Подзапросы sql: Подзапросы в основных командах SQL
Содержание
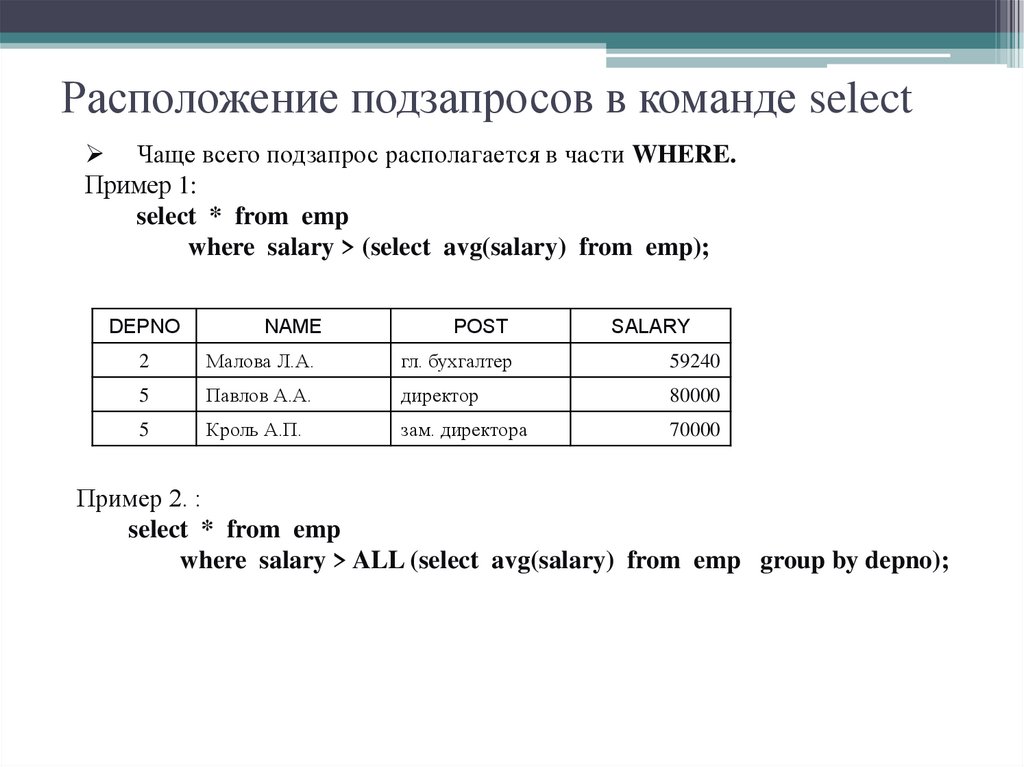
Подзапросы SQL
Подзапрос представляет собой оператор SELECT, вложенный в тело другого оператора.
Кодирование подзапроса подчиняется тем же правилам, что и кодирование простого оператора SELECT. Внешний оператор использует результат выполнения внутреннего оператора для определения окончательного результата.
По количеству возвращаемых значений подзапросы разделяются на два типа:
- скалярные подзапросы, которые возвращают единственное значение;
- табличные подзапросы, которые возвращают множество значений.
По способу выполнения выделяют два типа подзапросов:
- простые подзапросы;
- сложные подзапросы.
Подзапрос называется простым, если он может рассматриваться независимо от внешнего запроса. СУБД выполняет такой подзапрос один раз и затем помещает его результат во внешний запрос.
Сложный подзапрос не может рассматриваться независимо от внешнего запроса. В этом случае выполнение оператора начинается с внешнего запроса, который отбирает каждую отдельную строку таблицы. Для каждой выбранной строки СУБД выполняет подзапрос один раз.
Для каждой выбранной строки СУБД выполняет подзапрос один раз.
Спонсор поста
Простые скалярные подзапросы
Приведем примеры простых скалярных подзапросов.
База данных, используемая в примерах, находится в этом посте.
Пример 1.
Определить наименования деталей, цена которых больше цены детали ‘болт’.
SELECT dname
FROM D
WHERE dprice > (SELECT dprice
FROM D
WHERE dname = ’болт’)Данный подзапрос относится к скалярным, так как возвращает единственное значение — цену детали ‘болт’.
Подзапрос является простым, потому что он может рассматриваться независимо от внешнего запроса. СУБД сначала выполняет подзапрос, в результате чего получает цену детали ‘болт’ — значение 10, а затем помещает это значение во внешний запрос и выполняет его.
Пример 2.
Определить номера деталей, цена которых меньше средней цены деталей.
SELECT dname
FROM D
WHERE dprice < (SELECT AVG(dprice)
FROM D)Пример 3.
Определить номер поставщика, выполнившего поставку с минимальным объемом.
SELECT pnum
FROM PD
WHERE volume = (SELECT min(volume)
FROM PD)Пример 4.
Определить номера деталей, которых поставляется больше, чем деталей с номером 2.
SELECT pnum
FROM PD
GROUP BY dnum
HAVING sum(volume) > (SELECT sum(volume)
FROM PD
WHERE dnum = 2)Подзапросы можно использовать не только в предложении WHERE, но и в других предложениях оператора SELECT, например, в самом предложении SELECT.
Пример 5.
Вывести следующую информацию о деталях: наименование, цена, отклонение от средней цены.
SELECT dname, dprice, dprice - (SELECT AVG(dprice) FROM PD) AS dif FROM PD
В результате получим таблицу:
| dname | dprice | dif |
|---|---|---|
| болт | 10 | -10 |
| гайка | 20 | 0 |
| винт | 30 | 10 |
Простые табличные подзапросы
Если подзапрос возвращает множество значений, то его результат следует обрабатывать специальным образом. Для этого предназначены операции
Для этого предназначены операции IN, ANY, SOME и ALL.
Такие операции могут использоваться с подзапросами, возвращающими таблицу, состоящую из одного столбца значений.
Операция
IN
Операция IN осуществляет проверку на принадлежность значения множеству, которое получается после выполнения подзапроса.
Пример 6.
Определить наименования поставщиков, которые поставляют детали.
SELECT pname
FROM P
WHERE pnum in (SELECT pnum
FROM PD)Такой подзапрос относится к табличным, так как возвращает множество значений. Подзапрос является простым, потому что он может рассматриваться независимо от внешнего запроса.
