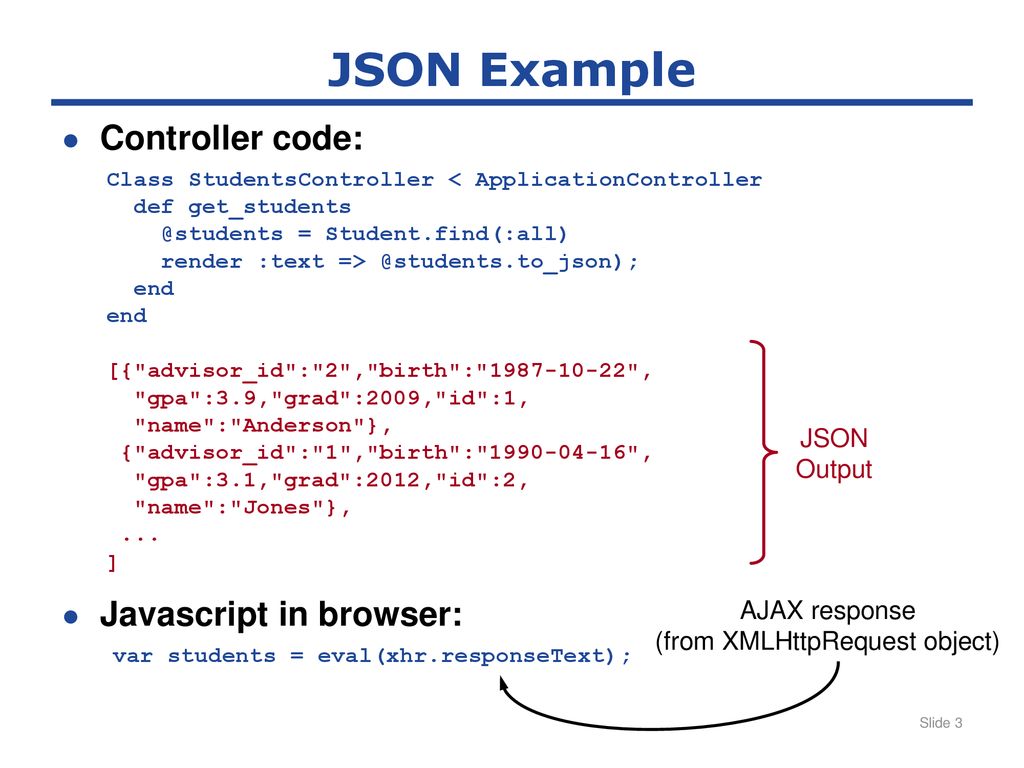
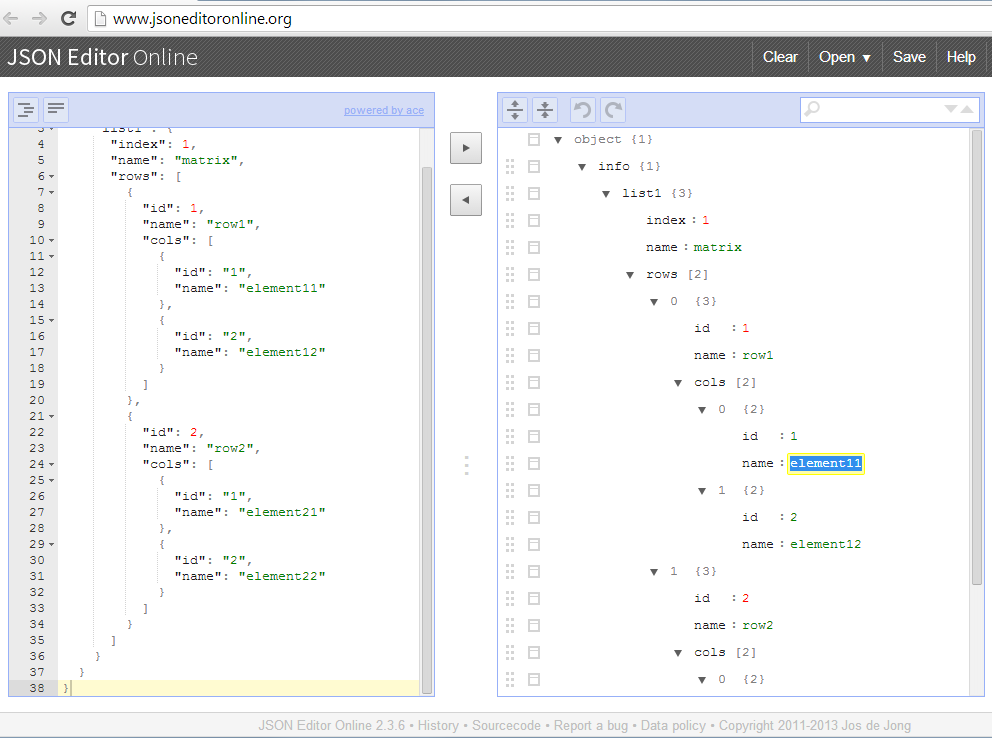
С json: C# и .NET | Сериализация в JSON. JsonSerializer
Содержание
Ищем альтернативу и упрощаем работу с JSON / Хабр
Разработчики часто находятся между Сциллой и Харибдой: «не улучшай то, что работает» и «можно ли сделать лучше то, что и так работает отлично?». Применительно к облачной архитектуре пространство для манёвра сужается: каждое изменение может повлиять на бизнес тысяч клиентов.
Сегодня наша тема — повод задуматься и подискутировать. Мы затронем аспект облака, о котором обычно не говорят — JSON. Объекты JSON используют для разных задач. В основном это обмен данными между серверами и веб-приложениями. Формат также применяют для управления облачной инфраструктурой, интеграции с кастомными скриптами и сервисами. Есть и экзотические кейсы вроде хранения в файлах JSON записей базы данных.
