Postgresql php пример: PHP: Базовое использование — Manual
Содержание
PHP: PostgreSQL — Manual
PHP 8.2.4 Released!
- Введение
- Установка и настройка
- Требования
- Установка
- Настройка во время выполнения
- Типы ресурсов
- Предопределённые константы
- Примеры
- Базовое использование
- Базовое использование
- Функции PostgreSQL
- pg_affected_rows — Возвращает количество затронутых запросом записей (кортежей)
- pg_cancel_query — Остановка асинхронного запроса.
- pg_client_encoding — Получение кодировки клиента.
- pg_close — Закрывает соединение с базой данных PostgreSQL
- pg_connect_poll — Опросить статус попытки асинхронного соединения PostgreSQL.
- pg_connect — Открывает соединение с базой данных PostgreSQL
- pg_connection_busy — Проверяет, занято ли соединение в данный момент.
- pg_connection_reset — Сброс подключения (переподключение)
- pg_connection_status — Определяет состояние подключения
- pg_consume_input — Читает вводные данные на соединении
- pg_convert — Преобразует значения ассоциативного массива в приемлемые для использования в SQL-запросах
- pg_copy_from — Вставляет записи из массива в таблицу
- pg_copy_to — Копирует данные из таблицы в массив
- pg_dbname — Определяет имя базы данных
- pg_delete — Удаляет записи
- pg_end_copy — Синхронизирует с бэкендом PostgreSQL
- pg_escape_bytea — Экранирует спецсимволы в строке для вставки в поле типа bytea
- pg_escape_identifier — Экранирует идентификатор для вставки в текстовое поле
- pg_escape_literal — Экранировать литерал при вставке в текстовое поле
- pg_escape_string — Экранирование спецсимволов в строке запроса
- pg_execute — Запускает выполнение ранее подготовленного параметризованного запроса и ждёт результат
- pg_fetch_all_columns — Выбирает все записи из одной колонки результата запроса и помещает их в массив
- pg_fetch_all — Выбирает все данные из результата запроса и помещает их в массив
- pg_fetch_array — Возвращает строку результата в виде массива
- pg_fetch_assoc — Выбирает строку результата запроса и помещает данные в ассоциативный массив
- pg_fetch_object — Выбирает строку результата запроса и возвращает данные в виде объекта
- pg_fetch_result — Возвращает запись из результата запроса
- pg_fetch_row — Выбирает строку результата запроса и помещает данные в массив
- pg_field_is_null — Проверка поля на значение SQL NULL
- pg_field_name — Возвращает наименование поля
- pg_field_num — Возвращает порядковый номер именованного поля
- pg_field_prtlen — Возвращает количество печатаемых символов
- pg_field_size — Возвращает размер поля
- pg_field_table — Возвращает наименование или идентификатор таблицы, содержащей заданное поле
- pg_field_type_oid — Возвращает идентификатор типа заданного поля
- pg_field_type — Возвращает имя типа заданного поля
- pg_flush — Сбросить данные исходящего запроса на соединении
- pg_free_result — Очистка результата запроса и освобождение памяти
- pg_get_notify — Получение SQL NOTIFY сообщения
- pg_get_pid — Получает ID процесса сервера БД
- pg_get_result — Получение результата асинхронного запроса
- pg_host — Возвращает имя хоста, соответствующего подключению
- pg_insert — Заносит данные из массива в таблицу базы данных
- pg_last_error — Получает сообщение о последней произошедшей ошибке на соединении с базой данных
- pg_last_notice — Возвращает последнее уведомление от сервера PostgreSQL
- pg_last_oid — Возвращает OID последней добавленной в базу строки
- pg_lo_close — Закрывает большой объект
- pg_lo_create — Создаёт большой объект
- pg_lo_export — Вывод большого объекта в файл
- pg_lo_import — Импорт большого объекта из файла
- pg_lo_open — Открывает большой объект базы данных
- pg_lo_read_all — Читает содержимое большого объекта и посылает напрямую в браузер
- pg_lo_read — Читает данные большого объекта
- pg_lo_seek — Перемещает внутренний указатель большого объекта
- pg_lo_tell — Возвращает текущее положение внутреннего указателя большого объекта
- pg_lo_truncate — Обрезает большой объект
- pg_lo_unlink — Удаление большого объекта
- pg_lo_write — Записывает данные в большой объект
- pg_meta_data — Получение метаданных таблицы
- pg_num_fields — Возвращает количество полей в выборке
- pg_num_rows — Возвращает количество строк в выборке