СУБД сначала выполняет подзапрос, в результате чего получает множество номеров поставщиков, которые поставляют детали. Затем СУБД проверяет номер каждого поставщика из таблицы P на принадлежность полученному множеству.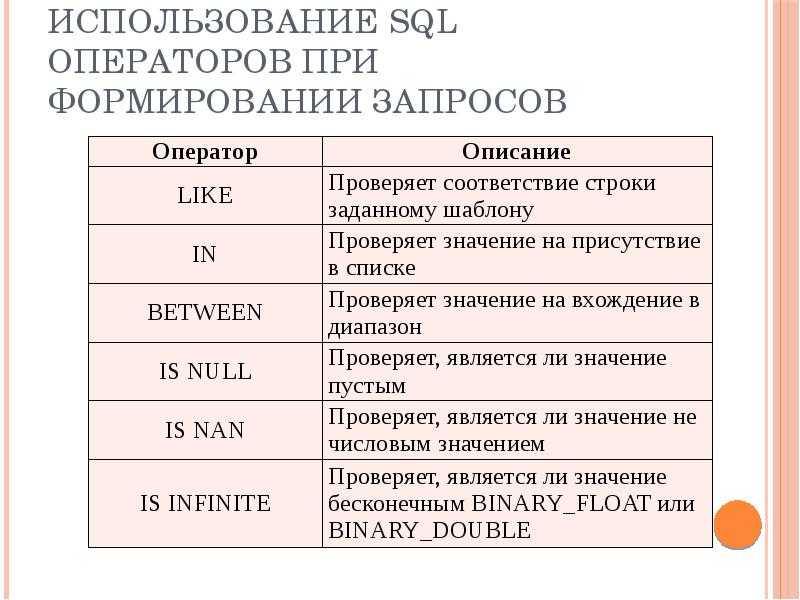 При вхождении в множество наименование поставщика помещается в результирующую таблицу.
При вхождении в множество наименование поставщика помещается в результирующую таблицу.
Пример 7.
Определить наименования поставщиков, которые не поставляют деталь с номером 2.
SELECT pname
FROM P
WHERE pnum not in (SELECT pnum
FROM PD
WHERE dnum = 2)Пример 8.
Определить наименования поставщиков, которые поставляют только деталь с номером 1.
SELECT pname
FROM PD
WHERE pnum in (SELECT pnum
FROM PD
WHERE dnum = 1) AND pnum not in (SELECT pnum
FROM PD
WHERE dnum <> 1)Операции
ANY, SOME, ALL
Если подзапросу предшествует ключевое слово ANY, то условие сравнения считается выполненным, когда оно выполняется хотя бы для одного из значений, которые получаются после выполнения подзапроса.
Если подзапросу предшествует ключевое слово ALL, то условие сравнения считается выполненным, только если оно выполняется для всех значений, которые получаются после выполнения подзапроса.
Если в результате выполнения подзапроса получено пустое множество, то для операции ALL условие сравнения будет считаться выполненным, а для ключевого слова ANY — невыполненным.
Ключевое слово SOME является синонимом ANY и используется для повышения наглядности текстов запросов.
Пример 9.
Определить наименования поставщиков, которые поставляют детали.
SELECT pname
FROM P
WHERE pnum = ANY(SELECT pnum
FROM PD)Такой подзапрос относится к табличным, так как возвращает множество значений. Подзапрос является простым, потому что он может рассматриваться независимо от внешнего запроса.
СУБД сначала выполняет подзапрос, в результате чего получает множество номеров поставщиков, которые поставляют детали. Затем СУБД проверяет номер каждого поставщика из таблицы P на равенство хотя бы одному из номеров из полученного множества. При выполнении условия наименование поставщика помещается в результирующую таблицу.
При выполнении условия наименование поставщика помещается в результирующую таблицу.
Пример 10.
Определить наименование детали с максимальной ценой.
SELECT dname
FROM D
WHERE dprice >= ALL(SELECT dprice
FROM PD)Последний пример можно решить следующим способом:
SELECT dname
FROM D
WHERE dprice = (SELECT max(dprice)
FROM PD)Сложные табличные подзапросы
Операция EXISTS
Результат выполнения таких операций представляет собой значения TRUE или FALSE.
Для операции EXISTS результат равен TRUE, если в возвращаемой подзапросом таблице присутствует хотя бы одна строка.
Если в результирующей таблице подзапроса пуста, то операция EXISTS возвращает значение FALSE. Для операции NOT EXISTS используются обратные правила обработки.
Поскольку обе операции проверяют лишь наличие строк в результирующей таблице подзапроса, то эта таблица может содержать произвольное количество столбцов.
Пример 11.
Определить наименования поставщиков, которые поставляют детали.
SELECT pname
FROM P
WHERE EXISTS(SELECT *
FROM PD
WHERE PD.pnum = P.pnum)Такой подзапрос относится к табличным, так как возвращает множество значений. Подзапрос является сложным, потому что он не может выполняться независимо от внешнего запроса.
В этом случае выполнение оператора начинается с внешнего запроса, который поочередно отбирает каждую отдельную строку таблицы P. Для каждой выбранной строки СУБД выполняет подзапрос один раз. В результирующую таблицу помещаются только те наименования поставщиков, для которых подзапрос возвращает хотя бы одну строку.
Первой выбирается строка с информацией о поставщике Иванов. В подзапрос вместо P.pnum подставляется значение 1 (номер поставщика Иванова), после чего подзапрос выполняется.
Подзапрос возвращает три первых строки из таблицы PD, соответствующие поставкам Иванова, поэтому результат операции EXISTS равен TRUE, и наименование Иванов помещается в результирующую таблицу.
Аналогично результат получается для поставщиков Петров и Сидоров. При выборе строки с информацией о поставщике Кузнецов, подзапрос возвращает пустое множество, поэтому результат операции EXISTS равен FALSE, и наименование Кузнецов не помещается в результирующую таблицу.
