значения и записать каждое отдельное значение в виде отдельного столбца. Однако техника довольно неинтуитивна.
К счастью, теперь у вас есть отличная новая функция PIVOT для представления любого запроса в формате кросс-таблицы с использованием нового оператора с соответствующим названием pivot . Вот как вы пишете запрос:
выберите из (
выберите times_purchased, state_code
от клиентов т
)
вращаться
(
количество (код_состояния)
для state_code в ('NY','CT','NJ','FL','MO')
)
заказать по times_purchased
/
Вот результат:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ---------- ---------- ----- ----- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
. .. и так далее ...
 .. и так далее ...
.. и так далее ...
Здесь показана мощность оператора Pivot . Коды состояний представлены в строке заголовка, а не в столбце. Наглядно вот как выглядит традиционный табличный формат:
Рисунок 1 Традиционное табличное представление
В кросс-таблице вы хотите транспонировать столбец «Количество покупок» в строку заголовка, как показано на рис. 2. Столбец становится строкой, как если бы столбец был повернут на 90 градусов против часовой стрелки, чтобы стать строкой заголовка. Это образное вращение должно иметь точку поворота, и в этом случае точкой поворота является выражение count(state_code).
Рисунок 2 Поворотное представление
Это выражение должно быть в синтаксисе запроса:
...
вращаться
(
количество (код_состояния)
для state_code в ('NY','CT','NJ','FL','MO')
)
...
Вторая строка, «for state_code. ..», ограничивает запрос только этими значениями. Эта строка необходима, поэтому, к сожалению, вы должны заранее знать возможные значения. Это ограничение ослаблено в XML-формате запроса, описанном далее в этой статье.
..», ограничивает запрос только этими значениями. Эта строка необходима, поэтому, к сожалению, вы должны заранее знать возможные значения. Это ограничение ослаблено в XML-формате запроса, описанном далее в этой статье.
Обратите внимание на строки заголовков в выходных данных:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ---------- ---------- ----- ----- ----------
Заголовки столбцов — это данные из самой таблицы: коды состояний. Аббревиатуры могут говорить сами за себя, но предположим, вы хотите отображать названия штатов вместо аббревиатур («Коннектикут» вместо «КТ»)? В этом случае вам нужно внести небольшие коррективы в запрос в предложении FOR, как показано ниже:
выберите из (
выберите times_purchased как «Частота покупок», state_code
от клиентов т
)
вращаться
(
количество (код_состояния)
для state_code в ("NY" как "Нью-Йорк", "CT" "Коннектикут", "NJ" "Нью-Джерси", "FL" "Флорида", "MO" как "Миссури")
)
заказать по 1
/
Частота покупок Нью-Йорк Коннектикут Нью-Джерси Флорида Миссури
------------------ ---------- ----------- ---------- -- -------- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
. ..
и так далее ...
 ..
и так далее ...
..
и так далее ...
Предложение FOR может иметь псевдонимы для значений, которые станут заголовками столбцов.
Unpivot
Для материи есть антиматерия; для поворота должно быть «разворот», верно?
Шутки в сторону, есть реальная необходимость в обратной операции поворота. Предположим, у вас есть электронная таблица, в которой показан перекрестный отчет, показанный ниже:
| Частота покупок | Нью-Йорк | Коннектикут | Нью-Джерси | Флорида | Миссури |
|---|---|---|---|---|---|
| 0 | 12 | 11 | 1 | 0 | 0 |
| 1 | 900 | 14 | 22 | 98 | 78 |
| 2 | 866 | 78 | 13 | 3 | 9 |
| … | . |
Теперь вы хотите загрузить данные в реляционную таблицу CUSTOMERS:
SQL> desc клиенты Имя Нуль? Тип ----------------------------------------- -------- - -------------------------- CUST_ID НОМЕР(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)
Данные электронной таблицы должны быть денормализованы в реляционном формате, а затем сохранены. Конечно, вы можете написать сложный сценарий SQL*:Loader или SQL, используя DECODE для загрузки данных в таблицу CUSTOMERS. Или вы можете использовать обратную операцию pivot —UNPIVOT— чтобы разбить столбцы на строки, как это возможно в Oracle Database 11 g .