- pg_options — Получение параметров соединения с сервером баз данных
- pg_parameter_status — Просмотр текущих значений параметров сервера
- pg_pconnect — Открывает постоянное соединение с сервером PostgreSQL
- pg_ping — Проверка соединения с базой данных
- pg_port — Возвращает номер порта, соответствующий заданному соединению
- pg_prepare — Посылает запрос на создание параметризованного SQL выражения
и ждёт его завершения - pg_put_line — Передаёт на PostgreSQL сервер строку с завершающим нулём
- pg_query_params — Посылает параметризованный запрос на сервер, параметры передаются отдельно от текста SQL запроса
- pg_query — Выполняет запрос
- pg_result_error_field — Возвращает конкретное поле из отчёта об ошибках
- pg_result_error — Возвращает сообщение об ошибке, связанное с запросом результата
- pg_result_seek — Смещает указатель на строку выборки в экземпляре результата запроса
- pg_result_status — Возвращает состояние результата запроса
- pg_select — Выбирает записи из базы данных
- pg_send_execute — Запускает предварительно подготовленный SQL-запрос и
передаёт ему параметры; не ожидает возвращаемого результата - pg_send_prepare — Посылает запрос на создание параметризованного SQL-выражения,
не дожидаясь его завершения - pg_send_query_params — Посылает параметризованный запрос на сервер, не ожидает возвращаемого результата
- pg_send_query — Отправляет асинхронный запрос
- pg_set_client_encoding — Устанавливает клиентскую кодировку
- pg_set_error_verbosity — Определяет объем текста сообщений, возвращаемых функциями
pg_last_error и pg_result_error - pg_socket — Получить дескриптор только для чтения на сокет, лежащего в основе соединения PostgreSQL
- pg_trace — Включает трассировку подключения PostgreSQL
- pg_transaction_status — Возвращает текущее состояние транзакции на сервере
- pg_tty — Возвращает имя терминала TTY, связанное с соединением
- pg_unescape_bytea — Убирает экранирование двоичных данных типа bytea
- pg_untrace — Отключает трассировку соединения с PostgreSQL
- pg_update — Обновление данных в таблице
- pg_version — Возвращает массив, содержащий версии клиента, протокола клиент-серверного
взаимодействия и сервера (если доступно)
- PgSql\Connection — Класс PgSql\Connection
- PgSql\Result — Класс PgSql\Result
- PgSql\Lob — Класс PgSql\Lob
+add a note
User Contributed Notes
There are no user contributed notes for this page.
Python и FastAPI | Подключение к базе данных и создание таблиц
Последнее обновление: 07.09.2022
FastAPI поддерживает работу с самыми разными системами баз данных: PostgreSQL, MySQL, SQLite, Oracle, Microsoft SQL Server и т.д. Причем мы не ограничены только реалиционными базами данных и равным
образом использовать и нереляционные, так называемые NoSQL-системы баз данных.
При работе с базами данных самым простым решением является использование специальных инструментов — ORM (Object Relational Mapper), которые позволяют абстрагироваться
от строения базы данных в конкретной СУБД и позволяет автоматически связать сущности в коде Python с таблицами в базе данных. В FastAPI наиболее распространным ORM-инструментом является
SQLAlchemy ORM
Рассмотрим работу с базой данных через SQLAlchemy ORM на примере SQLite, поскольку SQLite не требует установки сервера или каких-то дополнительных инструментов.
Кроме того, перейти от одной СУБД к другой не составить особого труда и почти не потребует изменения кода взаимодействия с БД, за исключением пары строк кода.
Прежде всего нам надо установить сам SQLAlchemy с помощью команды
pip install sqlalchemy
Определение строки подключения к БД
Прежде всего для подключения к базе данных необходима строка подключения, которая включает адрес базы данных и другие различные параметры, необходимые для подключения. Для
разных СУБД строка подключения может отличаться. Пример строки подключения к SQLite:
# строка подключения SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
Для sqlite строка подключения начинается с sqlite://, затем идет относительный или абсолютный путь к файлу:
sqlite:///относительный_путь/file.db sqlite:////абсолютный_путь/file.db
В данном случае это «./sql_app.db», который указывает, что файл базы данных будет называться
«sql_app.db» и будет располагаться в текущей папке.