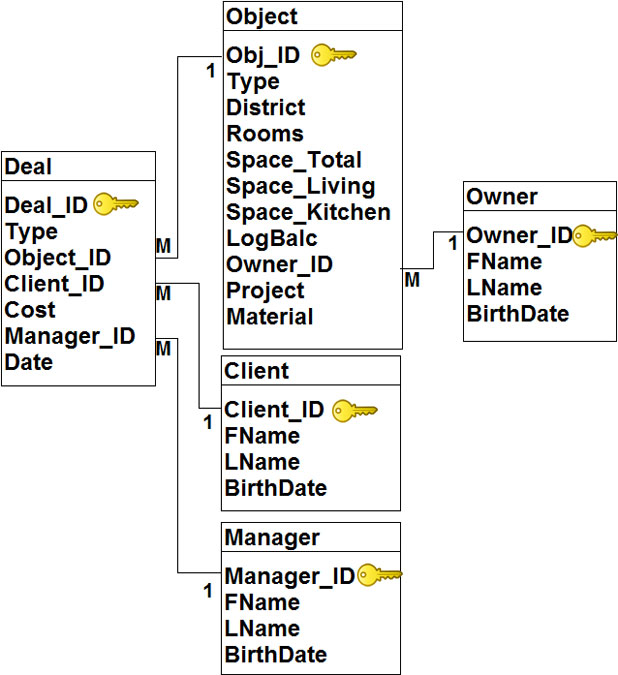
Создание самосоединений
Самосоединение это обычное соединение языка SQL, которое соединяет таблицу саму с собой. Такое соединение позволяет сравнивать значения, хранящиеся в одном столбце таблицы.
При самосоединении используются псевдонимы таблиц, которые позволяют различать соединяемые копии таблиц. Псевдонимы вводятся в предложении FROM и используются как обычные имена таблиц.
Пример 12.
Определить наименования поставщиков, которые поставляют и деталь с номером 1, и деталь с номером 2.
Один из вариантов решения задачи можно записать с помощью подзапроса следующим образом.
SELECT pnum
FROM PD
WHERE dnum = 1 AND pnum in (SELECT pnum
FROM PD
WHERE dnum = 2)Тот же самый результат можно получить используя соединение таблицы PD с ее копией, назовем ее PD1, следующим образом:
SELECT PD.pnum FROM PD INNER JOIN PD AS PD1 ON PD.pnum = PD1.pnum WHERE PD.dnum = 1 AND PD1.dnum = 2
 pnum
FROM PD INNER JOIN PD AS PD1 ON PD.pnum = PD1.pnum
WHERE PD.dnum = 1 AND PD1.dnum = 2
pnum
FROM PD INNER JOIN PD AS PD1 ON PD.pnum = PD1.pnum
WHERE PD.dnum = 1 AND PD1.dnum = 2Пример 13.
Определить наименования поставщиков, которые поставляют и деталь с номером 1, и деталь с номером 2, и деталь с номером 3.
SELECT PD.pnum FROM (PD INNER JOIN PD AS PD1 ON PD.pnum=PD1.pnum) INNER JOIN PD AS PD2 ON PD1.pnum=PD2.pnum WHERE PD.dnum=1 AND PD1.dnum=2 AND PD2.dnum=3
Резюмирую
Из этой статьи вы узнали что такое подзапрос в SQL. Теперь вы легко отличите скалярный запрос от табличного, и простой запрос от сложного.
Также мы рассмотрели на примерах такие операции, как IN, ANY, SOME и ALL.
Подзапросы в выражении CASE / Хабр
По материалам статьи Craig Freedman: Subqueries in CASE Expressions
В этой статье будет рассмотрено, как SQL Server обрабатывает подзапросы в выражении CASE. Кроме того, будут рассмотрены несколько экзотических возможностей соединений.
Скалярные выражения
Для простых случаев использования выражений CASE (без подзапросов), возможна оценка только выражения CASE, состоящего из нескольких скалярных выражений:
create table T1 (a int, b int, c int) select case when T1.a > 0 then T1.b else T1.c end from T1
|—Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [T1].[a]>(0) THEN [T1].[b] ELSE [T1].[c] END)) |—Table Scan(OBJECT:([T1])) |
Этот план запроса подразумевает просмотр таблицы T1 и оценку выражения CASE для каждой её строки. Оператор Compute Scalar вычисляет значение выражения CASE, включая оценку условия и принятие решения, будет ли выполняться оценка в предложении THEN или ELSE.
Если в выражение CASE поместить подзапросы, всё становится немного сложнее и существенно интересней.
Предложение WHEN
Давайте сначала добавим к предложению WHEN простой подзапрос:
create table T2 (a int, b int) select case when exists (select * from T2 where T2.a = T1.a) then T1.b else T1.c end from T1
|—Compute Scalar(DEFINE:([Expr1009]=CASE WHEN [Expr1010] THEN [T1].[b] ELSE [T1].[c] END)) |—Nested Loops(Left Semi Join, OUTER REFERENCES:([T1].[a]), DEFINE:([Expr1010] = [PROBE VALUE])) |—Table Scan(OBJECT:([T1])) |—Table Scan(OBJECT:([T2]), WHERE:([T2].[a]=[T1].[a])) |
Как и для других EXISTS подзапросов, этот план использует левое полусоединение, позволяющее проверить, имеется ли для каждой строки в T1 соответствующая строка в T2. Однако, нормальное полусоединение (или анти-полусоединение) возвращает только парные строки (или непарные). В этом случае, должно быть возвращено хоть что-то (T1.b или T1.c) для каждой строки в T1. Мы не можем просто отказаться от строки T1 только потому, что для неё нет соответствующей строки в T2.
В этом случае, должно быть возвращено хоть что-то (T1.b или T1.c) для каждой строки в T1. Мы не можем просто отказаться от строки T1 только потому, что для неё нет соответствующей строки в T2.
Решением стал специальный тип полусоединения со столбцом пробной таблицы. Это полусоединение возвращает все внешние соответствующие или не соответствующие строки, и устанавливает столбец пробной таблицы (в нашем случае это [Expr1010]) в истину или ложь, что указывает, была ли найдена соответствующая строка T1. После этого, выполняется оценка выражения CASE, для чего используется столбец пробной таблицы, с помощью которого определяется, какое значение будет возвращено.
Предложение THEN
Давайте теперь попробуем добавить к предложению THEN простой подзапрос:
create table T3 (a int unique clustered, b int) insert T1 values(0, 0, 0) insert T1 values(1, 1, 1) select case when T1.a > 0 then (select T3.b from T3 where T3.a = T1.b) else T1.
 c
end
from T1
c
end
from T1Я добавил к T3 ограничение уникальности, позволяющее гарантировать, что скалярный подзапрос возвратит только одну строку. Без ограничения, план запроса был бы более сложен, поскольку оптимизатору нужно было бы гарантировать, что подзапрос действительно возвратит только одну строку, и ему пришлось бы выдавать ошибку, если бы вернулось больше одной строки.