Возможно, будет проще продемонстрировать это на примере. Давайте сначала создадим кросс-таблицу, используя операцию сводной :
1 создать таблицу cust_matrix 2 как 3 выберите * из ( 4 выберите times_purchased как «Частота покупок», state_code 5 от клиентов т 6 ) 7 поворот 8 ( 9 счет (код_состояния) 10 для state_code в («NY» как «Нью-Йорк», «CT» «Конн», «NJ» «Нью-Джерси», «FL» «Флорида», «MO» как «Миссури») 11 ) 12* заказать по 1
Вы можете проверить, как данные хранятся в таблице:
SQL> выберите * из cust_matrix
2 /
Частота покупок Нью-Йорк Конн Нью-Джерси Флорида Миссури
------------------ ---------- ---------- ---------- --- ------- ---------
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109173 0 1 0
. .. и так далее ...
 .. и так далее ...
.. и так далее ...
Вот как данные хранятся в электронной таблице: Каждый штат представляет собой столбец в таблице («Нью-Йорк», «Коннектикут» и т. д.).
SQL> описание cust_matrix Имя Нуль? Тип ----------------------------------------- -------- - -------------------------- Частота покупок NUMBER(3) Нью-Йорк НОМЕР НОМЕР соединения НОМЕР Нью-Джерси Флорида НОМЕР НОМЕР Миссури
Вам нужно разбить таблицу, чтобы строки отображали только код состояния и количество для этого состояния. Это можно сделать с помощью операции unpivot , показанной ниже:
выбирать *
из cust_matrix
развернуть
(
state_counts
для state_code в ("Нью-Йорк", "Конн", "Нью-Джерси", "Флорида", "Миссури")
)
сортировать по "Частоте покупок", state_code
/
Вот результат:
Частота покупок STATE_CODE STATE_COUNTS
------------------ ---------- ------------
1 соединение 165
1 Флорида 0
1 Миссури 0
1 Нью-Джерси 0
1 Нью-Йорк 33048
2 соединение 1792 Флорида 0
2 Миссури 0
. ..
и так далее ...
 ..
и так далее ...
..
и так далее ...
Обратите внимание, как имя каждого столбца стало значением в столбце STATE_CODE. Как Oracle узнал, что state_code — это имя столбца? Это было известно из следующего предложения запроса:
для state_code в ("Нью-Йорк", "Конн", "Нью-Джерси", "Флорида", "Миссури")
Здесь вы указали, что значения «Нью-Йорк», «Конн» и т. д. являются значениями нового столбца, который вы хотите отменить, с именем state_code. Посмотрите на часть исходных данных:
Частота покупки Нью-Йорк Конн Нью-Джерси Флорида Миссури
------------------ ---------- ---------- ---------- --- ------- - ---------
1 33048 165 0 0 0
Поскольку столбец «Нью-Йорк» внезапно стал значением в строке, как бы вы отобразили значение 33048, под каким столбцом? На этот вопрос отвечает предложение чуть выше предложения for внутри оператор unpivot в приведенном выше запросе. Поскольку вы указали state_counts, это имя нового столбца, созданного в результирующем выводе.
Поскольку вы указали state_counts, это имя нового столбца, созданного в результирующем выводе.
Разворот может быть противоположным действием разворота , но не думайте, что первый может обратить вспять то, что сделал второй. Например, в приведенном выше примере вы создали новую таблицу CUST_MATRIX, используя сводную операцию для таблицы CUSTOMERS. Позже вы использовали unpivot для таблицы CUST_MATRIX, но это не вернуло детали исходной таблицы CUSTOMERS. Вместо этого отчет кросс-таблицы отображался другим способом для загрузки в реляционную таблицу. Так unpivot не предназначен для отмены того, что сделал pivot , факт, который вы должны тщательно обдумать, прежде чем создавать сводную таблицу, а затем удалять исходную.
Некоторые из очень интересных применений unpivot выходят за рамки обычных мощных манипуляций с данными, таких как пример, показанный ранее. Директор Oracle ACE Лукас Йеллема из Amis Technologies показал, как можно генерировать строки определенных данных для целей тестирования. Здесь я буду использовать слегка измененную форму его исходного кода для генерации гласных английского алфавита:
Здесь я буду использовать слегка измененную форму его исходного кода для генерации гласных английского алфавита:
выберите значение
от
(
(
выбирать
а v1,
е v2,
'я' v3,
'о' v4,
'у' v5
из двойного
)
развернуть
(
ценить
для value_type в
(v1,v2,v3,v4,v5)
)
)
/
Вот результат:
В - а е я о ты
Эта модель может быть расширена для любого типа генератора рядков. Спасибо, Лукас, что показал нам этот изящный трюк.