Однако некоторые специалисты отмечают большое количество «синтаксического мусора», другие — ограниченную поддержку инструментов разработки. Поэтому появляются альтернативы, о которых мы и поговорим в сегодняшнем материале.
Как обеспечить масштабируемость облака
По оценкам аналитического ресурса builtwith. com, JSON используют более 180 000 сайтов. Они принадлежат не только крупным телекомам, игровым платформам и ретейлерам, но и локальным тематическим площадкам.
com, JSON используют более 180 000 сайтов. Они принадлежат не только крупным телекомам, игровым платформам и ретейлерам, но и локальным тематическим площадкам.
В то же время с JSON работают облачные провайдеры — например, задействуют его для поддержания связи между клиентскими приложениями и сервером.
Виртуальная инфраструктура может автоматизировать масштабирование сервисов через запросы API, например, с помощью Terraform. Таким образом, можно быстрее предоставлять ИТ-ресурсы с учетом пиковых периодов спроса и обеспечивать сотрудникам (или клиентам) доступ из любой точки мира.
Широкий спектр применимости ведет и к более активной критике формата со стороны специалистов. Часть неудобств связана с синтаксисом — например, всего одна лишняя запятая приводит к сбою в JSON-файле.
Нюансы JSON формата
Головную боль у разработчиков вызывают и мелкие нюансы в вопросах функциональности. Так, формат не поддерживает комментарии, его спецификация излишне строгая, а сам он плохо подходит для работы с числами в шестнадцатеричном представлении.
Для решения этих и других проблем существуют различные инструменты, в том числе открытые. Например, библиотека RapidJSON упрощает парсинг данных, а процессор jq их структуризацию.
С другой стороны, консольная утилита dasel позволяет редактировать данные в разных форматах (JSON, TOML, YAML, XML и CSV) и поддерживает их конвертацию.
Но один разработчик решил пересмотреть подход и представил альтернативу JSON — язык UCL. В теории он должен исправить некоторые проблемы «классического» формата обмена данными.
Что предлагает UCL
Его задача — сделать работу с файлами конфигураций JSON более удобной. Чтобы достигнуть этой цели, автор внес множество синтаксических изменений. Например, в UCL не нужны фигурные скобки для описания верхних объектов — можно прописать «key»: «value» вместо {«key»: «value»}.
Также необязательно использовать двойные кавычки для строк и ключей, а вместо двоеточия при их декларации ставится равно:
key = value;
section {
key = value;
}
По сути, запись выше равнозначна следующей конструкции:
{
"key": "value",
"section": {
"key": "value"
}
}
По умолчанию классический JSON поддерживает только значения в десятичной системе счисления. В UCL добавили шестнадцатеричные целые (префикс 0x), а также булевы переменные — true, yes, on и соответствующие им false, no, off. В то же время UCL поддерживает автоматическое создание массивов и комментирование — знак # для одной строки и конструкцию /*… */ для нескольких. Так, можно быстро активировать и отключать части кода.
В UCL добавили шестнадцатеричные целые (префикс 0x), а также булевы переменные — true, yes, on и соответствующие им false, no, off. В то же время UCL поддерживает автоматическое создание массивов и комментирование — знак # для одной строки и конструкцию /*… */ для нескольких. Так, можно быстро активировать и отключать части кода.
В язык встроен макрос include для загрузки контента из других файлов в UCL-объект. В качестве атрибута макрос принимает или путь к директории, или URL:
.include "./relative/path.conf"
.include "http://example.com/file.conf"
UCL позволяет проводить валидацию объектов по схеме JSON-schema v4. Однако не поддерживает remote references. Если говорить о производительности, то автор утверждает, что UCL примерно в два раза быстрее jansson на задачах парсинга.
Что думает сообщество
В свое время проект UCL привлек внимание резидентов Hacker News. Многие встретили разработку с теплотой и положительно оценили работу с элементами так называемого «синтаксического сахара». И вокруг инструмента уже сформировалось сообщество энтузиастов — его репозиторий собрал больше 1,5 тыс. звезд.
И вокруг инструмента уже сформировалось сообщество энтузиастов — его репозиторий собрал больше 1,5 тыс. звезд.
Однако нашлись и те, кто встретил разработку с долей скептицизма, указав на ряд ограничений. Например, в формат XML инструмент переводит только собственные файлы конфигурации. Среди проблем UCL также отметили отсутствие подробной документации.
Возможно, что простой переделки кавычек и скобочек недостаточно, чтобы переманить аудиторию. Проблемы с файлами конфигураций редко связаны с синтаксическими особенностями. Чаще всего их вызывают проверки на соответствие схеме — опечатки в названии или дубли ключей. Чтобы у библиотеки было будущее, она должна решить именно эту проблему.
Если вы хотите поближе познакомиться с UCL и самостоятельно оценить его сильные и слабые стороны, то репозиторий на GitHub будет неплохой точкой для старта. В целом библиотеку можно использовать как в собственных, так и коммерческих проектах, так как она распространяется по лицензии BSD 2-Clause.
Какие есть альтернативы: HOCON и Augeas
Разумеется, UCL не единственный формат, предлагающий альтернативу и упрощающий работу с JSON. Примером может быть инструмент HOCON. Он похож на UCL, но поддерживает работу с API от Java и C#. Ориентирован на борьбу с дублированием данных и использует собственные функции «слияния» для объединения объектов или файлов, а также «подстановки» — для ссылок на другие части конфигурации или переменные среды.
Другой пример — утилита Augeas. Это — C-библиотека, которая парсит конфигурационные файлы и представляет их содержимое в виде древовидной структуры. Утилита помогает разработчикам автоматизировать взаимодействие с разными конфигурационными файлами и решает проблему несогласованности. Впрочем, инструмент официально поддерживает далеко не все виды конфигураций.