Я также добавил в T1 ещё две строки, причём, условие в предложение WHEN выдаст ложь для первой строки и истину для второй строки. Таким образом, первая строка у нас будет подходить для ELSE, а вторая для THEN. Обратите внимание, что значение подзапроса в THEN будет использоваться, только если предложение WHEN будет истинно.
Ниже показан профиль статистики для плана исполнения этого запроса:
Rows Executes 0 0 |—Compute Scalar(DEFINE:([Expr1008]=CASE WHEN [T1].[a]>(0) THEN [T3]. ELSE [T1].[c] END)) 2 1 |—Nested Loops(Left Outer Join, PASSTHRU: (IsFalseOrNull [T1].[a]>(0)), OUTER REFERENCES:([T1].[b])) 2 1 |—Table Scan(OBJECT:([T1])) 0 1 |—Clustered Index Seek(OBJECT:([T3].[UQ__T3__412EB0B6]), SEEK:([T3].[a]=[T1].[b]) ORDERED FORWARD) |
 [b]
[b] Этот план запроса использует специальный тип соединения вложенных циклов, в котором задействуется предикат PASSTHRU. Соединение оценивает предикат PASSTHRU для каждой внешней строки. Если предикат PASSTHRU оценивается как истина, соединение немедленно возвращает строку, подобную полусоединению или внешнему соединению. Если же предикат PASSTHRU оценивается как ложь, соединение выполняется обычным образом, т.е. выполняется попытка соединения внешней строки с внутренней строкой.
Если же предикат PASSTHRU оценивается как ложь, соединение выполняется обычным образом, т.е. выполняется попытка соединения внешней строки с внутренней строкой.
В показанном выше примере, предикат PASSTHRU выражения CASE является инверсией (обратите внимание на функцию IsFalseOrNull) предложения WHEN. Если предложение WHEN оценивается как истина, предикат PASSTHRU оценивается как ложь, происходит соединение, и поиск по внутренней части соединения выполняет оценку подзапроса THEN. Если предложение WHEN оценивается как ложь, предикаты PASSTHRU оценивается как истина, соединение пропускается, а поиск или подзапрос THEN не выполняется.
Обратите внимание, что просмотр T1 возвращает 2 строки, хотя поиск в T3 выполняется только один раз. Так происходит потому, что в нашем примере предложение WHEN истинно только для одной из двух строк. Предиката PASSTHRU является единственным механизмом, когда число строк на внешней стороне соединения вложенных циклов не соответствует в точности числу строк на внутренней стороне.
Также обратите внимание, что после того, как будет использовано внешнее соединение, невозможно гарантировать, что подзапрос в THEN вернёт хоть что-нибудь (в действительности гарантируется только то, что благодаря ограничению уникальности будет возвращено не более одной строки). Если подзапрос не возвращает строк, внешнее соединение просто возвратит NULL для T3.b. Если бы использовалось внутреннее соединение, отказаться от строки T1 было бы неправильно. Предостережение: я прогонял эти примеры на SQL Server 2005. Если Вы будете выполнять этот пример на SQL Server 2000, предикат PASSTHRU будет виден, но в плане исполнения запроса он появится как регулярный предикат предложения WHERE. К сожалению, для SQL Server 2000 не существует простого пути различения регулярных предикатов и предиката PASSTHRU.
Предложение ELSE и несколько предложений WHEN
Подзапрос в предложении ELSE работает точно так же, как и подзапрос в предложении THEN. Для оценки условия подзапроса будет использован предикат PASSTHRU.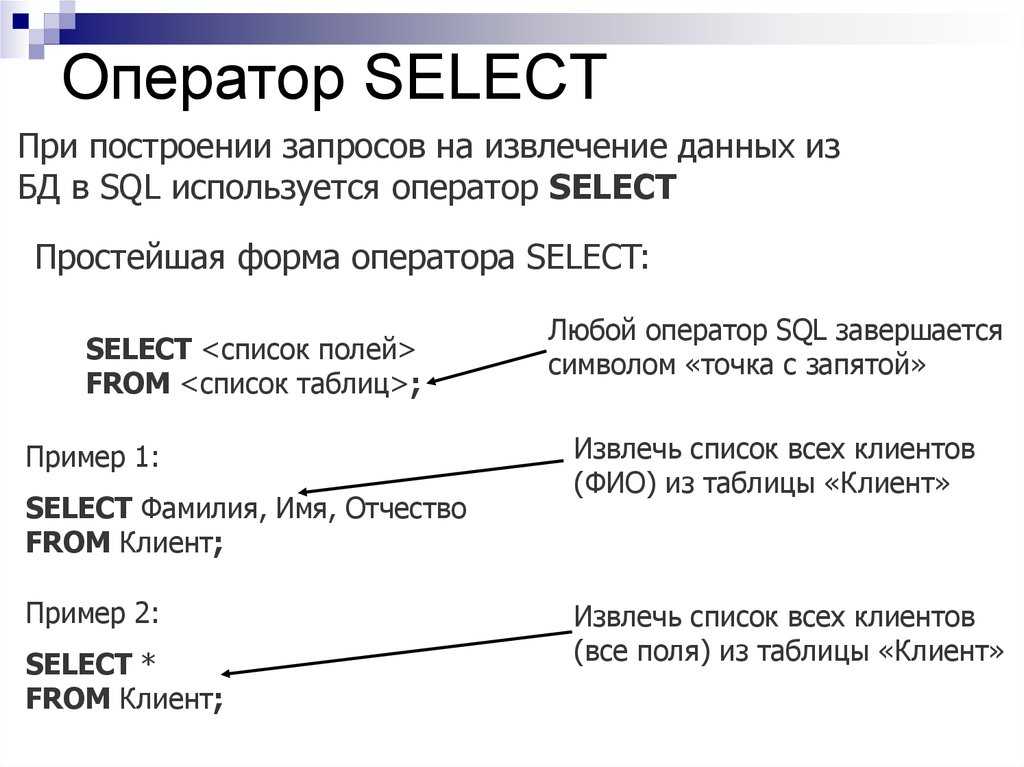
Точно так же выражение CASE с несколькими предложениями WHEN с подзапросами в каждом предложении THEN будет работать аналогичным образом. Отличие только в том, что предикатов PASSTHRU будет больше.