Тип XML
В приведенном выше примере обратите внимание на то, как вы должны были указать допустимые коды состояния:
для state_code в ('NY','CT','NJ','FL','MO')
Это требование предполагает, что вы знаете, какие значения присутствуют в столбце state_code. Если вы не знаете, какие значения доступны, как бы вы построили запрос?
Ну, в операции Pivot есть еще одно предложение, XML, которое позволяет вам создавать сводные выходные данные в виде XML, где вы можете указать специальное предложение ANY вместо литеральных значений. Вот пример:
Вот пример:
выберите из (
выберите times_purchased как «Частота покупок», state_code
от клиентов т
)
сводная XML-файл
(
количество (код_состояния)
для state_code в (любом)
)
заказать по 1
/
Вывод возвращается в виде CLOB, поэтому перед выполнением запроса убедитесь, что для параметра LONGSIZE установлено большое значение.
SQL> set long 99999
В этом запросе (выделены жирным шрифтом) есть два явных отличия от исходной операции Pivot . Во-первых, вы указали предложение, pivot xml, вместо просто pivot . Он создает вывод в XML. Во-вторых, предложение for показывает для state_code in (any) вместо длинного списка значений state_code. Нотация XML позволяет вам использовать ключевое слово ANY, и вам не нужно вводить значения state_code. Вот результат:
Частота покупок STATE_CODE_XML
------------------ -------------------------------- ------------------
1 CT<имя столбца = "COUNT(STATE_CODE)">165 NY<имя столбца = "COUNT(STATE_CODE)">33048 CT<имя столбца = "COUNT(STATE_CODE)">179 NY<имя столбца = "COUNT(STATE_CODE)">33151  .. и так далее ...
.. и так далее ...
Как видите, столбец STATE_CODE_XML имеет тип XMLTYPE, где корневым элементом является
В дополнение к предложению ANY вы можете написать подзапрос. Предположим, у вас есть список предпочтительных состояний, и вы хотите выбрать строки только для этих состояний. Вы поместили предпочтительные штаты в новую таблицу с именем selected_states:
.
SQL> создать таблицу Preferred_states
2 (
3 код_состояния varchar2(2)
4 )
5 /
Таблица создана.
SQL> вставить в значения selected_states ('FL')
2> /
Создана 1 строка.
SQL> зафиксировать;
Фиксация завершена.
Теперь стержень операция выглядит так:
выберите из ( выберите times_purchased как «Частота покупок», state_code от клиентов т ) сводная XML-файл ( количество (код_состояния) для state_code в (выберите state_code из предпочтительных_состояний) ) заказать по 1 /
Подзапрос в предложении for может быть чем угодно. Например, если вы хотите выбрать все записи без каких-либо ограничений на предпочтительные состояния, вы можете использовать следующее в качестве предложения for:
Например, если вы хотите выбрать все записи без каких-либо ограничений на предпочтительные состояния, вы можете использовать следующее в качестве предложения for:
для state_code в (выберите отдельный state_code от клиентов)
Подзапрос должен возвращать различные значения; в противном случае запрос завершится ошибкой. Вот почему мы указали предложение DISTINCT выше.
Заключение
Pivot добавляет в язык SQL очень важную и практичную функциональность. Вместо написания запутанного неинтуитивного кода с множеством функций декодирования вы можете использовать сводную функцию для создания отчета в виде кросс-таблицы для любой реляционной таблицы. Точно так же вы можете преобразовать любой отчет в виде кросс-таблицы для хранения в виде обычной реляционной таблицы, используя unpivot операция. Pivot может выводить данные в виде обычного текста или XML. В последнем случае вам не нужно указывать домен значений, в которых должна искать операция сводки.
Для получения дополнительной информации об операциях поворота и разворота см. Справочник по языку SQL Oracle Database 11g .