А какие альтернативы и аналоги JSON знаете вы?
Больше о возможностях масштабирования инфраструктуры:
- Virtual Infrastructure для разработчиков и сисадминов: обзор сервиса #CloudMTS
- Джентльменский набор IaaS: считаем преимущества, составляем план, используем бонусы для запуска ИТ-инфраструктуры
- Как вырасти с двух десятков до 700+ виртуальных машин в облаке и научиться выдерживать мощные нагрузки: опыт BelkaCar
Работа с JSON
Для работы с данными в формате JSON предназначены типы ЧтениеJson и ЗаписьJson. Они обеспечивают
Они обеспечивают
потоковое чтение и потоковую запись JSON.
Кроме того, вы можете автоматически преобразовывать в/из JSON многие типы встроенного
языка.
Поддержка комментариев
При чтении JSON поддерживаются однострочные комментарии, введенные в
версии JSON5 формата JSON.
Комментарий начинается с символов // и заканчивается с концом строки.
Содержимое комментария при чтении JSON игнорируется, то есть результат чтения JSON не
включает содержимого комментариев и не содержит какой-либо информации о наличии
комментариев.
Сериализация в формат JSON и десериализация
«1С:Исполнитель» обеспечивает сериализацию в формат JSON и обратную операцию — десериализацию. Основным типом для выполнения
этих операций является СериализацияJson. Экземпляр этого типа вы можете получить из свойства глобального контекста
СериализацияJson. Методы этого типа позволяют:
Методы этого типа позволяют:
- прочитать значение JSON в экземпляр типа, поддерживаемого «1С:Исполнителем» — ПрочитатьОбъект(),
- прочитать значение JSON в Соответствие — ПрочитатьСоответствие(),
- прочитать значение JSON в Массив — ПрочитатьМассив(),
- записать экземпляр типа, поддерживаемого «1С:Исполнителем», в значение JSON в поток — ЗаписатьОбъект(ПотокЗаписи,
Объект, НастройкиЗаписиОбъектовJson), - записать экземпляр типа, поддерживаемого «1С:Исполнителем», в значение JSON в строку — ЗаписатьОбъект(Объект,
НастройкиЗаписиОбъектовJson): Строка,
Если в структуре описание типа какого-либо поля включает Неопределено (например, пер Поле1: Строка? или
пер Поле1: Строка | Неопределено), то при чтении JSON в эту структуру методом
СериализацияJson. при отсутствии этого поля в JSON полю будет присвоено значение ПрочитатьОбъект
ПрочитатьОбъект
Неопределено.
Для настройки сериализации и десериализации существуют типы настроек со свойствами. Экземпляры этих типов используются в перечисленных
выше методах:
- Тип НастройкиЧтенияОбъектовJson:
- Кодировка — кодировка, которая будет использована при
чтении из потока; - ПсевдонимыCвойств — псевдонимы для имени свойства JSON для
конкретного свойства структуры; - ИгнорироватьНеизвестныеСвойства — признак игнорирования
неизвестных (лишних) полей в тексте JSON.
- Кодировка — кодировка, которая будет использована при
- тип НастройкиЗаписиОбъектовJson:
- ИспользуемыеИменаСвойств — устанавливает признак изменения записываемого имени свойства по аналогии с
@JsonProperty, - ИгнорируемыеСвойства — устанавливает признак игнорирования в результирующем экземпляре JSON определенных
свойств, - ЗаписьСвойствБезОбработки — свойства, которые будут записаны без обработки («как есть»),
- РежимЗаписиТипаЗначенияJson — способ записи информации о типе значения.

- ИспользуемыеИменаСвойств — устанавливает признак изменения записываемого имени свойства по аналогии с

В типе ЧтениеJson существуют методы для чтения значения JSON в один из конкретных типов:
- ПрочитатьСодержимоеКакДата(),
- ПрочитатьСодержимоеКакВремя(),
- ПрочитатьСодержимоеКакДлительность(),
- ПрочитатьСодержимоеКакБайты().
Также в ЧтениеJson существуют свойства для определения текущей строки и текущего столбца в позиции чтения:
- ТекущаяСтрока,
- ТекущийСтолбец.
Проверьте свои навыки: JSON — Изучите веб-разработку
Целью этого теста является проверка того, поняли ли вы нашу статью «Работа с JSON».
Примечание: Вы можете опробовать решения в интерактивных редакторах ниже, однако может быть полезно загрузить код и использовать онлайн-инструмент, такой как CodePen, jsFiddle или Glitch, для работы над задачами.
Если вы застряли, обратитесь к нам за помощью — см. раздел «Оценка или дополнительная помощь» внизу этой страницы.
Примечание: В приведенных ниже примерах, если в вашем коде есть ошибка, она будет выведена на панель результатов на странице, чтобы помочь вам найти ответ (или в консоль JavaScript браузера, в случае загружаемой версии).
Единственная задача в этой статье касается доступа к данным JSON и их использования на вашей странице. Данные JSON о некоторых мамах-кошках и их котятах доступны в файле sample.json. JSON загружается на страницу в виде текстовой строки и становится доступным в catString параметр функции displayCatInfo() . Ваша задача — заполнить недостающие части функции displayCatInfo() , чтобы сохранить:
- Имена трех кошек-матерей, разделенные запятыми, в переменной
motherInfo. - Общее количество котят (самцов и самок) в переменной
kittInfo.

Значения этих переменных затем выводятся на экран внутри абзацев.
Некоторые советы/вопросы:
- Данные JSON предоставляются в виде текста внутри функции
displayCatInfo(). Вам нужно будет разобрать его в JSON, прежде чем вы сможете извлечь из него какие-либо данные. - Вы, вероятно, захотите использовать внешний цикл для перебора кошек и добавления их имен в строку переменной
motherInfo, а внутренний цикл для перебора всех котят, сложения общего количества котят/кошек/самок , и добавьте эти данные в файлkittInfo 9.0016 переменная строка. - Перед последним именем кошки-матери должно стоять "и", а после него - точка. Как убедиться, что это работает, независимо от того, сколько котов в JSON?