В зависимости от конкретной субд строка подключения будет различаться. Так, если бы мы подключись бы к базе данных PostgreSQL, то строка подключения имела бы следующий формат:
SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
где user — имя пользователя на сервере PostgreSQL, password — пароль, postgresserver — адрес сервера, а db — имя базы данных на сервере.
При подключении к другим системам баз данных по сути это единственная строка кода, которая потребует изменения.
Определение движка
После определения строки подключения создается движок SQLAlchemy с помощью функции create_engine():
from sqlalchemy import create_engine
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# создание движка
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
Первый параметр функции указывает на строку подключения — то есть по сути базу данных, к которой идет подключение.
Второй параметр — дополнительные параметры подключения в виде словаря connect_args. В частности, элемент "check_same_thread": False предназначен только
для SQLite и указывает, что для взаимодействия с базой данных SQLite в рамках одного запроса может использоваться больше одного потока. Зачем это надо?
По умолчанию SQLite разрешает взаимодействовать с БД только одному потоку, чтобы один поток обрабатывал отдельный запрос, что позволяет предотвратить использование одного потока для разных запросов.
Но в FastAPI в рамках одного и того же запроса с базой данных могут взаимодействовать более одного потока. Собственно поэтому необходима подобная настройка для получения необходимых разрешений.
При этом каждый запрос будет получать свой собственный сеанс подключения к базе данных через механизм внедрения зависимостей, поэтому в механизме по умолчанию нет необходимости.
При работе с другими СУБД достаточно указать только адрес подключения:
engine = create_engine(SQLALCHEMY_DATABASE_URL)
Определение моделей
Модели представляют классы, которые соответствуют определению таблиц в базе данных и объекты которых хранятся в этих таблицах. И одним из преимуществ SQLAlchemy является то, что мы
можем работать таблицами через эти модели-классы языка Python, не прибегая к созданию запросов на языке SQL.
Для создания моделей необходима базовая модель, от которой потом наследуются остальные модели. Для создания базовой модели можно использовать различные способы, но самый короткий —
создания класса модели с помощью функции declarative_base():
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
 ext.declarative import declarative_base
Base = declarative_base()
ext.declarative import declarative_base
Base = declarative_base()
То есть в данном случае определяется класс Base — базовая модель. Затем уже можно определить конкретные модели, данные которых будут храниться в БД. Например:
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
Base = declarative_base()
class Person(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, index=True)
name = Column(String)
age = Column(Integer,)
Здесь определена модель Person, которая представляет пользователя. Она наследуется от Base и определяет ряд атрибутов.
Атрибут __tablename__ хранит имя таблицы, с которой будет сопоставляться текущая модель. То есть данные класса Person будут храниться в таблице «people».
Для хранения данных в классе модели определяются атрибуты, которые сопоставляются со столбцами таблицы. Такие атрибуты в качестве значения получаются объект Column.
Такие атрибуты в качестве значения получаются объект Column.
В данном случае класс Person определяет три таких атрибута: id, name и age, для которых в таблице people будут создаваться одноименные столбцы.
Класс Column с помощью параметров конструктора определяет настройки столбца в таблицы. Здесь в конструктор вначале передается тип столбца. Так, у id и age тип столбца — Integer,
то есть целое число. А столбец name представляет тип String, то есть строку.
Кроме того, в конструктор можно передать ряд дополнительных параметров. Так, для столбца id передаются параметры primary_key и index. Значение
primary_key=True указывает, что данный столбец будет представлять первичный ключ. А параметр index=True говорит, что для данного столбца будет создаваться индекс.
Создание базы данных и таблиц
Для создания базы данных и таблиц по метаданным моделей применяется метод Base.. Его ключевой параметр —  metadata.create_all()
metadata.create_all()bind принимает класс,
который используется для подключения к базе данных. В качестве такого класса применяется созданный ранее движок SQLAlchemy. Если база данных и все необходимые таблицы уже имеются, то метод не создает заново таблицы.