Назад к серии TOC
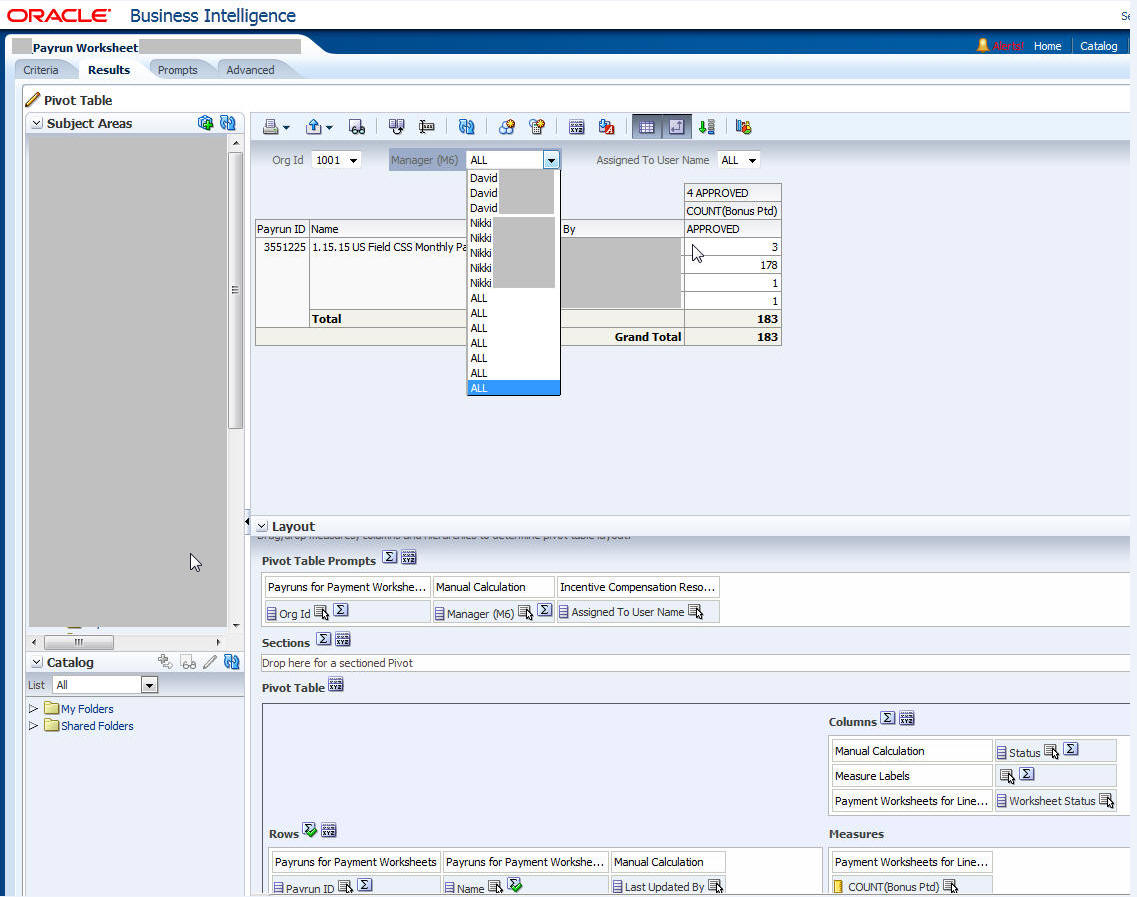
Как преобразовать строки в столбцы с помощью IDE и PL/SQL
Функциональность Oracle Pivot Table помогает преобразовать строки и столбцы данных в упрощенную таблицу, чтобы пользователь мог лучше понять отношения и зависимости данных.
На этой странице представлен краткий обзор функции сводной таблицы в dbForge Studio для Oracle.
и описывает процесс создания сводных таблиц.
Станьте гуру управления данными с помощью dbForge Studio для Oracle, теперь с Oracle Pivot Table.
Функция Oracle Pivot Table преобразует большие объемы данных в компактные
и информативные сводки — сводные таблицы. В интуитивно понятном и простом в использовании визуальном конструкторе запросов
поворот таблицы без кросс-таблицы становится быстрой и простой задачей: перетаскивание таблиц,
выбирать столбцы, создавать JOINS и настраивать отношения фильтрации, группировки или сортировки между таблицами
в редакторе с вкладками, а также суммировать, сохранять и генерировать данные в отчет.
С помощью нескольких щелчков мыши вы можете агрегировать данные и сводить строки в столбцы.
- Упрощение представления данных
- Обобщайте данные простым и гибким способом
- Настройка итогов для значений столбца или строки
- Выделите самую важную информацию в отчете
- Используйте множество метрик для эффективного и действенного построения сводных таблиц.
- Улучшить анализ данных
Что такое функция PIVOT в Oracle?
База данных Oracle предоставляет функциональные возможности PIVOT, предназначенные для помощи в обобщении и анализе объемов данных.