- Почему
para1.textContent = motherInfo;иpara2.textContent = котенокИнформация;строк внутри функцииdisplayCatInfo(), а не в конце скрипта? Это как-то связано с асинхронным кодом.

Попробуйте обновить код ниже, чтобы воссоздать готовый пример:
Загрузите начальную точку для этой задачи, чтобы работать в собственном редакторе или в онлайн-редакторе.
Вы можете попрактиковаться в этих примерах в интерактивном редакторе выше.
Если вы хотите, чтобы ваша работа была оценена, или вы застряли и хотите обратиться за помощью:
- Напишите сообщение с просьбой об оценке и/или помощи в разделе «Обучение» форума MDN Discourse. Ваш пост должен включать:
- Описательный заголовок, например «Требуется оценка для теста навыков JSON».
- Подробная информация о том, что вы уже пробовали, и что вы хотели бы, чтобы мы сделали, например. если вы застряли и вам нужна помощь или хотите получить оценку.
- Ваш код.
- Ссылка на фактическую страницу задачи или оценки, чтобы мы могли найти вопрос, по которому вам нужна помощь.
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Посмотреть исходный код на GitHub.

Хотите принять больше участия?
Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
Работа с данными JSON в Python — Real Python
Смотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Работа с данными JSON в Python
С момента своего появления JSON быстро стал стандартом де-факто для обмена информацией. Скорее всего, вы здесь, потому что вам нужно передать некоторые данные отсюда туда. Возможно, вы собираете информацию через API или храните свои данные в базе данных документов. Так или иначе, вы по уши в JSON, и у вас есть выход на Python.
К счастью, это довольно распространенная задача, и, как и в случае большинства обычных задач, Python делает ее почти отвратительно простой. Не бойтесь, товарищи Pythoneers и Pythonistas. Это будет на ура!
Не бойтесь, товарищи Pythoneers и Pythonistas. Это будет на ура!
Итак, мы используем JSON для хранения и обмена данными?
Ага, ты понял! Это не более чем стандартизированный формат, который сообщество использует для передачи данных. Имейте в виду, что JSON — не единственный формат, доступный для такого рода работы, но XML и YAML, вероятно, единственные, заслуживающие упоминания одновременно.
(Очень) краткая история JSON
Неудивительно, что J ava S cript O bject N otation был вдохновлен подмножеством языка программирования JavaScript, работающим с литеральным синтаксисом объекта. У них есть отличный веб-сайт, который объясняет все это. Однако не беспокойтесь: JSON уже давно стал независимым от языка и существует как собственный стандарт, поэтому мы можем, к счастью, избегать JavaScript ради этого обсуждения.
В конечном итоге все сообщество приняло JSON, потому что его легко создавать и понимать как людям, так и машинам.
Удалить рекламу
Смотри, это JSON!
Будьте готовы. Я собираюсь показать вам реальный JSON — такой, какой вы видели бы в дикой природе. Это нормально: JSON должен быть удобочитаемым для всех, кто использовал язык в стиле C, а Python — это язык в стиле C… так что это вы!
{
"firstName": "Джейн",
"lastName": "Доу",
"хобби": ["бег", "прыжки с парашютом", "пение"],
"возраст": 35,
"дети": [
{
"firstName": "Алиса",
"возраст": 6
},
{
"firstName": "Боб",
"возраст": 8
}
]
}
Как видите, JSON поддерживает примитивные типы, такие как строки и числа, а также вложенные списки и объекты.
Подождите, это похоже на словарь Python!
Я точно знаю? На данный момент это в значительной степени универсальное обозначение объектов, но я не думаю, что UON слетает с языка так же хорошо. Не стесняйтесь обсуждать альтернативы в комментариях.

Ура! Вы пережили свою первую встречу с каким-то диким JSON. Теперь вам просто нужно научиться приручать его.
Python изначально поддерживает JSON!
Python поставляется со встроенным пакетом json для кодирования и декодирования данных JSON.
Просто поместите этого маленького человека вверху вашего файла:
импорт json
Маленький словарный запас
Процесс кодирования JSON обычно называется сериализацией . Этот термин относится к преобразованию данных в серию байтов (отсюда последовательный ) для хранения или передачи по сети. Вы также можете услышать термин маршалирует , но это совсем другой разговор. Естественно, десериализация — это взаимный процесс декодирования данных, которые были сохранены или доставлены в стандарте JSON.
Здорово! Это звучит довольно технично.
Определенно.
 Но на самом деле все, о чем мы здесь говорим, это , читающий , и , записывающий . Подумайте об этом так: кодирует для записи данных на диск, а декодирует для чтение данных в память.
Но на самом деле все, о чем мы здесь говорим, это , читающий , и , записывающий . Подумайте об этом так: кодирует для записи данных на диск, а декодирует для чтение данных в память.Сериализация JSON
Что происходит после того, как компьютер обрабатывает большое количество информации? Нужно сделать дамп данных. Соответственно, библиотека json предоставляет метод dump() для записи данных в файлы. Существует также метод dumps() (произносится как «dump-s») для записи в строку Python.
простых объекта Python переводятся в JSON в соответствии с довольно интуитивным преобразованием.
| Питон | JSON |
|---|---|
дикт | объект |
список , кортеж | массив |
стр | струна |
int , long , float | номер |
Правда | правда |
Ложь | ложный |
Нет | ноль |
Простой пример сериализации
Представьте, что вы работаете с объектом Python в памяти, который выглядит примерно так:
данные = {
"президент": {
"name": "Зафод Библброкс",
"вид": "бетельгейский"
}
}
Крайне важно, чтобы вы сохранили эту информацию на диск, поэтому ваша задача — записать ее в файл.