Посмотрим на простейшем примере. Все объединим и определим в файле приложения следующий код:
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from fastapi import FastAPI
# строка подключения
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# создаем движок SqlAlchemy
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
#создаем базовый класс для моделей
Base = declarative_base()
# создаем модель, объекты которой будут храниться в бд
class Person(Base):
__tablename__ = "people"
id = Column(Integer, primary_key=True, index=True)
name = Column(String)
age = Column(Integer,)
# создаем таблицы
Base. metadata.create_all(bind=engine)
# приложение, которое ничего не делает
app = FastAPI()
 metadata.create_all(bind=engine)
# приложение, которое ничего не делает
app = FastAPI()
metadata.create_all(bind=engine)
# приложение, которое ничего не делает
app = FastAPI()
После запуска приложения в папке проекта будет создана таблица sql_app.db:
Мы можем открыть эту базу данных с помощью любой программы для просмотра баз данных sqlite
(например, с помощью DB Browser for SQLite) и увидеть содержимое бд:
НазадСодержаниеВперед
PHP: PostgreSQL — Руководство
Выпущен PHP 8.2.4!
- Introduction
- Installing/Configuring
- Requirements
- Installation
- Runtime Configuration
- Resource Types
- Predefined Constants
- Examples
- Basic usage
- Basic usage
- PostgreSQL Functions
- pg_affected_rows — Returns количество затронутых записей (кортежей)
- pg_cancel_query — отмена асинхронного запроса
- pg_client_encoding — получение кодировки клиента
- pg_close — закрытие соединения PostgreSQL
- pg_connect_poll — опрос состояния выполняемого асинхронного соединения PostgreSQL
try - pg_connect — открыть соединение с PostgreSQL
- pg_connection_busy — узнать занято соединение или нет0006
- pg_consume_input — Считывает ввод по соединению
- pg_convert — Преобразует значения ассоциативного массива в форму, подходящую для операторов SQL
- pg_copy_from — Вставляет записи в таблицу из массива
- pg_copy_to — Копирует таблицу в массив имя базы данных
- pg_delete — удаляет записи
- pg_end_copy — синхронизируется с серверной частью PostgreSQL
- pg_escape_bytea — экранирует строку для вставки в поле bytea
- pg_escape_identifier — экранирование идентификатора для вставки в текстовое поле
- pg_escape_literal — экранирование литерала для вставки в текстовое поле
- pg_escape_string — экранирование строки для запроса
- pg_execute — отправляет запрос на выполнение подготовленного оператора с заданными параметрами и ожидает результата
- pg_fetch_all_columns — извлекает все строки в определенном столбце результатов в виде массива
- pg_fetch_all — извлекает все строки из результата в виде массива
- pg_fetch_array — Выбрать строку как массив
- pg_fetch_assoc — Выбрать строку как ассоциативный массив
- pg_fetch_object — Выбрать строку как объект
- pg_fetch_result — Возвращает значения из экземпляра результата enumerated array
- pg_field_is_null — Проверяет, является ли поле SQL NULL
- pg_field_name — Возвращает имя поля
- pg_field_num — Возвращает номер именованного поля
- pg_field_prtlen — Возвращает напечатанную длину
- pg_field_size — Возвращает размер внутренней памяти именованного поля
- pg_field_table — Возвращает имя или oid поля таблиц
- pg_field_type_oid — Возвращает идентификатор типа (OID) для соответствующего номера поля
- pg_field_type — Возвращает имя типа для соответствующего номера поля
- pg_flush — Сброс данных исходящего запроса в соединение
- pg_free_result — Свободная память результатов
- pg_get_notify — Получает сообщение SQL NOTIFY
- pg_get_pid — Получает идентификатор процесса бэкенда
- pg_get_result — Получает результат асинхронного запроса
- pg_host — Возвращает имя хоста, связанное с соединением строка последнего сообщения об ошибке соединения
- pg_last_notice — возвращает последнее уведомление от сервера PostgreSQL
- pg_last_oid — возвращает OID последней строки
- pg_lo_close — Закрыть большой объект
- pg_lo_create — Создать большой объект