в вашей базе данных. Эта функция позволяет пользователям базы данных Oracle транспонировать строки в столбцы и представлять
любой тип запроса в формате кросс-таблицы с использованием оператора поворота. До Oracle 11g вы могли получить
аналогичные результаты с помощью функции DECODE или выражений CASE, но техника была весьма
громоздко и требует много времени.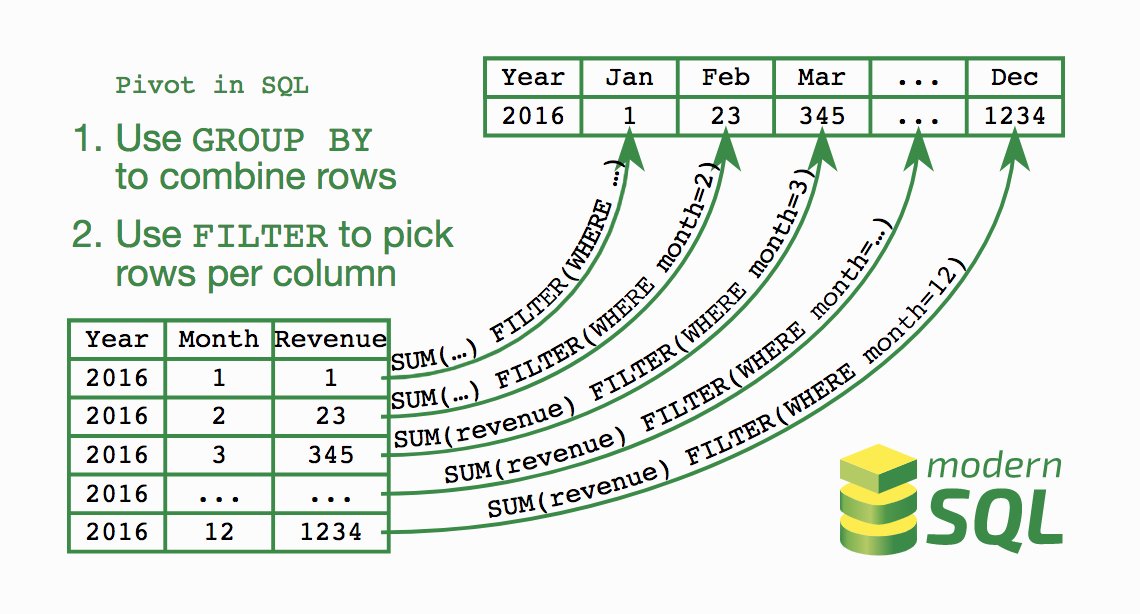 Функция сводки избавляет вас от лишних усилий при написании сложного SQL и позволяет
Функция сводки избавляет вас от лишних усилий при написании сложного SQL и позволяет
реорганизация ваших данных и просмотр их в сжатом формате. Давайте рассмотрим основные функции в Oracle
связан с оператором PIVOT.
Сводка нескольких столбцов
Используя оператор Oracle SQL Pivot, вы можете выполнить транспонирование нескольких столбцов.
Синтаксис SQL будет немного сложнее, так как вам нужно будет использовать несколько агрегатных функций.
в сводной оговорке. Обратите внимание, что вам нужно будет предоставить псевдонимы для каждой функции, потому что в противном случае
запрос может привести к ошибке.
Динамические столбцы
Учитывая изменения, которые часто происходят в столбцах, вы можете использовать динамический SQL при работе с
с помощью функции PIVOT в вашей базе данных Oracle. Динамические запросы — это запросы, полный текст которых не
доступны до выполнения. В этом случае в процессе будут генерироваться опорные значения,
и вам нужно будет применить функцию LISSTAG.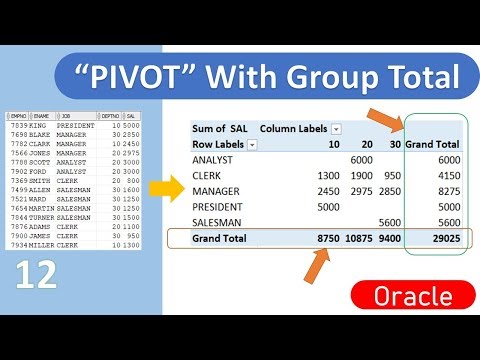 Это решение, однако, может оказаться довольно утомительным,
Это решение, однако, может оказаться довольно утомительным,
и задержите свой процесс, если вы работаете со сложным запросом.
Формат XML
Иногда вы можете не знать, какие значения доступны в столбце. В таких случаях,
вы можете добавить ключевое слово XML к оператору PIVOT и получить возможность генерировать сводные результаты
в формате XML. Нотация XML дает вам больше гибкости, так как вы сможете указать
специальное предложение, ANY или подзапрос вместо ввода точных значений.