Например:
create table T4 (a int unique clustered, b int) create table T5 (a int unique clustered, b int) select case when T1.a > 0 then (select T3.b from T3 where T3.a = T1.a) when T1.b > 0 then (select T4.b from T4 where T4.a = T1.b) else (select T5.b from T5 where T5.a = T1.c) end from T1
|—Compute Scalar(DEFINE:([Expr1016]=CASE WHEN [T1].[a]>(0) THEN [T3].[b] ELSE CASE WHEN [T1].[b]>(0) THEN [T4].[b] ELSE [T5]. END END)) |—Nested Loops(Left Outer Join, PASSTHRU:([T1].[a]>(0) OR [T1].[b]>(0)), OUTER REFERENCES:([T1].[c])) |—Nested Loops(Left Outer Join, PASSTHRU:([T1].[a]>(0) OR IsFalseOrNull [T1].[b]>(0)), OUTER REFERENCES:([T1].[b])) | |—Nested Loops(Left Outer Join, PASSTHRU: (IsFalseOrNull [T1].[a]>(0)), OUTER REFERENCES:([T1].[a])) | | |—Table Scan(OBJECT:([T1])) | | |—Clustered Index Seek(OBJECT:([T3]. SEEK:([T3].[a]=[T1].[a]) ORDERED FORWARD) | |—Clustered Index Seek(OBJECT:([T4].[UQ__T4__182C9B23]), SEEK:([T4].[a]=[T1].[b]) ORDERED FORWARD) |—Clustered Index Seek(OBJECT:([T5].[UQ__T5__1A14E395]), SEEK:([T5].[a]=[T1].[c]) ORDERED FORWARD) |
 [b]
[b]  [UQ__T3__164452B1]),
[UQ__T3__164452B1]), В этом плане запроса три соединения вложенных циклов с предикатами PASSTHRU. Для каждой строки T1, только один из трех предикатов PASSTHRU оценивается как истина, и только один из трех подзапросов будет выполнен. Обратите внимание, что пока второе предложение WHEN соответствует «T1. b > 0″, это значит, что первое предложение WHEN, где «T1.a > 0» оказалось ложным. Это также относится и к предложению ELSE. Таким образом, предикаты PASSTHRU для второго и третьего подзапроса включают проверку «T1.a > 0 OR…».
b > 0″, это значит, что первое предложение WHEN, где «T1.a > 0» оказалось ложным. Это также относится и к предложению ELSE. Таким образом, предикаты PASSTHRU для второго и третьего подзапроса включают проверку «T1.a > 0 OR…».
Столбец пробной таблицы в качестве предиката PASSTHRU
Наконец, давайте рассмотрим запрос с подзапросами в предложениях WHEN и в предложениях THEN. Также, для разнообразия, давайте переместим выражение CASE из списка SELECT в предложение WHERE.
select * from T1 where 0 = case when exists (select * from T2 where T2.a = T1.a) then (select T3.b from T3 where T3.a = T1.b) else T1.c end
|—Filter(WHERE:((0)=CASE WHEN [Expr1013] THEN [T3].[b] ELSE [T1].[c] END)) |—Nested Loops(Left Outer Join, PASSTHRU:(IsFalseOrNull [Expr1013]), OUTER REFERENCES:([T1]. |—Nested Loops(Left Semi Join, OUTER REFERENCES:([T1].[a]), DEFINE:([Expr1013] = [PROBE VALUE])) | |—Table Scan(OBJECT:([T1])) | |—Table Scan(OBJECT:([T2]), WHERE:([T2].[a]=[T1].[a])) |—Clustered Index Seek(OBJECT:([T3].[UQ__T3__164452B1]), SEEK:([T3].[a]=[T1].[b]) ORDERED FORWARD) |
 [b]))
[b]))В этом плане исполнения запроса имеется левое полусоединение со столбцом пробной таблицы, позволяющее оценить подзапрос в предложении WHEN, и соединение вложенных циклов с предикатом PASSTHRU для столбца пробной таблицы, позволяющее решить, выполнять ли оценку подзапроса в предложении THEN. Поскольку выражение CASE было перемещено в предложение WHERE, для оценки выходных значений из списка SELECT вместо оператора Compute Scalar используется оператор Filter, с помощью которого определяется, какие строки будут возвращены. Все остальное работает точно так же.
Все остальное работает точно так же.
Далее…
В следующей статье, я рассмотрю несколько других типов подзапросов.
Написание подзапросов в SQL | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Основы подзапросов
- Использование подзапросов для агрегирования в несколько этапов
- Подзапросы в условной логике
- Объединение подзапросов
- Подзапросы и UNION
На этом уроке вы продолжите работать с теми же данными о преступности в Сан-Франциско, что и на предыдущем уроке.
Основы подзапросов
Подзапросы (также называемые внутренними запросами или вложенными запросами) — это инструмент для выполнения операций в несколько шагов. Например, если вы хотите взять суммы нескольких столбцов, а затем усреднить все эти значения, вам нужно будет выполнить каждую агрегацию на отдельном шаге.
Подзапросы могут использоваться в нескольких местах внутри запроса, но проще всего начать с оператора FROM . Вот пример простого подзапроса:
SELECT sub.*
ИЗ (
ВЫБРАТЬ *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ day_of_week = 'Пятница'
) суб
ГДЕ подразрешение = 'НЕТ'
Давайте разберем, что происходит, когда вы выполняете приведенный выше запрос:
Сначала база данных выполняет «внутренний запрос» — часть в скобках:
SELECT * ИЗ tutorial.sf_crime_incidents_2014_01 ГДЕ day_of_week = 'Пятница'
Если бы вы запустили этот запрос самостоятельно, он выдал бы набор результатов, как и любой другой запрос. Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
SELECT sub.
 *
ИЗ (
<<результаты внутреннего запроса идут сюда>>
) суб
ГДЕ подразрешение = 'НЕТ'
*
ИЗ (
<<результаты внутреннего запроса идут сюда>>
) суб
ГДЕ подразрешение = 'НЕТ'
Подзапросы должны иметь имена, которые добавляются после круглых скобок так же, как вы добавляете псевдоним к обычной таблице. В данном случае мы использовали имя «sub».