- pg_lo_export — Экспортировать большой объект в файл
- pg_lo_import — Импортировать большой объект из файла
- pg_lo_opens — Открыть большой объект
6 весь большой объект и отправить прямо в браузер
- pg_lo_read — прочитать большой объект
- pg_lo_seek — найти позицию внутри большого объекта
- pg_lo_tell — вернуть текущую позицию поиска большого объекта
- PG_LO_TRUNCATE — усекает большой объект
- PG_LO_UNLINK — Удалить большой объект
- PG_LO_WRITE — Напишите в большой объект
- PG_META_DATA — GET META DATA для таблицы
- PG_NUM_FIELDS — returns. Возвращает количество строк в результате
- pg_options — Получить параметры, связанные с соединением
- pg_parameter_status — Ищет текущую настройку параметра сервера
- pg_pconnect — открыть постоянное соединение с PostgreSQL
- pg_ping — пропинговать соединение с базой данных
- pg_port — вернуть номер порта, связанный с соединением
с заданными параметрами и ожидает завершения - pg_put_line — отправляет завершающую NULL строку в серверную часть PostgreSQL
- pg_query_params — отправляет команду на сервер и ожидает результат, с возможностью передачи параметров отдельно от текста команды SQL
- pg_query — Выполнить запрос
- pg_result_error_field — Возвращает отдельное поле отчета об ошибке
- pg_result_error — Получить сообщение об ошибке, связанное с результатом
- pg_result_seek — Установить внутреннее смещение строки в экземпляре результата
- pg_select — Выбор записей
- pg_send_execute — Отправляет запрос на выполнение подготовленного оператора с заданными параметрами, не дожидаясь результата(ов)
- pg_send_prepare — Отправляет запрос на создание подготовленного оператора с заданными параметрами, не дожидаясь завершения
- pg_send_query_params — Отправляет команду и отдельные параметры на сервер, не дожидаясь результата(ов)
- pg_send_query — Отправляет асинхронный запрос
- pg_set_client_encoding — Установка кодировки клиента
- pg_set_error_verbosity — Определяет уровень детализации сообщений, возвращаемых pg_last_error
и pg_result_error - pg_socket — Получить дескриптор сокета, лежащего в основе соединения PostgreSQL, только для чтения
- pg_trace — Включить отслеживание соединения PostgreSQL connection
- pg_unescape_bytea — Unescape двоичный файл для типа bytea
- pg_untrace — отключить трассировку соединения PostgreSQL
- pg_update — обновить таблицу
- pg_version — возвращает массив с версией клиента, протокола и сервера (если доступно)
- PgSql\Connection — класс PgSql\Connection
- PgSql\Result — класс PgSql\Result
- PgSql\Lob — класс PgSql\ Класс Lob
 Возвращает количество строк в результате
Возвращает количество строк в результате+ добавить примечание
Пользовательские заметки
Для этой страницы нет пользовательских заметок.
Пример приложения PHP+PostgreSQL
Пример приложения PHP+PostgreSQL
Фон
Сайт, используемый для регистрации групп CS186, был разработан с использованием PHP и PostgreSQL. Хотя по соображениям безопасности сайт в некоторых областях сложнее, чем тот, который вам нужно будет спроектировать, он послужит хорошим начальным примером. При разработке сайта мы старались комментировать и кодировать «чисто», чтобы сделать пример максимально полезным для вас.
Исходные файлы
Здесь вы можете скачать исходные файлы, используемые для запуска сайта регистрации. За исключением удаления пароля, файлы являются точными файлами SQL и PHP, используемыми на реальном сайте. Вы можете сообщать о любых ошибках по адресу [email protected].
Архитектура
Сайт состоит из трех основных частей:
- Основной сайт: Эта часть взаимодействует с пользователем (через WWW) и действует как точка входа в систему. Эти два сценария выполняются на учебном веб-сервере.
- Внутренний сайт: эта часть работает на другом компьютере и представляет собой интерфейс PHP для PostgreSQL. Он работает на отдельной машине из соображений безопасности.
- База данных: это база данных PostgreSQL 7.2.2, работающая на исследовательской машине. Мы предоставили SQL, используемый для настройки базы данных.