Используя контекстный менеджер Python, вы можете создать файл с именем data_file.json и открыть его в режиме записи. (Файлы JSON удобно заканчиваются расширением .json .)
с open("data_file.json", "w") как write_file:
json.dump(данные, файл_записи)
Обратите внимание, что dump() принимает два позиционных аргумента: (1) объект данных для сериализации и (2) файловый объект, в который будут записываться байты.
Или, если вы склонны продолжать использовать эти сериализованные данные JSON в своей программе, вы можете записать их в собственный объект Python str .
json_string = json.dumps(данные)
Обратите внимание, что файлоподобный объект отсутствует, так как вы фактически не записываете на диск. Кроме этого, dumps() точно так же, как dump() .
Ура! У вас родился маленький JSON, и вы готовы выпустить его в дикую природу, чтобы он стал большим и сильным.
Удалить рекламу
Некоторые полезные аргументы ключевых слов
Помните, что JSON предназначен для легкого чтения людьми, но читабельного синтаксиса недостаточно, если все это сжато вместе. Кроме того, у вас, вероятно, другой стиль программирования, чем у меня, и вам может быть легче читать код, когда он отформатирован по вашему вкусу.
ПРИМЕЧАНИЕ:
Оба методаdump()иdumps()используют одни и те же аргументы ключевого слова.
Первая опция, которую большинство людей хотят изменить, это пробелы. Вы можете использовать аргумент ключевого слова indent , чтобы указать размер отступа для вложенных структур. Оцените разницу сами, используя data , которые мы определили выше, и выполнив следующие команды в консоли:
>>>
>>> json.dumps(данные) >>> json.dumps(данные, отступ=4)
Другим вариантом форматирования является аргумент ключевого слова разделителей . По умолчанию это 2-кортеж строк-разделителей
По умолчанию это 2-кортеж строк-разделителей (",", ":") , но распространенной альтернативой для компактного JSON является (",", ":") . Взгляните на пример JSON еще раз, чтобы увидеть, где эти разделители вступают в игру.
Есть и другие, например sort_keys , но я понятия не имею, что делает тот. Вы можете найти полный список в документации, если вам интересно.
Десериализация JSON
Отлично, похоже, вы поймали себя на диком JSON! Теперь пришло время привести его в форму. В json вы найдете load() и load() для преобразования данных, закодированных JSON, в объекты Python.
Как и при сериализации, существует простая таблица преобразования для десериализации, хотя вы, вероятно, уже догадались, как она выглядит.
| JSON | Питон |
|---|---|
объект | дикт |
массив | список |
строка | стр |
номер (внутренний) | внутр. |
номер (реальный) | поплавок |
правда | Правда |
ложный | Ложь |
ноль | Нет |
Технически это преобразование не является полной инверсией таблицы сериализации. В основном это означает, что если вы кодируете объект сейчас, а затем снова декодируете его позже, вы можете не получить точно такой же объект обратно. Я думаю, это немного похоже на телепортацию: разбиваю молекулы здесь и собираю их там. Я все тот же человек?
На самом деле это скорее похоже на то, как если бы один друг перевел что-то на японский, а другой — обратно на английский. Несмотря на это, самым простым примером будет кодирование кортеж и получение списка после декодирования, например:
>>>
>>> блэкджек_рука = (8, "Q") >>> encoded_hand = json.
 dumps(blackjack_hand)
>>> decoded_hand = json.loads(encoded_hand)
>>> блэкджек_рука == декодированная_рука
ЛОЖЬ
>>> тип(блэкджек_рука)
<класс 'кортеж'>
>>> введите (decoded_hand)
<класс 'список'>
>>> blackjack_hand == tuple(decoded_hand)
Истинный
dumps(blackjack_hand)
>>> decoded_hand = json.loads(encoded_hand)
>>> блэкджек_рука == декодированная_рука
ЛОЖЬ
>>> тип(блэкджек_рука)
<класс 'кортеж'>
>>> введите (decoded_hand)
<класс 'список'>
>>> blackjack_hand == tuple(decoded_hand)
Истинный
Простой пример десериализации
На этот раз представьте, что у вас есть данные, хранящиеся на диске, которыми вы хотите манипулировать в памяти. Вы по-прежнему будете использовать менеджер контекста, но на этот раз вы откроете существующий файл data_file.json в режиме чтения.
с open("data_file.json", "r") как read_file:
данные = json.load(read_file)
Здесь все довольно просто, но имейте в виду, что результат этого метода может возвращать любой из допустимых типов данных из таблицы преобразования. Это важно только в том случае, если вы загружаете данные, которых раньше не видели. В большинстве случаев корневым объектом будет dict или список .
Если вы извлекли данные JSON из другой программы или иным образом получили строку данных в формате JSON в Python, вы можете легко десериализовать их с помощью load() , которая естественным образом загружается из строки:
json_string = """
{
"Исследователь": {
"имя": "Форд Префект",
"виды": "бетельгейсовы",
"родственники": [
{
"name": "Зафод Библброкс",
"вид": "бетельгейский"
}
]
}
}
"""
данные = json. loads(json_string)
 loads(json_string)
loads(json_string)
Вуаля! Вы приручили дикий JSON, и теперь он под вашим контролем. Но то, что вы будете делать с этой силой, зависит от вас. Вы можете кормить его, воспитывать и даже учить трюкам. Не то чтобы я тебе не доверял… но держи его на привязи, ладно?
Удалить рекламу
Пример из реальной жизни (вроде)
В качестве вводного примера вы будете использовать JSONPlaceholder, отличный источник поддельных данных JSON для практических целей.
Сначала создайте файл сценария с именем cratch.py или что угодно. Я не могу тебя остановить.