Небольшое замечание по форматированию. Важно помнить, что при использовании подзапросов необходимо предоставить читателю возможность легко определить, какие части запроса будут выполняться вместе. Большинство людей делают это, тем или иным образом делая отступ в подзапросе. Примеры в этом руководстве имеют довольно большой отступ — вплоть до круглых скобок. Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Практическая задача
Напишите запрос, который выбирает все ордера на арест из набора данных tutorial.sf_crime_incidents_2014_01 , а затем оберните его во внешний запрос, который отображает только неразрешенные инциденты.
Попробуйте См. ответ
Вышеприведенные примеры, а также практическая задача на самом деле не требуют подзапросов — они решают проблемы, которые также можно решить, добавив несколько условий в предложение WHERE . В следующих разделах приводятся примеры, для которых подзапросы являются лучшим или единственным способом решения соответствующих проблем.
Использование подзапросов для агрегирования в несколько этапов
Что делать, если вы хотите выяснить, сколько инцидентов сообщается в каждый день недели? А что, если вы хотите узнать, сколько инцидентов происходит в среднем в пятницу декабря? В январе? Этот процесс состоит из двух шагов: подсчет количества инцидентов каждый день (внутренний запрос), затем определение среднемесячного значения (внешний запрос):
суб.день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ИЗ (
ВЫБЕРИТЕ день_недели,
свидание,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial. sf_crime_incidents_2014_01
sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
Если вы не можете понять, что происходит, попробуйте запустить внутренний запрос отдельно, чтобы понять, как выглядят его результаты. В общем, проще всего сначала написать внутренние запросы и пересматривать их до тех пор, пока результаты не станут для вас понятными, а затем перейти к внешнему запросу.
Практическая задача
Напишите запрос, отображающий среднее количество инцидентов в месяц для каждой категории. Подсказка: используйте tutorial.sf_crime_incidents_cleandate , чтобы немного облегчить себе жизнь.
Попробуйте См. ответ
Подзапросы в условной логике
Вы можете использовать подзапросы в условной логике (в сочетании с WHERE , JOIN / ON или CASE ). Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
SELECT * ИЗ tutorial.
 sf_crime_incidents_2014_01
ГДЕ Дата = (ВЫБРАТЬ МИН (дата)
ИЗ tutorial.sf_crime_incidents_2014_01
)
sf_crime_incidents_2014_01
ГДЕ Дата = (ВЫБРАТЬ МИН (дата)
ИЗ tutorial.sf_crime_incidents_2014_01
)
Приведенный выше запрос работает, поскольку результатом подзапроса является только одна ячейка. Большая часть условной логики будет работать с подзапросами, содержащими результаты с одной ячейкой. Однако IN — это единственный тип условной логики, который будет работать, когда внутренний запрос содержит несколько результатов:
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата В (ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
)
Обратите внимание, что вы не должны включать псевдоним при написании подзапроса в условном выражении. Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае IN ), а не как таблица.
Объединение подзапросов
Возможно, вы помните, что вы можете фильтровать запросы в соединениях. Довольно часто присоединяется к подзапросу, который обращается к той же таблице, что и внешний запрос, а не фильтруется в предложении
Довольно часто присоединяется к подзапросу, который обращается к той же таблице, что и внешний запрос, а не фильтруется в предложении WHERE . Следующий запрос дает те же результаты, что и в предыдущем примере:
ВЫБОР *
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
) суб
ВКЛ инциденты.дата = суб.дата
Это может быть особенно полезно в сочетании с агрегатами. При присоединении требования к выходным данным вашего подзапроса не такие строгие, как при использовании предложения WHERE . Например, ваш внутренний запрос может выводить несколько результатов. Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
ВЫБЕРИТЕ инциденты.
 *,
sub.incidents AS инциденты_этот_день
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ ПО 1
) суб
ВКЛ инциденты.дата = суб.дата
ORDER BY sub.incidents DESC, время
*,
sub.incidents AS инциденты_этот_день
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ ПО 1
) суб
ВКЛ инциденты.дата = суб.дата
ORDER BY sub.incidents DESC, время
Практическая задача
Напишите запрос, который отображает все строки из трех категорий с наименьшим количеством зарегистрированных инцидентов.
ПопробуйтеСмотреть ответ
Подзапросы могут быть очень полезны для повышения производительности ваших запросов. Давайте кратко вернемся к данным Crunchbase. Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
SELECT COALESCE(acquisitions.
 acquired_month, Investments.funded_month) AS month,
COUNT(DISTINCT Acquirements.company_permalink) КАК компании_приобретены,
COUNT(DISTINCT Investments.company_permalink) КАК инвестиции
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
СГРУППИРОВАТЬ ПО 1
acquired_month, Investments.funded_month) AS month,
COUNT(DISTINCT Acquirements.company_permalink) КАК компании_приобретены,
COUNT(DISTINCT Investments.company_permalink) КАК инвестиции
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
СГРУППИРОВАТЬ ПО 1
Обратите внимание, что для того, чтобы сделать это правильно, вы должны соединить поля даты, что вызывает массовый «взрыв данных». По сути, происходит то, что вы соединяете каждую строку в данном месяце из одной таблицы с каждым месяцем в данной строке в другой таблице, поэтому количество возвращаемых строк невероятно велико. Из-за этого мультипликативного эффекта вы должны использовать COUNT(DISTINCT) вместо COUNT , чтобы получить точные подсчеты. Вы можете увидеть это ниже:
Следующий запрос показывает 7414 строк:
ВЫБРАТЬ СЧЕТЧИК(*) ИЗ tutorial.crunchbase_acquisitions
Следующий запрос показывает 83 893 строки:
SELECT COUNT(*) FROM tutorial.
 crunchbase_investments
crunchbase_investments
Следующий запрос показывает 6 237 396 строк:
SELECT COUNT(*)
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
Если вы хотите понять это немного лучше, вы можете провести дополнительное исследование декартовых произведений. Также стоит отметить, что FULL JOIN и COUNT , приведенные выше, на самом деле работают довольно быстро — это COUNT(DISTINCT) , который занимает вечность. Подробнее об этом в уроке по оптимизации запросов.