Пользователи начинают с перехода на веб-страницу group-reg.php. Этот скрипт отображает веб-форму и получает данные, отправленные пользователями. Все отправленные данные проверяются, чтобы убедиться, что они существуют и не являются дублирующейся информацией. Если все данные в рабочем состоянии, они передаются на серверный веб-сайт с помощью HTTP-запроса.
Внутренние сайты повторяют проверку всех данных, а также проверяют, чтобы на входе были только допустимые символы и цифры. Эта окончательная проверка не позволяет пользователю вводить свои собственные SQL-команды, «заканчивая» предыдущую команду и предоставляя свои собственные. О любых ошибках немедленно сообщается запрашиваемому с помощью простого кода ответа, состоящего из одного слова, и обработка прекращается.
О любых ошибках немедленно сообщается запрашиваемому с помощью простого кода ответа, состоящего из одного слова, и обработка прекращается.
Затем сценарий подключается к базе данных, все ошибки здесь возлагаются на систему и сообщаются как таковые. Затем журнал запроса записывается в базу данных.
Наши сценарии используют транзакции, чтобы сделать процесс регистрации атомарным. Это означает (как вы позже узнаете подробнее), что либо происходит вся регистрация, либо ничего. Все команды между BEGIN и COMMIT (или ROLLBACK) считаются частью транзакции. COMMIT сделает действие всех команд постоянным, а ROLLBACK отменит любые сделанные изменения. Вы не обязаны использовать транзакции, хотя они могут упростить ваш код.
Каждый учащийся будет проверен, чтобы убедиться, что он существует и еще не зарегистрирован. В случае возникновения проблемы инициатору запроса отправляется неописуемое сообщение об ошибке, а точное состояние ошибки заносится в базу данных. Если проблем нет, создается новая группа, учащиеся назначаются в эту группу, и изменения фиксируются. Делается окончательная запись в журнале, и ученикам отправляется электронное письмо.
Делается окончательная запись в журнале, и ученикам отправляется электронное письмо.
Основная часть фактического взаимодействия с базой данных содержится во включенном файле db.php. В этом файле показано, как выполняется фактическое подключение к базе данных, как выполнять команды SQL и как извлекать информацию из выполняемого оператора SQL.
Примечания к схеме
Мы также предоставили файлы схемы, которые использовали для создания базы данных. Первый, schema.sql, содержит основные команды DDL, которые создают таблицы и связанные структуры. Вы заметите структуру, называемую последовательностью. Последовательности — это в основном счетчики, которые поддерживаются базой данных и обычно используются для генерации уникальных номеров. Мы используем счетчики для генерации идентификаторов журналов и идентификаторов групп. Функция с именем NEXTVAL извлекает текущее значение последовательности и увеличивает его значение.
Файл access.sql сбрасывает разрешения для всех таблиц, ограничивая доступ к веб-сайту в случае возникновения проблемы.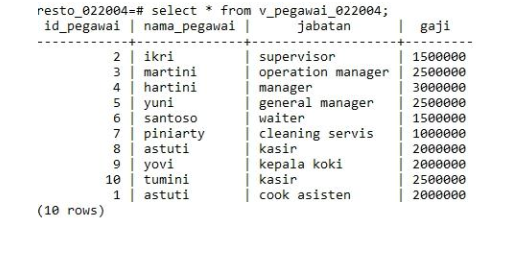
Файл views.sql содержит ряд представлений, которые мы используем для просмотра/сопоставления данных. Вы можете счесть полезным использовать представления для упрощения SQL в ваших сценариях, хотя в данном случае это не причина, поскольку данные недоступны через Интернет.
Последнее замечание относительно нашей схемы. Мы использовали таблицу с именем student_in, куда загружались необработанные данные. Схема этой таблицы отличается от фактической таблицы студентов из-за формата данных от TeleBears. Мы использовали оператор SQL для преобразования данных из одного формата в другой, который находится в файле dataconv.sql. В реальном мире обычно данные необходимо очищать/преобразовывать перед загрузкой в базу данных. Большинство основных продуктов баз данных содержат обширные утилиты, которые делают этот процесс простым и расширяемым. К сожалению, PostgreSQL не поддерживает методы простой загрузки, требующие от нас обработки данных после их загрузки в систему. Для вашего проекта вам не нужно будет беспокоиться об этом.