Оператор UNPIVOT
Часто бывает необходимо представить данные на основе столбцов в виде строк, что приводит к использованию обратного
команда PIVOT. Oracle предоставляет оператор UNPIVOT, который позволяет нам разбивать столбцы на
разделите строки, добавив столбцы, которые вы собираетесь развернуть, в предложении IN. Обратите внимание, что хотя
Оператор UNPIVOT может быть противоположностью PIVOT, вы не должны использовать его для обращения результата поворота.
так как вы рискуете потерять необходимые детали.
Пример предложения Oracle PIVOT
Сводную таблицу можно создать визуально в специальной среде IDE для баз данных Oracle (например, dbForge Studio для Oracle).
Кроме того, вы можете написать соответствующий запрос, используя предложение PIVOT в SQL.
Давайте рассмотрим оба варианта.
Визуальное создание сводной таблицы с помощью IDE для Oracle
В dbForge Studio для Oracle сводные таблицы создаются из встроенного конструктора запросов.
Откройте документ запроса, чтобы выбрать его в качестве источника данных для сводной таблицы. В проводнике базы данных
выберите необходимые таблицы из вашей базы данных и перетащите их в документ запроса.
Они отображаются в виде полей со столбцами. Затем выберите столбцы, которые вам нужны для вашей будущей сводной таблицы.
Переключитесь в представление сводной таблицы, чтобы увидеть шаблон сводной таблицы. Представление источника данных открывается автоматически.
с полями, указанными в нашем документе запроса. Чтобы добавить поля в сводную таблицу, просто
Чтобы добавить поля в сводную таблицу, просто
перетащите их из представления источника данных в нужную область сводной таблицы.
Пример запроса PIVOT в SQL
Второй вариант — писать и выполнять запросы вручную в той же dbForge Studio for Oracle.
Давайте проиллюстрируем это несколькими примерами, которые будут иметь очень четкую тему: продажи автомобилей.
А для хорошего начала давайте сделаем подборку менеджеров по продажам, которые тоже покажут нам
модели автомобилей, которые они продали, а также соответствующие цены и сроки оплаты.
ВЫБЕРИТЕ P.PAYMENT_ID,
СМ. НАЗВАНИЕ,
М.FIRST_NAME || ' ' || M.LAST_NAME МЕНЕДЖЕР_ИМЯ,
P.PAYMENT_DATE,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
И M.MANAGER_ID = P.MANAGER_ID
;
Пункт PIVOT поможет нам выбрать менеджеров, которые продавали автомобили нескольких конкретных марок, например, AMC, Buick, Datsun и Chrysler.
ВЫБЕРИТЕ *
ОТ (ВЫБЕРИТЕ P.PAYMENT_ID,
СМ. НАЗВАНИЕ,
М.FIRST_NAME || ' ' || M.LAST_NAME МЕНЕДЖЕР_ИМЯ,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
AND M.MANAGER_ID = P.MANAGER_ID) PIVOT (СУММА(СУММА) ДЛЯ НАЗВАНИЯ В ('AMC', 'Buick', 'Datsun', 'Chrysler'))
;
Псевдоним столбцов PIVOT
Теперь давайте посмотрим, как добавить псевдонимы для столбцов PIVOT. Например, вот случай, когда мы хотим вывести общий объем продаж автомобилей по отделам; и в этом случае к каждому псевдониму отдела мы добавляем псевдоним SUM.
ВЫБЕРИТЕ *
ОТ (ВЫБЕРИТЕ CM.TITLE CAR_MODEL,
P.DEPARTMENT_ID ОТДЕЛ,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
И M. MANAGER_ID = P.MANAGER_ID) PIVOT (СУММА(СУММА) СУММА
ДЛЯ ОТДЕЛА (1 КАК ОТДЕЛ_1, 2 КАК ОТДЕЛ_2, 3 КАК ОТДЕЛ_3))
;
 MANAGER_ID = P.MANAGER_ID) PIVOT (СУММА(СУММА) СУММА
ДЛЯ ОТДЕЛА (1 КАК ОТДЕЛ_1, 2 КАК ОТДЕЛ_2, 3 КАК ОТДЕЛ_3))
;
MANAGER_ID = P.MANAGER_ID) PIVOT (СУММА(СУММА) СУММА
ДЛЯ ОТДЕЛА (1 КАК ОТДЕЛ_1, 2 КАК ОТДЕЛ_2, 3 КАК ОТДЕЛ_3))
;
Сведение нескольких строк в столбцы в Oracle
Что, если мы хотим посчитать сумму платежей и индивидуальное количество продаж по каждому отделу? Для этой цели мы можем применить еще одну полезную функцию — сведение нескольких строк к столбцам.