Конечно, вы могли бы решить эту проблему намного эффективнее, объединив две таблицы по отдельности, а затем соединив их вместе, чтобы подсчеты выполнялись для гораздо меньших наборов данных:
приобретения.companies_acquired,
Investments.companies_rec_investment
ИЗ (
ВЫБЕРИТЕ приобретаете_месяц КАК месяц,
COUNT(DISTINCT company_permalink) AS company_acquired
ИЗ tutorial. crunchbase_acquisitions
crunchbase_acquisitions
СГРУППИРОВАТЬ ПО 1
) приобретения
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБЕРИТЕ funded_month AS месяц,
COUNT(DISTINCT company_permalink) КАК company_rec_investment
ИЗ tutorial.crunchbase_investments
СГРУППИРОВАТЬ ПО 1
)инвестиции
ON приобретения.месяц = инвестиции.месяц
ЗАКАЗАТЬ ПО 1 ДЕСК
Примечание. Мы использовали FULL JOIN выше на тот случай, если в одной таблице были наблюдения за месяц, которых не было в другой таблице. Мы также использовали COALESCE для отображения месяцев, когда в подзапросе поступлений не было записей о месяцах (предположительно, в эти месяцы не было поступлений). Мы настоятельно рекомендуем вам повторно выполнить запрос без некоторых из этих элементов, чтобы лучше понять, как они работают. Вы также можете запускать каждый из подзапросов независимо, чтобы лучше понять их.
Практическая задача
Напишите запрос, который подсчитывает количество основанных и приобретенных компаний по кварталам, начиная с первого квартала 2012 года. Создайте агрегаты в двух отдельных запросах, а затем объедините их.
Создайте агрегаты в двух отдельных запросах, а затем объедините их.
Попробуйте См. ответ
Подзапросы и ОБЪЕДИНЕНИЯ
В следующем разделе мы возьмем урок, посвященный ОБЪЕДИНЕНИЯМ, снова используя данные Crunchbase:
SELECT * ИЗ tutorial.crunchbase_investments_part1 СОЮЗ ВСЕХ ВЫБРАТЬ * ИЗ tutorial.crunchbase_investments_part2
Набор данных нередко бывает разделен на несколько частей, особенно если данные проходят через Excel в какой-либо момент (Excel может обрабатывать только около 1 млн строк на электронную таблицу). Две использованные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
SELECT COUNT(*) AS total_rows
ИЗ (
ВЫБРАТЬ *
ИЗ tutorial.crunchbase_investments_part1
СОЮЗ ВСЕХ
ВЫБРАТЬ *
ИЗ tutorial. crunchbase_investments_part2
) суб
 crunchbase_investments_part2
) суб
crunchbase_investments_part2
) суб
Это довольно просто. Попробуйте сами:
Практическая задача
Напишите запрос, который ранжирует инвесторов из приведенного выше комбинированного набора данных по общему количеству сделанных ими инвестиций.
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, который делает то же самое, что и в предыдущей задаче, но только для компаний, которые все еще работают. Подсказка: рабочий статус указан в tutorial.crunchbase_companies 9.0030 .
ПопробуйтеСмотреть ответ
Написание подзапросов в SQL | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
Основы подзапросовИспользование подзапросов для агрегирования в несколько этаповПодзапросы в условной логикеОбъединение подзапросовПодзапросы и UNION
На этом уроке вы продолжите работать с теми же данными о преступности в Сан-Франциско, что и на предыдущем уроке.
Основы работы с подзапросами
Подзапросы (также называемые внутренними запросами или вложенными запросами) — это инструмент для выполнения операций в несколько этапов. Например, если вы хотите взять суммы нескольких столбцов, а затем усреднить все эти значения, вам нужно будет выполнить каждую агрегацию на отдельном шаге.
Подзапросы могут использоваться в нескольких местах внутри запроса, но проще всего начать с С выписка. Вот пример простого подзапроса:
SELECT sub.*
ИЗ (
ВЫБРАТЬ *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ day_of_week = 'Пятница'
) суб
ГДЕ подразрешение = 'НЕТ'
Давайте разберем, что происходит, когда вы выполняете приведенный выше запрос:
Сначала база данных выполняет «внутренний запрос» — часть в скобках:
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ day_of_week = 'Пятница'
Если бы вы запустили этот запрос самостоятельно, он выдал бы набор результатов, как и любой другой запрос. Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После выполнения внутреннего запроса внешний запрос выполнит , используя результаты внутреннего запроса в качестве базовой таблицы :
Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После выполнения внутреннего запроса внешний запрос выполнит , используя результаты внутреннего запроса в качестве базовой таблицы :
SELECT sub.*
ИЗ (
<<результаты внутреннего запроса идут сюда>>
) суб
ГДЕ подразрешение = 'НЕТ'
Подзапросы должны иметь имена, которые добавляются после круглых скобок так же, как вы добавляете псевдоним к обычной таблице. В данном случае мы использовали имя «sub».
Небольшое замечание по форматированию. Важно помнить, что при использовании подзапросов необходимо предоставить читателю возможность легко определить, какие части запроса будут выполняться вместе. Большинство людей делают это, тем или иным образом делая отступ в подзапросе. Примеры в этом руководстве имеют довольно большой отступ — вплоть до круглых скобок. Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Практическая задача
Напишите запрос, который выбирает все ордера на арест из набора данных tutorial.sf_crime_incidents_2014_01 , а затем оберните его во внешний запрос, который отображает только неразрешенные инциденты.
Попробуйте См. ответ
Вышеприведенные примеры, а также практическая задача на самом деле не требуют подзапросов — они решают проблемы, которые также можно решить, добавив несколько условий в предложение WHERE . В следующих разделах приводятся примеры, для которых подзапросы являются лучшим или единственным способом решения соответствующих проблем.
Использование подзапросов для агрегирования в несколько этапов
Что делать, если вы хотите выяснить, сколько инцидентов сообщается в каждый день недели? А что, если вы хотите узнать, сколько инцидентов происходит в среднем в пятницу декабря? В январе? Этот процесс состоит из двух шагов: подсчет количества инцидентов каждый день (внутренний запрос), затем определение среднемесячного значения (внешний запрос):
суб. день_недели,
день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ИЗ (
ВЫБЕРИТЕ день_недели,
свидание,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
Если вы не можете понять, что происходит, попробуйте запустить внутренний запрос отдельно, чтобы понять, как выглядят его результаты. В общем, проще всего сначала написать внутренние запросы и пересматривать их до тех пор, пока результаты не станут для вас понятными, а затем перейти к внешнему запросу.
Практическая задача
Напишите запрос, отображающий среднее количество инцидентов в месяц для каждой категории. Подсказка: используйте tutorial.sf_crime_incidents_cleandate , чтобы немного облегчить себе жизнь.