Вам нужно будет сделать запрос API к службе JSONPlaceholder, поэтому просто используйте пакет запросов , чтобы выполнить тяжелую работу. Добавьте эти импорты вверху вашего файла:
импорт json запросы на импорт
Теперь вы будете работать со списком TODO, потому что… ну, вы знаете, это обряд посвящения или что-то в этом роде.
Сделайте запрос к JSONPlaceholder API для /todos конечная точка. Если вы не знакомы с запросами
Если вы не знакомы с запросами , на самом деле есть удобный метод json() , который сделает всю работу за вас, но вы можете попрактиковаться в использовании библиотеки json для десериализации атрибута text ответа. объект. Это должно выглядеть примерно так:
ответ = запросы.получить("https://jsonplaceholder.typicode.com/todos")
todos = json.loads(ответ.текст)
Вы не верите, что это работает? Хорошо, запустите файл в интерактивном режиме и проверьте сами. Пока вы это делаете, проверьте тип дела . Если вы чувствуете себя авантюрно, взгляните на первые 10 или около того пунктов в списке.
>>>
>>> задачи == response.json() Истинный >>> введите (список дел) <класс 'список'> >>> дела[:10] ...
Видишь ли, я бы не стал тебе врать, но я рад, что ты скептик.
Что такое интерактивный режим?
А, я думал, ты никогда не спросишь! Вы знаете, как вы всегда прыгаете туда-сюда между своим редактором и терминалом? Ну, мы, подлые Pythoneers, используем-iинтерактивный флаг при запуске скрипта.
 Это отличный маленький трюк для тестирования кода, потому что он запускает сценарий, а затем открывает интерактивную командную строку с доступом ко всем данным из сценария!
Это отличный маленький трюк для тестирования кода, потому что он запускает сценарий, а затем открывает интерактивную командную строку с доступом ко всем данным из сценария!Ладно, пора действовать. Вы можете увидеть структуру данных, посетив конечную точку в браузере, но вот пример TODO:
{
"идентификатор пользователя": 1,
"идентификатор": 1,
"title": "delectus aut autem",
"завершено": ложь
}
Существует несколько пользователей, каждый из которых имеет уникальный userId , и каждая задача имеет логическое свойство завершено . Можете ли вы определить, какие пользователи выполнили больше всего задач?
# Сопоставление userId с количеством полных TODO для этого пользователя
todos_by_user = {}
# Увеличить количество выполненных TODO для каждого пользователя.
для задач в todos:
если дело["завершено"]:
пытаться:
# Увеличить количество существующих пользователей.
todos_by_user[todo["userId"]] += 1
кроме KeyError:
# Этот пользователь не был замечен. Установите их количество на 1.
todos_by_user[todo["userId"]] = 1
# Создать отсортированный список пар (userId, num_complete).
top_users = отсортировано (todos_by_user.items(),
ключ=лямбда х: х[1], реверс=Истина)
# Получите максимальное количество полных TODO.
max_complete = топ_пользователей[0][1]
# Создать список всех пользователей, выполнивших
# максимальное количество TODO.
пользователи = []
для пользователя, num_complete в top_users:
если num_complete < max_complete:
перерыв
пользователи.append (ул (пользователь))
max_users = " и ".join(пользователи)
 Установите их количество на 1.
todos_by_user[todo["userId"]] = 1
# Создать отсортированный список пар (userId, num_complete).
top_users = отсортировано (todos_by_user.items(),
ключ=лямбда х: х[1], реверс=Истина)
# Получите максимальное количество полных TODO.
max_complete = топ_пользователей[0][1]
# Создать список всех пользователей, выполнивших
# максимальное количество TODO.
пользователи = []
для пользователя, num_complete в top_users:
если num_complete < max_complete:
перерыв
пользователи.append (ул (пользователь))
max_users = " и ".join(пользователи)
Установите их количество на 1.
todos_by_user[todo["userId"]] = 1
# Создать отсортированный список пар (userId, num_complete).
top_users = отсортировано (todos_by_user.items(),
ключ=лямбда х: х[1], реверс=Истина)
# Получите максимальное количество полных TODO.
max_complete = топ_пользователей[0][1]
# Создать список всех пользователей, выполнивших
# максимальное количество TODO.
пользователи = []
для пользователя, num_complete в top_users:
если num_complete < max_complete:
перерыв
пользователи.append (ул (пользователь))
max_users = " и ".join(пользователи)
Да, да, ваша реализация лучше, но дело в том, что теперь вы можете манипулировать данными JSON как обычным объектом Python!
Не знаю, как вы, но когда я снова запускаю скрипт в интерактивном режиме, я получаю следующие результаты:
>>>
>>> s = "s", если len(users) > 1 else ""
>>> print(f"user{s} {max_users} выполнил {max_complete} TODO")
пользователи 5 и 10 выполнили 12 TODO
Это круто и все такое, но вы здесь, чтобы узнать о JSON. В качестве последней задачи вы создадите файл JSON, содержащий выполнил TODO для каждого из пользователей, выполнивших максимальное количество TODO.
В качестве последней задачи вы создадите файл JSON, содержащий выполнил TODO для каждого из пользователей, выполнивших максимальное количество TODO.
Все, что вам нужно сделать, это отфильтровать todos и записать полученный список в файл. Для оригинальности можно назвать выходной файл filtered_data_file.json . Есть много способов сделать это, но вот один из них:
.
# Определите функцию для фильтрации завершенных TODO
# пользователей с максимальным количеством завершенных TODOS.
деф держать (что делать):
is_complete = задача["завершено"]
has_max_count = str(todo["userId"]) пользователей
вернуть is_complete и has_max_count
# Записать отфильтрованные TODO в файл.
с open("filtered_data_file.json", "w") в качестве data_file:
filtered_todos = список (фильтр (сохранить, todos))
json.dump (filtered_todos, data_file, отступ = 2)
Отлично, вы избавились от всех ненужных данных и сохранили нужные в новый файл! Запустите скрипт еще раз и проверьте filtered_data_file., чтобы убедиться, что все работает. Он будет находиться в том же каталоге, что и  json
json cratch.py , когда вы его запустите.