ВЫБЕРИТЕ *
ОТ (ВЫБЕРИТЕ CM.TITLE CAR_MODEL,
P.DEPARTMENT_ID ОТДЕЛ,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
И M.MANAGER_ID = P.MANAGER_ID) ОСНОВНОЙ (СУММА(СУММА) СУММА, СЧЕТЧИК(ОТДЕЛ) COUNT_DEPT ДЛЯ ОТДЕЛА (1 КАК ОТДЕЛ_1, 2 КАК ОТДЕЛ_2, 3 КАК ОТДЕЛ_3))
;
Использование PIVOT с подзапросами
Мы можем добавить подзапрос к нашему запросу PIVOT. Например, давайте выберем уникальные отделы с помощью подзапроса
а затем ограничить выбор этими отделами в основном запросе, содержащем функцию PIVOT.
ВЫБЕРИТЕ *
ОТ (ВЫБЕРИТЕ CM.TITLE CAR_MODEL,
P.DEPARTMENT_ID ОТДЕЛ,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
И M.MANAGER_ID = P.MANAGER_ID) ОСНОВНАЯ (СУММА(СУММА) СУММА ДЛЯ ОТДЕЛА (ВЫБЕРИТЕ ОТДЕЛ_ID
ОТ АВТО_ПРОДАЖИ.ОТДЕЛА))
;
Пример функции UNPIVOT в Oracle
Чтобы показать вам пример UNPIVOT, давайте сначала создадим сводное представление, показывающее общий объем продаж по отделам.
СОЗДАТЬ ПРОСМОТР CARS_SALE.PIVOTED_SALES_DEPT КАК
ВЫБИРАТЬ *
ОТ (ВЫБЕРИТЕ CM.TITLE CAR_MODEL,
P.DEPARTMENT_ID ОТДЕЛ,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
И M.MANAGER_ID = P.MANAGER_ID) PIVOT (СУММА(СУММА) СУММА ДЛЯ
ОТДЕЛ (1 КАК ОТДЕЛ_1, 2 КАК ОТДЕЛ_2, 3 КАК ОТДЕЛ_3))
Теперь давайте получим сводные данные из этого представления.
ВЫБЕРИТЕ * ИЗ АВТОМОБИЛЕЙ_ПРОДАЖИ.PIVOTED_SALES_DEPT
Наконец, мы можем развернуть наше представление.
ВЫБЕРИТЕ * ИЗ CARS_SALE.PIVOTED_SALES_DEPT UNPIVOT (total_sales FOR DEPT IN (DEPT_1_SUM,DEPT_2_SUM,DEPT_3_SUM))
Как использовать Oracle PIVOT без агрегата
Хотя Oracle PIVOT работает только с агрегатными функциями, мы можем попробовать использовать MAX или MIN для той же цели.
Например, так мы можем выбрать менеджера и максимальную сумму, заплаченную за конкретную модель автомобиля.
ВЫБОР *
ОТ (ВЫБЕРИТЕ НАЗВАНИЕ CM,
М.FIRST_NAME || ' ' || M.LAST_NAME МЕНЕДЖЕР_ИМЯ,
P.СУММА
FROM CARS_SALE.CAR_MODEL CM,
ПРОДАЖА АВТОМОБИЛЕЙ.МЕНЕДЖЕРЫ М,
АВТОМОБИЛЬ_ПРОДАЖА.ОПЛАТА P
ГДЕ CM.CAR_ID = P.CAR_ID
AND M.MANAGER_ID = P.MANAGER_ID) PIVOT (MAX(СУММА) ДЛЯ НАЗВАНИЯ В ('AMC', 'Buick', 'Datsun', 'Chrysler'))
Вот и все! Теперь, когда мы показали вам реальные примеры кода, давайте вернемся в визуальный режим в dbForge Studio и узнаем больше о переупорядочении, сортировке, группировке и фильтрации полей.
Изменение порядка полей
Переупорядочивание полей — это ключевой момент в поиске наилучшего макета таблицы, позволяющего четко понимать зависимости данных и извлекать из них выгоду.