Попробуйте См. ответ
Подзапросы в условной логике
Вы можете использовать подзапросы в условной логике (в сочетании с WHERE , JOIN / ON или CASE ). Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата = (ВЫБРАТЬ МИН (дата)
ИЗ tutorial.sf_crime_incidents_2014_01
)
Приведенный выше запрос работает, поскольку результатом подзапроса является только одна ячейка. Большая часть условной логики будет работать с подзапросами, содержащими результаты с одной ячейкой. Однако IN — это единственный тип условной логики, который будет работать, когда внутренний запрос содержит несколько результатов:
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата В (ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
)
Обратите внимание, что вы не должны включать псевдоним при написании подзапроса в условном выражении. Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае
Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае IN ), а не как таблица.
Объединение подзапросов
Возможно, вы помните, что вы можете фильтровать запросы в соединениях. Довольно часто присоединяется к подзапросу, который обращается к той же таблице, что и внешний запрос, а не фильтруется в предложении WHERE . Следующий запрос дает те же результаты, что и в предыдущем примере:
ВЫБОР *
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
) суб
ВКЛ инциденты.дата = суб.дата
Это может быть особенно полезно в сочетании с агрегатами. При присоединении требования к выходным данным вашего подзапроса не такие строгие, как при использовании предложения WHERE . Например, ваш внутренний запрос может выводить несколько результатов. Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
ВЫБЕРИТЕ инциденты.*,
sub.incidents AS инциденты_этот_день
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ ПО 1
) суб
ВКЛ инциденты.дата = суб.дата
ORDER BY sub.incidents DESC, время
Практическая задача
Напишите запрос, который отображает все строки из трех категорий с наименьшим количеством зарегистрированных инцидентов.
ПопробуйтеСмотреть ответ
Подзапросы могут быть очень полезны для повышения производительности ваших запросов. Давайте кратко вернемся к данным Crunchbase. Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
SELECT COALESCE(acquisitions.acquired_month, Investments.funded_month) AS month,
COUNT(DISTINCT Acquirements.company_permalink) КАК компании_приобретены,
COUNT(DISTINCT Investments.company_permalink) КАК инвестиции
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
СГРУППИРОВАТЬ ПО 1
Обратите внимание, что для того, чтобы сделать это правильно, вы должны соединить поля даты, что вызывает массовый «взрыв данных». По сути, происходит то, что вы соединяете каждую строку в данном месяце из одной таблицы с каждым месяцем в данной строке в другой таблице, поэтому количество возвращаемых строк невероятно велико. Из-за этого мультипликативного эффекта вы должны использовать
Из-за этого мультипликативного эффекта вы должны использовать COUNT(DISTINCT) вместо COUNT , чтобы получить точные подсчеты. Вы можете увидеть это ниже:
Следующий запрос показывает 7414 строк:
ВЫБРАТЬ СЧЕТЧИК(*) ИЗ tutorial.crunchbase_acquisitions
Следующий запрос показывает 83 893 строки:
SELECT COUNT(*) FROM tutorial.crunchbase_investments
Следующий запрос показывает 6 237 396 строк:
SELECT COUNT(*)
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
Если вы хотите понять это немного лучше, вы можете провести дополнительное исследование декартовых произведений. Также стоит отметить, что FULL JOIN и COUNT , приведенные выше, на самом деле работают довольно быстро — это COUNT(DISTINCT) , который занимает вечность. Подробнее об этом в уроке по оптимизации запросов.
Подробнее об этом в уроке по оптимизации запросов.
Конечно, вы могли бы решить эту проблему намного эффективнее, объединив две таблицы по отдельности, а затем соединив их вместе, чтобы подсчеты выполнялись для гораздо меньших наборов данных:
приобретения.companies_acquired,
Investments.companies_rec_investment
ИЗ (
ВЫБЕРИТЕ приобретаете_месяц КАК месяц,
COUNT(DISTINCT company_permalink) AS company_acquired
ИЗ tutorial.crunchbase_acquisitions
СГРУППИРОВАТЬ ПО 1
) приобретения
ПОЛНОЕ СОЕДИНЕНИЕ (
ВЫБЕРИТЕ funded_month AS месяц,
COUNT(DISTINCT company_permalink) КАК company_rec_investment
ИЗ tutorial.crunchbase_investments
СГРУППИРОВАТЬ ПО 1
)инвестиции
ON приобретения.месяц = инвестиции.месяц
ЗАКАЗАТЬ ПО 1 ДЕСК
Примечание. Мы использовали FULL JOIN выше на тот случай, если в одной таблице были наблюдения за месяц, которых не было в другой таблице. Мы также использовали
Мы также использовали COALESCE для отображения месяцев, когда в подзапросе поступлений не было записей о месяцах (предположительно, в эти месяцы не было поступлений). Мы настоятельно рекомендуем вам повторно выполнить запрос без некоторых из этих элементов, чтобы лучше понять, как они работают. Вы также можете запускать каждый из подзапросов независимо, чтобы лучше понять их.
Практическая задача
Напишите запрос, который подсчитывает количество основанных и приобретенных компаний по кварталам, начиная с первого квартала 2012 года. Создайте агрегаты в двух отдельных запросах, а затем объедините их.
Попробуйте См. ответ
Подзапросы и ОБЪЕДИНЕНИЯ
В следующем разделе мы возьмем урок, посвященный ОБЪЕДИНЕНИЯМ, снова используя данные Crunchbase:
SELECT *
ИЗ tutorial.crunchbase_investments_part1
СОЮЗ ВСЕХ
ВЫБРАТЬ *
ИЗ tutorial.crunchbase_investments_part2
Набор данных нередко бывает разделен на несколько частей, особенно если данные проходят через Excel в какой-либо момент (Excel может обрабатывать только около 1 млн строк на электронную таблицу). Две использованные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
Две использованные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
SELECT COUNT(*) AS total_rows
ИЗ (
ВЫБРАТЬ *
ИЗ tutorial.crunchbase_investments_part1
СОЮЗ ВСЕХ
ВЫБРАТЬ *
ИЗ tutorial.crunchbase_investments_part2
) суб
Это довольно просто. Попробуйте сами:
Практическая задача
Напишите запрос, который ранжирует инвесторов из приведенного выше комбинированного набора данных по общему количеству сделанных ими инвестиций.
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, который делает то же самое, что и в предыдущей задаче, но только для компаний, которые все еще работают. Подсказка: рабочий статус указан в tutorial.