Теперь, когда ты зашел так далеко, держу пари, ты чувствуешь себя довольно сексуально, не так ли? Не зазнавайся: смирение — это добродетель. Хотя я склонен с вами согласиться. До сих пор все было гладко, но вы, возможно, захотите задраить люки перед последним этапом путешествия.
Удаление рекламы
Кодирование и декодирование пользовательских объектов Python
Что происходит, когда мы пытаемся сериализовать класс Elf из приложения Dungeons & Dragons, над которым вы работаете?
класс Эльф:
def __init__(я, уровень, Ability_scores=Нет):
селф.уровень = уровень
self.ability_scores = {
"str": 11, "dex": 12, "con": 10,
«целое»: 16, «мудрое»: 14, «ча»: 13
} если Ability_scores имеет значение None, иначе Ability_scores
self. hp = 10 + self.ability_scores["con"]
 hp = 10 + self.ability_scores["con"]
hp = 10 + self.ability_scores["con"]
Неудивительно, что Python жалуется, что Elf не является сериализуемым (о чем вы бы знали, если бы когда-нибудь пытались сказать Elf иначе):
>>>
>>> эльф = эльф (уровень=4) >>> json.dumps(эльф) TypeError: Объект типа «Эльф» не сериализуем JSON
Хотя модуль json может обрабатывать большинство встроенных типов Python, он не понимает, как кодировать настраиваемые типы данных по умолчанию. Это все равно, что пытаться вставить квадратный колышек в круглое отверстие — вам понадобится циркулярная пила и родительский контроль.
Упрощение структур данных
Теперь вопрос в том, как работать с более сложными структурами данных. Что ж, вы можете попытаться кодировать и декодировать JSON вручную, но есть немного более умное решение, которое сэкономит вам часть работы. Вместо того, чтобы сразу перейти от пользовательского типа данных к JSON, вы можете добавить промежуточный шаг.
Все, что вам нужно сделать, это представить ваши данные в терминах встроенных типов json , которые уже понимает. По сути, вы переводите более сложный объект в более простое представление, которое 9Затем модуль 0015 json преобразуется в JSON. Это как свойство транзитивности в математике: если A = B и B = C, то A = C.
Чтобы освоить это, вам понадобится сложный объект для игры. Вы можете использовать любой пользовательский класс, который вам нравится, но в Python есть встроенный тип complex для представления комплексных чисел, и по умолчанию он не сериализуем. Итак, ради этих примеров ваш сложный объект будет сложным объектом . Еще не запутались?
>>>
>>> z = 3 + 8j >>> тип(г) <класс 'сложный'> >>> json.dumps(z) TypeError: Объект типа «сложный» не сериализуем JSON
Откуда берутся комплексные числа?
Видите ли, когда действительное число и мнимое число очень сильно любят друг друга, они складываются вместе, чтобы произвести число, которое (справедливо) называют сложным .

Хороший вопрос, который следует задать себе при работе с пользовательскими типами: Какой минимальный объем информации необходим для воссоздания этого объекта? В случае комплексных чисел вам нужно знать только действительную и мнимую части, обе из которых вы можете получить в качестве атрибутов сложного объекта :
>>>
>>> г.реал 3.0 >>> z.imag 8,0
Передача одних и тех же чисел в сложный конструктор достаточна для выполнения оператора сравнения __eq__ :
>>>
>>> комплекс(3, 8) == z Истинный
Разбиение пользовательских типов данных на их основные компоненты имеет решающее значение как для процессов сериализации, так и для процессов десериализации.
Кодирование пользовательских типов
Чтобы преобразовать пользовательский объект в JSON, все, что вам нужно сделать, это предоставить функцию кодирования для параметра по умолчанию метода dump() . Модуль
Модуль json будет вызывать эту функцию для любых объектов, которые изначально не сериализуемы. Вот простая функция декодирования, которую вы можете использовать для практики:
по определению encode_complex(z):
если isinstance (z, комплекс):
возврат (z.real, z.imag)
еще:
type_name = z.__class__.__name__
поднять TypeError(f"Объект типа '{type_name}' не сериализуем JSON")
Обратите внимание, что ожидается, что вы вызовете TypeError , если вы не получите ожидаемый тип объекта. Таким образом, вы избежите случайной сериализации любых эльфов. Теперь вы можете сами попробовать закодировать сложные объекты!
>>>
>>> json.dumps(9 + 5j, по умолчанию=encode_complex) '[9.0, 5.0]' >>> json.dumps(эльф, по умолчанию=encode_complex) TypeError: Объект типа «Эльф» не сериализуем JSON
Почему мы закодировали комплексное число как кортеж
?
Отличный вопрос! Конечно, это был не единственный выбор и не обязательно лучший выбор.
 На самом деле, это было бы не очень хорошим представлением, если бы вы захотели декодировать объект позже, как вы скоро увидите.
На самом деле, это было бы не очень хорошим представлением, если бы вы захотели декодировать объект позже, как вы скоро увидите. Другим распространенным подходом является создание подкласса стандартного JSONEncoder и переопределение его метода default() :
класс ComplexEncoder (json.JSONEncoder):
по умолчанию (я, г):
если isinstance (z, комплекс):
возврат (z.real, z.imag)
еще:
вернуть супер(). по умолчанию (z)
Вместо того, чтобы самостоятельно вызывать TypeError , вы можете просто позволить базовому классу справиться с этим. Вы можете использовать это либо непосредственно в dump() метод с помощью параметра cls или путем создания экземпляра кодировщика и вызова его метода encode() :
>>>
>>> json.dumps(2 + 5j, cls=ComplexEncoder) '[2.0, 5.0]' >>> кодировщик = ComplexEncoder() >>> encoder.encode(3 + 6j) '[3.