Просто перетащите поле из одной области сводной таблицы в другую, чтобы спроектировать его макет и изменить порядок данных так, как вам нужно. Вы можете легко поменять местами поля строк и столбцов, чтобы отображать значения полей строк в столбцах и значения полей столбцов в строках.
Сортировка и группировка полей
Сортировка данных в сводной таблице позволяет отображать их в порядке возрастания или убывания.
Вы можете группировать данные в сводной таблице Oracle, используя различные предопределенные групповые режимы. Группировка значений некоторых полей осуществляется одним щелчком мыши. Оно появится как новое подполе, и вы сможете добавить его в нужную область сводной таблицы.
Значения типа даты и времени могут быть сгруппированы по годам, месяцам, кварталам, неделям, дням и т. д. Числовые данные могут быть сгруппированы в числовые диапазоны. Текстовые данные можно группировать по первой букве.
д. Числовые данные могут быть сгруппированы в числовые диапазоны. Текстовые данные можно группировать по первой букве.
Помимо предопределенных групповых режимов, вы можете создавать свои собственные групповые критерии с помощью диалогового окна Редактор коллекций.
Поля фильтрации
Для отображения необходимых данных в сводной таблице могут применяться различные типы фильтрации.
Чтобы отфильтровать значения любого поля, щелкните Фильтр в заголовке поля и в открывшемся диалоговом окне выберите только необходимые значения, которые вы хотите отобразить. Данные будут отфильтрованы в соответствии с выбранными критериями.
Вы можете добавить поле фильтра для фильтрации всех данных в сводной таблице. Перетащите необходимое поле из представления «Источник данных» в область «Фильтр» сводной таблицы.
Использование функций суммирования для расчета пользовательских итогов
Сводная таблица предлагает несколько сводных функций, которые можно применять для расчета пользовательских итогов для значений столбца или строки.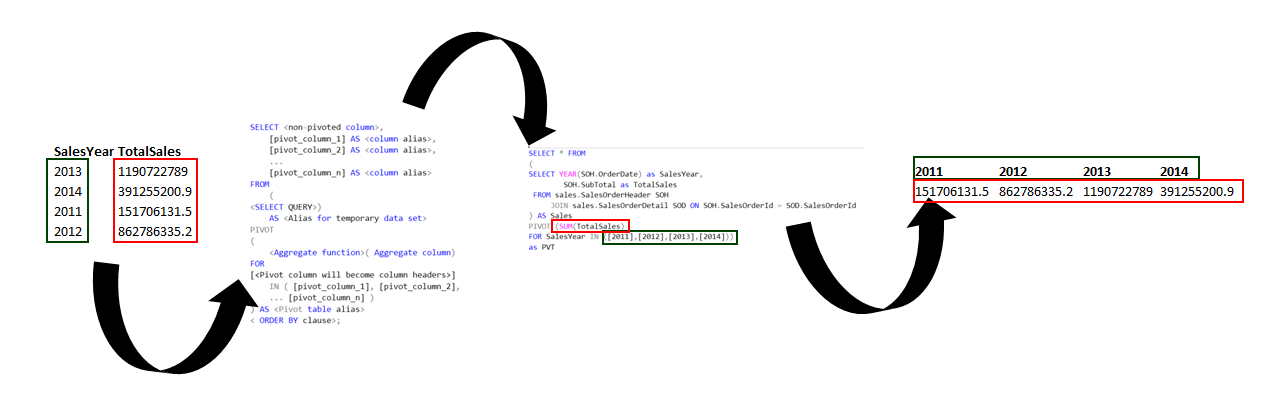 Пользовательские итоги отображаются в дополнительных строках или столбцах, выделенных серым цветом.
Пользовательские итоги отображаются в дополнительных строках или столбцах, выделенных серым цветом.
Сводная функция Oracle подсчитывает числовые значения в отчете, используя функцию СУММ по умолчанию. Однако вы можете выбрать другую итоговую функцию:
- Сумма всех значений
- Среднее значение
- Количество значений
- Максимальное значение
- Минимальное значение
Видеоруководство: создание таблиц PIVOT и UNPIVOT
В этом видеоролике показано создание сводной таблицы с использованием операторов Oracle PIVOT и UNPIVOT, а также сравнение их возможностей с более эффективным и практичным инструментом сводной таблицы, предоставляемым dbForge Studio для Oracle.
Заключение
Сводные таблицы незаменимы для простого и гибкого управления и обработки больших наборов данных.