 0, 6.0]'
0, 6.0]'
Удалить рекламу
Декодирование пользовательских типов
Хотя действительная и мнимая части комплексного числа абсолютно необходимы, на самом деле их недостаточно для воссоздания объекта. Вот что происходит, когда вы пытаетесь закодировать комплексное число с помощью ComplexEncoder и затем декодирование результата:
>>>
>>> complex_json = json.dumps(4 + 17j, cls=ComplexEncoder) >>> json.loads(complex_json) [4,0, 17,0]
Все, что вы получите в ответ, — это список, и вам придется передать значения в конструктор сложного , если вы хотите снова получить этот сложный объект. Вспомните наш разговор о телепортации. Не хватает метаданных или информации о типе данных, которые вы кодируете.
Я полагаю, что вопрос, который вы действительно должны задать себе, Каков минимальный объем информации, который одновременно необходим и достаточен для воссоздания этого объекта?
Модуль json ожидает, что все пользовательские типы будут выражены как объектов в стандарте JSON.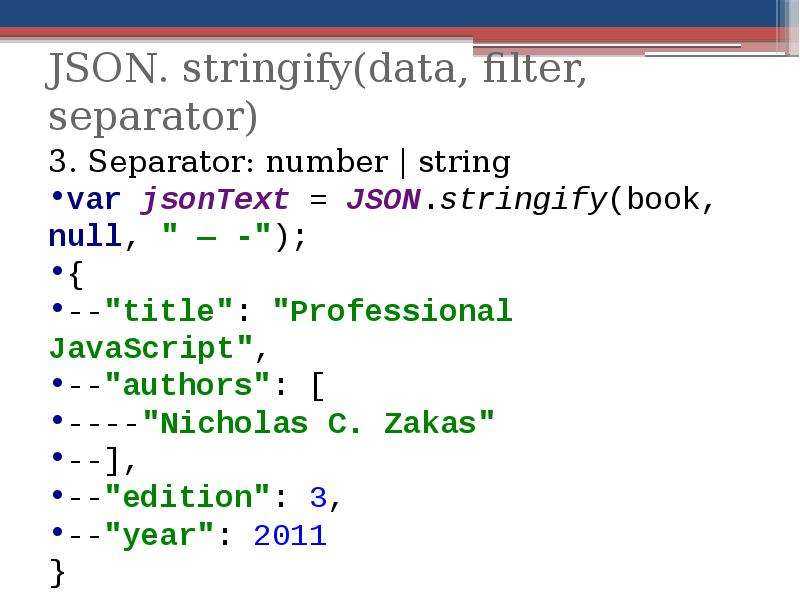 Для разнообразия вы можете создать файл JSON на этот раз с именем
Для разнообразия вы можете создать файл JSON на этот раз с именем complex_data.json и добавить следующий объект , представляющий комплексное число:
{
"__complex__": правда,
«настоящие»: 42,
"имаг": 36
}
Видите хитрость? Этот ключ "__complex__" является метаданными, о которых мы только что говорили. На самом деле не имеет значения, каково связанное значение. Чтобы заставить этот небольшой хак работать, все, что вам нужно сделать, это убедиться, что ключ существует:
def decode_complex(dct):
если "__complex__" в ДКП:
возвращаемый комплекс (dct["real"], dct["imag"])
возврат ДКП
Если "__complex__" отсутствует в словаре, вы можете просто вернуть объект и позволить декодеру по умолчанию обработать его.
Каждый раз, когда метод load() пытается проанализировать объект , вам предоставляется возможность вмешаться до того, как декодер по умолчанию обработает данные. Вы можете сделать это, передав функцию декодирования параметру
Вы можете сделать это, передав функцию декодирования параметру object_hook .
Теперь играйте в ту же игру, что и раньше:
>>>
>>> с open("complex_data.json") как complex_data:
... данные = complex_data.read()
... z = json.loads (данные, object_hook = decode_complex)
...
>>> тип(г)
<класс 'сложный'>
Хотя object_hook может показаться аналогом параметра по умолчанию метода dump() , на самом деле аналогия начинается и заканчивается.
Это работает не только с одним объектом. Попробуйте поместить этот список комплексных чисел в complex_data.json и снова запустить скрипт:
[
{
"__complex__": правда,
«настоящий»: 42,
"изображение": 36
},
{
"__complex__": правда,
«настоящий»: 64,
"изображение":11
}
]
Если все пойдет хорошо, вы получите список из сложных объектов:
>>>
>>> с open("complex_data. json") как complex_data:
... данные = complex_data.read()
... числа = json.loads (данные, object_hook = decode_complex)
...
>>> номера
[(42+36д), (64+11д)]
 json") как complex_data:
... данные = complex_data.read()
... числа = json.loads (данные, object_hook = decode_complex)
...
>>> номера
[(42+36д), (64+11д)]
json") как complex_data:
... данные = complex_data.read()
... числа = json.loads (данные, object_hook = decode_complex)
...
>>> номера
[(42+36д), (64+11д)]
Вы также можете попробовать создать подкласс JSONDecoder и переопределить object_hook , но по возможности лучше придерживаться облегченного решения.
Готово!
Поздравляем, теперь вы можете использовать могучую силу JSON для любых ваших гнусных потребностей Python.
Хотя примеры, с которыми вы работали здесь, безусловно, надуманы и чрезмерно упрощены, они иллюстрируют рабочий процесс, который вы можете применить к более общим задачам:
- Импорт пакета
json. - Считайте данные с помощью
load()илиload(). - Обработать данные.
- Запишите измененные данные с помощью
dump()илиdumps().
Что вы будете делать с данными после их загрузки в память, зависит от вашего варианта использования.